↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Sound source localization (SSL) is crucial for various applications but existing methods like Deep Neural Networks (DNNs) are computationally expensive and struggle in noisy conditions. Biological systems efficiently perform SSL using spike-based neural encoding and computations. This inspired researchers to explore energy-efficient spiking neural networks (SNNs) for SSL.
This paper introduces a novel neuromorphic SSL framework that integrates spike-based neural encoding and computation using Resonate-and-Fire (RF) neurons with phase-locking coding (RF-PLC) and a spike-driven multi-auditory attention (MAA) module. The RF-PLC method efficiently encodes interaural time difference (ITD) cues, while the MAA module enhances robustness by incorporating frequency selectivity and short-term memory. The proposed framework achieves state-of-the-art accuracy and demonstrates exceptional noise robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel neuromorphic model for sound source localization (SSL) that significantly improves both accuracy and robustness, especially in noisy environments. It addresses limitations of existing deep learning approaches by leveraging the energy efficiency of spiking neural networks and incorporating biologically inspired mechanisms. This work opens up new avenues for research in energy-efficient AI and neuromorphic computing, impacting applications like robotics, security monitoring, and autonomous driving.
Visual Insights#
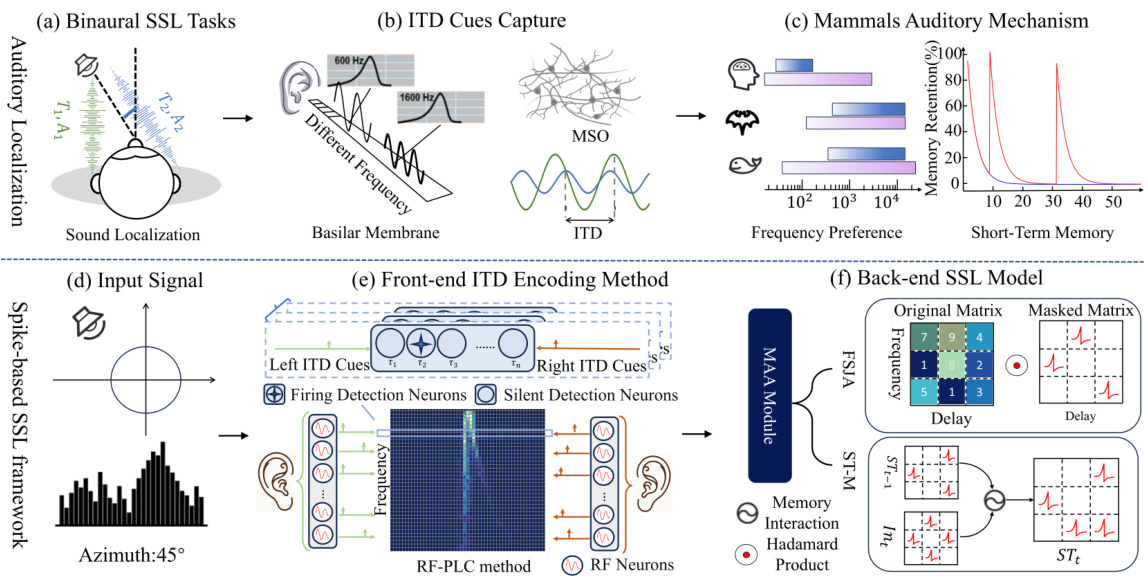
This figure illustrates the proposed spike-based sound source localization (SSL) framework, inspired by biological hearing mechanisms. It shows a schematic of a binaural SSL task, and then breaks down the biological processes of ITD cue capture and multi-auditory attention. The lower half of the figure details the proposed framework’s two main components: the front-end ITD encoding method (using resonate-and-fire (RF) neurons and detection neurons), and the back-end SSL model (utilizing a multi-auditory attention (MAA) module).
