↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Vision-Language Models (LVLMs) excel in understanding visual information and engaging in conversations, but they often suffer from object hallucination; they generate responses that are not factually aligned with the input images. This inaccuracy is a major drawback as it limits the reliability of these models. One significant cause identified is the long-term decay effect within the Rotary Position Encoding (RoPE), a mechanism that models positional dependencies within the data. This effect makes it challenging for the model to accurately connect visual elements that are spatially distant from the instruction tokens in the input sequence.
This research proposes a novel approach called Concentric Causal Attention (CCA) to effectively counter this problem. CCA cleverly reorganizes the positions of visual tokens within the input sequence, thereby decreasing the relative distances between visual and instruction tokens and enhancing their interaction. Through this innovative positional alignment strategy, CCA significantly improves the model’s ability to capture the visual-instruction interaction even over long distances. Experimental results demonstrate that CCA surpasses existing hallucination mitigation strategies by large margins across multiple benchmarks, not only reducing hallucination but also generally boosting model performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large vision-language models (LVLMs). It addresses the prevalent issue of object hallucination, offering a novel solution that significantly improves model accuracy and reliability. The findings could inspire new research directions in positional encoding strategies and enhance the overall performance of LVLMs in various applications. Its simplicity and effectiveness make it readily applicable to existing LVLMs, thus offering a valuable contribution to the field.
