↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models often struggle with slow convergence to optimal solutions and suboptimal generalization. This stems from the implicit regularization process, where models tend to settle into sharp minima which do not generalize well. Existing techniques like sharpness-aware minimization attempt to address this but are computationally expensive.
The proposed Implicit Regularization Enhancement (IRE) framework tackles this by strategically decoupling the dynamics of flat and sharp directions during training. This approach selectively accelerates convergence along flat directions, leading to faster convergence and enhanced generalization. The paper demonstrates IRE’s effectiveness across various vision and language tasks, showing improvements in generalization performance and even significant speedups (2x in LLaMA pre-training).
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep learning because it presents a novel framework to significantly improve model generalization and training efficiency. It addresses a key challenge in deep learning—the slow convergence towards optimal solutions—by accelerating the sharpness reduction process without compromising training stability. This opens up new avenues for optimizing large language models and other computationally intensive deep learning tasks, leading to more efficient and effective models.
Visual Insights#
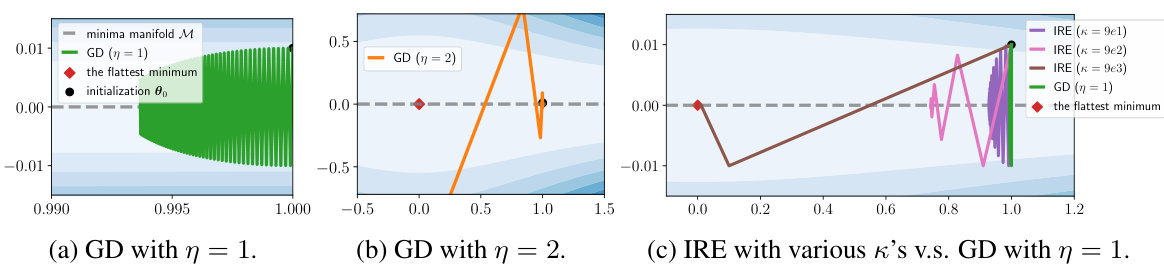
This figure shows a 2D illustration of the sharpness reduction process. Panel (a) demonstrates the slow convergence of Gradient Descent (GD) with a small learning rate (η=1) towards a flat minimum. Panel (b) shows that a larger learning rate (η=2) leads to divergence. Panel (c) illustrates the proposed Implicit Regularization Enhancement (IRE) method, which significantly accelerates the convergence to the flat minimum by selectively increasing the learning rate along flat directions while maintaining stability along sharp directions.
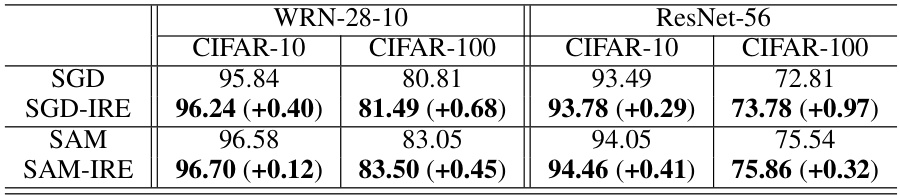
This table presents the classification accuracy results on CIFAR-10 and CIFAR-100 datasets using WideResNet-28-10 and ResNet-56 models. It compares the performance of standard SGD and SAM optimizers with their IRE-enhanced counterparts (SGD-IRE and SAM-IRE). The values show the improvement in accuracy achieved by IRE for each model and dataset.
In-depth insights#
Implicit Reg. Boost#
An ‘Implicit Reg. Boost’ section in a research paper would likely explore methods for enhancing the implicit regularization effects observed in deep learning models. This could involve analyzing existing implicit regularization mechanisms, such as those arising from specific optimizers like SGD or weight decay, and proposing novel techniques to amplify these effects. The core idea is to improve generalization performance and reduce overfitting by guiding the model towards solutions with desirable properties, like flat minima, without relying on explicit regularization terms. The discussion might involve theoretical analysis, such as examining the effect on loss landscapes and convergence rates, as well as empirical evaluations using various datasets and model architectures. Key aspects would include comparisons against baseline methods, showing significant improvements in generalization metrics like test accuracy or robustness to adversarial attacks. The paper could also investigate connections between implicit regularization and other model properties, such as sharpness or generalization. The effectiveness of the proposed boost methods would be a crucial element, and would require a robust empirical analysis demonstrating its wide applicability to different models and scenarios.
