↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Pre-trained vision-language models like CLIP, while powerful, are vulnerable to adversarial attacks that cause misclassifications. These attacks often manipulate the model’s attention mechanism, focusing it on irrelevant visual features. This paper investigates this vulnerability, highlighting the need for more robust models that are resistant to such manipulations.
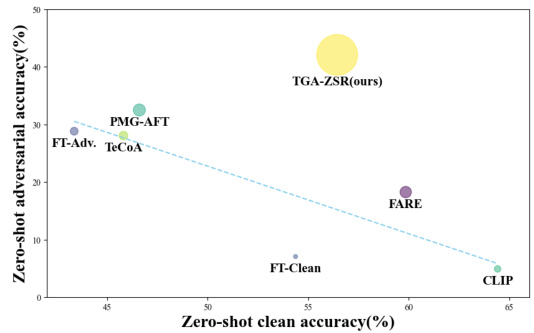
The paper introduces TGA-ZSR, a novel framework that enhances the robustness of vision-language models. TGA-ZSR incorporates two key modules: an Attention Refinement Module and an Attention-based Model Constraint Module. The refinement module aligns attention maps from adversarial and clean examples, improving robustness. The constraint module ensures consistent performance on clean images while boosting overall robustness. Experiments show TGA-ZSR surpasses previous state-of-the-art methods, establishing a new benchmark for zero-shot robust accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models and adversarial robustness. It offers a novel approach to enhance model robustness while preserving generalization capabilities, directly addressing a significant challenge in the field. The proposed method, its interpretability, and the provided experimental results provide a valuable benchmark and inspire further research into improving the robustness of large-scale models.
Visual Insights#

