↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Off-policy evaluation (OPE) in reinforcement learning faces challenges due to high variance or bias in existing methods, leading to inaccurate policy performance predictions. This often hinders the application of reinforcement learning to real-world scenarios with limited on-policy data. The issue is particularly acute in complex, continuous state spaces, making accurate evaluation difficult.
This work introduces STAR, a novel framework addressing these challenges. STAR leverages state abstraction to simplify complex problems into compact models called abstract reward processes (ARPs). These ARPs are then used to estimate policy performance using off-policy data, providing provably consistent estimates. The framework encompasses a range of estimators, including existing methods as special cases, achieving lower mean squared prediction errors.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on off-policy evaluation (OPE) in reinforcement learning. It introduces a novel framework, STAR, offering a fresh perspective, guaranteeing consistent estimates even for complex problems while significantly outperforming existing methods. This opens avenues for developing more robust and accurate OPE methods, impacting various RL applications. The framework’s flexibility by adjusting parameters allows researchers to explore the bias-variance trade-off. The empirical results on diverse domains show significant improvements, making it highly relevant to current research.
Visual Insights#

🔼 This figure illustrates the process of transforming an MDP and a behavior policy into an abstract reward process (ARP) and using it for off-policy evaluation. Panel (a) shows how a state abstraction function (φ) simplifies the MDP into a smaller discrete ARP. Panel (b) shows how off-policy data (generated by policy πb) is reweighted using importance weights (ρ) before applying the state abstraction function. This reweighted data is then used to estimate the ARP model for the evaluation policy (πe). The expected return of this estimated ARP acts as a consistent estimator for the evaluation policy’s expected return.
read the caption
Figure 1: (a): MDP M and policy πb are transformed into a discrete abstract reward process (ARP) using a state abstraction function φ. The ARP aggregates rewards (denoted by stars) and transition probabilities from all states that map to each abstract state. (b): A model of the ARP for the evaluation policy πe is constructed by: reweighting data generated by πb with importance weights ρ (middle), applying the state abstraction function φ, and performing weighted maximum likelihood estimation of the ARP (right). The expected return of a model of this ARP estimated from off-policy data is a consistent estimator of the expected return of πε.
In-depth insights#
STAR Framework#
The STAR framework, introduced for off-policy evaluation (OPE), offers a novel approach by integrating importance sampling within model learning. It addresses the limitations of existing OPE methods which suffer from either high variance (importance sampling) or irreducible bias (model-based). STAR leverages state abstraction to create compact, discrete models called abstract reward processes (ARPs). The use of ARPs ensures asymptotic correctness, eliminating model class mismatch issues common in purely model-based approaches. By combining importance sampling with ARP model estimation, STAR provides a consistent estimation procedure while mitigating variance through techniques like weight clipping. The framework’s flexibility is highlighted by its ability to encompass existing OPE methods as special cases and offers a range of estimators with varying bias-variance trade-offs, adjustable via parameters such as the state abstraction function and the extent of weight clipping. The empirical evaluation demonstrates that STAR estimators consistently outperform existing baselines, suggesting significant potential for improving the accuracy and reliability of OPE in various real-world reinforcement learning applications.
ARP Consistency#
The concept of ARP consistency is central to the reliability of the proposed off-policy evaluation framework. The core idea is to ensure that the abstract reward process (ARP), a simplified model of the original Markov Decision Process (MDP), accurately reflects the true performance of the target policy. This is crucial because the framework relies on estimating the ARP from off-policy data, which can be noisy and incomplete. Proving ARP consistency, therefore, demonstrates that despite simplification and use of imperfect data, the framework can reliably estimate policy performance. The authors achieve this consistency result asymptotically, meaning that with increasing amounts of data, the estimate from the ARP will converge to the true value. This theoretical guarantee is a significant contribution, contrasting with many existing methods which lack such strong guarantees and are susceptible to bias or high variance. However, it’s important to note the limitations. The consistency results depend on the choice of state abstraction function, highlighting the importance of good feature engineering and potentially limiting applicability depending on data quality and the nature of the task. Further research is needed to explore methods for optimal state abstraction selection to fully maximize the framework’s potential.
