↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning (CL) aims to enable models to learn new concepts without forgetting previously learned ones. However, existing CL methods often struggle when using pre-trained models (PTMs) as the starting point. They either lose the general knowledge inherent in PTMs or lack the plasticity to effectively learn new concepts. This is due to the direct application of parameter-efficient tuning (PET) in the first session and parameter freezing in subsequent sessions. This paper focuses on solving the issues of applying parameter-efficient tuning directly to downstream data, and freezing parameters in incremental sessions.
The proposed Slow and Fast parameter-Efficient tuning (SAFE) framework addresses this by introducing a slow learner that inherits general knowledge from PTMs and a fast learner that incorporates novel concepts while mitigating catastrophic forgetting. SAFE employs a knowledge transfer loss to ensure the slow learner retains general knowledge, and a feature alignment loss to help the fast learner learn without forgetting. Experiments across seven benchmark datasets show SAFE significantly outperforms existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in continual learning as it addresses the limitations of existing methods by proposing a novel framework, SAFE. SAFE significantly improves the generalizability and plasticity of pre-trained models in continual learning scenarios, opening new avenues for research in parameter-efficient tuning and addressing catastrophic forgetting. Its effectiveness across diverse benchmark datasets highlights its potential impact on various real-world applications.
Visual Insights#

This figure compares existing continual learning methods that use pre-trained models with the proposed SAFE method. Panel (a) shows that most previous methods use parameter-efficient tuning (PET) in the first session, but freeze parameters in later sessions. This contrasts with SAFE, which uses slow and fast PET methods to balance stability and plasticity. Panel (b) illustrates common PET methods including adapters, scale and shift, and visual prompt tuning.
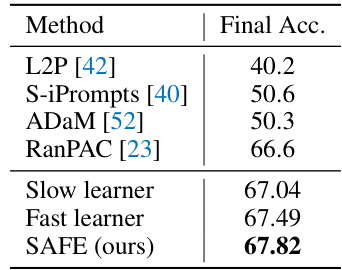
This table presents the performance comparison of different methods on the DomainNet dataset in terms of final accuracy. The results show that the proposed SAFE method achieves the highest accuracy (67.82%) compared to other state-of-the-art approaches, such as L2P, S-iPrompts, ADaM, and RanPAC. It also demonstrates the contribution of both the slow and fast learners within the SAFE framework, showcasing their individual performances before aggregation.
In-depth insights#
PTM Knowledge Transfer#
The concept of “PTM Knowledge Transfer” in continual learning focuses on effectively leveraging the vast knowledge embedded within pre-trained models (PTMs). Instead of treating PTMs merely as initialization, the core idea is to explicitly transfer their inherent knowledge to the continual learning model. This avoids catastrophic forgetting and enhances generalization by ensuring that the model retains and benefits from the previously learned generalizable features. Effective knowledge transfer strategies often involve mechanisms that align the feature representations or internal representations of the PTM and the downstream continual learning model. This alignment can be achieved through various techniques, such as minimizing the distance between feature embeddings or maximizing correlation between activations. A key challenge lies in striking a balance between preserving the PTM’s general knowledge and adapting to new tasks, which requires careful design of loss functions and training strategies. Successful PTM knowledge transfer leads to significantly improved performance on downstream tasks, particularly in class-incremental settings where new classes are continually introduced. This approach can lead to substantial improvements over methods that simply fine-tune PTMs directly or those that rely on freezing PTM parameters altogether.The effectiveness of PTM knowledge transfer hinges on choosing appropriate alignment mechanisms, managing the trade-off between stability and plasticity, and handling the distribution shifts between the pre-training and downstream datasets.
