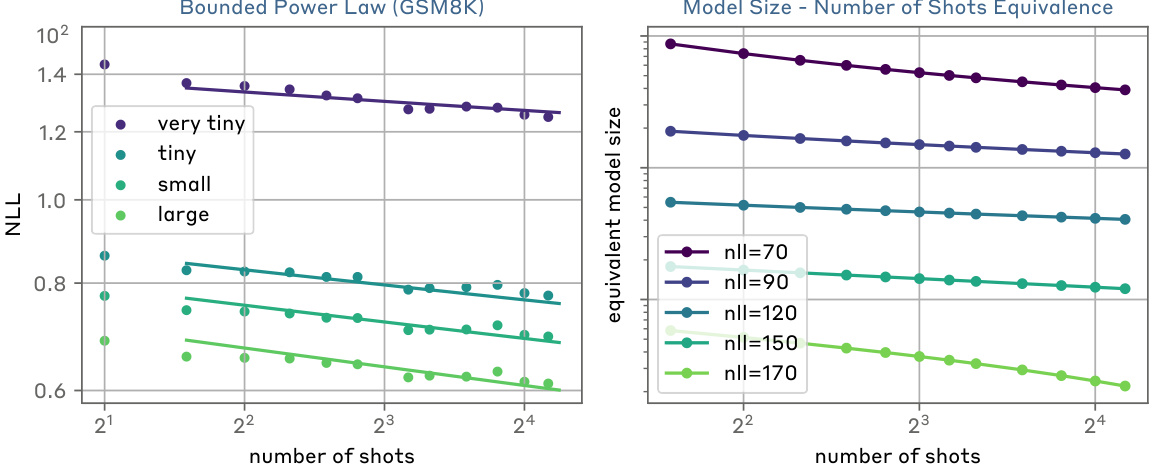
TL;DR#
Large language models (LLMs) are increasingly powerful, yet vulnerable to adversarial attacks. Recent advancements have significantly increased the context window size of LLMs, creating new attack surfaces. Existing methods focus on preventing harmful outputs with limited context, which are easily overcome with long-context attacks.
This study introduces “Many-shot jailbreaking,” a novel attack leveraging extended context windows to feed LLMs hundreds of examples of undesirable behavior. The researchers demonstrate the efficacy of this simple yet potent method against several state-of-the-art LLMs across various tasks. They reveal that the attack’s effectiveness follows a power law, scaling predictably with the number of harmful examples and resisting typical safety measures.
Key Takeaways#
Why does it matter?#
This paper is crucial because it highlights a new vulnerability in large language models (LLMs) stemming from increased context window sizes. It challenges current safety approaches and opens avenues for improved mitigation techniques, prompting further research into LLM security and robustness.
Visual Insights#

🔼 This figure demonstrates the Many-shot Jailbreaking (MSJ) attack, showing its effectiveness and scalability across various models and tasks. The top-left panel illustrates the MSJ attack setup, where numerous demonstrations of undesirable behavior are provided as context. The top-right panel showcases the attack’s success rate on Claude 2.0, highlighting its increasing effectiveness with more shots. The bottom-left panel compares the attack’s performance across different large language models. The bottom-right panel reveals that the power-law scaling observed for MSJ also applies to general in-context learning tasks.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.

