TL;DR#
Vision transformers, despite their powerful capabilities, lack deep understanding of their internal error mechanisms. Existing interpretation methods focus on input token or module importance and feature formation, neglecting error analysis. This paper introduces the “Information Integration Hypothesis”, proposing that errors arise from incorrect integration of information among and within tokens, similar to biological visual systems.
To address this, the authors propose “Transformer Doctor”, a framework that diagnoses errors using the hypothesis and employs heuristic dynamic and rule-based static integration constraint methods to rectify them. Extensive experiments show Transformer Doctor’s effectiveness in enhancing model performance across various datasets and architectures. The work highlights the importance of understanding internal error mechanisms in transformers and provides interpretable solutions for improving model reliability and performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with vision transformers. It offers interpretable methods for diagnosing and rectifying internal errors, improving model performance and enhancing transparency. This opens avenues for developing more robust and reliable vision transformer models, especially in sensitive domains. It also bridges machine vision and biological vision research, fostering cross-disciplinary advancements.
Visual Insights#

🔼 This figure illustrates the methodology of Transformer Doctor, which consists of two main stages: diagnosing and treating. The diagnosing stage involves analyzing the dynamic integration of information between tokens in the Multi-Head Self-Attention (MHSA) module and the static integration of information within tokens in the Feed-Forward Network (FFN) module. This analysis helps identify conjunction errors (errors in the integration of information). The treating stage involves applying heuristic dynamic integration constraint methods and rule-based static integration constraint methods to correct these errors, ultimately improving model performance. The figure visually represents the information flow and processing steps in each module of the Transformer, highlighting the key components and steps involved in the proposed framework.
read the caption
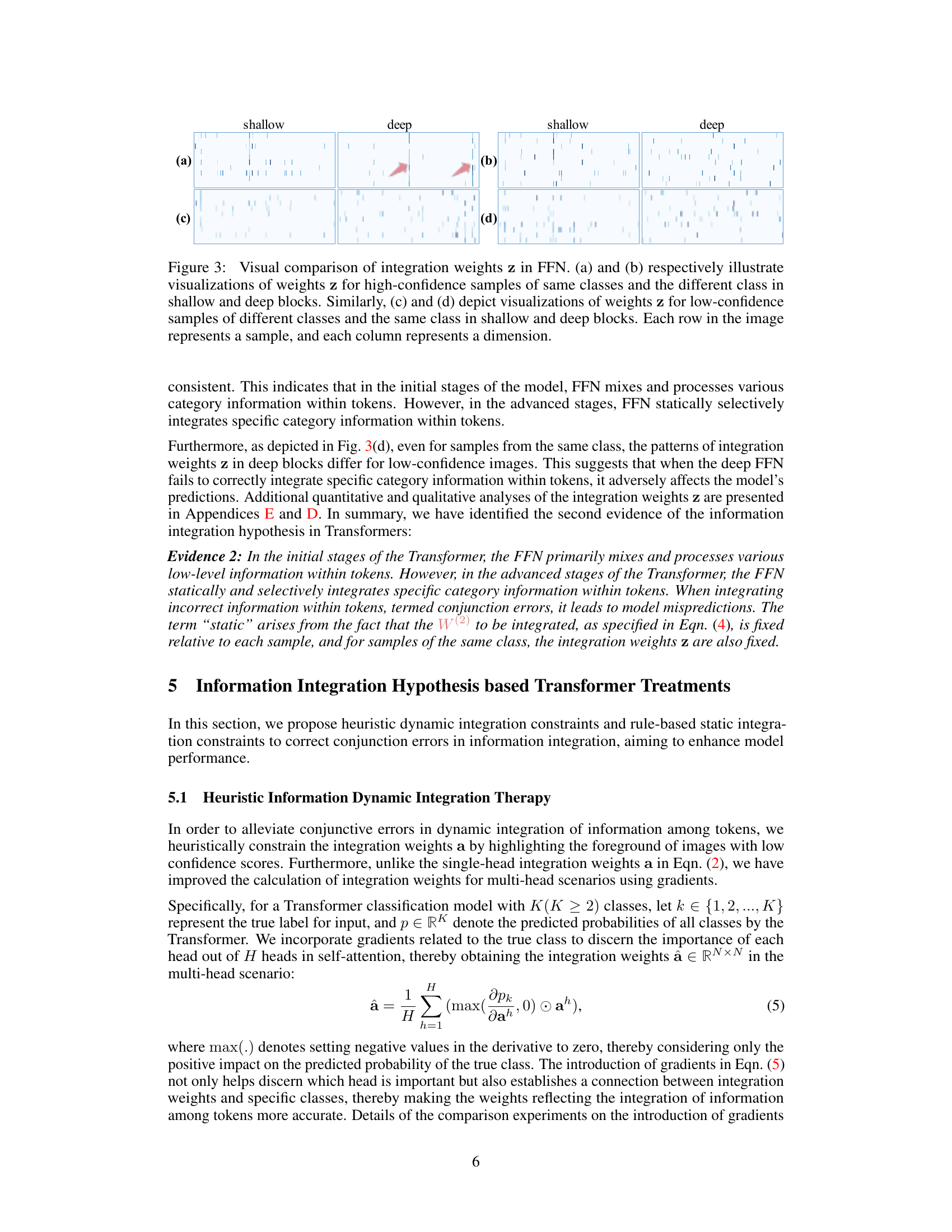
Figure 1: The methodology framework of Transformer Doctor. It begins by analyzing the dynamic integration of inter-token information in MHSA and the static integration of intra-token information in FFN, Subsequently, conjunction errors within them are diagnosed, and finally treated to enhance model performance.
