↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Self-Supervised Adversarial Training (SAT) aims to learn robust features without labels, but existing methods suffer from a large robust generalization gap and accuracy degradation. This paper identifies the lack of data complexity and model regularization as key issues hindering SAT’s effectiveness. Existing works are also limited by focusing on specific Self-Supervised Learning (SSL) frameworks, like contrastive learning, lacking generalizability.
The researchers propose a novel method, DAQ-SDP (Diverse Augmented Queries Self-Supervised Double Perturbation), to overcome these limitations. DAQ-SDP introduces diverse augmented queries to guide adversarial training and incorporates self-supervised double perturbation to enhance robustness. Key to the approach is a novel Aug-Adv Pairwise-BatchNorm adversarial training method that leverages the strength of diverse augmentations without sacrificing robustness. Experiments demonstrate that DAQ-SDP improves both robust and natural accuracies across various SSL frameworks and datasets, significantly reducing the generalization gap and bridging the gap between SAT and supervised adversarial training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on self-supervised adversarial training (SAT). It addresses the significant gap in robust generalization, a major challenge in SAT. The proposed DAQ-SDP method offers a general solution applicable to various self-supervised learning frameworks. This opens new avenues for improving the robustness and efficiency of SAT algorithms, directly impacting the development of more reliable and secure AI systems. The findings challenge prior assumptions about data augmentation and model regularization in SAT and offer insights for unifying SAT and supervised AT.
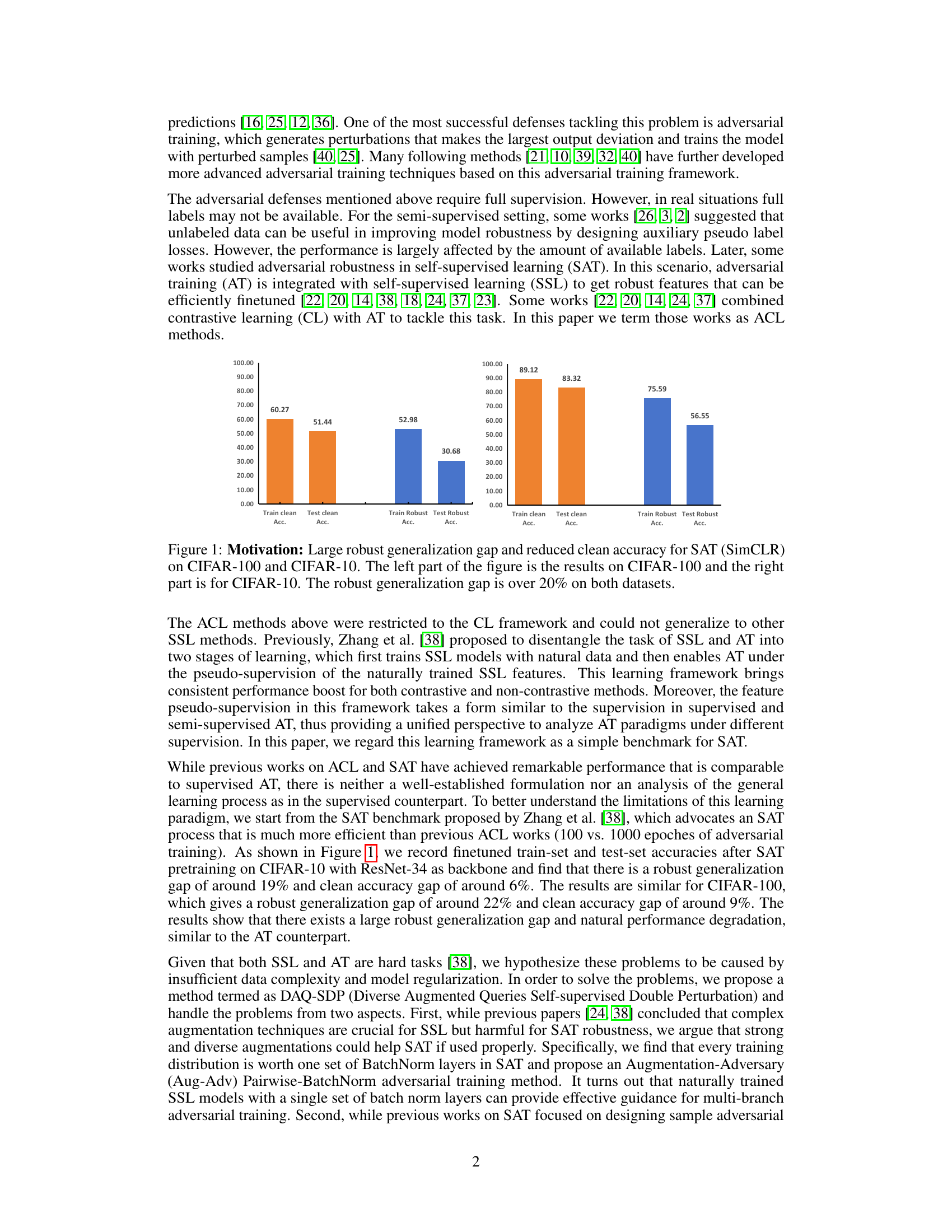
Visual Insights#

This figure shows the large performance gap between self-supervised adversarial training (SAT) and supervised adversarial training on CIFAR-10 and CIFAR-100 datasets. The left side displays the results for CIFAR-100, and