TL;DR#
Training high-performing Binary Neural Networks (BNNs) is challenging due to their discrete nature and the limitations of traditional optimization methods. Current approaches often rely on heuristics like the straight-through estimator (STE), which lack theoretical justification. This leads to accuracy loss compared to their high-precision counterparts, hindering their widespread deployment on resource-constrained devices.
This research introduces VISPA, a novel training framework that uses Gaussian variational inference to address these issues. VISPA tackles BNN training by solving low-rank semidefinite programs (SDPs), which explicitly model correlations between weights, unlike previous methods. This leads to improved accuracy across different datasets, significantly outperforming existing methods. The approach also provides theoretical support for the use of latent weights and STE, improving upon the heuristic nature of previous approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly improves the training of Binary Neural Networks (BNNs), a critical area for deploying deep learning on resource-constrained devices. The novel approach addresses longstanding challenges in BNN training, paving the way for more efficient and accurate AI applications in various domains.
Visual Insights#

🔼 This table compares the performance of various methods on the CIFAR-10 dataset using two different network architectures: VGG-Small and ResNet18. All methods use binarized activations and weights. The table shows the testing accuracy achieved by each method, providing a quantitative comparison of their effectiveness.
read the caption
Table 1: Performance comparison by testing accuracy (%) on CIFAR-10 using VGG-Small and ResNet18 architectures with binarized activations and weights.
In-depth insights#
BNN Training Gaps#
Binary Neural Networks (BNNs) offer significant computational advantages due to their binary weights and activations, enabling efficient deployment on resource-constrained devices. However, training BNNs effectively remains a major challenge. Traditional gradient-based methods struggle with the inherent non-convexity and discrete nature of the BNN weight space. The commonly used Straight-Through Estimator (STE) and latent weights, while empirically successful, lack strong theoretical justification. The gap lies in finding an optimization framework that effectively bridges the continuous optimization landscape of standard gradient methods with the discrete BNN weight space. This requires a robust approach capable of handling the combinatorial nature of BNN training while offering theoretical guarantees. Current approaches often lead to significant accuracy loss compared to their full-precision counterparts. The development of improved theoretical understanding and novel optimization algorithms that mitigate these limitations is crucial for wider adoption of BNNs.
Gaussian VI Inference#
Gaussian Variational Inference (VI) offers a powerful technique for approximating intractable posterior distributions in complex models. Applying Gaussian VI to Binary Neural Networks (BNNs) is particularly insightful because the binary nature of weights creates a discrete, high-dimensional space challenging for standard optimization methods. The core idea is to represent the discrete binary weights with a continuous latent variable following a Gaussian distribution. This allows the use of gradient-based optimization, but the connection between the continuous latent variable and the discrete binary weights needs careful handling. The framework leverages the mean of the Gaussian distribution as a natural choice for the latent weight and justifies the commonly used Straight-Through Estimator (STE) to approximate the gradients. A key innovation extends this to model correlations between weights via the covariance matrix of the Gaussian, improving accuracy. Low-rank approximations to the covariance matrix are crucial for scalability, efficiently capturing the most important pairwise interactions. The framework transforms a challenging combinatorial optimization problem into a tractable, albeit non-convex, semidefinite program. This approach provides a more principled foundation for understanding the success of latent variable methods for training BNNs, and empirically outperforms state-of-the-art techniques.
Low-Rank SDP Relax#
The heading ‘Low-Rank SDP Relax’ suggests a methodological approach within an optimization framework, likely concerning semidefinite programming (SDP). Low-rank indicates a constraint or approximation to reduce computational complexity, making the method scalable for large-scale problems. This is crucial as full-rank SDPs often become intractable with increasing dimensionality. The term SDP relax implies that the method addresses a complex optimization problem, possibly non-convex or combinatorial, by relaxing the problem into a more tractable SDP. This relaxation provides a lower bound on the optimal value of the original problem. By cleverly constraining the rank of the SDP solution, it balances accuracy and computational efficiency. The authors are likely leveraging this technique to gain improved performance in training binary neural networks (BNNs). This approach is advantageous because it is well-suited to handle situations involving binary variables or constraints, common in BNN training. The overall strategy is to frame a difficult BNN training problem as an SDP, simplifying the solution by reducing the rank, allowing for a balance between optimization accuracy and practical solvability.