Slow-Fast Tuning#
The concept of ‘Slow-Fast Tuning’ in continual learning aims to address the inherent trade-off between stability and plasticity. The ‘slow’ component focuses on preserving knowledge acquired from pre-trained models or earlier learning stages, emphasizing generalization and preventing catastrophic forgetting. This is often achieved by using parameter-efficient tuning methods with limited updates to key model parameters, effectively acting as a knowledge distillation process. The ‘fast’ component, on the other hand, is designed to adapt quickly to new information and concepts, offering the necessary plasticity. This often involves updating more parameters, but with careful regularization to maintain stability. The integration of these two components allows the model to gracefully learn new tasks without sacrificing past knowledge, providing a more robust and efficient approach to continual learning than relying solely on either slow or fast learning techniques.
Catastrophic Forgetting#
Catastrophic forgetting, a significant challenge in continual learning, describes the phenomenon where a neural network trained on a new task largely forgets previously learned tasks. This is especially problematic when dealing with sequential learning scenarios. The core issue stems from the nature of backpropagation and gradient descent, where learning new information often overwrites existing knowledge, leading to performance degradation on older tasks. Strategies to mitigate catastrophic forgetting often involve techniques like regularization, rehearsal (replaying old data), or architectural changes. Regularization methods, for example, constrain the network’s weights to prevent drastic updates, allowing for a balance between learning new and retaining old information. Rehearsal techniques directly address the problem by periodically reintroducing data from past tasks during training. Architecturally, techniques such as expanding the network capacity or using separate modules for different tasks can help reduce interference between knowledge representations. The effectiveness of these methods varies depending on the specific task, network architecture, and data characteristics. While significant progress has been made, completely eliminating catastrophic forgetting remains an active area of research in continual learning.
SAFE Framework#
The proposed SAFE framework offers a novel approach to continual learning, effectively addressing the limitations of existing methods. Its core innovation lies in the dual-learner architecture, combining a slow learner to preserve general knowledge from pre-trained models and a fast learner to incorporate new concepts. The slow learner, guided by a transfer loss function, ensures that generalizable knowledge is retained. The fast learner, in turn, employs cross-classification and feature alignment losses to avoid catastrophic forgetting while remaining plastic for novel concepts. This synergy, further enhanced by an entropy-based aggregation strategy during inference, allows SAFE to achieve a robust balance between stability and plasticity. The framework exhibits significant improvements across various benchmark datasets, demonstrating its effectiveness and establishing it as a noteworthy advancement in parameter-efficient continual learning.
Future Work#
Future research directions stemming from this continual learning work could involve exploring more sophisticated knowledge transfer mechanisms between the slow and fast learners. Improving the efficiency of the feature alignment loss is crucial, potentially through the development of more advanced similarity measures beyond cosine similarity. Investigating different aggregation strategies beyond the entropy-based approach, perhaps incorporating uncertainty estimates from each learner, could also yield improvements. The framework’s robustness to various pre-trained models and PET methods should be further evaluated across a broader range of tasks and datasets. Extending the framework to handle more complex continual learning scenarios, such as those with class imbalance or concept drift, remains a key challenge. Finally, a thorough theoretical analysis of SAFE’s properties, including its convergence guarantees and generalization performance, would significantly enhance the paper’s impact.
More visual insights#
More on figures

This figure illustrates the SAFE framework for continual learning. The left side shows the training process. In the first session (t=1), knowledge is transferred from the pre-trained model (PTM) to the slow learner (S-PET) which is then frozen. Subsequent sessions (t>1) involve a fast learner (F-PET) that is guided by the slow learner to learn new concepts while preventing catastrophic forgetting. The right side shows the inference process, where an entropy-based aggregation strategy combines the predictions of the slow and fast learners for robust results.
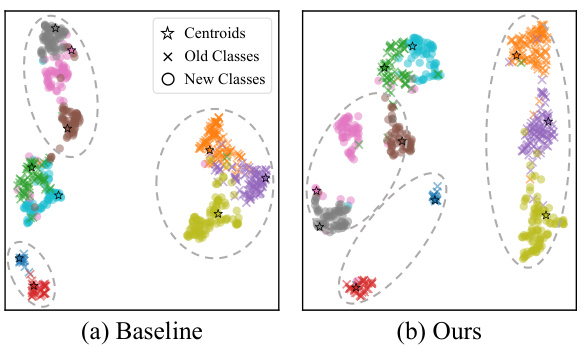
This figure visualizes the embedding space of five unseen classes and five seen classes using t-SNE after the first session adaptation. It compares the baseline method with the proposed method (ours) showing that the embedding space of the slow learner in the proposed method exhibits distinct separation between seen and unseen classes, illustrating the successful integration of generalization capabilities from the PTM into the slow learner.

