↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Blind image deblurring (BID) is a challenging task, typically relying on supervised learning with ground-truth images which is often impractical. Existing self-supervised BID methods have limitations in terms of performance, particularly on modestly blurred images and real-world images. They typically involve heuristic loss functions and lack efficient training strategies. This limits their applicability in various domains.
This paper proposes a novel self-supervised BID method that overcomes these limitations. It leverages implicit neural representations (INRs) for images and kernels to achieve resolution-free properties, leading to an effective cross-scale consistency loss. This loss function, combined with a progressive coarse-to-fine training strategy, allows for more accurate and efficient training without ground truth data. The method outperforms existing self-supervised methods across diverse datasets, demonstrating its effectiveness in handling various blur types and real-world images. The INR-based approach offers a more robust and adaptable framework for future self-supervised BID research. This innovative method significantly enhances the performance of self-supervised BID, offering significant advancements for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image processing and computer vision due to its novel self-supervised approach to blind image deblurring. It addresses the limitations of existing methods that rely on ground truth data, paving the way for more practical and versatile deblurring techniques applicable to various real-world scenarios. The proposed cross-scale consistency loss and progressive training strategy, utilizing implicit neural representations, offer significant advancements in the field, potentially impacting applications from medical imaging to surveillance.
Visual Insights#