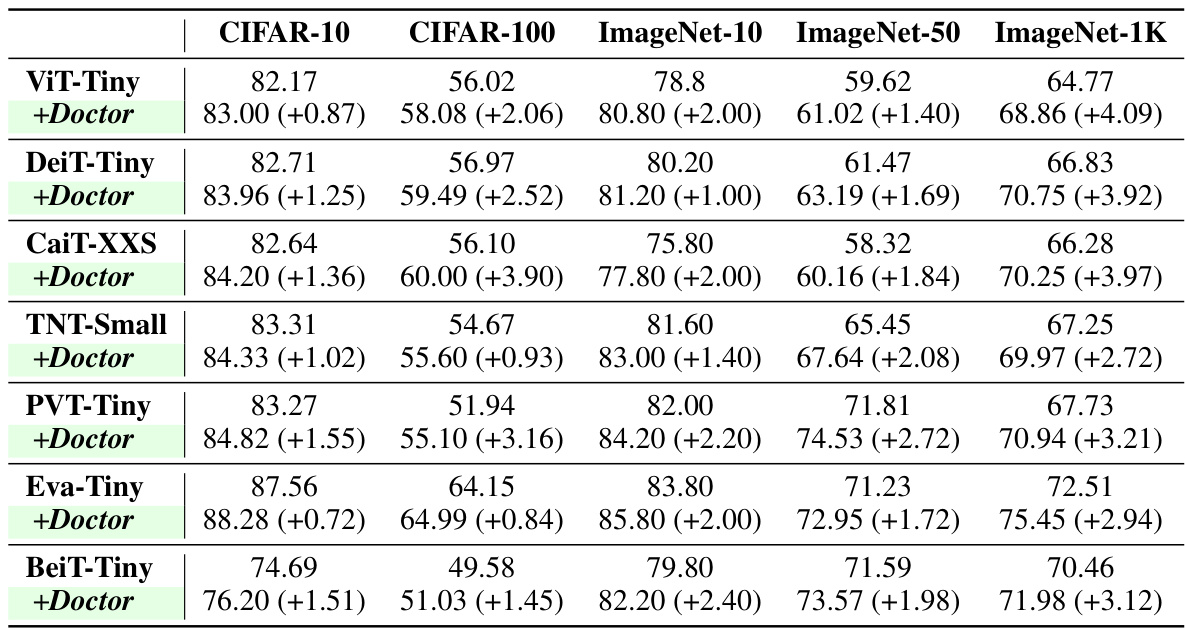
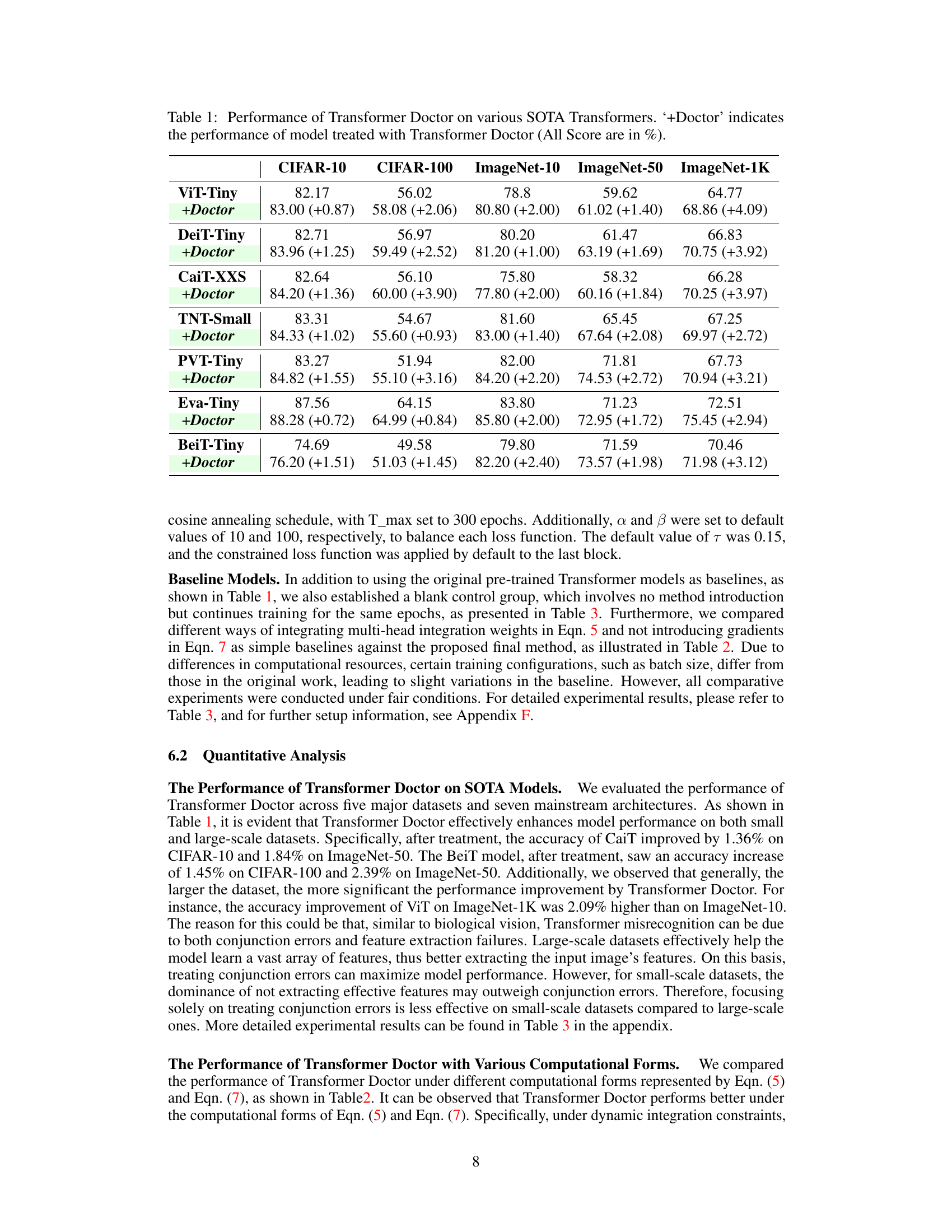
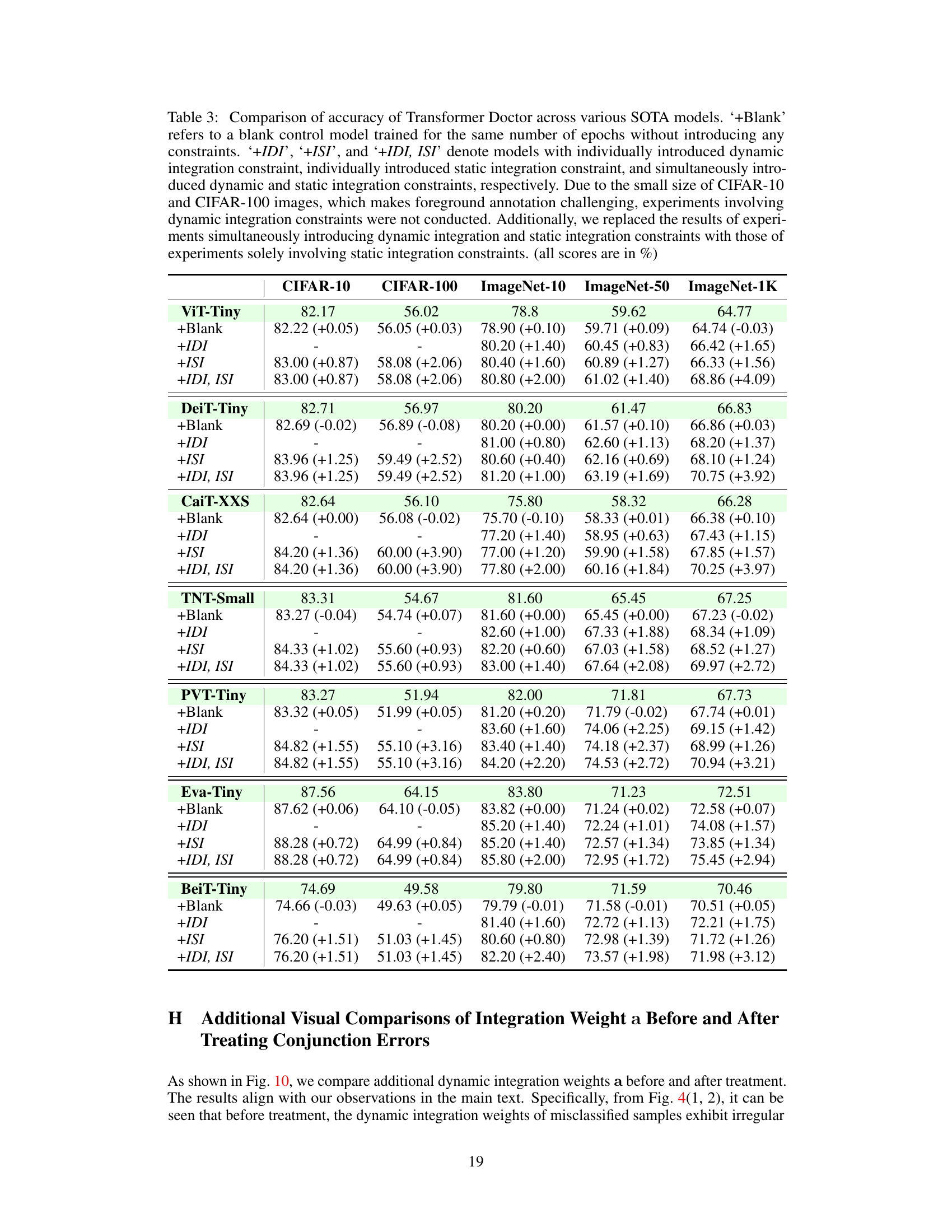
🔼 This table presents the performance comparison of several state-of-the-art (SOTA) Transformer models before and after applying the proposed Transformer Doctor method. The models are evaluated on five different datasets (CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-50, and ImageNet-1K) and the improvement in accuracy after applying Transformer Doctor is shown in parentheses. The results demonstrate that the Transformer Doctor method consistently improves the performance of different Transformer architectures across various datasets.
read the caption
Table 1: Performance of Transformer Doctor on various SOTA Transformers. '+Doctor' indicates the performance of model treated with Transformer Doctor (All Score are in %)
In-depth insights#
Vision Transformer Errors#
Vision Transformers, despite their impressive performance, are susceptible to specific error modes stemming from their unique architecture. Information integration, both dynamically across tokens and statically within tokens, is a crucial aspect where errors can arise. Conjunctive errors, a type of error identified in biological vision, also appear, caused by incorrect integration of features. These errors don’t solely result from flawed feature extraction but rather from problems during the synthesis and combining of information. This highlights the need for new diagnostic and treatment approaches for vision transformers that move beyond simply assessing feature importance. A framework that directly addresses errors in information integration, as proposed by the Transformer Doctor, provides a path towards creating more robust and interpretable models.
Information Integration#
The concept of ‘Information Integration’ in the context of vision transformers is crucial for understanding their performance and limitations. The authors propose that transformers, similar to biological visual systems, integrate information dynamically (across tokens) and statically (within tokens). This hypothesis suggests that errors arise not only from feature extraction but also from the incorrect integration of these features. Dynamic integration in multi-head self-attention (MHSA) involves a weighted sum of tokens, while