↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Monocular depth estimation (MDE) is a crucial task in computer vision, but existing methods struggle with issues like robustness, fine-grained details, and efficiency. Previous MDE models often rely on real-world datasets, which can be noisy and lack diversity. This creates challenges in training robust and accurate models, especially in complex or nuanced scenes. Real-world dataset annotation is also expensive and time-consuming, limiting the scale of existing datasets.
Depth Anything V2 tackles these limitations by using synthetic training images to generate high-quality depth labels. This addresses the noise and diversity issues in real-world datasets. The model is then improved further through a teacher-student training approach. A large teacher model is trained on synthetic images, and a smaller student model learns from this teacher via large-scale pseudo-labeled real images. The paper also introduces a new evaluation benchmark, DA-2K, with precise annotations and diverse scenes to improve the evaluation of MDE models. The proposed methods result in a superior MDE model compared to previous state-of-the-art models in both speed and accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in monocular depth estimation because it introduces Depth Anything V2, a significantly improved model achieving higher accuracy and efficiency than previous methods. Its focus on addressing data limitations and building a versatile evaluation benchmark, DA-2K, directly tackles major challenges in the field. This work paves the way for future research into more robust and precise depth estimation models, impacting applications in 3D reconstruction, robotics, and AI-generated content.
Visual Insights#

This figure demonstrates the improved performance of Depth Anything V2 over its predecessor (V1) and other state-of-the-art models. It showcases superior robustness in handling complex scenes, improved precision in capturing fine details, faster inference speed, and a reduction in model parameters while maintaining high accuracy. The comparison highlights the advancements in depth estimation achieved by Depth Anything V2.