Visual Insights#
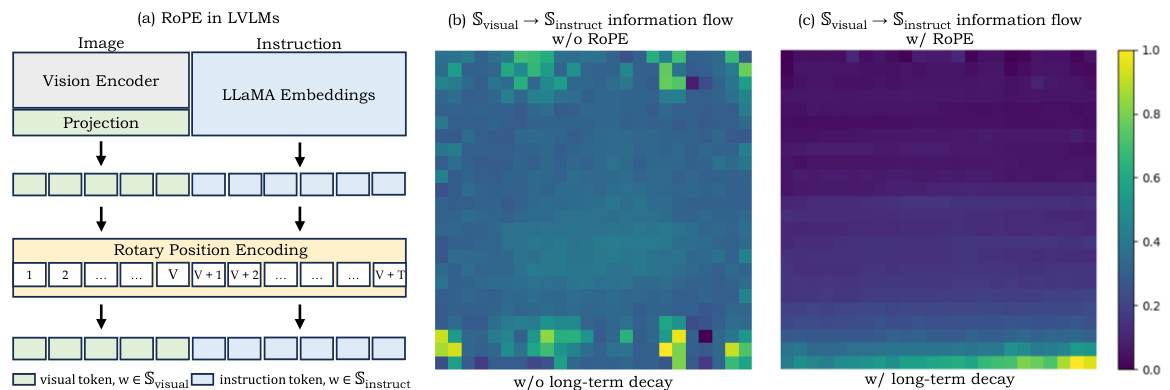
This figure illustrates the long-term decay effect of Rotary Position Encoding (RoPE) in Large Vision Language Models (LVLMs). It shows a schematic of LVLM inference, highlighting the role of RoPE in mapping visual and instruction tokens into a shared textual space. The heatmaps (b) and (c) visualize the information flow from visual tokens to instruction tokens, demonstrating how RoPE’s long-term decay weakens the interaction between visual and instruction tokens when they are far apart in the input sequence. This decay is more pronounced when visual tokens are distant from instruction tokens in the sequence.
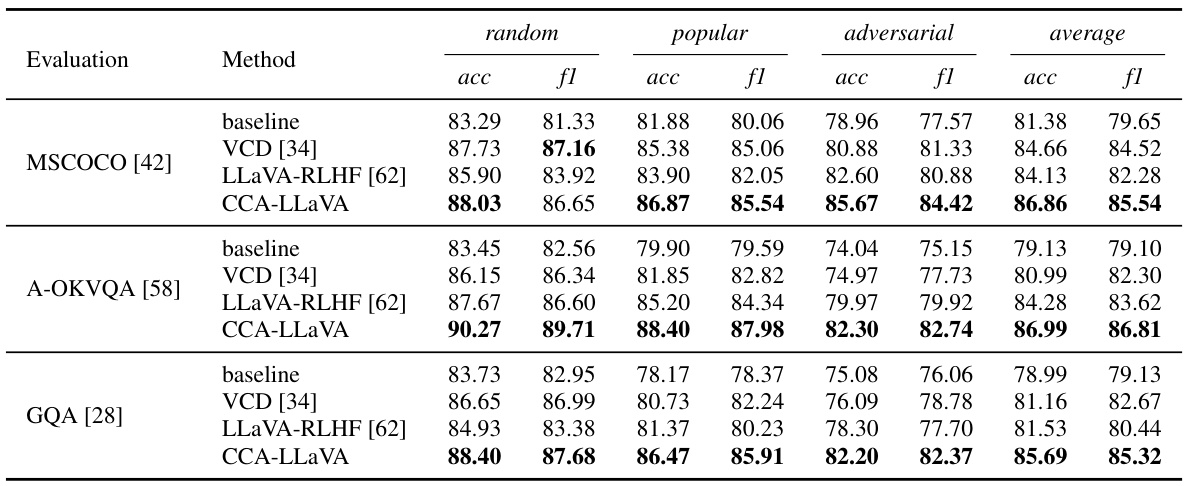
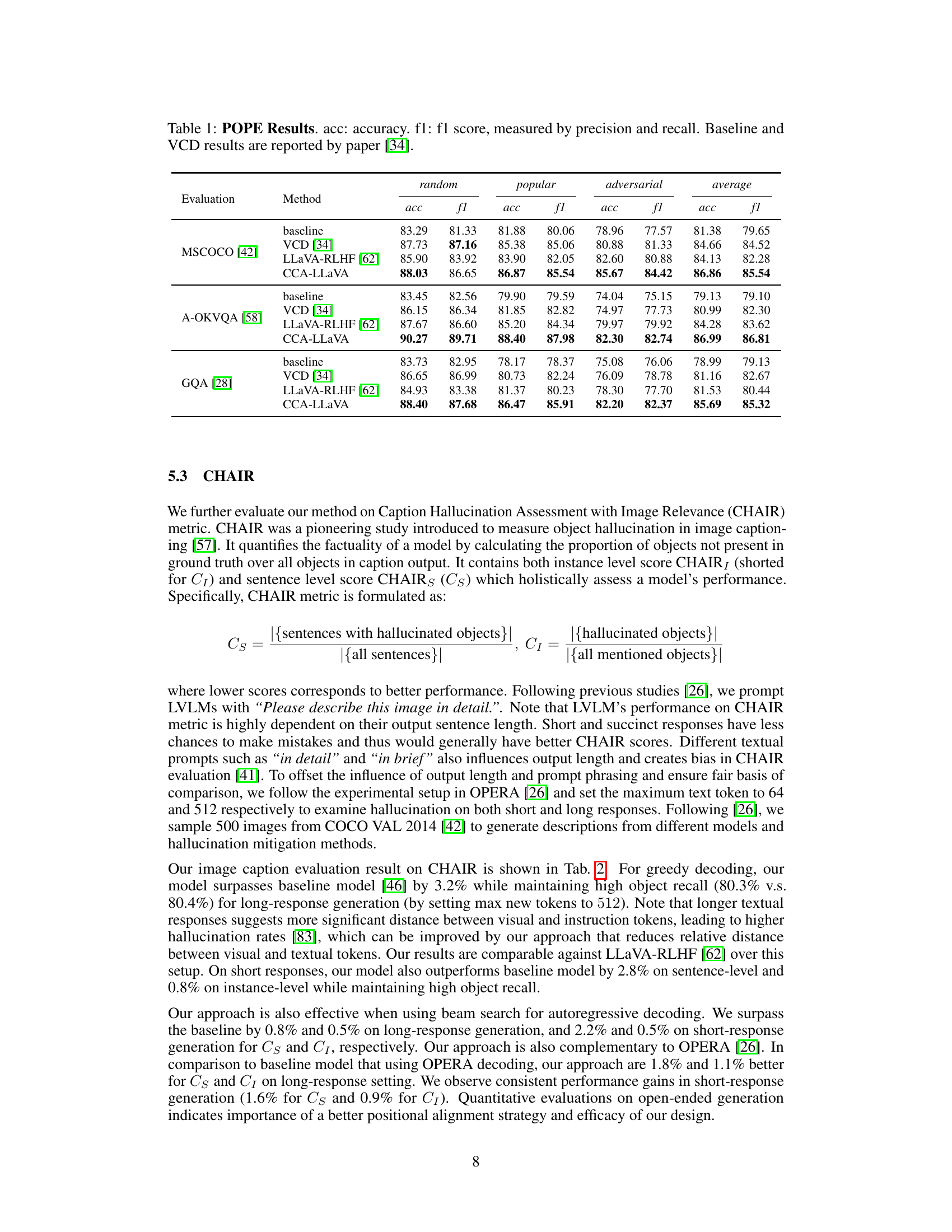
This table presents the results of the Polling-based Object Probing Evaluation (POPE) experiment, which evaluates object hallucination in Large Vision-Language Models (LVLMs). It shows the accuracy (acc) and F1 score (f1) of different models on three datasets (MSCOCO, A-OKVQA, and GQA) across three negative sampling methods (random, popular, and adversarial). The table compares the performance of the proposed CCA-LLaVA model against baseline LLaVA, VCD (a previous hallucination mitigation method), and LLaVA-RLHF (a model with human feedback). The results are broken down for each dataset and negative sampling method, allowing for a detailed analysis of the model’s performance in different scenarios.
