↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating complex 3D scenes has been challenging using traditional methods. Existing automatic text-to-3D generation methods are often limited to small scenes and offer restricted control over shape and texture. This creates a need for advanced techniques capable of handling larger, more intricate spaces with precise user control.
SceneCraft addresses these limitations by introducing a novel approach that integrates user-specified layouts (represented as 3D bounding boxes) with textual descriptions. It uses a rendering-based method to create multi-view 2D proxy maps and then employs a semantic and depth conditioned diffusion model to generate high-quality images. These images are then used to learn a neural radiance field (NeRF), resulting in a detailed 3D scene representation. This approach enables the generation of significantly more complex scenes compared to existing methods, such as multi-room apartments with irregular shapes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D scene generation because it introduces a novel, user-friendly method for creating complex indoor scenes. SceneCraft significantly advances the field by offering precise control over scene layout and achieving high visual quality, surpassing previous limitations in scale and detail. This opens doors for advancements in VR/AR, game development, and embodied AI.
Visual Insights#

This figure illustrates the SceneCraft framework, which takes a user-specified layout (Bounding-Box Scene or BBS) as input. The framework consists of two main stages: First, a 2D diffusion model (SceneCraft2D) is pre-trained using rendered images of the BBS to generate high-quality 2D images of the scene from different viewpoints. Second, these 2D images are used in a distillation process to learn a 3D representation (e.g., NeRF) of the generated scene. The final output is a high-quality, detailed 3D scene that adheres to both the textual description and spatial layout preferences provided by the user.
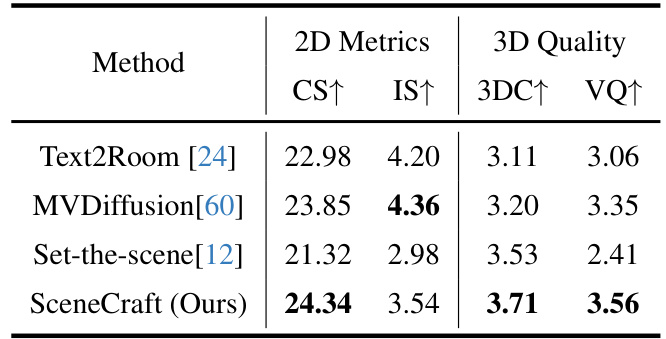
This table presents a quantitative comparison of the proposed SceneCraft model against three baseline methods: Text2Room, MVDiffusion, and Set-the-scene. The comparison uses both 2D metrics (CLIP Score and Inception Score) and 3D quality metrics (3D Consistency and Visual Quality), which are assessed via a user study. Higher scores indicate better performance. The results demonstrate that SceneCraft outperforms the baselines across all metrics.
In-depth insights#
Layout-Guided 3D#
Layout-guided 3D scene generation is a significant advancement in computer graphics and AI, offering more control and realism than previous text-to-3D methods. It moves beyond simple object generation by incorporating user-defined spatial layouts, enabling the creation of complex indoor scenes tailored to specific needs. This approach combines 2D diffusion models with 3D scene representations, leveraging the strengths of each. The 2D model generates multi-view images conditioned on the layout, while the 3D representation (often a NeRF) captures the scene’s geometry and appearance. User-friendly interfaces, such as using bounding boxes to define room layouts, make this technique more accessible. While challenging aspects remain (handling irregular shapes, complex occlusions), the results demonstrate impressive improvements in generating detailed, realistic indoor environments. The future will likely see further development in handling intricate geometries, seamless integration of diverse object types, and improved scalability for even larger and more complex scenes.
Diffusion Model#
Diffusion models have emerged as a powerful technique in generative modeling, particularly excelling in image synthesis. Their core mechanism involves a gradual denoising process, starting from pure noise and iteratively refining it to generate realistic data. This is achieved by learning a reverse diffusion process, which is often more tractable than modeling the forward process directly. This learned reverse process enables the generation of high-quality samples by iteratively removing noise from a random input. The effectiveness of diffusion models hinges upon the quality of the learned reverse diffusion process, making the design of effective training procedures crucial. While computationally intensive, advancements have mitigated this concern, making diffusion models a practical and effective tool in generating realistic images and other forms of data. Control over the generation process is an important challenge, with significant research focused on achieving desired attributes and avoiding unintended artifacts. Furthermore, the extensibility of diffusion models to other data modalities beyond images is an active area of research. The ability to leverage conditional inputs, such as text descriptions or other structured data, is essential for controlling the generation, making them valuable for various applications.
NeRF-Based 3D#
NeRF-based 3D techniques are revolutionizing how we represent and interact with three-dimensional environments. Neural Radiance Fields (NeRFs) offer a powerful method for synthesizing realistic 3D scenes from a collection of 2D images. This approach elegantly sidesteps the need for explicit 3D models, instead learning a continuous function that maps viewing rays to colors and densities. This allows for novel view synthesis, where photorealistic images can be rendered from viewpoints not present in the original data. However, traditional NeRF approaches have limitations, including high computational cost and sensitivity to the quality and quantity of input images. Recent advancements address these shortcomings, leveraging techniques such as multi-resolution representations, implicit surface representations, and novel training strategies to enhance efficiency and robustness. Looking ahead, combining NeRFs with other AI technologies, such as deep learning models for scene understanding and object detection, promises further advancements in areas such as virtual and augmented reality, robotics, and computer-aided design. The integration of NeRFs into broader AI systems will also likely drive the development of more sophisticated and user-friendly interfaces for generating and manipulating 3D content.
Ablation Experiments#
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of this research paper, ablation experiments would likely involve selectively disabling features (e.g., the layout-aware depth constraint, texture consolidation, or specific components of the diffusion model) to assess their impact on the quality and consistency of the generated 3D scenes. Analyzing results across these variations would reveal the relative importance of each component. For example, disabling the layout-aware depth constraint might lead to scenes with inaccurate geometries, while removing texture consolidation might produce blurry or unrealistic textures. Careful examination of these effects provides crucial insights into the design choices and the effectiveness of the overall architecture. Such an analysis is vital for identifying strengths and weaknesses, guiding future improvements, and ultimately validating the paper’s claims about the model’s capabilities.
Future Directions#
The paper’s exploration of future directions is insightful, emphasizing the need for improved 3D scene consistency and realism. Addressing limitations in generating complex scenes with irregular shapes and diverse object sizes is crucial. The suggestion of incorporating user feedback loops for iterative refinement represents a significant step towards enhancing user control and generating truly customized scenes. Exploring methods for automatically generating layouts and camera trajectories would significantly streamline the process, making it more accessible and efficient. Finally, extending the framework to generate outdoor scenes presents a compelling challenge, necessitating the development of new techniques capable of handling the larger scale and increased dynamism inherent in outdoor environments. These future directions highlight the potential for substantial advancement in the field of 3D scene generation.
More visual insights#
More on figures

