↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Multilingual large language models (LLMs) pose a research challenge due to their complex internal mechanisms. Existing studies primarily focus on English, neglecting crucial insights into multilingual processing. This paper tackles this issue by investigating how LLMs handle multilingualism. The study found a surprising three-stage multilingual workflow (MWork): understanding, task-solving, and generating. The authors propose this framework to explain how LLMs handle multiple languages.
The research introduces a novel method called Parallel Language-Specific Neuron Detection (PLND) to identify activated neurons for inputs in different languages. Using PLND, the authors conducted experiments by deactivating language-specific neurons in various layers. They validate the MWork framework by observing the impact on LLMs’ performance when specific neurons were deactivated, demonstrating that language-specific neurons are indeed crucial for multilingual capabilities. The authors show how fine-tuning these neurons can improve LLMs’ multilingual abilities in a particular language without compromising performance in other languages.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with multilingual LLMs because it unveils the inner workings of how these models handle multiple languages. The findings, especially the MWork framework and PLND method, provide valuable tools and insights for improving multilingual capabilities. This research also opens doors for further investigation on language-specific neurons and their role in various tasks, potentially leading to more efficient and effective multilingual models.
Visual Insights#

This figure shows the ratio of English and non-English tokens across different layers of two large language models (Vicuna-13b-v1.5 and BLOOMZ-7b1) when processing non-English queries. The heatmaps illustrate how the proportion of English tokens changes across layers. In both models, a shift towards English-centric representations is observed in the middle layers before reverting to predominantly non-English tokens in the output layers. This pattern suggests a multilingual workflow where the model initially processes the query in the original language, switches to English for reasoning in intermediate layers, and finally generates a response in the original language.