This table summarizes the desirable properties of an effective monocular depth estimation model. It compares three models: Marigold, Depth Anything V1, and Depth Anything V2 (the authors’ model). For each model, it shows whether it exhibits each of the listed preferable properties. The properties include the ability to capture fine details, accurately estimate depth of transparent objects and reflections, handle complex scenes, and achieve both efficiency and transferability.
In-depth insights#
Synthetic Data Edge#
The concept of “Synthetic Data Edge” in research suggests leveraging synthetic data for improved efficiency and performance at the edge. This approach is particularly relevant for resource-constrained edge devices where training complex models on real-world data is impractical. Synthetic data generation offers control over data characteristics, allowing researchers to address issues like data scarcity, bias, and privacy. The challenge lies in bridging the reality gap, ensuring that models trained on synthetic data perform well in real-world scenarios. Techniques like domain adaptation and data augmentation aim to mitigate this. However, careful consideration of synthetic data limitations and proper evaluation on real-world benchmarks are crucial for establishing the validity and robustness of this method. Successfully bridging the reality gap is key to unlocking the true potential of the “Synthetic Data Edge” paradigm and realizing the full benefits of AI at the edge.
Unlabeled Data Boost#
The concept of ‘Unlabeled Data Boost’ in the context of a research paper likely revolves around leveraging unlabeled data to enhance model performance. This is a crucial area because acquiring labeled data is often expensive and time-consuming. The paper likely explores techniques such as self-training, semi-supervised learning, or consistency regularization to effectively utilize unlabeled data. Self-training, for instance, might involve training a model on labeled data, then using it to predict labels for unlabeled data, and subsequently retraining the model on the expanded dataset. Semi-supervised learning methods aim to learn from both labeled and unlabeled examples simultaneously. Consistency regularization techniques enforce consistency in the model’s predictions for different augmented versions of the same unlabeled data point. The paper’s findings likely demonstrate a significant improvement in model accuracy or robustness when integrating unlabeled data, showcasing a cost-effective approach for enhancing model performance.
Robust Depth Model#
A robust depth model is crucial for reliable performance in various applications, particularly in challenging conditions. Robustness typically encompasses the model’s ability to handle noisy or incomplete data, variations in lighting and viewpoint, and the presence of artifacts or occlusions. Achieving robustness often requires careful design choices, including the selection of appropriate training data and loss functions, and the incorporation of techniques that improve generalization. Data augmentation plays a critical role in training a robust model. Synthetic data, combined with real-world data, can help to mitigate overfitting and improve the model’s ability to generalize to unseen situations. The choice of model architecture is equally important; using architectures with inherent robustness can significantly improve results. Finally, thorough evaluation on diverse benchmarks is key for assessing the true robustness of a depth estimation model.
DA-2K Benchmark#
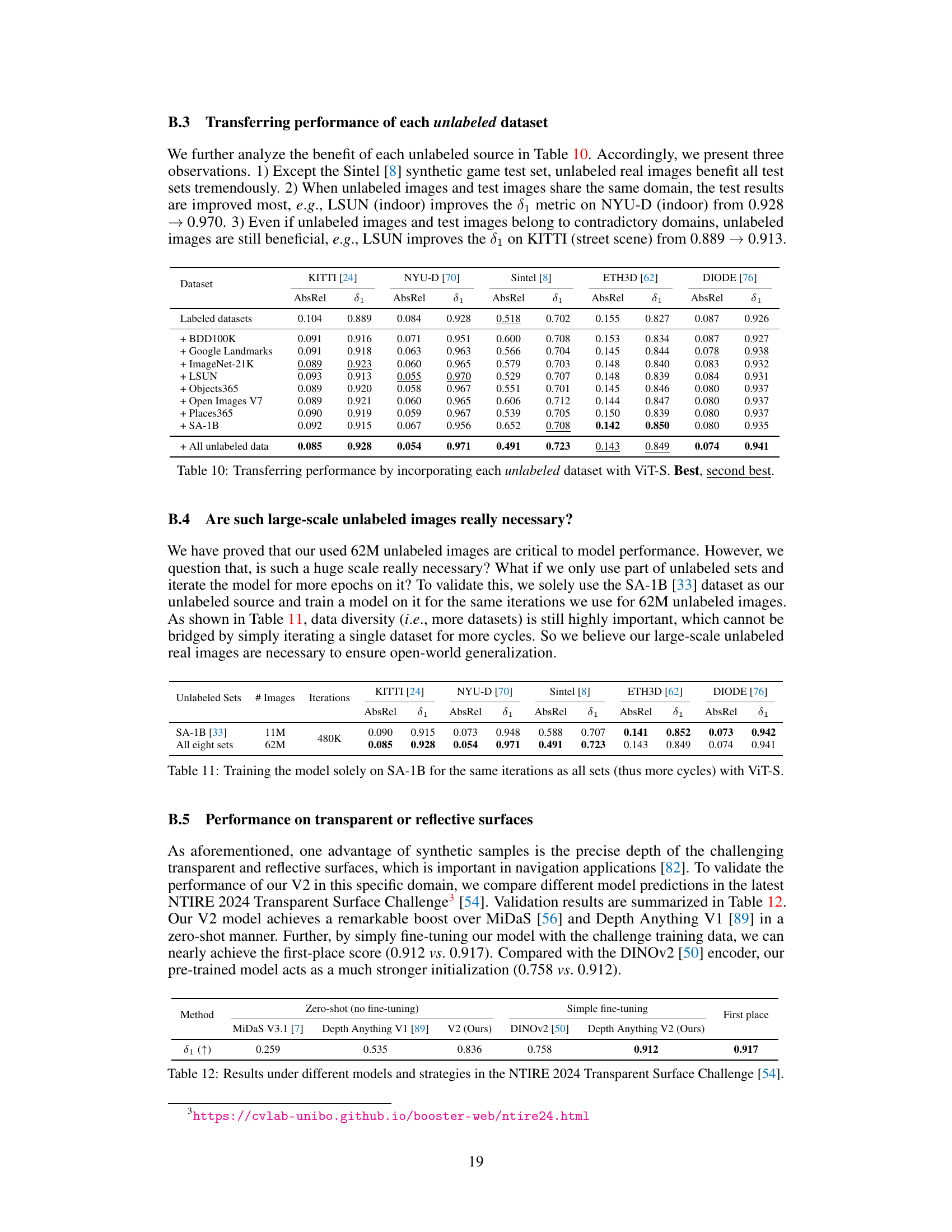
The DA-2K benchmark represents a notable contribution to the field of monocular depth estimation by addressing limitations in existing datasets. Its focus on precise relative depth annotation, encompassing diverse real-world scenarios, and high-resolution images provides a significant improvement. The meticulous annotation pipeline, involving human verification to resolve discrepancies among model predictions, ensures data quality. The inclusion of non-real images expands the dataset’s diversity and addresses the limitations of synthetic data. However, the sparse nature of the annotations might limit the benchmark’s scope for applications needing dense depth maps. Future work could explore dense depth labeling or incorporating more challenging scenarios to enhance this valuable resource and push the boundaries of MDE model evaluations.
Future MDE Research#
Future research in monocular depth estimation (MDE) should prioritize addressing the limitations of current datasets. Creating more diverse and comprehensive benchmarks with precise annotations is crucial, especially for challenging scenarios like transparent objects and reflective surfaces. Further exploration of synthetic data generation techniques that accurately model real-world complexities is needed to overcome the domain gap between synthetic and real images. Improving the efficiency of MDE models while maintaining accuracy remains a significant goal, especially for real-time applications. Exploring novel architectural designs that can effectively fuse multi-modal information (e.g., RGB, LiDAR) may lead to significant performance gains. Finally, research into more robust and generalizable MDE methods is crucial, capable of handling various scene complexities and environmental conditions with greater resilience.
More visual insights#
More on figures

This figure compares the performance of Depth Anything V2 with its predecessor, Depth Anything V1, and other state-of-the-art models on a benchmark dataset. It highlights improvements in both robustness (handling challenging scenes like misleading room layouts) and fine-grained detail (capturing details like a thin basketball net). V2 achieves higher accuracy with fewer parameters and faster inference speed.

