↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current audiovisual generation models often require separate training for each task, limiting efficiency and scalability. Also, generating temporally consistent sequences across multiple modalities remains challenging. This necessitates the development of task-agnostic models capable of handling various audiovisual tasks with high temporal consistency.
This paper presents AVDIT, a novel model trained with a Mixture of Noise Levels (MoNL) approach. This allows the model to learn arbitrary conditional distributions in the audiovisual space, handling diverse generation tasks at inference time without explicit task specification. Experiments show that AVDIT significantly outperforms existing methods in generating temporally consistent sequences across various tasks including cross-modal generation and multimodal interpolation.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel and versatile approach to audiovisual generation. It addresses the limitations of existing methods by enabling a single model to handle diverse tasks, reducing training costs and improving efficiency. The use of a Mixture of Noise Levels and a transformer-based model opens up new avenues for research in multimodal AI and related fields, particularly for the study of temporal consistency and efficient task-agnostic training strategies.
Visual Insights#

This figure shows examples of different audiovisual generation tasks that can be performed by the proposed Audiovisual Diffusion Transformer (AVDIT) model. The model is trained using a novel Mixture of Noise Levels approach, allowing it to handle various input-output combinations of audio and video data in a single model. The figure showcases various tasks including audio-to-video generation, video-to-audio generation, joint generation, audiovisual continuation with variable input durations, and multimodal interpolation tasks with variable settings. Each task is illustrated with example inputs (conditions) and corresponding generated outputs.
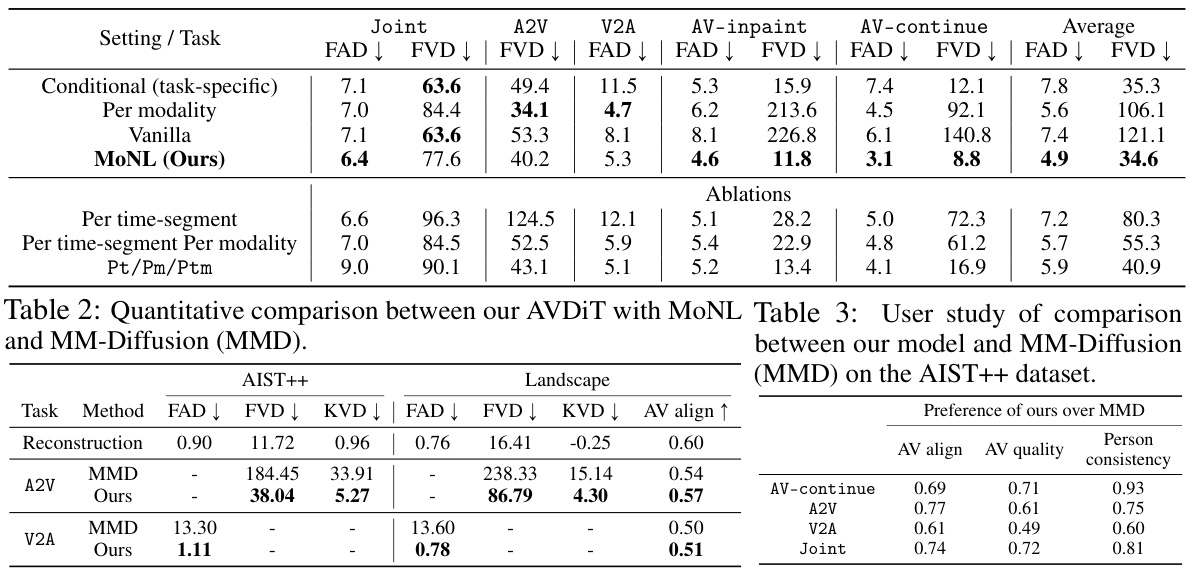
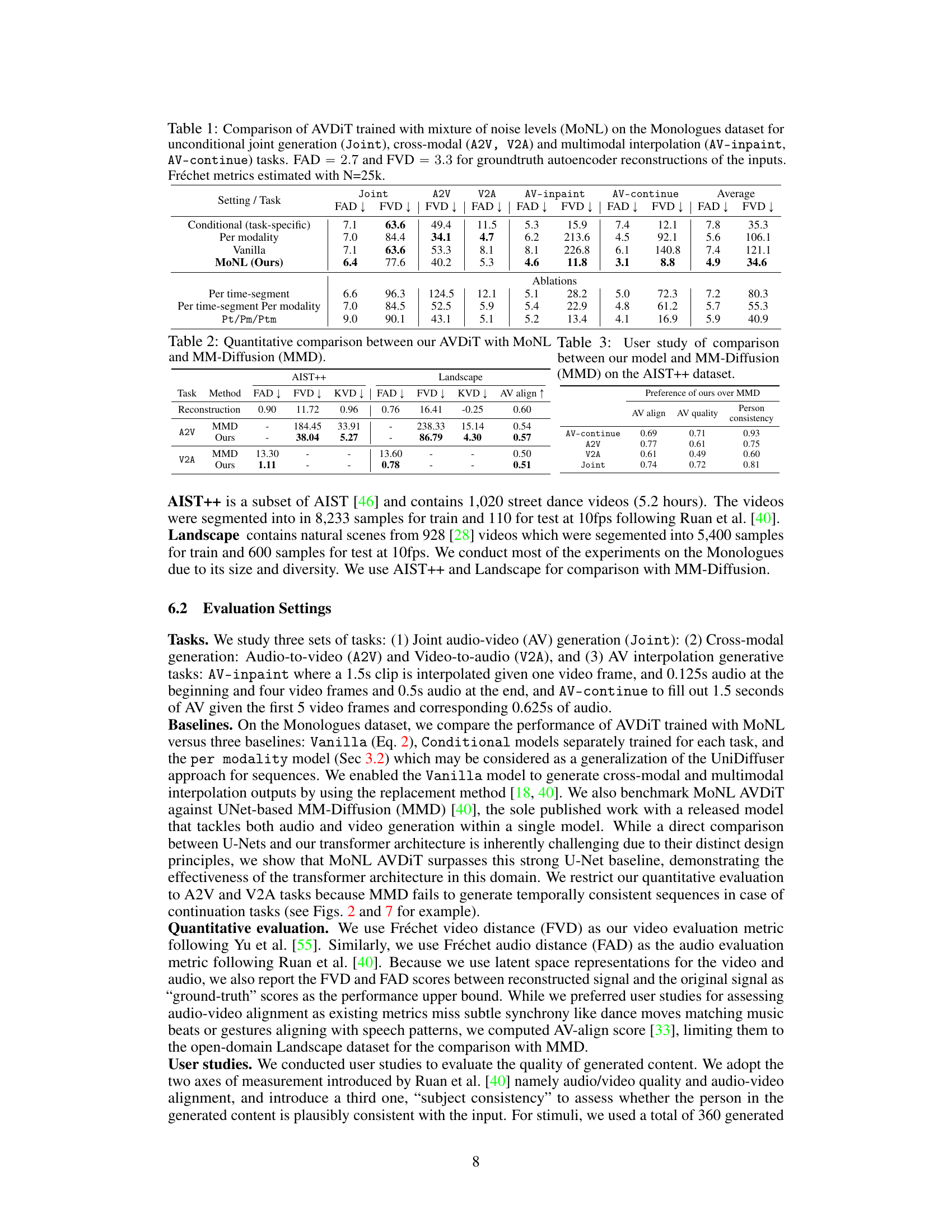
This table presents a quantitative comparison of the proposed AVDIT model trained with the Mixture of Noise Levels (MoNL) against the MM-Diffusion baseline. The comparison uses Fréchet metrics (FAD and FVD) to evaluate the quality of audio and video generation across several tasks: joint audio-video generation, audio-to-video generation, video-to-audio generation, and two interpolation tasks (inpainting and continuation). The results demonstrate the superior performance of AVDIT with MoNL across most tasks and metrics.
In-depth insights#
MoNL Diffusion#
MoNL Diffusion, a novel approach to training diffusion models, addresses limitations in existing multimodal methods by introducing variable noise levels across both modalities and time. Instead of a fixed diffusion timestep, MoNL parameterizes the timestep as a vector, enabling flexible noise injection tailored to different input portions. This allows a single model to effectively learn arbitrary conditional distributions, avoiding the expense of training separate models for each task. Task-agnostic training with MoNL provides versatility for various audiovisual generation tasks at inference time, including cross-modal and multimodal interpolation. The approach shows promising results in generating temporally consistent audiovisual sequences. However, limitations exist concerning visual and audio quality, with potential for future improvements through techniques like super-resolution. Ethical considerations related to generating human-like data are also important for future development.
AVDIT Model#