This figure shows a comparison of original images and their corresponding adversarial examples. Each row presents an image, its attention map highlighting the areas the model focused on during classification, the adversarial version of that image created using the PGD attack method, and finally, the attention map for the adversarial example. The goal is to visually demonstrate how adversarial attacks subtly alter the image, causing a shift in the model’s attention and leading to misclassification (incorrect labels are shown in red).
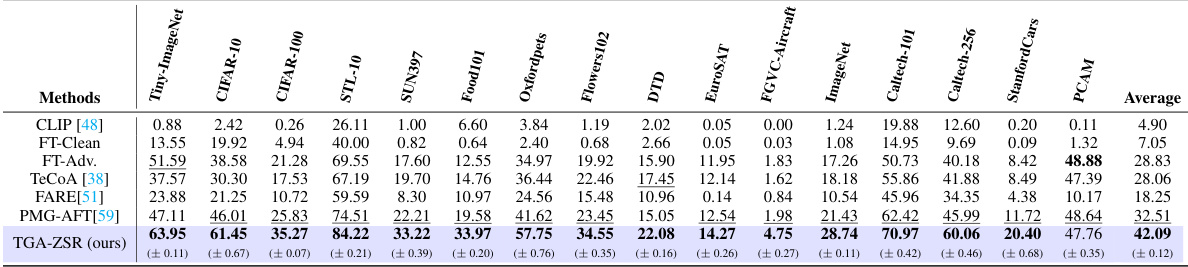
This table presents the zero-shot robust accuracy results for several methods on 16 different datasets. Each method was first trained on Tiny-ImageNet using adversarial examples generated by the Projected Gradient Descent (PGD) method and then tested on the other datasets against adversarial examples. The optimal and second-best accuracy values are highlighted for each dataset, providing a clear comparison of the different approaches in terms of robustness. The values in parentheses indicate the standard deviation of the results.
In-depth insights#
Adversarial Robustness#
The concept of adversarial robustness in deep learning models, especially vision-language models (VLMs), is crucial because of their susceptibility to adversarial attacks. These attacks involve adding small, often imperceptible, perturbations to input data, causing misclassifications or altered outputs. Adversarial training, a common defense mechanism, involves augmenting training data with adversarial examples. However, this method faces challenges, particularly with large-scale models, due to increased computational cost and potential overfitting. Zero-shot adversarial robustness, focusing on the model’s ability to generalize to unseen adversarial examples without retraining, is a more relevant area of research for large VLMs. The paper investigates the effects of adversarial attacks on text-guided attention within VLMs, proposing that adversarial perturbations induce shifts in the attention mechanism. This insight is leveraged to develop a novel framework for improving zero-shot robustness by aligning and constraining attention maps, thereby enhancing model resilience while preserving performance on clean data. Interpretability is also enhanced by the use of text-guided attention, offering insights into the model’s decision-making process and the impact of adversarial examples.
Attention Refinement#
The concept of ‘Attention Refinement’ in the context of enhancing zero-shot robustness in vision-language models is a crucial innovation. It directly addresses the observation that adversarial attacks cause significant shifts in the model’s attention mechanism, leading to misclassifications. The core idea is to align the attention map generated from an adversarial example with the attention map obtained from a clean example using the same textual prompt. This alignment process, achieved by minimizing the distance (e.g., using L2 loss) between these attention maps, forces the model to focus on the same relevant visual features, irrespective of the presence of adversarial perturbations. This method is particularly valuable as it enhances robustness without requiring significant retraining, which is computationally expensive and prone to overfitting for large-scale models. The success of Attention Refinement highlights the importance of understanding and leveraging the role of attention in improving model robustness. Moreover, it suggests a path towards creating more interpretable models by revealing how attention mechanisms respond to adversarial inputs. This approach avoids sacrificing performance on clean images by focusing solely on correcting attention shifts rather than altering the model’s overall feature representation. Future research could explore alternative methods for aligning attention maps or adapting this technique to other vision-language tasks and model architectures.
TGA-ZSR Framework#
The TGA-ZSR framework is a novel approach to enhancing zero-shot robustness in vision-language models, particularly addressing vulnerabilities to adversarial attacks. It cleverly leverages the inherent text-guided attention mechanism within such models, recognizing that adversarial perturbations often induce shifts in this attention. The framework comprises two key modules: the Attention Refinement Module, which aligns adversarial attention maps with those from clean examples, thus improving robustness; and the Attention-based Model Constraint Module, which ensures consistent performance on clean samples while enhancing overall robustness. This dual approach tackles the challenge of maintaining model generalization while boosting its resilience to adversarial attacks. The framework’s strength lies in its interpretability, providing valuable insights into how attention shifts under attack, thereby improving the trustworthiness and reliability of vision-language models in real-world applications. The use of text-guided attention is a particularly elegant solution, avoiding the need for extensive retraining or architectural modifications, making it a practical and effective method.
Interpretability Matters#
The heading “Interpretability Matters” highlights a critical aspect of any machine learning model, especially within the context of computer vision and natural language processing. Explainability is crucial for building trust and ensuring the reliable deployment of complex AI systems. In vision-language models, understanding how the model combines visual and textual information to form its conclusions is vital for identifying potential biases or weaknesses. Attention mechanisms, as mentioned in the paper, are a useful tool for interpreting the model’s decision-making process, but more advanced techniques might be needed to fully grasp the complexities of high-dimensional interactions. Adversarial attacks highlight the importance of interpretability: The ability to interpret how such attacks affect the model’s attention maps is crucial for designing robust defenses. Therefore, methods for understanding and improving the model’s robustness, such as the “Text-Guided Attention for Zero-Shot Robustness” (TGA-ZSR) approach described in the paper, should be accompanied by detailed interpretability analysis to ensure complete transparency and build confidence in the reliability and trustworthiness of the system.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the robustness of the model against stronger adversarial attacks such as AutoAttack remains a key challenge, potentially requiring more sophisticated attention refinement strategies. Further investigation into the interpretability of adversarial attacks by analyzing attention maps could offer insights into the model’s decision-making process under attack. The exploration of different attention mechanisms beyond text-guided attention could lead to improved robustness and generalization. Additionally, applying the proposed approach to diverse vision-language model architectures and downstream tasks would showcase its broader applicability and effectiveness. Finally, a significant area of future work involves addressing the computational overhead of the proposed method in order to make it more efficient and scalable for real-world deployment.
More visual insights#
More on figures