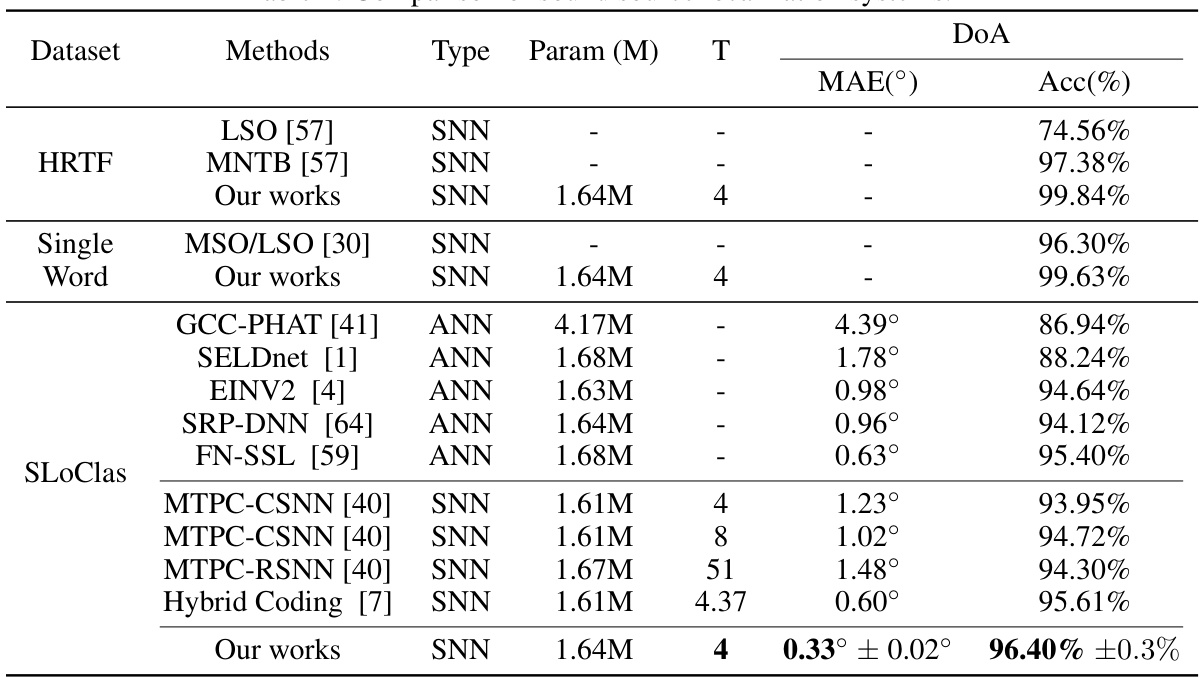
This table compares the performance of different sound source localization (SSL) systems on three datasets: HRTF, Single Word, and SLoClas. The comparison includes various methods, both spiking neural network (SNN) and artificial neural network (ANN) based. Key metrics used for comparison are the mean absolute error (MAE) in degrees and the accuracy (Acc) in percentage. The table also shows the type of network (SNN or ANN), the number of parameters (in millions), and the number of time steps (T) used in each model. The results show that the proposed SNN-based SSL framework achieves state-of-the-art accuracy and robustness, outperforming other methods in terms of both MAE and accuracy.
In-depth insights#
Neuromorphic SSL#
Neuromorphic sound source localization (SSL) leverages the energy efficiency and biological plausibility of spiking neural networks (SNNs). Unlike traditional DNN-based approaches, neuromorphic SSL mimics the brain’s auditory processing, encoding sound as precisely timed spikes. This event-driven computation reduces energy consumption and allows for robust performance in noisy environments. The core of neuromorphic SSL lies in efficiently encoding interaural time differences (ITDs), key cues for sound localization. Resonator-and-fire (RF) neurons, with their resonance properties, offer an energy-efficient alternative to traditional Fourier Transform (FT)-based methods for ITD extraction. Furthermore, incorporating biologically inspired mechanisms like frequency selectivity and short-term memory significantly enhances the robustness and accuracy of SSL, especially in complex acoustic scenes. This approach paves the way for developing portable and explainable AI systems capable of superior auditory perception in real-world conditions.
