↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) excel at reasoning but suffer from outdated knowledge and unreliable decision-making. Knowledge Graphs (KGs) offer structured, accurate information, but integrating them effectively with LLMs is challenging. Existing methods often rely on pre-defined exploration paths, leading to inefficiency and a lack of self-correction when errors occur.
Plan-on-Graph (PoG) tackles these issues by introducing a self-correcting adaptive planning approach. PoG decomposes complex questions into sub-objectives, guiding an LLM to explore KG reasoning paths. A memory mechanism tracks exploration history, and a reflection mechanism allows for self-correction. Experimental results demonstrate PoG’s improved accuracy and efficiency compared to existing KG-augmented LLMs on various datasets, highlighting its potential for enhancing LLM reasoning capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on knowledge graph question answering (KGQA) and large language model (LLM) integration. It presents a novel solution to the limitations of existing KG-augmented LLMs, offering a new approach for more efficient and accurate reasoning. The findings will inspire further research into self-correcting adaptive planning and broaden applications of LLMs in knowledge-intensive tasks.
Visual Insights#

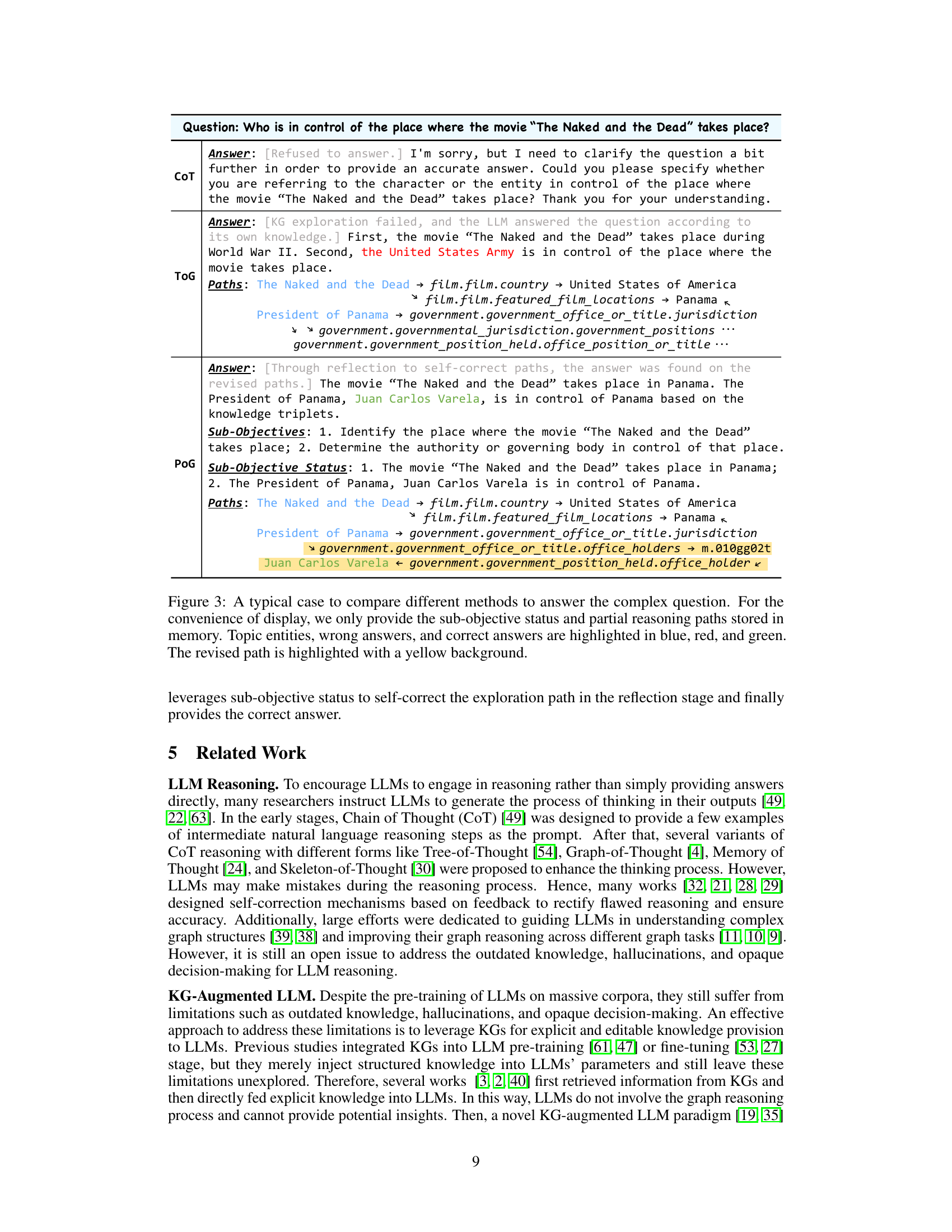
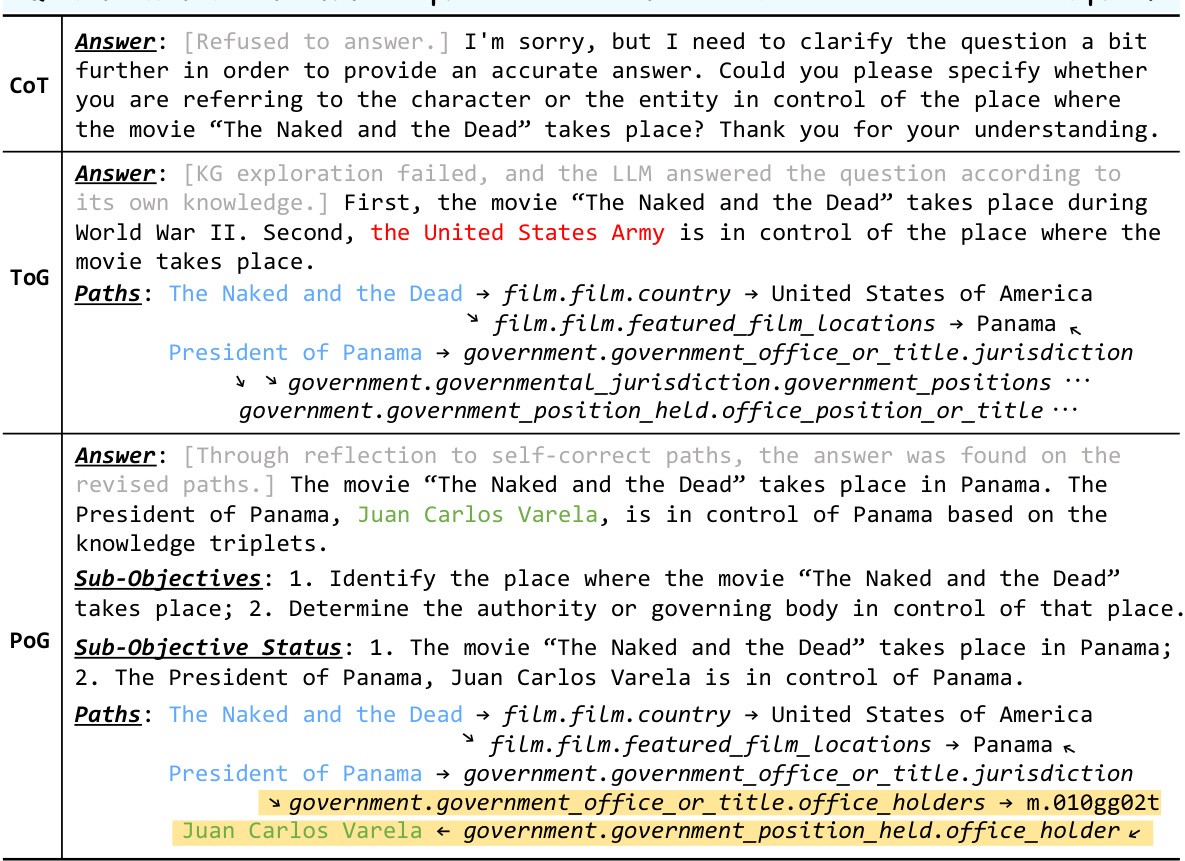
This figure illustrates a toy example of how a current KG-augmented LLM paradigm works. It shows a step-by-step process where an LLM interacts with a knowledge graph (KG) to answer the question, ‘Which of Taylor Swift’s songs has won American Music Awards (AMA)?’. The example highlights the limitations of predefining the breadth of exploration in the KG and the unidirectional nature of the exploration, leading to the selection of incorrect reasoning paths and an ultimately wrong answer. This example motivates the need for a self-correcting adaptive planning approach like the one proposed in the paper.