In-depth insights#
RoPE’s Decay Impact#
The authors investigate the impact of Rotary Position Embedding (RoPE)’s long-term decay on Large Vision-Language Models (LVLMs), specifically focusing on its contribution to object hallucination. RoPE’s inherent limitation of attenuating information flow over long distances in the multimodal sequences is identified as a key factor. This decay results in LVLMs having difficulty in establishing sufficient connections between visual cues far from the instruction tokens, causing inaccurate or hallucinatory outputs. The analysis reveals a correlation between the distance of visual tokens from instruction tokens and the occurrence of object hallucination. This observation is further supported by a controlled experiment reversing the input order of visual tokens, which amplifies the problem, thus demonstrating the crucial role of positional encoding in accurate multimodal alignment. This insightful analysis of RoPE’s decay sets the stage for the introduction of Concentric Causal Attention (CCA), a novel mitigation strategy designed to improve visual-instruction token interaction by reducing their relative distance.
Concentric CCA#
Concentric Causal Attention (CCA) is proposed as a novel positional alignment strategy for Large Vision-Language Models (LVLMs) to mitigate the adverse effects of Rotary Position Encoding (RoPE)’s long-term decay. RoPE’s decay weakens the interactions between visual and instruction tokens when they are spatially distant in the input sequence, leading to object hallucination. CCA addresses this by reorganizing visual tokens in a concentric pattern, starting from the image periphery and moving toward the center. This effectively reduces the relative distance between visual and instructional tokens, improving their interaction. Furthermore, CCA rectifies the default causal attention mask to align with this concentric arrangement, ensuring 2D spatial locality is preserved, which is more natural for image data than the original 1D raster-scan approach. The concentric arrangement and causal masking work in tandem to improve the model’s ability to correctly perceive and relate visual information to the instructions, ultimately leading to significant improvements in object hallucination benchmarks and general LVLM perception capabilities.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a thorough quantitative analysis comparing the proposed method’s performance against state-of-the-art techniques across multiple relevant benchmarks. Key metrics such as accuracy, precision, recall, F1-score, and any other relevant evaluation measures should be reported. The choice of benchmarks themselves is crucial and should reflect the problem domain’s diversity. Statistical significance testing (e.g., p-values) would bolster the reliability of reported results. For each benchmark, a table clearly showing the results for each method would be beneficial. Furthermore, a discussion of the results’ implications and potential limitations of the benchmarks should be included, contextualizing the performance figures and their significance in a broader context. Ultimately, a strong ‘Benchmark Results’ section will persuasively demonstrate the proposed method’s effectiveness and offer a fair comparison to the existing literature.
Method Limitations#
A research paper’s ‘Method Limitations’ section is crucial for assessing its validity and reliability. It should transparently discuss any constraints or shortcomings inherent in the methodology, such as sample size limitations which affect statistical power and generalizability, or technical constraints like specific hardware/software requirements that limit accessibility. The discussion must also explore the limitations of the data used, acknowledging potential biases, inaccuracies, or incompleteness that might skew results. It is essential to address methodological assumptions, explaining how their violation could impact the findings. For instance, if the study assumes a linear relationship between variables, the analysis should mention how non-linearity could affect interpretations. Finally, a thorough limitations section must acknowledge any unforeseen challenges or difficulties encountered during the research, clarifying their potential impact on the overall conclusions and suggesting avenues for future improvement. Transparency in this section builds trust and fosters credibility within the scientific community.
Future Directions#
Future research could explore improving CCA’s efficiency for even faster inference times. Extending CCA to other modalities beyond vision and language, such as audio or video, could unlock new applications. Investigating the interaction between CCA and other hallucination mitigation techniques could lead to hybrid approaches with superior performance. A deeper analysis of CCA’s effect on various LVLM architectures would solidify its generalizability. Finally, rigorous testing on a wider range of datasets and tasks is crucial to validate CCA’s robustness and assess its potential for real-world deployment. Furthermore, exploring alternative positional encoding methods that avoid the long-term decay issue inherent in RoPE could pave the way for more advanced and efficient positional encodings.