RF-PLC Encoding#
The RF-PLC (Resonate-and-Fire Phase-Locking Coding) encoding method is a core innovation, offering an energy-efficient alternative to traditional Fourier Transform (FT) based approaches for encoding Interaural Time Differences (ITDs). Leveraging the resonant properties of RF neurons, it directly converts audio signals into spike patterns representing ITDs, bypassing computationally expensive FT operations. This is achieved by a two-stage process: a silent stage where RF neurons selectively respond to frequencies based on resonance, creating a frequency decomposition akin to the basilar membrane; and a spike stage utilizing a phase-locking mechanism to convert the phase information directly into precise spike timings that represent ITDs. The efficiency gains are significant, reducing computational costs and contributing to the framework’s energy efficiency. The direct conversion to spike patterns also ensures that the entire SSL (Sound Source Localization) process remains spike-based, maintaining consistency with the neuromorphic model’s biological inspiration. This novel approach makes a strong contribution to efficient and biologically plausible SSL.
MAA Attention#
The proposed Multi-Auditory Attention (MAA) mechanism is a key contribution, enhancing the robustness and accuracy of the sound source localization (SSL) system. Inspired by biological auditory processing, MAA integrates frequency preferences and short-term memory. The frequency preference component effectively filters irrelevant frequency bands and spatial regions, focusing the network on salient ITD cues. The short-term memory component maintains context across adjacent time steps, improving the model’s ability to track sound sources in dynamic environments. This biologically-plausible approach stands out by its efficiency; unlike computationally expensive methods, MAA achieves superior performance with reduced complexity, making it suitable for real-world applications and resource-constrained settings. The combination of frequency selectivity and temporal context within the MAA module is crucial for superior noise robustness and high accuracy, even in low signal-to-noise ratio scenarios. Its event-driven nature aligns with the spiking neural network framework, making the system highly energy efficient.
Robustness Tests#
A Robustness Test section in a research paper would ideally demonstrate the resilience of a proposed model or system to various challenges. It should go beyond simple accuracy metrics, exploring how performance degrades under noisy conditions, adversarial attacks, or variations in input data. The specific tests employed should align with the application domain; for example, an image recognition system would be tested with images of varying quality or resolution, while a speech recognition system would be assessed under different noise levels or speaking styles. Quantitative metrics, such as accuracy, precision, and recall, are essential in quantifying robustness. Visualization techniques, such as plots demonstrating performance changes across different noise levels or attack intensities, help illustrate robustness results effectively. The analysis of these results is crucial for drawing meaningful conclusions about the system’s limitations and potential real-world applicability. A thorough robustness evaluation is vital for assessing the reliability and practical value of any proposed method.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Firstly, enhancing the model’s robustness to handle more complex real-world acoustic environments by incorporating advanced noise reduction techniques and more sophisticated auditory attention mechanisms is crucial. Secondly, investigating the potential for on-device deployment using neuromorphic hardware to fully leverage the model’s energy efficiency is a significant step towards practical applications. Thirdly, extending the framework to encompass more complex sound source localization scenarios, including multiple sound sources and reverberant environments, would greatly enhance its versatility. Finally, exploring the transferability of the learned features and the model’s generalizability to other acoustic tasks, such as speech recognition and sound event detection, offers exciting opportunities for broader applications of this bio-inspired approach.
