↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Personalizing large language models (LLMs) to individual users is a hot research area. Current methods often struggle with black-box LLMs (where internal model parameters are inaccessible) relying on prompt engineering which is difficult to generalize. Furthermore, incorporating entire user profiles in prompts can exceed LLM length limits. Retrieval-Augmented Generation (RAG) methods offer a better approach, yet struggle to capture shared knowledge across users.
The paper introduces HYDRA, a novel model factorization framework. HYDRA uses a two-stage retrieval-then-rerank process to select the most useful user information. This information is then used to train a personalized adapter that aligns LLM outputs with individual preferences, all without accessing the internal parameters of the black-box LLM. This method demonstrates better performance across five tasks in the LaMP benchmark, showing the effectiveness and scalability of the approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) personalization, especially those dealing with black-box models. It presents a novel, effective method that outperforms existing techniques, opening new avenues for research in adapting LLMs to individual user needs. The work also addresses the critical challenge of personalization in the context of privacy and limited model access.
Visual Insights#

This figure illustrates three different approaches to LLM personalization. (a) shows the traditional fine-tuning approach for white-box LLMs where user-specific models are trained. (b) shows the prompt-based approach for black-box LLMs where user-specific information is incorporated into the prompt. (c) shows the HYDRA approach which leverages a model factorization technique to achieve better personalization in black-box LLMs, by using a shared base model and user-specific heads. This allows it to learn both general knowledge and user-specific preferences without needing access to the internal model parameters of the black-box LLMs.
