TL;DR#
Few-shot font generation (FFG) aims to learn a target font style from limited reference glyphs and generate new glyphs. Existing methods attempt to disentangle content and style features, but this is challenging due to the complexity of glyphs and often produces artifacts. This often results in generated glyphs influenced by the source glyph’s style. This paper introduces IF-Font, a novel method that abandons the style-content disentanglement paradigm.
IF-Font utilizes Ideographic Description Sequences (IDS) instead of source glyphs to control the semantics of generated glyphs. It quantizes reference glyphs into tokens and models the token distribution of target glyphs using corresponding IDS and reference tokens. Extensive experiments demonstrate IF-Font significantly outperforms state-of-the-art methods in both one-shot and few-shot settings, especially when the target style differs significantly from the training font styles. The ability to generate new glyphs based on user-provided IDS is a key advantage, enhancing the method’s flexibility and potential.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel font generation paradigm that significantly outperforms current state-of-the-art methods, particularly when dealing with styles significantly different from the training data. It offers a new way to approach font generation by using Ideographic Description Sequences (IDS) which enables the creation of novel glyphs and high-quality results, opening new avenues of research in font generation and potentially cross-linguistic applications.
Visual Insights#

🔼 This figure compares two different approaches to font generation. The left side shows the traditional style-content disentangling method, which separates a glyph’s content and style features. The right side illustrates the proposed IF-Font method, which uses an autoregressive model to predict target tokens based on the Ideographic Description Sequence (IDS) and reference glyphs, then decodes these tokens to generate the final glyph. The key difference highlighted is the use of IDS instead of relying on source glyph content disentanglement, which is prone to artifacts.
read the caption
Figure 1: Comparison of two font generation paradigms. Left: The style-content disentangling paradigm. It assumes that a glyph can be decomposed into two distinct attributes: content and style. Right: The proposed paradigm. We first autoregressively predict the target tokens and decode them with a VQ decoder. Orange boxes show the main difference between the two paradigms.
🔼 This table presents a quantitative comparison of different font generation methods on two datasets: UFSC (Unseen Fonts and Seen Characters) and UFUC (Unseen Fonts and Unseen Characters). The evaluation metrics include FID (Fréchet Inception Distance), L1 loss, LPIPS (Learned Perceptual Image Patch Similarity), RMSE (Root Mean Squared Error), and SSIM (Structural Similarity Index). The results are shown for 1-shot, 3-shot, and 8-shot settings (meaning 1, 3, and 8 reference glyphs were used for generation). A user study was also conducted to assess the subjective quality of the generated fonts. Bold and underlined values highlight the top two-performing methods for each metric.
read the caption
Table 2: Quantitative evaluation on UFSC and UFUC dataset. 'User' indicates user study, the samples are generated under 3-shot setting. Bold and underlined numbers denote the best and the second best respectively. Please refer to Fig. 10 in Appendix for the corresponding radar plots.
In-depth insights#
Ideographic Font Gen#
Ideographic font generation presents a unique challenge in the field of font synthesis due to the complex nature of ideographic characters. Unlike alphabetic characters, ideographs possess intricate structural components and semantic nuances that must be carefully considered during generation. Successful methods must effectively disentangle content and style features, allowing for the creation of new glyphs while preserving the intended visual characteristics. Existing approaches often struggle with this disentanglement, leading to artifacts and inconsistencies in generated glyphs. A promising direction involves leveraging ideographic description sequences (IDS) to represent the semantic content of characters, providing a structured and style-neutral input for the generative model. This approach allows the model to focus on synthesizing the visual style without being influenced by potentially conflicting stylistic elements from source glyphs. Furthermore, the use of vector quantized generative models offers a potential advantage by representing glyphs as discrete tokens, reducing the complexity of the generation process and enabling higher-quality outputs. However, challenges remain in handling a large number of characters and maintaining consistency across various styles, and further research is needed to address these challenges and improve the efficiency of these models.
