↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing human rendering methods struggle with occlusions, often producing incomplete or unrealistic results. This is a significant limitation, as real-world scenarios frequently involve obstructions. The assumption of full visibility doesn’t hold true in many practical applications, which necessitates the development of more robust approaches. These methods are often computationally expensive and not suitable for real-time rendering.
OccFusion tackles this problem by combining 3D Gaussian splatting with 2D diffusion priors. This innovative approach uses a three-stage pipeline that recovers complete human masks from partial observations, optimizes 3D Gaussians using Score-Distillation Sampling, and refines the rendering using in-context inpainting. The result is a method that delivers state-of-the-art rendering quality and efficiency, surpassing existing techniques in handling occlusions and generating complete, artifact-free renderings of humans, even from monocular videos.
Key Takeaways#
Why does it matter?#
This paper is important because it presents OccFusion, a novel approach to high-fidelity human rendering that effectively handles occlusions, a common challenge in real-world scenarios. The method’s efficiency and state-of-the-art performance make it highly relevant to various applications, including augmented and virtual reality, and opens up new avenues for research in generative models and 3D reconstruction.
Visual Insights#
This figure demonstrates the problem of reconstructing humans from monocular videos in the presence of occlusions, where existing methods often fail to produce clean and complete renderings. It introduces OccFusion, a novel method that uses a combination of 3D Gaussian splatting and 2D diffusion priors to improve the quality and efficiency of human rendering, achieving state-of-the-art results in handling occlusions.
