↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often struggle in real-world scenarios with inherent ambiguity and incomplete information. Existing methods focus on improving reasoning within the given context, neglecting the crucial ability to actively seek missing information via effective questioning. This limitation hinders LLM performance in applications like medical diagnosis and troubleshooting, where acquiring necessary information is paramount.
The paper introduces “Uncertainty of Thoughts” (UoT), a novel algorithm that empowers LLMs to actively seek information by strategically asking questions. UoT combines an uncertainty-aware simulation, uncertainty-based rewards, and a reward propagation scheme. Experimental results across multiple LLMs and diverse tasks show a substantial 38.1% average improvement in task success rate compared to direct prompting. UoT demonstrates enhanced efficiency by reducing the number of questions needed for successful task completion. The researchers also make their benchmark and code publicly available, fostering future research and development in this crucial area.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs in uncertain environments. It introduces a novel approach for enhancing information seeking abilities, improving LLM performance on various tasks. The proposed method, UoT, offers a principled framework with broad applicability and opens exciting avenues for future research in improving LLM efficiency and performance in complex, real-world applications.
Visual Insights#

This figure shows a doctor-patient conversation illustrating the importance of information seeking in medical diagnosis. The patient initially reports only a headache. Through a series of well-placed questions by the doctor, additional crucial details (light sensitivity and a recent head injury) are elicited, leading to a correct diagnosis of post-concussion syndrome. The figure highlights how incomplete initial information necessitates active information gathering to achieve an accurate diagnosis.
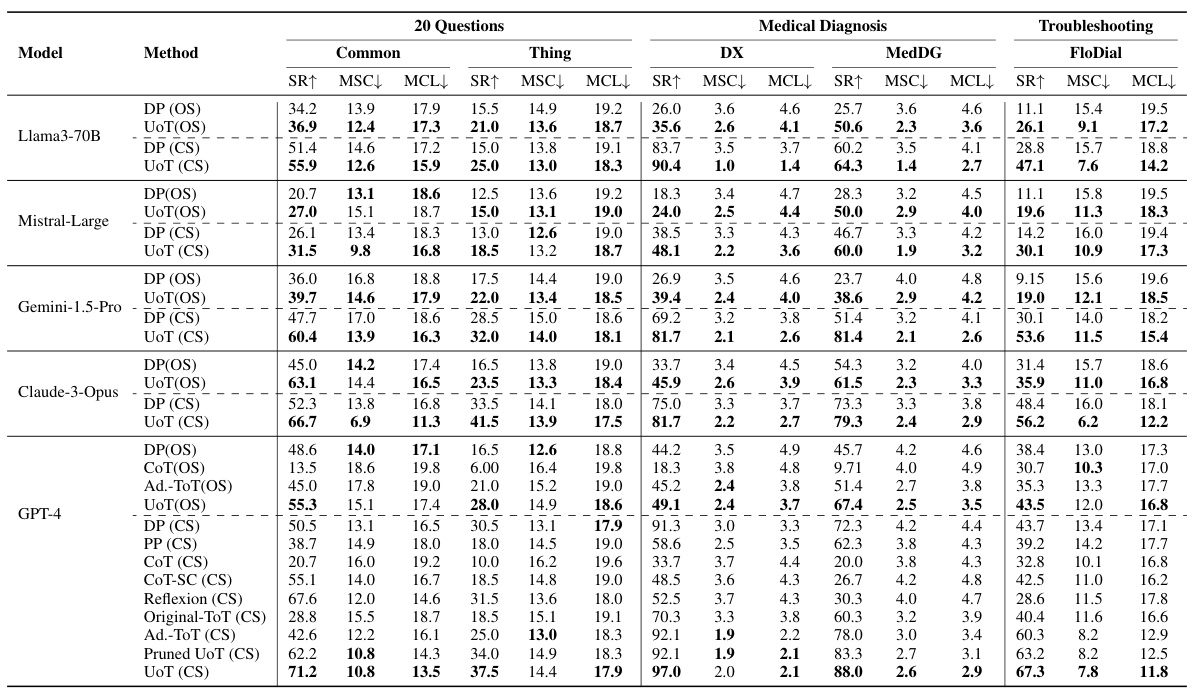
This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs. The table compares the performance of different methods, including Direct Prompting and Uncertainty of Thoughts (UoT), in terms of Success Rate (SR), the average length of successful conversations (MSC), and the average length of all conversations (MCL). Higher SR indicates better performance. Lower MSC and MCL values indicate higher efficiency. The results are shown separately for both Open Set and Closed Set settings.