This figure illustrates the SceneCraft framework, a two-stage process for generating 3D indoor scenes from a user-provided layout and text description. Stage (a) pre-trains a 2D diffusion model (SceneCraft2D) on rendered images from bounding box scenes (BBS), learning to generate high-quality 2D images from the layout. Stage (b) uses the pre-trained SceneCraft2D to generate multiple views of the scene, which are then used to learn a final 3D scene representation.

This figure visualizes the results of SceneCraft applied to three different room layouts from the HyperSim dataset. For each layout (BBS-A, BBS-B, BBS-C), it shows the 3D bounding box scene (BBS), the corresponding bounding box images (BBI) with semantic segmentation, and the resulting RGB images and depth maps generated by SceneCraft. This demonstrates the model’s ability to create complex and varied indoor scenes from user-provided layouts.

This figure compares the results of SceneCraft with three other baseline methods: Set-the-scene, Text2Room, and MVDiffusion. Two common indoor scene layouts, a bedroom and a living room, are used for the comparison. The generated color and depth images from each method are shown. The figure highlights that SceneCraft produces results with higher visual quality and better adherence to the layout specifications than the baseline methods, especially when dealing with more complex scenes.

This figure shows four examples of 3D scenes generated by SceneCraft, a novel method for generating detailed indoor scenes based on textual descriptions and spatial layouts. Each example includes the 3D bounding-box scene (BBS) layout, the bounding-box images (BBI) semantic maps (semantic categories and depth maps derived from the BBS), the generated scene RGB images, and a rendered depth map of the scene. The results demonstrate the model’s ability to generate complex and free-form indoor scenes with diverse textures and realistic visual quality, even for challenging layouts.