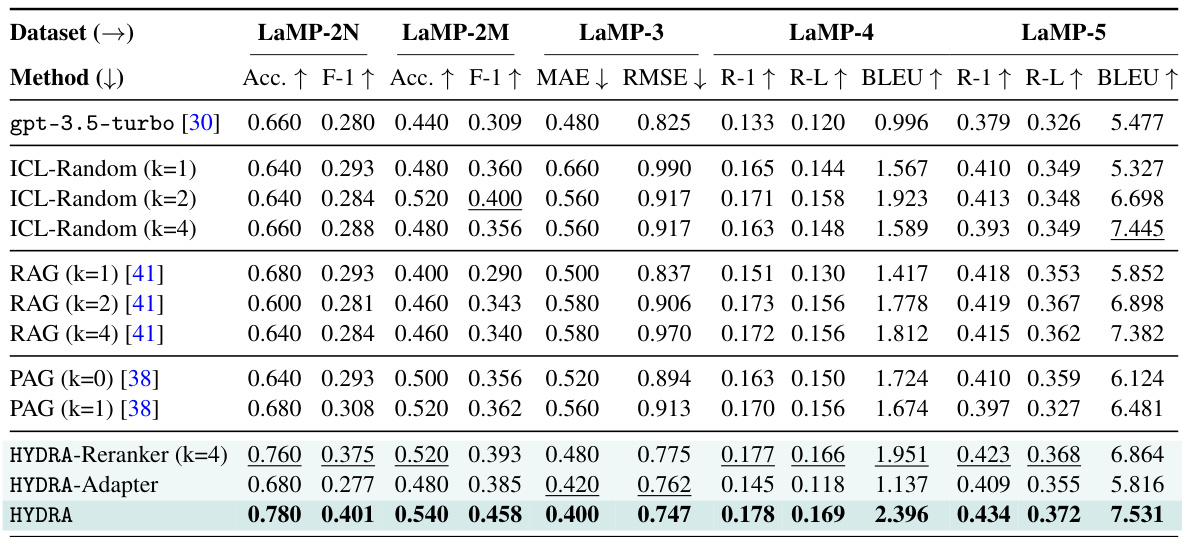
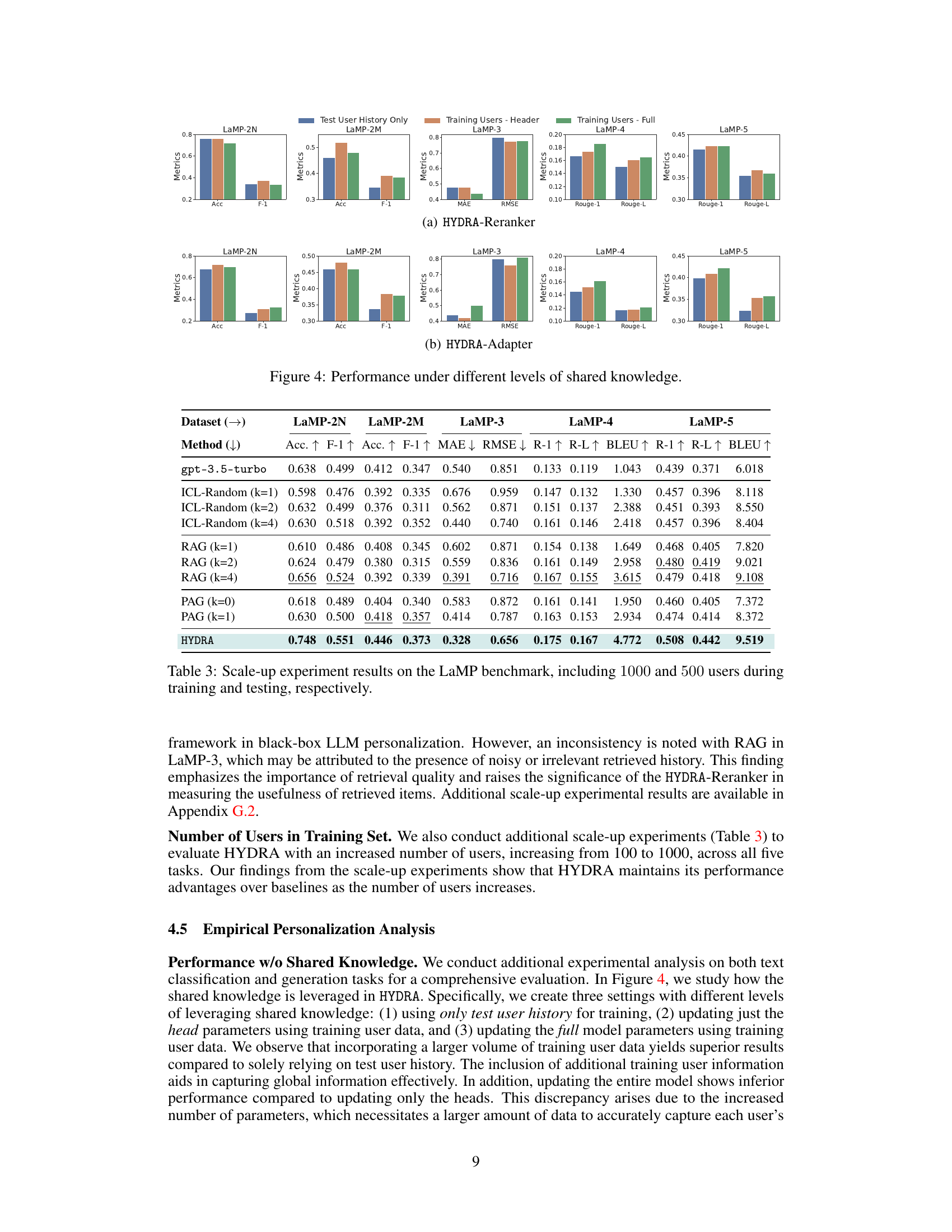
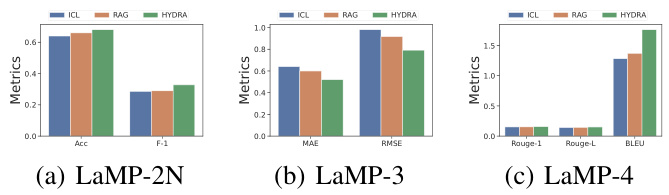
This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model (gpt-3.5-turbo), random in-context learning (ICL-Random), retrieval-augmented generation (RAG), and profile-augmented generation (PAG). The results show accuracy (Acc), F1-score (F1), mean absolute error (MAE), root mean squared error (RMSE), ROUGE-1 (R-1), ROUGE-L (R-L), and BLEU scores for each task and baseline, highlighting HYDRA’s superior performance.
In-depth insights#
LLM Personalization#
LLM personalization is a crucial area of research focusing on adapting large language models (LLMs) to individual user preferences. Current approaches often involve crafting user-specific prompts or fine-tuning the LLM, but these methods face challenges such as generalization and access to model parameters. Prompt engineering struggles to generalize effectively across diverse user needs, while fine-tuning requires access to the often proprietary LLM’s internal parameters, limiting its applicability. A key challenge is balancing user-specific adaptations with the preservation of general knowledge inherent in the LLM. There’s a need for methods that are effective with black-box LLMs, those whose inner workings are not revealed, and are able to generalize well across users and tasks while still providing a high level of personalization. This requires innovative techniques that avoid direct model modification, potentially leveraging model factorization, prompt augmentation strategies, or other techniques that can capture both shared and unique user characteristics.