This figure illustrates the TGA-ZSR framework. Adversarial examples are generated and fed into a target image encoder. The framework incorporates two modules: the Attention Refinement module, which aligns text-guided attention from adversarial and clean examples, and the Attention-based Model Constraint module, which maintains model performance on clean samples while improving robustness. Text embeddings from a frozen text encoder provide guidance throughout the process.
This figure visualizes the effect of adversarial attacks on image classification using a vision-language model. It shows four rows, each representing an original image, its corresponding attention map (highlighting the areas the model focuses on), a generated adversarial example (a slightly altered version of the original designed to fool the model), and the attention map of the adversarial example. The difference in attention maps between the original and adversarial images illustrates how the adversarial perturbation changes the model’s focus, often leading to misclassification. The labels in black indicate correct classifications, while labels in red indicate misclassifications due to the adversarial attack.
More on tables
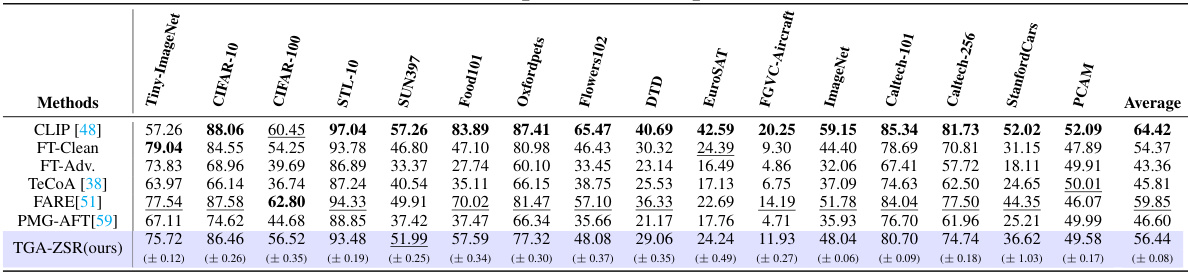
This table presents the zero-shot robust accuracy results achieved by various methods on 16 datasets. The images in each dataset were attacked using 100 steps of the Projected Gradient Descent (PGD) method. The table highlights the best-performing method in bold and the second-best in underlines, providing a clear comparison of different approaches to improving the robustness of vision-language models against adversarial attacks.
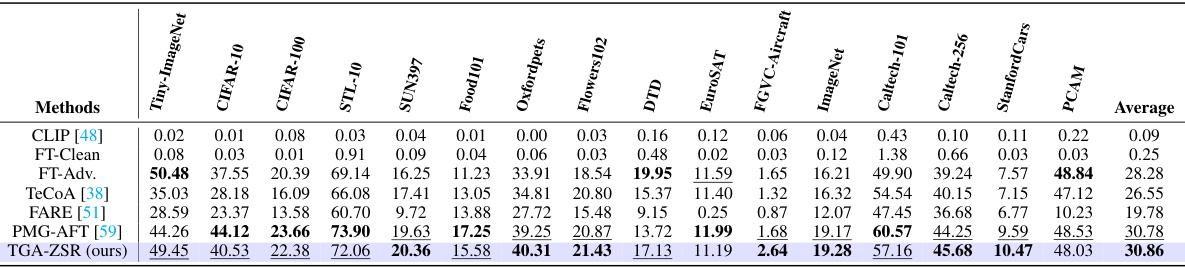
This table presents the zero-shot robust accuracy results of various methods on 16 datasets. The images in the datasets were attacked using the Projected Gradient Descent (PGD) method with 100 steps. The table compares the performance of different methods, including CLIP, fine-tuning with clean and adversarial examples, TeCoA, FARE, PMG-AFT, and TGA-ZSR (the proposed method). The best and second-best accuracy results for each dataset are emphasized, along with standard deviations.

This table presents the zero-shot robust accuracy achieved by different methods on 16 datasets. Each dataset’s images were attacked using 100 steps of the Projected Gradient Descent (PGD) method. The table highlights the best performing method (in bold) and second-best performing method (underlined) for each dataset, providing a comprehensive comparison of zero-shot robustness.