This figure demonstrates a comparison of using a simple base prompt versus using captions generated by BLIP2 for the SceneCraft2D model. The left side shows results using the base prompt ‘This is one view of a room.’ It produces good, stylistically consistent results while maintaining adherence to the layout. The right side shows the results from using BLIP2 generated prompts. These results suffer from control failure, showing inconsistencies in style and a lack of adherence to the layout constraints.

This figure showcases three examples of 3D scenes generated by SceneCraft, a method for generating complex indoor scenes from user-provided layouts and text descriptions. Each example shows a top-down view of the ‘bounding-box scene’ (BBS) layout used as input, along with the corresponding semantic maps (BBI) indicating object locations and categories. The figure then presents multiple views of the generated 3D scene, including RGB images and rendered depth maps, demonstrating SceneCraft’s ability to create complex and realistic indoor environments.
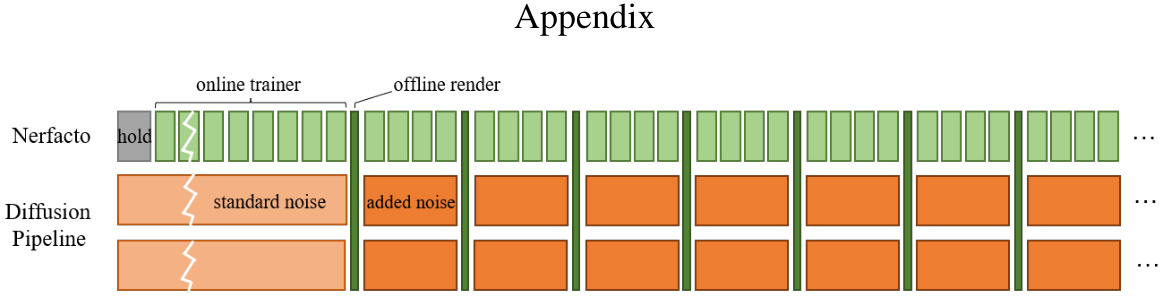
This figure illustrates the duo-GPU training scheduling used in the SceneCraft model. The leftmost part shows the Nerfacto model, which is trained continuously by the first GPU. Meanwhile, the second GPU continuously generates new images to update the dataset. When the diffusion procedure requires images from the first GPU to refine the dataset, the first GPU switches to an offline renderer. This configuration decouples the computationally expensive diffusion generation process from the faster NeRF training, improving efficiency without sacrificing quality.

This figure in the ablation study section demonstrates the effectiveness of the texture consolidation method used in SceneCraft. The top row shows results without texture consolidation, resulting in blurry renderings. The bottom row, conversely, shows results with texture consolidation, demonstrating significantly improved detail and texture in the generated 3D scenes.

This figure shows the effectiveness of the layout-aware depth constraint in SceneCraft. The leftmost image shows the condition input. The middle image shows the result without the depth constraint, demonstrating an inability to learn the scene geometry correctly. The right image demonstrates the result with the depth constraint, showcasing accurate geometry learning and convergence to the ground truth.

This figure shows example results of the SceneCraft model on the HyperSim dataset. For each scene, it displays the 3D bounding box scene (BBS), the bounding box images (BBI) with semantic maps, the generated RGB images of the scene, and the depth map of the generated scene. The results demonstrate the model’s ability to generate complex and diverse indoor scenes.

This figure showcases the ability of SceneCraft to generate complex indoor scenes with non-regular shapes and using arbitrary camera trajectories, which is a significant advancement over previous methods. It displays several examples of diverse, multi-room scenes, highlighting SceneCraft’s capacity to handle more complex layouts than other comparable methods that rely on panoramic views or simpler room structures.

This figure shows the results of generating a bedroom scene using SceneCraft with both a matched and mismatched prompt. The top row displays the layout (BBS) of a bedroom with its semantic map. The middle row shows the generated RGB images and depth maps with a matched prompt (‘Bedroom’). The bottom row shows the generated RGB images and depth maps with a mismatched prompt (‘Kitchen’). The mismatch in prompt causes the model to struggle with scene consistency, demonstrating the importance of prompt coherence for accurate generation with SceneCraft.
Full paper#