The AVDIT model, a novel Audiovisual Diffusion Transformer, stands out for its versatile architecture designed to handle diverse audiovisual generation tasks. Unlike traditional methods requiring separate models for each task, AVDIT leverages a mixture of noise levels (MoNL), parameterizing the diffusion timestep across modalities and time, allowing it to learn arbitrary conditional distributions. This task-agnostic training approach significantly reduces training costs and enhances efficiency. The model’s core strength lies in its ability to generate temporally consistent and perceptually realistic sequences by effectively tackling cross-modal and multimodal generation, continuation, and interpolation. The use of a transformer-based architecture further enhances its capability to model complex relationships between audio and video data, resulting in high-quality generation, specifically showcased in its impressive ability to retain subject consistency in the results. AVDIT’s design highlights a move towards more flexible and efficient multimodal diffusion models, offering significant advancement in handling complex audiovisual sequences.
Cross-Modal Tasks#
Cross-modal tasks, involving the generation of one modality conditioned on another (e.g., audio-to-video or video-to-audio), are crucial for evaluating the true understanding of the relationships between different modalities. Success in these tasks demonstrates the model’s ability to not only process individual modalities but also to translate information seamlessly between them. A key challenge is ensuring temporal consistency in generated sequences. The effectiveness of a model in cross-modal tasks is highly dependent on its ability to capture temporal dynamics and cross-modal correlations simultaneously. Furthermore, achieving high fidelity and perceptual quality in the generated output is critical for realistic and meaningful results. Finally, these tasks highlight the importance of carefully choosing training datasets which capture both the heterogeneity of the modalities and the complex dependencies between them.
Temporal Consistency#
Temporal consistency in audiovisual generation is crucial for producing realistic and engaging content. A model lacking temporal consistency might generate videos where objects suddenly change appearance, movements are jerky, or audio-visual synchronization is off. The challenge lies in modeling the complex temporal dependencies between modalities (audio and video) and within each modality. Successful approaches often leverage sophisticated architectures like transformers, which excel at capturing long-range dependencies. Careful training procedures, including loss functions that explicitly penalize inconsistencies over time, are also vital. Furthermore, incorporating latent representations of audio and video can significantly reduce computational costs and improve the model’s ability to learn and generalize temporal patterns effectively. Evaluating temporal consistency requires quantitative metrics such as Fréchet Video Distance (FVD) for video and corresponding metrics for audio, along with qualitative assessments using human evaluation. Future research should investigate more robust methods for evaluating temporal consistency and designing models capable of handling more diverse and complex temporal scenarios, including variable frame rates and long video sequences.
Future Work#
Future research directions stemming from this work could explore several key areas. Improving the quality of generated audio and video is paramount, perhaps through super-resolution techniques or advanced conditioning methods. Investigating the impact of different noise scheduling strategies within MoNL and their effects on various tasks warrants further investigation. Extending MoNL to other multimodal domains beyond audio-video offers exciting possibilities. The ethical considerations raised by human-centric generation, particularly the risk of perpetuating stereotypes, necessitate further attention. Thorough analysis of potential biases and mitigation strategies, including methods for enhancing diversity and consistency in generated outputs, is crucial. Finally, exploring alternative model architectures, such as expanding on the transformer-based approach used here, may unlock even greater generative capabilities.