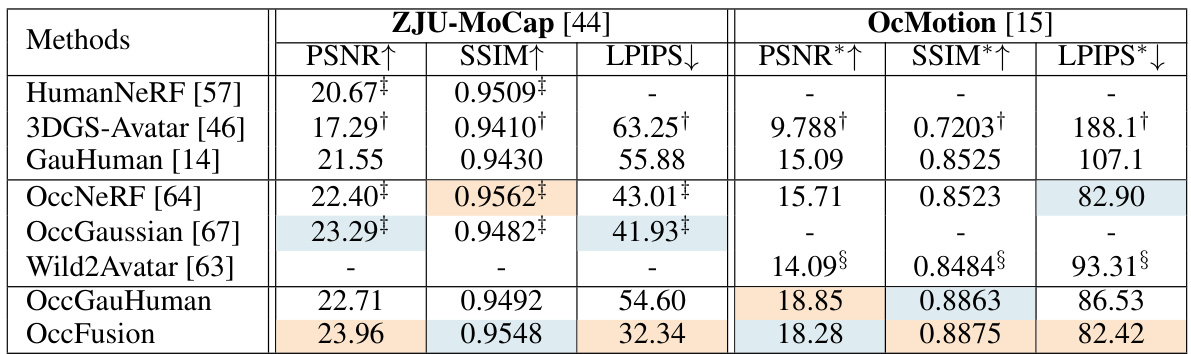
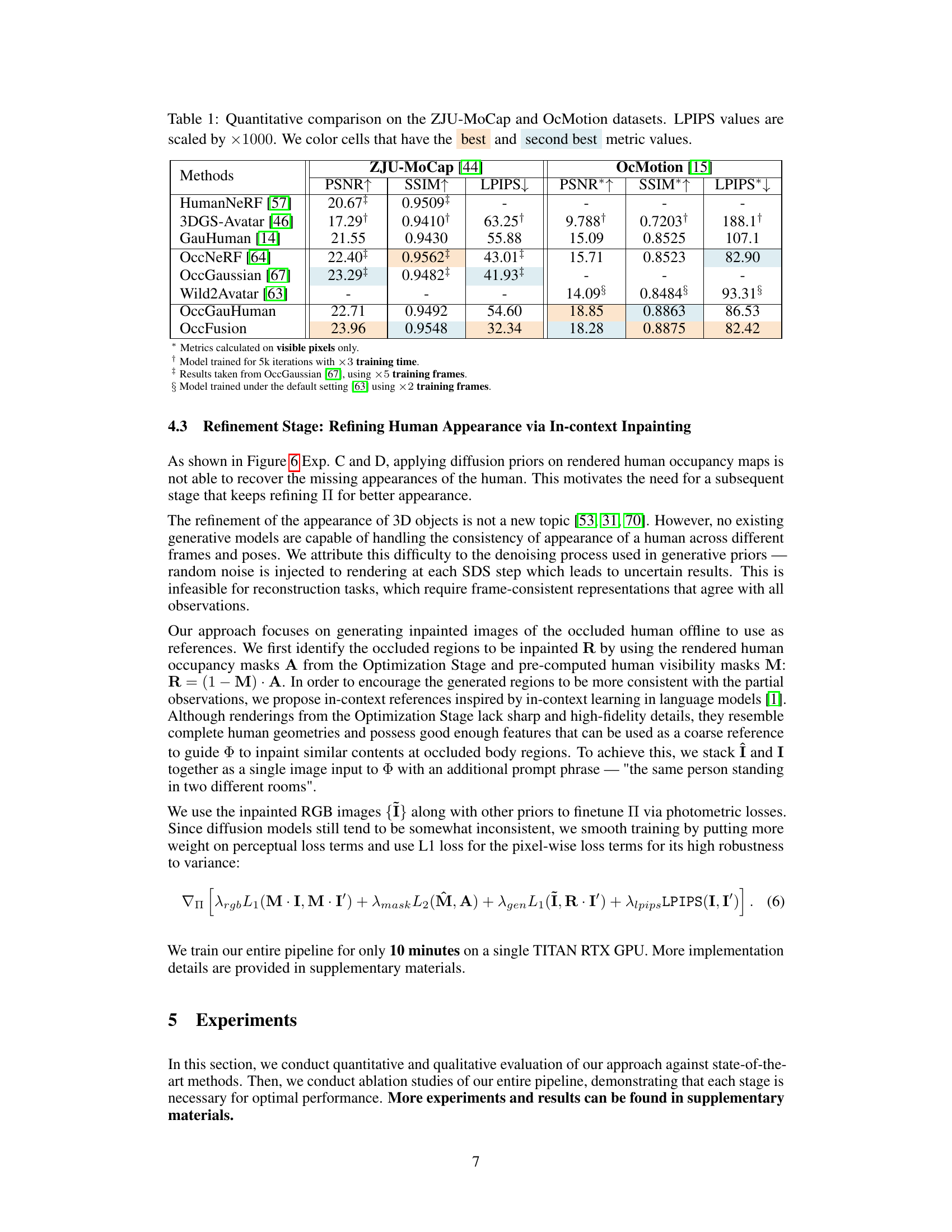
This table presents a quantitative comparison of different methods for human rendering on two benchmark datasets: ZJU-MoCap and OcMotion. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher PSNR and SSIM values indicate better rendering quality, while a lower LPIPS value suggests better perceptual similarity to the ground truth. The table highlights the best and second-best performing methods for each metric on each dataset, providing a clear comparison of the proposed OccFusion method against state-of-the-art techniques.
In-depth insights#
Occlusion Handling#
The paper tackles the challenge of rendering humans realistically despite occlusions, a common issue in real-world videos. Existing methods often struggle with this, producing incomplete or artifact-ridden results. The core approach involves leveraging generative diffusion models to effectively “hallucinate” missing parts of the human, ensuring completeness and visual fidelity. This involves using pre-trained models to inpaint masked areas of the human, improving the quality of both binary and RGB image renderings. The use of 3D Gaussian splatting is critical, providing an efficient and effective representation for the human’s geometry, and allowing for fast training and rendering speeds. Three distinct stages are presented for inpainting, optimization, and refinement, culminating in high-quality rendering of even heavily occluded humans. The method’s strength lies in its ability to seamlessly combine powerful generative models with an efficient geometric representation, leading to superior results compared to other state-of-the-art techniques.