This figure demonstrates different types of noise present in ground truth (GT) depth labels from various datasets (NYU-D, HRWSI, MegaDepth). Subfigure (a) shows noise in transparent objects, (b) shows noise due to repetitive patterns in stereo matching, and (c) shows noise related to dynamic objects in Structure from Motion (SfM) datasets. (d) shows the resulting errors in the model predictions due to these noisy labels. The black regions represent areas that were ignored during training due to significant uncertainty.

This figure compares the depth labels and model predictions from real images and synthetic images. Subfigure (a) shows the coarse depth labels obtained from real-world datasets (HRWSI [83], DIML [14]). Subfigure (b) displays the highly precise depth labels from synthetic datasets (Hypersim [58], vKITTI [9]). Subfigure (c) contrasts model predictions trained on these different datasets, highlighting the significantly improved precision of models trained on synthetic data.

This figure shows a qualitative comparison of the depth prediction results of several vision encoders (BEIT-Large, SAM-Large, SynCLR-Large, DINOv2-Giant, DINOv2-Small, DINOv2-Base, DINOv2-Large) when performing synthetic-to-real transfer in monocular depth estimation. The input image contains cats, and each subplot displays the depth map generated by each encoder. The results show that only the DINOv2-Giant model produces reasonably accurate depth prediction, highlighting the challenges and potential solutions in transferring knowledge learned from synthetic data to real-world scenes. Quantitative details are provided in Section B.6 of the paper.

This figure shows two examples where a model trained only on synthetic data fails to generalize well to real-world images. The first example shows that the model incorrectly predicts the distance to the sky, making it appear much closer than it actually is. The second example shows an inconsistency in the depth prediction of a person; the head is predicted to be at a different depth than the rest of the body. These failures highlight the limitations of training solely on synthetic data and demonstrate the need for incorporating real-world data to improve model generalization.

This figure illustrates the three-stage training process of Depth Anything V2. First, a powerful teacher model is trained using only high-quality synthetic images. Then, this teacher model is used to generate pseudo-labels for a large dataset of unlabeled real images, mitigating the distribution shift and limited diversity inherent in purely synthetic datasets. Finally, student models are trained using these high-quality pseudo-labeled real images, resulting in a model with improved generalization and robustness.

This figure demonstrates the various types of noise present in ground truth depth labels from different datasets (NYU-D, HRWSI, MegaDepth). It shows how these inaccuracies, stemming from limitations in data collection methods like depth sensors, stereo matching, and structure from motion (SfM), affect the predictions of models trained on these datasets. The examples illustrate label noise in transparent objects, repetitive patterns, and dynamic objects, highlighting the challenges of using real-world depth data for training.
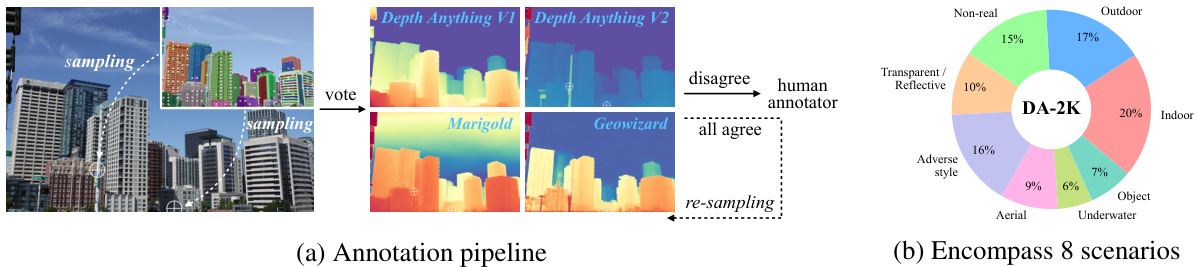
This figure illustrates the creation of the DA-2K benchmark dataset for evaluating monocular depth estimation models. Panel (a) details the annotation pipeline: four existing depth estimation models are used to predict relative depth between two points in an image. If these models disagree, human annotators provide the ground truth. Panel (b) shows a pie chart illustrating the diverse range of scenarios encompassed in the dataset, including indoor, outdoor, aerial, underwater, and images with transparent/reflective objects.
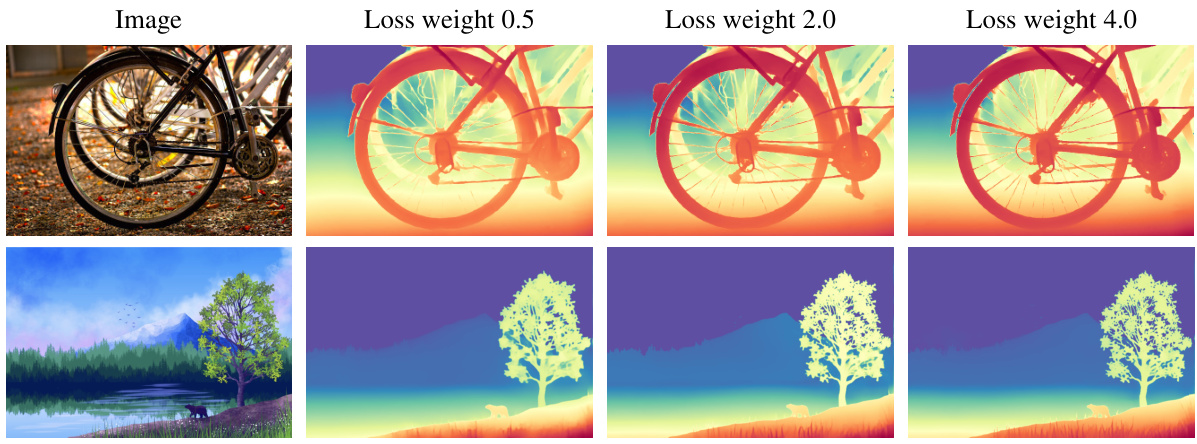
This figure shows the effect of the gradient matching loss (Lgm) on the sharpness of depth predictions. Three images are shown with depth predictions, each using different weights for the Lgm loss (0.5, 2.0, and 4.0). As the weight increases, the depth predictions become sharper, showing more fine-grained details. This demonstrates that the Lgm loss is beneficial for improving the sharpness of depth maps, especially when training with high-quality synthetic data.

