TL;DR#
Current data-driven deep learning models struggle with complex image segmentation tasks that require high-level reasoning and understanding of relationships between objects. They often fail when presented with abstract or context-dependent descriptions of objects within a scene. This paper highlights the limitations of existing neural baselines on deictic prompting for image segmentation, which refers to identifying objects based on descriptions that depend heavily on the context of the scene.
DeiSAM is proposed as a neuro-symbolic framework that integrates large language models (LLMs) with differentiable logic reasoners to overcome these challenges. The method uses LLMs to generate logical rules representing deictic descriptions, then combines these with scene graphs to perform differentiable forward reasoning. This enables accurate object identification by matching logical inferences to image regions, outperforming purely neural baselines. The paper also introduces a new benchmark dataset to facilitate further research and evaluation in this area.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of current data-driven neural approaches in image segmentation by incorporating differentiable logic reasoners and large language models. This opens new avenues for more robust and adaptable segmentation methods, particularly for complex scenes and abstract prompts. The introduction of a new benchmark dataset further enhances the value of this research for the wider AI community.
Visual Insights#

🔼 The figure shows the result of object segmentation with a complex textual prompt (deictic prompting). The input is an image of people on a boat, some holding umbrellas. The baseline methods (GroundedSAM and SEEM) incorrectly identify the boat as the target object. In contrast, DeiSAM correctly identifies and segments the people holding umbrellas as the target object specified in the prompt.
read the caption
Figure 1: DeiSAM segments objects with deictic prompting. Shown are segmentation masks with an input textual prompt. DeiSAM (right) correctly segments the people on the boat holding umbrellas, whereas the neural baselines (left) incorrectly segment the boat instead (Best viewed in color).
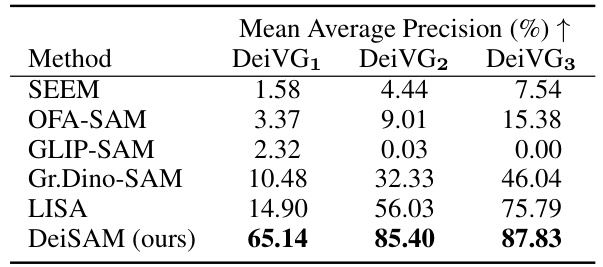
🔼 This table presents the mean average precision (mAP) results for DeiSAM and several neural baseline models on the DeiVG dataset. The DeiVG dataset is categorized into three subsets (DeiVG1, DeiVG2, DeiVG3) based on the complexity of the deictic prompts used. Higher mAP values indicate better performance in segmenting objects based on complex textual descriptions. The table shows that DeiSAM significantly outperforms the baselines across all three subsets, demonstrating its improved ability to handle the challenging task of deictic promptable segmentation.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.
In-depth insights#
Deictic Prompting#
Deictic prompting, as explored in the DeiSAM research paper, presents a novel approach to image segmentation by leveraging the power of natural language. Instead of relying solely on explicit object labels, DeiSAM utilizes deictic descriptions, which are context-dependent phrases like “the object behind the cup.” This requires a higher level of reasoning, moving beyond simple object recognition to an understanding of spatial relationships and contextual cues. The core idea is to bridge the gap between human-like language comprehension and machine learning’s limitations by using LLMs to translate these complex descriptions into formal logic rules. These rules are then applied to a scene graph representation of the image, enabling the system to infer and segment the target object. The use of differentiable logic reasoners makes the whole process end-to-end trainable, offering a substantial advantage over purely data-driven baselines. DeiSAM’s success demonstrates the potential of neuro-symbolic AI, combining the strengths of large language models and differentiable reasoning to tackle challenging tasks that demand advanced reasoning capabilities. The limitations, however, highlight areas for future research such as refining LLM rule generation and addressing the complexities involved in semantic unification between natural language and structured scene graph representations.
Neuro-symbolic Reasoning#
Neuro-symbolic AI aims to bridge the gap between the flexibility of neural networks and the explainability of symbolic reasoning. Neural networks excel at complex pattern recognition but lack inherent explainability, while symbolic systems offer transparency but struggle with the nuances of real-world data. Neuro-symbolic approaches integrate these paradigms, leveraging neural networks to handle complex sensory inputs and symbolic methods to structure, interpret, and reason about the information extracted. This integration can lead to more robust, explainable, and generalizable AI systems. Key benefits include improved accuracy in complex tasks by combining strengths, enhanced explainability through symbolic representation of learned knowledge, and better generalization through structured reasoning. However, challenges remain in effectively combining diverse techniques, and efficient knowledge representation and reasoning remain active research areas. The field actively explores differentiable logic programming, which allows backpropagation through reasoning steps, enabling end-to-end training of neuro-symbolic systems. Developing robust and scalable neuro-symbolic architectures that efficiently handle large datasets and complex reasoning tasks remains a significant ongoing challenge.