VISPA Algorithm#
The VISPA algorithm, a novel approach for training Binary Neural Networks (BNNs), is presented as a solution to the longstanding challenge of efficiently training high-performing BNNs. VISPA leverages Gaussian variational inference, framing the problem as learning an optimal Gaussian distribution over weights. This allows for the explicit modeling of pairwise correlations between weights, which are often ignored in previous methods. Unlike many BNN training techniques that rely on heuristics like the straight-through estimator (STE), VISPA provides a theoretically sound framework that naturally incorporates the STE and weight clipping. A key innovation is the use of low-rank semidefinite programming (SDP) relaxations, addressing the computational complexity of dealing with large covariance matrices. By focusing on low-rank approximations, VISPA remains computationally tractable while capturing crucial weight dependencies. Empirical results demonstrate that VISPA consistently outperforms current state-of-the-art methods across various benchmark datasets. The ability to model weight correlations provides a significant advantage, particularly in complex datasets, improving accuracy, stability, and efficiency in BNN training. The algorithm combines the strength of variational inference with the power of SDP, providing a robust and effective approach to address the unique optimization challenges posed by BNNs.
Future BNN Research#
Future research in Binary Neural Networks (BNNs) should prioritize addressing the limitations of current training methods. Improving the theoretical understanding of the Straight-Through Estimator (STE) and developing alternative, more principled training approaches are crucial. Exploring advanced optimization techniques, such as those based on Gaussian variational inference and low-rank semidefinite programming, holds promise for achieving better accuracy. Furthermore, research should focus on developing more effective architectures specifically tailored for BNNs, moving beyond simple binarization of existing network designs. Investigating novel quantization schemes and exploring the potential of BNNs in resource-constrained environments will greatly expand their applicability. Finally, a concerted effort to establish standardized benchmarks and datasets is needed to ensure fair and meaningful comparisons across different BNN methods, facilitating future research progress.
More visual insights#
More on tables
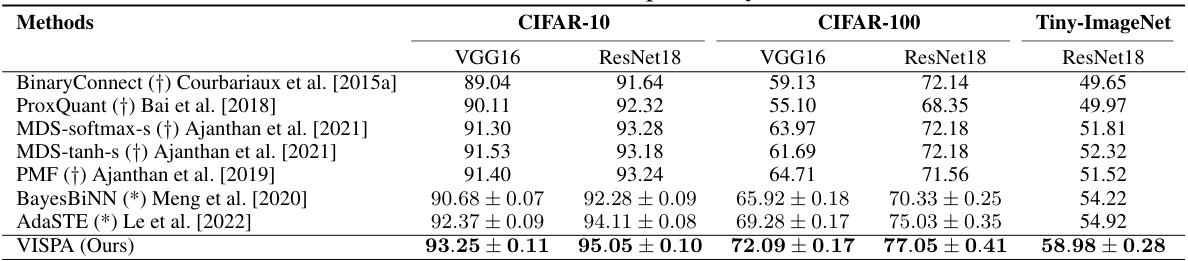
🔼 This table compares the performance of different BNN training methods on three benchmark datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) using two different network architectures (VGG16 and ResNet18). The methods are evaluated based on their testing accuracy. The table highlights the superior performance of the proposed VISPA method compared to existing state-of-the-art techniques, particularly on more complex datasets like CIFAR-100 and Tiny-ImageNet.
read the caption
Table 2: Performance comparison by testing accuracy (%) of various approaches on CIFAR-10, CIFAR-100, and Tiny-ImageNet across VGG16 and ResNet18 architectures with binarized weights only. (†) indicates that results are obtained from the numbers reported by Ajanthan et al. [2021]. (*) indicates that results are obtained from the numbers reported by Le et al. [2022].