More visual insights#
More on figures
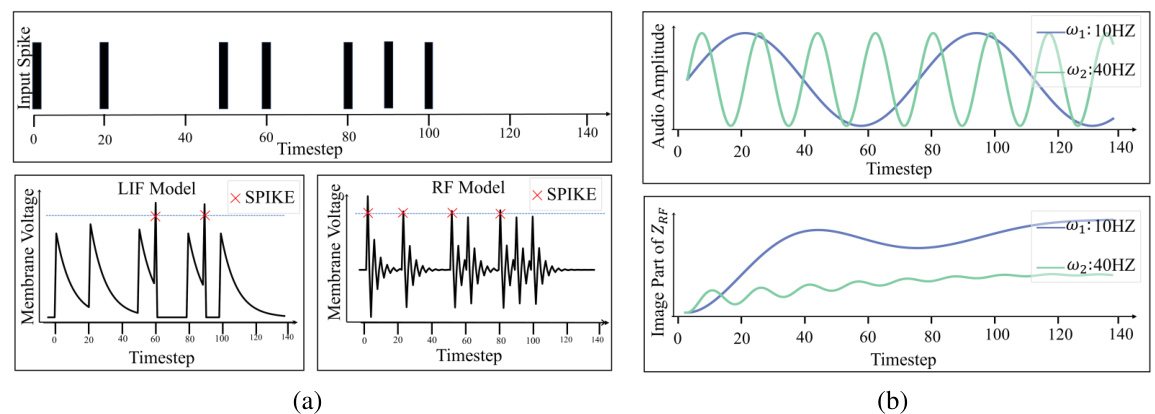
This figure compares the LIF and RF neuron models’ responses to identical input spike trains, showcasing the RF neuron’s frequency selectivity. The left panel (a) shows the distinct voltage accumulation and spiking patterns for both models. The right panel (b) demonstrates that RF neurons with a resonant frequency of 10Hz exhibit a much stronger response to a 10Hz input compared to a 40Hz input, demonstrating frequency selectivity.

This figure illustrates the RF-PLC method for ITD cue extraction and encoding. Panel (a) shows how Resonate-and-Fire (RF) neurons process the input audio in two stages: a silent stage where resonant frequencies are detected and a spike stage where the phase-locking mechanism converts the phase information into spike timings, representing ITD cues. Panel (b) depicts the coincidence detection network, which uses detection neurons with varying delays to encode these spike timings from multiple RF neurons (from two ears) into spike patterns reflecting the ITD.

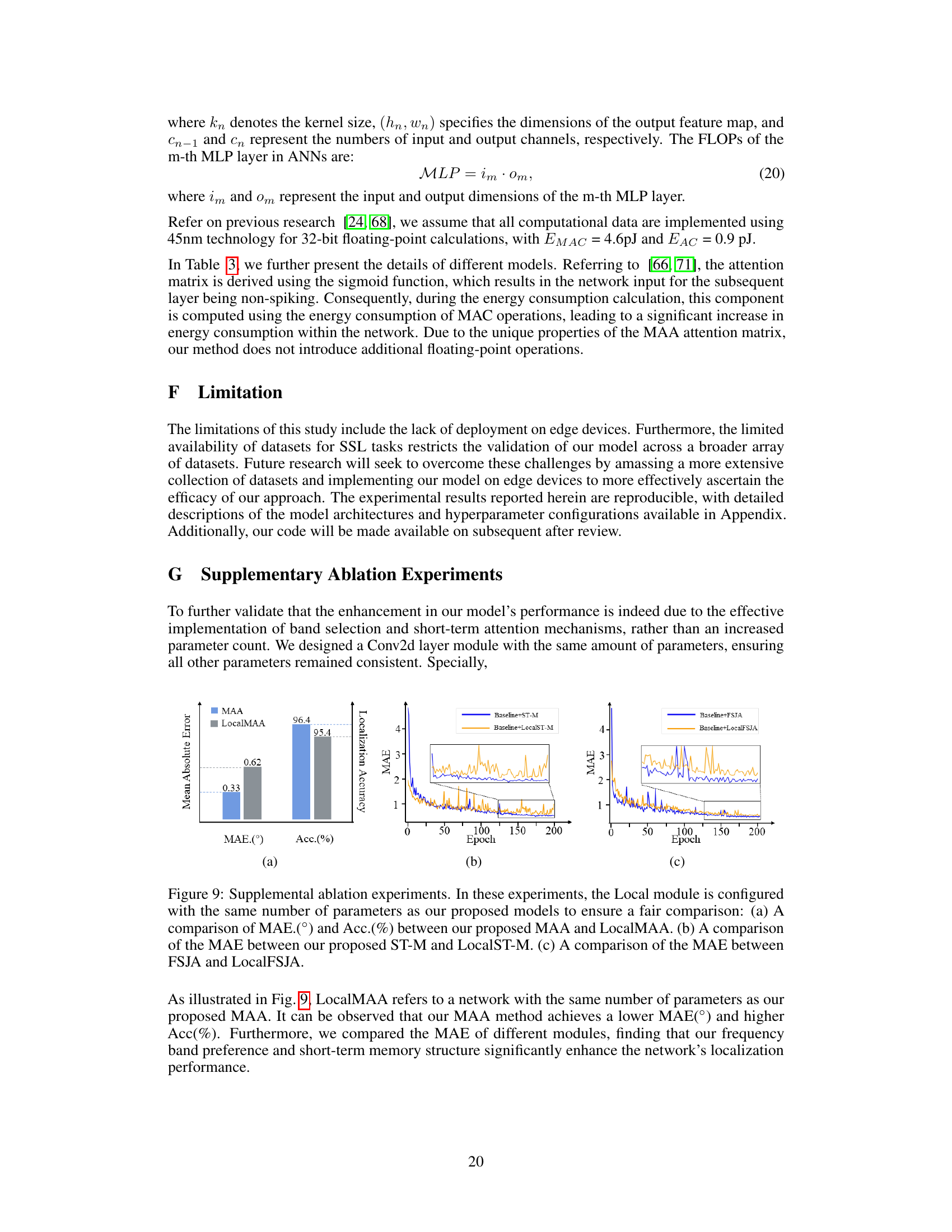