IRE Framework#
The IRE (Implicit Regularization Enhancement) framework, as described in the research paper, presents a novel approach to accelerate the discovery of flat minima in deep learning models. The core innovation lies in its ability to decouple the training dynamics of flat and sharp directions. By selectively accelerating the dynamics along flat directions, IRE aims to enhance the implicit sharpness regularization process inherent in gradient-based optimization. This is significant because flatter minima have been empirically linked to improved generalization capabilities. A key advantage of IRE is its practical applicability, which is demonstrated by its seamless integration with various base optimizers, such as SGD and AdamW, without imposing significant computational overhead. Experimental results validate the effectiveness of IRE across diverse datasets and architectures, showcasing consistent improvements in generalization performance and, surprisingly, accelerated convergence in some cases. The theoretical underpinnings provide further support for IRE’s mechanism, demonstrating a substantial acceleration of convergence toward flat minima, particularly within the context of sharpness-aware minimization (SAM). The IRE framework offers a promising avenue for enhancing both the efficiency and generalization of deep learning models.
Llama Speedup#
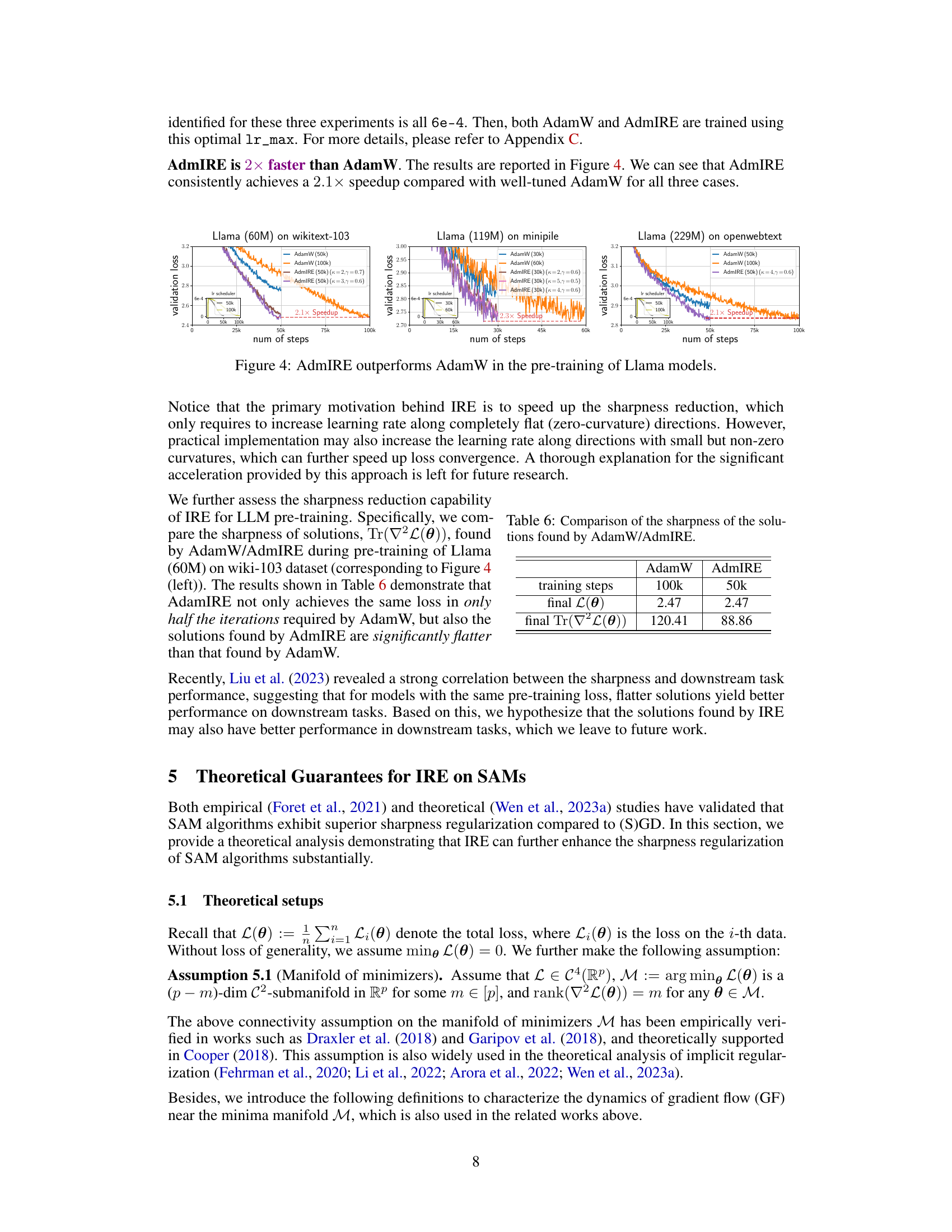
The research demonstrates a significant speedup in the pre-training of large language models (LLMs) using the proposed Implicit Regularization Enhancement (IRE) framework. IRE accelerates the convergence to flatter minima, which are known to generalize better. The experiments on Llama models (60M, 119M, 229M parameters) across diverse datasets (Wikitext-103, Minipile, Openwebtext) showcased a consistent 2x speedup compared to the widely-used AdamW optimizer. This improvement is especially noteworthy because IRE is designed to accelerate convergence to flatter minima and not explicitly to increase overall training speed. The unexpected speed gains suggest that IRE’s mechanism of enhancing implicit regularization might have a synergistic effect with existing optimization techniques, leading to improved efficiency. Further investigation into this surprising synergy between IRE and AdamW is needed, to fully understand the reasons for the substantial speed improvements. This breakthrough has important implications for training increasingly large language models, as it significantly reduces the computational cost and time involved in the crucial pre-training phase.