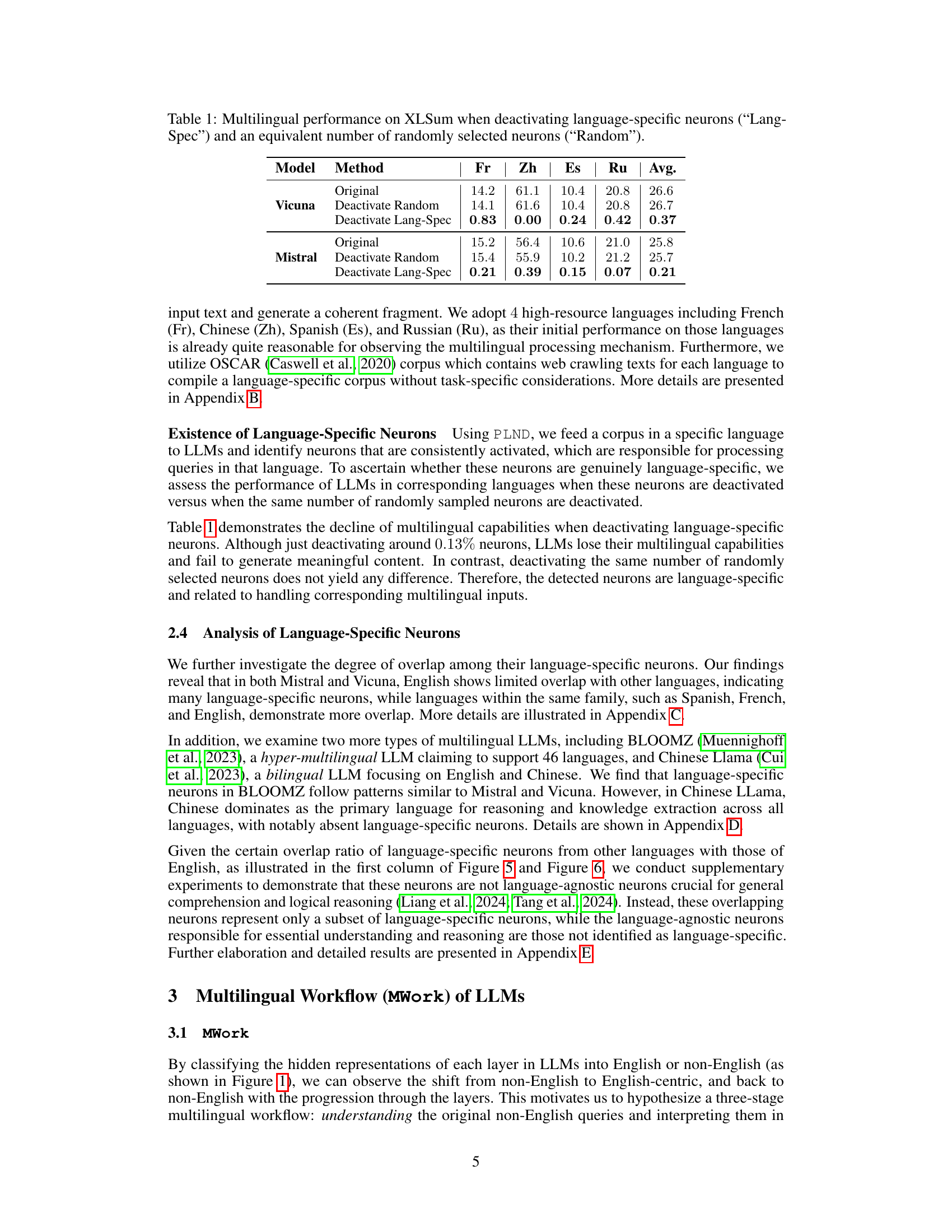
This table presents the results of a multilingual summarization experiment using the XLSum dataset. It compares the performance of two large language models (Vicuna and Mistral) under different conditions: the original model, after deactivating randomly selected neurons, and after deactivating language-specific neurons. The performance is measured for several languages (French, Chinese, Spanish, Russian) and averaged. The goal is to show that deactivating language-specific neurons significantly reduces performance more than deactivating random neurons, suggesting the importance of these neurons for multilingual capabilities.
In-depth insights#
LLM Multilingualism#
LLM multilingualism is a complex area of research focusing on how large language models (LLMs) process and generate text in multiple languages. A key challenge is understanding how LLMs handle the nuances of different languages, including their varying grammatical structures, vocabulary, and cultural contexts. Current research suggests that LLMs may not truly understand languages in the same way humans do, but rather leverage statistical relationships between words and phrases across languages to generate seemingly fluent and coherent text. This raises questions about the nature of LLM understanding, and whether it constitutes true multilingual comprehension or simply sophisticated pattern matching. Developing methods to evaluate and improve LLM multilingual capabilities is crucial, particularly for low-resource languages with limited training data. Future research should explore ways to enhance LLMs’ understanding of linguistic subtleties and cultural contexts to achieve truly robust and reliable multilingual performance. The development of novel architectures and training methods tailored for multilingual tasks is another important direction for future research.
MWork Hypothesis#
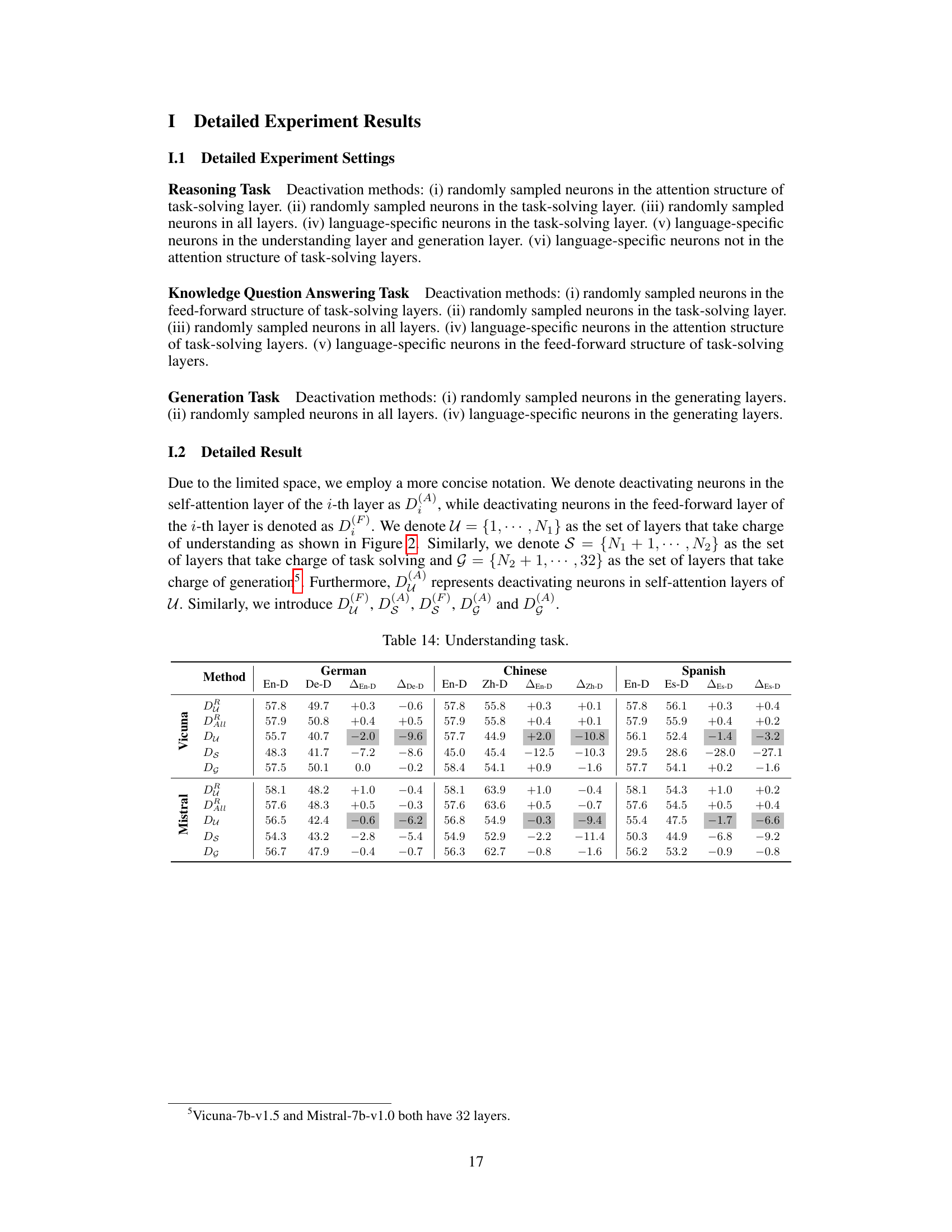
The MWork hypothesis proposes a layered approach to how large language models (LLMs) handle multilingual tasks. It posits a three-stage process: initial understanding where multilingual inputs are converted into a unified representation, possibly an English-centric one; task-solving, leveraging the unified representation and incorporating multilingual knowledge, with self-attention mechanisms focusing on reasoning and feed-forward structures handling factual knowledge; and finally, response generation, where the output is tailored to the original language of the query. This framework suggests that while English may play a central role in the intermediate processing stages, LLMs do retain and utilize multilingual information to generate appropriate responses. The hypothesis highlights the dynamic interplay between different model components and their specialized roles in processing multilingual queries. Furthermore, it opens avenues for targeted improvements in specific languages through focused fine-tuning of language-specific neurons without negatively impacting performance in other languages.
PLND Method#