More visual insights#
More on figures
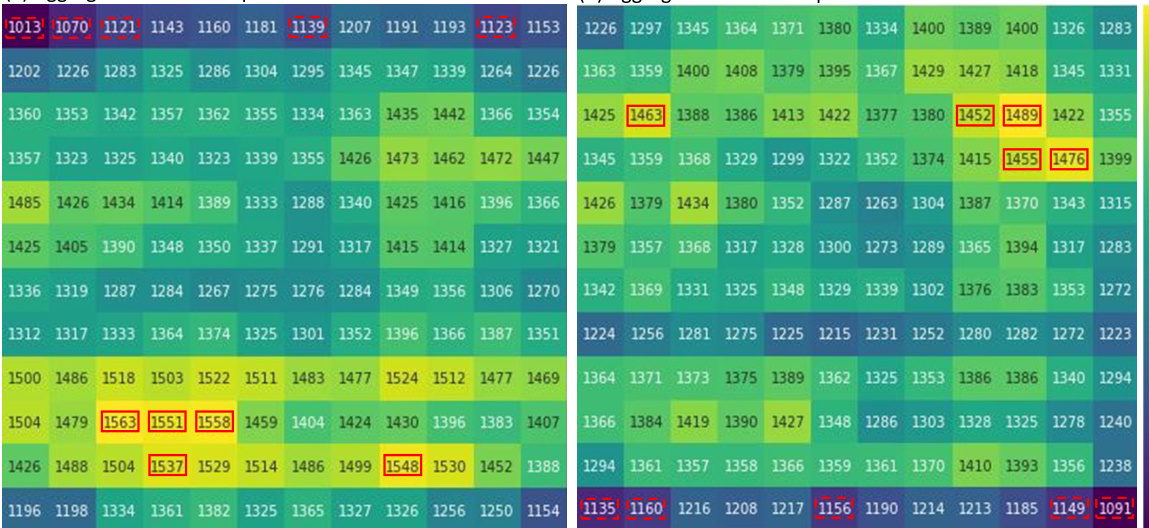
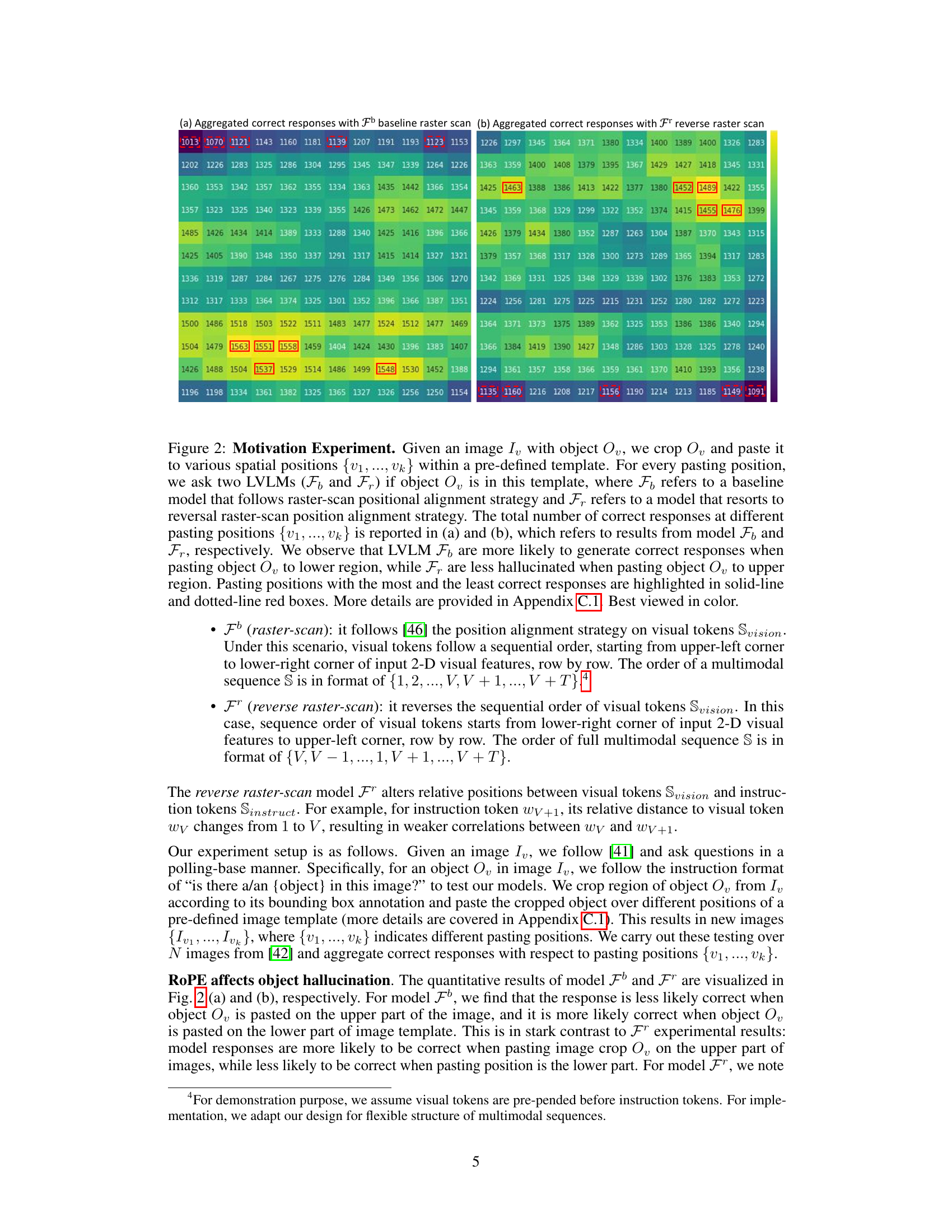
This figure presents a motivation experiment to show the impact of RoPE long-term decay on object hallucination in LVLMs. Two models, one using raster-scan positional alignment and the other using reverse raster-scan, are tested by pasting a cropped object to various positions on a template image. The results show a clear positional bias in the models’ accuracy, suggesting that RoPE’s long-term decay affects object hallucination in LVLMs.