Theoretical Gains#
A theoretical gains section in a research paper would rigorously justify the claims made. It would delve into the mathematical underpinnings of the proposed method, providing proofs, convergence analysis, or other relevant theoretical arguments to establish its validity and effectiveness. A strong emphasis would be placed on showing that the method achieves improved performance (e.g., faster convergence, better generalization) compared to existing approaches, often under specific conditions or assumptions. The analysis may involve techniques such as bounding the error, characterizing the convergence rate, or establishing optimality conditions. Crucially, this section would not just state the theoretical results but would also thoroughly explain their implications and limitations. It would address the assumptions made, highlight any trade-offs, and discuss scenarios where the theoretical guarantees might not hold. In short, a robust theoretical gains section provides solid backing for empirical findings, offering valuable insights into the algorithm’s behavior and performance beyond pure experimental observations.
Future Work#
The paper’s “Future Work” section suggests several promising avenues. Understanding IRE’s mechanism for accelerating convergence beyond simply reducing sharpness is crucial. This involves exploring the interplay between IRE and factors like the Edge of Stability (EoS) and its effect on dynamics near flat minima. Expanding the empirical evaluation to a broader range of LLMs and datasets beyond those tested, and measuring downstream performance improvements, are essential to validate IRE’s effectiveness. Investigating IRE’s interaction with other regularization techniques like weight decay and dropout, or its compatibility with different optimizer types, could lead to further optimizations. Finally, theoretical analysis to establish more robust guarantees for IRE’s acceleration in SAM and broader convergence properties is highly desirable.
More visual insights#
More on figures

This figure shows a 2D illustration of the loss landscape with flat and sharp directions. Panel (a) demonstrates the slow convergence of Gradient Descent (GD) with a small learning rate towards a flat minimum. Panel (b) shows that increasing the learning rate too much causes divergence. Panel (c) illustrates the proposed Implicit Regularization Enhancement (IRE) method, which selectively accelerates convergence along flat directions without impacting stability along sharp directions, leading to significantly faster convergence to the flattest minimum.