Variance Reduction#
The heading ‘Variance Reduction’ in the context of off-policy evaluation (OPE) highlights a critical challenge. OPE methods, while aiming to estimate the performance of a policy using data from a different behavior policy, often suffer from high variance due to the inherent weighting of samples. Importance sampling (IS), a common technique, is particularly prone to this issue. The paper explores methods to mitigate this variance, a key aspect being the use of state abstraction and modeling of Abstract Reward Processes (ARPs). By abstracting the state space, the complexity of the problem is reduced, leading to more stable estimations and lower variance. Weight clipping is introduced as another strategy. This limits the influence of extreme importance weights, thereby stabilizing the estimates, but it may introduce bias. The effectiveness of the proposed methods for variance reduction is thoroughly evaluated via empirical studies, demonstrating significant performance improvements compared to traditional OPE methods. The theoretical analysis and experiments thus suggest that combining state abstraction with careful weighting schemes provides a powerful approach for robust and reliable OPE.
Empirical Analysis#
The heading ‘Empirical Analysis’ suggests a section dedicated to evaluating the proposed method using real-world or simulated data. A robust empirical analysis would involve testing on multiple datasets, varying in size and characteristics, to demonstrate the generalizability of the approach. Comparisons with existing state-of-the-art methods are crucial, providing a benchmark to assess the performance gains. The analysis should be thorough, including metrics such as mean squared error to quantify the effectiveness. Further examination of the bias-variance tradeoff would provide deeper insights into the reliability and robustness of the method. Investigating sensitivity to hyperparameter choices and exploring various scenarios (e.g., varying data distributions) would strengthen the overall analysis and lead to a more complete understanding of the algorithm’s strengths and weaknesses.
Future of OPE#
The future of off-policy evaluation (OPE) is bright, driven by the need for robust and reliable methods in reinforcement learning. Addressing high variance and bias in current OPE techniques remains paramount. Future research might focus on developing more sophisticated model-based approaches, perhaps leveraging advanced deep learning architectures, to better capture the complexity of real-world environments. State abstraction techniques, as explored in the STAR framework, show promise, enabling consistent estimation even with limited data, but automating the discovery of effective abstractions remains a crucial challenge. Furthermore, combining model-based and importance sampling methods might yield estimators with both low variance and low bias, a sweet spot currently elusive. Addressing continuous state and action spaces effectively is another key focus area, along with handling the complexities of partial observability. Finally, rigorous theoretical guarantees for OPE methods, applicable to a wide range of MDPs, are crucial for fostering trust and adoption of OPE in safety-critical applications.
More visual insights#
More on figures
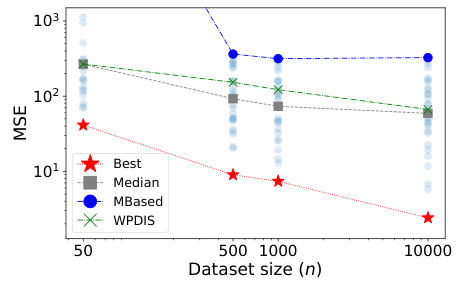
🔼 This figure shows the mean squared prediction error (MSE) for different configurations of the state abstraction function (ø) and weight clipping factor (c) used in the STAR framework. The x-axis represents the dataset size (n), and the y-axis represents the MSE. The lines represent the average MSE across multiple trials for various estimators, including the best and median performing estimators within STAR, along with two existing OPE methods, namely, MBased and WPDIS, which serve as benchmarks for comparison. This plot allows for an assessment of STAR’s performance compared to those of existing methods.
read the caption
Figure 2: Mean squared prediction errors of the estimated ARPs for the set of hyperparameters swept over for CartPole.

