TL;DR#
Event cameras offer high temporal resolution but their data is sparse and asynchronous, making traditional methods ineffective. Existing approaches often lose temporal precision or suffer from computational inefficiency. Hybrid methods, while showing progress, still face challenges in efficiently managing both spatial and temporal dimensions.
The proposed EGSST framework uses graph structures to model event data while preserving temporal information and capturing spatial details. It incorporates a Spatiotemporal Sensitivity Module (SSM) and an adaptive Temporal Activation Controller (TAC) to mimic the human eye’s attention mechanism, focusing on dynamic changes. A lightweight multi-scale Linear Vision Transformer (LViT) further enhances processing efficiency. EGSST achieves high accuracy and speed while conserving computational resources, providing a practical solution for object detection in dynamic environments.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and robotics due to its novel approach to object detection using event cameras. It addresses the challenges of processing sparse and asynchronous event data by leveraging graph neural networks and transformers, resulting in a lightweight and efficient solution. The work opens new avenues for research into event-based vision, particularly concerning real-time applications in dynamic environments such as autonomous driving and robotics.
Visual Insights#
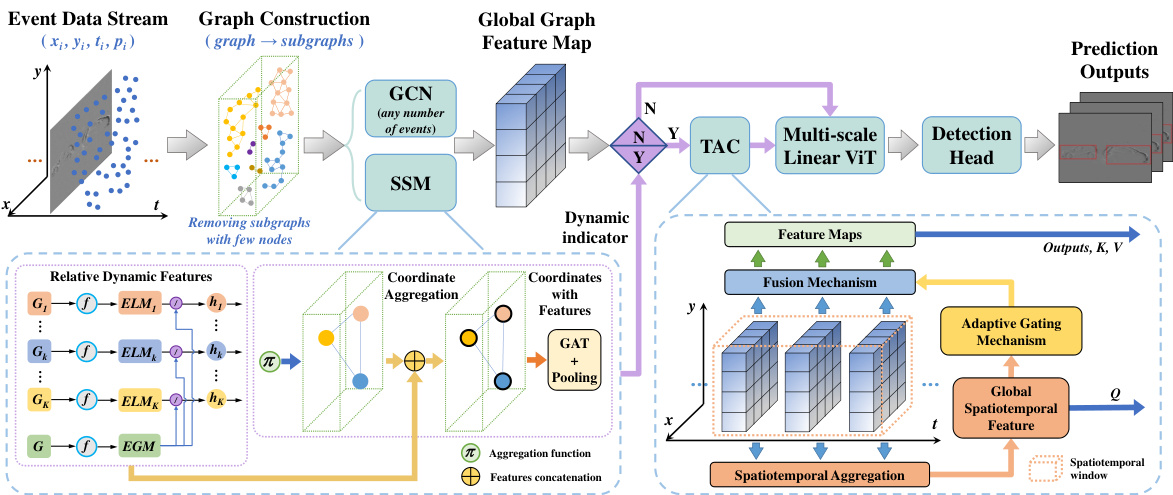