This figure compares different spiking attention methods used in Spiking Neural Networks (SNNs) for sound source localization. It highlights the proposed method, Multi-auditory Attention (MAA), which consists of a Frequency-Spatial Joint Attention (FSJA) module and a Short-Term Memory (ST-M) module. The figure contrasts MAA with conventional spatial attention (CA/SA) and temporal attention (TA), demonstrating MAA’s advantages in terms of computational efficiency and noise robustness due to its use of a binary attention map and focus on relevant temporal information.
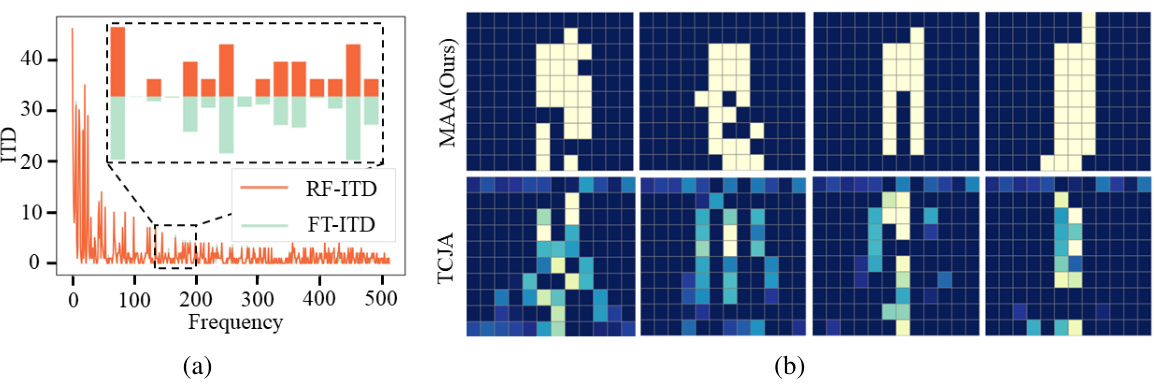
Figure 5(a) compares the ITD extraction results using the proposed RF-PLC method and the traditional FT-ITD method. It demonstrates that RF-PLC achieves comparable accuracy to FT-ITD while avoiding the computationally expensive FT operations, highlighting its efficiency. Figure 5(b) visually compares the attention mechanisms of MAA and TCJA. It showcases that MAA uses a binary attention map, leading to reduced computational cost and noise robustness compared to TCJA’s non-binary attention mechanism.