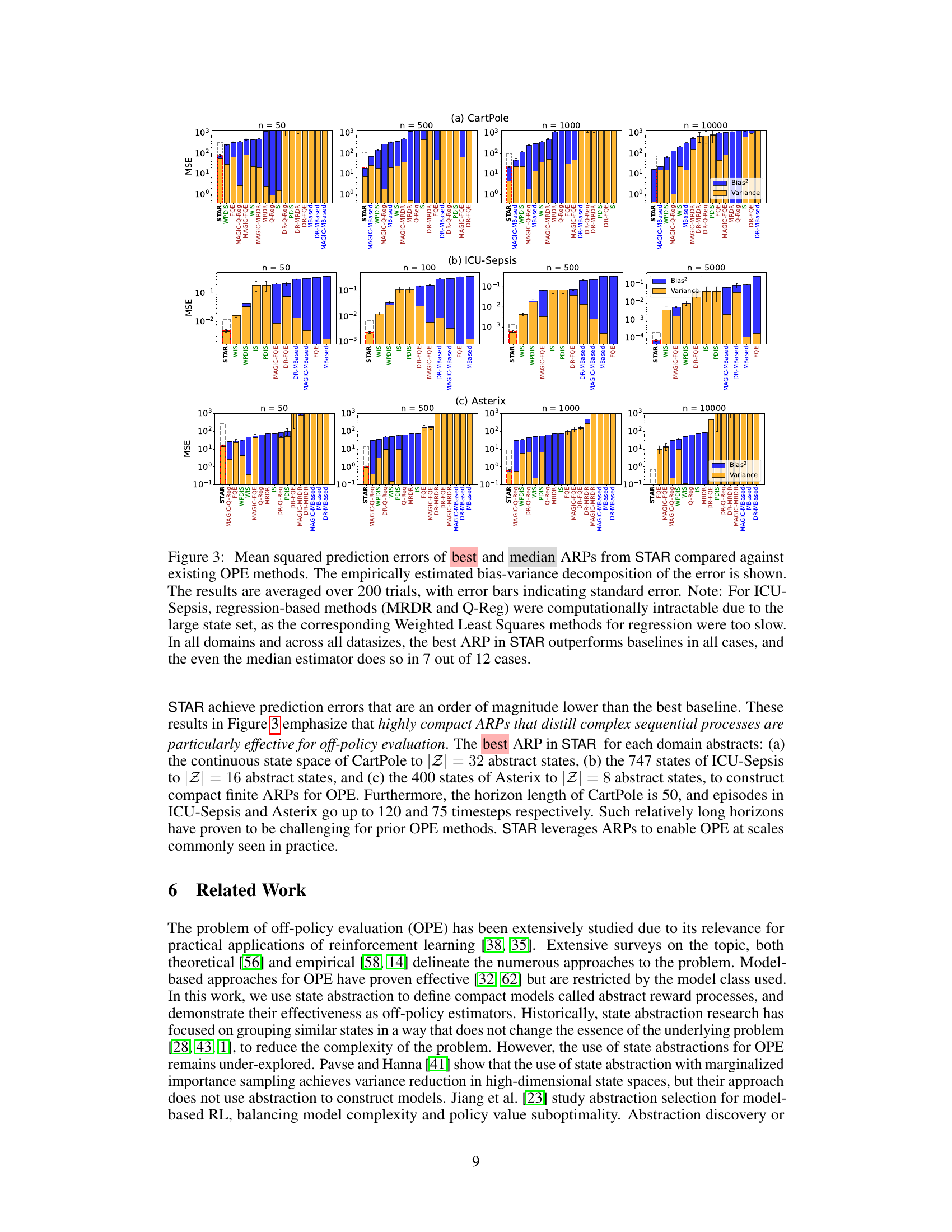
🔼 This figure compares the performance of the best and median ARPs from the STAR framework against existing off-policy evaluation (OPE) methods across three different domains (CartPole, ICU-Sepsis, and Asterix) and various dataset sizes. It displays the mean squared prediction error (MSE), broken down into bias and variance components, for each method. The results demonstrate that STAR estimators consistently outperform baseline OPE methods, highlighting the effectiveness of the STAR framework in providing accurate and low-variance OPE estimates.