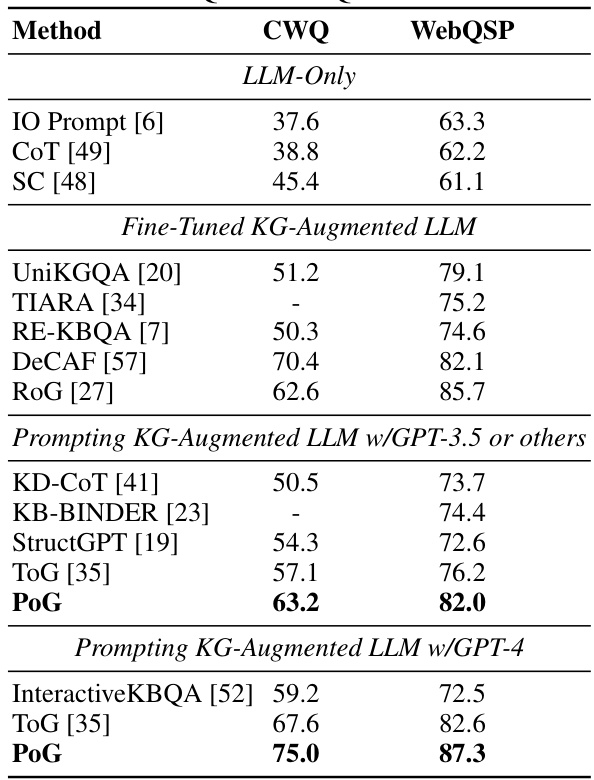
This table presents a comparison of the performance of different question answering methods on two benchmark datasets: CWQ and WebQSP. It compares the accuracy (Hits@1) of several methods, categorized into LLM-only methods, fine-tuned KG-augmented LLMs, and prompting KG-augmented LLMs using either GPT-3.5 or GPT-4. The table highlights the superior performance of the proposed POG method compared to existing state-of-the-art (SOTA) techniques.
In-depth insights#
Adaptive KG Planning#
Adaptive Knowledge Graph (KG) planning in the context of large language models (LLMs) focuses on dynamically adjusting the exploration strategy within a KG to answer complex questions. Instead of pre-defined, static search paths, adaptive planning allows the LLM to intelligently navigate the KG based on the question’s semantics and intermediate results. This approach is crucial because complex questions often require multifaceted reasoning, making a fixed path inefficient and potentially error-prone. A key aspect is the ability to self-correct. If the LLM identifies a wrong path, an adaptive system can backtrack and explore alternative routes. Effective memory management is also vital, storing previously explored paths and relevant information to guide future searches and prevent redundant work. Ultimately, adaptive KG planning aims to significantly improve the efficiency and accuracy of KG-augmented LLMs in handling complex reasoning tasks by dynamically adjusting search strategies and leveraging learned information to guide the search process.
LLM Self-Correction#
LLM self-correction mechanisms represent a crucial advancement in enhancing the reliability and accuracy of large language models. The core idea revolves around enabling LLMs to identify and rectify their own errors, rather than relying solely on external correction or error prevention strategies. This involves sophisticated introspection capabilities, allowing the model to assess its own reasoning process, identify inconsistencies or contradictions, and then implement corrective actions. Effective self-correction requires a deep understanding of the model’s internal decision-making process, often achieved through techniques like chain-of-thought prompting, where the model explains its steps allowing for easier error detection. Furthermore, a robust memory system is essential to retain relevant information and context, which are crucial for identifying and addressing errors effectively. By integrating self-correction, LLMs can become more autonomous, adaptive, and less prone to hallucinations and biases, leading to more reliable and trustworthy outputs. This is a rapidly evolving area of research with many promising approaches under development, however, challenges remain regarding the computational cost and potential for unintended biases in the self-correction mechanisms themselves.