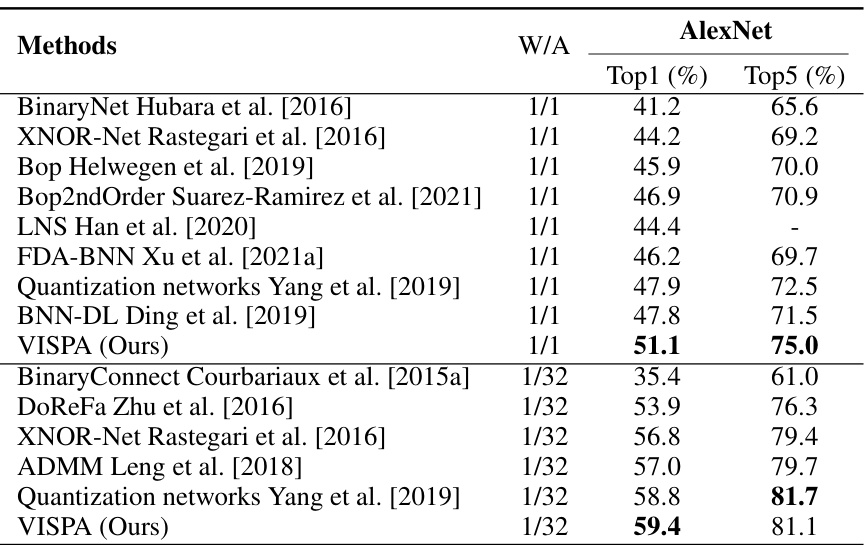
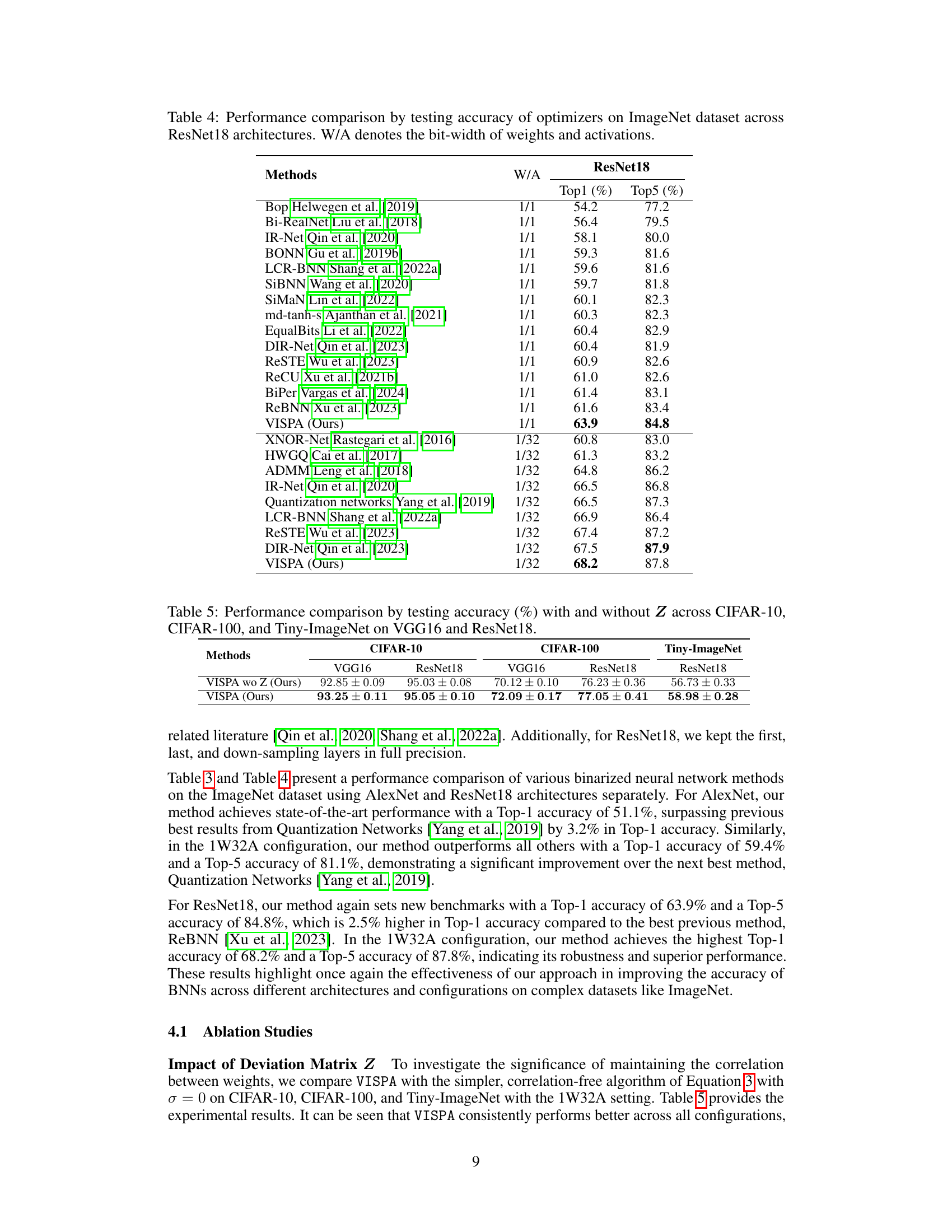
🔼 This table compares the performance of different methods for training binarized neural networks on the ImageNet dataset using the AlexNet architecture. The comparison includes methods that use 1-bit weights and activations (W/A 1/1) and methods that use 1-bit weights and 32-bit activations (W/A 1/32). The table shows the Top-1 and Top-5 accuracy for each method. The results highlight the performance of the proposed VISPA method in comparison to state-of-the-art approaches.