IDS-Based Synthesis#
An IDS-Based Synthesis approach in a research paper would likely focus on generating complex structures using a sequence-based representation. The core idea revolves around utilizing Ideographic Description Sequences (IDS) as a symbolic encoding of the target structure, enabling precise control over the generation process. This method offers advantages over traditional pixel-based or feature-based approaches by providing a higher-level, semantic representation. Instead of manipulating low-level visual features, the system directly works with the abstract description, allowing for a more accurate and efficient synthesis. The IDS acts as a blueprint, guiding the generation process towards the desired form. A key challenge lies in designing an appropriate model architecture capable of interpreting the IDS and translating it into a concrete representation, be it a vector graphic or a raster image. This likely involves advanced techniques like recurrent neural networks or transformers to process the sequential nature of the IDS. The success of such an approach depends on the completeness and consistency of the IDS system used. An incomplete or ambiguous IDS would lead to errors or artifacts during synthesis. Evaluation of this method would necessitate comparing the generated structures against ground truth, measuring metrics such as accuracy, fidelity, and efficiency. Furthermore, the scalability and generalizability of the system must be assessed, examining its ability to handle a wide range of complex structures and different styles.
Style-Content Fusion#
Style-content fusion in font generation aims to disentangle stylistic and semantic features of glyphs, enabling the creation of new glyphs with desired styles while preserving their original character. This approach involves representing glyphs as a combination of content features (shape, structure) and style features (stroke thickness, curves). Successful disentanglement is crucial for generating high-quality fonts, as it avoids artifacts and ensures that the generated glyphs maintain both semantic accuracy and stylistic consistency. However, the complexity of glyphs makes complete disentanglement challenging, leading to compromises between semantic accuracy and stylistic fidelity. A key challenge lies in defining appropriate representations for both content and style. Various methods exist, employing different techniques like variational autoencoders (VAEs), generative adversarial networks (GANs), and diffusion models, each with strengths and weaknesses. Despite challenges, style-content fusion represents a significant advancement in font generation, enabling creative control and efficiency in producing new font styles from limited training data. Future research should explore more sophisticated disentanglement methods and investigate the use of auxiliary information (e.g., semantic descriptions) to enhance both the accuracy and creativity of style-content fusion approaches.
VQGAN Decoder#
A VQGAN decoder is a crucial component in vector-quantized generative models, tasked with reconstructing high-fidelity images from quantized latent representations. Its core function involves taking the indices generated by the encoder (representing the closest codebook vectors) and utilizing these indices to access the corresponding vectors within a learned codebook. The decoder’s architecture is designed to learn complex mappings between these discrete latent codes and the continuous pixel space of images, effectively reversing the quantization process. This process involves sophisticated techniques like transformer-based architectures or autoregressive models to capture and reconstruct the intricate details and textures lost during quantization. Performance is critically dependent on the quality and size of the codebook; a larger codebook allows for finer-grained representations but significantly increases computational complexity. Further advancements in VQGAN decoder architectures might include exploring more efficient attention mechanisms or developing innovative methods to handle the inherent limitations of discrete latent representations, leading to improved image generation quality and reduced computational overhead. The ability to generate high-resolution images with fine detail is a testament to the decoder’s effectiveness in capturing and reconstructing image information from a compressed latent space.
Few-Shot Learning#
Few-shot learning (FSL) aims to address the challenge of training machine learning models with limited labeled data. The core idea is to leverage prior knowledge and effective data augmentation techniques to improve model generalization capabilities. This is particularly relevant in domains where obtaining large labeled datasets is expensive, time-consuming, or impractical. Several approaches exist, including meta-learning, which focuses on learning to learn, enabling fast adaptation to new tasks with limited examples; data augmentation, which artificially expands the training dataset to enhance model robustness; and transfer learning, where knowledge from related, data-rich tasks is transferred to the target task. The success of FSL hinges on choosing appropriate algorithms that can effectively exploit the limited data while avoiding overfitting and ensuring generalizability. However, a crucial limitation is the inherent difficulty of reliably evaluating the generalization performance of FSL models. Due to the scarcity of data, standard evaluation metrics may not accurately reflect the true performance on unseen data. Ongoing research focuses on improving FSL techniques, developing more robust evaluation strategies, and exploring novel applications in areas such as computer vision and natural language processing.