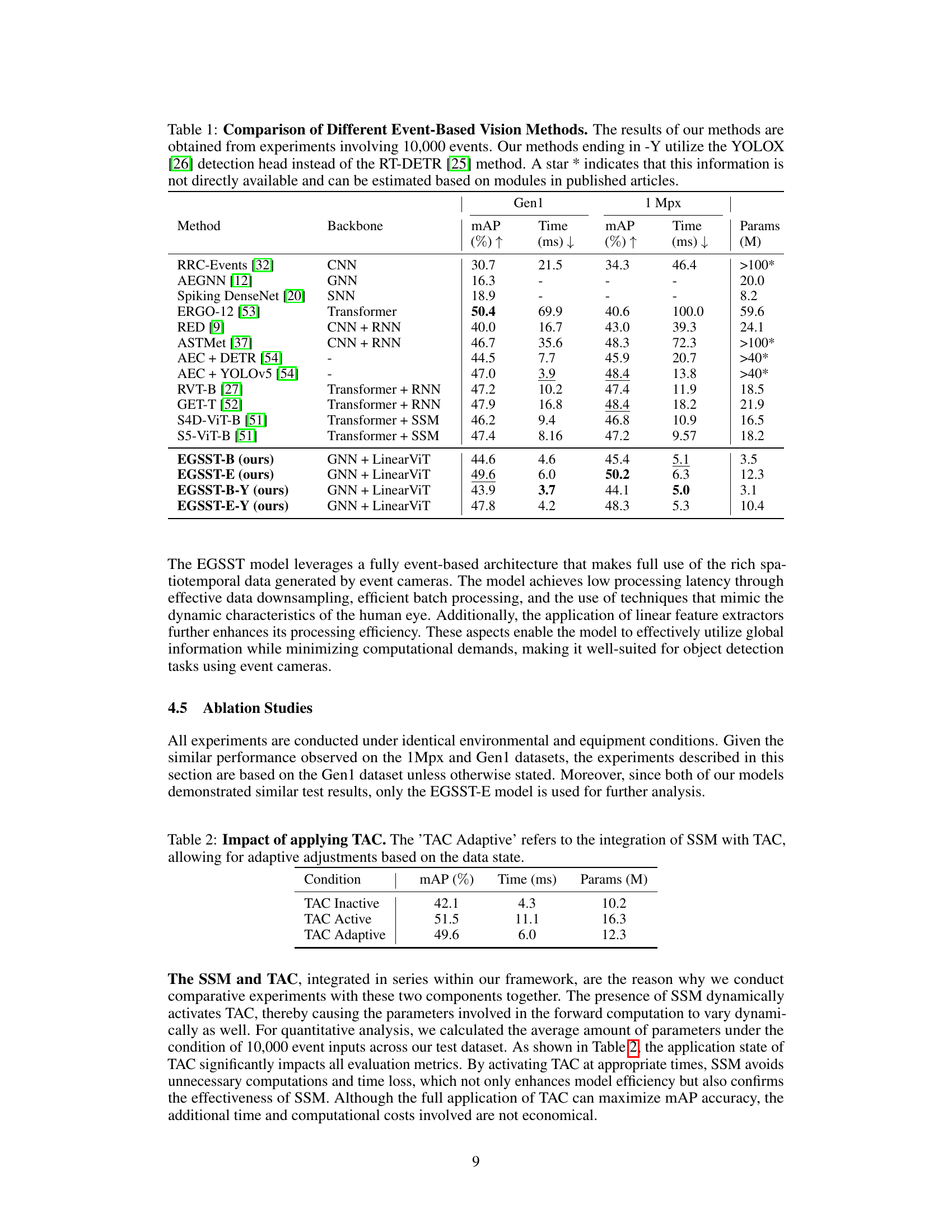
🔼 This figure provides a detailed overview of the EGSST framework, illustrating the flow of event data through various modules. It begins with graph construction from the event stream, followed by processing via a GCN and SSM. The SSM assesses object dynamics and informs the TAC, which either focuses on temporal data or feeds data directly to a Linear ViT. Finally, a detection head produces the predictions.
read the caption
Figure 1: An overview of the proposed EGSST framework. The EGSST is an event-based, lightweight, and efficient framework designed for rapid object detection in event data. A graph is constructed from the data and divided into K connected subgraphs. These subgraphs are fed into a Graph Convolutional Network (GCN) [22] and a SSM. The GCN processes the subgraphs that are not removed to produce a global Graph Feature Map, which preserves both spatial and temporal information. The SSM assesses the dynamics of the entire graph and outputs a dynamic feature indicator, which includes the dynamics of each subgraph and the aggregated dynamics obtained through a Graph Attention Network (GAT) [23]. The TAC is activated based on the output from the SSM to enhance focus on the temporal dimension or to feed the graph feature maps directly into a Multi-scale Linear ViT [24]. Finally, a detection head, such as RT-DETR [25] or YOLOX [26], is employed to generate prediction outputs.