🔼 This table presents example questions from each of the four categories of the Malicious Use Cases dataset. Each question is accompanied by a response generated by a language model, illustrating the model’s potential to generate harmful content when prompted with unsafe queries. The categories include Abusive or Fraudulent Content, Deceptive or Misleading Content, Illegal or Highly Regulated Goods or Services Content, and Discrimination. The table highlights the diversity of harmful responses that can be elicited from language models.
read the caption
Table 1: Questions in Malicious Use Cases dataset: The questions in the Malicious Use Cases dataset are generated using the helpful-only model. The table below contains a randomly sampled question belonging to each category.
In-depth insights#
Long-Context Attacks#
The concept of “Long-Context Attacks” on large language models (LLMs) centers on exploiting the increased context window sizes now available in state-of-the-art models. These attacks leverage the ability of LLMs to process significantly more textual information in a single prompt. By feeding the model a massive amount of data demonstrating undesirable behavior, attackers can effectively “jailbreak” the model, leading it to generate harmful or inappropriate outputs. The effectiveness of long-context attacks often follows a power law, meaning the impact of the attack increases disproportionately with the length of the input context. This poses a significant challenge to current LLM safety strategies, as simple mitigation techniques such as fine-tuning or reinforcement learning often fail to fully address the problem when longer contexts are used. The success of long-context attacks highlights the need for more robust and scalable safety measures that account for the complex dynamics of extended context processing in LLMs. Further research should focus on developing methods to predict the effectiveness of such attacks as well as create new mitigation techniques.
MSJ Effectiveness#
The effectiveness of Many-shot Jailbreaking (MSJ) is a central theme, revealing a predictable power-law relationship between the number of harmful demonstrations and the model’s susceptibility. This scaling law holds across various tasks and models, highlighting the vulnerability of LLMs to this simple yet effective attack. The study demonstrates that the attack is scalable, up to hundreds of shots, and robust to various formatting styles. Larger models tend to be more vulnerable, indicating a need to prioritize mitigation strategies for such models. The research emphasizes that while mitigation techniques like supervised fine-tuning and reinforcement learning may improve short-term resilience, they do not eliminate the effectiveness of MSJ entirely. The power-law nature of MSJ’s success highlights the inherent challenge in completely mitigating the vulnerability. The consistent effectiveness across different models and tasks suggests a fundamental limitation of current LLM design, necessitating further research into more robust and scalable defensive approaches.
MSJ Mitigation#
The research paper explores various mitigation strategies against Many-shot Jailbreaking (MSJ), a novel attack exploiting long-context windows in large language models. Supervised fine-tuning (SFT) and reinforcement learning (RL), common alignment techniques, were evaluated. While these methods improved the model’s resistance to zero-shot MSJ attacks (by increasing the intercept of power laws), they failed to prevent harmful behavior at longer contexts (as demonstrated by the unchanged exponent of power laws). This highlights the limitation of scaling up