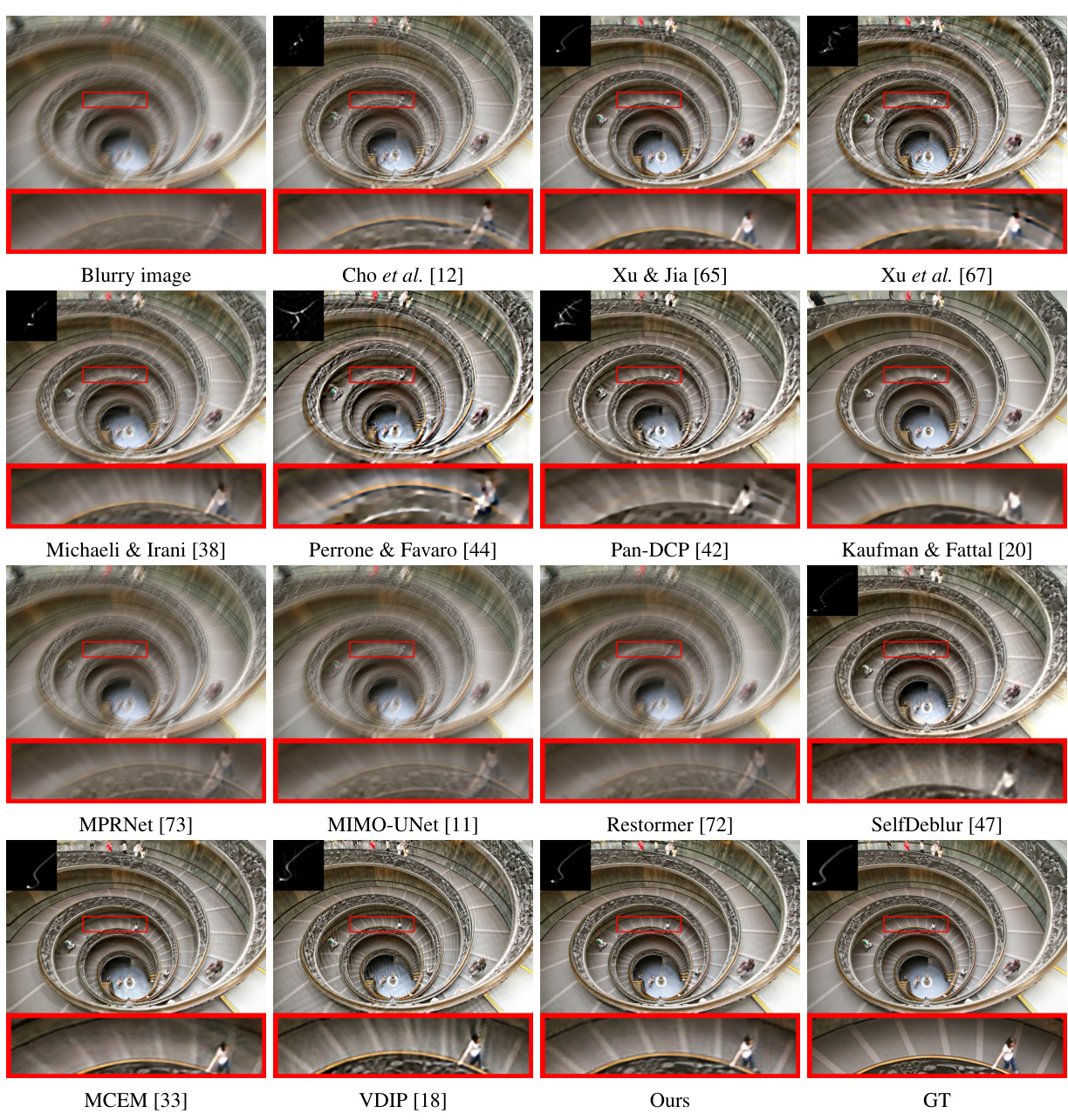
This figure displays visual comparisons of different deblurring methods on a subset of images from the Lai et al. dataset [26]. The dataset is known for having severely blurred images, thus making it a challenging benchmark. The first column shows the blurry input images. Subsequent columns demonstrate the deblurred outputs from various traditional and deep learning-based methods. This provides a qualitative assessment of each method’s performance in terms of sharpness, artifact reduction, and overall image quality, compared to the ground truth images in the last column.
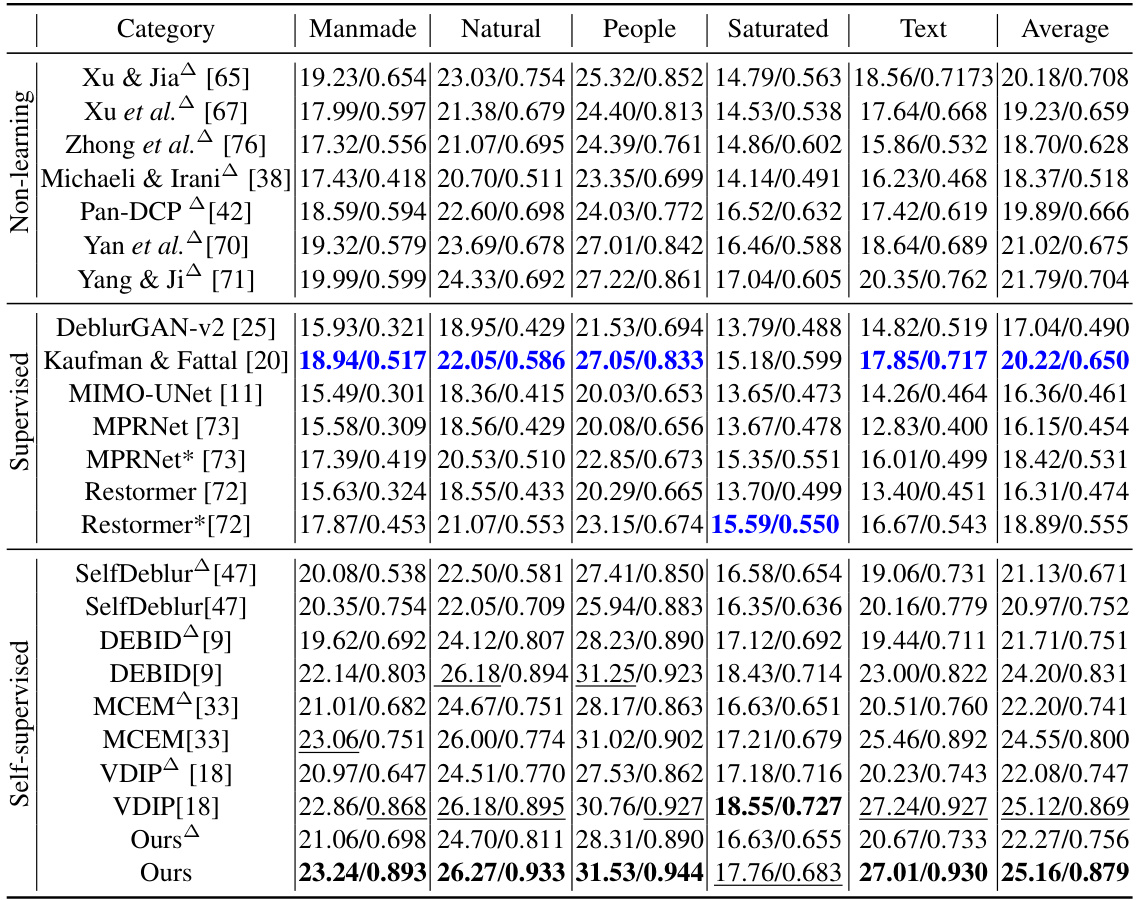
This table presents a comparison of the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) scores achieved by various blind image deblurring (BID) methods on the Lai et al. dataset. It compares non-learning, supervised, and self-supervised approaches, showing the performance of each method across different image categories (Manmade, Natural, People, Saturated, Text). Methods marked with △ used a standard protocol where a separate deblurring method [23] is used with the estimated blur kernel, while methods marked with * were retrained on the BSD-D dataset.
In-depth insights#
Cross-Scale Consistency#
Cross-scale consistency, in the context of image deblurring, is a crucial concept that leverages the inherent relationships between blurred images and their latent sharp counterparts across different scales. The core idea is to enforce consistency in the estimated blur kernel and latent image when the input image is downsampled. This approach is particularly useful in self-supervised scenarios where ground truth images are unavailable, providing a powerful form of regularization to prevent overfitting. By imposing this consistency, the method implicitly introduces prior knowledge about the blurring process’ behavior at different resolutions. This allows the network to learn robust representations that generalize well, improving the quality of deblurred images, especially in low-resolution regimes. The cross-scale consistency loss function, when paired with a progressively coarse-to-fine training strategy, ensures that the network converges efficiently toward more accurate, and less trivial, solutions.
INR in BID#
The application of Implicit Neural Representations (INRs) to Blind Image Deblurring (BID) offers a compelling approach to overcome limitations of traditional methods. INRs’ resolution-free property is particularly advantageous, allowing consistent processing across multiple scales without the artifacts introduced by manual rescaling or interpolation, inherent in many CNN-based approaches. This is crucial in BID due to its inherent ill-posed nature and its non-linearity. By leveraging the resolution-free property of INRs, the authors are able to build effective cross-scale consistency loss functions, thereby effectively regularizing the training process and mitigating overfitting issues. This is a key contribution since ground truth data is unavailable in self-supervised BID. The seamless multi-scale processing enabled by INRs is further utilized in a progressive coarse-to-fine training scheme which significantly enhances the training efficiency and accuracy. This combination of INR’s resolution-free property with a progressive training scheme forms a unique and powerful approach to self-supervised BID, ultimately leading to a significant performance gain over existing self-supervised methods.
Progressive Training#