This figure shows the results of Depth Anything V2 model with different resolutions (1x, 2x, 4x). It demonstrates that increasing the resolution at test time improves the prediction sharpness, which is a property of the model.

This figure shows a comparison of depth prediction results using purely synthetic images versus a combination of synthetic and real images (HRWSI). The results demonstrate that adding real images, even a small percentage, to the training dataset significantly degrades the fine details in the depth map predictions. This highlights the negative impact of noisy real-world depth labels on the model’s ability to learn precise depth information from synthetic data.

This figure shows a qualitative comparison of the depth estimations produced by Depth Anything V1 and Depth Anything V2 on various open-world images. It visually demonstrates the improvements in Depth Anything V2 in terms of accuracy and detail, particularly in challenging scenes.

This figure compares the depth estimation results of Marigold and Depth Anything V2 on several real-world images. It visually demonstrates the differences in the quality and robustness of depth maps generated by each model, highlighting Depth Anything V2’s improved performance, especially in handling complex scenes and fine details.

This figure compares the performance of ZoeDepth, a state-of-the-art metric depth estimation model, with the authors’ fine-tuned metric depth model. The comparison is shown through qualitative results on several real-world images. Each row displays an input image alongside the depth maps generated by ZoeDepth and the authors’ model. The visual difference helps illustrate the strengths and weaknesses of each approach in terms of accuracy and detail.

This figure compares the performance of a DINOv2-small depth estimation model trained using two different approaches: one trained solely on labeled synthetic images, and another trained solely on pseudo-labeled real images. The comparison visually demonstrates that using pseudo-labeled real images significantly enhances the model’s robustness in generating accurate depth maps, particularly for complex or challenging scenes.

This figure visualizes the pseudo depth labels generated by the model on various unlabeled real images. The images are sampled from eight different large-scale datasets representing diverse scenes and object categories. Each pair shows an unlabeled real image alongside its corresponding pseudo depth map, highlighting the model’s ability to accurately estimate depth in various complex scenarios.

This figure presents a qualitative comparison of depth estimation results between Depth Anything V1 and the proposed Depth Anything V2 model. The comparison is performed on widely used benchmark datasets such as KITTI, NYU, and DIODE. For each image, the ground truth image is shown alongside the depth maps generated by both models. The comparison aims to highlight the improvements in depth estimation accuracy and detail achieved by Depth Anything V2 compared to its predecessor.