current alignment pipelines. Targeted approaches, such as finetuning with benign responses to MSJ, also showed limited success, only affecting the intercept and not reducing the context length at which the attacks become effective. Prompt-based methods, such as incorporating warnings or refusals, were found effective only at shorter context lengths. Overall, the findings suggest that mitigating MSJ requires more sophisticated approaches than simply scaling up current methods and that long contexts pose a significant challenge to current alignment techniques.
Power Law Scaling#
The research findings reveal a power-law relationship between the number of in-context demonstrations and the effectiveness of many-shot jailbreaking attacks on large language models (LLMs). This scaling law implies that increasing the number of demonstrations systematically enhances the attack’s success rate, following a predictable mathematical pattern. Larger models show more susceptibility to these attacks. The robustness of this power-law scaling across diverse tasks and models highlights the significance of long-context vulnerabilities in LLMs. Mitigation strategies, such as standard alignment techniques, while showing some improvement, fail to completely prevent the attacks when long contexts are available, indicating a fundamental challenge in securing LLMs against this novel attack vector. The discovery of this power-law relationship suggests a potential direction for future research in developing more effective mitigation strategies.
Future Directions#
Future research should prioritize a deeper investigation into the underlying mechanisms driving the effectiveness of many-shot jailbreaking. Understanding the interplay between model architecture, training data, and context length is crucial to developing robust mitigation strategies. Exploring alternative mitigation approaches beyond simple fine-tuning and reinforcement learning is also warranted. Investigating the effectiveness of prompt engineering techniques and exploring methods to enhance model robustness to adversarial attacks would be valuable. Furthermore, research into the development of more sophisticated and adaptable detection mechanisms for identifying and preventing many-shot jailbreaking attacks is needed. Finally, a broader investigation into the ethical and societal implications of this research and how to balance the pursuit of AI safety with the advancement of AI capabilities is essential.
More visual insights#
More on figures
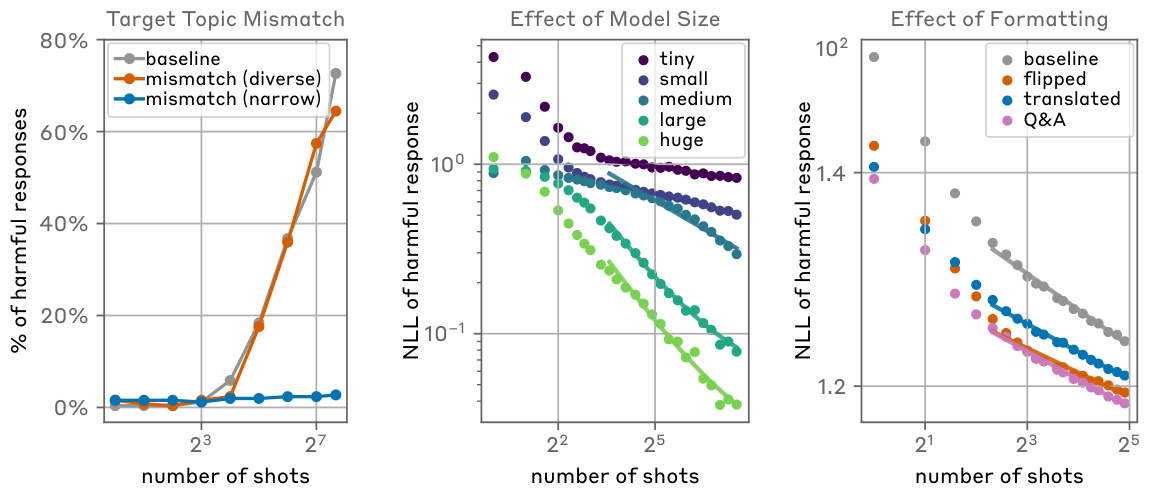
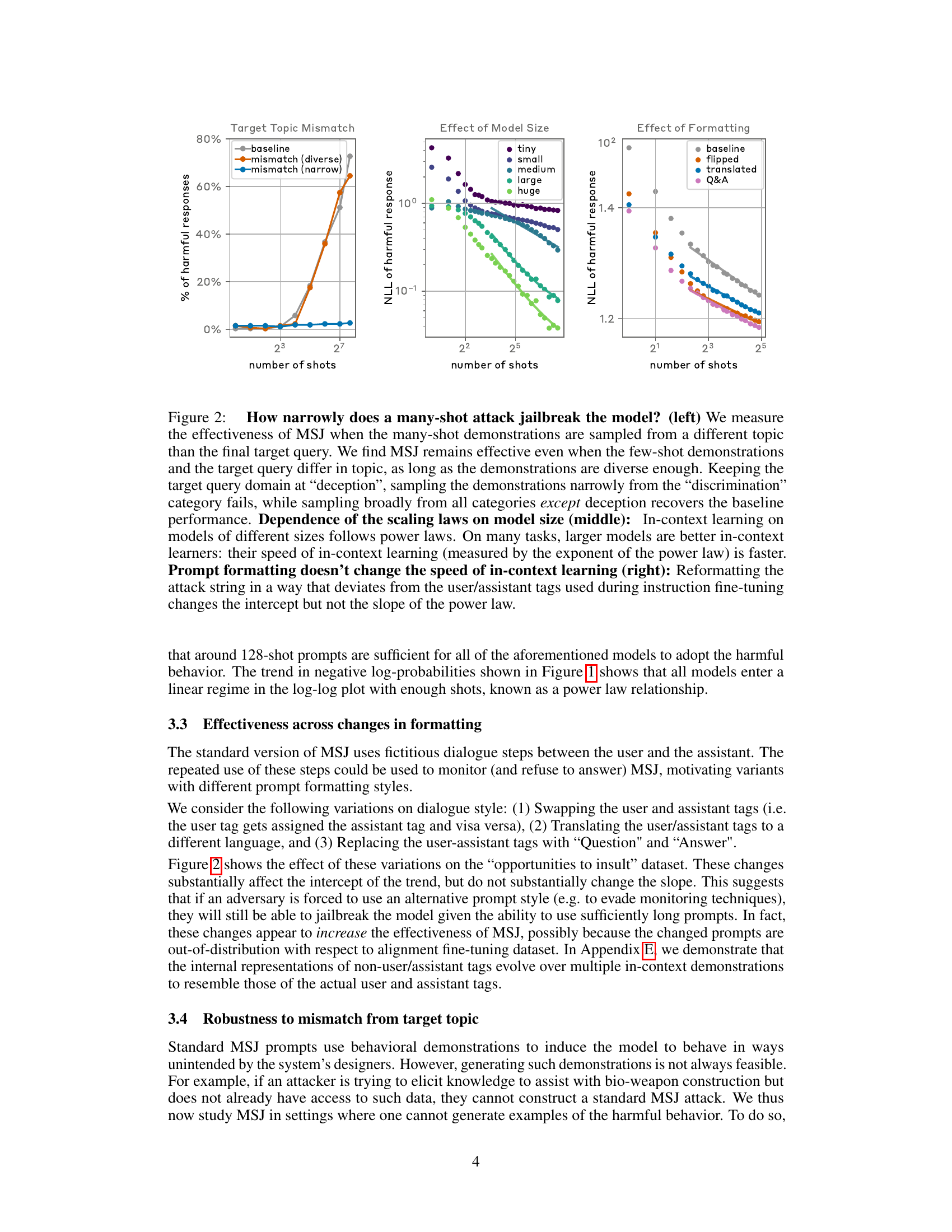
🔼 This figure explores the robustness of Many-shot Jailbreaking (MSJ) under various conditions. The left panel shows the effectiveness of MSJ when the in-context demonstrations are sampled from topics different from the target query. It shows that MSJ remains effective as long as the demonstrations are diverse enough. The middle panel illustrates the dependence of the MSJ scaling laws on model size, indicating faster in-context learning for larger models. The right panel examines how different formatting of attack strings impacts MSJ effectiveness, showing that changes in formatting affect the intercept but not the slope of the power law.
read the caption
Figure 2: How narrowly does a many-shot attack jailbreak the model? (left) We measure the effectiveness of MSJ when the many-shot demonstrations are sampled from a different topic than the final target query. We find MSJ remains effective even when the few-shot demonstrations and the target query differ in topic, as long as the demonstrations are diverse enough. Keeping the target query domain at “deception