read the caption
Table 3: Performance comparison by testing accuracy of various methods on ImageNet dataset at AlexNet. W/A denotes the bit-width of weights and activations.
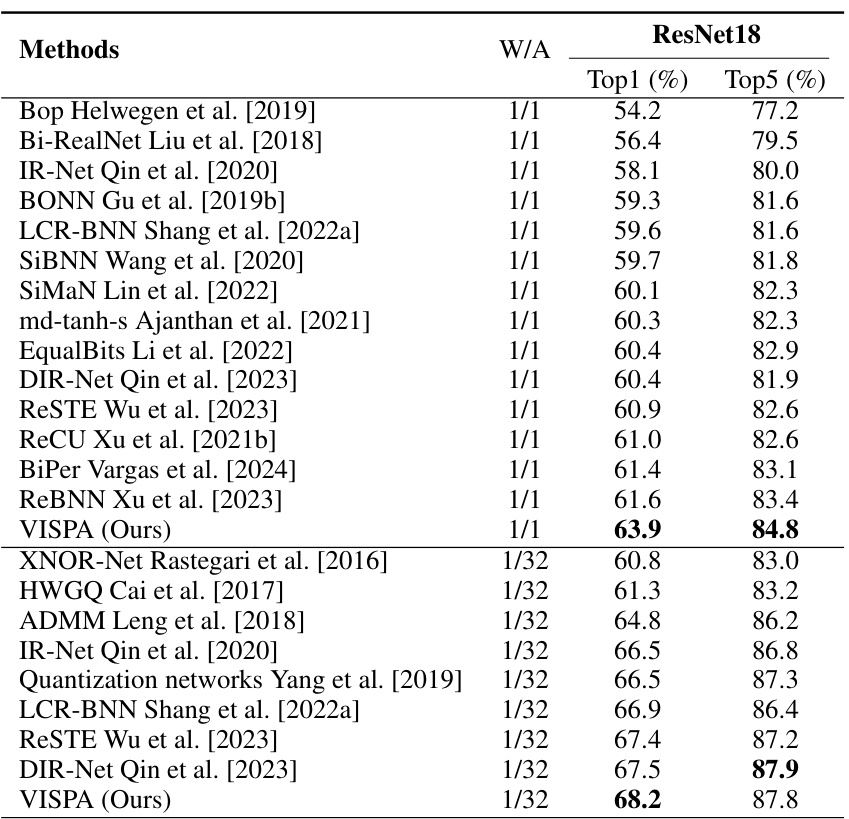
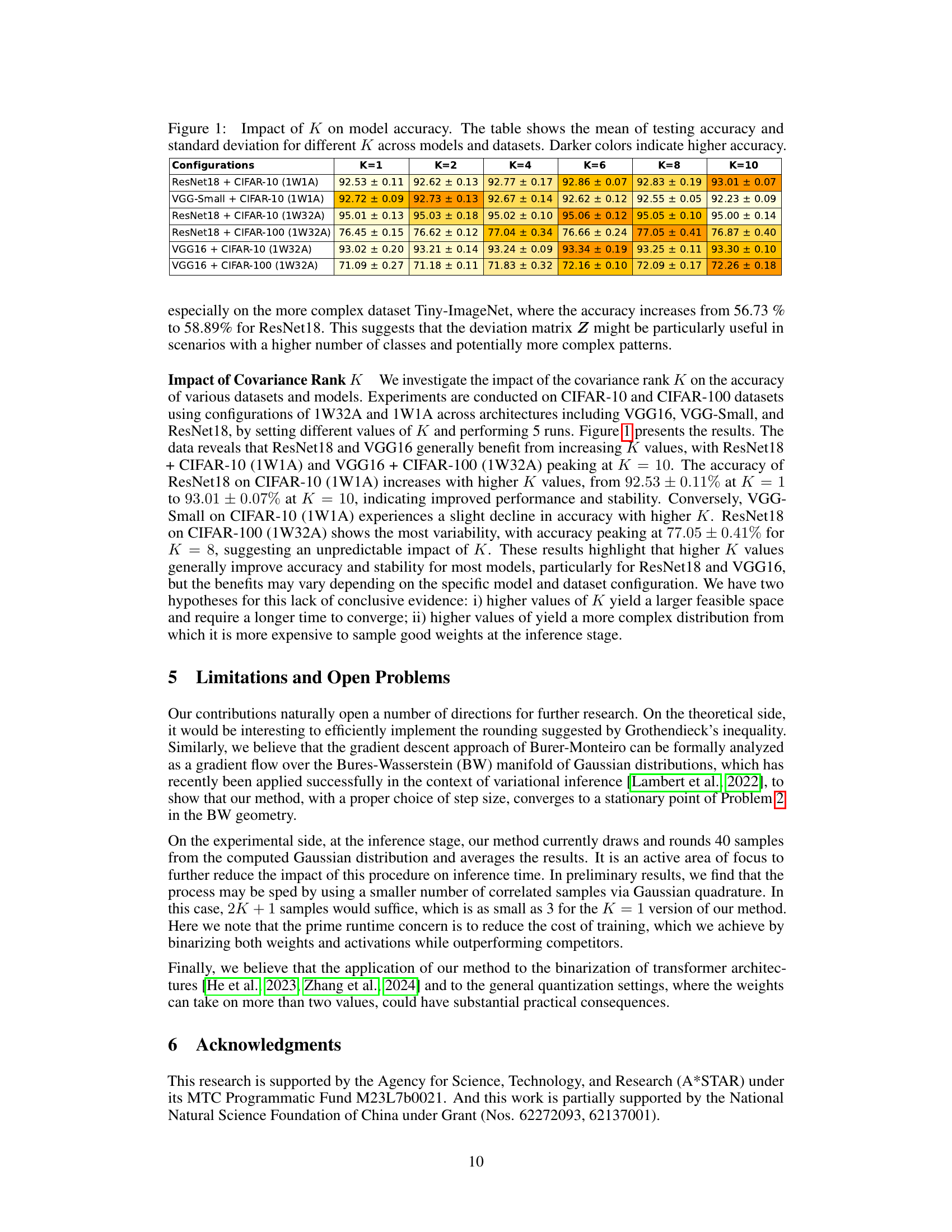
🔼 This table compares the performance of various methods for training binary neural networks (BNNs) on the ImageNet dataset using the ResNet18 architecture. The methods are categorized by whether they use 1-bit weights (W) and 1-bit activations (A), or 1-bit weights and 32-bit activations. The table shows the Top-1 and Top-5 accuracy achieved by each method. Top-1 accuracy indicates the percentage of images correctly classified into the most likely category, while Top-5 accuracy indicates the percentage of images correctly classified into one of the five most likely categories. The results highlight the relative performance of VISPA (the authors’ proposed method) against other state-of-the-art methods.
read the caption
Table 4: Performance comparison by testing accuracy of optimizers on ImageNet dataset across ResNet18 architectures. W/A denotes the bit-width of weights and activations.

🔼 This table compares the testing accuracy of various methods for training binary neural networks (BNNs) on three benchmark datasets: CIFAR-10, CIFAR-100, and Tiny-ImageNet. Two different network architectures, VGG16 and ResNet18, are used for each dataset. The table highlights the performance improvements achieved by the proposed VISPA method compared to several state-of-the-art BNN training techniques. Only weights are binarized in these experiments.
read the caption
Table 2: Performance comparison by testing accuracy (%) of various approaches on CIFAR-10, CIFAR-100, and Tiny-ImageNet across VGG16 and ResNet18 architectures with binarized weights only. (†) indicates that results are obtained from the numbers reported by Ajanthan et al. [2021]. (*) indicates that results are obtained from the numbers reported by Le et al. [2022].

🔼 This table compares the testing accuracy achieved by different methods on the CIFAR-10 dataset using two different network architectures: VGG-Small and ResNet18. Both architectures employ binarized activations and weights. The table highlights the performance of the proposed method (VISPA) against several state-of-the-art approaches.
read the caption
Table 1: Performance comparison by testing accuracy (%) on CIFAR-10 using VGG-Small and ResNet18 architectures with binarized activations and weights.
Full paper#