↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning, while aiming to protect user data by sharing only gradients, is vulnerable to gradient inversion attacks. Existing attacks struggle with text data, achieving only approximate reconstruction of small batches and short sequences. This poses a significant challenge to the privacy guarantees of federated learning, particularly when applied to large language models.
DAGER, a novel algorithm, addresses these limitations by leveraging the low-rank structure of self-attention layers in transformers and the discrete nature of token embeddings. It achieves exact reconstruction of full input text batches, significantly outperforming existing methods in speed and scalability. This breakthrough has significant implications for ensuring data privacy in federated learning setups using LLMs, highlighting the urgent need for robust defense mechanisms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and privacy-preserving machine learning. It highlights a significant vulnerability in using large language models (LLMs) within federated learning frameworks by demonstrating that private training data can be accurately reconstructed from shared gradients. This discovery necessitates the development of robust defense mechanisms to protect sensitive information. Its findings are particularly relevant given the increasing prevalence of LLMs in collaborative settings and the growing need for robust data privacy protection. The work opens up new avenues for research into secure aggregation techniques, differential privacy methods, and other safeguards to enhance privacy in collaborative machine learning scenarios.
Visual Insights#
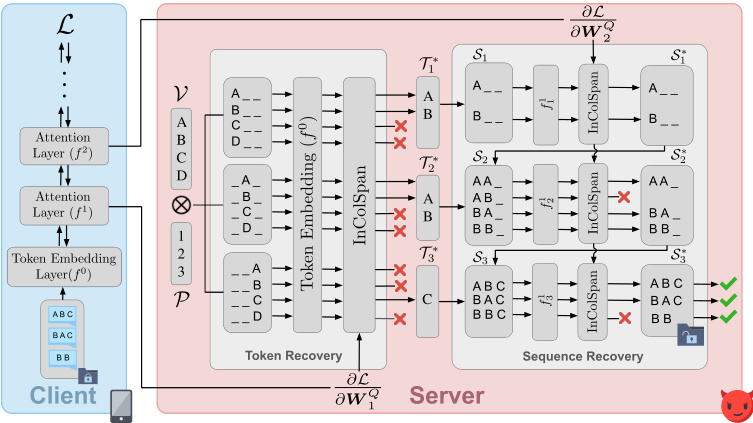
This figure illustrates the overall working mechanism of DAGER. The process starts with the client’s token embeddings which are processed through multiple layers of self-attention within a Transformer model. The server only receives the gradients of these layers. DAGER leverages a low-rank property of the self-attention gradients to check which tokens were used by the client. This ‘span check’ is first performed on the first layer of self-attention, revealing the possible tokens at each position. Then, these tokens are used in a recursive process to create partial sequences. The second layer of self-attention gradient information is used to filter these sequences, resulting in the exact recovery of the client’s input sequence. The figure shows multiple possible sequence generation scenarios and how the algorithm eliminates incorrect sequences until the correct one is identified.
This table compares the performance of DAGER against two state-of-the-art gradient inversion attack algorithms, TAG and LAMP. The comparison is done across different datasets (COLA, SST-2, Rotten Tomatoes) and varying batch sizes (B=1, 2, 4, 8). The results are presented in terms of ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams, respectively, between the original text and the reconstructed text. Higher ROUGE scores indicate better reconstruction quality.
In-depth insights#
Gradient Leakage#
Gradient leakage attacks exploit the information inadvertently revealed in model gradients during federated learning. These attacks aim to reconstruct sensitive training data by analyzing the gradients shared by clients. While initially successful with image data, applying these attacks to text data presents a significant challenge due to the discrete nature of text and the complexity of language models. Recent work has shown that approximate reconstruction is possible for small batches and short sequences, but recovering full batches of text data exactly remained a significant hurdle. The discrete nature of language models, combined with the low-rank structure of self-attention layer gradients, are leveraged to improve the accuracy of these attacks. Research highlights the need for more robust privacy-preserving techniques in federated learning, especially given the growing capabilities of large language models.