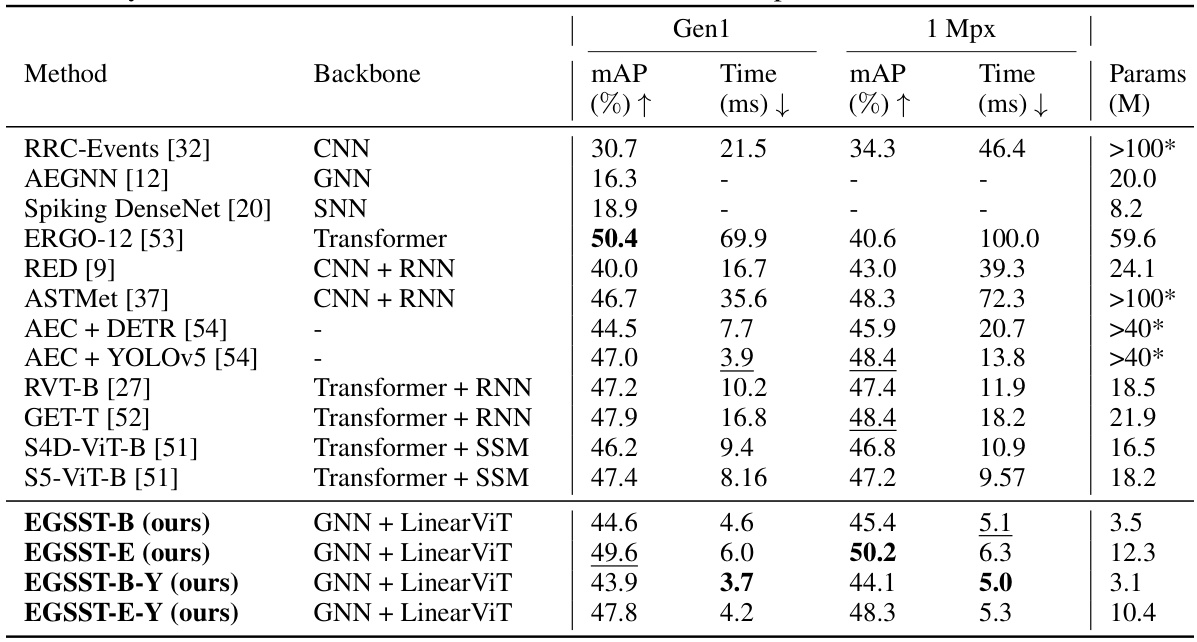
🔼 This table compares the performance of various event-based object detection methods on two datasets (Gen1 and 1 Mpx). The table includes the mAP (mean Average Precision), processing time, and model parameters for each method. The methods are categorized by their backbone architectures (CNN, GNN, Transformer, SNN, etc.) and the results highlight the superior performance of the proposed EGSST model in terms of both accuracy and efficiency.
read the caption
Table 1: Comparison of Different Event-Based Vision Methods. The results of our methods are obtained from experiments involving 10,000 events. Our methods ending in -Y utilize the YOLOX [26] detection head instead of the RT-DETR [25] method. A star * indicates that this information is not directly available and can be estimated based on modules in published articles.
In-depth insights#
Event Data Fusion#
Event data fusion, in the context of this research paper, likely involves integrating data from multiple event cameras or combining event data with other sensor modalities. This is crucial because event cameras offer high temporal resolution but limited spatial information. Fusion strategies could focus on improving spatial accuracy by combining observations from multiple viewpoints or leveraging complementary sensor data like RGB images or LiDAR. A successful fusion technique must effectively address the asynchronous nature of event data and the inherent differences in sampling rates and data representation between various sensor types. The objective is to produce a more complete and robust representation of a dynamic scene exceeding the capabilities of individual sensors alone. Efficient algorithms are essential, given the high volume of data generated by event cameras, and should consider factors such as computational complexity and latency. The fusion approach likely plays a pivotal role in object detection and tracking tasks, enabling accurate and reliable results in dynamic environments. Ultimately, the success of the event data fusion strategy directly impacts the effectiveness and practicality of the overall system.