In-depth insights#
UoT: Info Seeking#
The concept of “UoT: Info Seeking” centers on enhancing Large Language Models (LLMs) to actively seek information, rather than passively relying on initial input. This is achieved through an uncertainty-aware planning algorithm that allows the LLM to simulate future scenarios, assess uncertainty, and strategically select questions to maximize information gain. Uncertainty-based rewards incentivize the model to ask questions that significantly reduce its uncertainty, driving the information-seeking process. The effectiveness of this approach is demonstrated across various tasks involving medical diagnosis, troubleshooting, and interactive games, showing a considerable improvement in task completion rates and efficiency. Key to UoT’s success is the integration of simulation, reward mechanisms, and question selection using reward propagation, creating a principled approach for active information seeking in LLMs. This represents a significant step towards more robust and adaptable AI agents capable of operating effectively in uncertain real-world environments.
Uncertainty Models#
The concept of ‘Uncertainty Models’ in the context of a research paper likely delves into how uncertainty is represented and handled within a system. This could involve exploring various probabilistic frameworks, such as Bayesian networks or Markov models, to quantify and reason under uncertainty. Different types of uncertainty, like aleatoric (inherent randomness) and epistemic (lack of knowledge), might be distinguished and modeled separately. The paper may investigate how these models are used for prediction, decision-making, or risk assessment in a particular application domain. A key aspect could be the evaluation of these uncertainty models. How well do they capture the true uncertainty? How computationally expensive are they? Are they robust to noise or incomplete data? The analysis might involve comparing different uncertainty models, assessing their performance on benchmark datasets, and examining the trade-off between accuracy and complexity. Ultimately, the discussion of uncertainty models is crucial for evaluating the reliability and trustworthiness of any system built upon them, highlighting the need for robust and well-calibrated uncertainty quantification.
Reward Design#
Effective reward design is crucial for training reinforcement learning agents, especially in complex tasks involving uncertainty. A well-crafted reward function should accurately reflect the desired behavior, guiding the agent towards successful task completion. In scenarios with inherent ambiguity, the reward needs to incentivize information-seeking actions, prompting the agent to actively acquire knowledge rather than relying solely on initial information. Uncertainty-based rewards are particularly valuable in such scenarios, providing a principled way to balance exploration and exploitation. A key aspect is reward propagation, which allows the agent to evaluate the long-term consequences of its actions, making decisions that maximize overall reward over time. The effectiveness of the reward function should be empirically validated through rigorous experimentation, potentially involving different scaling methods and hyperparameters, to ensure optimal performance and efficiency.
LLM Evaluation#
Evaluating Large Language Models (LLMs) is a complex undertaking. Standard metrics like perplexity or BLEU scores are insufficient, particularly for assessing the nuanced abilities of LLMs in real-world scenarios. Effective LLM evaluation must consider the task at hand, encompassing various aspects of performance, such as accuracy, fluency, relevance, and overall coherence. Benchmark datasets are valuable for comparing models, but these must be carefully designed and representative of the intended application. Moreover, the inherent ambiguity of natural language necessitates incorporating human evaluation, especially for subjective qualities like creativity or common sense. Methods for quantifying uncertainty and reasoning abilities are crucial for a complete assessment, especially as LLMs are increasingly used in high-stakes applications. Thus, future LLM evaluation strategies should emphasize holistic approaches that integrate quantitative metrics with qualitative human judgments, focusing on practical task performance within realistic contexts. Bias detection and mitigation are also crucial considerations in a responsible evaluation framework. Ultimately, LLM evaluation should aim to provide a comprehensive and transparent understanding of a model’s capabilities and limitations for both developers and end-users.