Progressive training, in the context of this research paper, is a crucial technique enhancing the accuracy and efficiency of self-supervised blind image deblurring. It involves a coarse-to-fine strategy, starting with training the neural network on low-resolution representations of blurry images. This allows the model to initially grasp the overall structure and relationships within the image before delving into intricate details. Gradually increasing resolution during subsequent training stages refines the model’s understanding, preventing it from getting stuck in suboptimal local minima and ensuring convergence towards a more accurate deblurred image. This approach is particularly valuable in self-supervised settings, where the absence of ground truth data poses significant challenges for model regularization and optimization. The progressive training scheme effectively addresses overfitting by leveraging cross-scale consistency, ultimately leading to a significant performance improvement compared to other self-supervised and even some supervised methods.
Real-world Robustness#
Real-world robustness is a crucial aspect for evaluating the practical applicability of any image deblurring method. A model demonstrating high accuracy on synthetic datasets may fail to generalize effectively to real-world scenarios due to the presence of various unanticipated factors such as noise, non-uniform blur, and complex lighting conditions. A thorough evaluation on diverse real-world datasets is paramount to establish the true robustness and reliability of a proposed method. Such real-world testing often involves subjective quality assessments, comparing the results to ground truth images, or potentially using metrics such as PSNR and SSIM that might not always fully capture perceptual quality. Careful consideration must be given to the diversity and representative nature of the real-world datasets utilized, to ensure that the evaluation adequately captures the range of challenges that might be encountered in practice. The analysis of performance variations across these datasets highlights limitations and areas for improvement in the model’s generalization capabilities. Ultimately, a focus on real-world robustness enhances the impact and trustworthiness of the research findings, ensuring that the developed methodology is practically viable and truly beneficial.
Future of BID#
The future of blind image deblurring (BID) likely involves tackling its inherent ill-posed nature through more sophisticated regularization techniques. Implicit neural representations (INRs), as demonstrated in the paper, show promise by offering resolution-free properties enabling efficient multi-scale processing. Further research should explore advanced INRs or other neural architectures that can better model the complex relationships between blurred images, latent images, and blur kernels, potentially incorporating physics-based priors. Cross-scale consistency losses, also highlighted, provide a valuable self-supervised learning strategy for BID, but refinement of these methods is crucial for enhanced performance. Finally, the expansion of BID beyond uniform blurring, to encompass non-uniform blur types typical in real-world scenarios, is a critical area for future development; this will require robust methods capable of handling significantly more complex blur kernel estimations. Addressing these challenges will require a deeper synergy between deep learning techniques and image processing fundamentals.
More visual insights#
More on figures
This figure shows visual comparisons of different deblurring methods on a specific image from the Lai et al. dataset [26]. The results demonstrate that the proposed method produces sharper and more detailed images compared to existing methods, particularly in areas with fine details or complex blurring patterns.