Graph Transformer#
The concept of a ‘Graph Transformer’ in the context of a research paper likely involves a novel neural network architecture that combines the strengths of graph neural networks (GNNs) and transformers. GNNs excel at modeling relationships within unstructured data, such as graphs, while transformers are adept at processing sequential information and long-range dependencies. A Graph Transformer would likely leverage GNNs to encode the structural information of a graph, potentially representing nodes and edges as embeddings. These embeddings would then be fed into a transformer architecture, enabling the model to capture complex relationships across different parts of the graph, going beyond local neighborhood interactions. The integration of these two powerful architectures could yield a model capable of handling complex, multi-relational data with impressive efficiency and accuracy. This approach would be particularly well-suited for tasks where both the relationships between data points and the sequential order or temporal dynamics are crucial, such as in object detection using event-based cameras or complex social network analysis.
Spatiotemporal SSM#
A Spatiotemporal Sensitivity Module (SSM) in an event-based object detection system is crucial for efficiently processing asynchronous event data. By mimicking human visual attention, the SSM selectively focuses on areas with significant dynamic changes, thus conserving computational resources. This is achieved by quantifying both global and local motion using metrics derived from the event stream’s spatiotemporal characteristics. The SSM’s output, a dynamic indicator, is used to activate a Temporal Activation Controller (TAC), which further optimizes processing by dynamically adjusting the emphasis on temporal information. This adaptive approach is key to balancing accuracy and efficiency, particularly important for event-based vision which processes high-frequency, asynchronous data streams.
Adaptive TAC#
The Adaptive Temporal Activation Controller (TAC) is a crucial module within the proposed event-based object detection framework. Its primary function is to dynamically adjust the focus on the temporal dimension based on the relative dynamics of objects detected by the Spatiotemporal Sensitivity Module (SSM). This adaptive mechanism is inspired by the human visual system’s selective attention, prioritizing rapidly changing elements while ignoring slow-moving ones. This selective approach conserves computational resources by avoiding unnecessary processing of static or slow-moving objects in the temporal dimension. The TAC achieves this by acting as an adaptive gating mechanism which selectively enhances or suppresses temporal features based on a global spatiotemporal feature map that reflects the overall dynamics within the scene. This dynamic weighting and aggregation of temporal information allows the framework to balance efficiency and accuracy effectively. The design of TAC is also particularly important as it mimics the human visual systems’ responsiveness to events, allowing the system to respond faster to important events. In essence, the Adaptive TAC enhances the efficiency and adaptability of the proposed system, making it particularly effective for complex dynamic environments.
Future Enhancements#
Future enhancements for event-based object detection systems like the one presented could involve several key areas. Improving the efficiency of graph neural network (GNN) processing is crucial, as GNNs, while powerful for unstructured data, can be computationally expensive. Exploring more efficient GNN architectures or alternative graph representations could significantly boost speed and scalability. Multi-modal integration, combining event data with traditional camera images or other sensor modalities (e.g., LiDAR), is another promising direction. This could provide complementary information, leading to more robust and accurate object detection, especially in challenging conditions. Developing advanced adaptive attention mechanisms could further enhance the system’s ability to selectively process information, prioritizing dynamic events and reducing computational load. Finally, research into more sophisticated data augmentation techniques tailored specifically for event data, would improve model generalizability and robustness. This would also contribute to better performance on datasets with limited labeling.