This table presents the zero-shot robust accuracy results of several methods (including the proposed TGA-ZSR) on 16 image classification datasets. Each dataset was tested using images that were adversarially attacked with 100 steps of Projected Gradient Descent (PGD). The table compares the performance of different methods on clean images, providing a comprehensive evaluation of their robustness against adversarial attacks. The optimal and second-best accuracy for each dataset are highlighted for easy comparison.
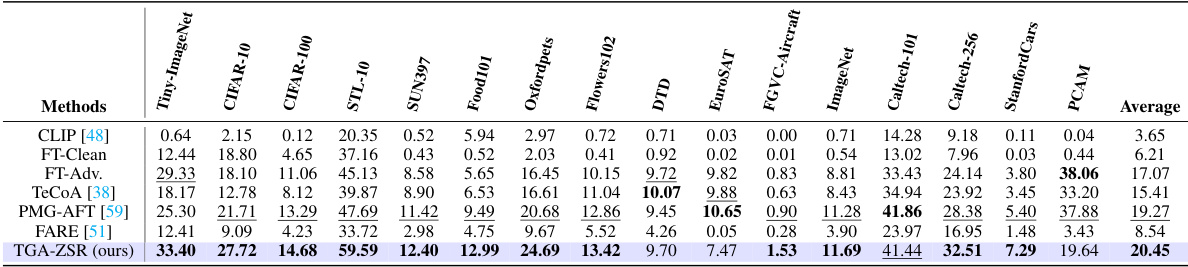
This table presents the zero-shot robust accuracy results of different methods on 16 datasets. The images in each dataset were attacked using 100 steps of the Projected Gradient Descent (PGD) method. The table shows the optimal and second-best accuracies for each method across all datasets, highlighting the superior performance of the proposed TGA-ZSR method. Standard deviations are also included to indicate the variability of the results.
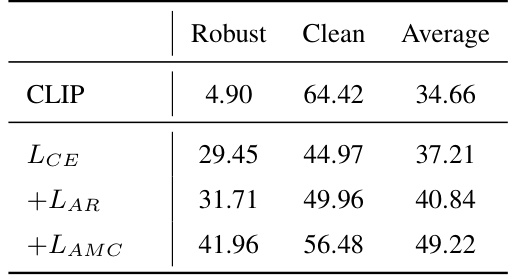
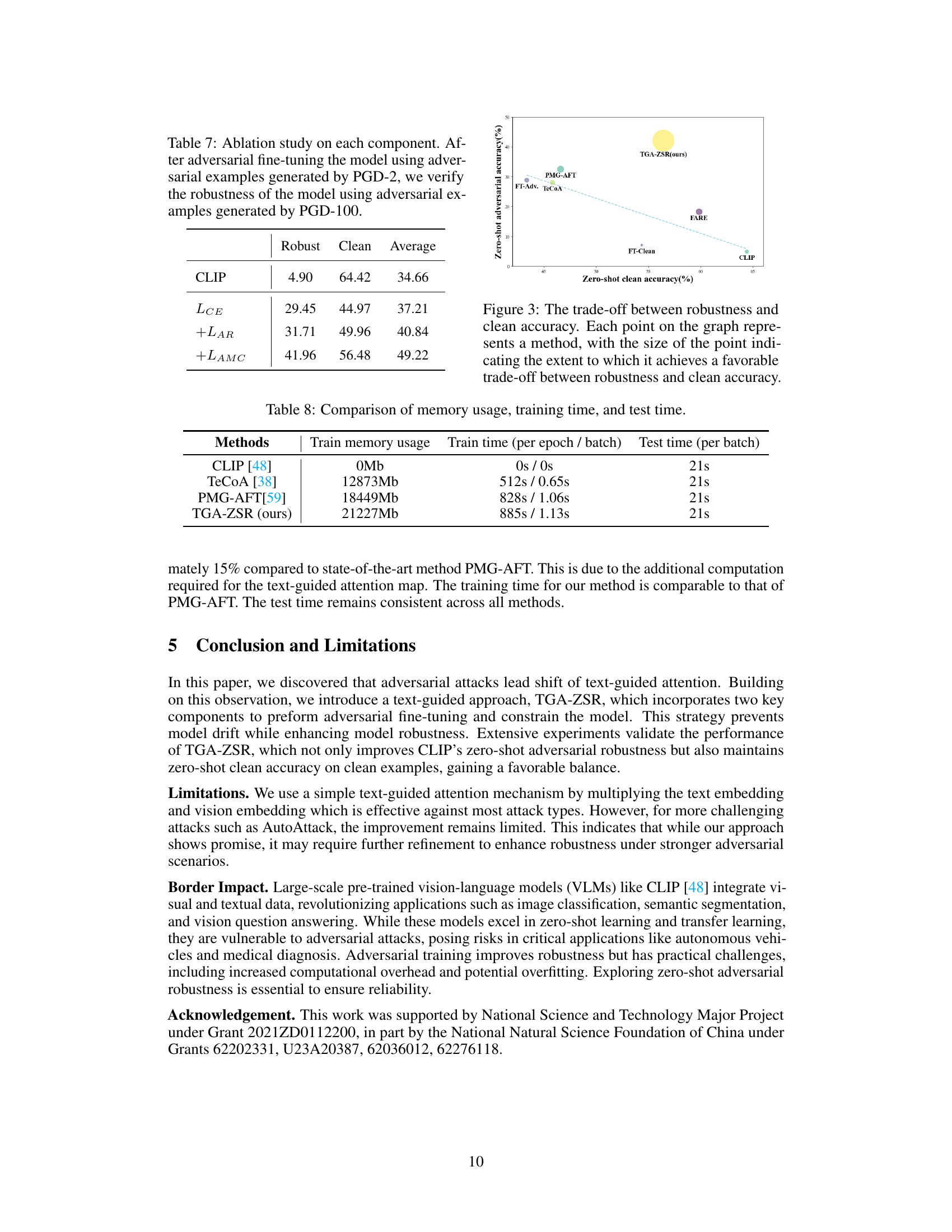
This table presents the results of an ablation study on the proposed TGA-ZSR framework. It shows the impact of each component (Attention Refinement Module, Attention-based Model Constraint Module) on both robust accuracy and clean accuracy. The results are presented as percentage values for zero-shot robust accuracy and zero-shot clean accuracy, with an average column summarizing the overall performance. The table helps to understand the contribution of each module to the overall performance gains of the method.