static integration in feed-forward networks (FFN) involves a weighted sum of feature dimensions within each token. The authors’ framework, “Transformer Doctor,” leverages this hypothesis to diagnose and treat these errors, improving overall model accuracy by rectifying faulty information integration. This approach highlights a novel perspective by bridging machine vision and biological vision research.
Transformer Doctor#
The concept of “Transformer Doctor” presents a novel and insightful approach to addressing the limitations of vision Transformers. The name itself evokes a sense of diagnosis and treatment, implying a methodical process of identifying and rectifying internal errors within these complex models. This is a significant departure from traditional approaches focusing primarily on input or feature analysis. Instead, “Transformer Doctor” suggests a deeper investigation into the model’s internal mechanisms, focusing on information integration and the presence of conjunction errors. By proposing methods to rectify these errors through constraint methods, the framework offers a potential path to improve model accuracy and reliability. The approach emphasizes interpretability, which can address concerns about the “black box” nature of Transformers and pave the way for more trustworthy applications, especially in sensitive domains.
Dynamic Integration#
The concept of ‘Dynamic Integration’ in the context of vision transformers is a significant contribution to the field. It highlights the time-evolving nature of information processing within the transformer architecture, emphasizing that information isn’t simply statically combined. Instead, the integration process dynamically adapts, integrating information among tokens in ways that change depending on the depth of the model and the specific characteristics of the input. This contrasts with previous interpretations that focused on static feature maps and relationships. This dynamic integration is a crucial aspect of how the model learns complex visual relationships from data. The paper’s exploration of this concept offers a new perspective on how to improve these models and diagnose potential errors which can cause a model to misclassify objects. The use of visualizations and mathematical formulations support the ideas proposed.