More visual insights#
More on figures

🔼 This figure shows a comparison of original event data and the output of the Spatiotemporal Sensitivity Module (SSM). The SSM processes 10,000 events to identify and highlight dynamic regions. Subfigure (a) displays a scene with low relative dynamics, showing limited difference between the original and processed data. Subfigure (b) depicts a more dynamic scene with a faster-moving truck overtaking a slower car. The SSM effectively highlights the faster-moving vehicle by assigning it higher relative dynamic values, showcasing the module’s ability to filter noise and highlight relevant motion.
read the caption
Figure 2: Dynamic Visualization of the SSM. Each image is generated from 10,000 event points, causing slight blurring. However, connected subgraphs effectively filter out background noise, preserving only relevant objects. (a) The scene shows low relative dynamic, hence the distinction is not pronounced. (b) The truck on the right accelerates to overtake, while the car on the left moves slower, making the truck's relative values significantly higher.
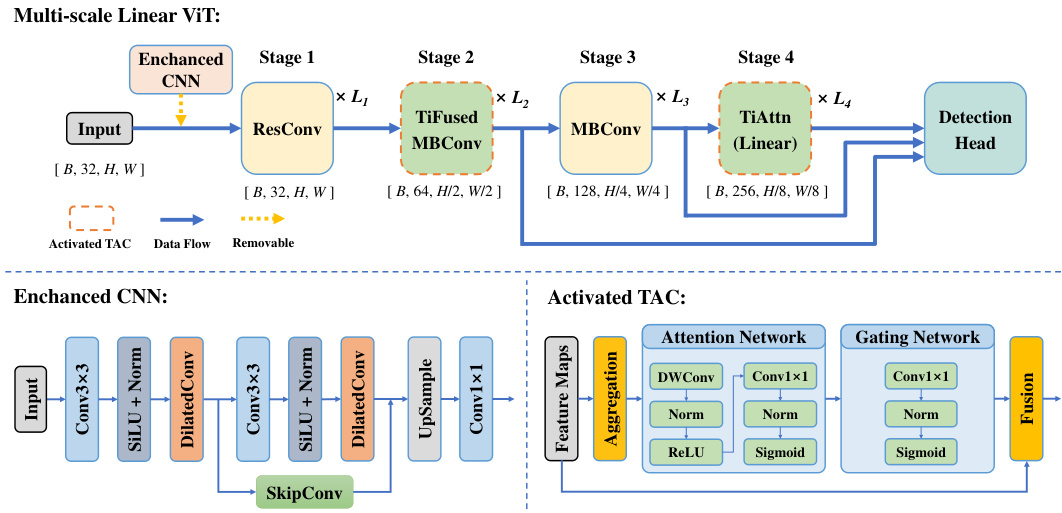
🔼 This figure shows the architecture of the Multi-scale Linear Vision Transformer (ViT) used in the EGSST framework. It details the flow of data through an enhanced CNN (Convolutional Neural Network) for initial feature extraction, followed by four stages of the ViT, each incorporating linear attention mechanisms. Activated Temporal Activation Controllers (TACs) are integrated at stages 2 and 4 to adaptively manage the temporal processing based on the dynamic features. Finally, a detection head processes the output to provide object detection predictions.
read the caption
Figure 3: The flowchart of the Multi-scale Linear ViT. This diagram shows the stages of the Multi-scale Linear ViT, with the removable Enhanced CNN and Activated TAC modules. The Enhanced CNN processes input data through convolutional and normalization layers before passing it to the ViT stages. Activated TACs at Stage 2 and Stage 4 optimize temporal processing and balance efficiency. The data is then sent to the detection head for final object detection.