DAGER Attack#
The DAGER attack is a novel gradient inversion method targeting large language models (LLMs). Unlike prior work, DAGER achieves exact recovery of full input batches, a significant leap in capability. This is achieved by leveraging the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings. For decoders, a greedy algorithm efficiently reconstructs sequences; for encoders, heuristics make exhaustive search feasible. DAGER surpasses previous attacks in speed and scalability, handling significantly larger batch sizes and longer sequences, with superior reconstruction quality. While effective, DAGER’s complexity scales poorly with batch size for encoders, posing a limitation for extremely large batches. The attack highlights a critical vulnerability in LLMs, particularly decoders, and underscores the need for robust privacy-preserving techniques in federated learning settings.
LLM Vulnerability#
Large language model (LLM) vulnerability is a significant concern in the field of artificial intelligence. Data privacy is a major issue, as LLMs are trained on massive datasets that may contain sensitive personal information. Gradient inversion attacks can compromise this privacy by reconstructing training data from gradients shared during federated learning. Model robustness is another key vulnerability. LLMs can be manipulated by adversarial attacks, leading to biased or incorrect outputs. Bias and fairness are also major concerns; LLMs trained on biased data often perpetuate and amplify existing societal biases. Addressing these vulnerabilities is crucial for building trustworthy and responsible AI systems. Research focuses on developing defense mechanisms, such as differential privacy, and enhancing model robustness through techniques like adversarial training. Regulatory frameworks are also needed to guide ethical development and deployment of LLMs.
Empirical Results#
An empirical results section of a research paper should present a rigorous and comprehensive evaluation of the proposed method. It should demonstrate the method’s effectiveness relative to baseline approaches, ideally using multiple metrics and datasets to ensure robustness. Detailed experimental settings should be clearly described, including datasets used, hyperparameters, evaluation protocols, and any pre-processing steps. Statistical significance of results should be assessed and clearly reported, preferably using confidence intervals. Ablation studies are crucial to isolate the impact of individual components of the method and to understand the relative contribution of each. The discussion of results should move beyond simple comparisons, focusing on meaningful insights extracted from the data, explaining any unexpected findings or limitations observed. Visualizations (tables, graphs) should be used effectively to convey results clearly and concisely. Finally, a strong empirical results section should convincingly demonstrate the value and practicality of the proposed method.
Future Defenses#
Future defenses against gradient inversion attacks on large language models (LLMs) must move beyond simple defenses. Improving the robustness of gradient masking techniques is crucial, exploring more sophisticated methods that can adapt to the evolving sophistication of attacks. Differential privacy offers a promising avenue, but careful calibration of parameters is necessary to balance privacy with utility. Furthermore, research into alternative training paradigms that minimize information leakage in gradients is warranted. This could involve exploring decentralized training approaches or developing novel architectures that inherently obfuscate sensitive data. Finally, a multi-pronged approach that combines multiple defensive strategies, such as gradient perturbation with enhanced model architectures and improved data sanitization, will likely be the most effective way to safeguard privacy in future LLM development.
More visual insights#
More on figures