DeiVG Benchmark#
The DeiVG benchmark is a crucial contribution, addressing the limitations of existing datasets in evaluating deictic reasoning for image segmentation. Its novelty lies in pairing visual scenes with complex, deictic textual prompts, moving beyond simple object descriptions. This allows for a more realistic assessment of models’ capabilities in understanding nuanced, context-dependent language. The creation of DeiVG involved a careful curation and filtering process to ensure high-quality data, mitigating issues such as ambiguity or noise prevalent in other datasets like Visual Genome. The benchmark’s modularity, incorporating diverse complexity levels (DeiVG1, DeiVG2, DeiVG3), offers a valuable tool for comparing and contrasting different model architectures, specifically those incorporating neuro-symbolic reasoning and those relying on purely neural approaches. Its use in evaluating DeiSAM demonstrates its effectiveness in highlighting the limitations of data-driven baselines, which struggle with complex, high-level reasoning embedded in deictic expressions. By providing a standardized evaluation framework, DeiVG fosters further research and development of more robust and sophisticated vision-language models capable of true deictic understanding.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, a well-executed ablation study is crucial for understanding the model’s behavior and justifying design choices. By removing specific modules (e.g., attention mechanism, a certain layer), the study reveals whether the performance gain comes from a specific component or is a result of the model’s overall architecture. A strong ablation study isolates the effects of individual elements, showing that the improvements are indeed due to the claimed novel contributions and not merely coincidental or arising from other parts of the system. Careful selection of ablation targets is essential. These should be chosen to test specific hypotheses about the system’s workings. Results should quantify the effect of each ablation, ideally with statistical significance testing to rule out randomness. Clearly presented ablation results demonstrate the value of individual components, lending credibility to the proposed approach and highlighting the specific components critical for superior performance. Finally, a discussion of unexpected results or interactions between ablated components can also provide valuable insight, opening avenues for future research and model refinements.
Future Directions#
Future research could explore several promising avenues. Improving the robustness and accuracy of LLM-based logic rule generation is crucial, perhaps through techniques like fine-tuning LLMs on specific datasets or using more constrained prompt engineering. Another critical area is enhancing the semantic unification module, which currently relies on word embeddings and could benefit from more sophisticated methods of cross-referencing and aligning terms from different knowledge sources. Addressing the limitations of current scene graph generators—developing more robust and comprehensive scene graph representations—would further boost performance and enable the handling of more complex visual scenes. Finally, exploring the potential of end-to-end training with larger datasets and more powerful models should lead to a more adaptable and generalizable DeiSAM system. The current work demonstrates significant progress, but further refining these components could unlock its full potential, especially for real-world applications with diverse and challenging visual contexts.
More visual insights#
More on figures
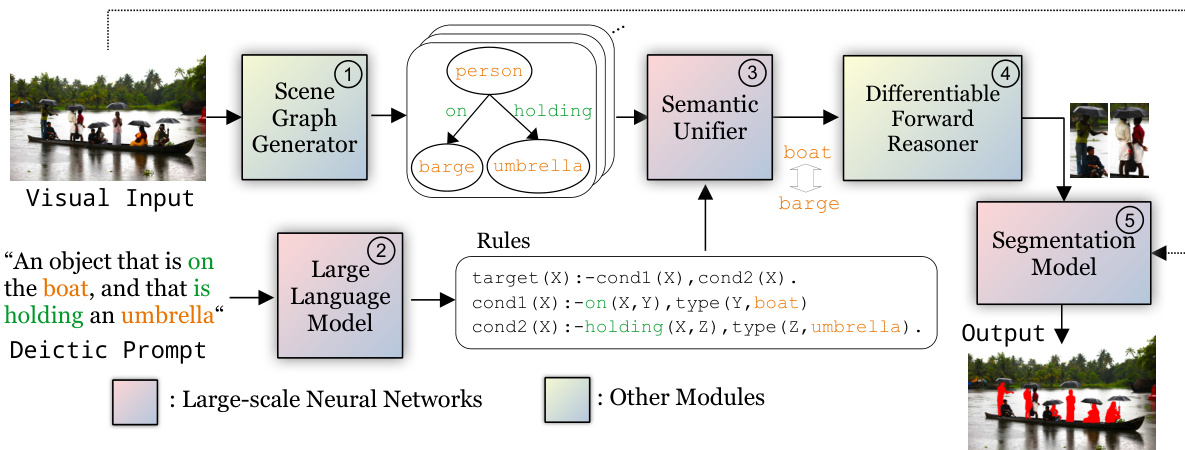
🔼 The figure illustrates the DeiSAM architecture, detailing the flow of information from visual input and deictic prompt through scene graph generation, rule generation via a large language model, semantic unification, differentiable forward reasoning, and finally, object segmentation using a segmentation model. The modular and fully differentiable nature of the pipeline is highlighted, emphasizing the seamless integration of neural networks and neuro-symbolic reasoners.
read the caption
Figure 2: DeiSAM architecture. An image paired with a deictic prompt is given as input. We parse the image into a scene graph (1) and generate logic rules (2) corresponding to the deictic prompt using a large language model. The generated scene graph and rules are fed to the Semantic Unifier module (3), where synonymous terms are unified. For example, barge in the scene graph and boat in the generated rules will be interpreted as the same term. Next, the forward reasoner (4) infers target objects specified by the textual deictic prompt. Lastly, we perform object segmentation (5) on extracted cropped image regions of the target objects. Since the forward reasoner is differentiable (Shindo et al., 2023), gradients can be passed through the entire pipeline (Best viewed in color).