the right side for CIFAR-10. The bar chart compares training and testing accuracy under clean and robust conditions. The key observation is a significant difference between clean and robust accuracies in the testing phase for SAT, indicating poor generalization under adversarial attacks. This motivates the need for improved SAT methods.

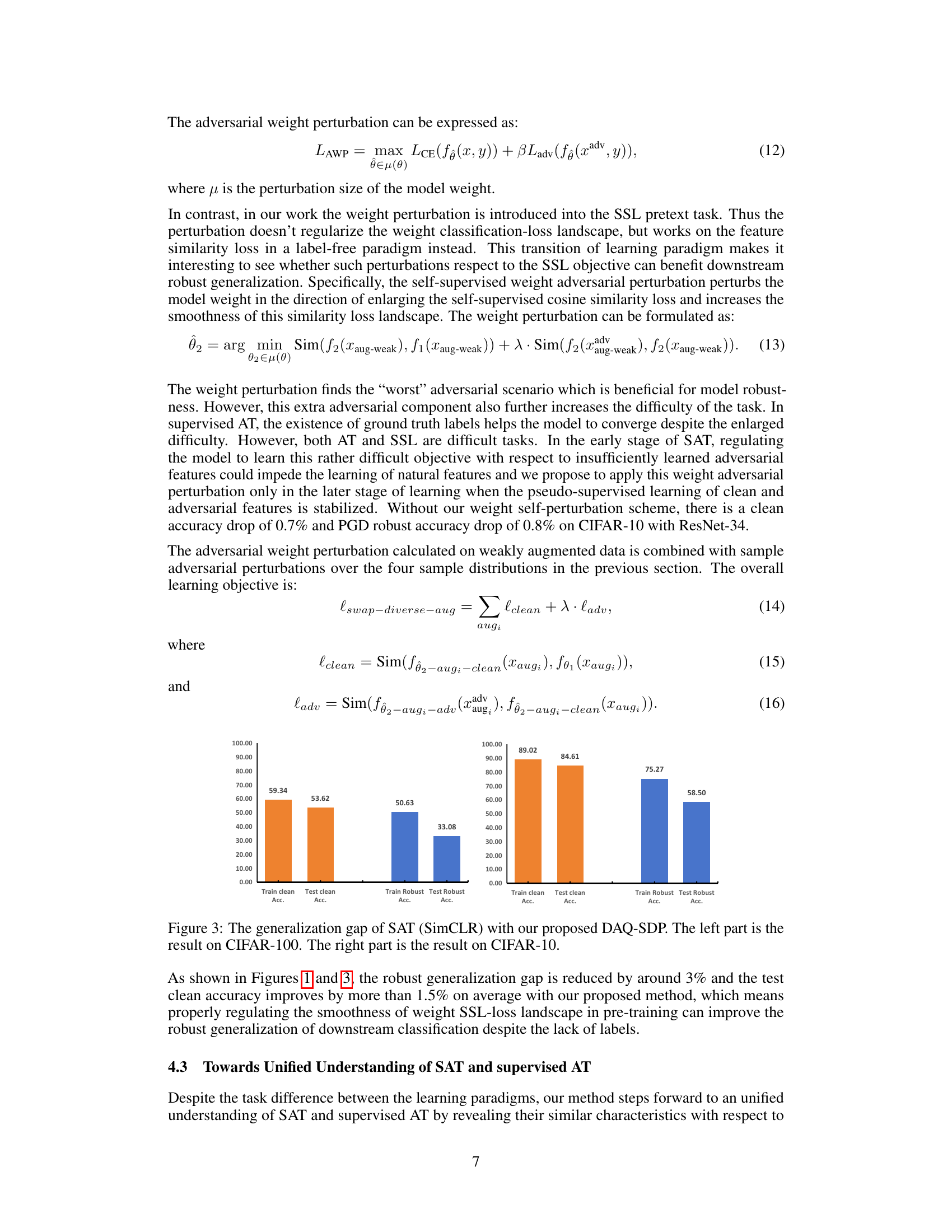
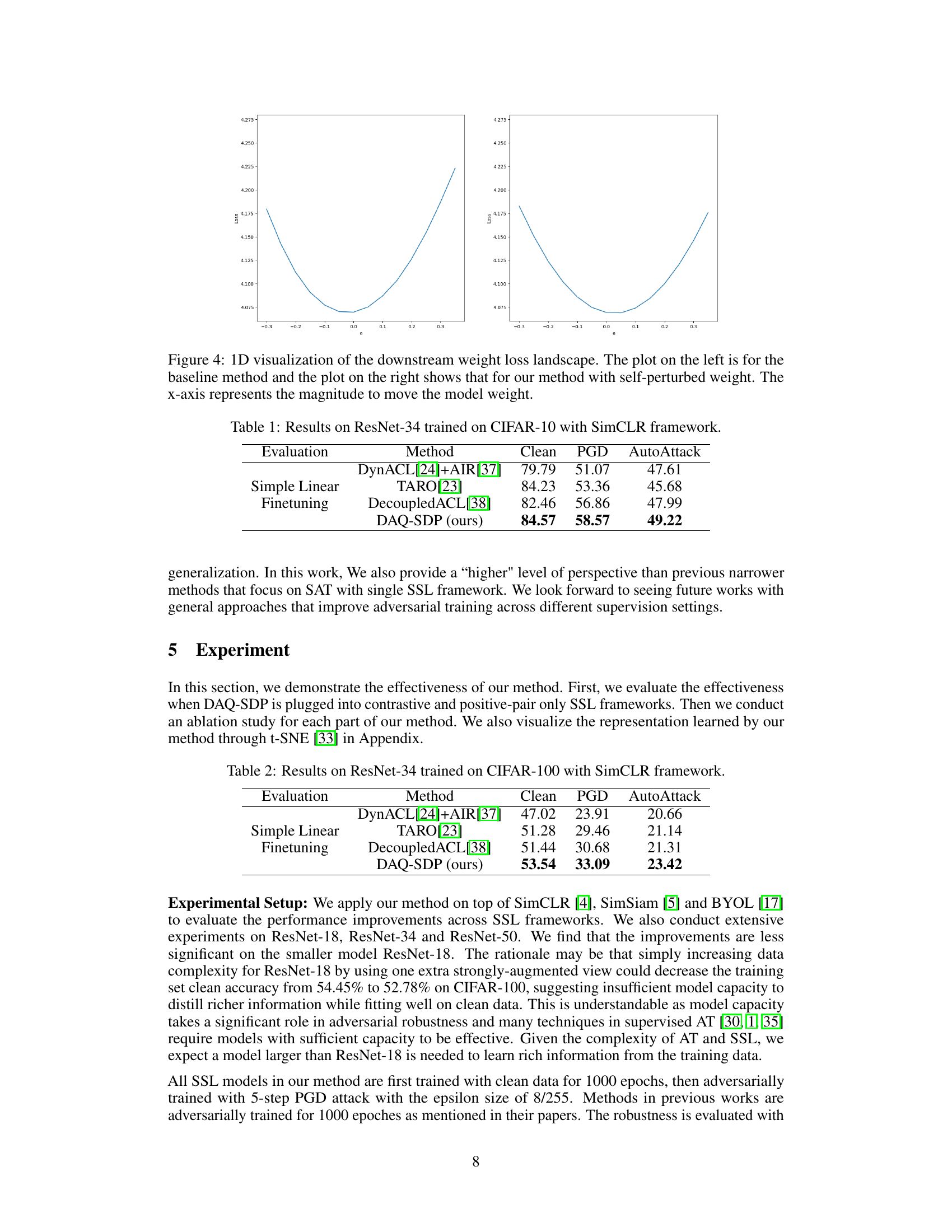
This table presents the results of different methods on CIFAR-10 using ResNet-34 as the backbone model and SimCLR framework. The evaluation metrics include Clean accuracy, PGD accuracy (measuring robustness against Projected Gradient Descent attacks), and AutoAttack accuracy (measuring robustness against a more powerful, ensemble-based attack). The methods compared include DynACL+AIR, TARO, DecoupledACL, and the proposed DAQ-SDP. The results show the performance of each method under different evaluation metrics, providing insight into the effectiveness of each method in achieving both high accuracy and robustness.
