↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Video restoration faces the challenge of efficiently modeling video frame transition dynamics. Existing methods often process many frames simultaneously, leading to high computational costs and memory consumption, or sequentially, leading to error accumulation and limiting parallelization. This paper introduces TURTLE, a novel video restoration framework that addresses these limitations.
TURTLE uses a truncated causal history model. It efficiently summarizes a video frame’s history to improve restoration quality while maintaining computational efficiency. By storing and summarizing a truncated history, TURTLE avoids the need to process numerous frames in parallel or sequentially. The framework achieves state-of-the-art results on several video restoration benchmarks, including video desnowing, deraining, and super-resolution, while significantly reducing computational costs compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient approach to video restoration, significantly improving performance and computational efficiency compared to existing methods. It tackles the challenging problem of modeling temporal dynamics in video effectively by using a truncated causal history model, demonstrating state-of-the-art results across several video restoration benchmarks. This work will be highly relevant to researchers working on video processing, computer vision, and deep learning, and opens up new avenues for more efficient and high-performing video restoration techniques.
Visual Insights#

This figure shows the architecture of the proposed video restoration method, TURTLE. It’s a U-Net style architecture with historyless feedforward encoder blocks and a decoder that incorporates a Causal History Model (CHM) to utilize information from previous frames. The figure also includes example results of video restoration for various tasks, such as raindrop removal, night deraining, and deblurring, highlighting the model’s capabilities.
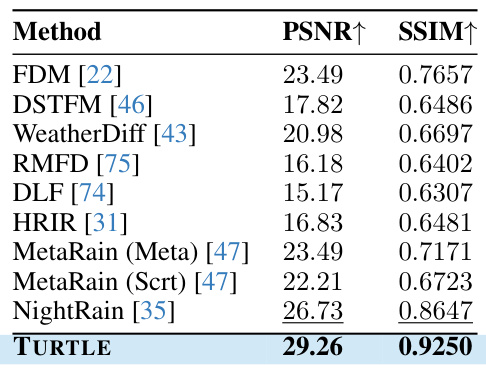
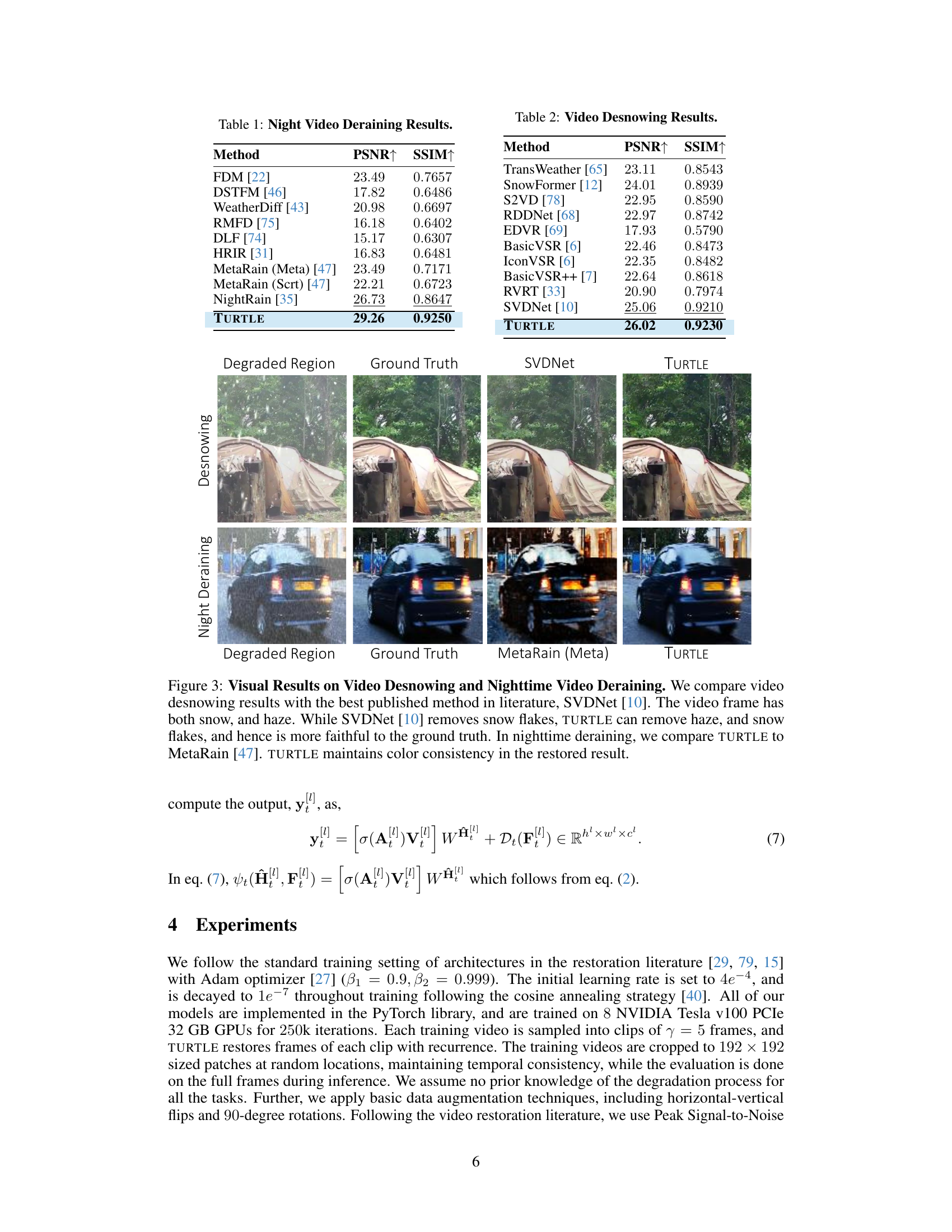
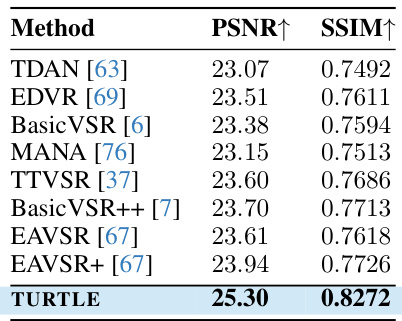
This table presents a comparison of different methods for night video deraining, showing the PSNR and SSIM scores achieved by each method. The results demonstrate the performance of TURTLE compared to existing state-of-the-art methods. Higher PSNR and SSIM values indicate better restoration quality.
In-depth insights#
Truncated Causal Model#
A truncated causal model, in the context of video restoration, represents a powerful approach to efficiently model temporal dependencies in video data. Truncation limits the model’s reliance on an extensive history of frames, thus enhancing computational efficiency, a crucial aspect for real-time processing. The causal nature ensures that the model’s predictions only depend on past frames, avoiding the need for future frames and aligning with online processing scenarios. This framework is particularly beneficial when dealing with long sequences where storing and processing the entire history becomes infeasible. By summarizing historical information, the model retains relevant contextual features while managing computational resources. This technique allows for a balance between considering temporal context and controlling model complexity, making it suitable for various video restoration tasks. The effectiveness hinges on the method employed for truncation and summarization which may involve techniques like selective feature aggregation or memory-efficient recurrent structures. The choice of these methods can greatly influence the model’s performance and the trade-off between accuracy and computational cost.
CHM: History Alignment#
A hypothetical heading, “CHM: History Alignment,” suggests a crucial mechanism within a video restoration model. It likely describes how the model aligns and leverages information from previously processed frames (the “history”) to enhance the current frame’s restoration. This process is likely sophisticated, addressing challenges like motion and inter-frame variations. Effective alignment is key to the model’s success, preventing cumulative errors and efficiently utilizing previously learned features. The method might involve motion compensation techniques to account for movement between frames, and a similarity-based retrieval system to select the most relevant historical information for each specific restoration task. The “causal” nature of CHM likely means that only past information is used, avoiding issues associated with future frames in real-time applications. Successfully implementing such an alignment strategy is critical for computationally efficient and high-quality video restoration, particularly with long sequences of frames.