Future Work#
The ‘Future Work’ section of this research paper presents exciting avenues for expanding upon the current Transformer Doctor framework. Improving the model’s ability to handle low-confidence samples more robustly is crucial, as is extending the framework to encompass more diverse vision tasks beyond those already examined. Furthermore, investigating the applicability of the Information Integration Hypothesis in NLP and multimodal domains could significantly broaden the impact and relevance of this work. Developing a more automated and intelligent Transformer Doctor would streamline the diagnostic and treatment process, making it more efficient and accessible to a wider range of researchers. Finally, a deeper exploration of error mechanisms beyond conjunction errors could provide even more comprehensive insights into the inner workings of Transformers.
More visual insights#
More on figures

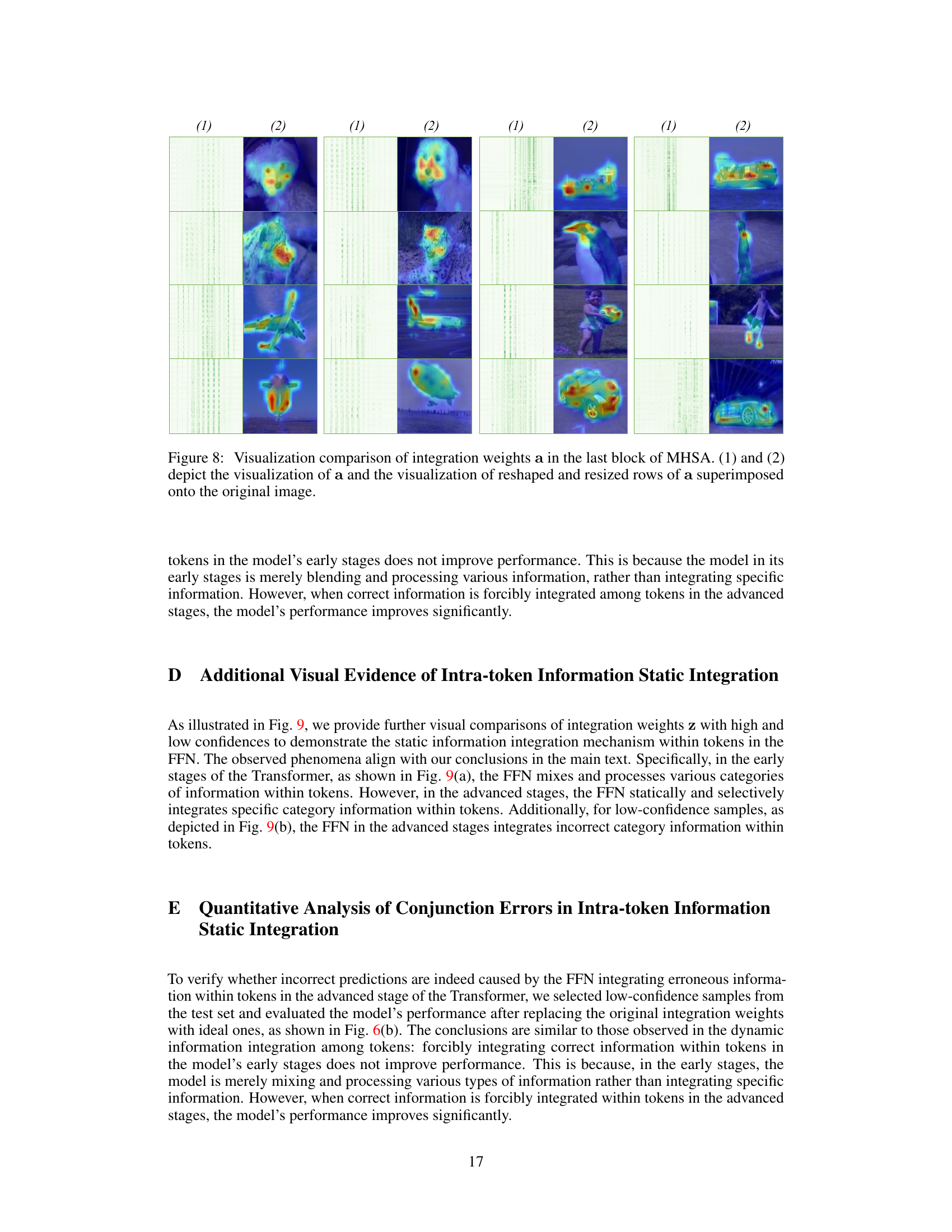
🔼 This figure compares the integration weights (a) in the multi-head self-attention (MHSA) module of a vision transformer at different depths for both high-confidence and low-confidence images. The visualizations show how the weights change as the model processes the image, highlighting the dynamic integration of information among tokens. High-confidence images show a diagonal pattern in shallower blocks, transitioning to a vertical pattern in deeper blocks, indicating a shift from local to global feature integration. Low-confidence images exhibit less consistent patterns, suggesting issues in the integration process. The overlay shows how these integration weights map onto the original images.
read the caption
Figure 2: Visual comparison of integration weights a in MHSA. (a) and (b) respectively present visualizations of weights a at different depths of blocks for high-confidence images and the overlay of reshaped and resized rows of a onto the original image. Similarly, (c) and (d) depict visualizations of weights a for low-confidence images and their overlay onto the original image.

🔼 This figure compares the integration weights (a) in the multi-head self-attention (MHSA) module of a vision transformer model at different depths (shallow vs. deep blocks) for both high and low-confidence image classifications. It visually represents these weights as heatmaps, overlaid onto the original image to show the spatial distribution of attention. The comparison highlights differences in attention patterns between high-confidence (correctly classified) and low-confidence (incorrectly classified) predictions. In high-confidence samples, the weights show a clear focus on relevant image features, whereas low-confidence images exhibit less coherent attention patterns.
read the caption
Figure 2: Visual comparison of integration weights a in MHSA. (a) and (b) respectively present visualizations of weights a at different depths of blocks for high-confidence images and the overlay of reshaped and resized rows of a onto the original image. Similarly, (c) and (d) depict visualizations of weights a for low-confidence images and their overlay onto the original image.