🔼 This figure shows an example image from the DeiVG2 dataset, which is a subset of the Deictic Visual Genome dataset used for evaluating the DeiSAM model. The image depicts a cooler on a picnic table surrounded by other items, such as a blender, drinks, and other picnic supplies. The prompt associated with this image in the dataset would be a complex deictic description, challenging a model to identify the cooler based on its relationship with other objects in the scene, rather than simply by its visual appearance.
read the caption
Figure 3: An example from Deictic Visual Genome (DeiVG2).

🔼 This figure compares the performance of DeiSAM and other neural baselines on a deictic prompting task. The input is a textual prompt describing an object within a complex scene (people on a boat holding umbrellas). DeiSAM successfully identifies the target objects based on the contextual prompt, while neural baselines fail to interpret the prompt correctly. This illustrates the main advantage of DeiSAM over traditional methods.
read the caption
Figure 1: DeiSAM segments objects with deictic prompting. Shown are segmentation masks with an input textual prompt. DeiSAM (right) correctly segments the people on the boat holding umbrellas, whereas the neural baselines (left) incorrectly segment the boat instead (Best viewed in color).

🔼 The figure shows the segmentation masks generated by DeiSAM and several baseline methods on three different images from the DeiVG dataset. Each image has a corresponding deictic prompt (complex textual description). DeiSAM successfully segments the target object in each case, while the baseline models frequently fail to correctly identify and segment the object specified in the prompt, often focusing on irrelevant parts of the scene. This demonstrates DeiSAM’s superior ability to handle complex deictic descriptions. Appendix G contains additional examples.
read the caption
Figure 5: DeiSAM segments objects with deictic prompts. Segmentation results on the DeiVG dataset using DeiSAM and baselines are shown with deictic prompts. DeiSAM correctly identifies and segments objects given deictic prompts (left-most column), while the baselines often segment a wrong object. More results are available in App. G (Best viewed in color).