More visual insights#
More on figures

🔼 This figure presents a detailed overview of the IF-Font model’s architecture, which is composed of three main modules: IDS Hierarchical Analysis (IHA), Structure-Style Aggregation (SSA), and a decoder. The IHA module processes the input target character to extract its Ideographic Description Sequence (IDS). The SSA module takes the reference characters and their corresponding glyph images as input, extracts style features, and aggregates them based on the similarity between the target character’s IDS and the reference characters’ IDSs. Finally, the decoder uses both semantic and style features to generate the target glyph using a VQGAN decoder.
read the caption
Figure 2: Overview of our proposed method. The overall framework mainly consists of three parts: IDS Hierarchical Analysis module E₁, Structure-Style Aggregation block E₂, and a decoder D.
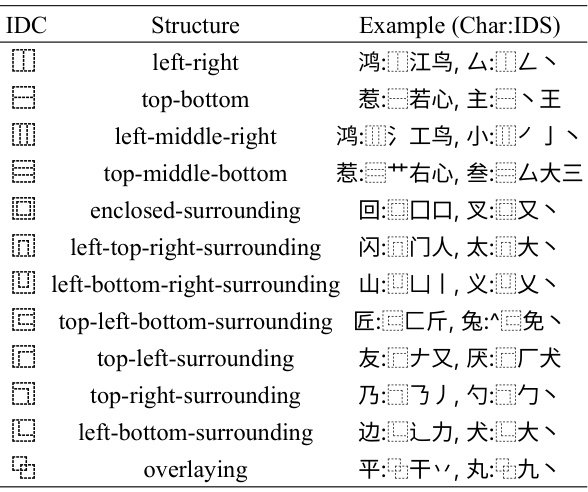
🔼 This figure shows that a single Chinese character can have multiple equivalent Ideographic Description Sequences (IDS). The figure illustrates this by showing three different but equivalent IDS representations for the characters ‘树’ (tree) and ‘克’ (gram). Each representation uses different component characters, but all result in the same meaning. This demonstrates the flexibility and redundancy inherent in IDS representations, a key aspect of the IF-Font model’s ability to generate glyphs from diverse structural inputs.
read the caption
Figure 3: The illustration of equivalent IDSs.

🔼 This figure shows the fusion module (Efuse) within the Structure-Style Aggregation (SSA) block. It illustrates how the global and local style features are aggregated. The global style features (fsg) are generated by merging the coarse style features (Fr) with similarity weights (Sim). The local style features (fsl) are obtained through cross-attention, focusing on finer details like stroke length and direction based on the target character’s semantic features (ft). The final style feature (fr) is the combination of these local and global features.
read the caption
Figure 4: The illustration of the fusion module Efuse of SSA block.