PoG Mechanism Design#
The Plan-on-Graph (PoG) mechanism is thoughtfully designed to address the limitations of existing KG-augmented LLMs. Guidance leverages the LLM’s ability to decompose complex questions into smaller, manageable sub-objectives, thus guiding the exploration of relevant knowledge graph paths. This flexible approach contrasts with existing methods’ fixed-breadth exploration, improving both efficiency and accuracy. Memory plays a crucial role by dynamically storing and updating relevant information, including the explored subgraph, reasoning paths, and sub-objective status. This allows the LLM to avoid repeatedly processing the same information, enabling more efficient reflection and self-correction. Reflection, the third key component, is a powerful self-correction mechanism. It uses the LLM to evaluate the current reasoning progress, deciding whether to continue exploration, backtrack to correct errors, or explore alternative paths. The interplay of Guidance, Memory, and Reflection forms a sophisticated adaptive planning system, capable of flexible exploration breadth and self-correction of erroneous reasoning, leading to enhanced accuracy and efficiency in KG-augmented LLM reasoning.
Empirical Validation#
An empirical validation section in a research paper should rigorously demonstrate the effectiveness of proposed methods. This involves carefully selected datasets, clearly defined evaluation metrics, and a comprehensive comparison against relevant baselines. The methodology should be transparent, allowing for reproducibility. Statistical significance should be established, and any limitations of the experiments should be openly discussed. Results should be presented clearly, often visually with appropriate figures and tables, providing an in-depth analysis that goes beyond superficial comparisons. A robust empirical validation is critical for establishing the credibility and impact of research findings and should highlight both the strengths and limitations of the proposed approach in relation to the state-of-the-art.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Expanding the scope of the self-correcting mechanism is crucial, potentially by incorporating more sophisticated error detection techniques and refining the reflection process to handle a wider array of reasoning failures. Investigating alternative memory structures beyond the subgraph approach could improve efficiency and scalability. A key area to explore is the integration of more complex reasoning patterns within the adaptive planning framework. The current paradigm focuses on relatively straightforward reasoning paths, and extending it to handle more intricate relationships would significantly enhance its capabilities. Evaluating the robustness of PoG across diverse KG structures and question types is important, particularly focusing on scenarios with noisy or incomplete data. Finally, further research should assess the potential for combining PoG with other LLM-enhancement techniques, such as those focused on improving factuality or reducing hallucination, to explore synergies and further augment the performance of the overall system.
More visual insights#
More on figures

This figure illustrates the overall architecture of the Plan-on-Graph (PoG) model. It shows the four main stages of the process: 1) Task Decomposition, where the input question is broken down into smaller, more manageable sub-objectives; 2) Path Exploration, which uses the LLM to adaptively explore relevant paths within the knowledge graph; 3) Memory Updating, where the explored subgraph, reasoning paths, and sub-objective status are recorded and updated; and 4) Evaluation, where the LLM determines if sufficient information has been gathered, leading to either an answer or a reflection and correction step to refine the search. The diagram visually represents the iterative and self-correcting nature of the PoG model’s approach to KGQA.

This figure shows the impact of varying the depth of exploration on the accuracy of the Plan-on-Graph (PoG) model. The x-axis represents the depth of exploration (number of reasoning steps), and the y-axis represents the accuracy of the model on the CWQ dataset. The graph shows that accuracy generally increases with depth up to a point, after which further increases in depth yield minimal gains. This indicates an optimal depth beyond which additional steps do not significantly improve performance and may even be detrimental due to increased computational cost and the potential for error accumulation.
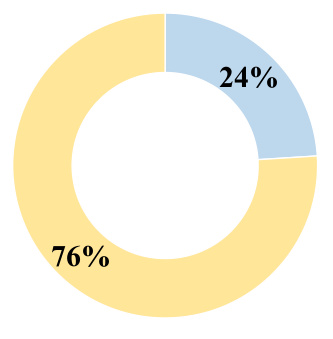
This figure shows a donut chart illustrating the percentage of cases in the dataset where the reasoning process involves backtracking (self-correction) versus those that proceed without any reversals. The majority of cases (76%) follow a direct path, while a smaller portion (24%) require self-correction.