Video Restoration Benchmarks#
A robust evaluation of video restoration methods necessitates a comprehensive benchmark suite. Key aspects include diverse degradation types (noise, blur, rain, snow), realistic and synthetic datasets, and standardized metrics (PSNR, SSIM, visual quality). Dataset diversity is crucial, encompassing variations in scene complexity, motion dynamics, and recording conditions. Metric selection should consider both objective (numerical) and subjective (perceptual) evaluations, recognizing that numerical scores alone might not fully capture visual fidelity. Careful consideration of computational efficiency is also vital; the benchmark should assess the trade-off between restoration quality and processing speed. Finally, a well-defined benchmark facilitates fair comparison and drives progress in the field by providing a common standard for evaluating new techniques and advancing the state-of-the-art.
Computational Efficiency#
The research paper highlights the crucial aspect of computational efficiency in video restoration. Traditional methods often process numerous contextual frames simultaneously, leading to high memory consumption and slow inference times. The proposed TURTLE model addresses this limitation by employing a truncated causal history model. Instead of parallel processing, TURTLE summarizes a truncated history of the input frame’s latent representation into an evolving state, enhancing efficiency. This is achieved through a similarity-based retrieval mechanism implicitly accounting for motion and alignment, thus efficiently utilizing information across multiple frames. The causal design enables recurrence during inference while maintaining parallel training, demonstrating a significant reduction in computational cost compared to existing contextual methods across multiple video restoration tasks. This improved efficiency is a major contribution, enabling applications on resource-constrained devices and faster processing, making the approach both powerful and practical.
Future Research: Scope#
Future research could explore several avenues to enhance the proposed truncated causal history model. Improving the motion compensation mechanism is crucial, potentially using more advanced techniques than optical flow to handle challenging conditions like severe degradation or fast motion. Investigating alternative history aggregation strategies beyond the similarity-based retrieval method would also be beneficial. Exploring different attention mechanisms or incorporating more sophisticated temporal modeling techniques could enhance performance. Extending the model to handle a wider variety of video restoration tasks would broaden its applicability, testing on more challenging datasets and exploring the potential for cross-task generalization. Finally, reducing computational cost while maintaining accuracy is important for real-world applications; investigating more efficient network architectures or optimizing the existing model for specific hardware could achieve this.
More visual insights#
More on figures
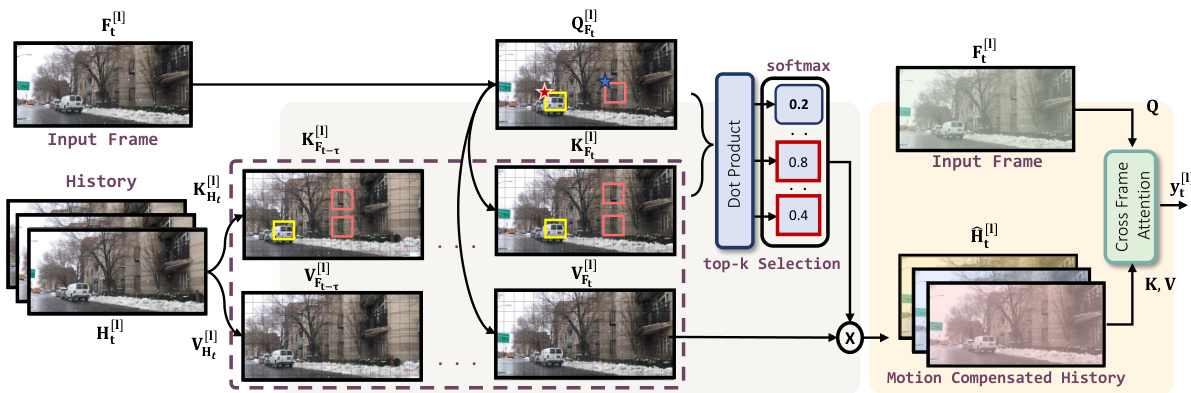
The figure illustrates the Causal History Module (CHM), a key component of the TURTLE architecture. CHM aligns patches from the current frame with similar patches from a truncated history of previous frames. This alignment is implicit, learned by the model rather than relying on explicit motion estimation. After alignment, a scoring mechanism determines the relevance of each historical patch to the current frame’s restoration. The relevant patches are aggregated to create a refined output that combines current frame information with relevant historical information, improving restoration quality.