read the caption
Figure 3: Mean squared prediction errors of best and median ARPs from STAR compared against existing OPE methods. The empirically estimated bias-variance decomposition of the error is shown. The results are averaged over 200 trials, with error bars indicating standard error. Note: For ICU-Sepsis, regression-based methods (MRDR and Q-Reg) were computationally intractable due to the large state set, as the corresponding Weighted Least Squares methods for regression were too slow. In all domains and across all datasizes, the best ARP in STAR outperforms baselines in all cases, and the even the median estimator does so in 7 out of 12 cases.
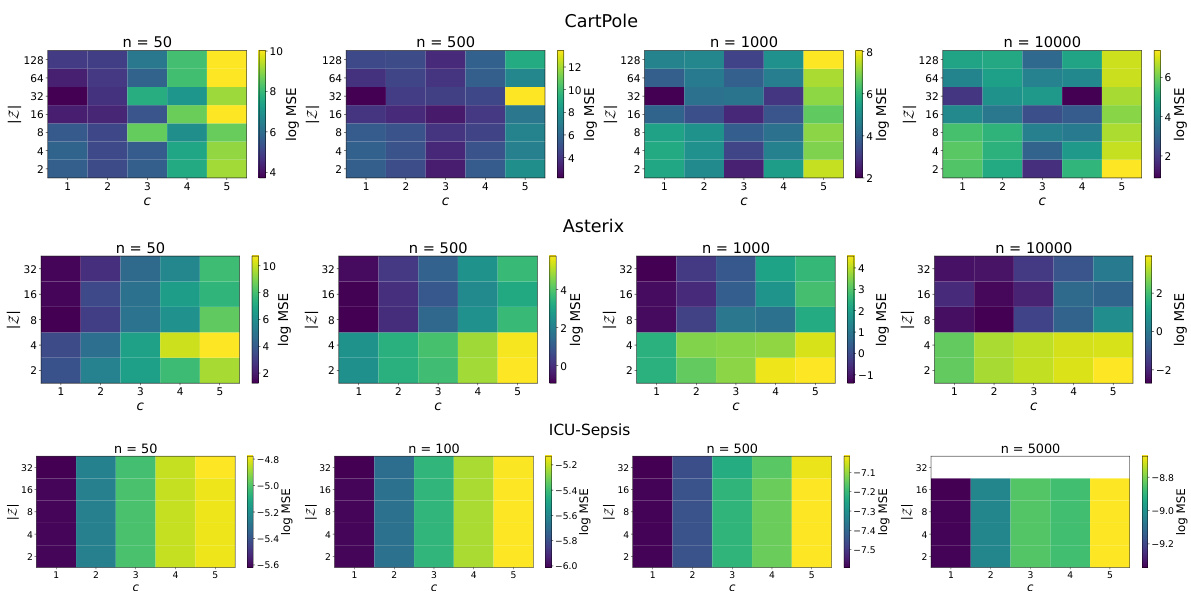
🔼 The figure shows the mean squared prediction errors for the estimated ARPs across a range of configurations of state abstraction (|Z|) and weight clipping (c). It compares the performance of the best and median performing ARPs against two baseline methods: Weighted Per-Decision Importance Sampling (WPDIS) and the approximate model-based estimator (MBased). The plot demonstrates that even median-performing ARPs from STAR achieve competitive performance compared to existing state-of-the-art methods.
read the caption
Figure 2: Mean squared prediction errors of the estimated ARPs for the set of hyperparameters swept over for CartPole.
Full paper#