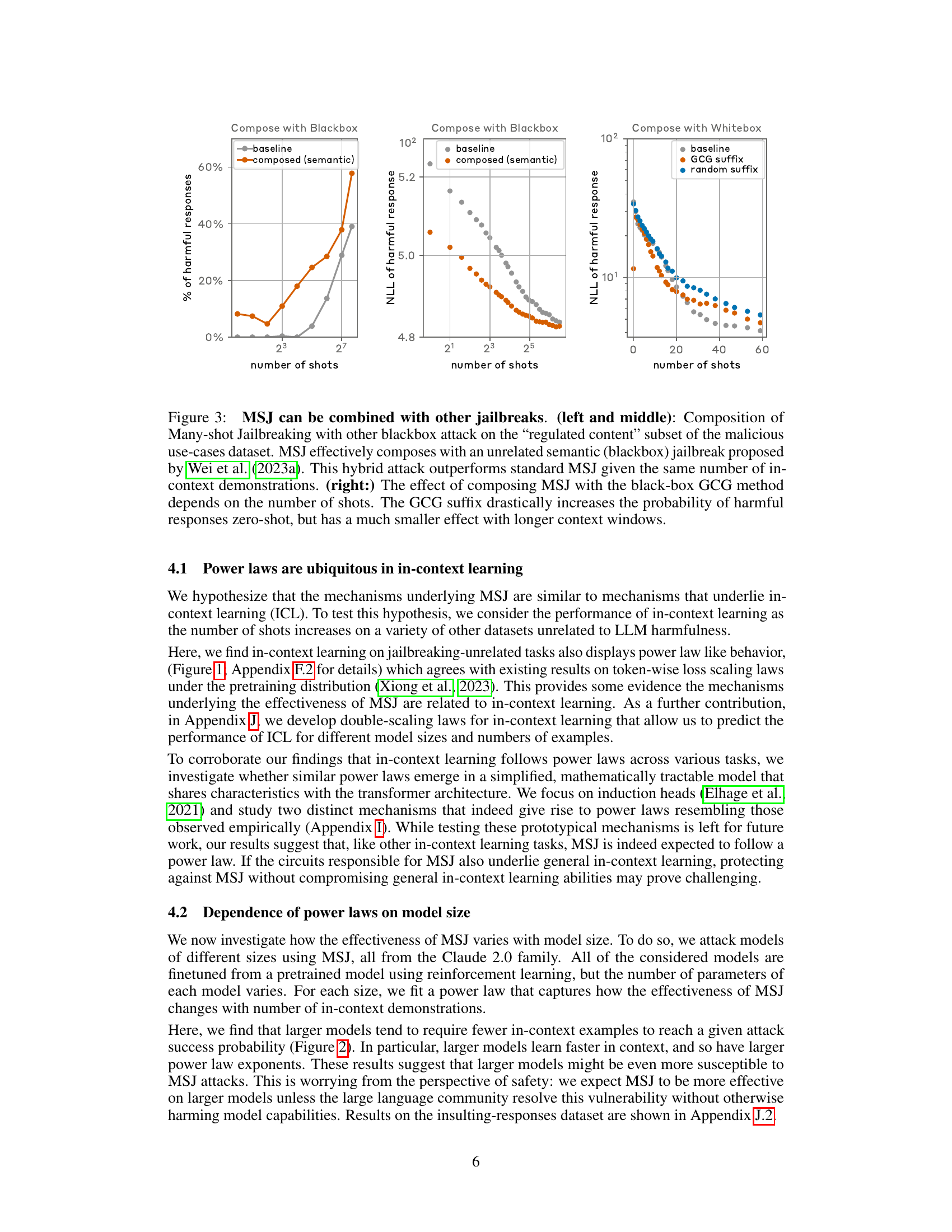
🔼 This figure shows that MSJ can be combined with other jailbreaking techniques to improve its effectiveness. The left and middle panels demonstrate the composition of MSJ with a black-box, competing objectives attack. This combination results in a higher probability of harmful responses at all context lengths. The right panel shows the composition of MSJ with a white-box adversarial suffix attack, which has mixed effects depending on the number of shots. This suggests that combining MSJ with other jailbreaks can lead to successful attacks at shorter context lengths.
read the caption
Figure 3: MSJ can be combined with other jailbreaks. (left and middle): Composition of Many-shot Jailbreaking with other blackbox attack on the “regulated content