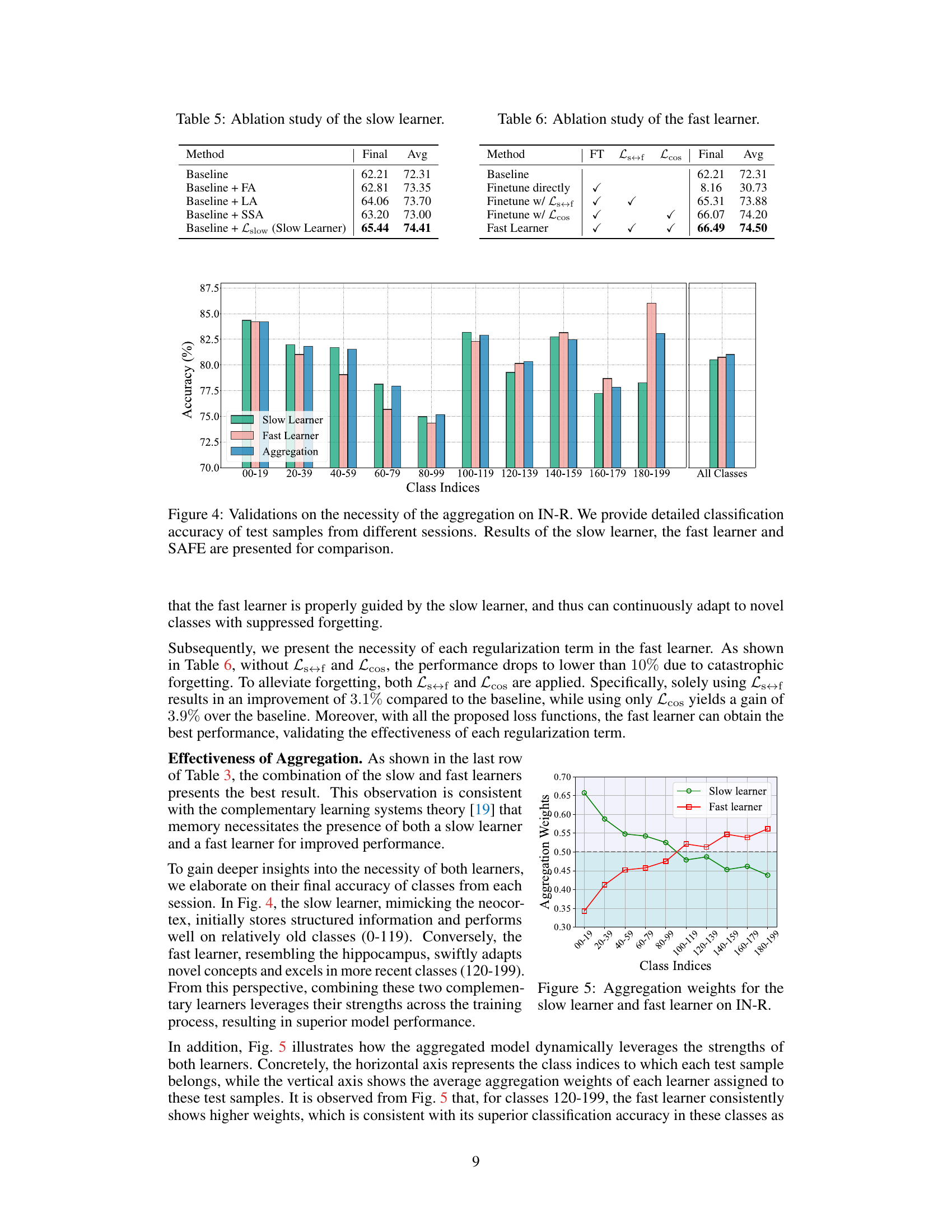
This figure validates the necessity of using an aggregation strategy that combines the predictions from both the slow and fast learners. It shows the classification accuracy for different class ranges (00-19, 20-39, etc.) on the ImageNet-R (IN-R) dataset across different training sessions. The results demonstrate that the aggregation method outperforms using only the slow learner or the fast learner, highlighting the complementary strengths of both learners for robust performance.