Hydra Framework#
The Hydra framework, as conceived, presents a novel approach to LLM personalization, particularly addressing the challenges posed by black-box models. Its core innovation lies in model factorization, separating user-specific preferences from shared, general knowledge. This allows for personalization without direct access to the model’s internal parameters, a critical advantage when dealing with proprietary LLMs. The framework is built upon a two-stage process: retrieval-then-reranking, followed by adaptation via a trainable adapter. The reranker prioritizes relevant historical data, enhancing personalization accuracy. The adapter itself uses a hydra-like structure, combining a shared base model with user-specific heads to generalize effectively across users while maintaining individual preferences. Experimental results demonstrate superior performance compared to existing methods, highlighting Hydra’s effectiveness in delivering personalized LLM outputs.
Black-Box Methods#
Black-box methods in machine learning, particularly in the context of large language models (LLMs), present a unique set of challenges and opportunities. Because the internal workings of these models are opaque, their decisions can’t be easily interpreted. This lack of transparency makes it hard to understand why they make specific predictions, which hinders debugging and raises concerns about potential biases and fairness issues. However, the inability to directly access and modify internal parameters also presents advantages. Since black-box models are often pre-trained on massive datasets and are readily available via APIs, they provide a powerful, readily deployable tool for various applications. Research focuses on techniques to work around the black-box nature—using methods like prompt engineering, retrieval-augmented generation, or model factorization to indirectly guide model outputs towards desired behaviors. This approach balances the power of black-box LLMs with the need for control and interpretability, paving the way for personalized and effective applications, though still needing to address concerns over bias and transparency.
Model Factorization#
Model factorization, in the context of large language model (LLM) personalization, presents a powerful technique to address the inherent limitations of existing methods. It elegantly disentangles shared knowledge from user-specific preferences, overcoming the challenges of prompt-based approaches that struggle with generalization and the constraints of fine-tuning which requires access to model parameters. By decomposing the LLM into a shared base model and multiple user-specific heads, it effectively captures both global patterns and individual nuances. This factorization allows for efficient adaptation to new users without retraining the entire model, promoting scalability and reducing computational costs. Furthermore, the framework’s modularity enhances flexibility, allowing for independent training and optimization of the shared and user-specific components. This approach is particularly valuable for black-box LLMs, where internal parameters are inaccessible. The resulting personalized generation benefits from both the breadth of shared knowledge and the depth of user-specific adaptations. This hybrid strategy strikes a balance between generalizability and individualization, delivering personalized experiences with superior performance and efficiency.
Future Directions#
Future research should prioritize expanding HYDRA’s capabilities to encompass multi-modal data, enabling personalized responses that integrate visual and auditory information, enhancing user experience. Addressing privacy concerns through rigorous data anonymization and access control mechanisms is crucial, and developing techniques for user-specific bias mitigation is essential to ensure fairness and prevent discrimination. Investigating model efficiency improvements to enable on-device personalization, particularly for resource-constrained environments, is also key. Furthermore, exploring how to dynamically adapt to evolving user preferences and behaviour shifts, rather than relying on static historical data, represents a significant challenge. Robust evaluation metrics that capture the nuanced aspects of personalized user experiences are needed, moving beyond simple accuracy scores to address the holistic impact of personalization. Finally, it is critical to focus on the ethical implications of personalized LLMs, particularly concerning transparency and potential biases, to ensure responsible development and deployment.
More visual insights#
More on figures

This figure illustrates the HYDRA framework’s workflow. It starts with retrieving and reranking relevant user history to focus on the most useful information. This refined history is then used to train an adapter that aligns the black-box LLM’s output with the user’s preferences. Both the reranker and adapter use a base model with multiple user-specific heads (the ‘Hydra’). The base model handles shared knowledge across all users, while the individual heads learn the specific preferences of each user.
This figure illustrates the HYDRA framework. It shows a two-stage retrieval-augmented process: First, a reranker prioritizes useful information from retrieved user history; second, an adapter aligns black-box LLM outputs with user preferences using the prioritized history and query. Both reranker and adapter use a base model with multiple user-specific heads, capturing shared and user-specific knowledge respectively. This architecture is designed to improve personalization in black-box LLMs.