🔼 This figure demonstrates DeiSAM’s ability to perform abstract reasoning tasks in image segmentation. Two example prompts are given, both requiring logical operations (deleting a red object, then sorting by color). DeiSAM successfully identifies and segments the target object according to the instructions in each prompt. In contrast, the GroundedSAM and LISA baselines fail to produce the correct segmentation results, highlighting DeiSAM’s superior abstract reasoning capabilities.
read the caption
Figure 6: DeiSAM performs abstract reasoning segmentation. When presented with a visual scene paired with an abstract, complex prompt (left), DeiSAM effectively identifies and segments the object specified by the prompt, while neural baselines frequently fail to deduce the target object (right).

🔼 This figure shows the improvement in segmentation masks produced by DeiSAM after end-to-end training. The left shows the input image; the middle shows the segmentation masks and confidence scores before training; the right shows the improved masks and scores after training, highlighting DeiSAM’s ability to learn and improve its performance.
read the caption
Figure 7: DeiSAM can learn to produce better masks. Shown are the input image (left) and target segmentation masks together with confidence scores obtained before (middle) and after (right) end-to-end training DeiSAM. DeiSAM improves the quality of segmentation by learning (Best viewed in color).

🔼 This figure shows the forward reasoning graph used in DeiSAM. It is a bipartite graph with atom nodes (representing facts) and conjunction nodes (representing conjunctions of facts). The edges represent the relationships between the facts according to the logic rules. The bi-directional message passing through this graph allows DeiSAM to perform differentiable logical reasoning, enabling it to identify the objects that satisfy the given deictic prompt.
read the caption
Figure 8: Forward reasoning graph for Program 1 in Listing 1. A reasoning graph consists of atom nodes and conjunction nodes, and is obtained by grounding rules i.e., removing variables by, e.g., X ← obj1, Y ← obj2. By performing bi-directional message passing on the reasoning graph using soft-logic operations, DeiSAM computes logical consequences in a differentiable manner. Only relevant nodes are shown (Best viewed in color).

🔼 This figure compares the performance of DeiSAM against other neural baseline models on a deictic prompting task. The input is a visual scene and a complex textual prompt describing a target object within the scene. DeiSAM successfully identifies and segments the target object (people holding umbrellas on a boat), while the baselines incorrectly segment a different object (the boat itself). This highlights DeiSAM’s superior ability to handle complex, context-dependent descriptions.
read the caption
Figure 1: DeiSAM segments objects with deictic prompting. Shown are segmentation masks with an input textual prompt. DeiSAM (right) correctly segments the people on the boat holding umbrellas, whereas the neural baselines (left) incorrectly segment the boat instead (Best viewed in color).
🔼 This figure compares the performance of DeiSAM against several baseline models on the task of segmenting objects from images using deictic prompts. DeiSAM consistently outperforms the baselines, correctly identifying and segmenting the target objects even in complex scenarios where baselines fail. The deictic prompts provide complex instructions about the target object’s relationships to other objects in the scene. The figure highlights DeiSAM’s superior ability to reason and understand these complex relationships.
read the caption
Figure 5: DeiSAM segments objects with deictic prompts. Segmentation results on the DeiVG dataset using DeiSAM and baselines are shown with deictic prompts. DeiSAM correctly identifies and segments objects given deictic prompts (left-most column), while the baselines often segment a wrong object. More results are available in App. G (Best viewed in color).

🔼 The figure shows a comparison of DeiSAM and neural baseline models on a deictic prompting task. Given the complex prompt ‘An object that is on the boat, and that is holding an umbrella’, DeiSAM correctly identifies and segments the people on the boat holding umbrellas, whereas the baselines incorrectly segment the boat itself. This highlights DeiSAM’s superior ability to handle complex, context-dependent descriptions.
read the caption
Figure 1: DeiSAM segments objects with deictic prompting. Shown are segmentation masks with an input textual prompt. DeiSAM (right) correctly segments the people on the boat holding umbrellas, whereas the neural baselines (left) incorrectly segment the boat instead (Best viewed in color).