Future of UoT#
The future of Uncertainty of Thoughts (UoT) looks promising, with potential enhancements across several key areas. Improving the efficiency of the simulation process is crucial; current methods may become computationally expensive for complex tasks or larger possibility spaces. Exploration of more efficient tree search algorithms or alternative simulation techniques (e.g., sampling-based methods) could significantly boost scalability. Expanding UoT to handle open-ended questions and responses will broaden its applicability to real-world scenarios with inherent ambiguity. This requires developing more sophisticated natural language processing methods to interpret nuanced answers and refine uncertainty estimates effectively. Integrating UoT with other advanced reasoning techniques, such as chain-of-thought prompting or tree-of-thoughts, could further amplify its capabilities by combining diverse reasoning strategies. Finally, exploring applications in diverse domains beyond the examples provided (medical diagnosis, troubleshooting, and 20 Questions) represents a significant opportunity. Research should focus on developing specialized reward functions appropriate for specific problem domains and establishing comprehensive benchmarks to evaluate the effectiveness of UoT across a variety of tasks and language models.
More visual insights#
More on figures

This figure illustrates the Uncertainty of Thoughts (UoT) algorithm’s three main components. (a) shows how UoT generates candidate questions and simulates possible future scenarios using an LLM. (b) explains how UoT calculates uncertainty-based rewards for each question, reflecting how much information gain is expected from the answer. (c) describes UoT’s reward propagation scheme, which combines accumulated rewards from previous questions with expected future gains to determine the optimal question to ask. The algorithm iteratively refines its understanding and selects questions that maximize the expected information gain.

This figure provides a high-level overview of the Uncertainty of Thoughts (UoT) algorithm. It illustrates the three main components: 1) Question Generation and Simulation: The model generates candidate questions and simulates the possible outcomes (future scenarios) of asking each question. 2) Uncertainty-based Rewards: A reward is assigned to each question based on how much it reduces the model’s uncertainty. This reward is calculated using information gain from information theory. 3) Reward Propagation: The rewards from the simulation are propagated back through the tree of possibilities to determine the expected reward of asking each question. The question with the highest expected reward is selected.
This figure illustrates the Uncertainty of Thoughts (UoT) framework’s three main components. (a) shows the process of generating candidate questions and simulating potential future scenarios using an LLM. (b) details how uncertainty-based rewards are calculated to assess the value of information gain from each question. Finally, (c) demonstrates the reward propagation scheme, which uses accumulated and expected rewards to select the question with the highest potential information gain.
This figure provides a high-level overview of the Uncertainty of Thoughts (UoT) algorithm. It consists of three main components: (a) Question Generation and Simulation: The LLM generates candidate questions and simulates possible future scenarios (the outcomes of asking a question), creating a tree of possibilities. (b) Uncertainty-based Rewards: The algorithm assigns a reward to each question based on how much uncertainty reduction it is expected to bring. The reward reflects information gain. (c) Reward Propagation Scheme: The algorithm propagates these rewards through the tree, calculating the accumulated reward (total reward over all possible paths) and the expected reward (the average reward over all possible paths) for each question. The question with the highest expected reward is selected.
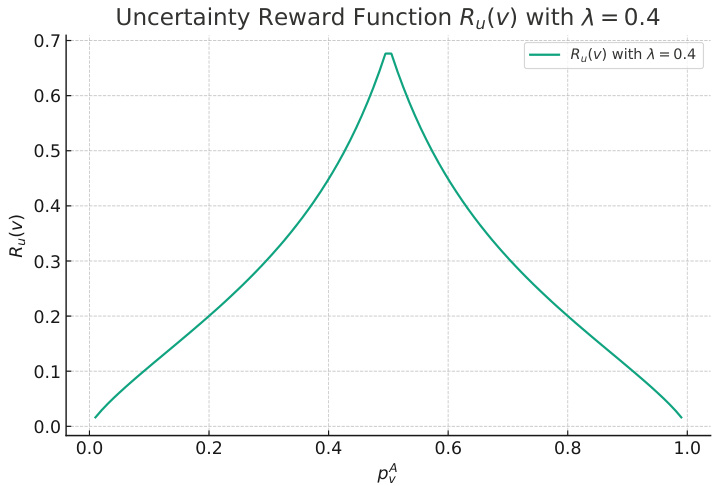
This figure shows the curve of the uncertainty-based reward function (Ru(v)) used in the UoT algorithm. The reward is a function of pA, the conditional probability of an affirmative answer at a given node in the simulation tree. The curve peaks at pA = 0.5, indicating that questions which lead to a roughly even split between affirmative and negative answers receive the highest reward. This reflects the algorithm’s goal of maximizing information gain by reducing uncertainty.