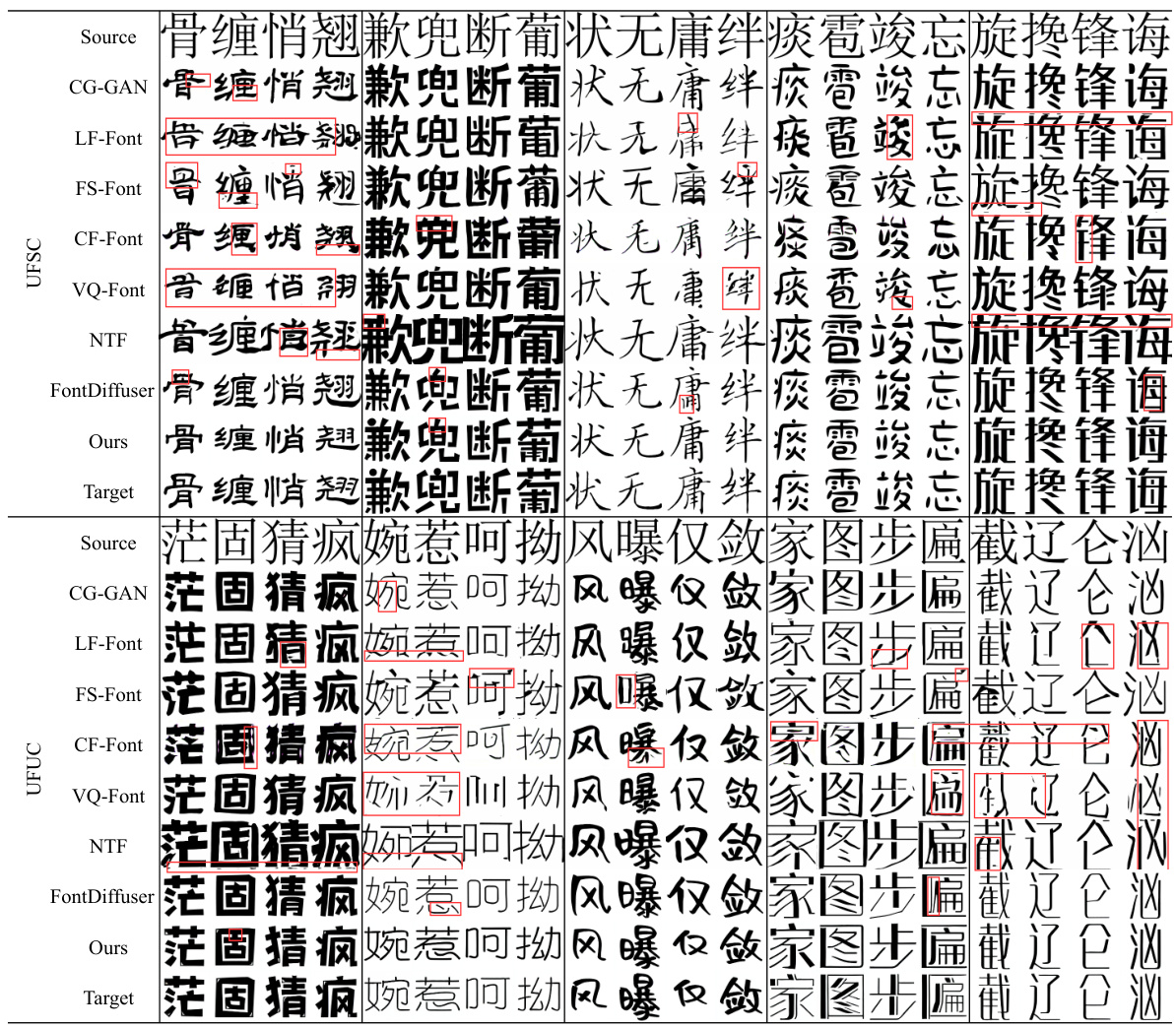
🔼 This figure compares the qualitative results of IF-Font against other state-of-the-art methods on two test datasets, UFSC and UFUC. The figure shows several Chinese characters generated by each method, highlighting artifacts like missing strokes or blurred parts with red boxes. Notably, it emphasizes that IF-Font uses only the Ideographic Description Sequence (IDS) for each character, unlike other methods which also use a source glyph.
read the caption
Figure 5: Qualitative comparison with state-of-the-art methods, in which red boxes outline the artifacts. 'Source' denotes the content glyph of other methods, IF-Font only employs the corresponding IDS.