🔼 The figure shows a comparison of the results of DeiSAM and other neural baseline models for image segmentation using a deictic prompt. The prompt is ‘An object that is on the boat, and that is holding an umbrella’. DeiSAM successfully identifies and segments the people on the boat holding umbrellas. However, the neural baselines incorrectly identify and segment the boat itself.
read the caption
Figure 1: DeiSAM segments objects with deictic prompting. Shown are segmentation masks with an input textual prompt. DeiSAM (right) correctly segments the people on the boat holding umbrellas, whereas the neural baselines (left) incorrectly segment the boat instead (Best viewed in color).

🔼 This figure compares the performance of DeiSAM against several baselines on the task of segmenting objects based on complex, deictic prompts. Each row presents a different deictic prompt and shows the segmentation masks produced by DeiSAM and several baseline methods. DeiSAM demonstrates superior performance, correctly identifying and segmenting the intended objects even in challenging scenarios. The baselines, however, frequently make errors and fail to accurately identify the target object specified in the prompts.
read the caption
Figure 5: DeiSAM segments objects with deictic prompts. Segmentation results on the DeiVG dataset using DeiSAM and baselines are shown with deictic prompts. DeiSAM correctly identifies and segments objects given deictic prompts (left-most column), while the baselines often segment a wrong object. More results are available in App. G (Best viewed in color).
More on tables
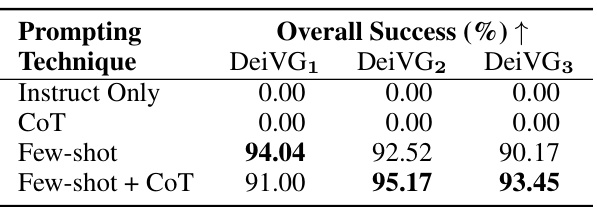
🔼 This table presents the ablation study results on different prompting techniques used for generating logic rules with the Llama-2-13B-Chat large language model. It shows the overall success rate of rule generation on three different subsets of the DeiVG dataset (DeiVG1, DeiVG2, DeiVG3), each representing varying complexities of deictic prompts. The results demonstrate that using few-shot examples significantly improves the success rate, and incorporating chain-of-thought (CoT) prompting further enhances performance, especially for complex prompts.
read the caption
Table 2: Ablations on prompting techniques for rule generation w/ Llama-2-13B-Chat. Few-shot examples are imperative for rule generation with chain-of-thought (CoT) prompting providing additional improvements for complex deictic prompts.

🔼 This table presents a comparison of the performance of three different methods (LISA, GroundedSAM, and DeiSAM) on the RefCOCO+ dataset. The dataset is used to evaluate the models’ ability to perform reference expression tasks in images. The table shows the mean average precision (mAP) for each method on the validation set and two test sets (testA and testB). DeiSAM achieves the highest mAP on all three sets. The results highlight DeiSAM’s superior performance in handling reference expression tasks, especially when compared to the purely neural baselines (GroundedSAM) and other existing neuro-symbolic methods (LISA).
read the caption
Table 3: Comparison on RefCOCO+.
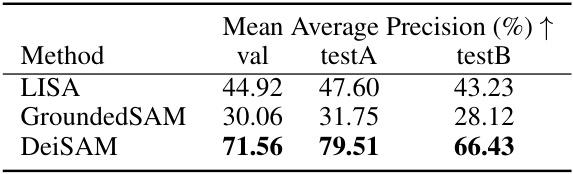
🔼 This table presents a comparison of the performance of different methods on the DeiRefCOCO+ dataset. DeiRefCOCO+ is a modified version of the RefCOCO+ dataset where the descriptive phrases have been removed from the prompts, making them more abstract and challenging. The table shows the mean average precision (mAP) achieved by LISA, GroundedSAM, and DeiSAM on the validation set and test sets A and B. The results highlight DeiSAM’s superior performance compared to the other methods, particularly on the more challenging abstract prompts.
read the caption
Table 4: Comparison on DeiRefCOCO+.