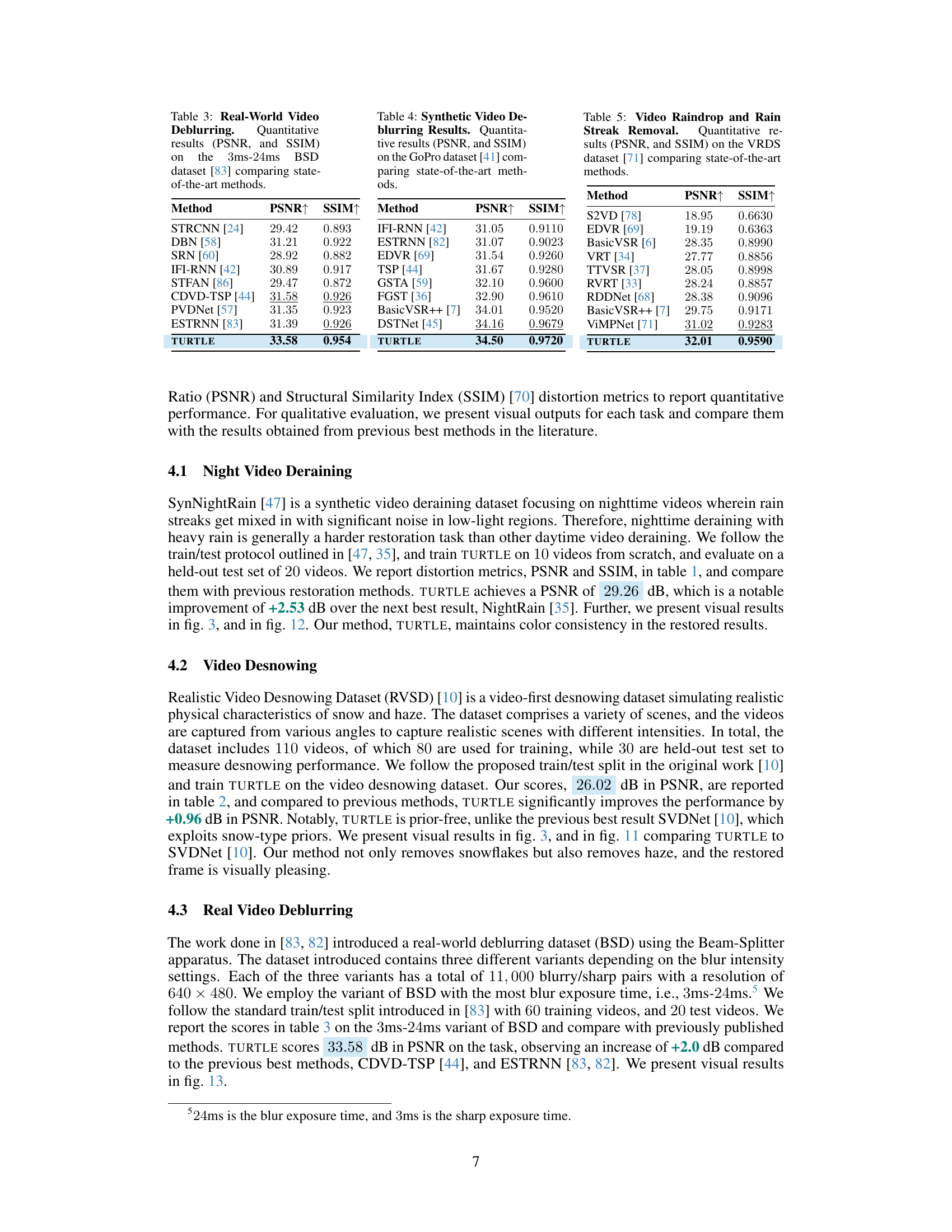
This figure shows visual comparisons of video desnowing and nighttime deraining results between TURTLE and other state-of-the-art methods. The desnowing example demonstrates that while SVDNet removes snow, TURTLE additionally removes haze, resulting in a more accurate restoration. In the nighttime deraining example, TURTLE produces a result that is more color-consistent than MetaRain.