🔼 This figure visualizes the attention mechanism in the Structure-Style Aggregation (SSA) block of the IF-Font model. It shows how the model attends to different parts of reference glyphs based on the input Ideographic Description Sequence (IDS). The top row shows the target character and the corresponding IDS components. Each column represents a reference glyph from the dataset. The orange highlights on the reference glyphs indicate the regions that receive the most attention from a specific part of the IDS. This visualization demonstrates that IF-Font effectively uses the IDS to guide the style extraction process, focusing attention on relevant stylistic features of the reference glyphs.
read the caption
Figure 7: Visualization of attention maps between IDS and reference glyphs. The symbols above are the target character (black) and the corresponding IDS (orange).

🔼 This figure presents a comparison of IF-Font’s performance against other state-of-the-art methods across three different few-shot settings (1-shot, 3-shot, 8-shot). The evaluation metrics used are FID, SSIM, L1, LPIPS, and RMSE, calculated on two datasets (UFSC and UFUC). The radar charts visually represent the performance of each method across these metrics in each setting, showcasing IF-Font’s superior performance.
read the caption
Figure 10: Compared with the methods based on the content-style disentanglement paradigm, IF-Font achieves state-of-the-art performance on all metrics under three few-shot settings. The metrics are annotated with brackets in the figure to specify the dataset used for evaluation: (S) represents UFSC, and (U) refers to UFUC. (a) 1-shot setting. (b) 3-shot setting. (c) 8-shot setting.

🔼 This figure provides a qualitative comparison of the proposed IF-Font method against seven state-of-the-art (SOTA) methods for font generation. The comparison is shown for two sets of Chinese characters. Red boxes highlight artifacts or errors produced by the other methods, demonstrating that IF-Font produces clearer and more style-consistent results. The ‘Source’ column indicates that other methods rely on a source glyph (as input), while IF-Font only uses the Ideographic Description Sequence (IDS) to generate its glyphs.
read the caption
Figure 5: Qualitative comparison with state-of-the-art methods, in which red boxes outline the artifacts. 'Source' denotes the content glyph of other methods, IF-Font only employs the corresponding IDS.
More on tables

🔼 This table presents a quantitative comparison of different font generation methods on two test datasets: UFSC (Unseen Fonts, Seen Characters) and UFUC (Unseen Fonts, Unseen Characters). The methods are evaluated using several metrics: FID (Fréchet Inception Distance), L1 distance, LPIPS (Learned Perceptual Image Patch Similarity), RMSE (Root Mean Squared Error), and SSIM (Structural Similarity Index). The table also includes the results of a user study to assess the subjective quality of the generated fonts. Results are shown for one-shot, three-shot, and eight-shot settings, reflecting the number of reference glyphs used for training. Bold and underlined numbers highlight the top two performing methods for each metric.
read the caption
Table 2: Quantitative evaluation on UFSC and UFUC dataset. 'User' indicates user study, the samples are generated under 3-shot setting. Bold and underlined numbers denote the best and the second best respectively. Please refer to Fig. 10 in Appendix for the corresponding radar plots.
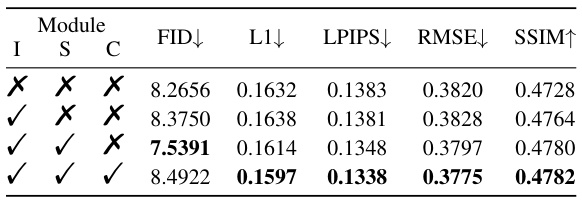
🔼 This table presents the ablation study results for the proposed IF-Font model. It shows the impact of each module (IHA, SSA, and SCE) on the overall performance, measured by FID, L1, LPIPS, RMSE, and SSIM. The baseline model is the model without any of the three modules, and each subsequent row adds one more module to the baseline.
read the caption
Table 3: Ablation studies on different modules. The first row is the results of baseline. I, S and C represent IHA, SSA, and SCE respectively.