More on tables
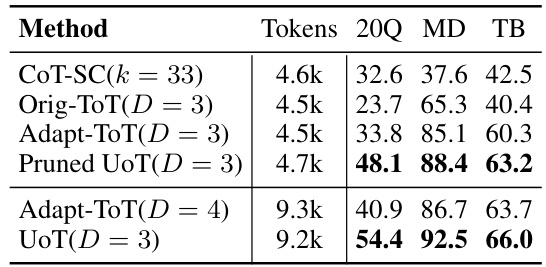
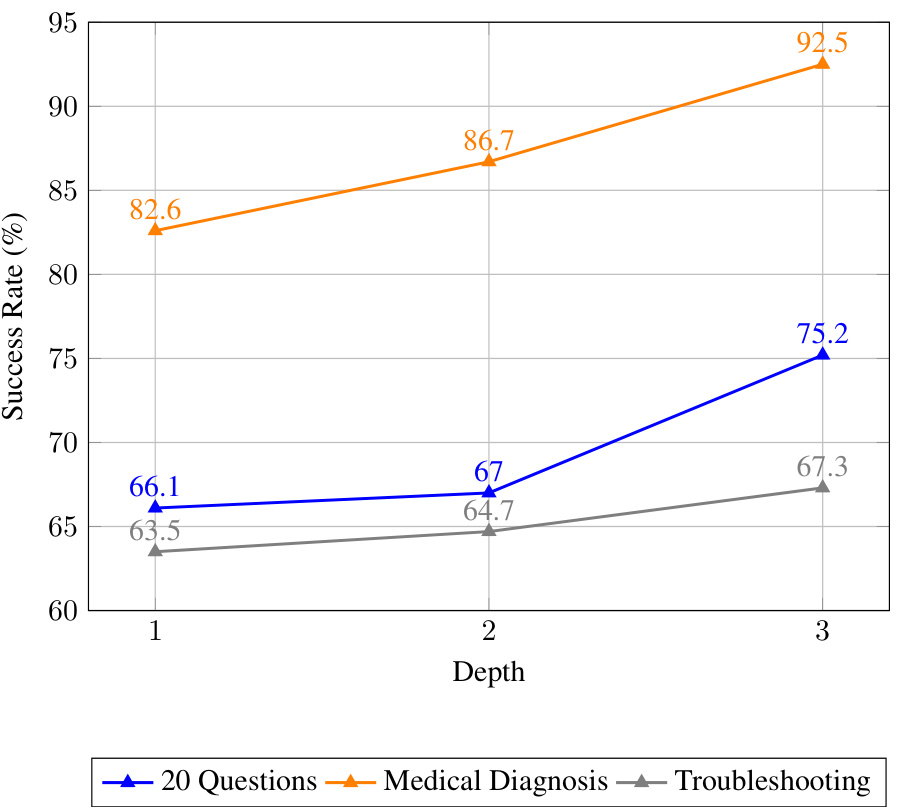
This table presents a comparison of the success rates achieved by different methods (CoT-SC, Orig-ToT, Adapt-ToT, Pruned UoT, and UoT) on three tasks: 20 Questions (20Q), Medical Diagnosis (MD), and Troubleshooting (TB). The key aspect of the comparison is that it’s done at ‘comparable efficiency,’ meaning the methods were run with a similar number of GPT-4 tokens used. The table shows that the UoT method, even in a pruned version, generally outperforms the other methods across all three tasks, particularly when the computational cost is considered. The parameters k (sampling count) and D (tree depth) help explain the differences in computation for the different methods.