More visual insights#
More on figures

This figure compares the results of audiovisual continuation tasks using two different methods: MM-Diffusion and the proposed method (Ours). The left side shows the results from MM-Diffusion, while the right side shows the results from the proposed method. The task is to continue an audiovisual sequence, given a short initial segment. The figure shows that the proposed method is better at generating temporally consistent sequences. The ‘Landscape’ dataset indicates the type of data used for the comparison.
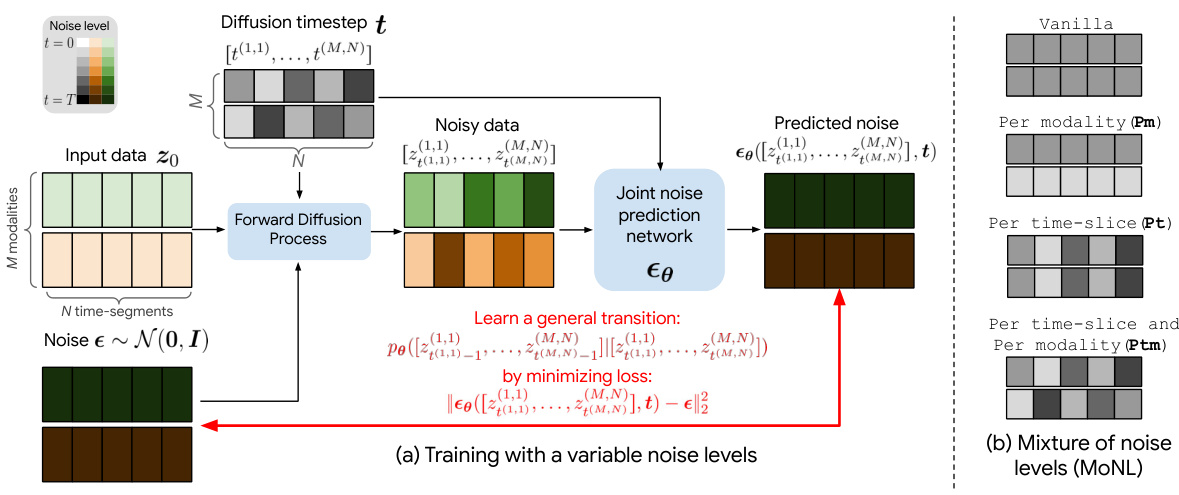
This figure illustrates the training process of the proposed Audiovisual Diffusion Transformer (AVDIT) model. The training process uses a novel method called Mixture of Noise Levels (MoNL). Panel (a) shows how variable noise levels are applied to the multimodal input data (M modalities and N time segments) during the forward diffusion process. The noise level is determined by a diffusion timestep vector ’t’. The noisy data ‘zt’ is then fed into a joint noise prediction network to learn a general transition matrix that captures the complex relationships between the modalities and time segments. Panel (b) shows the different strategies for applying variable noise levels: Vanilla (same noise level for all modalities and time segments), Per modality (variable noise levels for each modality), Per time-slice (variable noise levels for each time segment), and Per time-slice and Per modality (variable noise levels for both modalities and time segments). The MoNL approach combines these strategies, effectively learning the conditional distributions across various portions of the input.
This figure illustrates the core idea of the paper: using a mixture of noise levels (MoNL) during diffusion training to handle multiple modalities and time-segments. Panel (a) shows how variable noise levels are applied across modalities and time, while panel (b) shows the MoNL approach in which the noise level is determined by a vector, allowing for flexibility in how noise is added during training. The overall goal is to learn a general transition matrix between modalities and time-segments, enabling the model to handle a wide range of tasks at inference time.
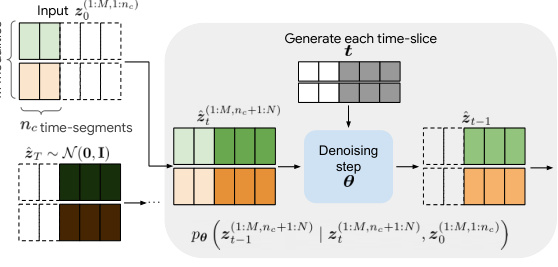
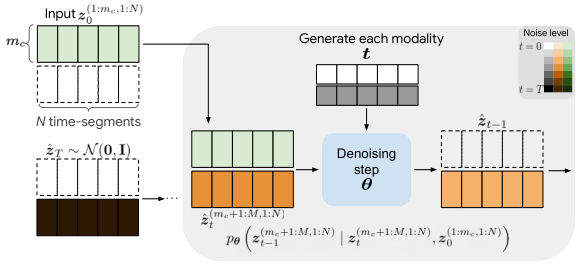
This figure illustrates how the model performs conditional inference for two different tasks: cross-modal generation and multimodal interpolation. In cross-modal generation (a), the model generates a sequence of modalities (e.g., video) conditioned on a different set of modalities (e.g., audio). The input consists of a set of time segments, where some have noise and some do not. The model generates the missing portions of the signal. In multimodal interpolation (b), the model interpolates a sequence of time segments based on a set of conditioning segments. This interpolation uses variable noise levels to generate smooth and temporally consistent sequences.