This figure visualizes how the entropy-based aggregation dynamically balances the contributions of the slow and fast learners during inference on the ImageNet-R dataset. The x-axis represents class indices grouped into ranges, while the y-axis shows the average aggregation weights assigned to each learner for those classes. The plot reveals that the slow learner has higher weights for older classes (0-119), reflecting its superior performance on previously seen data, while the fast learner receives stronger weights for newer classes (120-199), indicating its better ability to adapt to recently introduced concepts. This dynamic allocation of weights highlights the complementary strengths of the two learners.

This figure compares the memory usage (parameter size) and final accuracy of different continual learning methods (ADAM, RanPAC, Ours (SAFE), SSIAT, CODAPrompt, EASE). It demonstrates that SAFE achieves comparable or better performance than other methods while using a similar or even smaller parameter size. This highlights SAFE’s efficiency in terms of resource usage.

This figure visualizes the effectiveness of the slow learner by comparing the t-SNE embeddings of five unseen classes and five seen classes, after the first session adaptation. It shows a clear separation between seen and unseen classes in the slow learner’s embedding space, demonstrating successful knowledge transfer from the PTM and improved generalization ability.

This figure shows a visualization of the seven benchmark datasets used in the paper: CIFAR100, CUB200, ImageNet-A, Omnibenchmark, ImageNet-R, DomainNet, and VTAB. Each dataset is represented by a grid of images, showcasing the variety of visual data included in each dataset. This visualization helps demonstrate the diversity and complexity of the datasets, highlighting the differences in image content, style, and quality. The datasets cover a wide range of image types and visual characteristics, making them suitable for evaluating the continual learning capabilities of different models.
More on tables
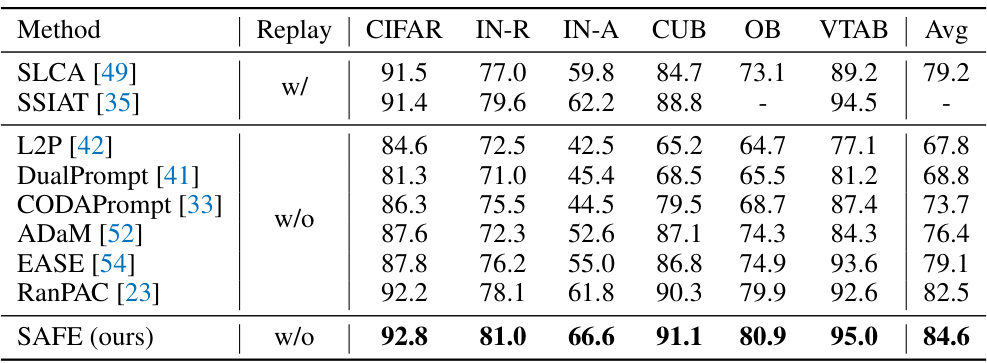
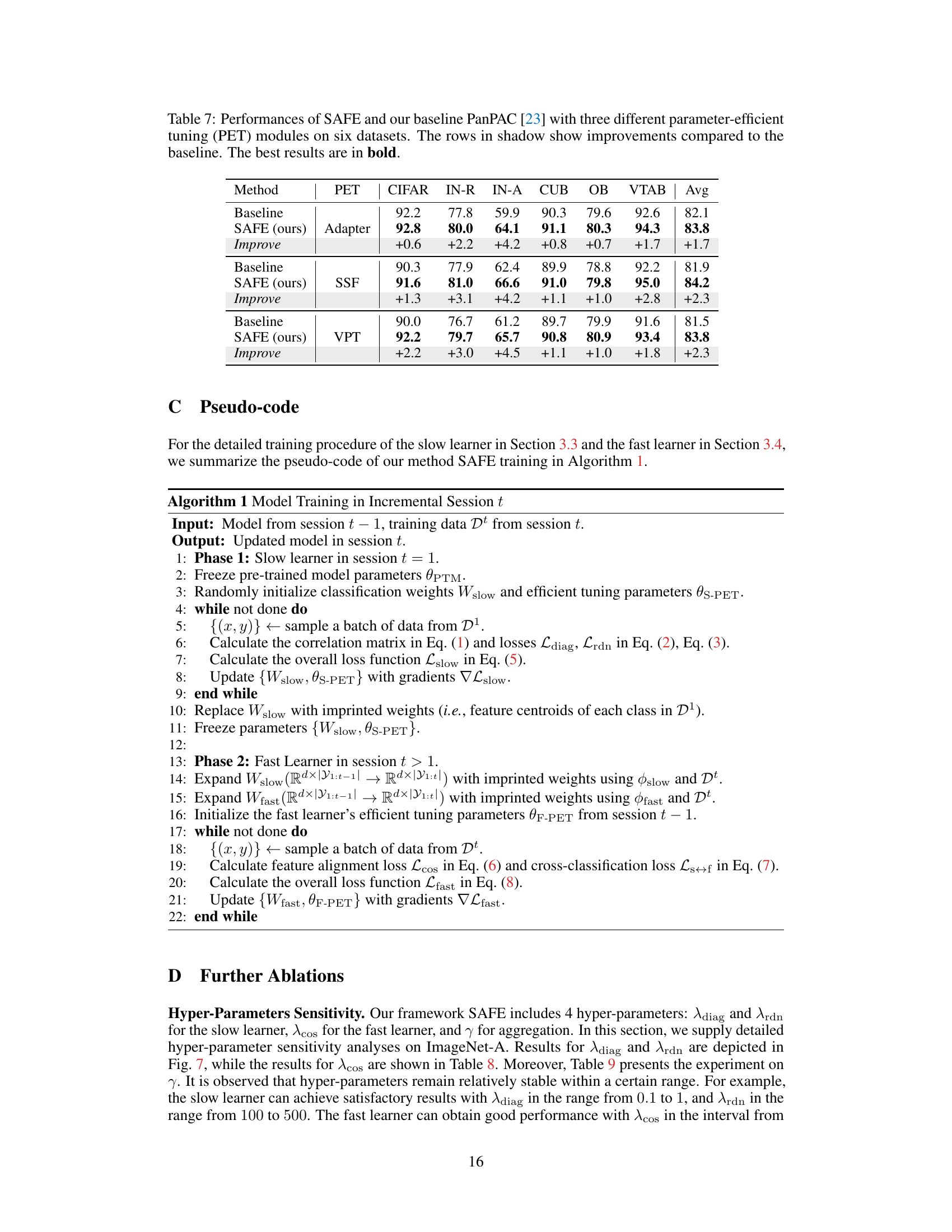
This table compares the performance of different continual learning methods on six benchmark datasets. The ‘Replay’ column indicates whether the method uses data replay or not. Each subsequent column shows the final accuracy achieved by each method on a specific dataset (CIFAR, IN-R, IN-A, CUB, OB, VTAB). The final column provides the average accuracy across all six datasets. This allows for a comprehensive comparison of the methods, considering both their individual performance on different datasets and their overall average performance. It highlights the relative strengths and weaknesses of each approach.

This table presents the ablation study results on the ImageNet-A dataset. It shows the impact of including the slow learner, the fast learner, and both learners (SAFE) on the final and average accuracy. The baseline represents the result without any of these components. This helps to understand the contribution of each component to the overall performance improvement.