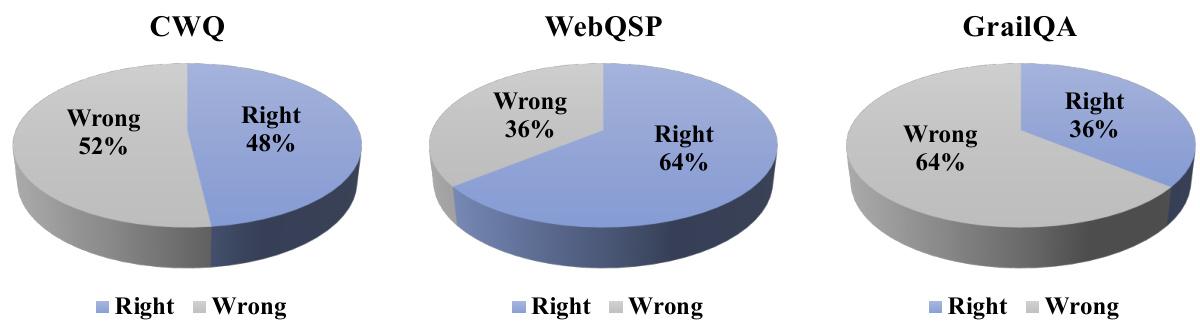
This figure shows the results of the self-correction mechanism implemented in the PoG model on three different KGQA datasets: CWQ, WebQSP, and GrailQA. The pie charts illustrate the percentage of questions answered correctly (in blue) versus incorrectly (in grey) after the self-correction process. The results demonstrate the effectiveness of the self-correction mechanism, which improves the accuracy of the model on all three datasets, although the extent of improvement varies between them.

This figure presents a visual representation of the Plan-on-Graph (PoG) framework. PoG is a novel self-correcting adaptive planning paradigm for KG-augmented LLMs. The framework is comprised of four main components: Task Decomposition, which breaks down complex questions into smaller, manageable sub-objectives; Path Exploration, which dynamically explores relevant reasoning paths in the