Diffusion Priors#
The utilization of diffusion priors in the paper presents a novel approach to address the challenge of rendering occluded humans. Generative diffusion models, pretrained on large datasets of images, are leveraged to provide a powerful prior for guiding the reconstruction process. This approach allows the system to effectively
Gaussian Splatting#
Gaussian splatting is a novel rendering technique that represents 3D scenes as a collection of 3D Gaussian distributions. Instead of relying on continuous functions like traditional NeRFs, it uses discrete Gaussians to model the scene’s geometry and appearance, making it computationally efficient and well-suited for real-time applications. Each Gaussian splat is defined by its location, opacity, color, and covariance matrix, capturing both the scene’s geometry and surface properties. This discrete representation allows for faster rendering and simplifies the optimization process, as the model parameters are directly associated with individual scene elements. The technique’s strength lies in its ability to effectively handle dynamic scenes and occlusions, demonstrating improved performance in various scenarios compared to traditional methods. Its efficiency makes it suitable for applications involving dynamic human rendering, where speed is often critical. Furthermore, the explicit nature of the Gaussian representation makes it easier to incorporate additional priors, such as shape or pose constraints. This renders Gaussian splatting an effective and adaptable technique for complex 3D scenes, particularly in scenarios demanding real-time performance and high rendering quality.
3-Stage Pipeline#
The proposed 3-stage pipeline for rendering occluded humans represents a significant advance in handling the challenges of partial visibility. The Initialization Stage cleverly leverages generative diffusion models to intelligently inpaint incomplete human masks, providing crucial guidance for subsequent stages. This is crucial because it ensures that the subsequent optimization process is not misled by missing data, leading to more accurate and complete 3D reconstructions. The Optimization Stage builds upon this foundation by optimizing 3D Gaussian splatting with the aid of Score Distillation Sampling (SDS), ensuring the human model remains consistent across different poses and viewing angles. Finally, the Refinement Stage utilizes in-context inpainting to further enhance the rendering quality by filling in details in areas of less observation. This multi-stage approach offers a holistic solution, addressing the problem from multiple angles and significantly improving the state-of-the-art in efficiency and quality for rendering occluded humans. The combination of geometry-based 3D Gaussian splatting and generative diffusion priors is particularly effective, capitalizing on the strengths of both approaches for superior performance.
Future of Rendering#
The future of rendering is poised for significant advancements, driven by the convergence of several key trends. Generative models, particularly diffusion models, will play an increasingly important role, enabling the creation of highly realistic and detailed scenes with reduced computational cost. Improved efficiency will be paramount, with techniques like Gaussian splatting and neural representations continually refined for real-time performance on increasingly complex scenes. The ability to handle occlusions and partial views robustly will be crucial for creating photorealistic renderings of humans and other dynamic objects in real-world environments. We can anticipate breakthroughs in handling dynamic content, such as the accurate and efficient rendering of articulated characters, moving crowds, or deformable objects. Ultimately, the trend is toward versatility and generalizability, where rendering systems seamlessly adapt to a wider range of scenarios, datasets and viewing conditions with minimal training, paving the way for realistic virtual and augmented reality applications and breakthroughs in fields such as healthcare and entertainment.