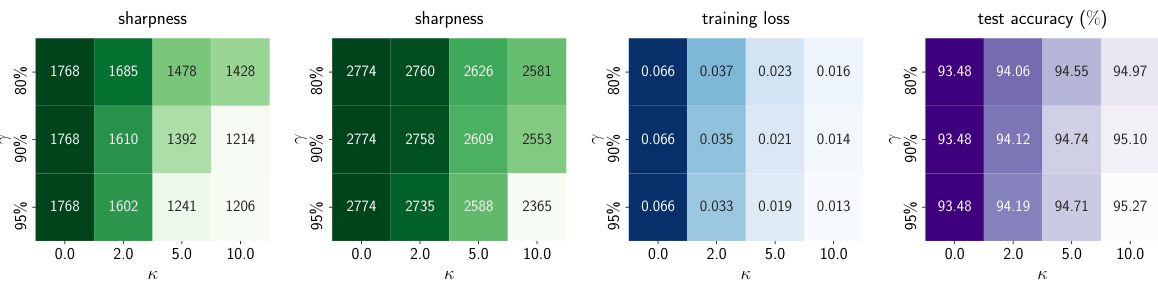
This figure presents the results of training a WideResNet-16-8 model on the CIFAR-10 dataset using the Sharpness-Aware Minimization with Implicit Regularization Enhancement (SAM-IRE) method. It shows how varying the hyperparameters κ (enhancement strength) and γ (proportion of flat directions considered) affects the sharpness (trace of the Hessian), training loss, and test accuracy. The heatmaps visually represent the performance across different combinations of κ and γ, with constant and decayed learning rates. The results demonstrate that SAM-IRE consistently achieves flatter minima (lower sharpness), lower training loss, and higher test accuracy compared to the standard SAM (κ = 0).
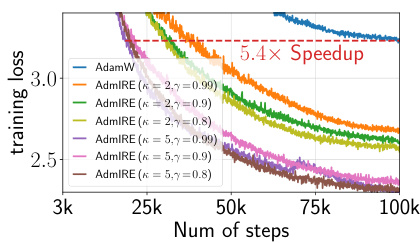
This figure shows the training loss curves for AdamW and AdmIRE with various hyperparameter settings (κ and γ) when training a 2-layer decoder-only transformer model on the Wikitext-2 dataset. The x-axis represents the number of training steps, and the y-axis represents the training loss. The plot demonstrates that AdmIRE consistently achieves a faster convergence rate than AdamW, with the best configuration resulting in a 5.4x speedup. The different colored lines represent different AdmIRE configurations.

This figure shows the validation loss curves for training three different sizes of Llama language models (60M, 119M, and 229M parameters) on three different datasets (wikitext-103, minipile, and openwebtext). The figure compares the performance of AdamW (a widely used optimizer for large language models) against AdmIRE (the proposed Implicit Regularization Enhancement framework combined with AdamW). For all three model sizes and datasets, AdmIRE demonstrates faster convergence towards lower validation loss than AdamW, achieving approximately a 2x speedup in terms of the number of training steps required. The figure highlights the consistent improvement of AdmIRE over AdamW across different model sizes and datasets.
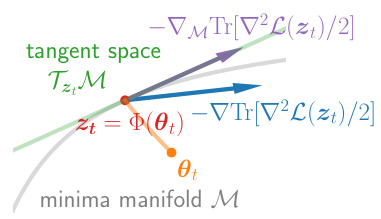
This figure shows a 2D illustration of the optimization problem (1) where the goal is to minimize L(u,v) = (1+u^2)v^2/2. The gray arrows indicate the minima manifold M = {(u,v):v=0}, with flatter minima at smaller values of u. The red dot represents the flattest minimum at (0,0). Subfigure (a) demonstrates the slow convergence of gradient descent (GD) with a learning rate η=1 towards flatter minima. Subfigure (b) shows that a larger learning rate (η=2) leads to divergence. Subfigure (c) illustrates how the proposed Implicit Regularization Enhancement (IRE) method significantly accelerates convergence towards the flattest minimum by boosting the dynamics along flat directions, while maintaining stability in sharp directions.