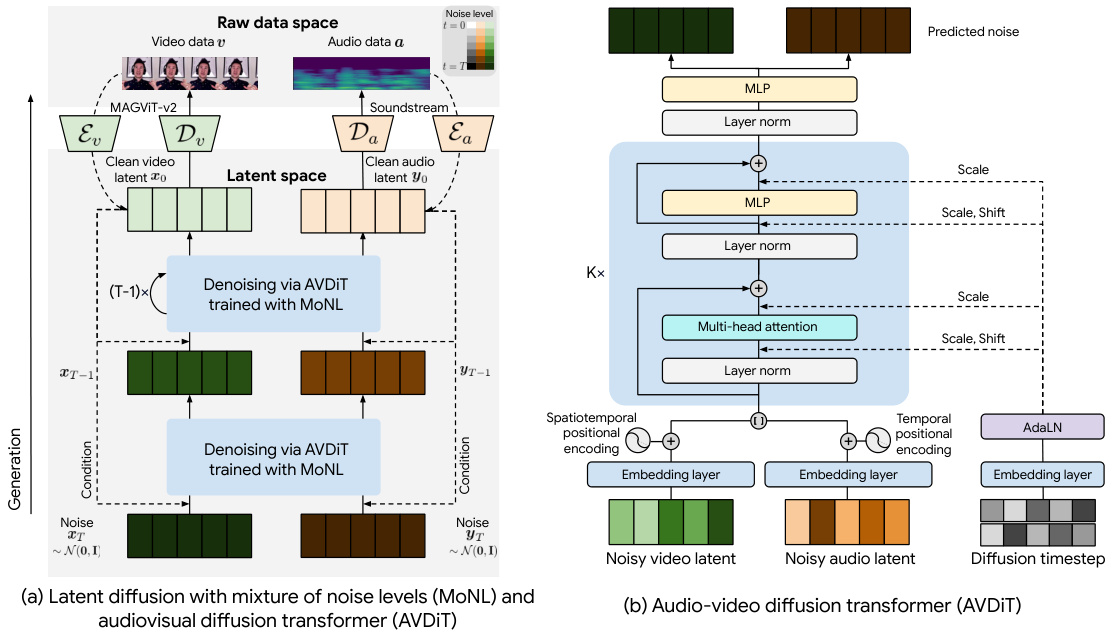
This figure shows a schematic of the proposed approach for audiovisual generation using a mixture of noise levels and an audio-video diffusion transformer. (a) shows the overall architecture of the system, which includes latent diffusion with mixture of noise levels (MoNL) and an audiovisual diffusion transformer (AVDIT). The latent diffusion process converts raw audio and video data into latent representations, which are then used by the AVDIT to predict the noise levels. (b) illustrates the architecture of the AVDIT, which is a transformer-based network that takes the noisy latent representations and diffusion timesteps as input and outputs the predicted noise levels. This is a high-level illustration of the method and its components.

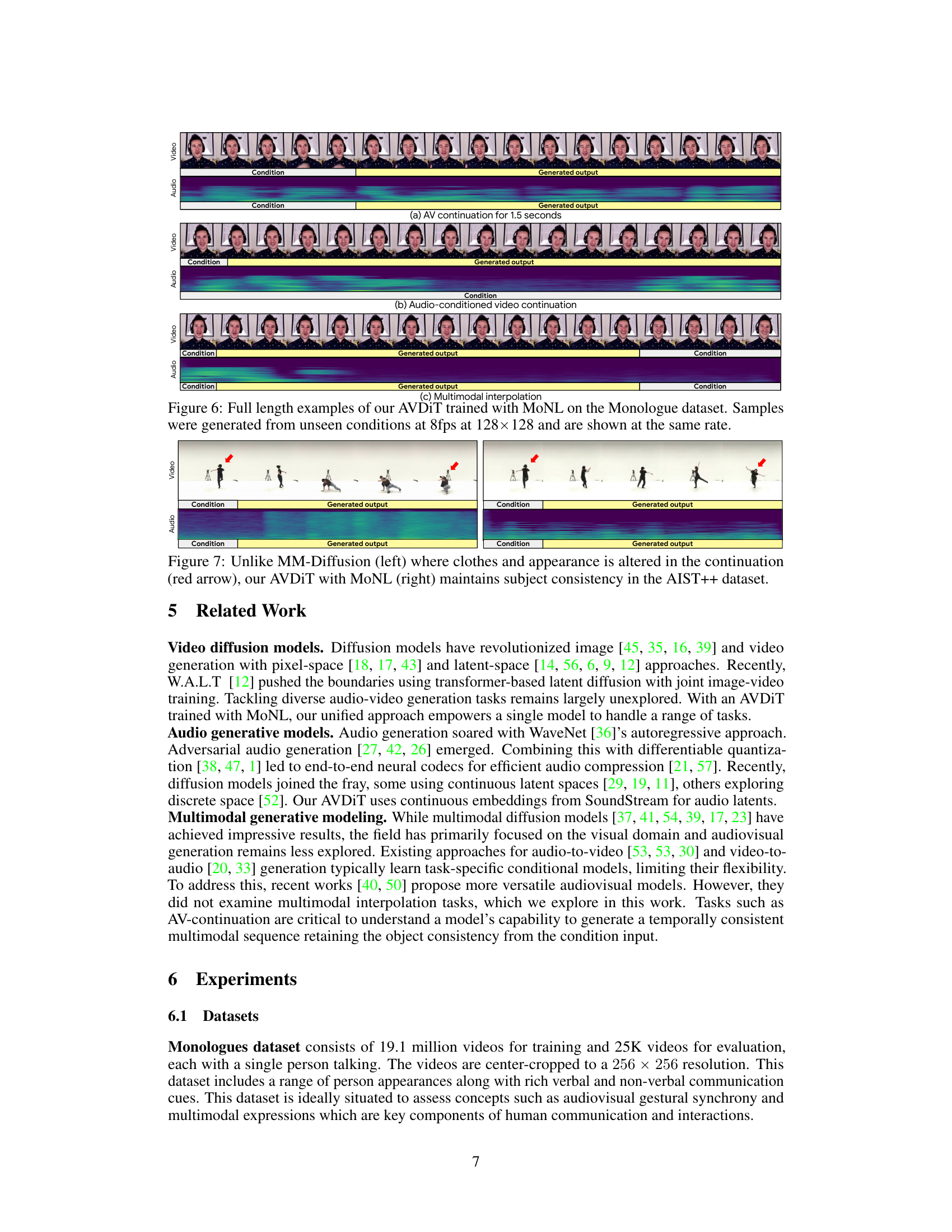
This figure shows three examples of video and audio generation using the Audiovisual Diffusion Transformer (AVDiT) model trained with Mixture of Noise Levels (MoNL). The top example demonstrates audiovisual continuation, where the model generates a 1.5-second continuation of both audio and video given a short input segment. The middle example focuses on audio-conditioned video continuation, showing how the model extends a video sequence based on a given audio input. The bottom example illustrates multimodal interpolation, where the model generates a smooth transition between two audio-video segments with varying lengths. All examples highlight the temporal consistency achieved by AVDiT-MoNL, a key aspect of the paper’s contribution.