🔼 This figure visually compares the attention weights (integration weights ‘a’) within the multi-head self-attention (MHSA) module of a vision transformer at different depths (layers) for both high and low-confidence image classifications. The left column shows the matrices of integration weights, revealing patterns that change as the network deepens. The right column overlays a reshaped version of these weights onto the original input image as heatmaps, making it easier to understand which parts of the image were focused on during attention.
read the caption
Figure 2: Visual comparison of integration weights a in MHSA. (a) and (b) respectively present visualizations of weights a at different depths of blocks for high-confidence images and the overlay of reshaped and resized rows of a onto the original image. Similarly, (c) and (d) depict visualizations of weights a for low-confidence images and their overlay onto the original image.

🔼 This figure illustrates the methodology of Transformer Doctor. It’s a flowchart showing the two main diagnostic steps (analyzing dynamic and static information integration) and treatment steps (applying dynamic and static integration constraints) to correct conjunction errors in Vision Transformers, ultimately improving model performance.
read the caption
Figure 1: The methodology framework of Transformer Doctor. It begins by analyzing the dynamic integration of inter-token information in MHSA and the static integration of intra-token information in FFN, Subsequently, conjunction errors within them are diagnosed, and finally treated to enhance model performance.

🔼 This figure visualizes the integration weights (a) within the Multi-Head Self-Attention (MHSA) module of a Transformer model at various depths. Panels (a) and (b) show the weights for high-confidence images, illustrating a transition from diagonal patterns in shallower layers to vertical patterns in deeper layers. The overlay on the original images helps to understand the spatial focus of these weights. Panels (c) and (d) repeat this visualization for low-confidence images, revealing a difference in weight patterns that is indicative of errors.
read the caption
Figure 2: Visual comparison of integration weights a in MHSA. (a) and (b) respectively present visualizations of weights a at different depths of blocks for high-confidence images and the overlay of reshaped and resized rows of a onto the original image. Similarly, (c) and (d) depict visualizations of weights a for low-confidence images and their overlay onto the original image.

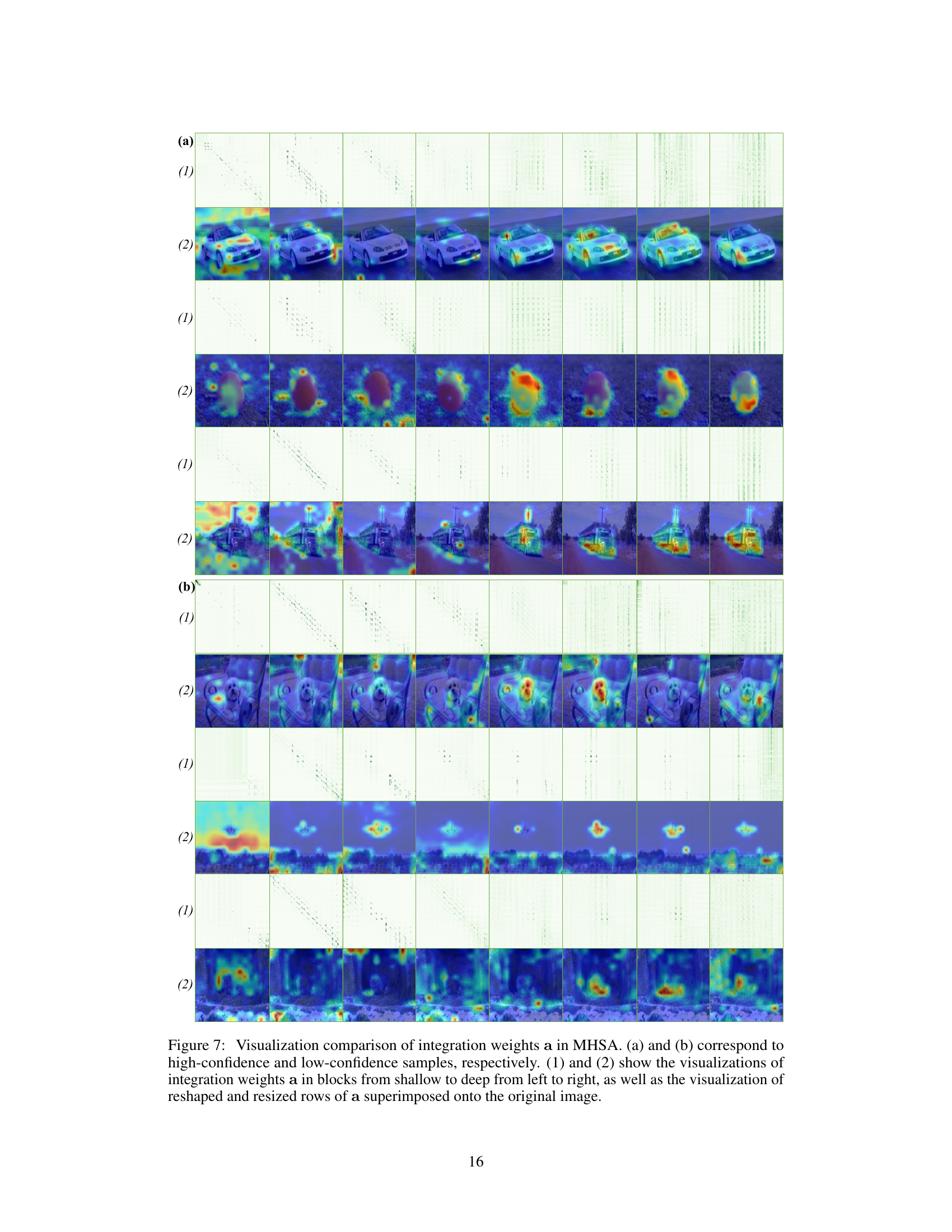
🔼 This figure compares the integration weights (a) in the Multi-Head Self-Attention (MHSA) module of a Transformer model for both high and low confidence image samples. It shows the visualization of these weights at different depths within the model. The top row shows high confidence samples while the bottom shows low confidence samples. The left column for each shows the integration weights themselves at various depths. The right column shows the weights overlaid onto the original images for visualization. The difference highlights how the model processes information differently depending on confidence in its prediction, with correct predictions (high-confidence) showing a consistent integration pattern and incorrect predictions showing inconsistent and erroneous patterns.