This figure shows examples from the DA-2K benchmark dataset, highlighting the diversity of scenes and the precise sparse annotations used for relative depth estimation. Each image pair shows two points, one labeled as closer (green) and one as farther (red). The scenes include indoor and outdoor settings, non-real images (like illustrations), transparent or reflective surfaces, adverse weather/lighting conditions, aerial views, underwater scenes, and diverse object types.
More on tables
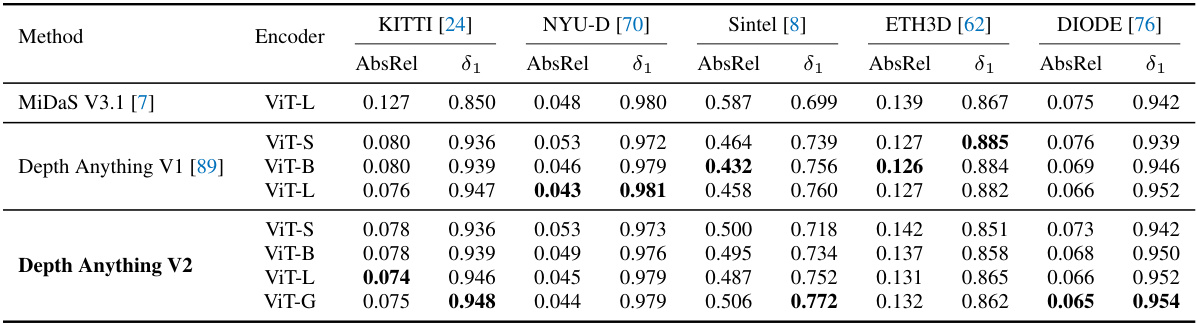
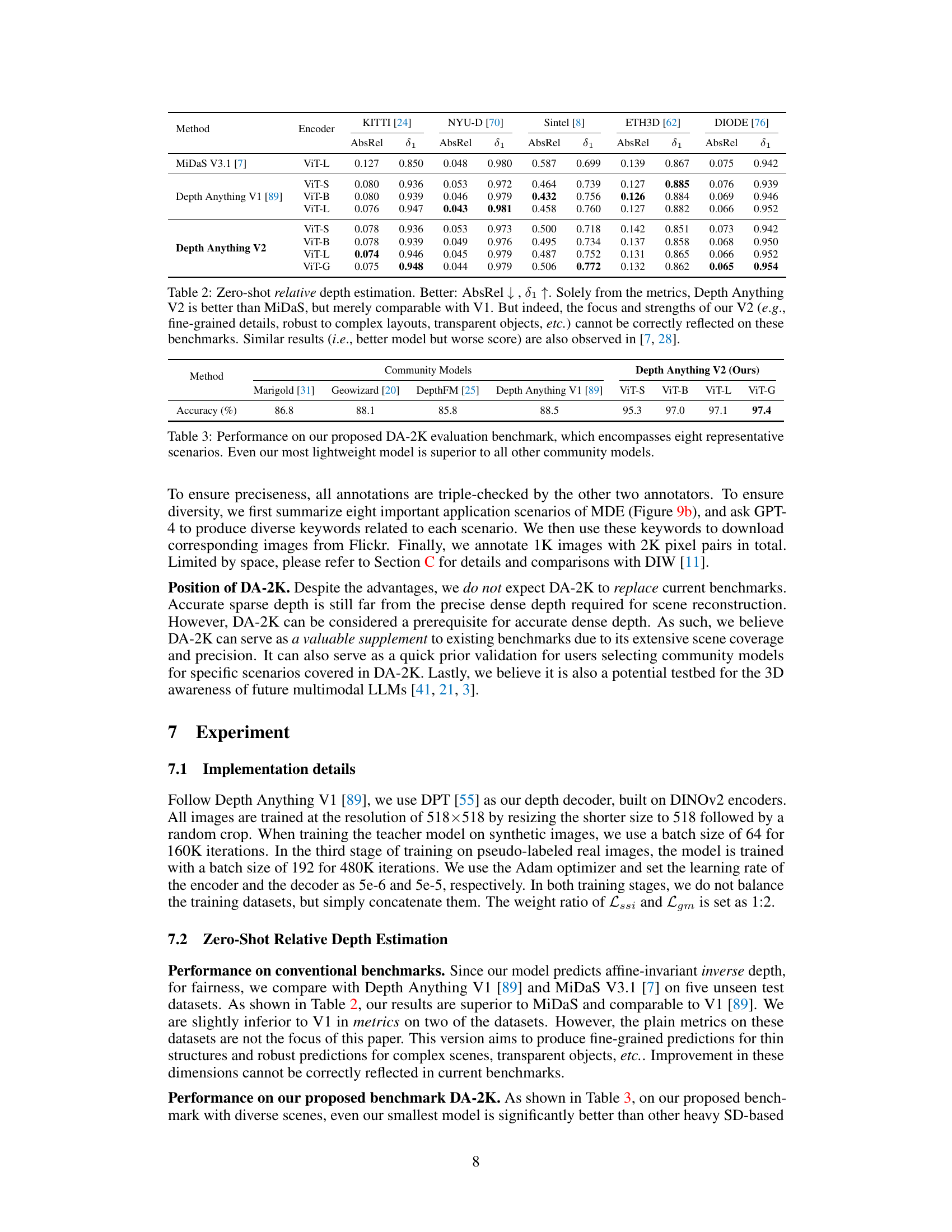
This table presents a comparison of zero-shot relative depth estimation performance across different methods on five unseen test datasets (KITTI, NYU-D, Sintel, ETH3D, and DIODE). It highlights the limitations of using standard metrics to fully capture the improvements achieved by Depth Anything V2, which excels in fine-grained details and robustness to complex scenes, aspects not fully reflected in the presented metrics. Depth Anything V2 shows comparable or slightly better results than Depth Anything V1 and MiDaS V3.1 based on the given metrics.