This figure shows a visual comparison of the results from different methods on a subset of Lai et al.’s dataset [26]. The results demonstrate the effectiveness of the proposed method in handling severe blurring effects, with sharper details and fewer artifacts compared to existing methods. In contrast, supervised learning methods trained on external datasets yield poor quality results, highlighting the limited generalization performance of supervised approaches when dealing with complex real-world blurring.

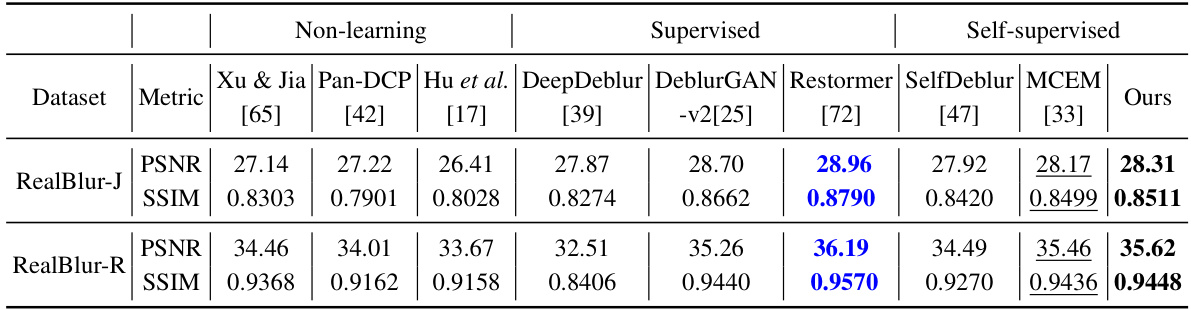
This figure compares the deblurring results of the proposed self-supervised method with several state-of-the-art supervised methods on challenging examples from the RealBlur-J dataset. Despite the proposed method having slightly lower quantitative scores (PSNR and SSIM), the visual results show that it produces sharper images with fewer artifacts compared to the supervised approaches. This highlights the ability of the self-supervised method to generate visually pleasing results even when the quantitative metrics do not show a significant advantage.

This figure shows a visual comparison of the results from different methods on a selection of images from Lai et al.’s dataset. The top row shows the blurry input image and the results from several traditional methods. The bottom row shows the results from several deep-learning methods (including the proposed method) and ground truth. It highlights the superior performance of the proposed method in producing sharp, artifact-free results that closely match the ground truth, particularly when compared to existing deep-learning methods.

This figure compares the visual results of the proposed self-supervised method against several state-of-the-art supervised learning methods on challenging cases from the RealBlur-J dataset. Despite achieving slightly lower average PSNR and SSIM values overall, the self-supervised method produces images with sharper details and fewer artifacts than the supervised methods in many cases, indicating that the visual quality is better than what the quantitative metrics alone might suggest.

This figure displays visual comparisons of deblurring results from various methods on a sample image from the Lai et al. dataset [26]. It showcases the blurry input image alongside results from several traditional and deep learning-based deblurring methods including Cho & Lee [12], Xu & Jia [65], Xu et al. [67], Michaeli & Irani [38], Perrone & Favaro [44], Pan-DCP [42], Kaufman & Fattal [20], MPRNet [73], MIMO-UNet [11], Restormer [72], SelfDeblur [47], MCEM [33], VDIP [18], and the authors’ proposed method. The ground truth (GT) image is also included for reference. The figure aims to visually demonstrate the superior performance of the authors’ proposed approach in producing sharper, artifact-free deblurred images compared to existing methods, especially in handling complex real-world blurring.

This figure compares the deblurring results of different methods on the Köhler et al. dataset, which is known for its non-uniform blurring. It demonstrates that the proposed method effectively handles this challenging scenario, generating high-quality images with sharp details and fewer artifacts compared to existing methods. The comparison highlights the limitations of other methods in dealing with complex real-world blurring scenarios.

This figure shows a visual comparison of different image deblurring methods applied to a sample image from the Lai et al. [26] dataset, which is known for its challenging blurring effects. The top row displays the blurry input image followed by results from several existing methods including Cho et al. [12], Xu & Jia [65], Xu et al. [67], Michaeli & Irani [38], Perrone & Favaro [44], Pan-DCP [42], Kaufman & Fattal [20], MPRNet [73], MIMO-UNet [11], Restormer [72], and SelfDeblur [47]. The bottom row shows results from MCEM [33], VDIP [18], the proposed method, and the ground truth image.

This figure shows a visual comparison of the results from state-of-the-art supervised learning methods and the proposed self-supervised method on challenging cases from the RealBlur-J dataset. The results demonstrate that while the supervised methods achieve slightly higher average PSNR and SSIM values, the self-supervised approach produces results that are often sharper and visually superior, suggesting that the gap between the methods is smaller in terms of visual quality than indicated by quantitative metrics alone.