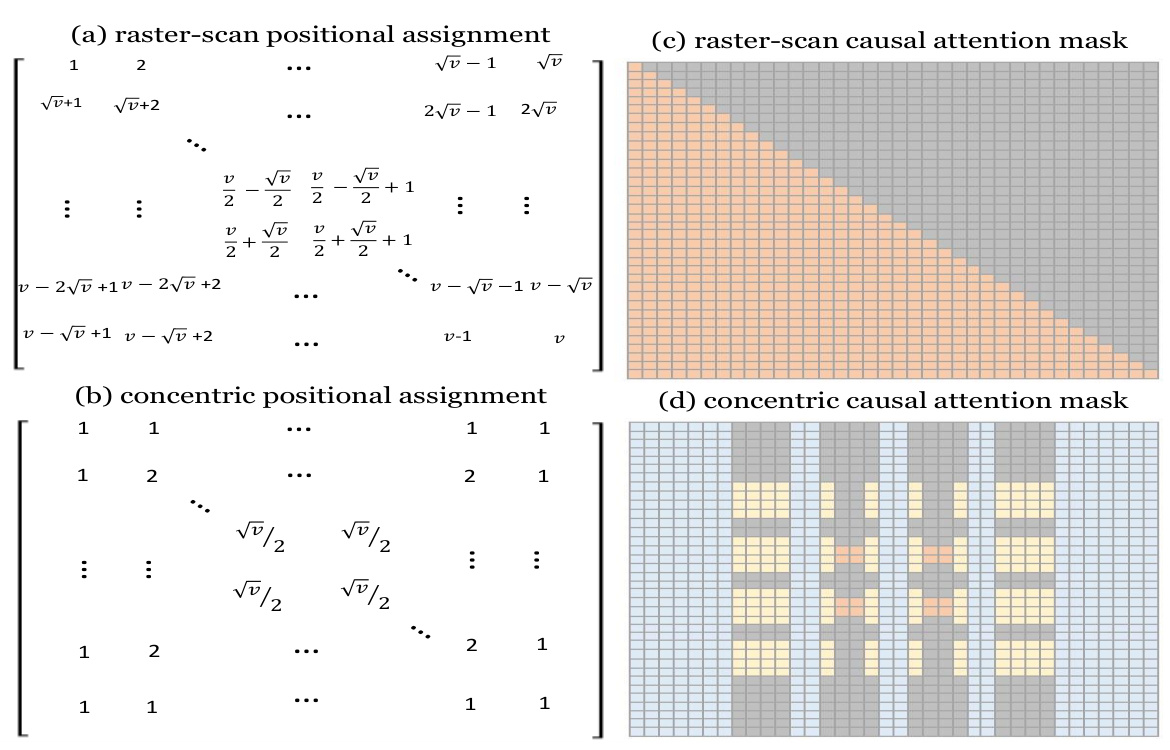
This figure illustrates the proposed Concentric Causal Attention (CCA) method. The left side shows how CCA re-organizes visual tokens in a concentric manner, reducing the distance between visual and instruction tokens compared to the traditional raster-scan approach. The right side demonstrates the CCA’s causal attention mask, which models 2D spatial relationships between visual tokens, unlike the traditional 1D causal mask.
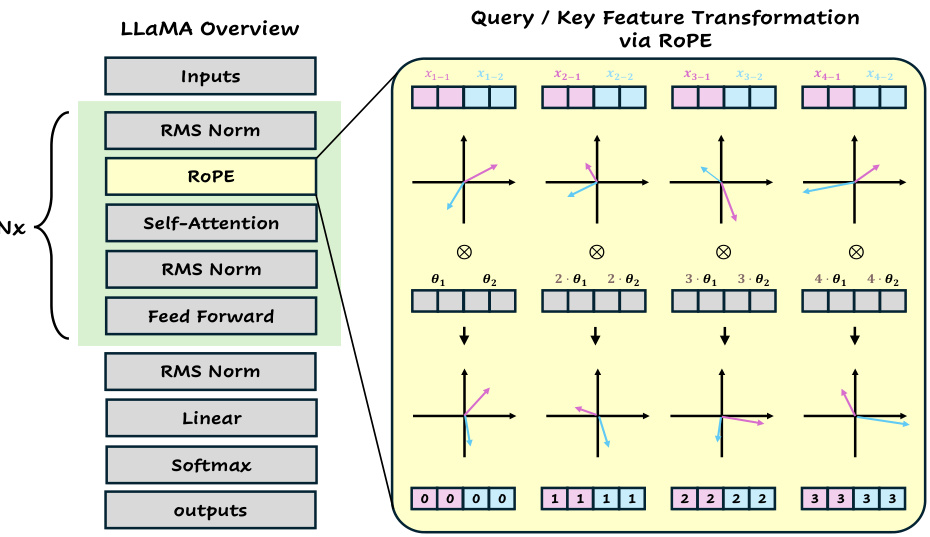
This figure shows how Rotary Position Encoding (RoPE) is implemented in the LLaMA architecture. It illustrates RoPE’s application to query and key features using a simplified example of a short input sequence. The schematic diagram demonstrates the integration of RoPE within the LLaMA layers. The detailed mathematical explanation is provided in Section 3 of the paper.