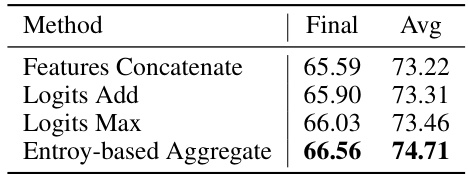
This table presents the results of an ablation study on different aggregation strategies for combining the predictions of the slow and fast learners in the SAFE framework. The methods compared are: simple feature concatenation, logits addition, logits maximization, and the proposed entropy-based aggregation. The table shows the final and average accuracy on the ImageNet-A dataset for each method. The results demonstrate that the entropy-based aggregation approach yields the best performance.

This table presents the ablation study results for the slow learner component of the SAFE framework. It shows the impact on the final and average accuracy metrics when different variations of the slow learner are used. The baseline represents the performance without the slow learner. The other rows show the results of adding Feature Alignment (FA), Logits Alignment (LA), Second-order Statistics Alignment (SSA), and the proposed Slow Learner method (Baseline + Lslow). The last row shows a significant improvement in accuracy, highlighting the effectiveness of the slow learner component.
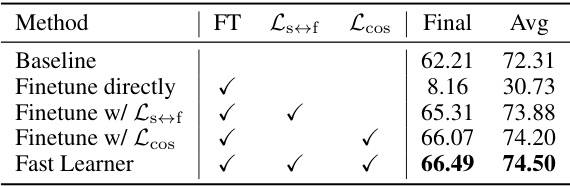
This table presents the results of ablation experiments conducted on the fast learner component of the SAFE framework. It shows the impact of using different loss functions (Ls↔f, Lcos) on the model’s performance (final and average accuracy) on a specific dataset, by comparing a baseline against different configurations. The results highlight the importance of using both Ls↔f and Lcos for optimal performance.
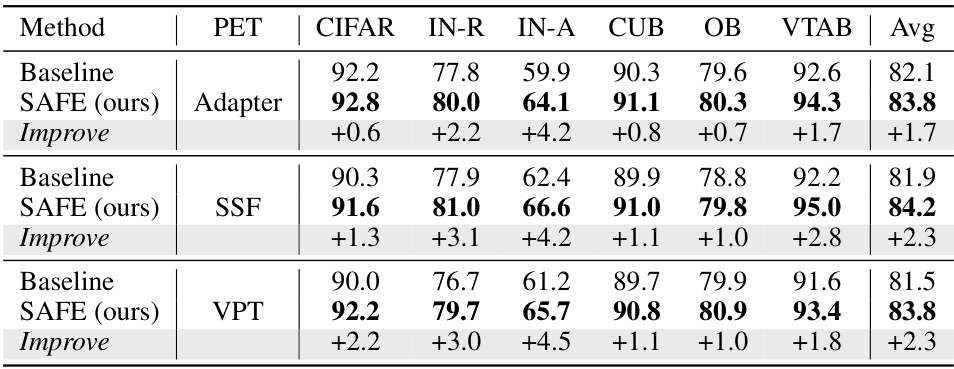
This table presents a comparison of different continual learning methods across six datasets. It shows the final accuracy achieved by each method on each dataset, as well as the average accuracy across all datasets. The table also indicates whether each method used data replay or not.