This figure compares the results of audiovisual continuation using MM-Diffusion and the proposed AVDIT model. The left panel shows the MM-Diffusion results, where the generated continuation shows changes in the subject’s clothing and appearance. This demonstrates a lack of subject consistency in the model’s generation. The right panel shows the results of AVDIT with the Mixture of Noise Levels (MoNL) approach, where the generated continuation preserves the subject’s appearance and clothing, indicating better subject consistency in the model’s generation.
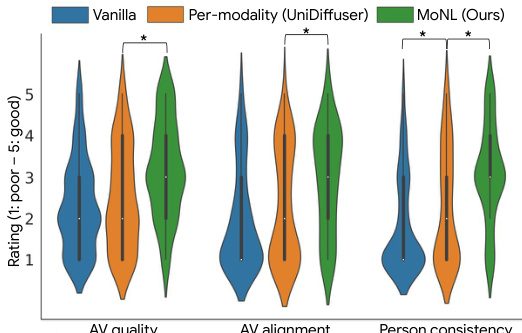
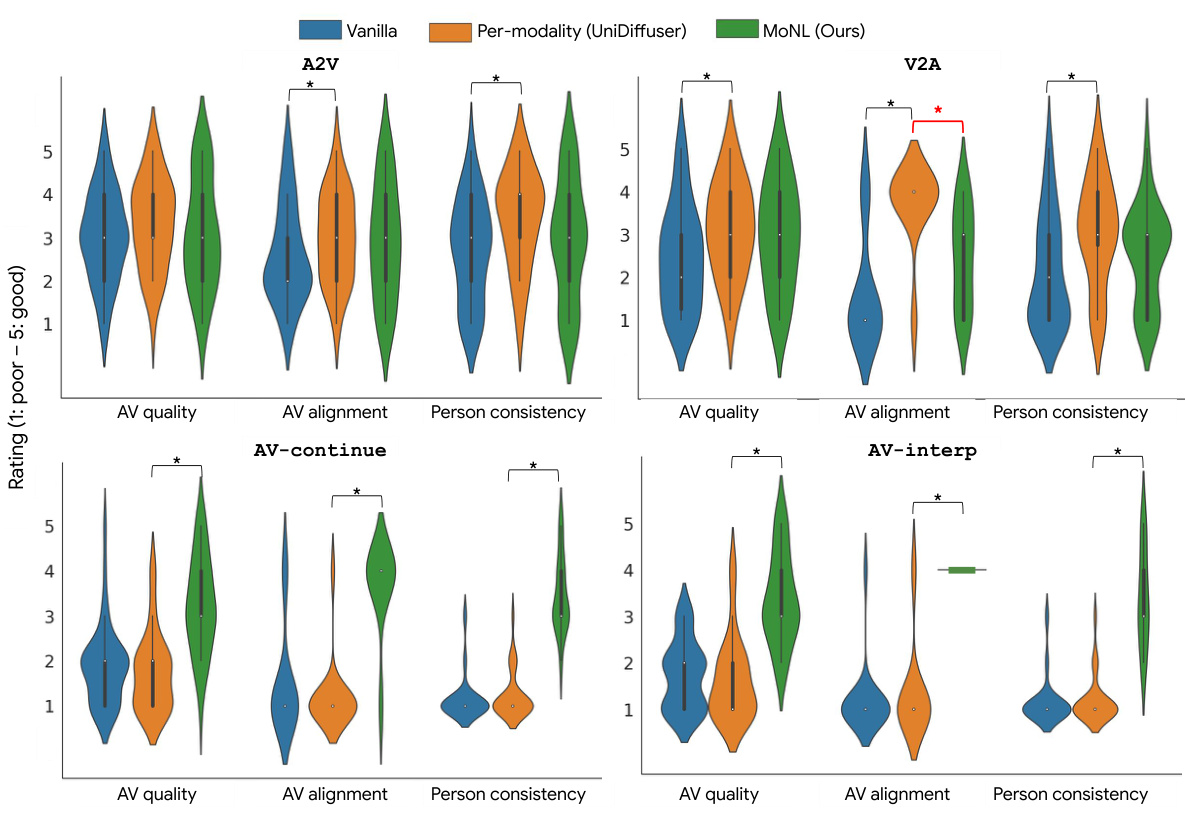
The violin plot shows the distribution of Likert scores (1-5, 1 being poor and 5 being good) given by human raters for three aspects of the generated videos: Audio-Video quality, Audio-Video alignment, and Person consistency. The three different AVDIT models are compared: Vanilla, Per-modality (UniDiffuser), and MoNL (Ours). The asterisk (*) indicates statistically significant differences between the models (p<0.01 after Bonferroni correction). The results show that the MoNL model generally outperforms the other two models across all three aspects.