The Parallel Language-specific Neuron Detection (PLND) method is a crucial innovation in the paper, offering a novel approach to identify neurons responsible for processing specific languages within large language models (LLMs). Unlike existing methods which rely on labeled data or extensive fine-tuning, PLND leverages the inherent activation patterns of neurons during the processing of different languages to identify language-specific ones. This is achieved by comparing the activation patterns when a specific neuron is activated versus deactivated during input processing. The methodology is particularly valuable because it enables the identification of language-specific neurons without the need for labeled data which significantly reduces the computational cost and data requirements. Furthermore, the parallel nature of PLND accelerates the process, making it computationally efficient for large-scale LLMs. The method is not just efficient but also effective in identifying neurons specifically associated with particular languages, as validated through extensive experiments, enabling a more refined understanding of the multilingual mechanisms within LLMs and facilitating targeted improvements.
Lang-Specific Neurons#
The concept of ‘Lang-Specific Neurons’ in large language models (LLMs) is crucial for understanding their multilingual capabilities. These neurons, identified using techniques like Parallel Language-Specific Neuron Detection (PLND), exhibit heightened activation when processing specific languages. Deactivating these neurons significantly impairs LLM performance in the corresponding language, but not others, demonstrating a localized effect. This finding supports the hypothesis of a modular, layered multilingual processing workflow within LLMs, where dedicated neural components handle different languages. The existence of lang-specific neurons also offers a promising avenue for targeted multilingual enhancement; fine-tuning these neurons using a small dataset improves performance for a given language without negatively impacting others, thus enabling resource-efficient adaptation of LLMs to low-resource languages.
Multilingual Enhance#
Multilingual enhancement in large language models (LLMs) is a significant area of research focusing on improving the models’ ability to handle multiple languages effectively. A key challenge is to enhance performance in low-resource languages without negatively impacting high-resource languages. One promising approach is fine-tuning language-specific neurons, identified through techniques like Parallel Language-specific Neuron Detection (PLND), with smaller datasets. This targeted approach allows for efficient improvements, avoiding the need for massive multilingual corpora. The results suggest that LLMs process multilingual queries in a layered manner, converting inputs to an internal representation (often English) for reasoning, and incorporating multilingual knowledge before generating responses in the original languages. Understanding this layered workflow, and the role of language-specific neurons in it, is crucial for developing strategies to enhance multilingual capabilities in LLMs. The research also highlights the importance of considering the interplay between high and low-resource languages when enhancing multilingual performance.
More visual insights#
More on figures
This figure illustrates the proposed multilingual workflow (MWork) of large language models (LLMs). It consists of three stages: understanding, task-solving, and generating. The understanding stage involves converting multilingual inputs into a unified representation (likely English). The task-solving stage is further broken down into two sub-processes: reasoning (using English primarily in the self-attention layers) and knowledge extraction (incorporating multilingual knowledge with feed-forward structures). Finally, the generating stage outputs the response in the original language of the query.