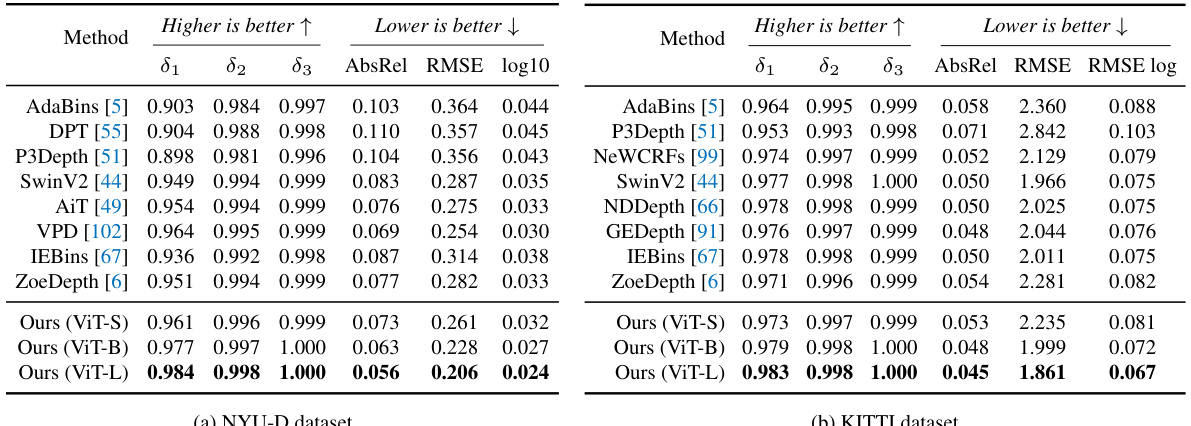
This table presents the accuracy results of different depth estimation models on the DA-2K benchmark. The DA-2K benchmark is a newly proposed, more comprehensive and accurate evaluation benchmark that includes diverse scenarios not well-represented in previous benchmarks. The table shows that Depth Anything V2 significantly outperforms existing state-of-the-art models, even with its smallest model.
This table presents the results of zero-shot relative depth estimation on several benchmark datasets (KITTI, NYU-D, Sintel, ETH3D, DIODE). It compares the performance of Depth Anything V1, Depth Anything V2, and MiDaS V3.1. While the quantitative metrics suggest that Depth Anything V2 is slightly better or comparable to existing methods, the authors emphasize that the table does not fully capture the qualitative improvements of Depth Anything V2, such as improved robustness to complex scenes and finer details. They note that this limitation is common to several benchmark datasets.
This table presents the results of zero-shot relative depth estimation on several benchmark datasets (KITTI, NYU-D, Sintel, ETH3D, DIODE). It compares the performance of Depth Anything V2 with MiDaS V3.1 and Depth Anything V1. While numerical results show Depth Anything V2 is slightly better or comparable to the others, the authors highlight that these metrics do not fully capture the improvements in fine-grained details and robustness to complex scenes which are key features of Depth Anything V2.

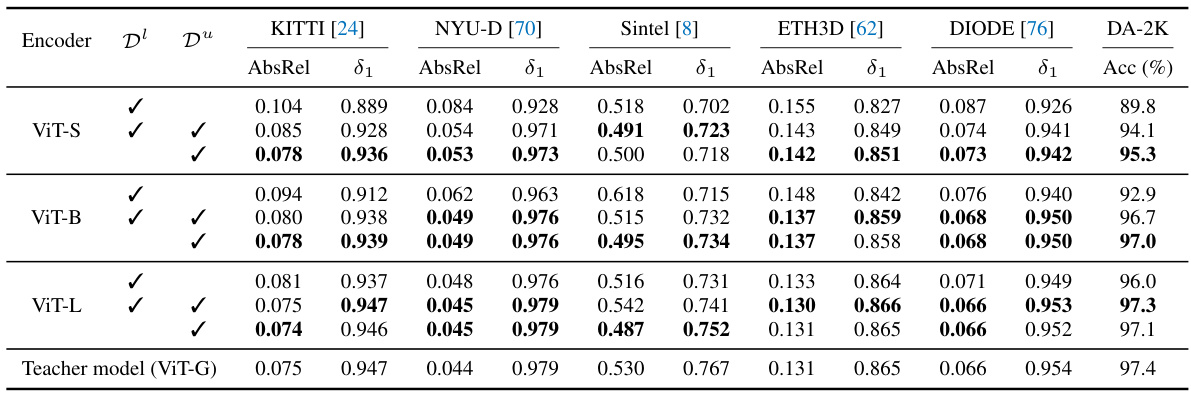
This table compares the performance of depth estimation models trained using manually labeled data from the DIML dataset versus models trained using pseudo labels generated by the authors’ method. The results demonstrate a significant improvement in performance when using pseudo labels, highlighting the effectiveness of the authors’ approach in addressing the challenges of noisy manual labels in real-world datasets.
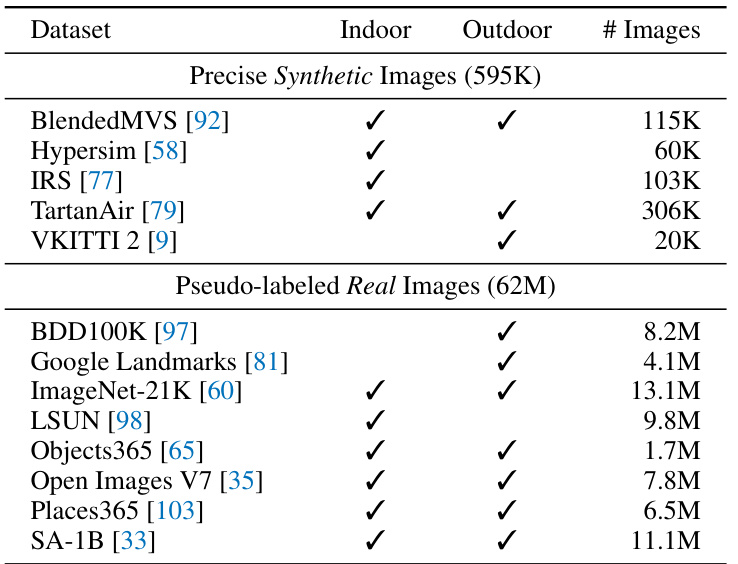
This table lists the datasets used for training Depth Anything V2. It’s divided into two parts: Precise Synthetic Images and Pseudo-labeled Real Images. The Precise Synthetic Images section shows five datasets used to create highly accurate depth labels, with the number of images in each dataset specified. The Pseudo-labeled Real Images section shows eight large-scale datasets that were used to enhance the model’s generalization ability, with pseudo labels generated by the model. The table indicates whether each dataset contains indoor and/or outdoor scenes.