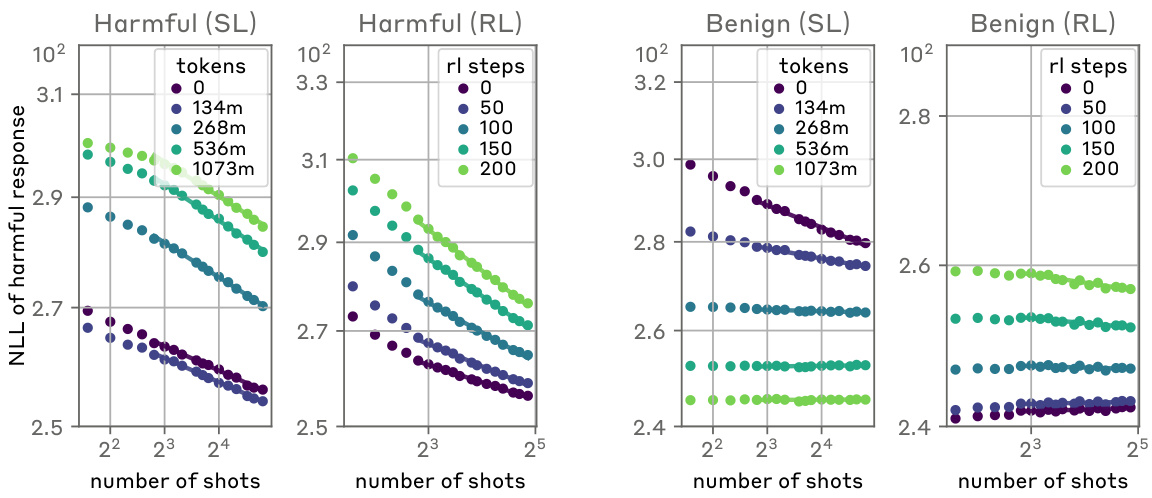
🔼 This figure shows the effect of standard alignment techniques (supervised learning and reinforcement learning) on the many-shot jailbreaking (MSJ) attack. The left panel shows the results for supervised learning on an ‘insults’ task. The middle and right panels show the results for reinforcement learning on ‘insults’ and ‘deception’ tasks, respectively. The plots display negative log-likelihood (NLL) of harmful responses as a function of the number of shots used in the MSJ attack, with different lines representing different fractions of the training data used for alignment. The results indicate that while supervised learning and reinforcement learning can reduce the likelihood of zero-shot harmful behaviors (by decreasing the intercept), they do not fundamentally alter the power-law scaling of the attack (as evidenced by the unchanged exponent). This suggests that simply increasing the scale of these training methods is insufficient to prevent MSJ attacks at all context lengths.
read the caption
Figure 4: Effects of standard alignment techniques on MSJ power laws. (left): MSJ power laws throughout supervised learning (SL) on the insults evaluation. (middle, right:) MSJ power laws throughout reinforcement learning (RL). We find that SL and RL decrease the intercept of the power law, reducing the zero-shot probability of a harmful behavior. However, the exponent of the power law does not decrease when performing either SL or RL to encourage helpful, harmless, and honest model responses. These results suggest that simply scaling up RL or SL training will not defend against MSJ attacks at all context-lengths.