This table presents the zero-shot robust accuracy results for several methods (CLIP, FT-Clean, FT-Adv, TeCoA, FARE, PMG-AFT, and TGA-ZSR) evaluated on 16 datasets. Each method’s performance is assessed using images that have been adversarially attacked with 100 steps of the Projected Gradient Descent (PGD) attack. The optimal accuracy for each dataset is shown in bold, and the second-best is underlined. Parentheses indicate the standard deviation of the results.

This table presents the zero-shot robust accuracy results for various vision-language models on 16 different datasets. Each model was tested against images that had been adversarially perturbed using the Projected Gradient Descent (PGD) method. The results showcase the effectiveness of the proposed TGA-ZSR method compared to several existing state-of-the-art methods. The best performance for each dataset is shown in bold, while the second-best performance is underlined. Standard deviations are also provided.

This table presents the zero-shot robust accuracy results of different methods on 16 datasets, where the images were attacked using 100 steps of Projected Gradient Descent (PGD). The methods compared include CLIP (baseline), fine-tuning on clean data (FT-Clean), fine-tuning on adversarial data (FT-Adv.), TeCoA, FARE, PMG-AFT, and the proposed TGA-ZSR. The optimal and second-best accuracies are highlighted for each dataset. Parentheses show standard deviations.
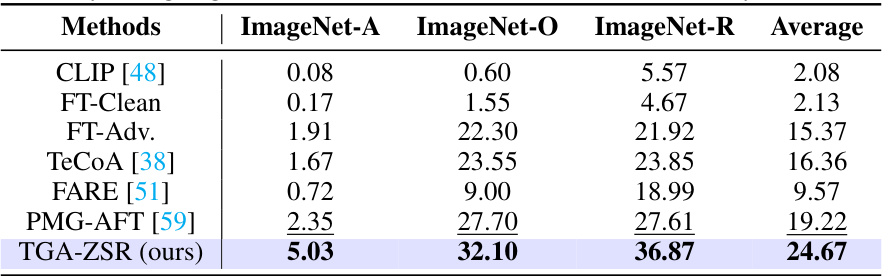
This table presents the zero-shot robust accuracy results for three additional datasets (ImageNet-A, ImageNet-O, ImageNet-R) besides the Tiny-ImageNet dataset. Several methods are compared, including the baseline CLIP model and state-of-the-art techniques. The table shows the performance of each method under the PGD attack with 100 steps. The optimal and second-best accuracy values are highlighted for better clarity.

This table presents the zero-shot robust accuracy results for various methods on 16 different datasets. Each method was initially trained on the Tiny-ImageNet dataset, and tested for robustness against the Projected Gradient Descent (PGD) attack. The optimal and second-best accuracies are highlighted for each dataset, providing a comprehensive comparison of performance.