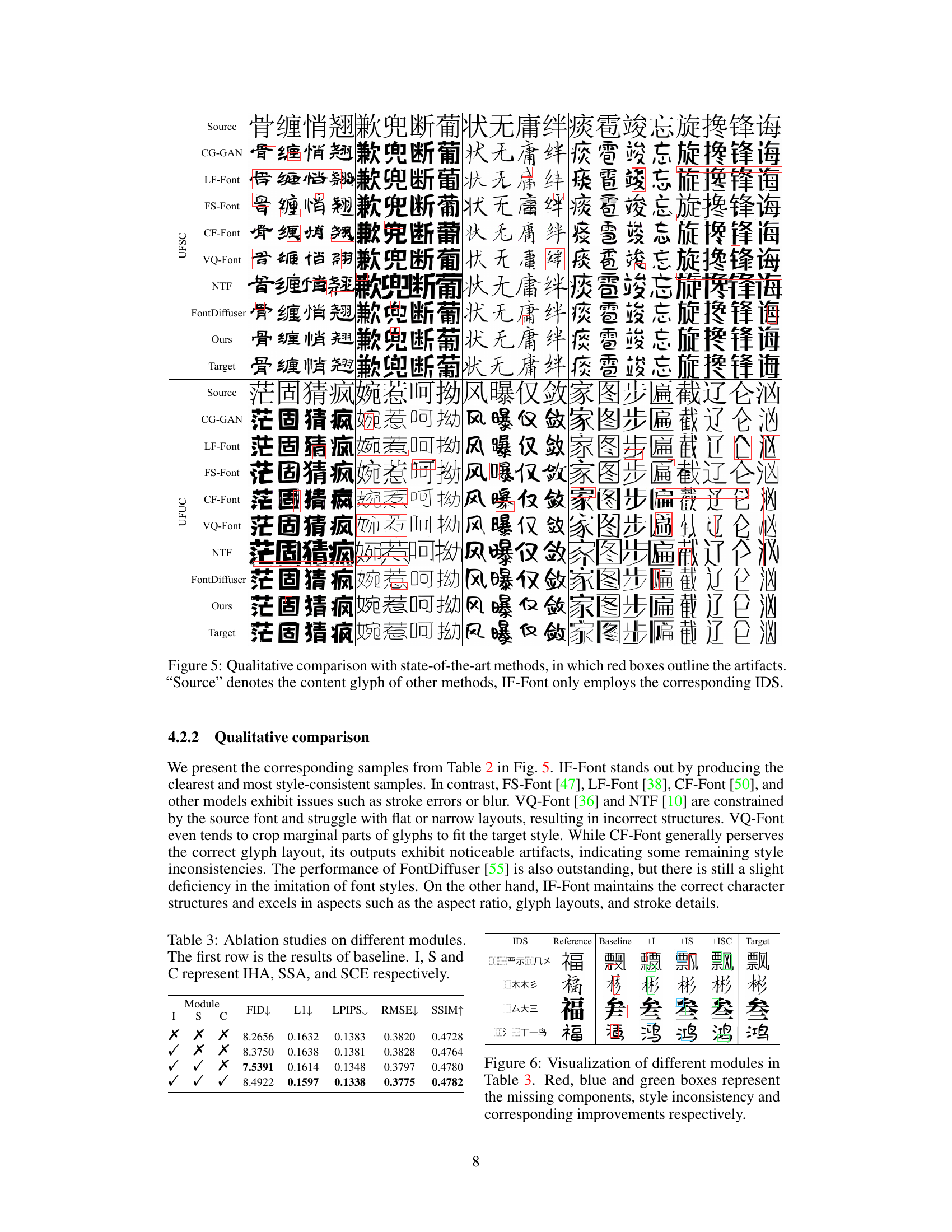
🔼 This table presents a quantitative evaluation of the impact of different levels of granularity in Ideographic Description Sequences (IDS) on the performance of the IF-Font model. Three levels of granularity are compared: Component, Stroke, and Mixed. The performance is measured across several metrics, including FID, L1, LPIPS, RMSE, and SSIM, providing a comprehensive assessment of the model’s effectiveness under varied IDS representations.
read the caption
Table 4: The impact of IDS granularity on performance.