This figure shows the average number of activated language-specific neurons in Mistral’s attention and feed-forward structures when processing various multilingual queries. The x-axis represents the layer index, ranging from 0 to 31. The y-axis shows the number of language-specific neurons. Two lines are plotted: one for the attention structure and one for the feed-forward structure. The plot reveals that the number of language-specific neurons decreases in the attention structure during the task-solving phase but remains relatively consistent in the feed-forward structure across all layers. This suggests that the model relies more on English for reasoning in the attention structure while using multilingual knowledge from the feed-forward structure for additional context.

This figure displays the performance improvement achieved by fine-tuning language-specific neurons in four high-resource languages (De, Fr, Zh, Es, Ru) across four different multilingual tasks. The x-axis represents the datasets (MGSM, XQuAD, X-CSQA, XLSum), and the y-axis shows the scores. Different bars in each group represent the results using various training corpus sizes (100, 200, 400, 800 documents). The original performance is also shown as a baseline for comparison.
This figure shows the ratio of English and non-English tokens across different layers of two LLMs (Vicuna-13b-v1.5 and BLOOMZ-7b1) when processing non-English queries. It illustrates a trend where non-English queries initially have predominantly non-English tokens, but the representation becomes surprisingly English-centric in the middle layers, before reverting to mostly non-English tokens in the final layers. This observation motivated the authors’ hypothesis of a three-stage multilingual workflow.

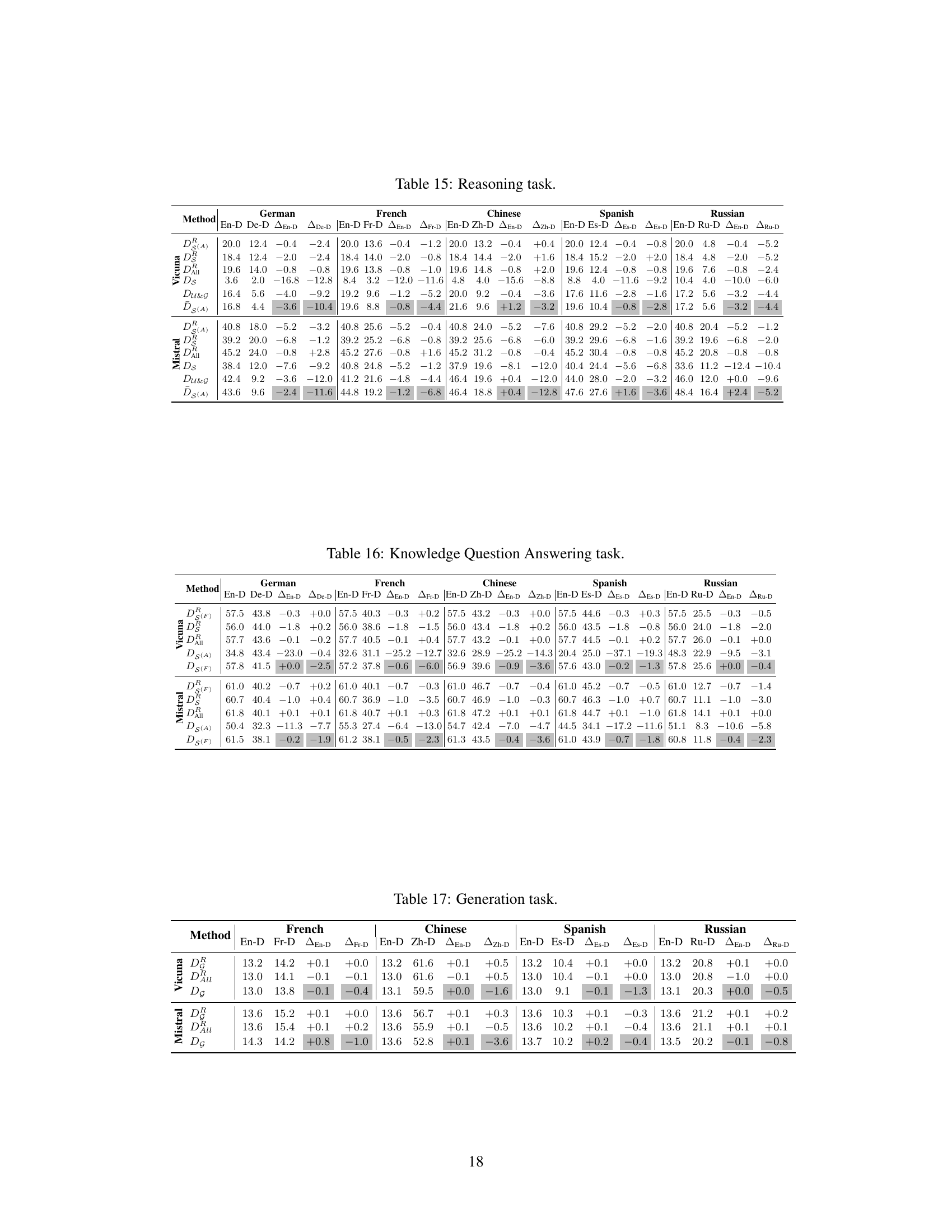
This figure visualizes the degree of overlap among language-specific neurons in the BLOOMZ large language model. It presents two heatmaps: one for the self-attention layers and one for the feed-forward layers. Each cell in the heatmap represents the degree of overlap between the language-specific neurons of two different languages. Darker colors indicate a higher degree of overlap, suggesting that certain neurons may be shared across multiple languages. The figure demonstrates that in BLOOMZ, in contrast to other models studied in the paper, there is significantly less overlap between the language-specific neurons of different languages. This suggests that BLOOMZ has a more modular multilingual representation compared to other LLMs, with each language relying on a relatively more distinct set of neurons.