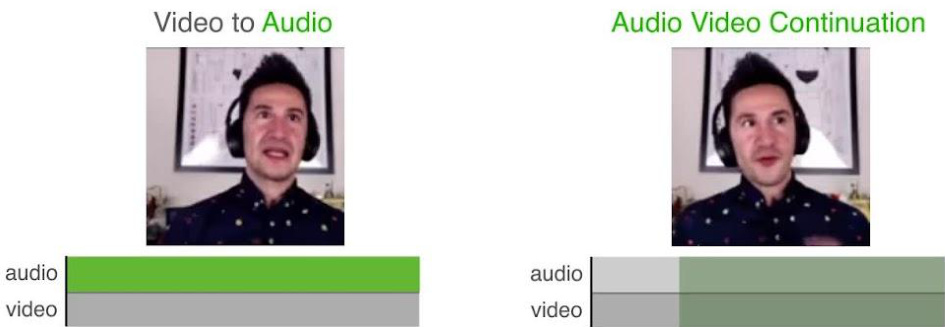
This figure shows example stimuli used in user studies to evaluate the quality of generated content for four different tasks: audio-to-video (A2V), video-to-audio (V2A), audiovisual continuation, and multimodal interpolation. For each stimulus, a video clip is shown, and below the video is one track for the generated audio, and one track for the generated video. The generated portions are highlighted in green, while the condition inputs (the input data used for generation) are in gray. This setup was designed to make it easy for the raters to see and understand the generated audio and video compared to the input used to generate it.
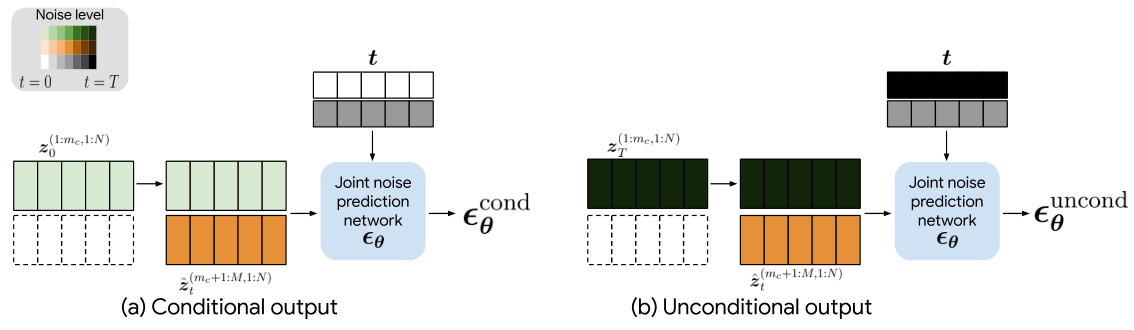
This figure illustrates how the proposed mixture of noise levels (MoNL) approach enables classifier-free guidance (CFG) without requiring additional training. In the traditional CFG, a null token is used to generate unconditional outputs. In contrast, MoNL uses a variable noise level vector to achieve the same effect. The figure shows how, for cross-modal generation, MoNL sets the noise level to 0 (no noise) for the conditioning modalities and T for the target modality, effectively achieving the same result as CFG without explicitly generating unconditional outputs.
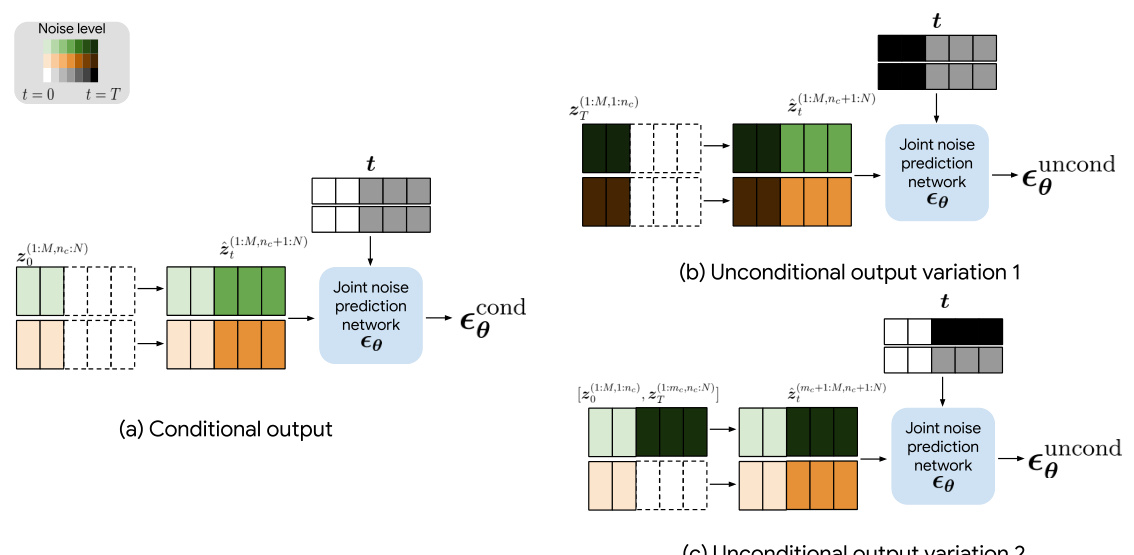
This figure illustrates the application of classifier-free guidance (CFG) within the Mixture of Noise Levels (MoNL) framework for multimodal interpolation tasks. It demonstrates how the flexible timestep vector in MoNL allows for various configurations of CFG by selectively applying noise to different parts of the input. Three scenarios are shown: (a) conditional output, where the model is conditioned on existing information,(b) unconditional output variation 1, using only noise, and (c) unconditional output variation 2, combining both conditional and unconditional parts. This highlights the versatility of MoNL for handling diverse conditional generation tasks by flexibly controlling the noise level in the input.
This figure showcases the versatility of the proposed Audiovisual Diffusion Transformer (AVDIT) model. It demonstrates the model’s ability to handle diverse audiovisual generation tasks using a single model trained with a Mixture of Noise Levels (MoNL). The figure illustrates several example tasks, such as audio-to-video generation, video-to-audio generation, joint generation, audiovisual continuation with variable input durations, and multimodal interpolation with variable settings. The results suggest that the model can effectively learn conditional distributions in the audiovisual space and produce high-quality, temporally consistent outputs across various generation tasks. A link to video demonstrations is also provided.