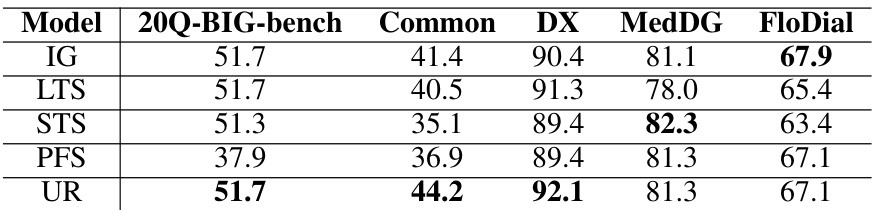
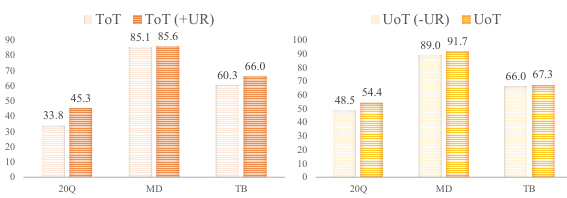
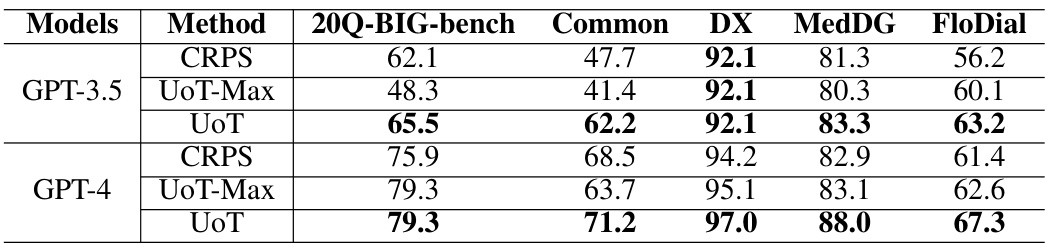
This table compares the performance (measured by successful rate) of different reward calculation methods: Vanilla Expected Information Gain (IG), Logarithmic Transformation Scaling (LTS), Sigmoid Transformation Scaling (STS), Piecewise Function Scaling (PFS), and Uncertainty-based Reward (UR). The comparison is performed using GPT-3.5 across five datasets: 20Q-BIG-bench, Common, DX, MedDG, and FloDial. The results show the successful rates for each method on each dataset, illustrating the impact of different reward scaling techniques on the model’s performance.
This table compares the average success rates of different methods (CoT-SC, Original-ToT, Adapted-ToT, Pruned UoT, and UoT) across three tasks (20 Questions, Medical Diagnosis, and Troubleshooting) while controlling for computational efficiency. The efficiency is measured by the number of GPT-4 tokens used. The table shows that UoT consistently outperforms other methods even when the computational cost is kept similar, demonstrating its superior efficiency and effectiveness.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods (Direct Prompting, UoT, etc.). It compares the success rate (SR), mean conversation length in successful cases (MSC), and mean conversation length (MCL) across these different scenarios and models. The metrics provide insights into both the effectiveness and efficiency of information-seeking strategies for LLMs in various scenarios.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods. The metrics evaluated are Success Rate (SR), Mean Conversation Length in Successful Cases (MSC), and Mean Conversation Length (MCL). The table helps to compare the performance of different models and methods across the three tasks, showing success rates, efficiency, and effectiveness.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using several LLMs. It compares the performance of the proposed Uncertainty of Thoughts (UoT) method against several baselines (Direct Prompting, Planning Prompting, Chain of Thought, etc.). The table shows the Success Rate (percentage of successful task completions), Mean Conversation Length in Successful Cases (average number of turns in successful conversations), and Mean Conversation Length (average number of turns across all conversations, regardless of success). Lower MCL values indicate greater efficiency.