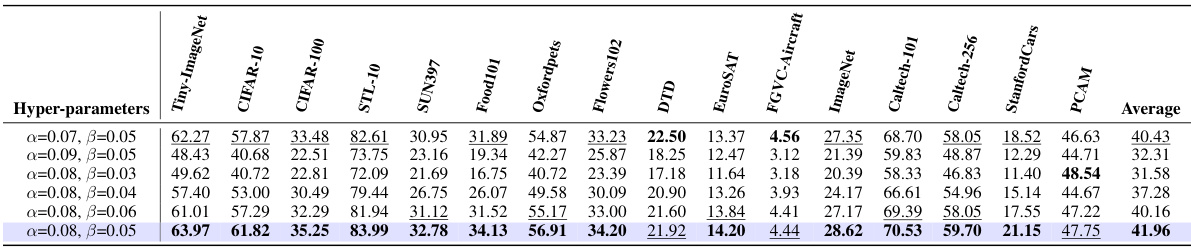
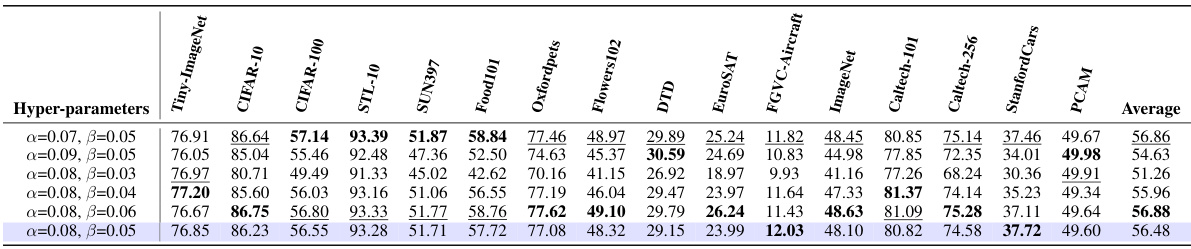
This table presents the results of hyperparameter tuning on the validation set of the Tiny-ImageNet dataset. Different combinations of alpha (α) and beta (β) values were tested, and the table shows the resulting zero-shot robust accuracy, zero-shot clean accuracy, and the average of the two. This is used to determine optimal values for α and β which are then used in the final evaluation.
This table presents the zero-shot robust accuracy results for various vision-language models on 16 different datasets. Each model was tested using images adversarially attacked with 100 steps of Projected Gradient Descent (PGD). The table compares the performance of several methods including the baseline CLIP model, fine-tuning with clean and adversarial data, and other state-of-the-art techniques. The best performing model for each dataset is highlighted in bold, indicating superior robustness to adversarial attacks.
This table presents the zero-shot robust accuracy results of different methods on 16 datasets. Each dataset’s images were attacked using 100 steps of the Projected Gradient Descent (PGD) method. The table compares the performance of the proposed TGA-ZSR method against several baselines, including CLIP, fine-tuning on clean data (FT-Clean), fine-tuning on adversarial data (FT-Adv), TeCoA, FARE, and PMG-AFT. The best and second-best results are highlighted for each dataset, with standard deviations included.

This table presents the zero-shot robust accuracy results for various methods on 16 different datasets. Each dataset was tested using images that had been adversarially attacked with 100 steps of Projected Gradient Descent (PGD). The table highlights the best performing method (in bold) and the second-best method (underlined) for each dataset, demonstrating the efficacy of the proposed TGA-ZSR approach in enhancing zero-shot robustness compared to existing methods. Standard deviation values are provided in parentheses to illustrate the variability of the results.

This table presents the zero-shot robust accuracy of different methods on 16 datasets, where images were attacked using 100 steps of Projected Gradient Descent (PGD). The methods compared include CLIP (baseline), fine-tuning on clean data (FT-Clean), fine-tuning on adversarial examples (FT-Adv.), TeCoA, FARE, PMG-AFT, and the proposed TGA-ZSR method. The optimal and second-best accuracies for each dataset are highlighted. Parentheses show standard deviation.

This table presents the zero-shot robust accuracy results of different methods on 16 datasets. The images were attacked using 100 steps of the Projected Gradient Descent (PGD) method. The optimal and second-best accuracies are highlighted for comparison, showing the effectiveness of the proposed method (TGA-ZSR) compared to existing techniques.

This table presents the zero-shot robust accuracy results of different methods on 16 datasets. The images in these datasets were attacked using 100 steps of Projected Gradient Descent (PGD). The table highlights the best performing method (in bold) and the second-best method (underlined) for each dataset. Parentheses show standard deviations of the accuracy scores.

This table presents the zero-shot robust accuracy results of different methods on 16 datasets. The images in each dataset were attacked using the Projected Gradient Descent (PGD) method for 100 steps. The best performing method for each dataset is shown in bold, and the second-best is underlined. The results demonstrate the relative robustness of different approaches against adversarial attacks.

This table presents the zero-shot robust accuracy of different methods on 16 datasets. The images were adversarially attacked using 100 steps of Projected Gradient Descent (PGD). The table compares the performance of several methods, including CLIP, fine-tuning with clean and adversarial examples, TeCoA, FARE, PMG-AFT, and the proposed TGA-ZSR. The best and second-best accuracy are highlighted for each dataset.
Full paper#