knowledge graph; Memory Updating, which maintains and updates a subgraph of retrieved knowledge and tracks reasoning progress; and Evaluation, which assesses the sufficiency of retrieved information and triggers self-correction if necessary. The figure uses a flowchart-style diagram to illustrate the interactions and flow between these components.
More on tables
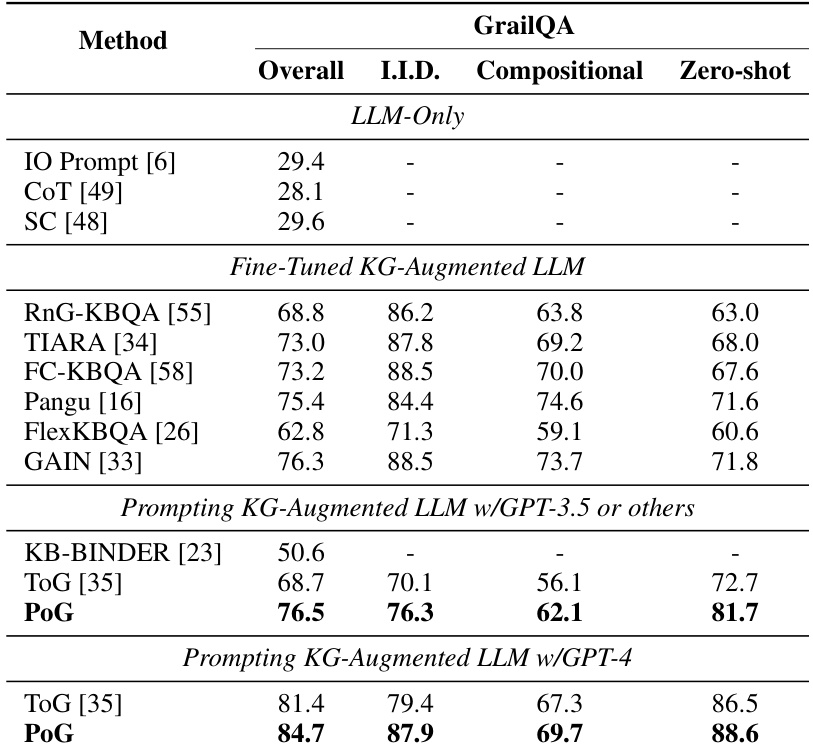
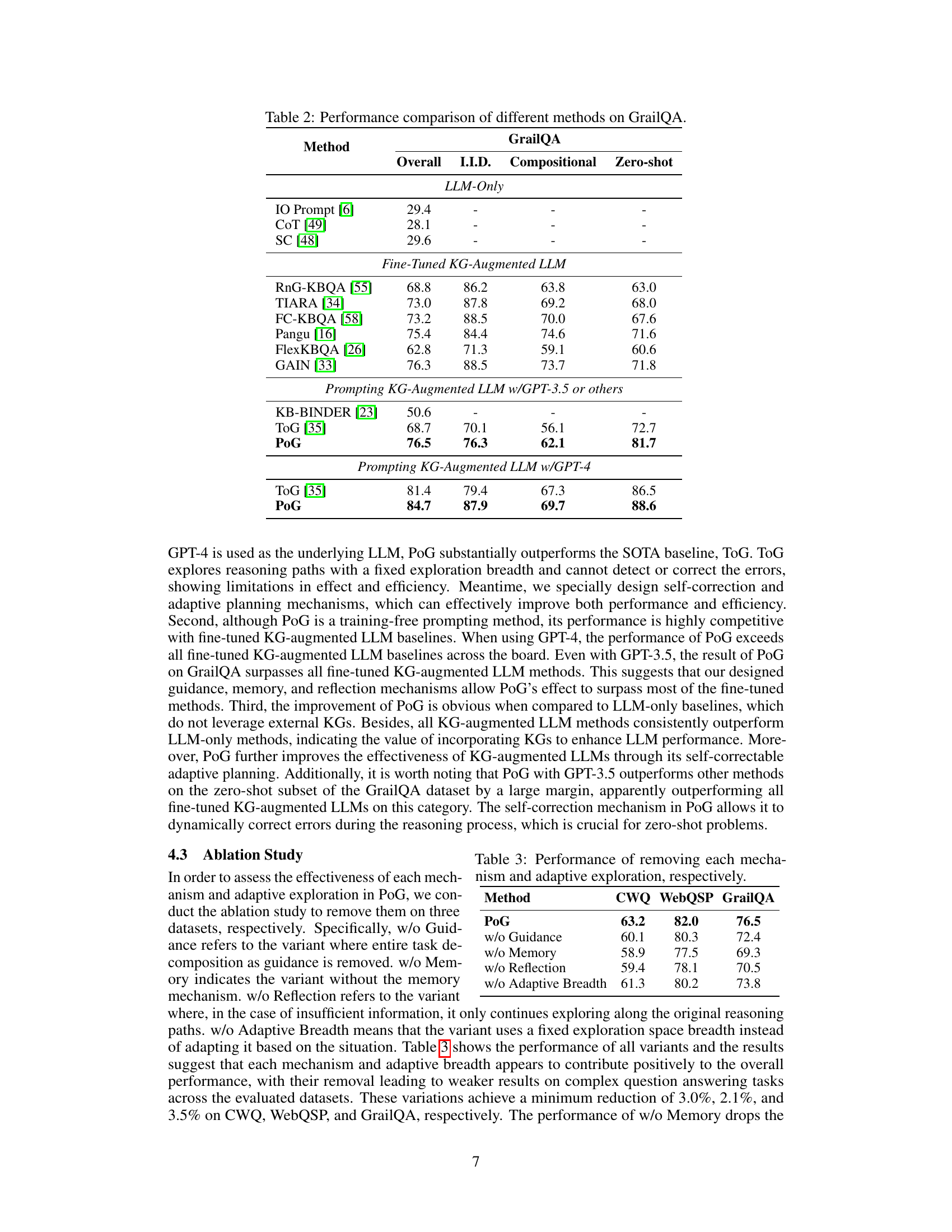
This table presents a performance comparison of various methods on the GrailQA dataset. The methods are categorized into LLM-only, fine-tuned KG-augmented LLMs, and prompting KG-augmented LLMs using either GPT-3.5 or GPT-4. The performance is measured across four different settings: Overall, I.I.D., Compositional, and Zero-shot. This allows for a comprehensive evaluation of different approaches and their ability to handle varying levels of complexity in question answering tasks.