This figure shows three examples of audiovisual generation results from the model. The model successfully generates temporally consistent and high-quality audiovisual sequences even with unseen conditions, demonstrating its ability to handle various tasks.
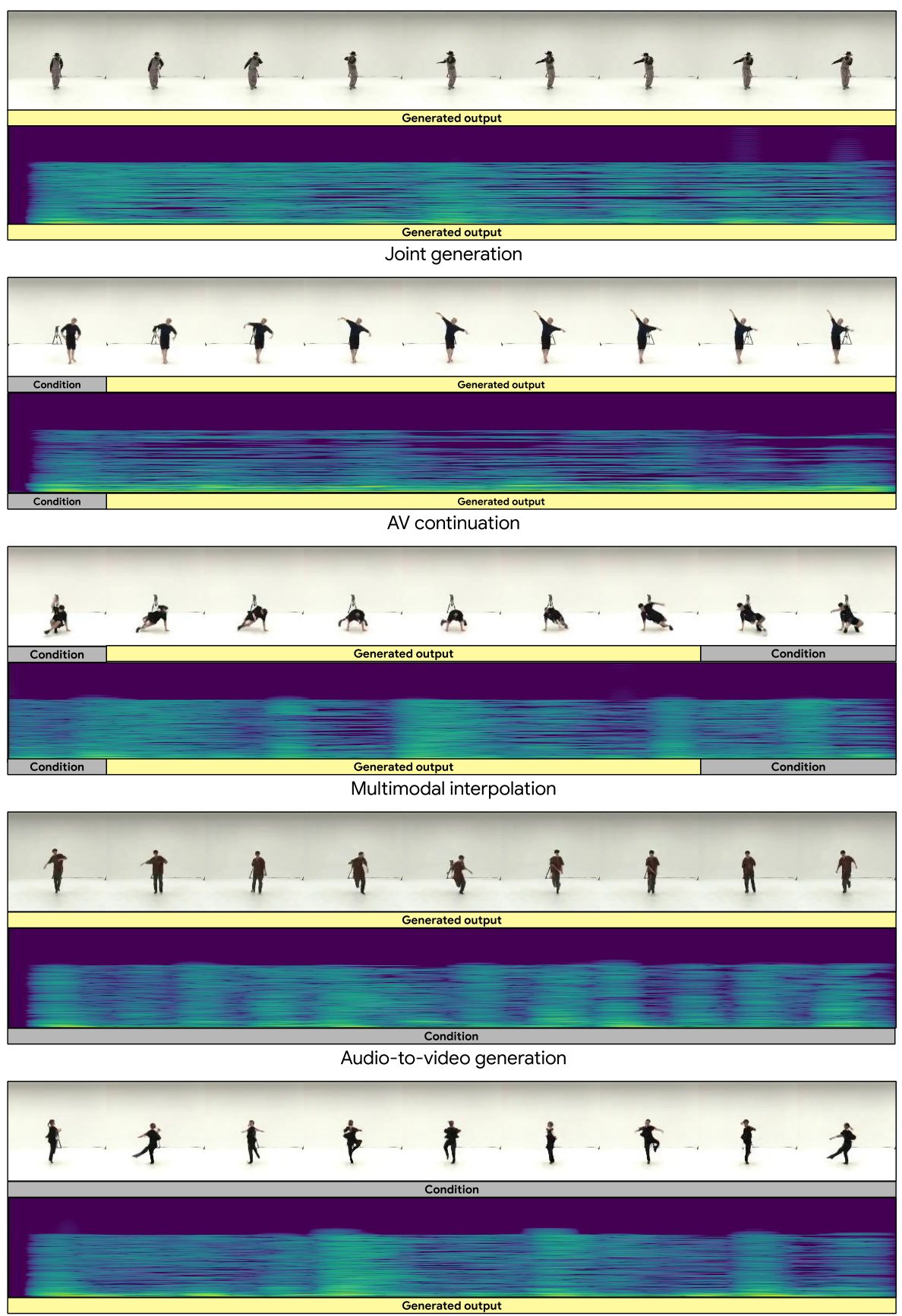
This figure showcases the versatility of the proposed Audiovisual Diffusion Transformer (AVDIT) model. Trained using a Mixture of Noise Levels (MoNL), the AVDIT model successfully handles various audiovisual generation tasks within a single model. These tasks include audio-to-video generation, video-to-audio generation, joint generation, multimodal interpolation, and audiovisual continuation, all with variable input durations and settings. The figure visually represents the different tasks and their respective input conditions and generated outputs. A link to video demonstrations is also provided for a more comprehensive understanding.

This figure showcases the versatility of the proposed Audiovisual Diffusion Transformer (AVDIT) model. It demonstrates the model’s ability to handle various audiovisual generation tasks, including audio-to-video generation, video-to-audio generation, joint generation, audiovisual continuation with variable input durations, and multimodal interpolation tasks with variable settings. The figure highlights the model’s capacity to perform these diverse tasks within a single model, indicating its efficiency and flexibility. A link is provided to access video demonstrations of the model’s capabilities.
More on tables

This table presents a quantitative comparison of the proposed Audiovisual Diffusion Transformer (AVDIT) model trained with the Mixture of Noise Levels (MoNL) approach against various baseline methods. The evaluation metrics (Fréchet Audio Distance (FAD) and Fréchet Video Distance (FVD)) assess the quality of generated audio and video, respectively, across different tasks: unconditional joint generation, audio-to-video (A2V), video-to-audio (V2A), and two types of multimodal interpolation (AV-inpaint and AV-continue). The ground truth autoencoder reconstruction FAD and FVD values are also provided for reference.