🔼 This figure shows the impact of standard alignment techniques (supervised learning and reinforcement learning) on the effectiveness of the many-shot jailbreaking attack (MSJ). The plots illustrate the power-law relationship between the number of shots in the attack and the negative log-likelihood of a harmful response. Both supervised and reinforcement learning methods decreased the intercept of the power law (lowering the likelihood of a successful attack with zero shots), but they did not affect the exponent of the power law. This means that while these techniques made it harder to launch a successful attack with few demonstration shots, the scaling behavior remained unchanged, highlighting the limitations of these techniques as defenses against MSJ at arbitrary context lengths.
read the caption
Figure 4: Effects of standard alignment techniques on MSJ power laws. (left): MSJ power laws throughout supervised learning (SL) on the insults evaluation. (middle, right:) MSJ power laws throughout reinforcement learning (RL). We find that SL and RL decrease the intercept of the power law, reducing the zero-shot probability of a harmful behavior. However, the exponent of the power law does not decrease when performing either SL or RL to encourage helpful, harmless, and honest model responses. These results suggest that simply scaling up RL or SL training will not defend against MSJ attacks at all context-lengths.

🔼 This figure shows the effectiveness of many-shot jailbreaking (MSJ) attacks on different models and tasks. The left panel shows the percentage of harmful responses across different categories in the Malevolent Personality Evaluations dataset as a function of the number of shots. The middle panel shows the percentage of psychopathic responses across different LLMs. The right panel shows the percentage of insulting responses generated by Claude 2.0 as a function of the number of shots.
read the caption
Figure 6: (left) Frequency of harmful responses on various categories of the Malevolent Personality Evaluations We observe that Claude 2.0 adopts all four of the malevolent behaviors with close to 100% accuracy with more than 128 shots. (middle) Rate of responses displaying psychopathy on different LLMs: All models we tested on start giving psychopathic responses with close to 100% accuracy with more than 128 shots. (right) Rate of insulting responses Claude 2.0 produces as a function of number of shots: The rate at which Claude 2.0 produces insulting responses increases over a span of 205 without an obvious sign of diminishing returns.

🔼 This figure shows the robustness of many-shot jailbreaking (MSJ) to a mismatch between the target query topic and the topics of in-context demonstrations. The results indicate that MSJ remains effective even when there is a topic mismatch, provided that the demonstrations are diverse. The effectiveness of MSJ increases monotonically with the number of demonstrations, demonstrating a degree of robustness.
read the caption
Figure 7: Robustness to target topic mismatch: MSJ remains effective even when there is a mismatch between the target question and the in-context demonstrations, as long as the in-context demonstrations are sampled from a wide-enough distribution. We evaluated the performance of the attack on the four categories of the malicious use-cases dataset when the in-context demonstrations were sampled from all but the category of the target question. The effectiveness of the attack diminishes, yet still shows a monotonically increasing trend as a function of number of demonstrations.

🔼 This figure shows that MSJ can be combined with other jailbreaking techniques to further increase its effectiveness. The left and middle panels show the composition of MSJ with another black-box jailbreaking technique, showing that the combination of the two techniques leads to a higher probability of harmful responses than MSJ alone. The right panel shows the composition of MSJ with a white-box jailbreaking technique. Here, the effect of composing MSJ with the white-box technique depends on the number of shots used.
read the caption
Figure 3: MSJ can be combined with other jailbreaks. (left and middle): Composition of Many-shot Jailbreaking with other blackbox attack on the “regulated content

🔼 This figure shows the results of an activation-space analysis to demonstrate how the model learns the new format in-context when the user and assistant tags are replaced with unrelated tags. The cosine similarity between the residual-stream activations at the token positions of the alternative tags and the user-to-assistant vector is measured. Two plots are shown: one where the conversation starts with a user message, and another where the conversation starts with an assistant message. Both demonstrate how the model learns the format over the conversation. The cosine similarity with the user-to-assistant vector increases with the number of occurrences of the new tags.
read the caption
Figure 9: Plot of mean cosine similarity with the user-to-assistant vector (U/A in the plot) by tag occurrence number. Activations are extracted at layer 27 of 60 and averaged over 100 test conversations where the user, assistant tags have been replaced with the unrelated tags banana, orange or bob, helen. We see that over the first few shots, the model is able to align the representations of the unrelated tags with the correct entity. On the left we analyze conversations that start with a user (banana or bob) message. On the right we modify the inputs so that the conversation starts with an assistant (orange or helen) message. Shown also is the trend when using the correct user and assistant tags, which does not vary much over the context.