This figure shows the architecture of the proposed video restoration method, TURTLE. It is a U-Net architecture with historyless feedforward encoder blocks and a decoder that incorporates a causal history model (CHM). The CHM uses a truncated history of the input to improve restoration. The figure also includes examples of video restoration results for various tasks such as raindrop removal, night deraining, and video deblurring, demonstrating the effectiveness of the proposed method.

This figure shows visual comparisons of video denoising and super-resolution results using different methods, including TURTLE and several state-of-the-art techniques. The top row presents a blind video denoising example, highlighting TURTLE’s ability to preserve fine details compared to BSVD-64’s smudged output. The bottom row showcases video super-resolution, demonstrating TURTLE’s superior sharpness and detail retention compared to methods such as TTVSR, BasicVSR++, and EAVSR, which produce blurrier results.

The figure shows the architecture of the proposed TURTLE model for video restoration. It’s a U-Net-like architecture with a historyless feedforward encoder and a decoder that uses a Causal History Model (CHM) to incorporate information from previous frames. The right side of the image shows examples of video restoration results from different tasks.

This figure shows how the causal history model (CHM) tracks similar patches across the frames in the history. The top row shows successful tracking, while the bottom row demonstrates limitations when redundant patterns exist. Note that this visualization uses input frames for clarity; the CHM actually operates on feature maps.