🔼 This table presents a quantitative evaluation of the impact of different Ideographic Description Sequence (IDS) granularities on the performance of the IF-Font model. Three granularities are compared: Component, Stroke, and Mixed. The evaluation metrics used are FID (Fréchet Inception Distance), L1 distance, LPIPS (Learned Perceptual Image Patch Similarity), RMSE (Root Mean Squared Error), and SSIM (Structural Similarity Index). Lower FID, L1, LPIPS, and RMSE values indicate better performance, while a higher SSIM value indicates better performance. The results show that the ‘Stroke’ granularity achieves the best performance based on the metrics used.
read the caption
Table 4: The impact of IDS granularity on performance.

🔼 This table presents a quantitative comparison of different font generation methods on two test datasets (UFSC and UFUC) using several metrics (FID, L1, LPIPS, RMSE, SSIM). The results are shown for different numbers of reference glyphs (1-shot, 3-shot, and 8-shot), along with the results of a user study. Bold and underlined numbers highlight the best and second-best performing methods for each metric.
read the caption
Table 2: Quantitative evaluation on UFSC and UFUC dataset. 'User' indicates user study, the samples are generated under 3-shot setting. Bold and underlined numbers denote the best and the second best respectively. Please refer to Fig. 10 in Appendix for the corresponding radar plots.

🔼 This table presents a quantitative comparison of different font generation methods on two test datasets (UFSC and UFUC) using various metrics such as FID, L1, LPIPS, RMSE, and SSIM. It also includes the results of a user study to assess the subjective quality of the generated fonts. The results are shown for one-shot, three-shot and eight-shot settings, highlighting the performance of each method across different scenarios.
read the caption
Table 2: Quantitative evaluation on UFSC and UFUC dataset. 'User' indicates user study, the samples are generated under 3-shot setting. Bold and underlined numbers denote the best and the second best respectively. Please refer to Fig. 10 in Appendix for the corresponding radar plots.
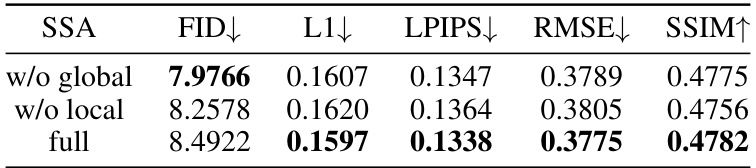
🔼 This table presents the ablation study results focusing on the two branches of the SSA (Structure-Style Aggregation) block. It compares the performance of the model with the full SSA block against versions where either the global or local branch is removed. The metrics used for comparison include FID (Fréchet Inception Distance), L1 distance, LPIPS (Learned Perceptual Image Patch Similarity), RMSE (Root Mean Squared Error), and SSIM (Structural Similarity Index). Lower values for FID, L1, LPIPS, and RMSE indicate better performance, while a higher SSIM value suggests better visual similarity.
read the caption
Table 6: Ablation studies on both branches of SSA.

🔼 This table presents a quantitative comparison of different font generation methods on two test datasets (UFSC and UFUC) using several evaluation metrics including FID, L1, LPIPS, RMSE, and SSIM. It also includes the results of a user study to assess the aesthetic quality of the generated fonts. The results are shown for one-shot, three-shot, and eight-shot scenarios, with the best and second-best results highlighted.
read the caption
Table 2: Quantitative evaluation on UFSC and UFUC dataset. 'User' indicates user study, the samples are generated under 3-shot setting. Bold and underlined numbers denote the best and the second best respectively. Please refer to Fig. 10 in Appendix for the corresponding radar plots.
Full paper#