More visual insights#
More on figures
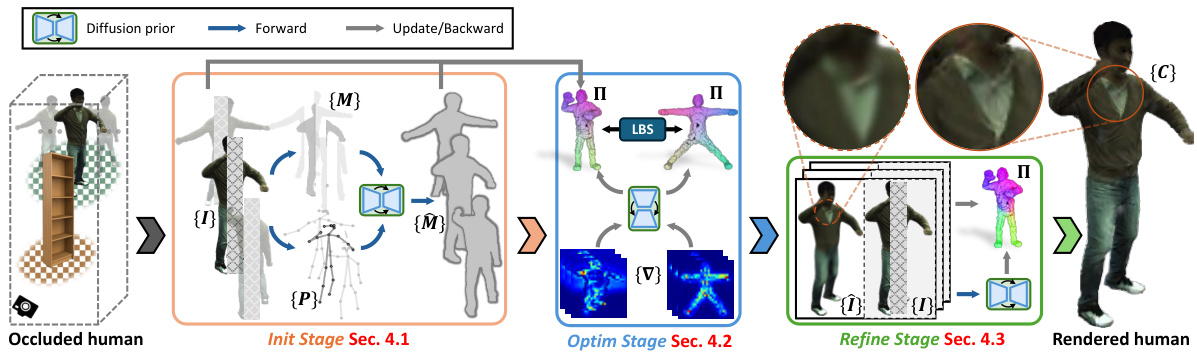
This figure shows the OccFusion pipeline, which consists of three stages: Initialization, Optimization, and Refinement. The Initialization stage uses a diffusion model to inpaint missing parts of the human mask from partially visible input images. The Optimization stage uses 3D Gaussian splatting and Score Distillation Sampling (SDS) to optimize the 3D Gaussian representation of the human, enforcing completeness. Finally, the Refinement stage employs in-context inpainting to enhance the rendering quality, particularly in less observed regions.

This figure shows the results of using Stable Diffusion 1.5 to generate images conditioned on challenging poses. The leftmost column shows an example of an occluded human image. The middle column shows that directly using the original pose as input leads to unstable generations with multiple limbs and abnormalities. The rightmost column illustrates that simplifying the pose by removing self-occluded joints before inputting into the Stable Diffusion model yields more realistic and feasible generations.
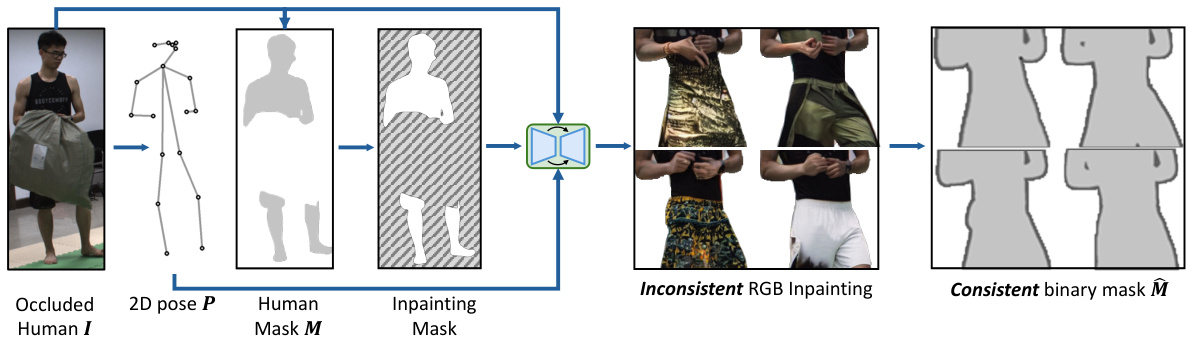
This figure illustrates the inpainting process used in the Initialization Stage of the OccFusion method. It demonstrates that using a generative model to directly inpaint occluded human regions in an RGB image is unreliable, resulting in inconsistent results. However, inpainting the corresponding binary human mask produces much more consistent results. This is due to the fact that minor variations in human silhouette are less critical than variations in color and texture. The consistent binary masks obtained after this process are then used to provide reliable supervision in the subsequent stages of the OccFusion pipeline.