read the caption
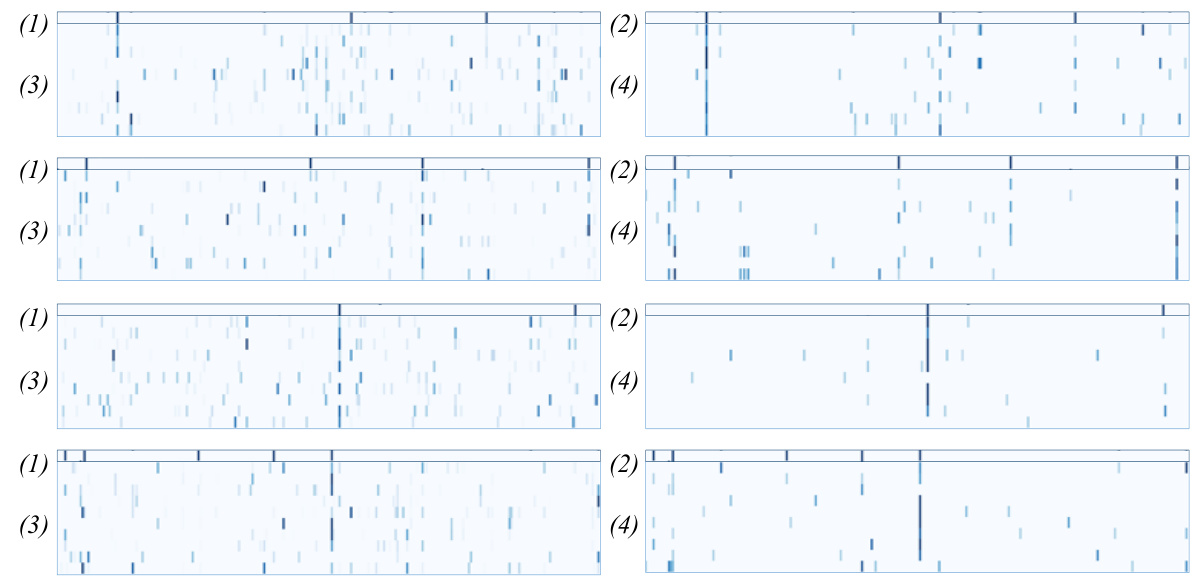
Figure 7: Visualization comparison of integration weights a in MHSA. (a) and (b) correspond to high-confidence and low-confidence samples, respectively. (1) and (2) show the visualizations of integration weights a in blocks from shallow to deep from left to right, as well as the visualization of reshaped and resized rows of a superimposed onto the original image.

🔼 This figure compares the integration weights (a) in the Multi-Head Self-Attention (MHSA) module of a Transformer model for high-confidence and low-confidence image samples. It visualizes these weights at different depths within the model, showing how they change from shallow to deep layers. The visualizations overlay the reshaped integration weights on the original images to show the spatial regions of focus.
read the caption
Figure 7: Visualization comparison of integration weights a in MHSA. (a) and (b) correspond to high-confidence and low-confidence samples, respectively. (1) and (2) show the visualizations of integration weights a in blocks from shallow to deep from left to right, as well as the visualization of reshaped and resized rows of a superimposed onto the original image.
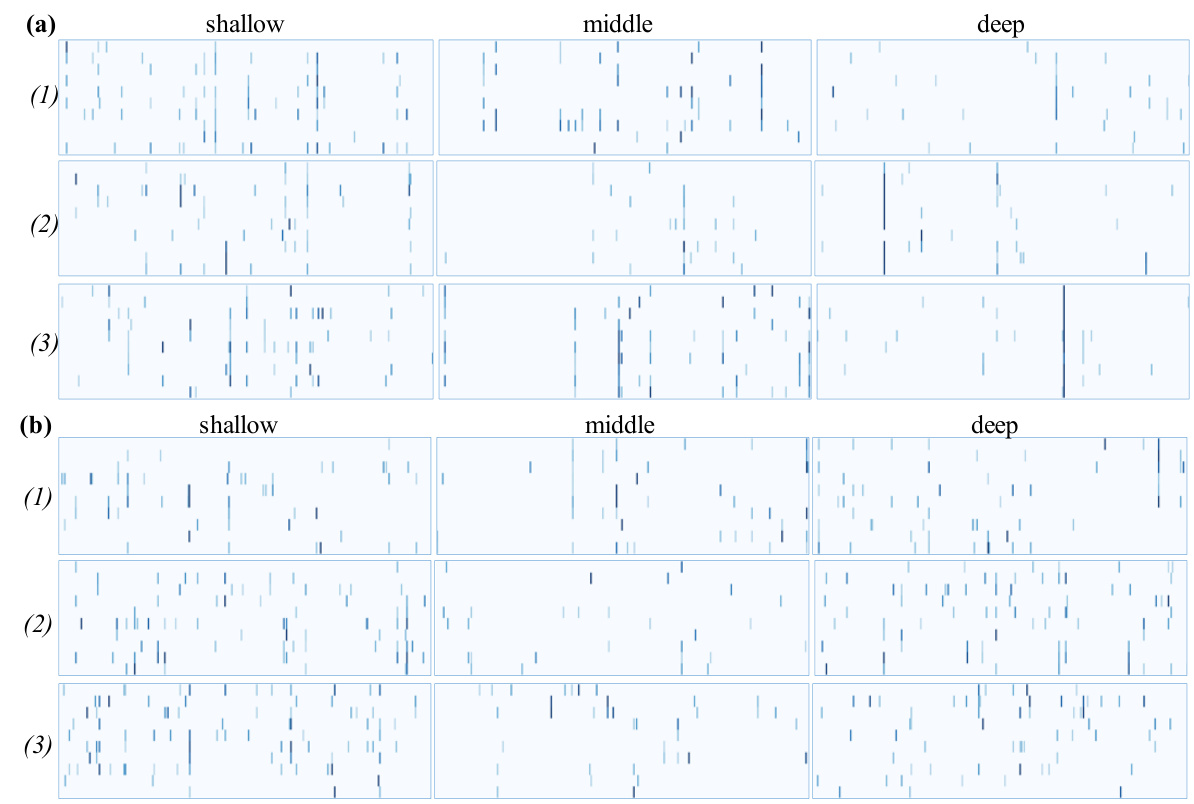
🔼 This figure compares the integration weights (a) in the multi-head self-attention (MHSA) module of a Transformer model for high-confidence and low-confidence image samples. It shows how the weights change across different depths (shallow, middle, deep) within the Transformer blocks. The visualization includes both a matrix representation of the weights and an overlay of reshaped and resized rows of the weights onto the original image to demonstrate their spatial relationship.