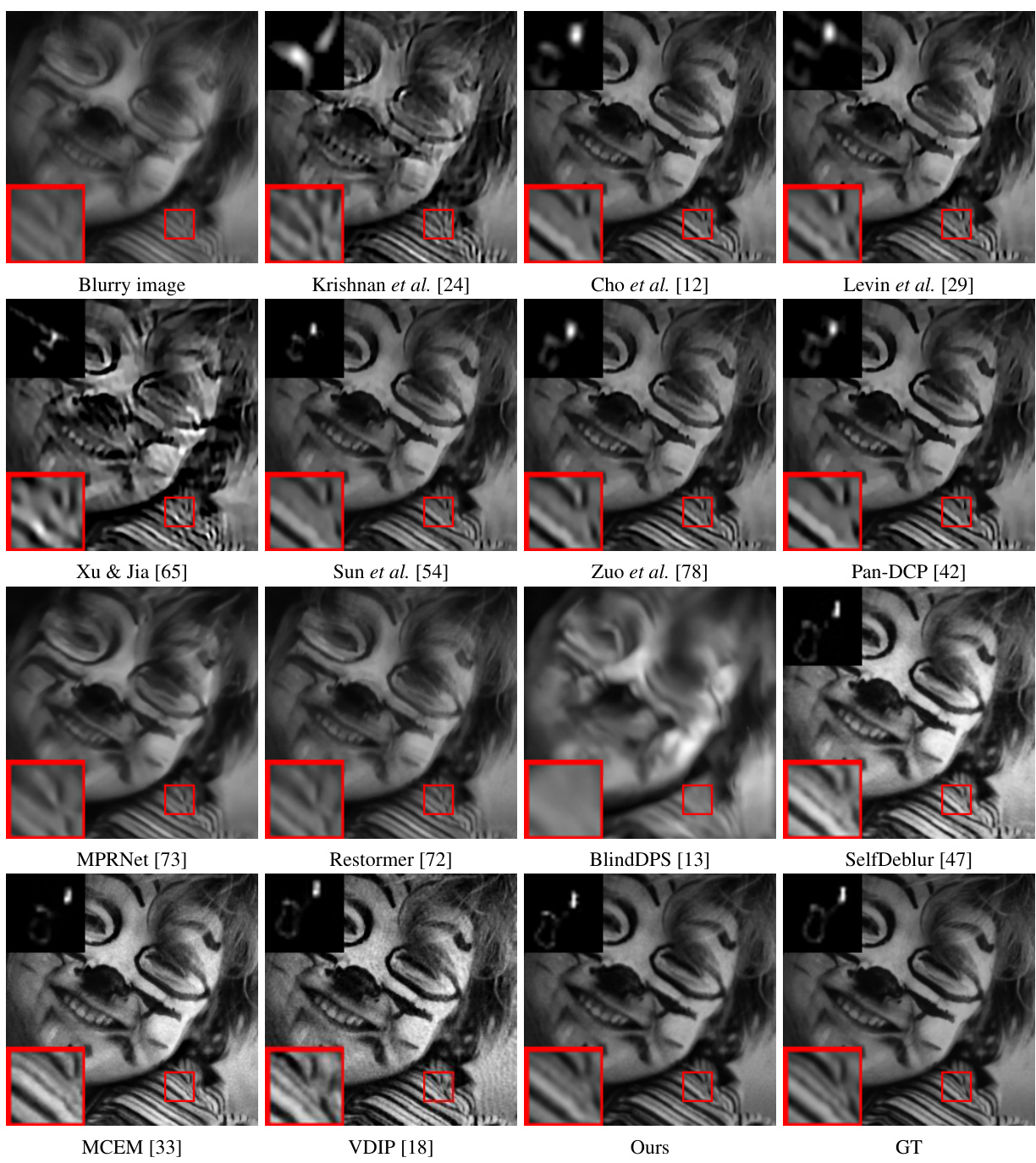
This figure shows a visual comparison of the results obtained by various methods on the microscopic deconvolution task. The goal is to highlight the differences in image restoration quality among the compared methods (INIKNet, SelfDeblur, BlindDPS, MCEM, VDIP, and the proposed method). Each row represents a different microscopic image and its reconstructions. The original blurry images are shown in the first column; followed by restored images from each method, and finally the ground truth (GT) image is displayed in the last column. A colormap is used to enhance the visual comparison and differences in textures and details.

This figure in the ablation study section presents a visual comparison of the results obtained using different configurations of the proposed method. It shows the impact of removing the cross-scale consistency loss, using only single-scale training, removing the progressive training scheme, and using different architectures for the image and kernel generators (INR/CNN, MLP/INR, MLP/CNN). A comparison with the ground truth image is also provided to evaluate the efficacy of the proposed approach.