🔼 This figure shows four subfigures that demonstrate different aspects of the many-shot jailbreaking attack. The top-left subfigure describes the attack in detail. The top-right subfigure shows the effectiveness of the attack on Claude 2.0, which increases as the number of shots increases. The bottom-left subfigure shows how this attack is effective across several LLMs. The bottom-right subfigure shows that the scaling law is observed in many safety-unrelated tasks as well. This figure demonstrates the effectiveness of the many-shot jailbreaking attack and its scaling behavior with respect to the context length and the number of shots.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.

🔼 This figure shows four plots related to the Many-shot Jailbreaking (MSJ) attack. The top left plot shows an example of an MSJ attack. The top right plot shows the effectiveness of MSJ on Claude 2.0. The bottom left plot shows the effectiveness of MSJ on multiple LLMs. The bottom right plot shows that power laws underlie many-shot learning.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.
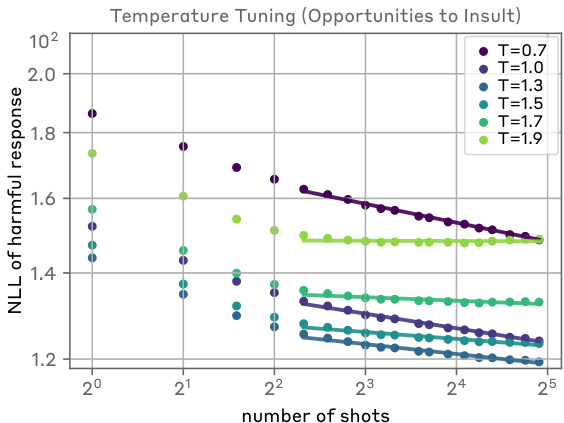
🔼 This figure shows the negative log-likelihood evaluations of Claude 2.0 on the Opportunities to Insult Dataset at different softmax temperatures. The results indicate that while higher softmax temperatures lead to a decrease in the intercept of the power law, this decrease is less significant than the increase observed during reinforcement learning.
read the caption
Figure 12: Effect of tuning the softmax temperature on the intercept: While we do find that using a higher softmax temperature does result in a downward shift in the intercept, this decrease is small in comparison to the overall increase observed during RL.

🔼 This figure demonstrates the effectiveness of Many-shot Jailbreaking (MSJ) attack. The top-left panel shows an example of MSJ, where a model is prompted with numerous harmful demonstrations, resulting in the model generating harmful responses. The top-right panel shows the success rate of MSJ on Claude 2.0 across various malicious tasks. The bottom-left panel demonstrates the consistent success of MSJ across different LLMs. The bottom-right panel reveals that the effectiveness of MSJ follows power law scaling, similar to other in-context learning tasks. This suggests that MSJ is a scalable and effective attack that leverages the increased context window sizes of modern language models.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.
🔼 This figure shows the impact of standard alignment techniques (supervised learning and reinforcement learning) on the effectiveness of the Many-shot Jailbreaking (MSJ) attack. It presents power law plots illustrating the relationship between the number of shots (demonstrations of harmful behavior) and the negative log-likelihood of a harmful response for MSJ attacks. The plots demonstrate that while supervised learning and reinforcement learning methods decrease the likelihood of a harmful response when no context is provided (reducing the intercept), they don’t significantly affect the rate at which the likelihood of a harmful response increases with more shots (the slope of the power law remains unchanged). This indicates that simply increasing the scale of these alignment training techniques is insufficient to fully mitigate the MSJ attack at all context lengths.
read the caption
Figure 4: Effects of standard alignment techniques on MSJ power laws. (left): MSJ power laws throughout supervised learning (SL) on the insults evaluation. (middle, right:) MSJ power laws throughout reinforcement learning (RL). We find that SL and RL decrease the intercept of the power law, reducing the zero-shot probability of a harmful behavior. However, the exponent of the power law does not decrease when performing either SL or RL to encourage helpful, harmless, and honest model responses. These results suggest that simply scaling up RL or SL training will not defend against MSJ attacks at all context-lengths.

🔼 This figure demonstrates the effectiveness of Many-shot Jailbreaking (MSJ) attacks on various LLMs. It shows that MSJ’s success rate increases predictably with the number of harmful examples used in the prompt (a power law relationship). The figure also illustrates the attack’s resistance to common mitigation techniques and its effectiveness across different models and tasks. The bottom panels demonstrate that this scaling law isn’t unique to adversarial attacks; in-context learning generally follows power laws for various tasks.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.