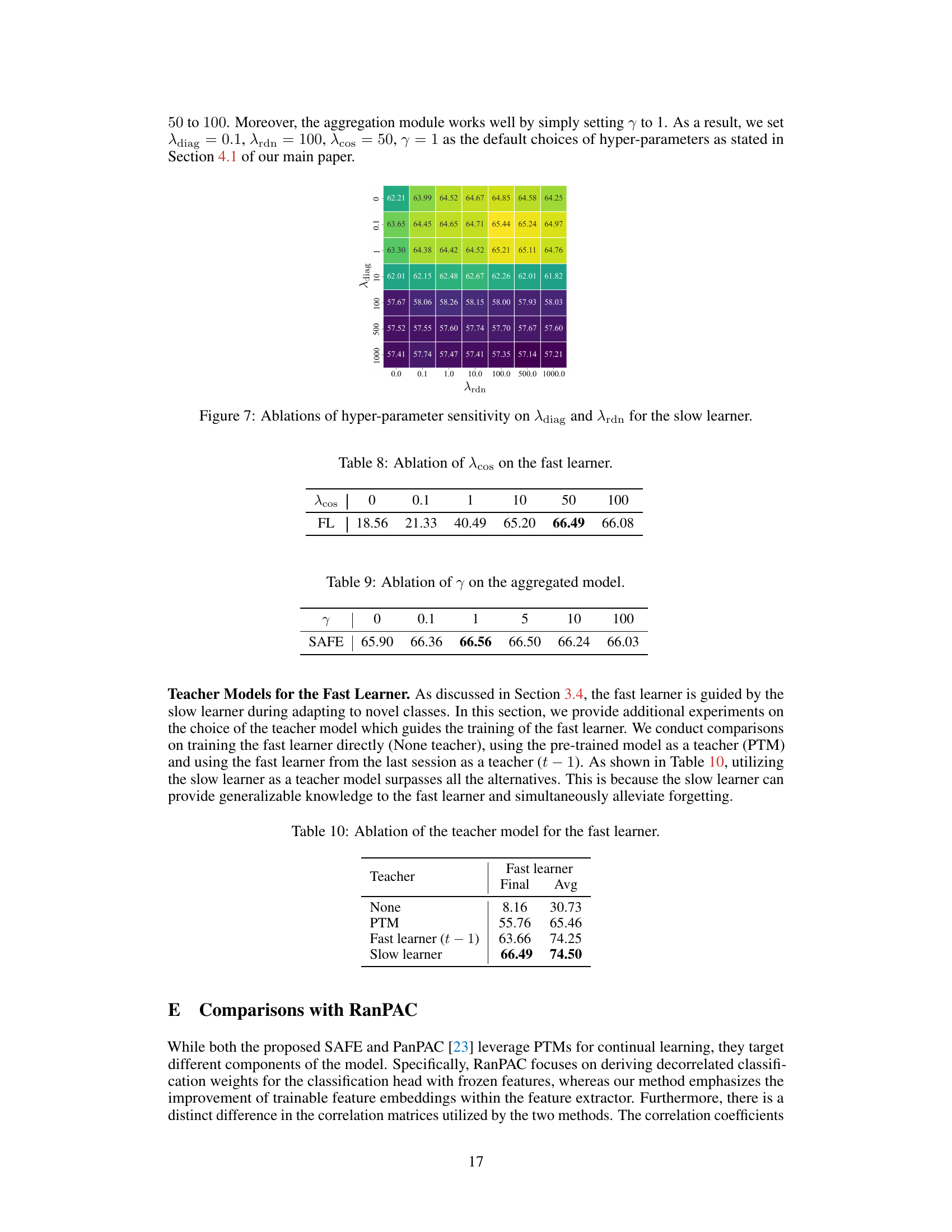
This ablation study investigates the effect of the hyperparameter λcos on the performance of the fast learner. The table shows that varying λcos impacts the final accuracy of the fast learner on the ImageNet-A dataset, with the optimal value appearing to be around 50.

This table shows the ablation study of the hyperparameter γ used in the entropy-based aggregation of the slow and fast learners’ predictions in the SAFE framework. The results demonstrate the impact of different values of γ on the final accuracy of the model on the ImageNet-A dataset. The optimal value of γ = 1 yields the best overall performance, which is highlighted in bold.
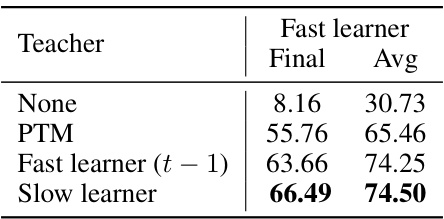
This table presents the ablation study of different teacher models used for guiding the fast learner in the SAFE framework. It compares the final and average accuracy results achieved when using no teacher, the pre-trained model (PTM), the fast learner from the previous session (t-1), and the slow learner as the teacher. The results demonstrate the superior performance of the slow learner as a teacher model.
Full paper#