In-depth insights#
SAT’s Robustness Gap#
The paper investigates the robustness gap in self-supervised adversarial training (SAT). A core observation is that SAT, while showing promise, still underperforms supervised AT in terms of robustness. This gap is attributed to a lack of data complexity and insufficient model regularization during SAT. The authors hypothesize that current approaches fail to effectively leverage the inherent generalization capabilities of self-supervised learning models. This leads to a significant discrepancy between performance on clean and adversarial examples. The proposed DAQ-SDP method aims to directly address these limitations by using diverse augmented queries to guide adversarial training, thereby improving robustness without sacrificing accuracy on natural samples. The incorporation of self-supervised double perturbation further enhances the robustness and generalizability of the model. The analysis of this robustness gap provides valuable insights into the key challenges of robust feature learning in a self-supervised setting. The findings suggest that enhancing data complexity and model regularization through techniques like augmentations and double perturbation are vital steps towards bridging the performance gap between SAT and supervised AT.
DAQ-SDP Approach#
The DAQ-SDP approach tackles the challenge of robust generalization in self-supervised adversarial training (SAT) by addressing two key limitations: insufficient data complexity and lack of model regularization. Diverse Augmented Queries (DAQ) challenges the conventional wisdom that complex augmentations hinder robustness in SAT. Instead, DAQ leverages diverse augmentations to generate multiple sample views, using them as queries to guide adversarial training. This expands data complexity and improves generalization. Self-Supervised Double Perturbation (SDP) introduces model perturbation into the self-supervised learning phase, improving robustness transferable to downstream classification. Unlike previous methods that solely focus on sample-level perturbations, SDP enhances the robustness of the learned features themselves. By combining DAQ and SDP, the approach seamlessly integrates into various self-supervised learning frameworks without modifying learning objectives, bridging the gap between SAT and supervised adversarial training. The innovative strategy of using diverse augmentations and model perturbation demonstrates a more holistic and effective approach to achieving robust and accurate models in the SAT paradigm.
Aug-Adv Pairwise-BN#
The proposed Aug-Adv Pairwise-BN technique represents a novel approach to enhancing the robustness of self-supervised adversarial training (SAT). It directly addresses the limitations of previous methods by integrating diverse augmentations and a pairwise Batch Normalization (BN) strategy. The core idea is to leverage the inherent generalization capabilities of self-supervised learning (SSL) models trained on naturally augmented data, even under the challenging conditions of adversarial training. Instead of viewing complex augmentations as detrimental to SAT robustness, as some prior work suggests, this method uses them constructively. By creating multiple input streams with varied augmentations (strong and weak) and adversarial perturbations, it allows the model to learn richer, more robust representations. The pairwise BN further refines this process by enabling each input stream’s features to adapt to the diverse augmentations and adversarial examples while preserving features from the clean, naturally trained model. This approach fosters a stronger balance between generalization and specialization, bridging the gap often observed between self-supervised and supervised adversarial training. The innovative Aug-Adv Pairwise-BN technique, therefore, contributes significantly to the improvement of SAT by intelligently using diverse data augmentation and tailored model regularization strategies.