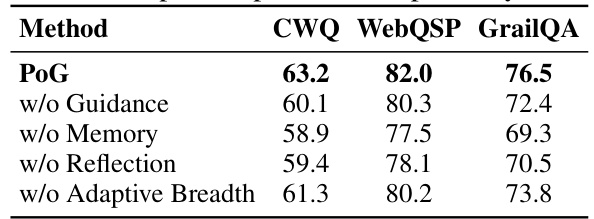
This table presents the results of an ablation study conducted to evaluate the impact of each mechanism (Guidance, Memory, Reflection) and adaptive exploration breadth on the overall performance of the proposed PoG model across three KGQA datasets: CWQ, WebQSP, and GrailQA. The ‘w/o’ prefix indicates the removal of a specific mechanism. The results demonstrate the contribution of each component to the model’s performance. For instance, removing the Guidance mechanism reduced accuracy substantially on all three datasets.
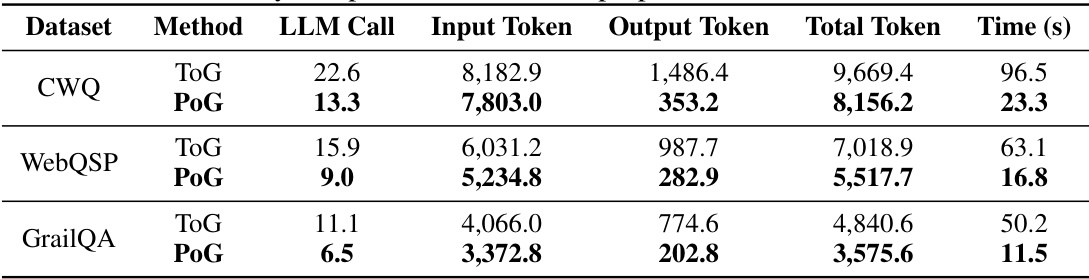
This table compares the efficiency of the proposed PoG model with the ToG baseline across three different KGQA datasets (CWQ, WebQSP, and GrailQA). The metrics used for comparison include the number of LLM calls, input tokens, output tokens, total tokens processed, and the total time taken for question answering. The results show that PoG is significantly more efficient than ToG across all metrics in all three datasets.
This table presents a comparison of the performance of various question answering methods on two benchmark datasets: CWQ and WebQSP. It contrasts the accuracy (Hits@1) of different LLM-only methods and KG-augmented LLM methods (both fine-tuned and prompting-based). The table helps to illustrate the effectiveness of incorporating knowledge graphs into LLMs for improved question answering.

This table presents a comparison of the performance of various question answering methods on two benchmark datasets: CWQ and WebQSP. It compares different categories of models, including LLM-only methods (standard prompting, Chain-of-Thought, and Self-Consistency) and KG-augmented LLM methods (both fine-tuned and prompting-based). The table shows the accuracy (Hits@1) achieved by each method on both datasets, allowing for a direct comparison of their effectiveness in answering complex questions.

This table compares the performance of the proposed PoG method with various baseline methods on two datasets: CWQ and WebQSP. It shows the accuracy (Hits@1) achieved by different LLM-only methods and KG-augmented LLM methods (both fine-tuned and prompting-based). The results highlight the superior performance of PoG compared to other methods, demonstrating its effectiveness in KG-augmented LLM reasoning.

This table compares the performance of the proposed PoG model against various baselines (LLM-only and KG-augmented LLMs) on two benchmark datasets, CWQ and WebQSP. It shows the accuracy (Hits@1) achieved by each method, highlighting PoG’s superior performance.

This table presents a comparison of the performance of various methods (LLM-only and KG-augmented LLMs) on two benchmark datasets, CWQ and WebQSP, using the exact match accuracy (Hits@1) as the evaluation metric. It highlights the effectiveness of the proposed PoG model in comparison to other state-of-the-art (SOTA) approaches.

This table presents the statistics of three KGQA datasets used in the paper: ComplexWebQuestions, WebQSP, and GrailQA. For each dataset, it shows the answer format (Entity or Entity/Number), the number of training examples, the number of test examples, and the license associated with the dataset.
Full paper#