This figure shows intermediate results of the proposed method at different stages of the progressive coarse-to-fine training process. It visualizes how the estimations of both the blur kernel and latent image improve progressively across scales, from coarser resolutions to finer details, eventually generating a high-quality deblurred image. This process demonstrates the effectiveness of the proposed progressive training scheme, illustrating the model’s ability to refine its estimates over multiple scales and converge to accurate reconstructions.

This figure shows a comparison of the results from different methods on some examples from Lai et al.’s dataset [26]. The dataset is known for its severe blurring effects. The figure demonstrates that the proposed method consistently produces results with sharper details and fewer artifacts compared to existing methods. In contrast, supervised learning methods trained on external datasets yield poor quality results, highlighting the limited generalization performance of supervised approaches when dealing with complex real-world blurring.
This figure displays the visual comparison of the results from various methods on the dataset of Lai et al. [26]. The dataset is known for its challenging blurring effects and includes images categorized into five groups: manmade, natural, people, saturated, and text. The results showcase the effectiveness of the proposed method in addressing these blurring challenges compared to other methods, both supervised and self-supervised.
More on tables
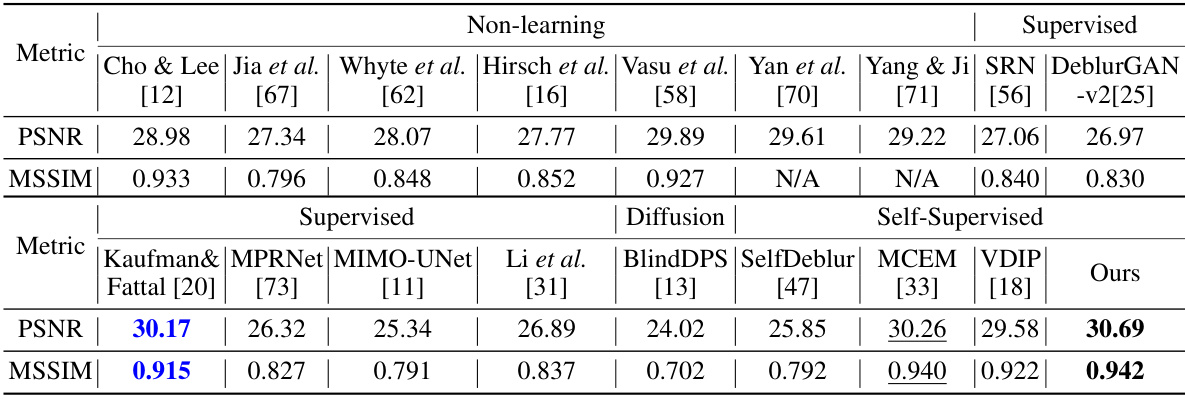
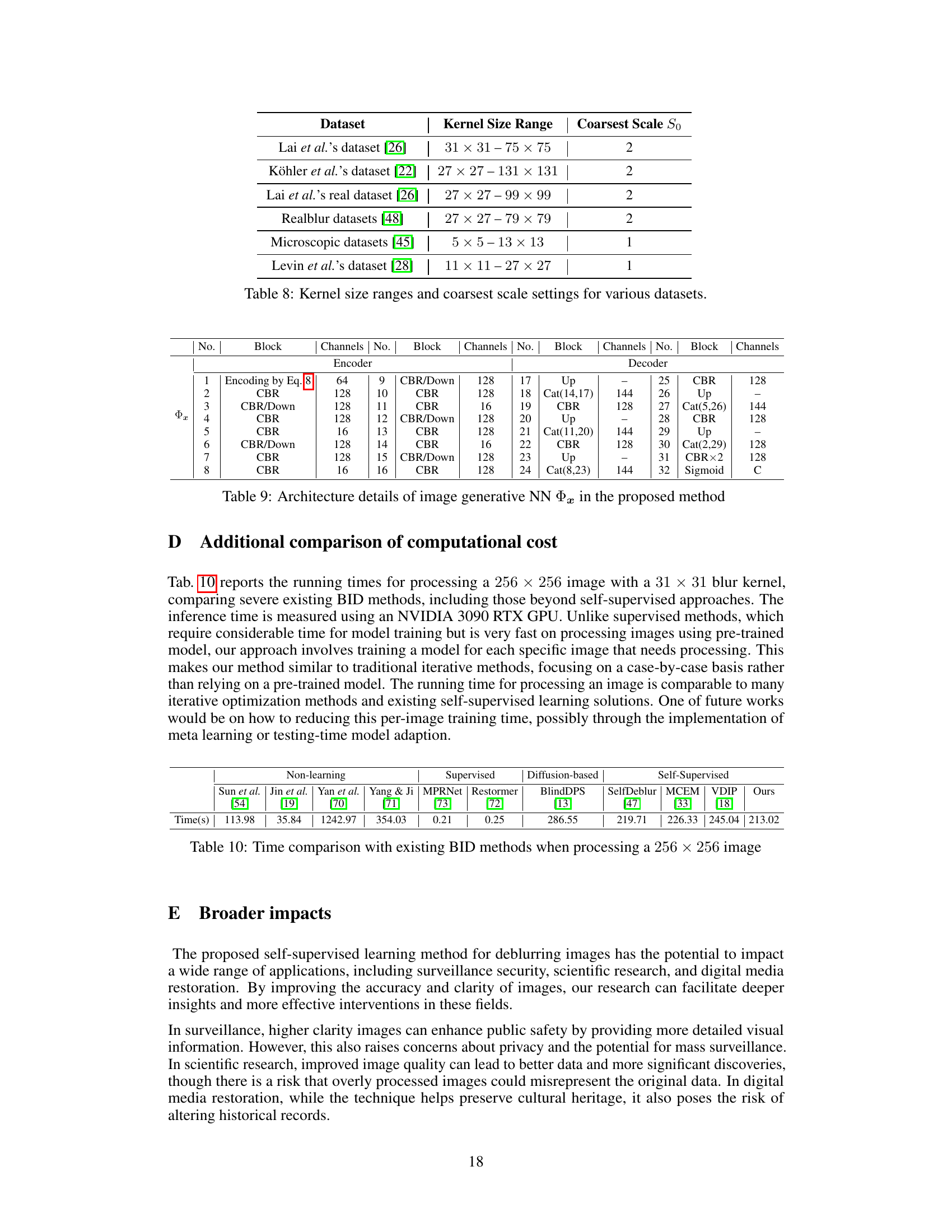
This table presents a quantitative comparison of various blind image deblurring (BID) methods on the Lai et al. dataset [26]. The methods are categorized into non-learning, supervised, and self-supervised approaches. The table reports the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) for each method across five image categories: Manmade, Natural, People, Saturated, and Text. Methods marked with a triangle (△) utilize a standard kernel estimation protocol (from [23]) for evaluation, while methods marked with an asterisk (*) were retrained on a different dataset (BSD-D [48]). This allows for a comprehensive comparison of different techniques’ performance across various blurring types and evaluation methodologies.
This table presents a quantitative comparison of various blind image deblurring (BID) methods on the Lai et al. dataset [26], categorized by non-learning, supervised, and self-supervised approaches. The results are evaluated using Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity index (SSIM). Some methods use a standard protocol where deblurring is performed using a pre-estimated kernel, denoted with a triangle symbol. Other methods are retrained on the Berkeley Segmentation Dataset (BSD-D), denoted with an asterisk.