This figure shows the impact of applying a filtering method based on the low rank structure of gradients (L1 filtering) and an additional filtering step using the gradients of the second self-attention layer (L1+L2 filtering). It demonstrates how these filtering techniques narrow down the number of candidate tokens to a much smaller subset compared to the ground truth number of tokens. The x-axis represents the threshold used for filtering, while the y-axis shows the number of tokens remaining after filtering. The figure suggests that the combined L1+L2 filtering is more effective at identifying the correct tokens than L1 filtering alone. The effectiveness of the filtering methods is particularly evident at smaller threshold values.

This ablation study visualizes the effect of different rank thresholds (Δb) on the reconstruction accuracy of the DAGER algorithm for encoder architectures. It shows how varying the rank threshold impacts the ability of the algorithm to accurately recover tokens from gradients of different sizes. The dotted line represents the embedding dimension of the GPT-2 model, highlighting a threshold beyond which accurate reconstruction becomes less likely.

This ablation study compares the performance of DAGER on an encoder-based model (BERT) with different batch sizes (B=1, B=4) and with/without heuristics. The results show that DAGER performs near perfectly when B=1, achieving almost 100% accuracy across all tested sequence lengths. However, its performance decreases significantly as the batch size increases to B=4, especially without heuristics. The use of heuristics substantially improves the accuracy for B=4, indicating their importance in handling larger batch sizes in the encoder setting.
More on tables

This table compares the performance of DAGER against two state-of-the-art gradient inversion attack algorithms, TAG and LAMP. The comparison is made across different datasets (COLA, SST-2, Rotten Tomatoes) and varying batch sizes (B=1, 2, 4, 8). The results are evaluated using ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams, respectively, between the original and reconstructed sequences. Higher ROUGE scores indicate better reconstruction quality.

This table compares the performance of DAGER against two state-of-the-art gradient inversion algorithms, TAG and LAMP. The comparison is done across different datasets (COLA, SST-2, Rotten Tomatoes) and varying batch sizes (B=1, 2, 4, 8). The results are presented as ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams between the reconstructed and original sequences, respectively. Higher scores indicate better reconstruction quality.
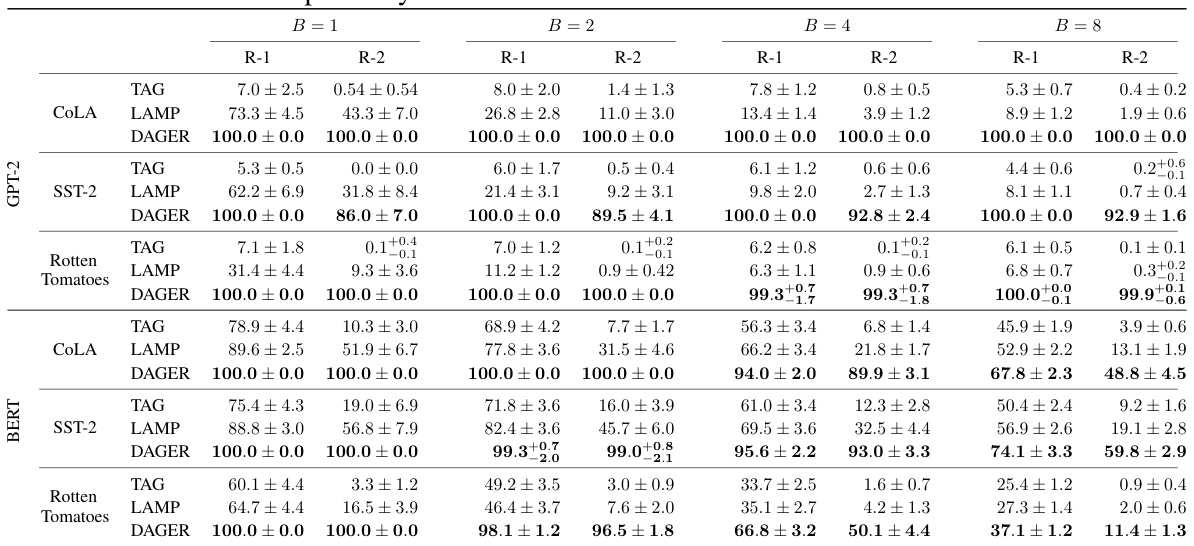
This table compares the performance of the proposed DAGER algorithm against two state-of-the-art gradient inversion algorithms, TAG and LAMP, across different datasets (COLA, SST-2, Rotten Tomatoes) and batch sizes (B=1, 2, 4, 8). The results are presented as ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams between the reconstructed sequences and the ground truth, respectively. Higher ROUGE scores indicate better reconstruction quality.
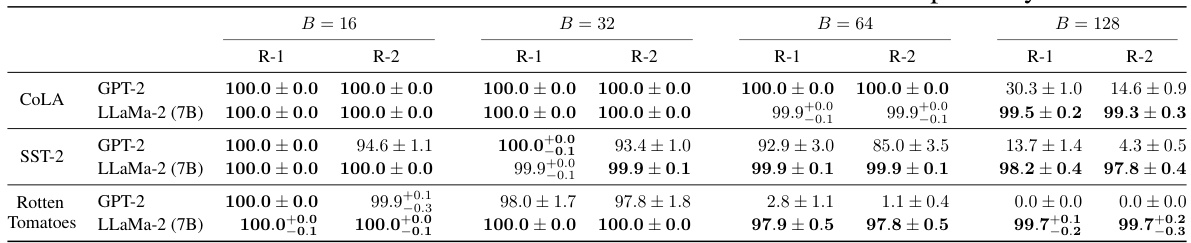
This table compares the performance of DAGER against two state-of-the-art gradient inversion attack algorithms, TAG and LAMP. The comparison is done across different datasets (COLA, SST-2, Rotten Tomatoes) and varying batch sizes (B=1, 2, 4, 8). The results are presented in terms of ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams respectively between the reconstructed and original sequences. Higher ROUGE scores indicate better reconstruction quality.