This figure illustrates the architecture of HYDRA, a model factorization framework for black-box LLM personalization. It consists of three main steps: First, a retriever extracts relevant user behaviors from historical data. Second, a reranker prioritizes the most useful information from these retrieved records. Third, an adapter aligns the output of a black-box LLM with individual user preferences using the prioritized historical data. The reranker and adapter are both composed of a shared base model and multiple user-specific heads, resembling a hydra, allowing HYDRA to capture both shared knowledge and user-specific behaviors.
This figure illustrates the architecture of HYDRA, a model factorization framework for black-box LLM personalization. It shows a retrieval-augmented workflow with two main components: a reranker and an adapter. The reranker prioritizes useful information from retrieved user behavior records. The adapter then aligns the output of the black-box LLM with user-specific preferences. Both components are decomposed into a base model with multiple user-specific heads. The base model represents shared knowledge among all users, and the heads capture user-specific behavior patterns.

This figure illustrates the architecture of HYDRA, a model factorization framework for black-box LLM personalization. It depicts a retrieval-augmented workflow with two key components: a reranker and an adapter. The reranker prioritizes useful information from retrieved user behavior records, while the adapter aligns the black-box LLM outputs with user-specific preferences. Both components are decomposed into a base model with multiple user-specific heads, allowing HYDRA to capture both shared knowledge and user-specific behavior patterns. The model factorization enhances generalization across users.

This figure illustrates the HYDRA framework’s architecture and workflow. It’s a retrieval-augmented system with two main components: a reranker prioritizing useful historical data and an adapter aligning LLM outputs to user preferences. Both components use a base model with multiple user-specific heads to balance shared knowledge and personalized behavior.

This figure illustrates the HYDRA model architecture, showing its retrieval-augmented framework which uses a reranker to prioritize information from historical data, and an adapter to align black-box LLM outputs with personalized preferences. Both components use a base model and multiple user-specific heads to capture shared and user-specific knowledge. The figure breaks down the process into three steps: retrieval, reranking/adapter training, and personalized inference.
More on tables
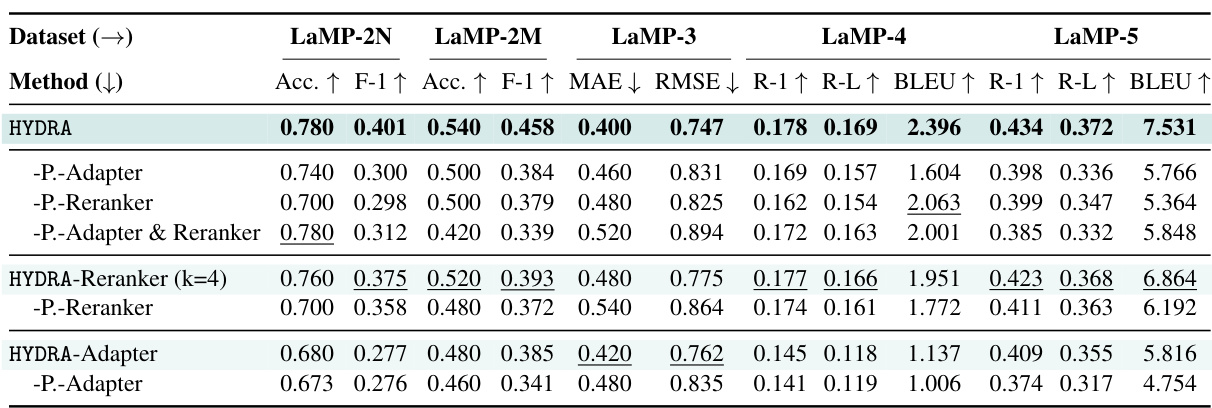
This table presents the main experimental results of HYDRA on five personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model and methods using random sampling, retrieval, and profile augmentation. The metrics used vary depending on the task and include accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU scores. The table highlights the best and second-best performing methods for each task to showcase HYDRA’s improved performance.