Self-Perturbed Weights#
The concept of “Self-Perturbed Weights” introduces a novel approach to enhance the robustness of self-supervised adversarial training (SAT). Instead of solely focusing on perturbing input data, this method proposes to directly perturb the model’s weights during the self-supervised learning phase. This internal perturbation acts as a form of regularization, improving the model’s generalization and resistance to adversarial attacks. By optimizing the model’s weights against these self-induced perturbations, the model learns to be less sensitive to changes in its internal representation, leading to more robust features. The key benefit lies in its compatibility with existing self-supervised learning frameworks, seamlessly integrating into the training process without requiring significant architectural modifications. This method effectively bridges the gap between self-supervised and fully supervised adversarial training paradigms, offering a potentially more efficient and generalized approach for building robust models.
Unified SAT view#
A unified SAT (Self-Supervised Adversarial Training) view would ideally bridge the gap between supervised and self-supervised adversarial training methods. It would highlight shared principles and transferable techniques, enabling a more efficient and effective approach to building robust models. Such a perspective might focus on the core mechanism of adversarial training – creating robust features through the generation and handling of adversarial examples – rather than dwelling on the specific data augmentation or loss functions employed in either paradigm. A unified view could also explore how the inherent properties of self-supervised learning (SSL), such as learning from unlabeled data and the use of pretext tasks, can be leveraged to enhance adversarial robustness. This could involve investigating the transferability of robustness learned during the SSL phase to downstream classification tasks. Finally, a unified view would likely propose generalizable frameworks and methods that can easily incorporate various SSL pretext tasks and architectures, moving beyond the constraints of specific contrastive learning setups. This could lead to more efficient algorithms and better performance across different SSL methods.
More visual insights#
More on figures
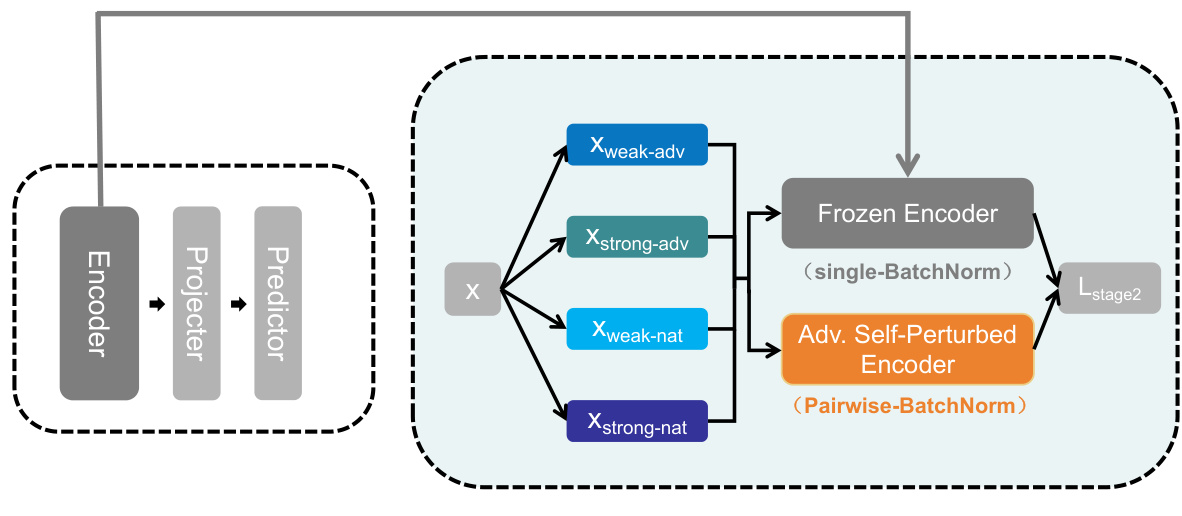
The figure shows the architecture of the proposed method, DAQ-SDP, which is composed of two stages: self-supervised learning and adversarial training. In the first stage, a self-supervised model is trained with clean data. Then, in the second stage, the features predicted by the clean model are used to guide the adversarial training of a robust encoder. The robust encoder uses a pairwise-BatchNorm to handle diverse augmented queries and self-supervised double perturbation.