This table presents the results of a zero-shot relative depth estimation experiment. It compares Depth Anything V2 against MiDaS V3.1 on several benchmark datasets (KITTI, NYU-D, Sintel, ETH3D, DIODE). While quantitative metrics suggest Depth Anything V2 performs similarly to or slightly better than V1 and MiDaS, the authors highlight that these metrics don’t fully capture the improvements in fine-grained details and robustness to complex scenes achieved by V2.
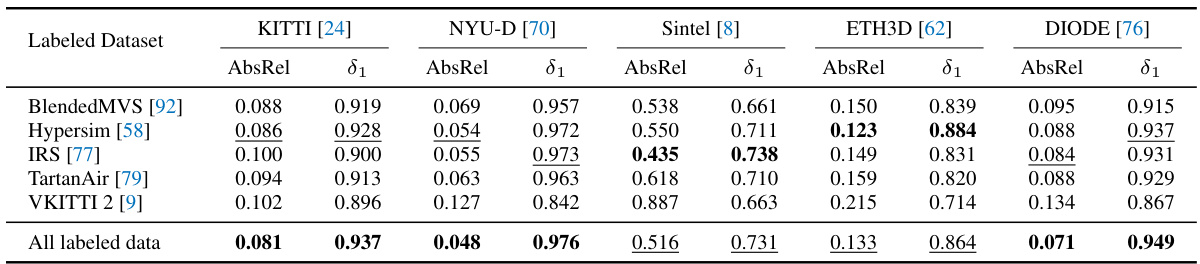
This table presents zero-shot relative depth estimation results on several benchmarks (KITTI, NYU-D, Sintel, ETH3D, DIODE). It compares Depth Anything V2 with MiDaS V3.1 and Depth Anything V1. While the metrics show Depth Anything V2 as slightly better than MiDaS and comparable to Depth Anything V1, the authors highlight that these metrics don’t fully capture the improvements in fine-grained details and robustness to complex scenes that Depth Anything V2 offers. They argue that the existing benchmarks are inadequate for fully evaluating the model’s strengths.
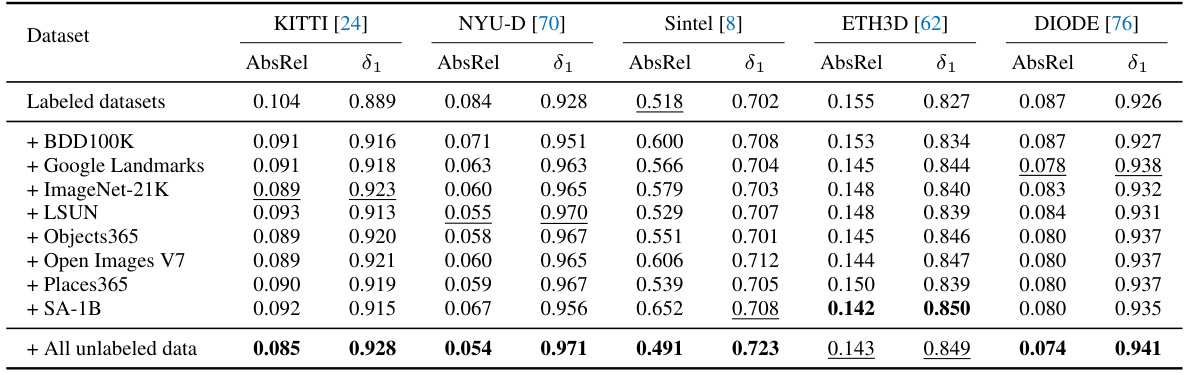
This table presents the zero-shot relative depth estimation results on five unseen test datasets (KITTI, NYU-D, Sintel, ETH3D, DIODE) using different encoders (ViT-S, ViT-B, ViT-L, ViT-G). The results are compared against MiDaS V3.1 and Depth Anything V1. It highlights the limitations of using standard metrics to fully capture the improvements achieved in Depth Anything V2, particularly regarding fine-grained details and robustness to complex scenes.