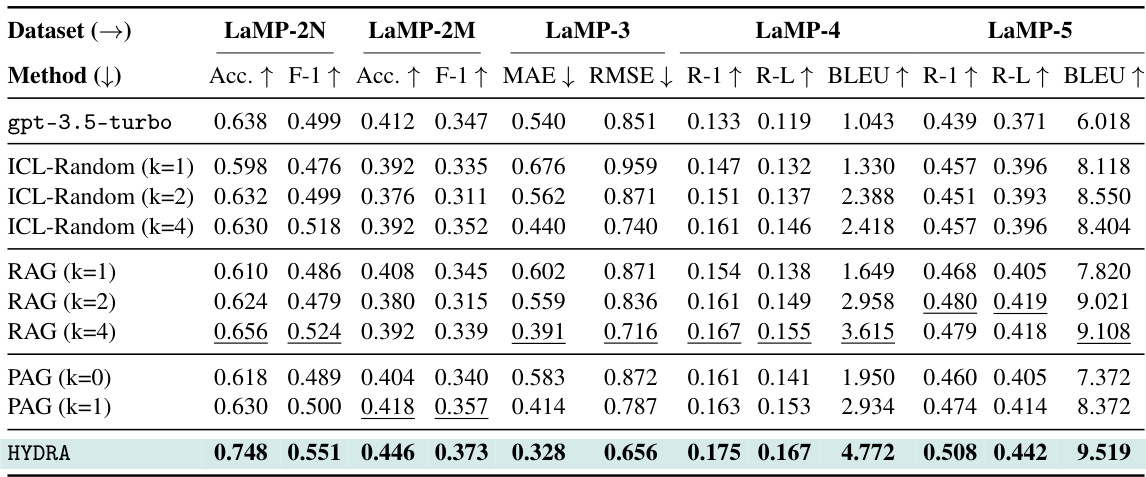
This table presents the main experimental results of HYDRA on five personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model, random in-context learning, retrieval-augmented generation (RAG), and profile-augmented generation (PAG). The table shows accuracy, F1-score (for classification tasks), mean absolute error (MAE), root mean squared error (RMSE), and ROUGE scores (for generation tasks) for each method and task. Higher values are better for accuracy, F1-score, ROUGE-1, ROUGE-L, and BLEU; lower values are better for MAE and RMSE.

This table summarizes existing LLM personalization methods, including prompting-based, learning-based, and the proposed HYDRA framework. It compares these methods based on six key aspects: personalization for specific users; presence of global knowledge; whether the method uses retrieval from user history; whether the retrieval prioritizes relevance or usefulness; whether the method is learning-based; and whether the method supports black-box LLMs. This allows for a clear comparison across methods and highlights HYDRA’s unique capabilities.

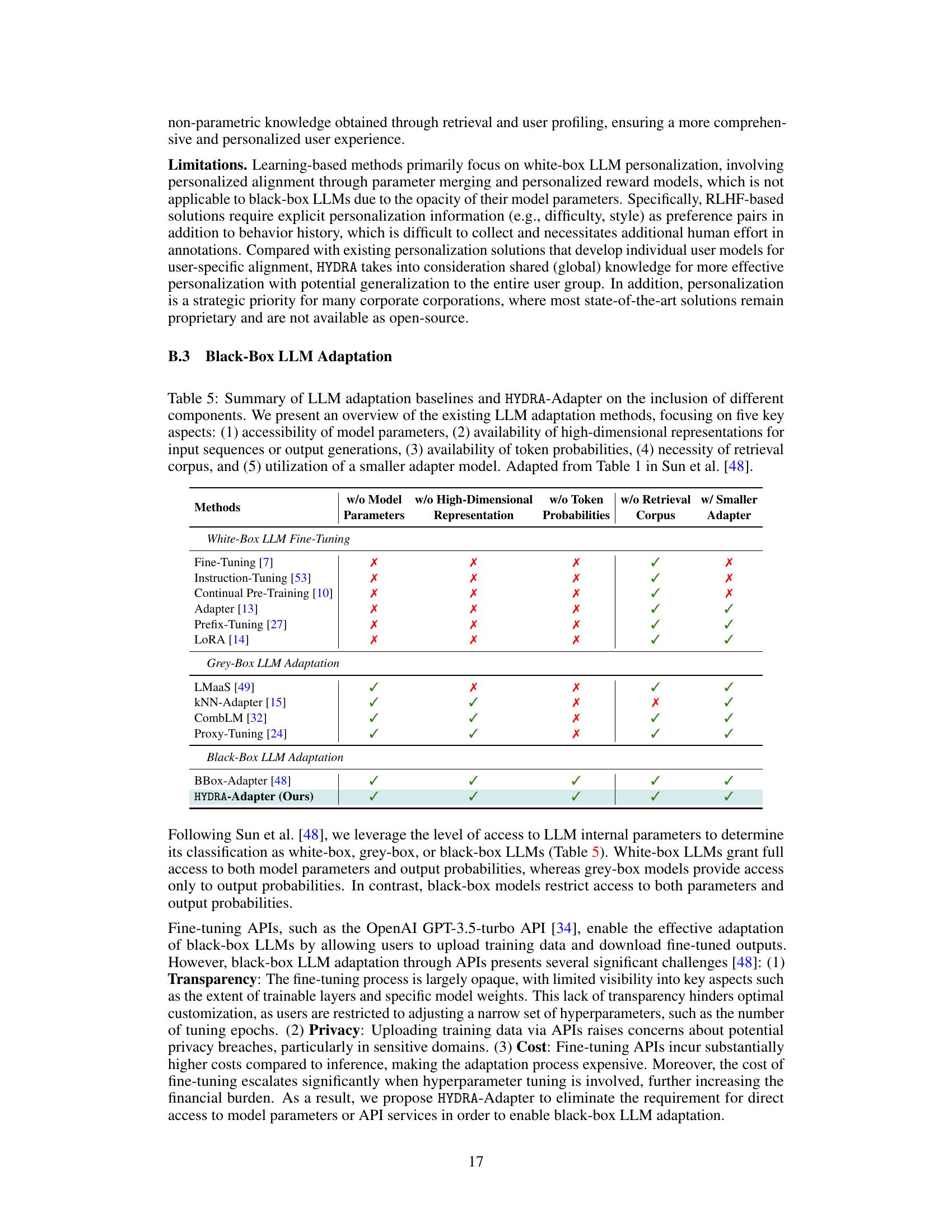
This table compares different LLM adaptation methods based on five key features: access to model parameters, availability of high-dimensional representations, access to token probabilities, need for a retrieval corpus, and the use of a smaller adapter model. It highlights the differences between white-box, grey-box, and black-box LLM adaptation techniques, showing HYDRA-Adapter’s unique position as a method that requires neither full model parameters nor a large retrieval corpus, while still using a smaller adapter model.