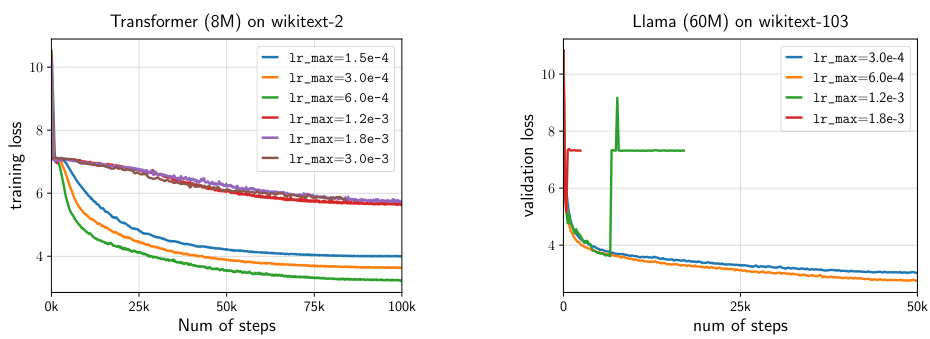
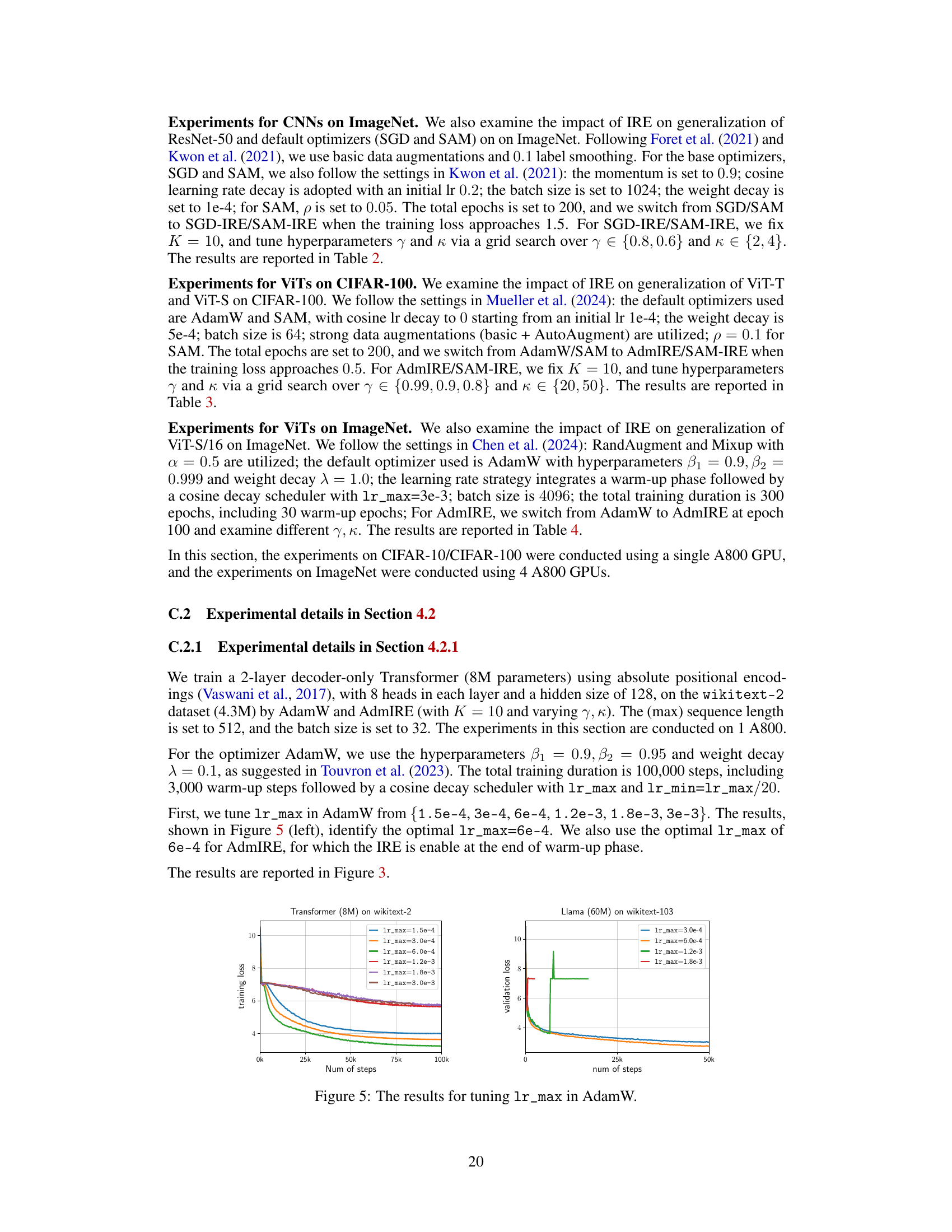
This figure presents the results of tuning the maximum learning rate (lr_max) in the AdamW optimizer. Two sub-figures are shown. The left sub-figure displays the training loss curves for different lr_max values on a 2-layer Transformer model trained on the wikitext-2 dataset. The right sub-figure shows the validation loss curves for varying lr_max values on a Llama (60M) model trained on the wikitext-103 dataset. These plots illustrate how different learning rates affect the convergence and performance during the training process, aiding in the selection of an optimal lr_max for both model types.