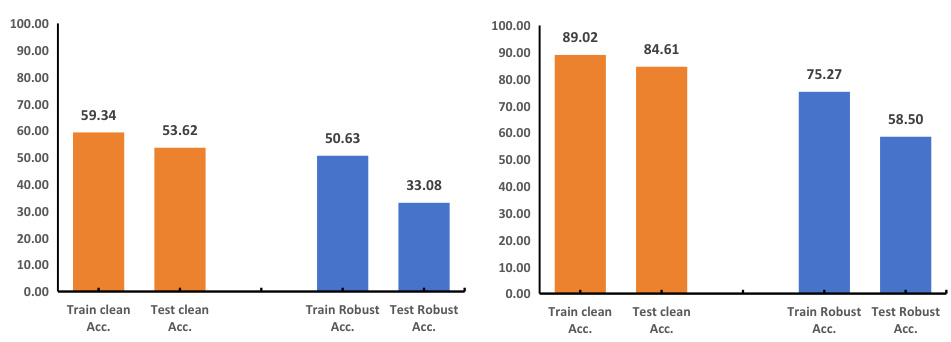
This figure shows the performance of Self-Supervised Adversarial Training (SAT) using SimCLR on CIFAR-10 and CIFAR-100 datasets. The bar chart displays the training and testing accuracies for both clean and robust (adversarial) examples. The key observation is a significant gap between clean and robust accuracies, highlighting the robustness issue faced by SAT. This gap is particularly pronounced in the testing phase. The results are presented separately for CIFAR-100 and CIFAR-10 datasets.
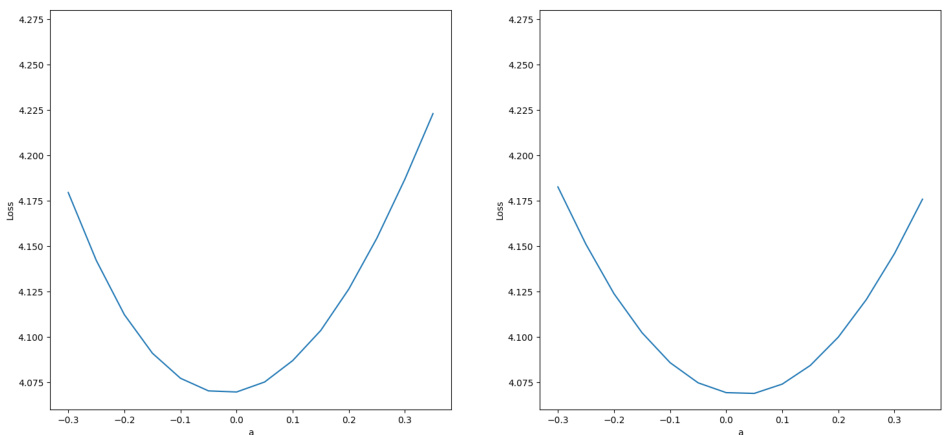
This figure visualizes the effect of the proposed DAQ-SDP method on the downstream weight loss landscape. Two 1D plots are shown, one for the baseline method and another for the method with self-perturbed weights. The x-axis represents the magnitude of the weight perturbation, while the y-axis shows the corresponding loss. The plots illustrate how the self-perturbation technique affects the smoothness of the loss landscape, potentially improving model robustness.

This figure visualizes the t-SNE results of the test set features using two different methods: the adversarial training baseline and the proposed DAQ-SDP method. Each data point represents a feature vector, colored according to its class label. The visualization shows that the features predicted by DAQ-SDP exhibit clearer boundaries between different classes compared to the baseline, indicating better class separation and potentially improved performance.
More on tables

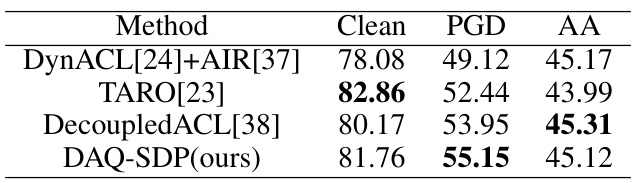
This table presents the results of experiments conducted on the CIFAR-100 dataset using ResNet-34 as the backbone model and the SimCLR framework. The table compares four different methods for self-supervised adversarial training (SAT): DynACL[24]+AIR[37], TARO[23], DecoupledACL[38], and the proposed DAQ-SDP. The evaluation metrics include clean accuracy, accuracy under PGD attack, and accuracy under AutoAttack. The results show the performance of each method in terms of robustness against adversarial attacks and natural accuracy.