This table compares the performance of Depth Anything V2 with other zero-shot relative depth estimation models on standard benchmarks such as KITTI, NYU-D, Sintel, ETH3D, and DIODE. The metrics used are Absolute Relative Error (AbsRel) and δ1. While Depth Anything V2 shows competitive results according to these metrics, the authors emphasize that these metrics don’t fully capture the model’s advantages, especially its improved robustness and detail in complex scenes, compared to other models.

This table shows the performance comparison of different models on the NTIRE 2024 Transparent Surface Challenge. It compares the performance of MiDaS V3.1, Depth Anything V1, Depth Anything V2 (both zero-shot and with simple fine-tuning) and DINOv2 on the δ1 metric, showing Depth Anything V2 achieves the highest score with simple fine-tuning.
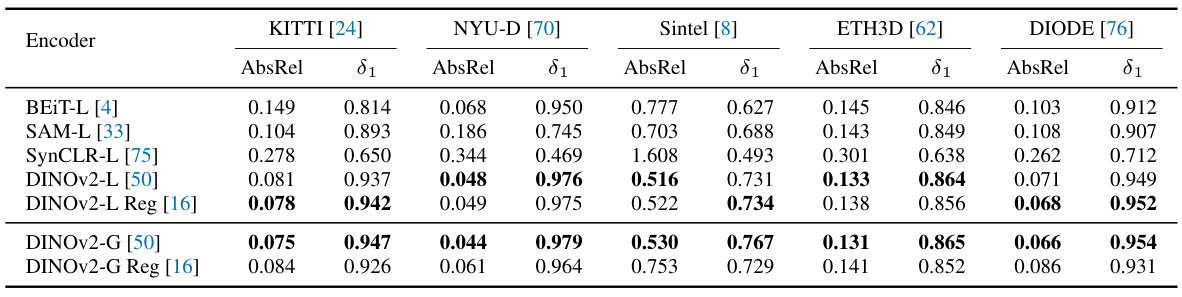
This table presents the zero-shot relative depth estimation results on five unseen test datasets (KITTI, NYU-D, Sintel, ETH3D, and DIODE) for three different models: MiDaS V3.1, Depth Anything V1, and Depth Anything V2. The results are evaluated using two metrics: AbsRel (absolute relative error) and δ1 (percentage of pixels with relative error less than 1.25). Depth Anything V2 shows improved performance over MiDaS but only comparable performance to Depth Anything V1 based solely on these metrics. The authors highlight that the table does not fully capture the improvements in fine-grained details and robustness to complex scenes achieved by Depth Anything V2.
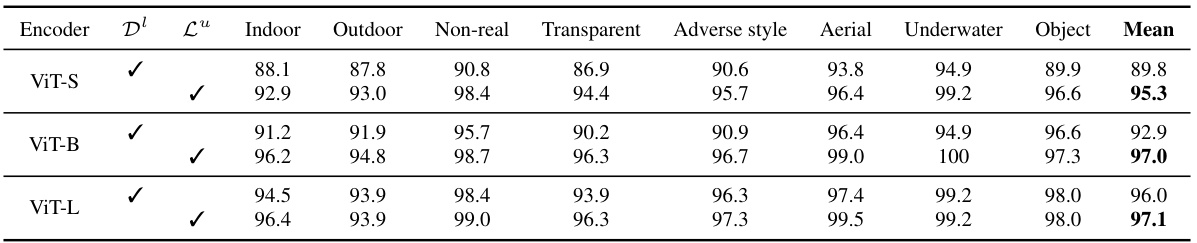
This table presents the per-scenario accuracy of the Depth Anything V2 model on the DA-2K benchmark. It shows the model’s performance across different scenarios (Indoor, Outdoor, Non-real, Transparent, Adverse style, Aerial, Underwater, Object) and two encoders (with and without pseudo-labeled real images) for different model sizes (ViT-S, ViT-B, ViT-L). The mean accuracy across all scenarios is also provided for each model configuration. This allows for a detailed analysis of the model’s strengths and weaknesses in various contexts.

This table presents a comparison of zero-shot relative depth estimation performance across different models on five unseen test datasets (KITTI, NYU-D, Sintel, ETH3D, DIODE). It compares Depth Anything V1 and V2 against MiDaS V3.1, highlighting the limitations of using standard metrics to capture the improvements in fine-grained details and robustness offered by Depth Anything V2, especially for complex layouts and transparent objects.
Full paper#