This figure shows the layer-wise distribution of languages in the Chinese Llama model when processing non-English instructions. It illustrates the proportion of each language’s tokens at each layer, revealing how the model handles multilingual inputs and shifts language representation across layers.
More on tables
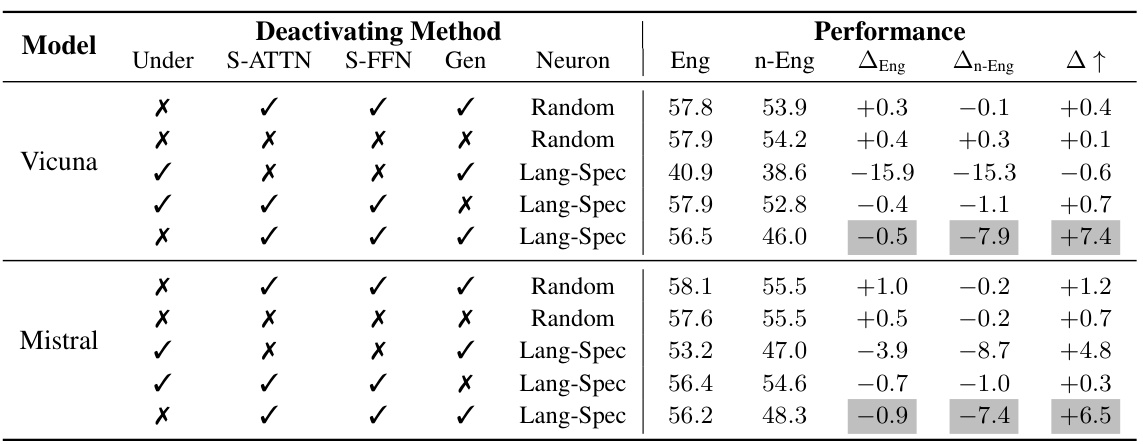
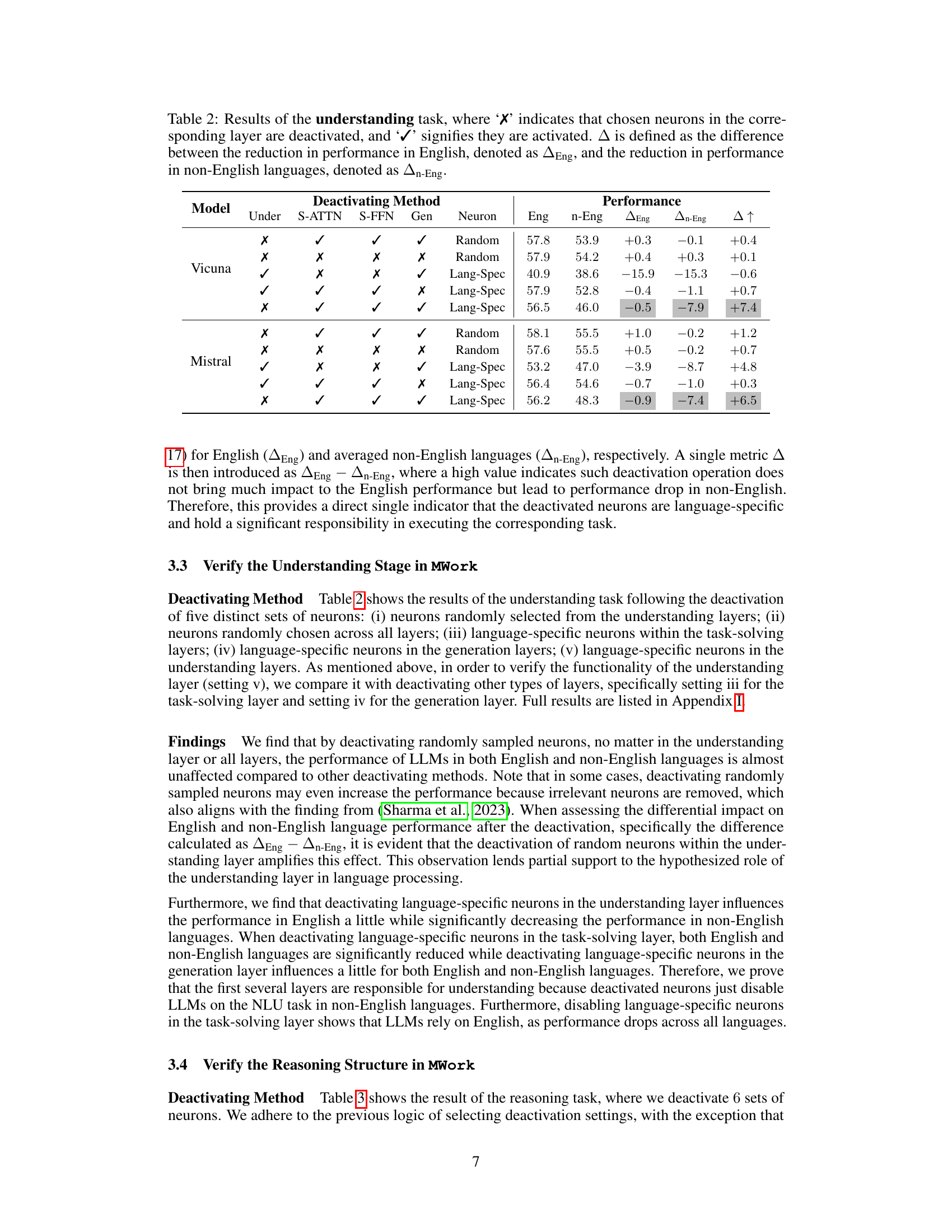
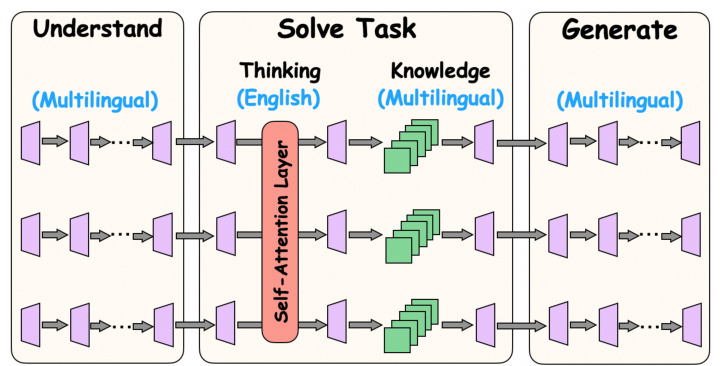
This table presents the results of the understanding task after deactivating different sets of neurons in various layers of the model. It shows the performance in English and non-English languages after deactivating random neurons or language-specific neurons in the understanding, task-solving, and generation layers. The ‘A’ metric helps determine the relative impact on English vs. non-English performance after deactivation, indicating which neurons are more crucial for each language.
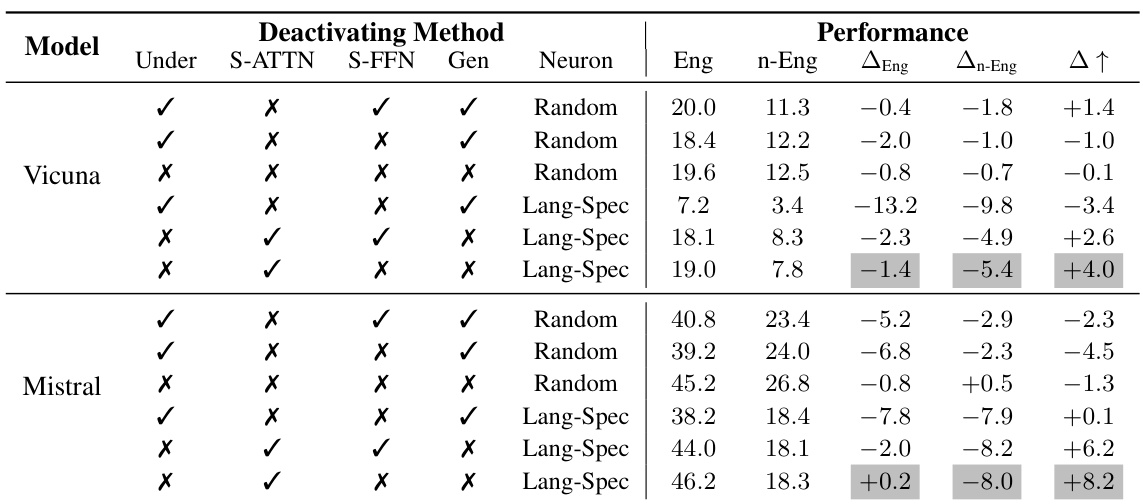
This table presents the results of an experiment on the understanding task. It shows the performance (in English and non-English languages) after deactivating different sets of neurons: randomly selected, language-specific in different layers (Understanding, Task-Solving, Generation), and the difference between the performance reduction in English and non-English. The goal is to verify the function of the understanding layer in the proposed Multilingual Workflow (MWork).
This table presents the results of an experiment on the understanding task. It shows the performance (in English and non-English languages) after deactivating different sets of neurons in various layers of the model (understanding, task-solving, and generation layers). The ‘A’ metric helps to determine if the deactivation impacts English performance differently compared to non-English performance, highlighting the specificity of certain neurons for non-English languages.