This table presents a summary of the five datasets used in the LaMP benchmark experiments. For each dataset, the table provides the type of task (classification or generation), the number of training, validation, and test instances, and the average length of the input and output sequences. Additionally, it shows the number of profiles (unique users) and classes (categories or tags) present in each dataset.

This table presents the main experimental results of HYDRA on five personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model and methods that utilize random sampling, retrieval, and profile augmentation. The metrics used vary depending on the specific task and include accuracy, F1 score, mean absolute error (MAE), root mean squared error (RMSE), ROUGE-1, ROUGE-L, and BLEU. Higher values are better for most metrics, while lower values are better for MAE and RMSE.

This table compares the performance of HYDRA-Adapter with the Personalized BBox-Adapter [48] across three tasks from the LaMP benchmark: LaMP-3 (MAE and RMSE), LaMP-4 (R-1, R-L, and BLEU), and LaMP-5 (R-1, R-L, and BLEU). The results show that HYDRA-Adapter outperforms the baseline across all metrics. This highlights the effectiveness of HYDRA’s adapter design in capturing global and user-specific knowledge to better adapt to personalized model outputs.
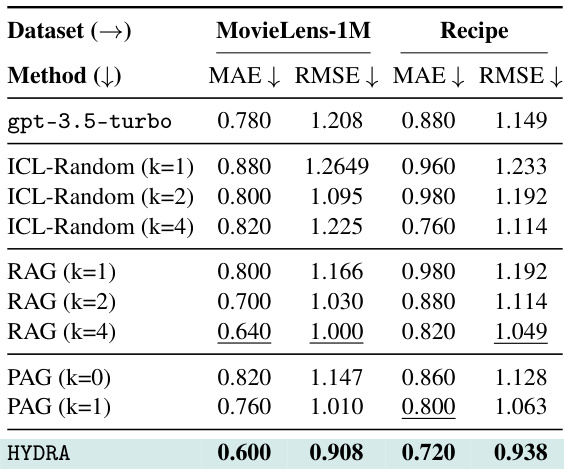
This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model (gpt-3.5-turbo), random in-context learning (ICL-Random), retrieval-augmented generation (RAG), and profile-augmented generation (PAG). The table shows accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU scores for each task, indicating HYDRA’s superior performance in most cases. The ‘k’ value represents the number of retrieved items used in some methods.