🔼 This table presents the mean Average Precision (mAP) for DeiSAM and baseline models (GroundedSAM and LISA) evaluated on the DeiCLEVR dataset. DeiCLEVR is a dataset designed to evaluate the ability of models to perform abstract visual reasoning. The table shows the mAP for both the ‘Delete’ and ‘Sort’ tasks. The results demonstrate DeiSAM’s significantly higher performance compared to purely neural baselines on abstract reasoning tasks.
read the caption
Table 5: DeiSAM handles abstract visual reasoning. mAP on DeiCLEVR.

🔼 This table shows the mean average precision (mAP) results for three different methods on the DeiVG1 and DeiVG2 datasets. The methods are: DeiSAM-VETO (using a pre-trained VETO model), DeiSAM-Mixture (naive, using a mixture of pre-trained VETO and VG scene graphs with random weights), and DeiSAM-Mixture* (the same as naive, but after end-to-end weight learning). The results demonstrate that end-to-end training significantly improves the performance of DeiSAM.
read the caption
Table 6: End-to-end training improves DeiSAM. Mean Average Precision on the test split of the task of learning SGGs. DeiSAM-VETO uses a trained VETO model (Sudhakaran et al., 2023), DeiSAM-Mixture (naive) uses a mixture of a trained VETO model and VG scene graphs with randomly initialized rule weights, DeiSAM-Mixture* uses the resulted mixture model after the weight learning.

🔼 This table presents a comparison of the performance of DeiSAM and several neural baseline models on the DeiVG dataset. The DeiVG dataset consists of images paired with complex, deictic (context-dependent) textual descriptions. The table shows the mean average precision (mAP) achieved by each model on three different subsets of the dataset (DeiVG1, DeiVG2, DeiVG3), which vary in the complexity of the deictic prompts. Higher mAP indicates better performance.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.

🔼 This table presents a comparison of the performance of DeiSAM and several neural baseline models on the DeiVG dataset. The mean average precision (mAP) is reported for each model on three subsets of the DeiVG dataset (DeiVG1, DeiVG2, DeiVG3), representing different levels of complexity in the deictic prompts. The subscript numbers in the caption indicate the number of relations used in the prompt, reflecting the complexity of the scene description. Higher mAP scores suggest better performance in segmenting objects based on complex deictic descriptions.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.

🔼 This table presents the performance comparison of DeiSAM and several neural baseline models on the DeiVG dataset for deictic prompting. The performance metric used is mean average precision (mAP), which assesses how well the models can identify and segment objects based on complex textual descriptions. The DeiVG dataset is categorized into three subsets (DeiVG1, DeiVG2, DeiVG3) based on the complexity of the prompts (number of relations involved), and the results are shown for each subset. The subscript numbers in the caption refer to this complexity level. Higher mAP indicates better performance in segmenting objects according to the given deictic descriptions.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.

🔼 This table presents the performance comparison of DeiSAM and several neural baseline methods on the DeiVG dataset. The mean average precision (mAP) is reported for each method across three subsets of the DeiVG dataset (DeiVG1, DeiVG2, DeiVG3), which represent different complexities of deictic prompts. Higher mAP values indicate better performance in segmenting objects based on complex textual descriptions.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.
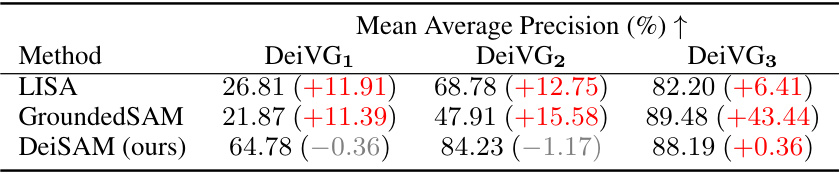
🔼 This table presents the performance comparison of DeiSAM against several neural baseline methods on the DeiVG dataset. The mean average precision (mAP) is reported for each method across three subsets of the DeiVG dataset (DeiVG1, DeiVG2, DeiVG3), representing increasing complexity of deictic prompts. The numbers in parentheses show the improvement (positive values) or decrease (negative values) in mAP compared to the baseline methods.
read the caption
Table 1: DeiSAM handles deictic prompting. Mean Average Precision (mAP) of DeiSAM and neural baselines on DeiVG datasets are shown. Subscript numbers indicate the complexity of prompts.
Full paper#



