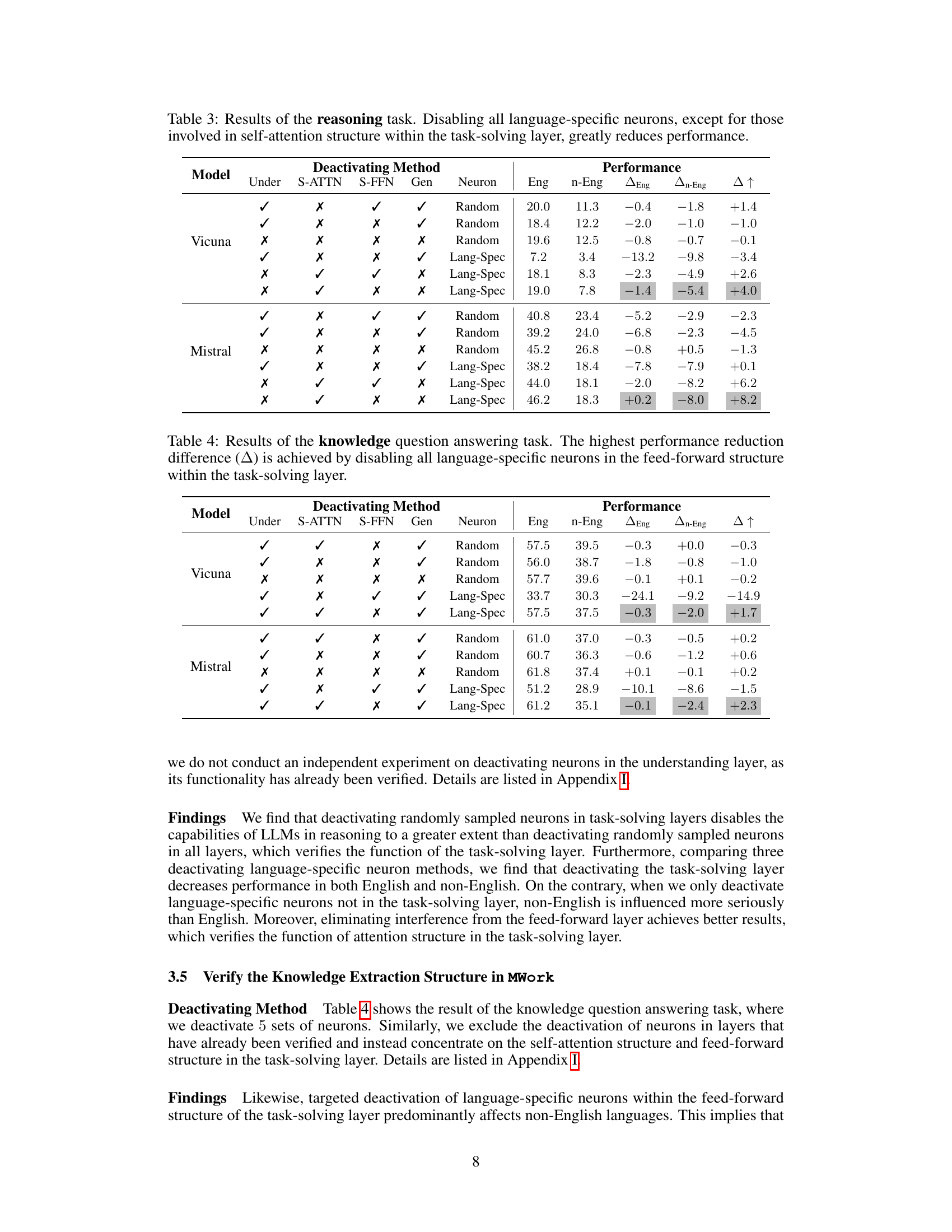
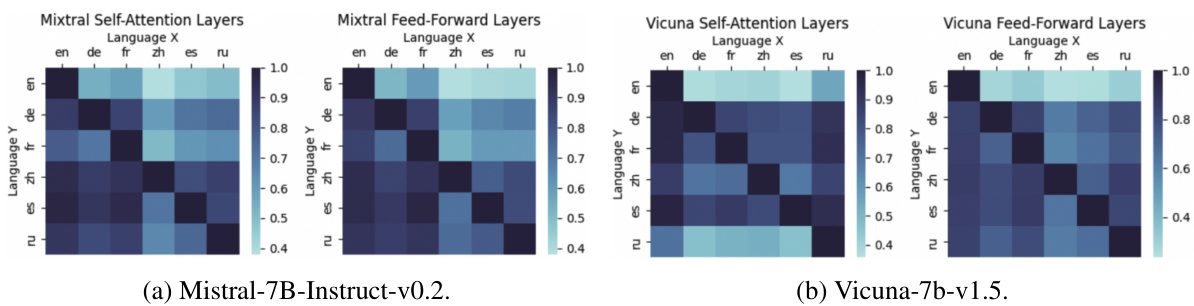
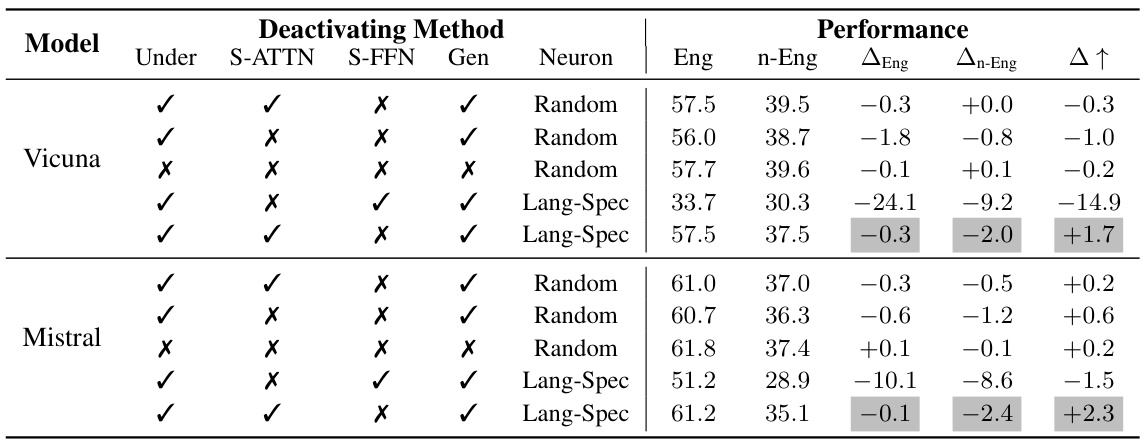
This table shows the results of the generation task when deactivating different sets of neurons in various layers of the model. It compares the performance when deactivating language-specific neurons versus randomly selected neurons, and focuses specifically on the generation layer. The results are presented for English and non-English languages, showing the impact of deactivating language-specific neurons on multilingual capabilities. The ‘Δ↑’ column indicates the performance difference between English and non-English language performance changes after deactivation.