This table shows the results of experiments conducted using the FedAvg algorithm on the GPT-2 model. The experiments were performed on the Rotten Tomatoes dataset with a batch size of 16. The table explores how different hyperparameters (number of epochs, learning rate, and mini-batch size) impact the performance of the gradient inversion attack (DAGER) in terms of ROUGE-1 and ROUGE-2 scores. ROUGE-1 and ROUGE-2 are metrics that measure the quality of the reconstruction of the original data.

This table presents the main experimental results of DAGER, showing its performance on GPT-2BASE and LLaMa-2 (7B) models for different batch sizes (16, 32, 64, and 128) and datasets (COLA, SST-2, and Rotten Tomatoes). ROUGE-1 and ROUGE-2 scores are used to evaluate the reconstruction quality. The results demonstrate DAGER’s ability to achieve near-perfect reconstructions even at large batch sizes, especially for the larger LLaMa-2 model.

This table lists the specifications of the language models used in the paper’s experiments. For each model, it provides the model type (encoder or decoder), the number of layers, the hidden dimension (d), the number of attention heads, the feed-forward size, the vocabulary size (V), the type of positional embedding used, and the total number of parameters.

This table compares the performance of DAGER against two state-of-the-art gradient inversion attack algorithms, TAG and LAMP. The comparison is done across different datasets (COLA, SST-2, Rotten Tomatoes) and varying batch sizes (B=1, 2, 4, 8). The results are measured using ROUGE-1 and ROUGE-2 scores, which evaluate the overlap of unigrams and bigrams between the reconstructed and original sequences, respectively. Higher ROUGE scores indicate better reconstruction quality.
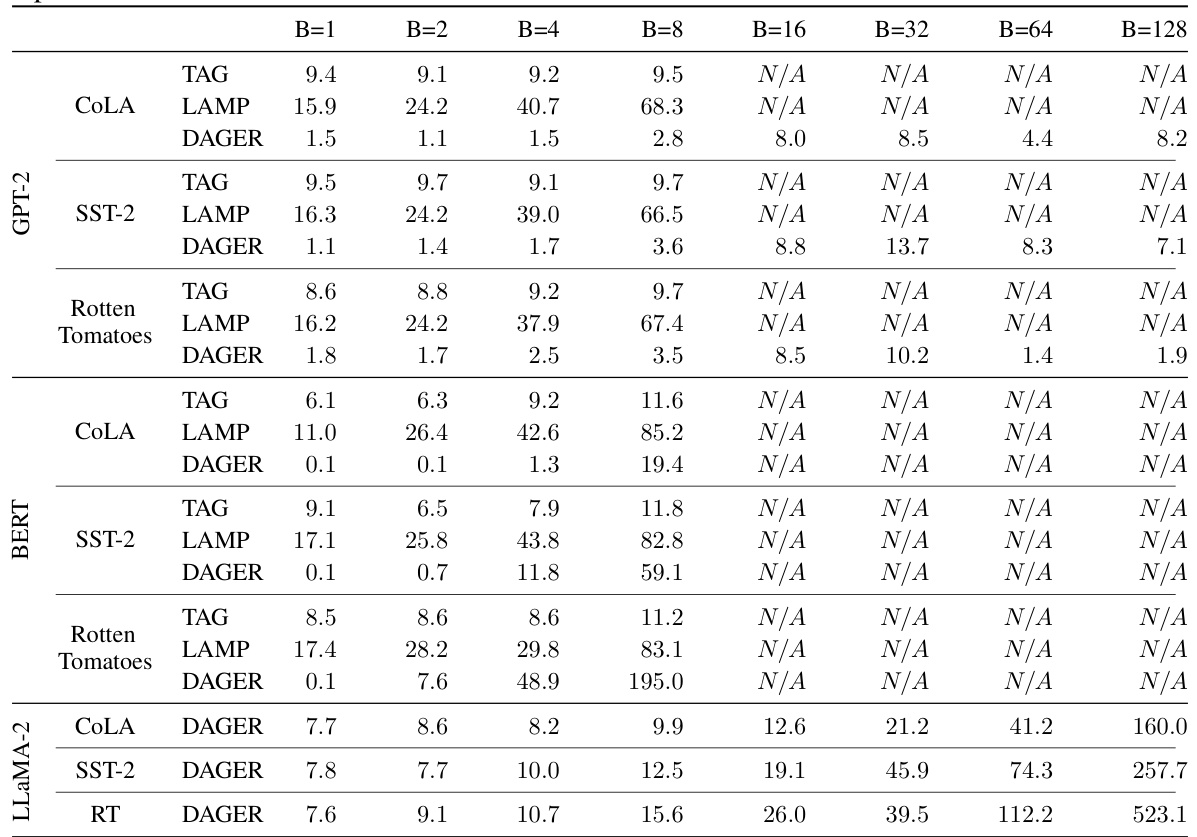
This table compares the performance of DAGER against two state-of-the-art gradient inversion algorithms, TAG and LAMP, across different batch sizes (B=1, 2, 4, 8) and datasets (COLA, SST-2, Rotten Tomatoes). The results are presented in terms of ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams, respectively, between the reconstructed and original sequences. Higher ROUGE scores indicate better reconstruction quality.