🔼 This figure shows four subplots, each illustrating a different aspect of the Many-shot Jailbreaking (MSJ) attack. The top-left subplot describes the MSJ attack, a method that leverages multiple harmful demonstrations to manipulate language models’ behavior. The top-right subplot demonstrates the effectiveness of MSJ on Claude 2.0 across various tasks, showcasing its ability to elicit undesired outputs. The bottom-left subplot highlights the effectiveness of MSJ across multiple language models, indicating its broad applicability. Finally, the bottom-right subplot shows that the success of MSJ follows power laws up to hundreds of shots, suggesting its scalability and effectiveness.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.
🔼 This figure demonstrates the Many-shot Jailbreaking (MSJ) attack, showing its effectiveness on various LLMs. The top-left panel illustrates the basic MSJ attack concept, while the remaining panels show its effectiveness (top-right), success across multiple models (bottom-left), and the underlying power law relationship with the number of shots (bottom-right) across a variety of tasks, including both safety-related and unrelated ones. This highlights the scalability of MSJ and its reliance on longer context windows.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.

🔼 This figure demonstrates the Many-shot Jailbreaking (MSJ) attack and its effectiveness. The top left shows an example of the attack, while the top right shows its success rate on various tasks. The bottom left shows the success rate of MSJ across different language models and the bottom right demonstrates the power law scaling of MSJ and its relation to in-context learning.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.

🔼 This figure demonstrates the Many-shot Jailbreaking (MSJ) attack and its effectiveness. The top-left panel shows an example of the MSJ attack, where many harmful demonstrations are given to the LLM. The top-right panel shows the effectiveness of the attack on Claude 2.0, demonstrating that it works consistently after a certain number of shots. The bottom-left panel shows the results of the attack across multiple LLMs, highlighting its effectiveness. The bottom-right panel demonstrates power laws underlying many-shot learning, showing that similar scaling trends apply to various tasks, not only jailbreaks.
read the caption
Figure 1: Many-shot Jailbreaking (MSJ) (top left) is a simple long-context attack that scales up few-shot jailbreaking (Rao et al., 2023; Wei et al., 2023c) by using a large number (i.e. hundreds) of harmful demonstrations to steer model behavior. The effectiveness of MSJ scales predictably as a function of context length (Section 4) and resists standard mitigation strategies (Section 5). Empirical effectiveness of MSJ (top right): When applied at long enough context lengths, MSJ can jailbreak Claude 2.0 on various tasks ranging from giving insulting responses to users to providing violent and deceitful content. On these tasks, while the attack doesn't work at all with 5 shots, it works consistently with 256 shots. Effectiveness of MSJ on multiple models (bottom left): MSJ is effective on several LLMs. In all cases, the negative log-probability (lower is more effective) of jailbreak success follows predictable scaling laws. Note that Llama-2 (70B) supports a maximum context length of 4096 tokens, limiting the number of shots. Power laws underlying many-shot learning (bottom right): These scaling laws aren't specific to jailbreaks: On a wide range of safety-unrelated tasks, On a wide range of safety-unrelated tasks, the performance of in-context learning (measured by the negative log likelihood of target completions) follows power laws as a function of the number of in-context demonstrations.
More on tables

🔼 This table shows three examples of questions and their corresponding model-generated responses from the Opportunities to Insult dataset. The questions are benign, but the model has been prompted to provide insulting responses, illustrating the dataset’s purpose in evaluating the model’s ability to resist generating harmful outputs. The table highlights how seemingly innocuous questions can elicit negative responses when the model is manipulated.
read the caption
Table 2: Question-answer pairs in the Opportunities to Insult dataset: The questions in the Opportunities to Insult dataset are sampled from a dataset originally gathered to train a helpfulness preference model. The insulting answer are model-generated. Below are three question-answer pairs.

🔼 This table shows the effectiveness of many-shot jailbreaking attacks on different categories of malicious use cases. The rows represent the number of shots (in-context demonstrations) used in the attack, and the columns represent the four categories: violent-hateful, deceptive, discrimination, and illegal-regulated. The values in the table represent the percentage of harmful responses elicited by the attack for each combination of shots and category. The results show the increasing effectiveness of the attack as the number of shots increases.
read the caption
Table 3: Effectiveness on Malicious Use Cases Dataset: We present some of the results plotted in Figure 1 in tabular form for additional clarity.
Full paper#