This figure illustrates the process of creating synthetic data for testing. An object is cropped from a real image and pasted onto a template image at various locations. This creates a dataset of images with the object at different positions, allowing for the evaluation of the model’s ability to detect objects at varying distances from instruction tokens.

This figure illustrates the core idea of the Concentric Causal Attention (CCA) method. The left side shows how CCA reorganizes the positions of visual tokens in a 2D concentric manner, reducing the distance between visual and instruction tokens compared to the traditional raster-scan approach. The right side depicts the modified causal attention mask that reflects this concentric arrangement, enabling visual tokens to interact with more relevant instruction tokens.

This figure shows an experiment designed to demonstrate the effect of positional alignment strategies on object hallucination in Large Vision-Language Models (LVLMs). Two models, one using a standard raster-scan alignment (Fb) and the other using a reversed raster-scan alignment (Fr), were tested. The experiment involved cropping an object from an image, pasting it into different locations within a template image, and then querying the models about the object’s presence. The results show that the models’ performance varies significantly depending on the object’s position and the alignment strategy used, highlighting the impact of long-term decay in RoPE on object hallucination.

This figure compares the image captioning results of the baseline LLaVA model and the CCA-LLaVA model. The input is an image of a pizza in a box with a bottle of beer on the side. The baseline model hallucinates a knife and a cup that are not present in the image. The CCA-LLaVA model produces a more accurate and less hallucinatory caption.