This table shows the performance improvement achieved by fine-tuning the Mistral language model using language-specific neurons. The model was fine-tuned with 400 documents per language, and the results are presented for five languages (English, Vietnamese, Thai, Arabic, and Swahili) across four tasks. The ‘Original’ row shows the performance before fine-tuning, ‘Random’ shows performance after fine-tuning a random set of neurons, and ‘Lang-Spec’ shows results after fine-tuning language-specific neurons. The improvements in low-resource languages are notable.

This table shows the size of the corpus used for each of the six languages in the study (English, German, French, Chinese, Spanish, and Russian). It indicates the number of documents (Corpus Size), the number of unique words within those documents (Corpus Vocab), and the total number of words in the vocabulary of that language (Vocab Size). The corpus size is tailored to ensure substantial coverage of each language’s vocabulary.

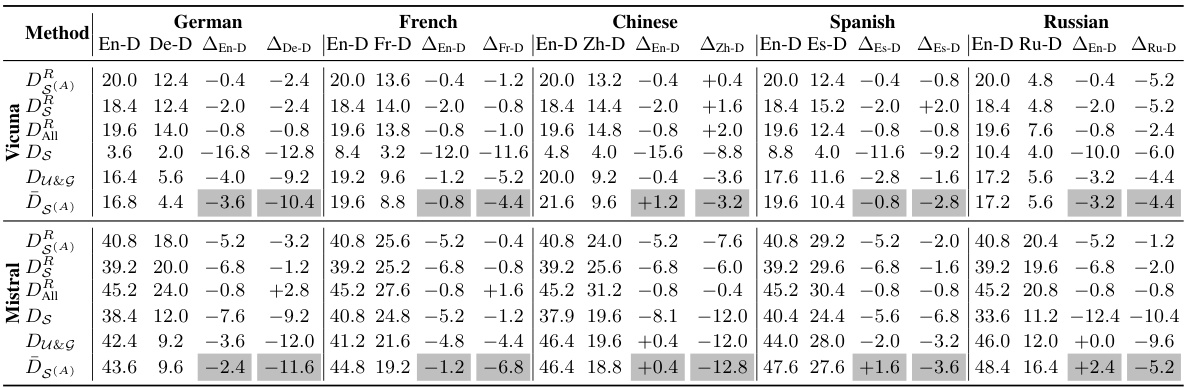
This table presents the results of an experiment where language-specific neurons were deactivated in a multilingual language model. Specifically, it shows the impact of deactivating all language-specific neurons versus only those that do not overlap with English. The results are presented in terms of the model’s performance on English and non-English languages, showing the effect of removing language-specific neurons on multilingual capabilities.

This table presents the results of an experiment where language-specific neurons, excluding those shared with English, were deactivated. It compares the performance in English and non-English languages after this selective deactivation to the performance when all language-specific neurons are deactivated. The goal is to investigate the impact of removing the overlapping neurons and assess their role in multilingual understanding.

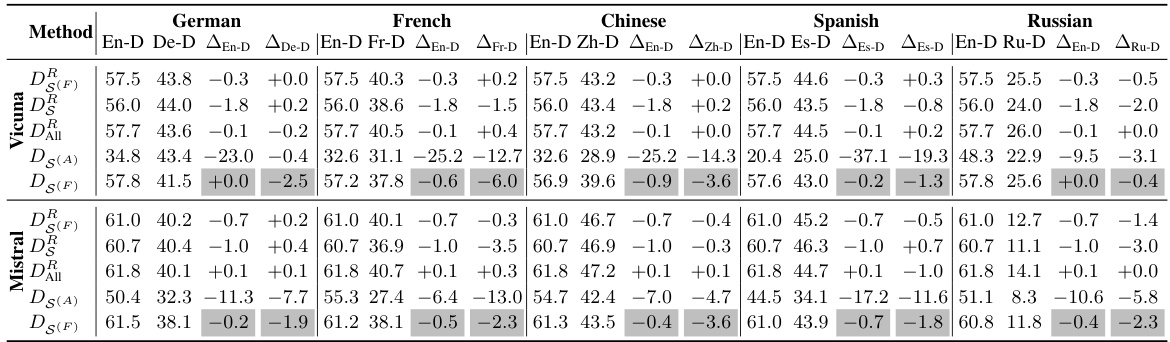
This table presents the results of a multilingual summarization experiment on the XLSum dataset using two large language models (Vicuna and Mistral). It shows the performance (average F1 score) of each model on four languages (French, Chinese, Spanish, and Russian) under two conditions: 1) Deactivating neurons identified as being specific to each language; 2) Deactivating the same number of randomly selected neurons. The comparison reveals the impact of language-specific neurons on multilingual summarization performance.
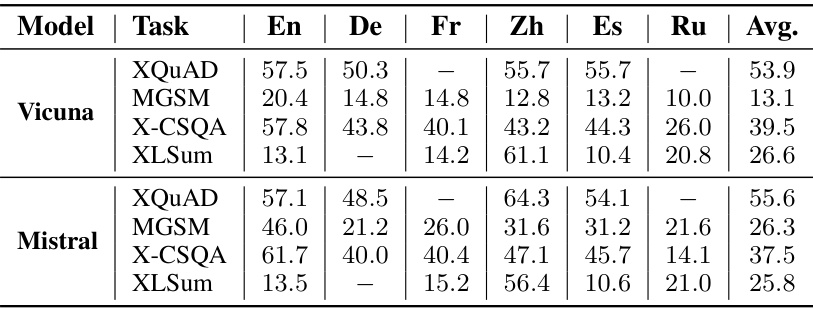
This table presents the results of a multilingual summarization experiment on the XLSum dataset. It compares the performance of two large language models (Vicuna and Mistral) when language-specific neurons (neurons consistently activated for specific languages) are deactivated, versus when an equivalent number of random neurons are deactivated. The performance is measured across four high-resource languages (French, Chinese, Spanish, Russian) using the average F1 score, showing the impact of language-specific neurons on the model’s ability to summarize text in different languages. The metric shows that deactivating language-specific neurons causes a significantly larger drop in performance than deactivating random neurons, indicating the crucial role of language-specific neurons in handling multilingual tasks.