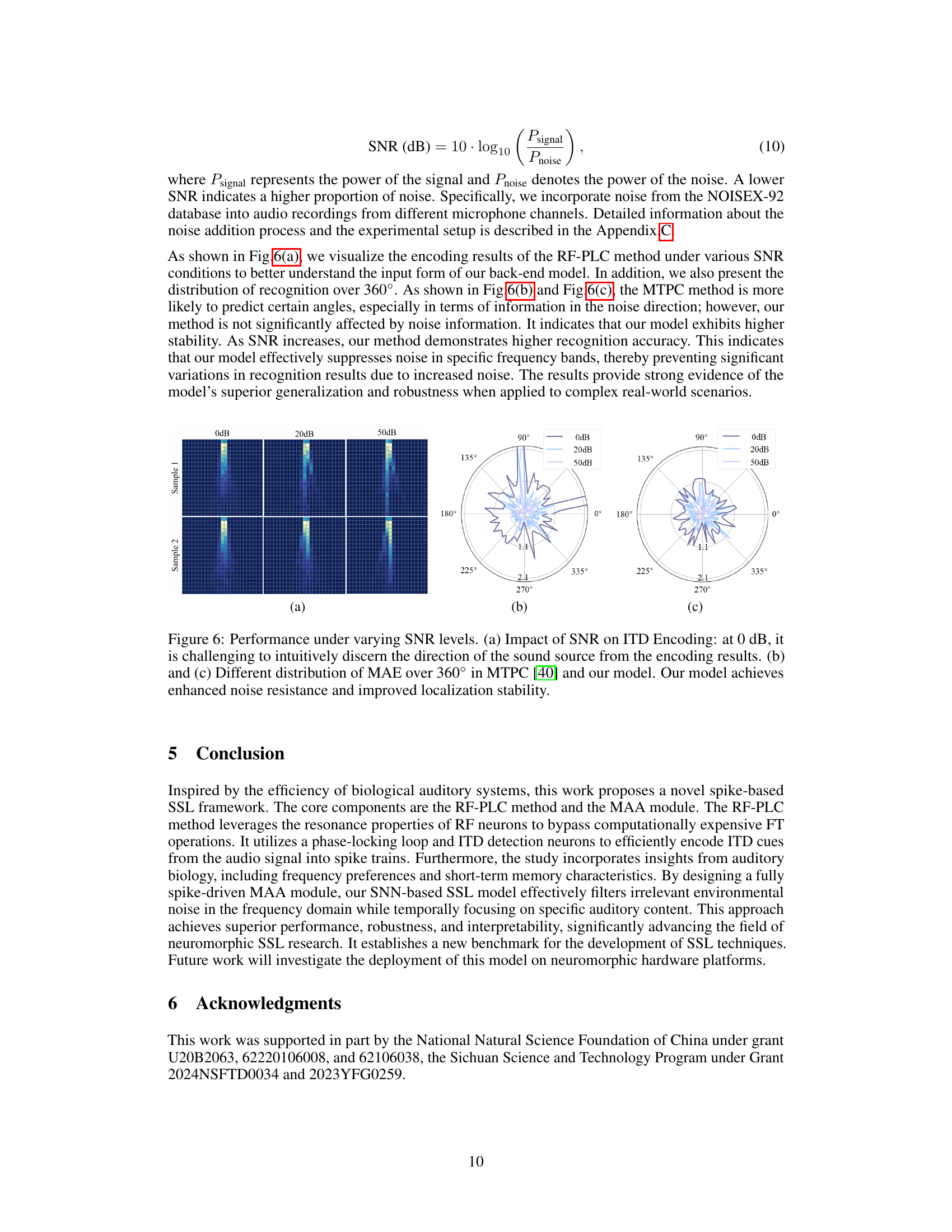
This figure demonstrates the robustness of the proposed model to noise at various signal-to-noise ratios (SNRs). Subfigure (a) shows the ITD encoding results at different SNR levels (0dB, 20dB, and 50dB). Subfigures (b) and (c) compare the mean absolute error (MAE) distribution over 360 degrees for the proposed model and the MTPC method [40], respectively. The results highlight that the proposed model achieves better localization accuracy and stability at low SNR levels, indicating improved noise resistance.