This figure shows the architecture of the Historyless Feed Forward Network (FFN) and the Transformer block used in the Causal History Module (CHM). The Historyless FFN consists of several convolutional layers, followed by a GELU activation function, and then a 1x1 convolutional layer. The Transformer block is similar to the one used in the Restormer paper [79], which uses a combination of pointwise convolutions, depthwise convolutions, channel attention, and channel MLP. The figure highlights the differences in architecture between the Historyless FFN and the Transformer block, illustrating their roles within the overall TURTLE model.

This figure shows a comparison of video deblurring and rain removal results between TURTLE and other state-of-the-art methods. The top row demonstrates that TURTLE effectively removes blur from a video frame without introducing artifacts, unlike DSTNet, which leaves artifacts. The bottom row showcases the superiority of TURTLE over ViMPNet in removing rain streaks and raindrops, preserving details that ViMPNet fails to retain.

This figure shows visual comparisons of video deblurring and rain removal results. The top row demonstrates that TURTLE effectively removes blur from a video sequence better than a competing method (DSTNet), preserving fine details like license plates. The bottom rows compare TURTLE to ViMPNet on a rain/streak removal task. While ViMPNet leaves artifacts (blurriness, missing details), TURTLE produces cleaner results.

This figure shows visual comparisons of video desnowing and nighttime video deraining results between the proposed TURTLE method and existing state-of-the-art methods (SVDNet for desnowing and MetaRain for deraining). The results demonstrate TURTLE’s improved ability to remove both snow and haze in desnowing, and to maintain color consistency while removing rain streaks in nighttime deraining, showcasing superior performance compared to existing methods.

This figure shows the architecture of the proposed TURTLE model for video restoration. It’s a U-Net architecture with historyless feedforward encoder blocks and a decoder that uses a causal history model (CHM) to incorporate previous frames’ information. The figure also displays example restoration results for various video degradation types, demonstrating the model’s capability.

This figure shows the architecture of the proposed TURTLE model for video restoration. It’s a U-Net-like structure with a historyless feedforward encoder and a decoder that incorporates a Causal History Model (CHM). The CHM leverages a truncated history of the input frames to improve restoration quality. The figure also includes examples of restoration results from several video restoration tasks.