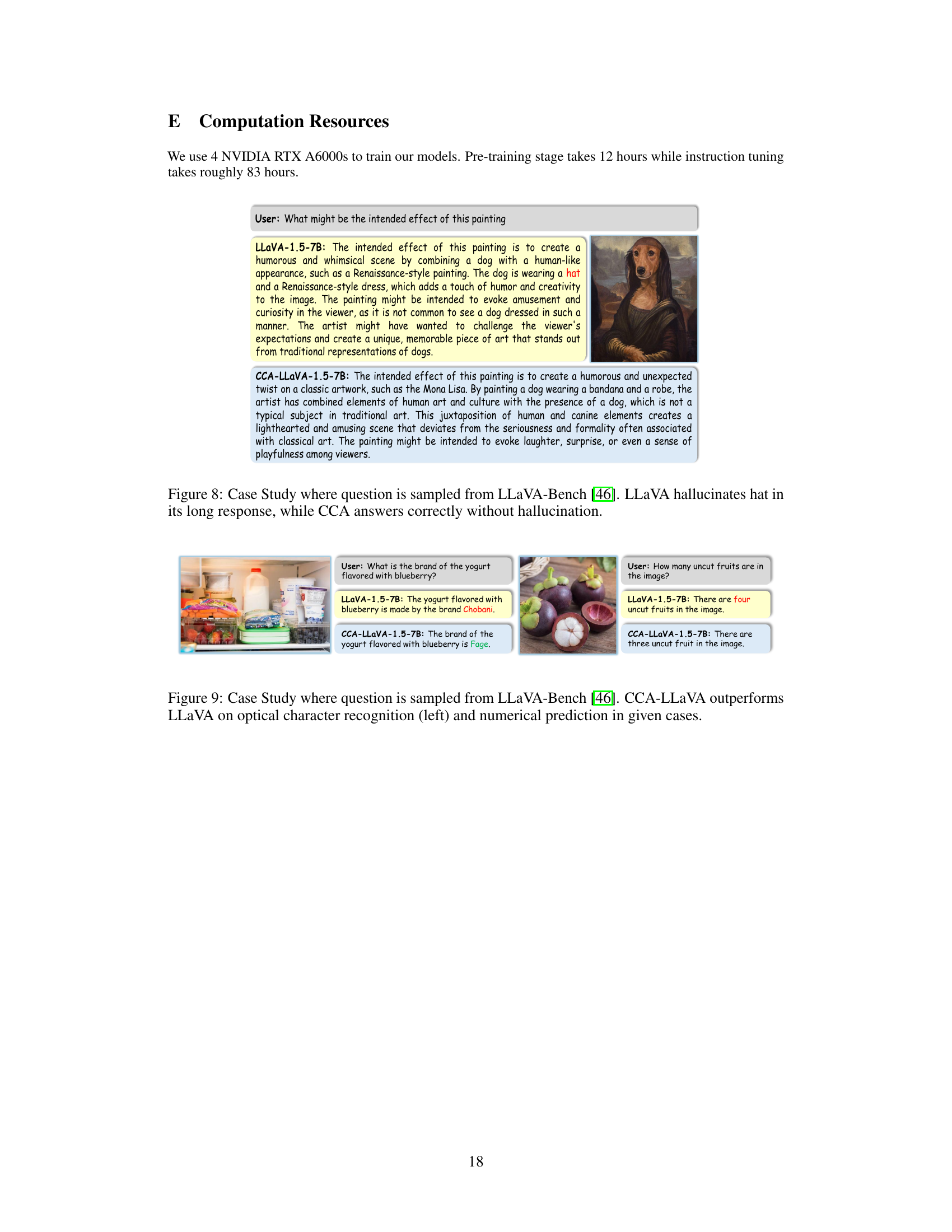
This figure presents a case study comparing the responses of the baseline LLaVA model and the CCA-LLaVA model to a question from the LLaVA-Bench dataset. The question asks about the intended effect of a painting depicting a dog in Renaissance-style clothing. The LLaVA response hallucinates details (mentions a hat which is not in the image), while the CCA-LLaVA response accurately describes the painting’s intent without hallucination, highlighting the improved factual accuracy of the CCA method.

This figure shows two examples where CCA-LLaVA outperforms the baseline LLaVA model in handling questions that require OCR and numerical reasoning. The left example involves identifying the brand of yogurt in an image, and the right example involves counting the number of uncut fruits. In both cases, CCA-LLaVA produces correct answers, while LLaVA generates incorrect answers showing the effectiveness of CCA in improving the model’s accuracy and reducing hallucinations.
More on tables
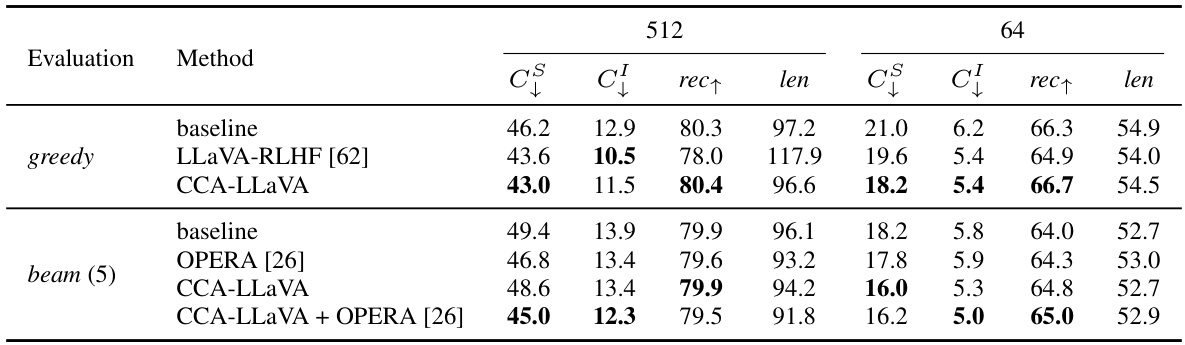
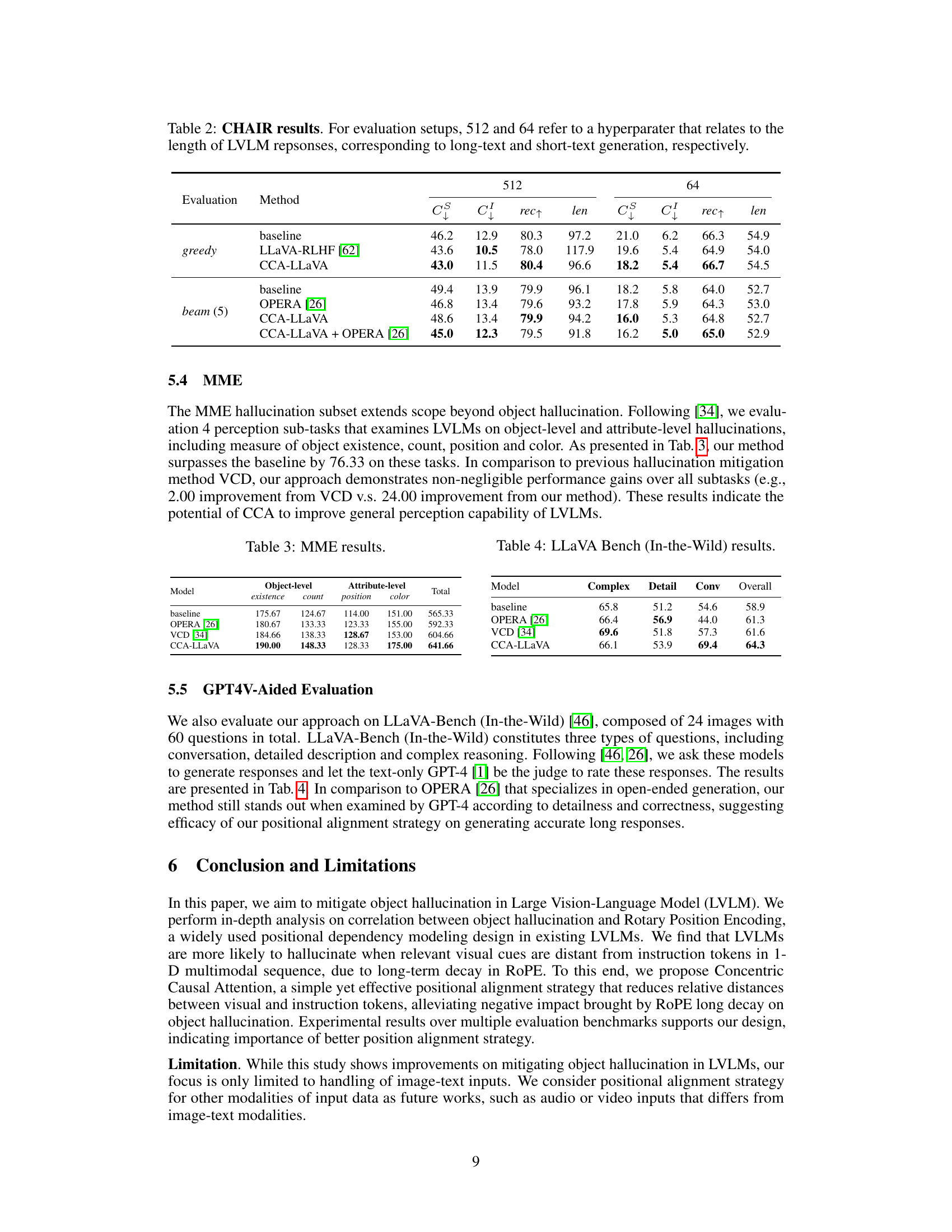
This table presents the results of the CHAIR (Caption Hallucination Assessment with Image Relevance) metric, which evaluates the factuality of image captions generated by different models. The evaluation is performed using two different text lengths (512 and 64 tokens) to examine hallucination in both short and long responses. The results are shown for both greedy and beam search decoding methods, and include comparisons with baseline and other approaches. The table shows that CCA-LLaVA consistently improves the accuracy of captions generated by mitigating object hallucination.
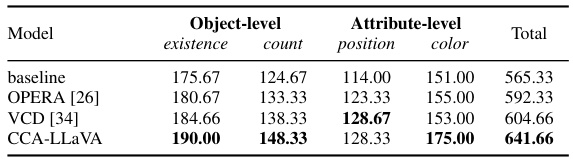