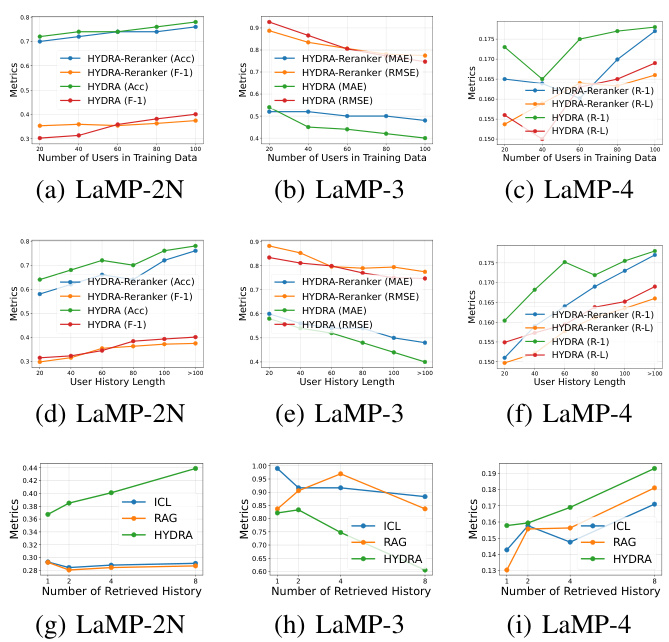
This table shows the time complexity and actual running times for different stages of the HYDRA model across the five LaMP tasks. The time complexity is expressed in Big O notation and reflects the dependence on various factors such as the number of training/test users, number of retrieved history records, sequence length and the hidden dimension (d). The running times are provided for each of the HYDRA components in different modes (training, fitting new users, inference). These results offer insights into the efficiency and scalability of the proposed approach.
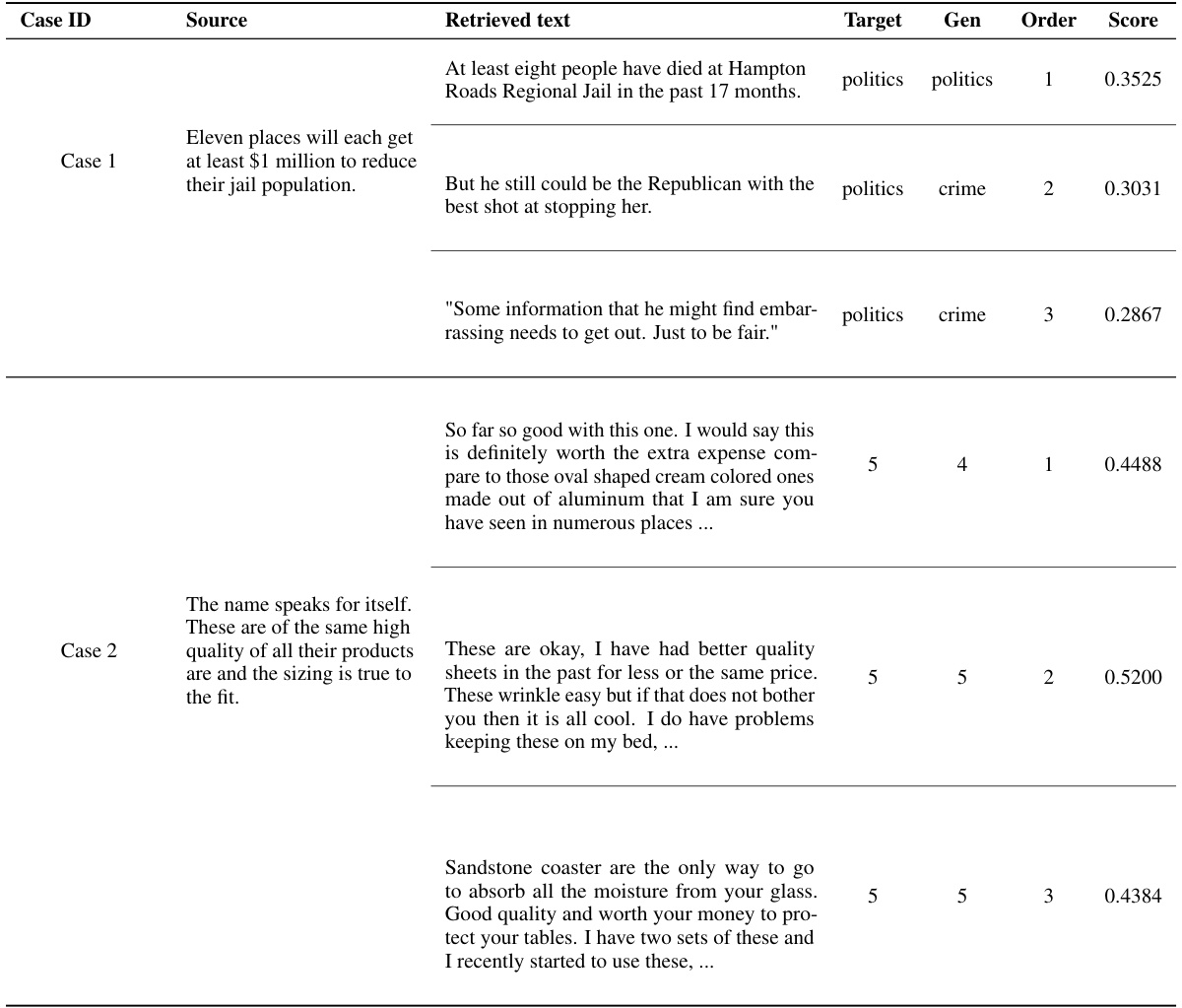
This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model (gpt-3.5-turbo), in-context learning with randomly selected items from user history (ICL-Random), retrieval-augmented prompting (RAG), and profile-augmented prompting (PAG). The table shows accuracy (Acc.), F1-score (F1), mean absolute error (MAE), root mean squared error (RMSE), ROUGE-1 (R-1), ROUGE-L (R-L), and BLEU scores for each task and baseline method. Higher values are generally better for accuracy, F1, ROUGE, and BLEU, while lower values are better for MAE and RMSE.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines (gpt-3.5-turbo, ICL-Random, RAG, and PAG) across multiple evaluation metrics relevant to each task type (accuracy, F1 score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU). The results show HYDRA’s superior performance in most cases, highlighting the effectiveness of the proposed model factorization approach.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines (gpt-3.5-turbo, ICL-Random, RAG, and PAG) across various evaluation metrics relevant to each task type (accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU). The table highlights HYDRA’s superior performance compared to the baselines.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model (gpt-3.5-turbo), random in-context learning, retrieval-augmented generation (RAG), and profile-augmented generation (PAG). The metrics used vary depending on the task and include accuracy, F1-score, mean absolute error (MAE), root mean squared error (RMSE), ROUGE-1, ROUGE-L, and BLEU scores. The table highlights HYDRA’s superior performance across all five tasks.