read the caption
Figure 7: Visualization comparison of integration weights a in MHSA. (a) and (b) correspond to high-confidence and low-confidence samples, respectively. (1) and (2) show the visualizations of integration weights a in blocks from shallow to deep from left to right, as well as the visualization of reshaped and resized rows of a superimposed onto the original image.
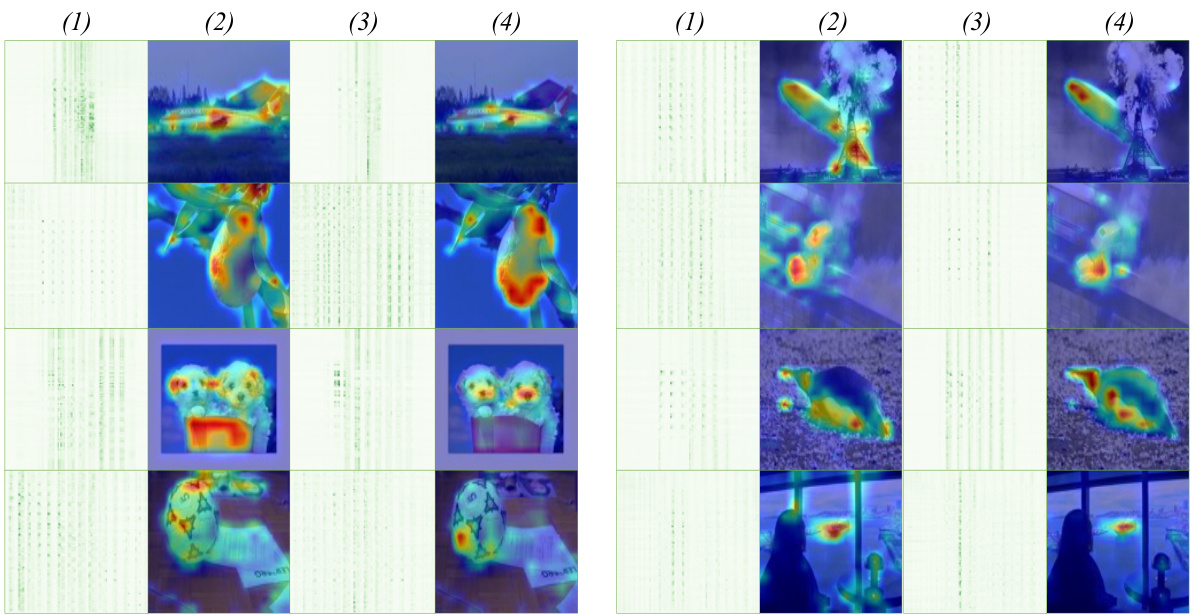
🔼 This figure visually compares the integration weights (a) from the Multi-Head Self-Attention (MHSA) module of a Transformer model at different depths (layers) for both high-confidence and low-confidence image classifications. Panels (a) and (b) show the weights for high-confidence images, with (b) overlaying a reshaped and resized representation of the weights onto the original image as a heatmap. Panels (c) and (d) repeat this process for low-confidence images. The visualizations aim to demonstrate the dynamic integration of information among tokens in MHSA as the model processes information at different depths.
read the caption
Figure 2: Visual comparison of integration weights a in MHSA. (a) and (b) respectively present visualizations of weights a at different depths of blocks for high-confidence images and the overlay of reshaped and resized rows of a onto the original image. Similarly, (c) and (d) depict visualizations of weights a for low-confidence images and their overlay onto the original image.
🔼 This figure visually compares the integration weights (a) in the Multi-Head Self-Attention (MHSA) module of a Transformer model. It shows how these weights change across different depths (shallow to deep) for both high-confidence and low-confidence image samples. The visualization helps understand how information is integrated among tokens at various stages of the network, highlighting differences between correct and incorrect predictions.
read the caption
Figure 7: Visualization comparison of integration weights a in MHSA. (a) and (b) correspond to high-confidence and low-confidence samples, respectively. (1) and (2) show the visualizations of integration weights a in blocks from shallow to deep from left to right, as well as the visualization of reshaped and resized rows of a superimposed onto the original image.

🔼 This figure illustrates the workflow of the Transformer Doctor framework. It starts by analyzing the dynamic information integration among tokens (inter-token) within the Multi-Head Self-Attention (MHSA) module and the static information integration within tokens (intra-token) in the Feed-Forward Network (FFN) module of a vision transformer. The framework then diagnoses conjunction errors in both MHSA and FFN. Finally, it applies treatment methods (heuristic dynamic integration constraints for MHSA and rule-based static integration constraints for FFN) to correct these errors and improve model performance.
read the caption
Figure 1: The methodology framework of Transformer Doctor. It begins by analyzing the dynamic integration of inter-token information in MHSA and the static integration of intra-token information in FFN, Subsequently, conjunction errors within them are diagnosed, and finally treated to enhance model performance.

🔼 This figure illustrates the methodology of Transformer Doctor. It’s a flowchart showing the diagnostic and treatment steps for vision transformers. First, the model analyzes dynamic integration of information between tokens (inter-token) within the Multi-Head Self-Attention (MHSA) module and static information integration within each token (intra-token) within the Feed-Forward Network (FFN). Then, it diagnoses conjunction errors that occur during the integration of information. Finally, it applies methods to correct these errors, enhancing overall model performance.
read the caption
Figure 1: The methodology framework of Transformer Doctor. It begins by analyzing the dynamic integration of inter-token information in MHSA and the static integration of intra-token information in FFN, Subsequently, conjunction errors within them are diagnosed, and finally treated to enhance model performance.