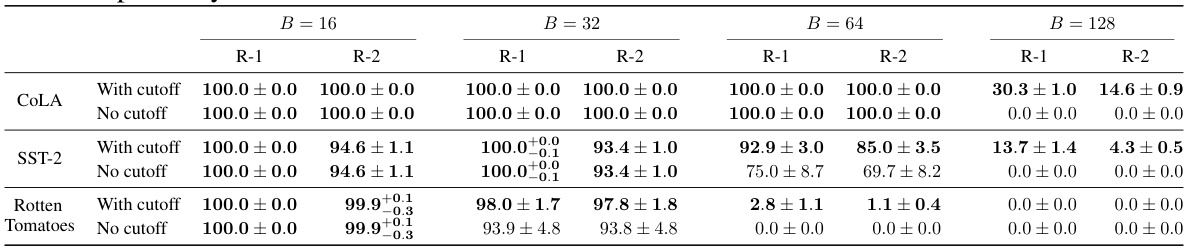
This table compares the performance of DAGER against two state-of-the-art gradient inversion algorithms, TAG and LAMP, across different batch sizes and datasets. It shows the ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams respectively between the original text and the reconstructed text. Higher ROUGE scores indicate better reconstruction quality.

This table compares the performance of DAGER against two state-of-the-art gradient inversion attack algorithms, TAG and LAMP, across various datasets and batch sizes. It shows ROUGE-1 and ROUGE-2 scores, which measure the overlap of unigrams and bigrams respectively, to evaluate the quality of the reconstructed sequences. The table highlights the significant improvement in reconstruction quality, achieved by DAGER, particularly for larger batch sizes.

This table presents the results of experiments evaluating the performance of the DAGER attack against a model protected with differential privacy. The experiments were conducted on the GPT-2 model using the Rotten Tomatoes dataset with a batch size of 1. Different levels of Gaussian noise (σ) were added to the gradients, and the ROUGE-1 and ROUGE-2 scores, which measure the quality of the reconstructed text, were recorded for each noise level. The results show how the effectiveness of the DAGER attack decreases as the level of noise increases.

This table presents results from several supplementary experiments to further illustrate DAGER’s versatility and robustness. It shows the performance of DAGER under different model sizes (LLaMa-3 70B and LLaMa-3.1 8B), different loss functions (Frobenius norm loss and the standard cross-entropy loss), different activation functions (ReLU activation), and with LoRA (Low-Rank Adaptation) finetuning. The results demonstrate near-perfect reconstruction across various settings and modifications. This highlights the effectiveness of DAGER across different model architectures and fine-tuning methods.
Full paper#