This table presents the results of the MME (Multimodal Hallucination Evaluation) benchmark. MME assesses four perception sub-tasks related to object hallucination: object existence, object count, object position, and object color, both at the object level and attribute level. The table compares the performance of the baseline LLaVA model against three other hallucination mitigation methods: OPERA, VCD, and CCA-LLaVA. The total score is the sum of the four sub-task scores. CCA-LLaVA shows significant improvement over the other methods, indicating its effectiveness in mitigating object-level and attribute-level hallucinations.
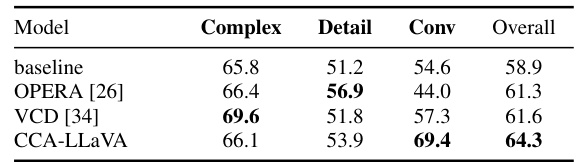
This table presents the results of evaluating the CCA-LLaVA model and other baselines on the LLaVA Bench (In-the-Wild) dataset. The LLaVA Bench is a benchmark for evaluating multimodal language models. The table shows the performance of each model on different aspects of the benchmark including complex, detail, conversation, and overall scores. The results illustrate CCA-LLaVA’s performance in comparison to other models like OPERA and VCD, highlighting its improvements in generating detailed and comprehensive responses.

This table presents the results of evaluating the proposed Concentric Causal Attention (CCA) method and several baseline methods on six different multiple-choice benchmarks that assess the general visual perception capabilities of Large Vision-Language Models (LVLMs). The benchmarks include SEED-Bench, ScienceQA, GQA, VizWiz, MMBench, and MMStar. The table compares the accuracy of CCA-LLaVA against LLaVA, LLaVA with VCD (a previous hallucination mitigation method), and two variants of SeVa. The results demonstrate the improvement in performance achieved by the CCA method across various benchmarks and evaluation dimensions.
Full paper#