This table presents the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) scores for various methods on a microscopic deconvolution task. The methods include supervised learning approaches (Restormer, INIKNet, BlindDPS), self-supervised methods (SelfDeblur, MCEM, VDIP), and the proposed method. The results are split into two categories based on the type of Point Spread Function (PSF) used: Gaussian and Poisson. The table aims to show the performance of the proposed method relative to state-of-the-art methods on this specific image deconvolution task for microscopic images.

This table presents a comparison of the performance of various blind image deblurring (BID) methods on the Lai et al. dataset. The methods are categorized as non-learning, supervised, and self-supervised. The results are shown in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), which are common metrics for evaluating image quality. Some methods are marked with △ or *, indicating that they use a specific kernel estimation method or are trained using a different dataset, respectively. This allows for a more comprehensive comparison of the different methods.
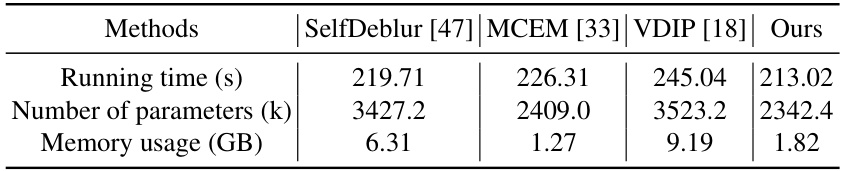
This table compares the computational efficiency of the proposed method against three other self-supervised BID methods. The comparison is based on running time, the number of parameters, and memory usage required to process a single 256x256 image with a 31x31 blur kernel using an NVIDIA 3090 RTX GPU. It demonstrates the balance achieved by the proposed method between computational cost and deblurring performance.