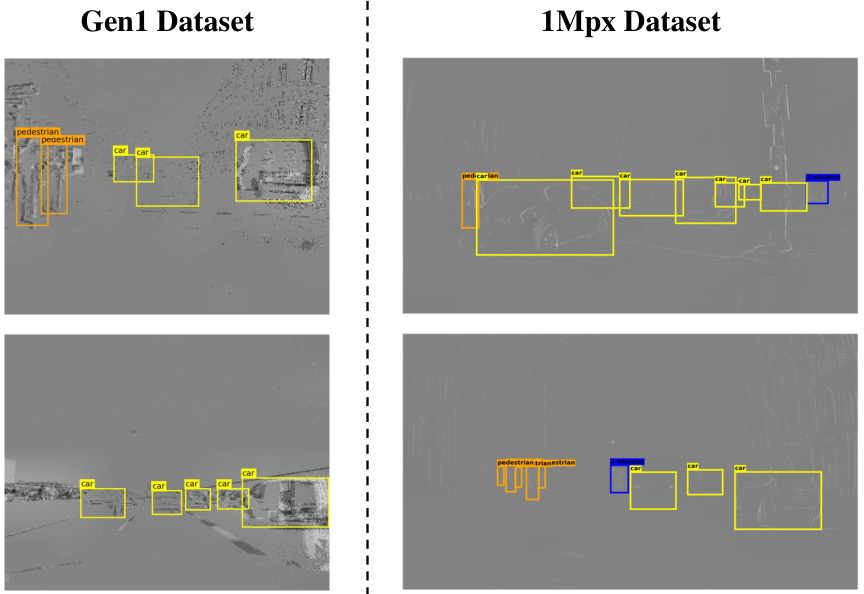
🔼 This figure shows the results of object detection on two datasets (Gen1 and 1Mpx). The images display detected objects with bounding boxes labeled ‘car’ or ‘pedestrian’. The low event count leads to some blurring, but the model still accurately identifies objects, showcasing its robustness and efficacy.
read the caption
Figure 4: Prediction Results. Due to the low accumulated event count, the visualizations appear somewhat blurred. Nevertheless, our model effectively identifies objects within these sparse events, demonstrating its robustness and efficacy.
More on tables

🔼 This table presents the results of an ablation study evaluating the impact of the Temporal Activation Controller (TAC) module on the model’s performance. Three conditions are compared: TAC Inactive (TAC module disabled), TAC Active (TAC module always enabled), and TAC Adaptive (TAC module dynamically enabled based on the output of the Spatiotemporal Sensitivity Module (SSM)). The metrics presented are mean Average Precision (mAP), processing time (in milliseconds), and the number of model parameters (in millions). The results show that a dynamic approach (TAC Adaptive) balances accuracy and efficiency, achieving a good compromise between the always-on TAC (high mAP but longer processing time) and the completely inactive TAC (lower mAP but faster processing time).
read the caption
Table 2: Impact of applying TAC. The 'TAC Adaptive' refers to the integration of SSM with TAC, allowing for adaptive adjustments based on the data state.

🔼 This table presents the results of adding a Convolutional Neural Network (CNN) to the baseline and extended versions of the EGSST model. It shows the impact of this addition on three key metrics: mean Average Precision (mAP), processing time (in milliseconds), and the number of model parameters (in millions). The values in parentheses represent the change in each metric after incorporating the CNN.
read the caption
Table 3: Comparison after incorporating CNN. The increase with the addition of the CNN is shown in parentheses.

🔼 This table shows the performance scalability of the EGSST-E model with different numbers of input events (2,000, 10,000, and 18,000). The metrics measured are mAP (mean Average Precision), Time (processing time in milliseconds), and Params (number of parameters in millions). The table demonstrates how the model’s performance and processing time vary based on the amount of input data. Note that the results are consistent across different input event sizes, showing a high degree of consistency for the model.
read the caption
Table 4: Performance scalability analysis with different number of input events. The results here are all run on the Gen1 dataset and the results on 1Mpx are similar. (Note: T refers to thousand.)

🔼 This table presents the results of an ablation study evaluating the impact of different data augmentation techniques on the model’s accuracy. The techniques include horizontal flipping, zooming in, zooming out, and the proposed dynamic label augmentation method. The mAP (mean Average Precision) is used as the metric to assess the model’s accuracy. The table shows that all methods improve accuracy, but dynamic label augmentation offers the greatest improvement in mAP, highlighting its effectiveness in handling dynamic scenes.
read the caption
Table 5: Accuracy Improvement from Dynamic Label Augmentation. All augmentation techniques improve accuracy, with dynamic augmentation showing the greatest improvement.
Full paper#