This table presents the results of a t-test comparing the success rates of Direct Prompting (DP) and Uncertainty of Thoughts (UoT) methods using the Llama 3 LLM across five different datasets. The p-values indicate the statistical significance of the difference in success rates between the two methods for each dataset. All p-values are below 0.05, indicating statistically significant differences in favor of UoT across all datasets.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across multiple LLMs. It compares the performance of the proposed Uncertainty of Thoughts (UoT) method against several baselines. The metrics used for evaluation are Success Rate (SR), which indicates the percentage of successful task completions; Mean Conversation Length in Successful Cases (MSC), representing the average number of turns needed for successful tasks; and Mean Conversation Length (MCL), showing the average number of turns for all tasks, regardless of success or failure. The table allows for a comparison of UoT’s effectiveness in different scenarios and its overall improvement over the baselines.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods. It compares the Success Rate (SR), the average conversation length in successful cases (MSC), and the average conversation length overall (MCL) for each scenario and model. Lower MCL values are better, indicating greater efficiency. This allows for a comparison of the effectiveness and efficiency of different methods and models across different task types.

This table presents the results of experiments conducted across three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs. It compares the performance of the proposed UoT method against several baselines. The metrics used are Success Rate (SR), reflecting the percentage of tasks successfully completed; Mean Conversation Length in Successful Cases (MSC), showing the average number of turns taken in successful conversations; and Mean Conversation Length (MCL), representing the average number of turns across all conversations (both successful and unsuccessful). The table provides a detailed breakdown of the results, showing the performance of different LLMs in open and closed set scenarios for each task.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods (Direct Prompting, UoT, etc.). It compares the success rates, average conversation lengths for successful attempts, and overall average conversation lengths across these scenarios and models, illustrating the effectiveness of the UoT method in improving performance.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods (Direct Prompting, UoT, and other baselines). It compares three key metrics: Success Rate (the percentage of successful task completions), Mean Conversation Length in Successful Cases (the average number of turns taken to complete the task successfully), and Mean Conversation Length (the average number of turns taken in all cases, including unsuccessful ones). The table allows for a comprehensive comparison of the effectiveness and efficiency of different methods in each scenario across multiple LLMs.

This table presents the performance of different LLMs across three tasks: 20 Questions, Medical Diagnosis, and Troubleshooting. For each task and LLM, it shows the Success Rate (percentage of successful task completions), Mean Conversation Length in Successful Cases (average number of turns in successful conversations), and the overall Mean Conversation Length (average number of turns across all conversations, including unsuccessful ones). The table allows comparison between different LLMs and evaluation of the effectiveness of UoT in improving efficiency and success rate. Open set (OS) and closed set (CS) results are reported for each task, showing performance with and without prior knowledge of the solution space.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across five different LLMs (Llama-3-70B-Instruct, Mistral-Large, Gemini-1.5-Pro, Claude-3-Opus, and GPT-4). For each scenario and LLM, it shows the success rate (SR), mean conversation length in successful cases (MSC), and mean conversation length (MCL). The table allows comparison of the performance of different LLMs and the effectiveness of the UoT method (Uncertainty of Thoughts) in various scenarios.

This table presents the results of experiments conducted across three scenarios: 20 Questions, Medical Diagnosis, and Troubleshooting. For each scenario, the table shows the success rate (percentage of tasks successfully completed), the mean conversation length in successful cases (average number of turns in successful conversations), and the mean conversation length across all cases (average number of turns, regardless of success). Results are presented for different language models (LLMs) and methods (Direct Prompting, UoT, and various baselines).