This figure shows the overall architecture of the proposed TURTLE model for video restoration. The model uses a U-Net architecture with historyless feedforward encoder blocks and a decoder that incorporates a causal history model (CHM) to leverage information from previously processed frames. The right side of the figure displays examples of video restoration results from various tasks, illustrating the model’s capabilities in handling different types of degradation, such as raindrops, rain streaks, night deraining, and deblurring.
More on tables
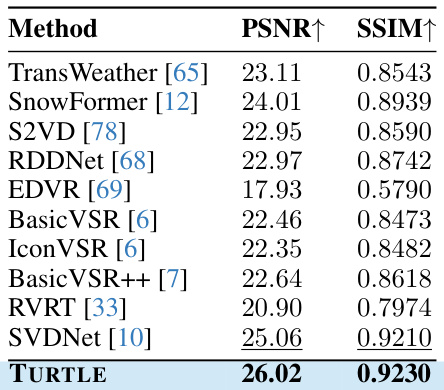
This table presents a comparison of different video desnowing methods in terms of Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). The PSNR and SSIM scores are presented for various state-of-the-art methods, including TransWeather, SnowFormer, S2VD, RDDNet, EDVR, BasicVSR, IconVSR, BasicVSR++, RVRT, and SVDNet, along with the proposed method, TURTLE. Higher PSNR and SSIM values indicate better performance in video desnowing.
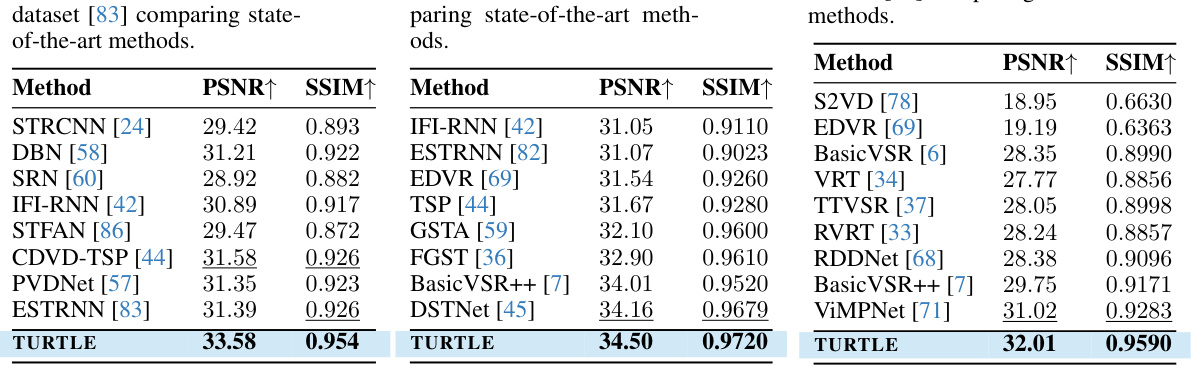
This table shows a comparison of different video deblurring methods on the BSD dataset. The methods are evaluated using two metrics: PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). Higher values for both metrics indicate better performance. The table highlights the performance of the proposed TURTLE method compared to other state-of-the-art techniques on real-world blurry videos captured at various blur intensities (3ms-24ms).
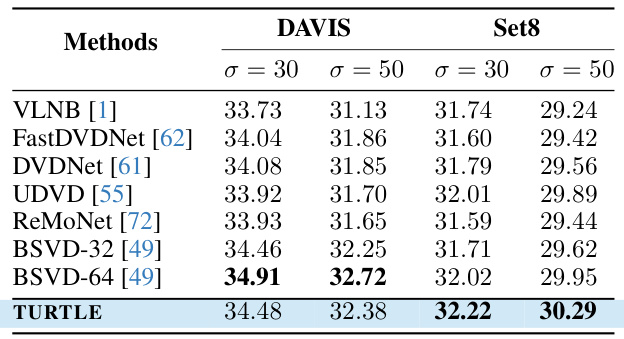
This table presents the quantitative results of blind video denoising experiments on two benchmark datasets, DAVIS and Set8. The results are evaluated using two metrics: Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). Different noise levels (σ = 30 and σ = 50) are tested. The table compares the performance of TURTLE with several state-of-the-art methods. Higher PSNR and SSIM values indicate better denoising performance.
This table presents a comparison of different video denoising methods on two datasets, DAVIS and Set8. The methods are evaluated using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), two common metrics for assessing the quality of denoised videos. The results show the performance of various methods under different noise levels (σ = 30 and σ = 50).
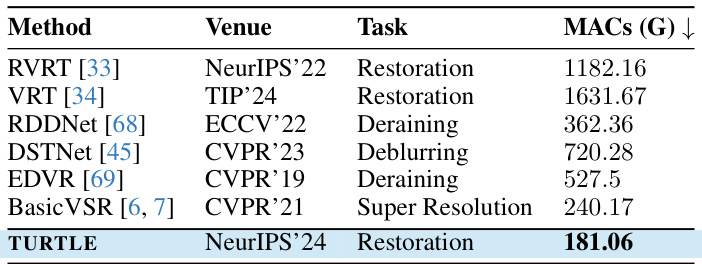
This table compares the computational cost (in Giga Multiply-Accumulates or MACs) of the proposed TURTLE model with several other state-of-the-art video restoration methods. It shows that TURTLE achieves comparable or better performance with significantly lower computational cost. The appendix F provides more detail on the computational profiling.

This table presents the ablation study results for three different aspects of the TURTLE model: the State Align Block, the truncation factor (τ), and the value of k in topk. Each part shows the PSNR score obtained with different configurations, providing insights into the impact of each component on the model’s performance. The results indicate the effectiveness of the State Align Block and CHM in improving performance, an optimal truncation factor of 5, and an optimal value of k as 5 for topk.

This table presents the ablation study on the State Align Block in the Causal History Model (CHM) within the TURTLE architecture. It compares the PSNR values achieved with different configurations: No CHM (no causal history model), No φ (no state alignment), and the full TURTLE model. The results demonstrate the importance of both the State Align Block and CHM for optimal performance.

This ablation study compares the performance of using softmax versus topk (with k=5) in the model. The results show that using topk yields better performance (32.26) compared to using softmax alone (32.04). This indicates that the topk selection mechanism is beneficial for improving restoration quality by focusing on the most relevant features from the history.

This table compares the computational performance of TURTLE against three other video restoration methods (ShiftNet, VRT, and RVRT). The comparison is made across various video resolutions (256x256 to 1920x1080), and assesses parameters like inference time, MACs (million multiply-accumulate operations), FLOPs (floating-point operations), and GPU memory usage. The results highlight TURTLE’s efficiency and scalability, particularly at higher resolutions, where other methods often encounter out-of-memory errors.
Full paper#