More on tables

🔼 This table shows the performance improvements achieved by applying the Transformer Doctor method to various state-of-the-art (SOTA) vision transformer models. The performance is measured as accuracy (%) on five different datasets (CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-50, and ImageNet-1K) for several transformer architectures. For each model and dataset, both the baseline accuracy (without Transformer Doctor) and the accuracy after treatment with Transformer Doctor are presented, showing the percentage improvement.
read the caption
Table 1: Performance of Transformer Doctor on various SOTA Transformers. '+Doctor' indicates the performance of model treated with Transformer Doctor (All Score are in %).
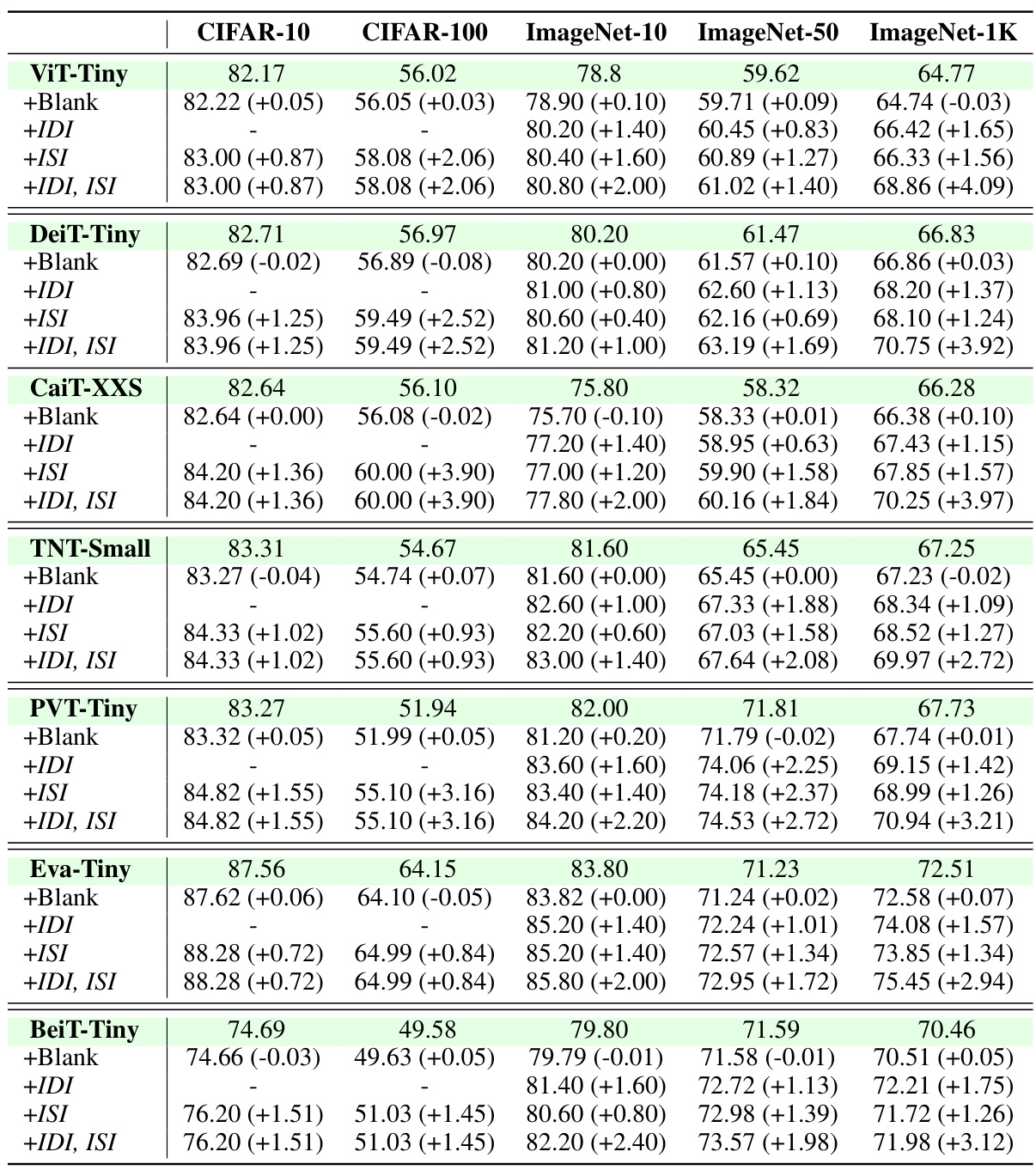
🔼 This table presents the performance comparison of several state-of-the-art (SOTA) vision transformers before and after applying the Transformer Doctor method. The table shows accuracy improvements (in percentage points) across five different datasets (CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-50, and ImageNet-1K) for various transformer architectures such as ViT-Tiny, DeiT-Tiny, CaiT-XXS, TNT-Small, PVT-Tiny, Eva-Tiny and BeiT-Tiny. The ‘+Doctor’ column indicates the performance after treatment with the Transformer Doctor. The table highlights the effectiveness of the Transformer Doctor method in enhancing model performance across diverse datasets and architectures.
read the caption
Table 1: Performance of Transformer Doctor on various SOTA Transformers. '+Doctor' indicates the performance of model treated with Transformer Doctor (All Score are in %)

🔼 This table presents the performance improvement achieved by applying the Transformer Doctor framework to several state-of-the-art (SOTA) vision transformers. The results are shown for five different datasets (CIFAR-10, CIFAR-100, ImageNet-10, ImageNet-50, and ImageNet-1K) and across various transformer architectures. For each model and dataset, the baseline accuracy is given, along with the accuracy after treatment with Transformer Doctor, showing the percentage increase in performance. The ‘+Doctor’ designation indicates the model’s performance after treatment.
read the caption
Table 1: Performance of Transformer Doctor on various SOTA Transformers. '+Doctor' indicates the performance of model treated with Transformer Doctor (All Score are in %).
Full paper#