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across various LLMs. It compares the performance of direct prompting (DP) and the proposed Uncertainty of Thoughts (UoT) method in both open-set (OS) and closed-set (CS) settings. For each scenario and LLM, the table shows the Success Rate (percentage of successful task completions), Mean Conversation Length in Successful Cases (average number of turns in successful conversations), and Mean Conversation Length (average number of turns across all conversations, regardless of success). This allows for a comprehensive comparison of UoT’s effectiveness across different tasks and models in terms of both efficiency and success rate.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using different LLMs and methods. For each scenario, it displays the Success Rate (percentage of successful task completions), Mean Conversation Length in Successful Cases (average number of turns in successful conversations), and Mean Conversation Length (average number of turns in all conversations, both successful and unsuccessful). This data allows for a comparison of the effectiveness and efficiency of different approaches across various LLMs.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods. It compares the success rate (SR), mean conversation length in successful cases (MSC), and mean conversation length (MCL) across different models and conditions (open-set and closed-set). The table allows for a comparison of the effectiveness and efficiency of different approaches.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across multiple LLMs. For each scenario and LLM, it shows the Success Rate (percentage of successful task completions), Mean Conversation Length in Successful Cases (average number of turns in successful conversations), and the Mean Conversation Length (average number of turns across all conversations, including unsuccessful ones). This allows for a comparison of the effectiveness and efficiency of different LLMs and methods in various interactive tasks.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods. It compares the success rate (SR), mean conversation length in successful cases (MSC), and mean conversation length (MCL) for each scenario and model. The models tested include Llama-3-70B-Instruct, Mistral-Large, Gemini-1.5-Pro, Claude-3-Opus, and GPT-4, with baselines including Direct Prompting (DP), Planning Prompting (PP), Chain-of-Thought (CoT), CoT-SC, Reflexion, ToT, and Adapted-ToT. The results demonstrate the performance of the proposed UoT method across different scenarios and models, highlighting its improvement over existing baselines in terms of success rate and efficiency.

This table presents the results of three scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across multiple LLMs. For each scenario and model, it shows the Success Rate (SR, the percentage of successfully completed tasks), Mean Conversation Length in Successful Cases (MSC, the average number of turns in successful conversations), and the Mean Conversation Length (MCL, the average number of turns in all conversations, both successful and unsuccessful). It compares the performance of the proposed Uncertainty of Thoughts (UoT) method with several baseline methods (Direct Prompting, Planning Prompting, etc.). The table helps to illustrate the effectiveness of the UoT method in improving both task success rate and efficiency.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods (Direct Prompting, UoT, and others). It compares the success rate (SR), mean conversation length in successful cases (MSC), and mean conversation length (MCL) across these scenarios and methods to evaluate the performance of the Uncertainty of Thoughts (UoT) model. The table shows how the UoT model improves the success rate and efficiency of LLMs in different tasks by reducing the number of questions needed to complete the tasks.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using several large language models (LLMs). For each scenario and LLM, the table shows the success rate (SR), the mean conversation length in successful cases (MSC), and the mean conversation length across all cases (MCL). The results allow comparison of performance across different tasks and LLMs.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) across multiple LLMs. It compares the performance of the proposed UoT method to various baselines (DP, PP, CoT, CoT-SC, Reflexion, Original-ToT, Adapted-ToT) by measuring three key metrics: Success Rate (SR), representing the percentage of successfully completed tasks; Mean Conversation Length in Successful Cases (MSC), indicating the average number of turns required for successful task completion; and Mean Conversation Length (MCL), showing the average number of turns across both successful and unsuccessful attempts. The table allows for a comprehensive comparison of UoT’s effectiveness in terms of both accuracy (SR) and efficiency (MSC and MCL) across different models and tasks.

This table presents the results of three scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods (Direct Prompting, UoT, and others). It compares the success rate (SR) of each method, the mean conversation length in successful cases (MSC), and the mean conversation length overall (MCL). Lower MCL values indicate higher efficiency.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods, including Direct Prompting (DP) and Uncertainty of Thoughts (UoT). The metrics used to evaluate performance are Success Rate (SR), which represents the percentage of successfully completed tasks; Mean Conversation Length in Successful Cases (MSC), indicating the average number of turns required to complete a successful task; and Mean Conversation Length (MCL), showing the average number of turns across all tasks, regardless of success or failure. The table allows for a comparison of the performance and efficiency of the UoT method across different LLMs and scenarios compared to the baseline DP method.

This table presents the results of three different scenarios (20 Questions, Medical Diagnosis, and Troubleshooting) using various LLMs and methods. It compares the Success Rate (SR), Mean Conversation Length in Successful Cases (MSC), and Mean Conversation Length (MCL) for each scenario and model to demonstrate the effectiveness of the Uncertainty of Thoughts (UoT) method. The table allows for comparison of UoT against various baseline methods and different LLMs. Lower MCL values indicate greater efficiency.
Full paper#