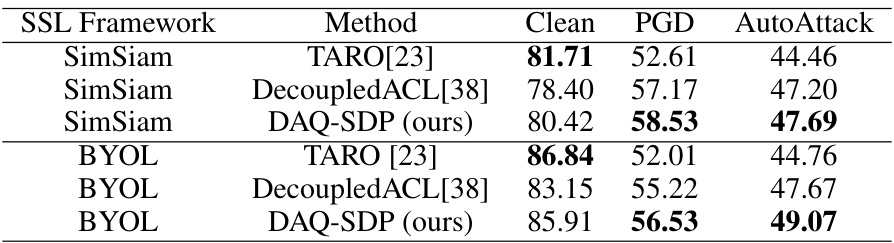
This table presents the results of the proposed DAQ-SDP method and baseline methods on different self-supervised learning (SSL) frameworks using ResNet-34 as the backbone and CIFAR-10 as the dataset. The table compares the performance (Clean accuracy, PGD attack robustness, and AutoAttack robustness) of the DAQ-SDP method to other state-of-the-art methods. It highlights the effectiveness of DAQ-SDP across various SSL frameworks and its improvement over the baselines.
This table presents the results of experiments conducted using ResNet-18, trained on CIFAR-10 with the SimCLR framework. It compares the performance of four different methods across three evaluation metrics: Clean accuracy, PGD attack accuracy, and AutoAttack accuracy. The methods compared are DynACL+AIR, TARO, DecoupledACL, and the proposed DAQ-SDP. The table highlights the improvements in robust accuracy achieved by the proposed DAQ-SDP method over existing state-of-the-art methods.
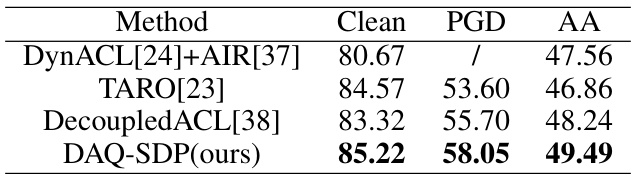
This table presents the results of experiments conducted using ResNet-50, trained on CIFAR-10 dataset with the SimCLR framework. It compares the performance of different methods (DynACL[24]+AIR[37], TARO[23], DecoupledACL[38], and the proposed DAQ-SDP) in terms of clean accuracy, accuracy under PGD attack, and accuracy under AutoAttack. The results highlight the performance improvement of the DAQ-SDP method over existing state-of-the-art techniques.

This table shows the results of cross-dataset transfer learning experiments from CIFAR-100 to CIFAR-10. The methods used are not limited to a single self-supervised learning (SSL) framework. Both simple linear finetuning (SLF) and adversarial full finetuning (AFF) are employed. ResNet-34 is used as the backbone model. The table presents clean and PGD accuracy for both finetuning methods. The goal is to demonstrate the transferability and robustness of the proposed DAQ-SDP approach across different settings.
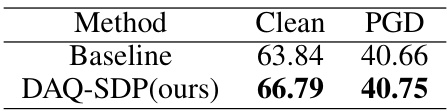
This table presents the results of transfer learning experiments from the CIFAR-10 dataset to the STL-10 dataset using ResNet-34 as the backbone model. The results show the clean accuracy and accuracy under PGD attacks for both a baseline method and the proposed DAQ-SDP method. The purpose is to evaluate the generalizability and robustness of the DAQ-SDP method on a different dataset.
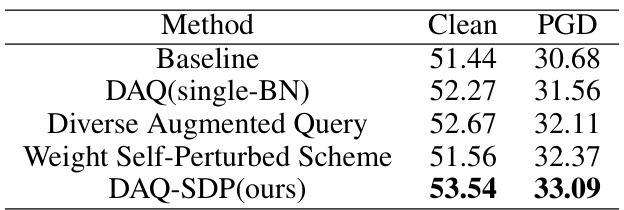
This table presents the ablation study results conducted using the SimCLR framework on the CIFAR-100 dataset with a ResNet-34 backbone. It compares the performance of different components of the proposed DAQ-SDP method against the baseline, illustrating the individual contributions of each part to improved clean and robust accuracy. The baseline refers to the original method without any of the proposed enhancements.
Full paper#