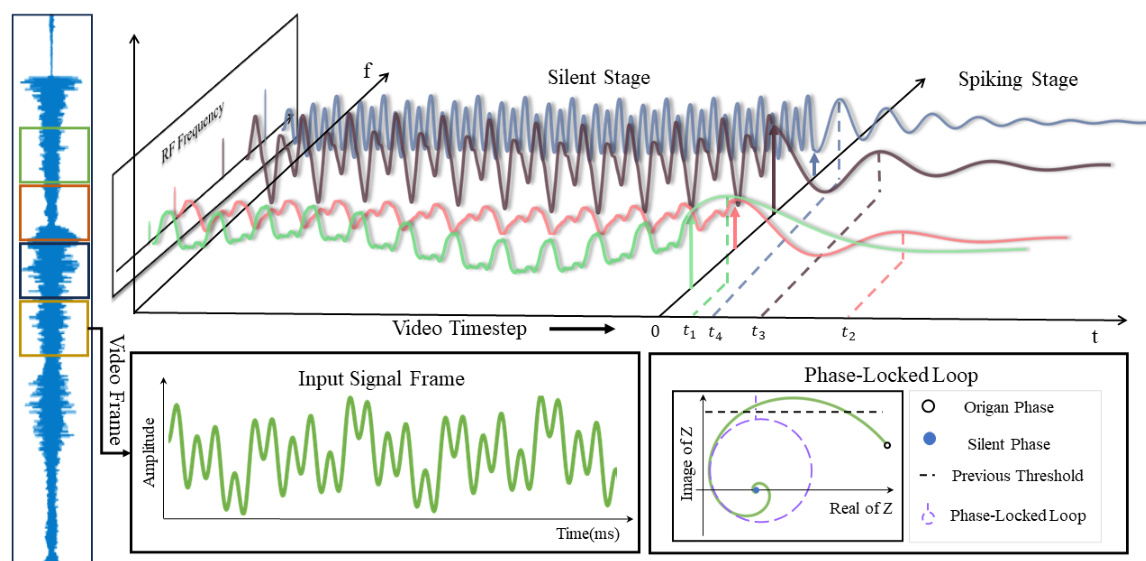
This figure illustrates the energy-efficient mechanism of RF neurons as an alternative to the traditional Fourier Transform (FT) method in sound source localization. It shows how RF neurons accumulate membrane potential during a silent stage, effectively replacing the computationally expensive FT process. During the subsequent spiking stage, the phase information is directly mapped, encoding the ITD cues for efficient and effective sound source localization. The figure includes waveforms showing membrane potential accumulation during the silent stage, and then the resulting spike pattern in the spiking stage, with a phase-locked loop mechanism indicated. The overall process enables highly efficient ITD encoding.

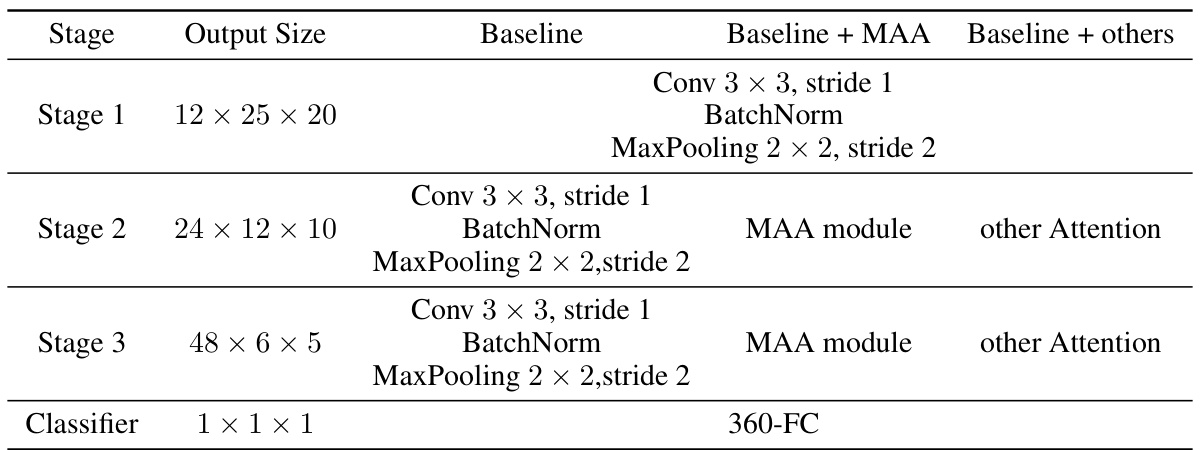
This figure illustrates the architecture of the proposed spike-based neuromorphic model for sound source localization. It consists of two main parts: a front-end ITD encoding method using RF-PLC and a back-end SSL model leveraging a multi-auditory attention (MAA) mechanism. The RF-PLC method efficiently encodes interaural time differences (ITDs) using resonate-and-fire (RF) neurons and detection neurons, avoiding computationally expensive Fourier Transforms (FTs). The MAA module incorporates frequency preferences and short-term memory to enhance robustness. The figure shows the detailed components of the RF-PLC and MAA modules, including their interactions and signal processing steps, finally resulting in a classification of the sound source location.