This table compares the performance of the proposed Audiovisual Diffusion Transformer (AVDIT) model trained with the Mixture of Noise Levels (MoNL) approach against various baselines across different audiovisual generation tasks. The tasks include unconditional joint generation, cross-modal generation (audio-to-video and video-to-audio), and multimodal interpolation (inpainting and continuation). The Fréchet audio distance (FAD) and Fréchet video distance (FVD) metrics are used to evaluate the quality of the generated audio and video, respectively. Lower FAD and FVD scores indicate better generation quality. The table also provides ablation results comparing the MoNL approach to other variable noise level strategies and a vanilla baseline.

This table presents a quantitative comparison of the proposed Audiovisual Diffusion Transformer (AVDIT) model trained using the Mixture of Noise Levels (MoNL) approach against several baseline methods across various audiovisual generation tasks. The tasks include unconditional joint generation, cross-modal generation (audio-to-video and vice-versa), and multimodal interpolation. The performance is measured using Fréchet Inception Distance (FID) for video (FVD) and Fréchet Audio Distance (FAD) for audio. The ground truth autoencoder reconstructions provide a baseline for comparison. The results show the performance gains achieved by MoNL across various tasks.
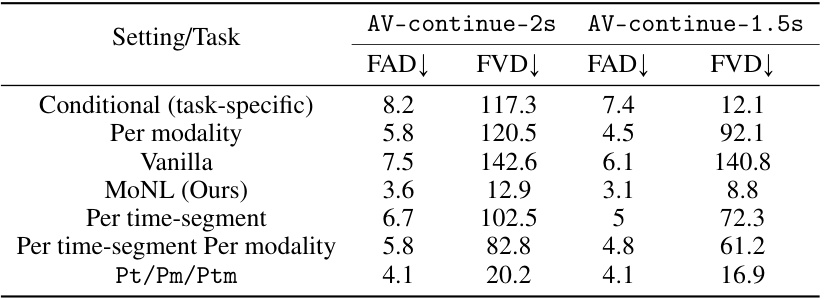
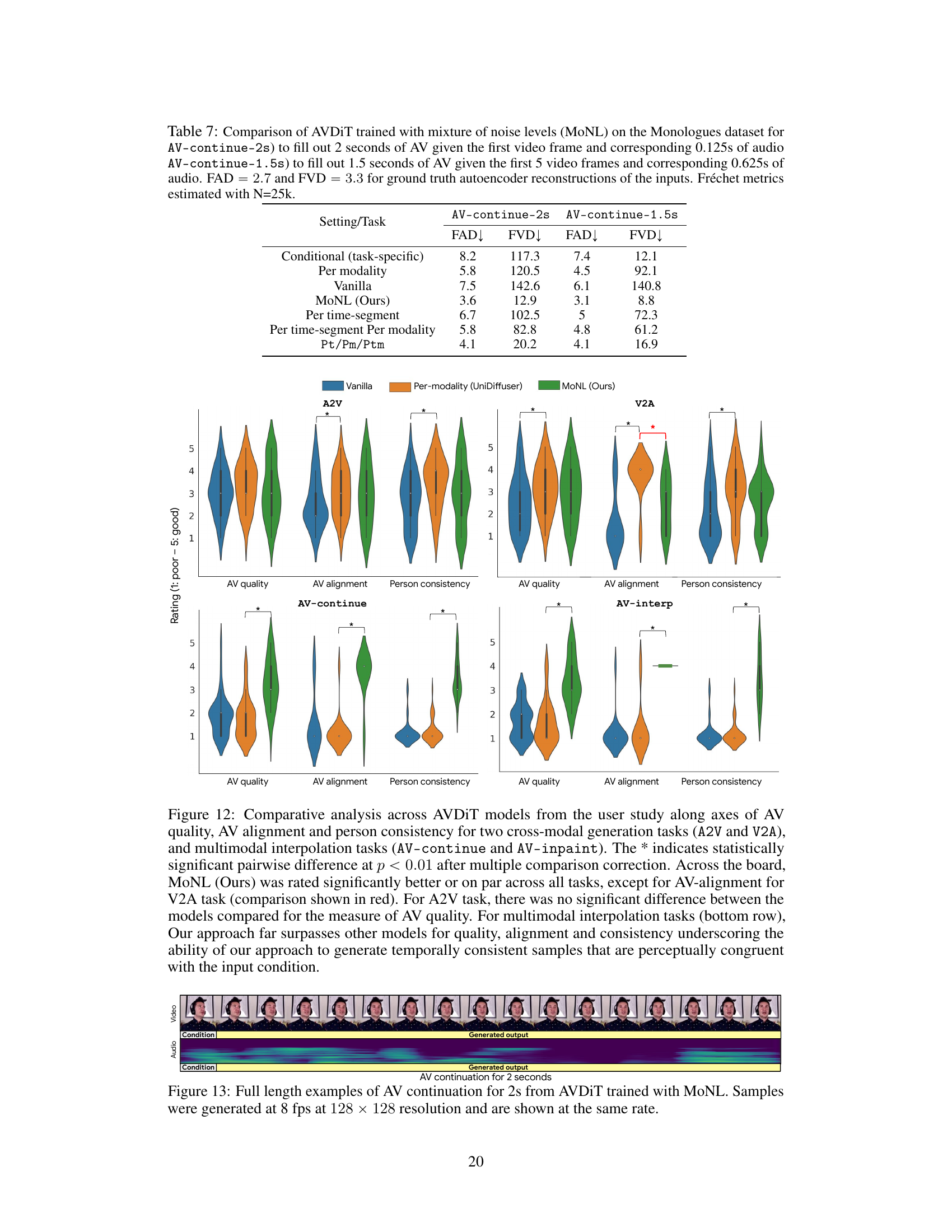
This table compares the performance of different training methods (conditional, per modality, vanilla, MONL, etc.) on two audiovisual continuation tasks. The tasks differ in the amount of conditioning information provided (1 frame vs. 5 frames of video, and corresponding audio). The Fréchet audio distance (FAD) and Fréchet video distance (FVD) metrics are reported, evaluating the quality of the generated audio and video, respectively. Lower FAD and FVD values indicate better performance.
Full paper#