This table presents the main experimental results of HYDRA on the LaMP benchmark across five different tasks. It compares HYDRA’s performance against several baselines, including a zero-shot model and various prompt-based approaches. The metrics used vary depending on the task (accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, BLEU) and reflect the effectiveness of the different methods in achieving personalization. The table highlights the best-performing methods for each task and indicates whether higher or lower values are better for each metric.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance (accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, BLEU) against several baselines (gpt-3.5-turbo, ICL-Random, RAG, PAG). Higher values are better for accuracy, F1-score, ROUGE scores, and BLEU; lower values are better for MAE and RMSE. The best and second-best results for each task are highlighted.

This table presents the main experimental results of HYDRA on the LaMP benchmark across five different tasks. It compares HYDRA’s performance against several baselines, including a zero-shot model, random in-context learning, retrieval-augmented prompting, and profile-augmented prompting. The results show the accuracy, F1-score (for classification tasks), Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and ROUGE scores (for generation tasks), highlighting HYDRA’s superiority.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines, including a zero-shot model, random in-context learning, retrieval-augmented prompting, and profile-augmented prompting. The results are presented using various metrics appropriate to each task type (accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU), showing HYDRA’s superior performance across all tasks.

This table presents the main experimental results of HYDRA on five different personalization tasks from the LaMP benchmark. It compares HYDRA’s performance against several baselines (gpt-3.5-turbo, ICL-Random, RAG, and PAG), using metrics appropriate to each task (accuracy, F1-score, MAE, RMSE, ROUGE-1, ROUGE-L, and BLEU). The table shows that HYDRA significantly outperforms all baselines across all five tasks, demonstrating its effectiveness in black-box LLM personalization.
Full paper#