More on tables

This table presents the results of training a ResNet-50 model on the ImageNet dataset using different optimization methods. The table compares the Top-1 and Top-5 accuracy achieved by standard SGD and SAM optimizers, against their enhanced versions using the Implicit Regularization Enhancement (IRE) framework proposed in the paper. The numbers in parentheses show the improvement in accuracy resulting from the use of IRE. The results demonstrate that IRE consistently leads to improvements in accuracy for both SGD and SAM.
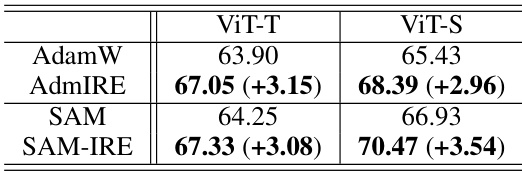
The table presents the results of image classification experiments using Vision Transformers (ViT-T and ViT-S) on the CIFAR-100 dataset. The performance of AdamW, AdmIRE (AdamW with IRE), SAM (Sharpness-Aware Minimization), and SAM-IRE (SAM with IRE) are compared, showcasing the improvement in accuracy achieved by incorporating the IRE framework. The numbers in parentheses indicate the increase in accuracy compared to the baseline optimizer (AdamW or SAM).
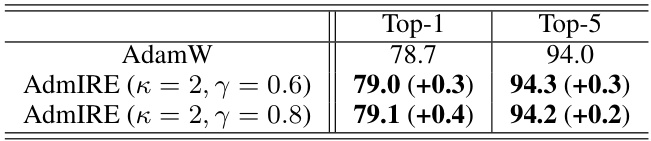
This table presents the results of training a Vision Transformer (ViT-S) model on the ImageNet dataset using AdamW and AdmIRE (a variant of AdamW that incorporates the Implicit Regularization Enhancement (IRE) framework). The table shows that AdmIRE achieves a higher top-1 and top-5 accuracy compared to AdamW, demonstrating the effectiveness of the IRE framework in improving the generalization performance of the model.
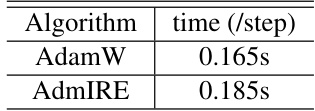
This table presents the wall-clock time per step for both AdamW and AdmIRE on a single A800 GPU. It demonstrates the computational efficiency of AdmIRE, showing that its per-step time is only slightly higher than AdamW’s.
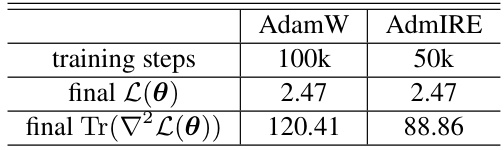
This table compares the sharpness of the solutions obtained using AdamW and AdmIRE after training a Llama (60M) model on the Wikitext-103 dataset. Sharpness is measured by the trace of the Hessian (Tr(∇²L(θ))). The results show that AdmIRE achieves a comparable final loss in half the number of training steps, and the resulting solution exhibits significantly lower sharpness.
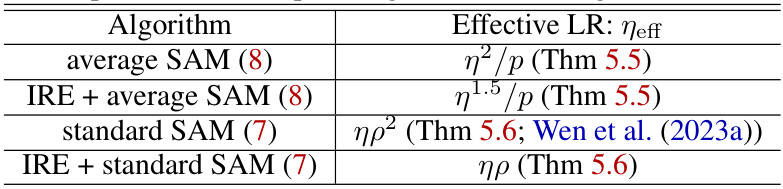
This table compares the effective learning rate (LR) of different algorithms in minimizing the trace of the Hessian, a measure of sharpness. It shows that IRE (Implicit Regularization Enhancement) significantly increases the effective LR for both standard and average SAM (Sharpness-Aware Minimization), thereby accelerating the convergence towards flatter minima, which improves generalization.

This table shows the classification accuracy results on CIFAR-10 and CIFAR-100 datasets using two different Convolutional Neural Networks (CNNs): WideResNet-28-10 and ResNet-56. The results are presented for four different training methods: SGD (standard stochastic gradient descent), SGD-IRE (SGD with Implicit Regularization Enhancement), SAM (Sharpness-Aware Minimization), and SAM-IRE (SAM with Implicit Regularization Enhancement). The numbers in parentheses indicate the improvement in accuracy achieved by IRE compared to the baseline methods (SGD and SAM).
Full paper#