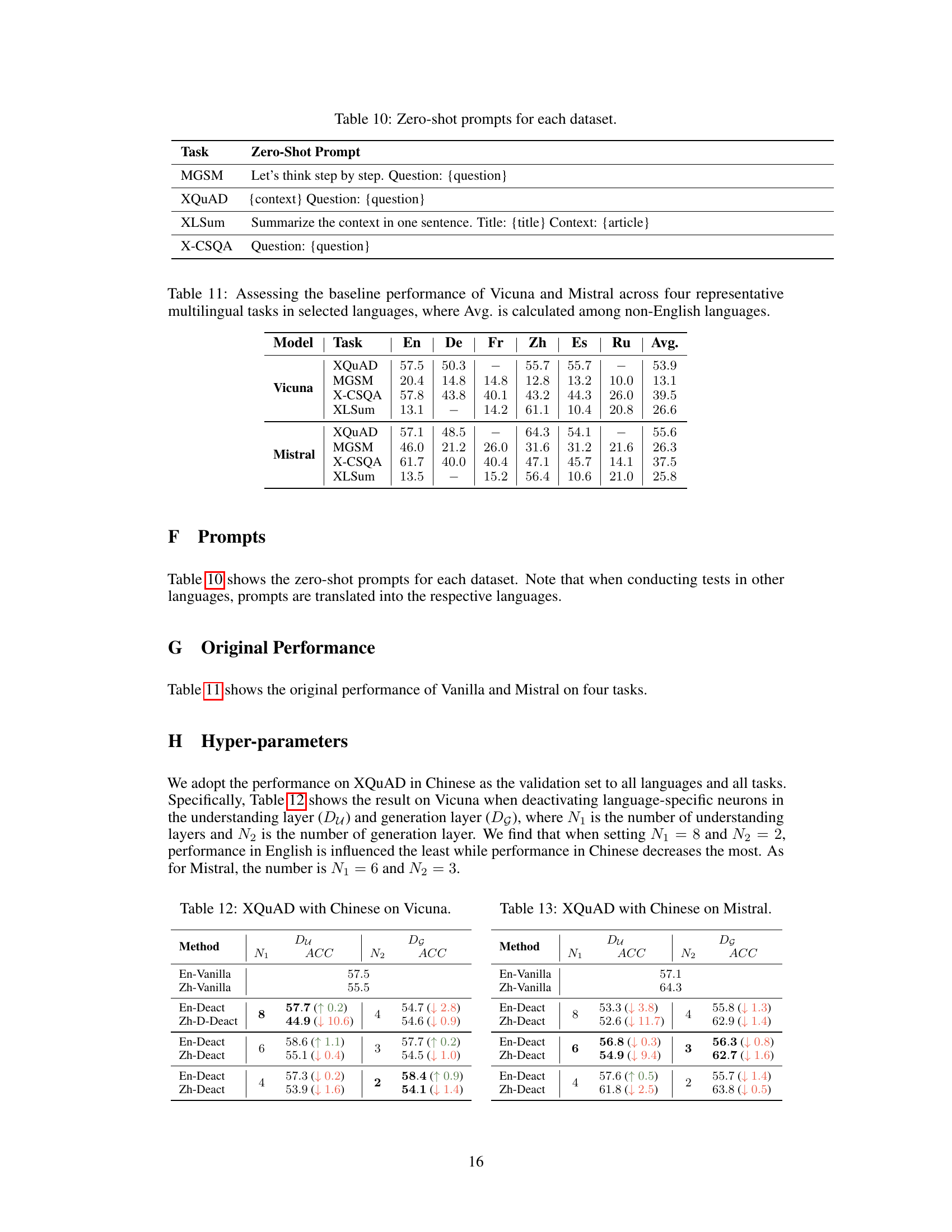
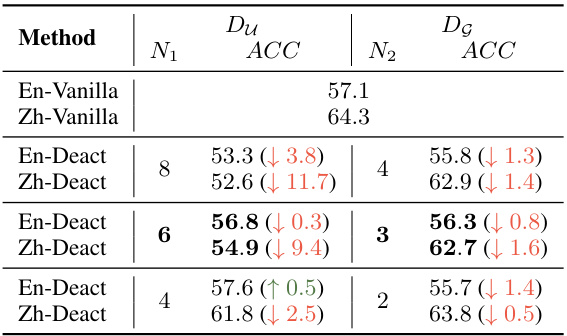
This table shows the results of the XQuAD experiment on Mistral model with Chinese language. It presents the accuracy (ACC) achieved under different settings of deactivating neurons (Du) in the understanding layer and deactivating neurons (Dg) in the generation layer with various numbers of layers (N1 and N2) involved. The results are compared to the original performance of the model on English (En-Vanilla) and Chinese (Zh-Vanilla). It helps in determining the optimal layer numbers (N1 and N2) for deactivation to maximize performance.
This table presents the results of a multilingual summarization experiment using the XLSum dataset. It shows the performance of two large language models (Vicuna and Mistral) when language-specific neurons (neurons consistently activated when processing a particular language) were deactivated, compared to when an equivalent number of randomly selected neurons were deactivated. The performance is measured in terms of average scores across four languages (French, Chinese, Spanish, and Russian). The goal is to demonstrate the impact of language-specific neurons on the models’ multilingual capabilities.

This table presents the results of a multilingual summarization experiment on the XLSum dataset using two large language models (LLMs): Vicuna and Mistral. The experiment involved selectively deactivating either language-specific neurons or a random set of neurons within the models. The table shows the performance (likely measured as accuracy or ROUGE score) on summarization tasks across several languages (French, Chinese, Spanish, Russian) for each deactivation method. It allows comparison of the impact of deactivating language-specific versus randomly selected neurons on multilingual performance.
This table presents the results of a multilingual summarization experiment using the XLSum dataset. It shows the performance of two language models (Vicuna and Mistral) when language-specific neurons are deactivated, compared to when a similar number of randomly selected neurons are deactivated. The performance is measured across multiple languages (French, Chinese, Spanish, Russian) and averaged. The table helps demonstrate the impact of language-specific neurons on multilingual capabilities.
This table shows the results of multilingual text summarization experiments using the XLSum dataset. The performance of two large language models (Vicuna and Mistral) is evaluated under two conditions: deactivating language-specific neurons and deactivating a similar number of randomly selected neurons. The metrics are presented for several high-resource languages (French, Chinese, Spanish, and Russian), showing the impact of deactivating language-specific neurons on the models’ ability to perform summarization in various languages. The average performance across all languages is also included.

This table presents the results of a multilingual summarization experiment using the XLSum dataset. It compares the performance of two large language models (Vicuna and Mistral) when language-specific neurons are deactivated versus when a comparable number of random neurons are deactivated. The goal is to assess the impact of language-specific neurons on the models’ ability to summarize text in different languages. The table shows the performance (presumably a metric like ROUGE score) for each language (French, Chinese, Spanish, Russian) and the average across these languages, broken down by whether language-specific or random neurons were deactivated. This helps determine the importance of language-specific neurons for multilingual capabilities.
Full paper#