This figure compares the proposed Multi-auditory Attention (MAA) mechanism with other spiking attention methods. Panel (a) shows a conventional method (CA/SA) using expensive MAC operations. Panel (b) demonstrates a time attention (TA) method that is inefficient for streaming data. Panel (c) highlights the proposed Frequency-Spatial Joint Attention (FSJA) module which uses a binary attention map, making it more computationally efficient and effective at noise reduction. Panel (d) shows the proposed Short-Term Memory (STM) module, which improves efficiency by focusing on relevant temporal cues.
More on tables
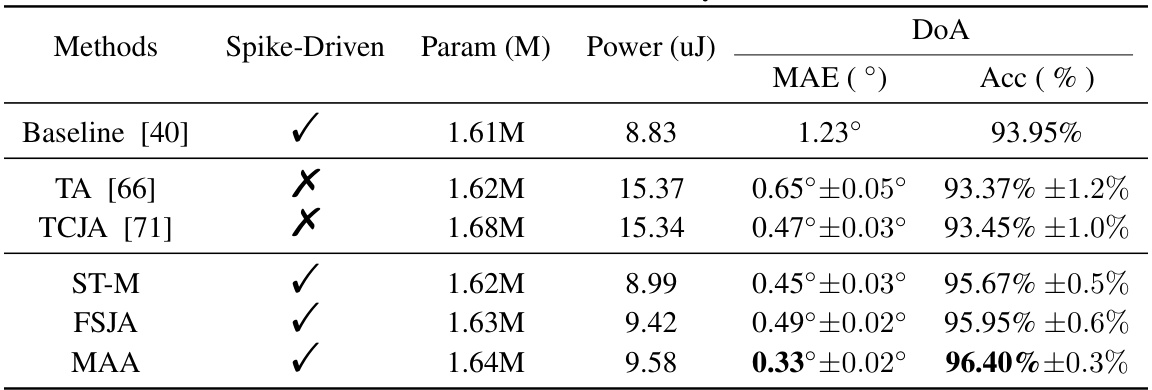
This table compares the performance of various sound source localization (SSL) systems, including both spiking neural network (SNN) and artificial neural network (ANN) based models. The comparison is based on three datasets: HRTF, Single Word, and SLoClas, which vary in complexity and recording conditions. The key metrics used for comparison are Mean Absolute Error (MAE) in degrees, and Accuracy (Acc) in percentage. The table highlights the proposed SNN-based SSL model’s superior accuracy and efficiency compared to existing state-of-the-art (SOTA) methods.

This table compares the performance of various sound source localization (SSL) systems on three datasets: HRTF, Single Word, and SLoClas. The comparison includes methods based on spiking neural networks (SNNs) and artificial neural networks (ANNs), showing parameters, mean absolute error (MAE), and accuracy (Acc). The results highlight the superior performance of the proposed SNN-based SSL framework.
This table compares the performance of various sound source localization systems, including both spiking neural network (SNN) and artificial neural network (ANN) based models. The comparison is done across three datasets: HRTF, Single Word, and SLoClas. For each system, the table lists the model type, the number of model parameters (in millions), the temporal resolution (T), the mean absolute error (MAE) in degrees, and the accuracy (Acc) in percentage. The results show that the proposed SNN-based system outperforms other methods in terms of accuracy and MAE.
Full paper#