This table presents the ablation study results on the impact of different maximum scales (So) on the performance of the proposed method. It compares the results using the same framework with different So values (single-scale, two-scale, three-scale, and four-scale). The results are evaluated in terms of PSNR/SSIM on the Lai et al. dataset. The best and second-best performers are highlighted in bold and underlined, respectively.
This table presents a comparison of various blind image deblurring (BID) methods on the Lai et al. dataset [26], categorized by different image types (Manmade, Natural, People, Saturated, Text). The table shows the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) scores achieved by each method. Methods marked with a triangle (△) use the estimated kernel from [23] for deblurring, while those marked with an asterisk (*) were retrained on the BSD-D dataset [48]. This allows for a comprehensive comparison of different BID approaches, highlighting their performance across various blur types and image characteristics.
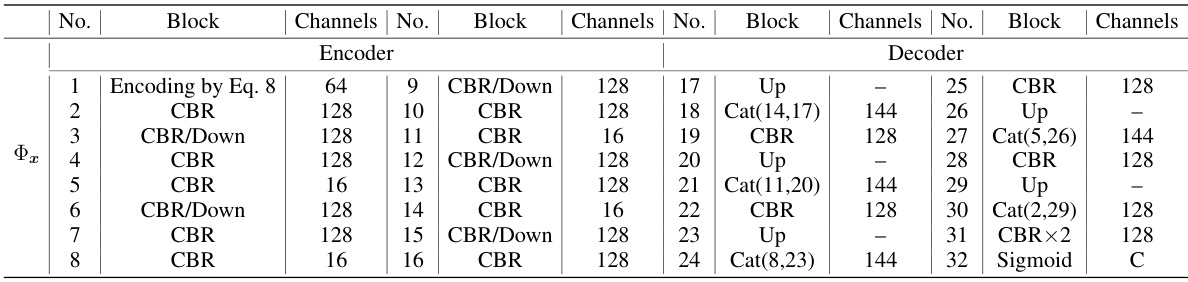
This table presents a comparison of various blind image deblurring (BID) methods on the Lai et al. dataset [26], which contains images categorized into five groups: manmade, natural, people, saturated, and text, each with 4 different kernels. The table reports the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) for each method and category. Methods marked with △ use a standard protocol for evaluating kernel estimation accuracy in BID where the image is deblurred using an estimated kernel from a separate method. Methods marked with * were retrained on the BSD-D dataset [48], allowing for comparison of performance with models trained on a different dataset.

This table compares the computational efficiency of the proposed method against three other self-supervised BID methods. The metrics used are running time (in seconds), the number of parameters (in thousands), and memory usage (in GB) required to process a single 256x256 image with a 31x31 blur kernel on an NVIDIA 3090 RTX GPU. The table highlights the balance achieved by the proposed method between computational cost and deblurring performance.
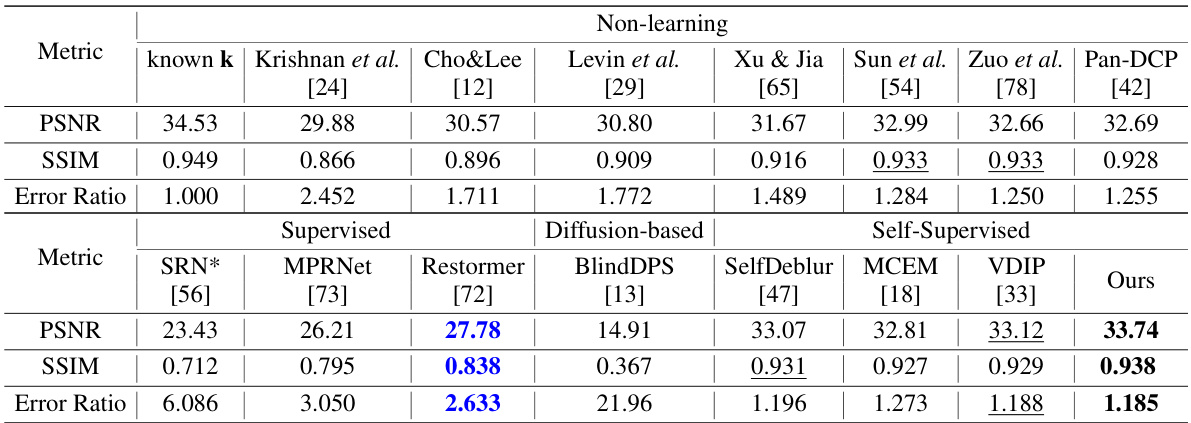
This table presents a comparison of the performance of various blind image deblurring (BID) methods on the Lai et al. dataset. The table shows the average Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) for each method across five categories of images (Manmade, Natural, People, Saturated, Text) and an average across all categories. Methods marked with a triangle (△) used a kernel estimated by a separate method ([23]) before deblurring, highlighting the accuracy of their kernel estimation. Methods with an asterisk (*) were retrained on a different dataset (BSD-D [48]), showing the impact of training data on the performance.
Full paper#