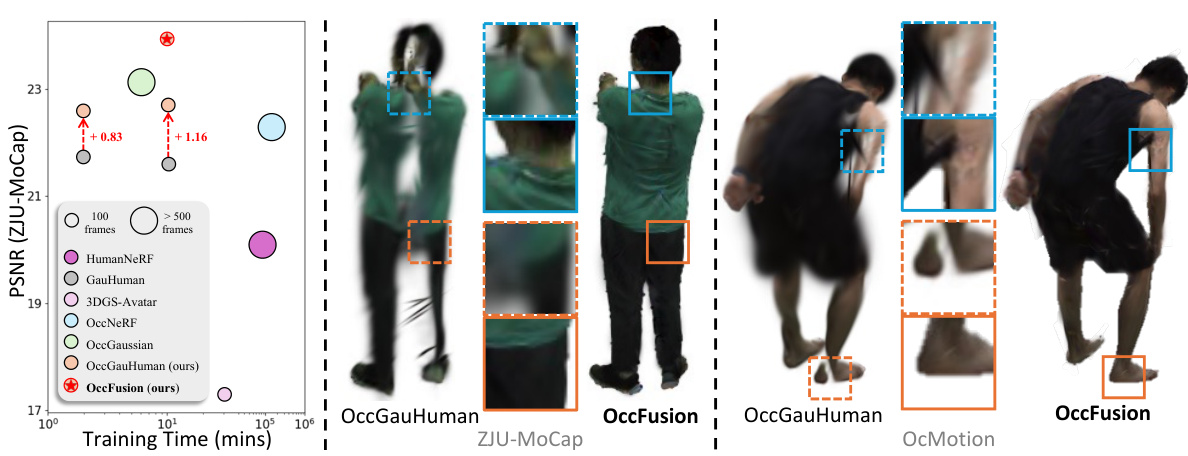
This figure presents a qualitative comparison of the OccFusion model against other state-of-the-art methods on the ZJU-MoCap and OcMotion datasets. The left side shows simulated occlusions from ZJU-MoCap, while the right shows real-world occlusions from OcMotion. Each column represents a different method: input (occluded view), OccNeRF (ON), OccGauHuman (OGH), OccFusion (Ours), and the reference (ground truth). The results demonstrate that OccFusion produces more realistic and complete renderings of humans compared to other methods, especially in the presence of occlusions.
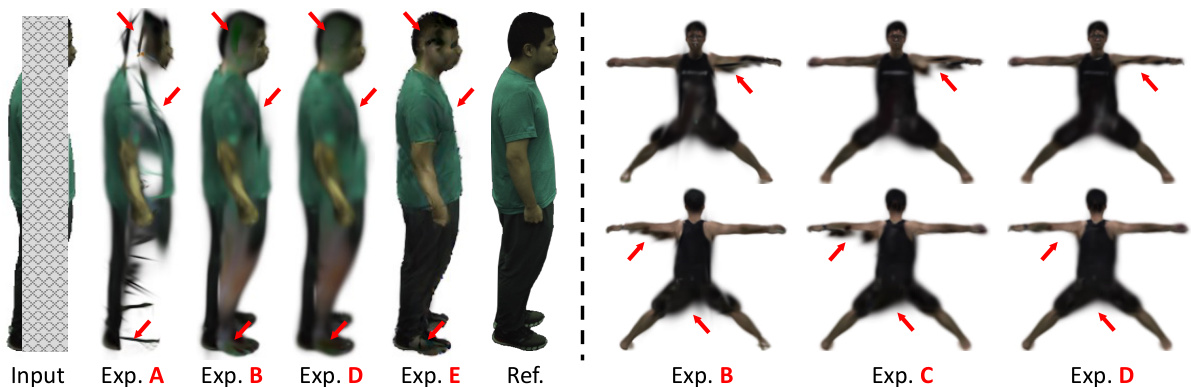
This figure shows a qualitative comparison of the ablation experiments presented in Table 2. The left panel illustrates the results of experiments A-E on a person from the ZJU-MoCap dataset [44] in a relatively simple side pose. The right panel shows results from experiments B-D on a person from the OcMotion dataset [15] in a more challenging, spread-leg pose. Red arrows highlight the key differences between the results of each experiment, showing how each component contributes to improving the final reconstruction of the human. This figure visually demonstrates the importance of each stage in the OccFusion pipeline, highlighting the impact of the initialization, optimization and refinement stages in recovering complete human geometry from occluded observations.

This figure presents a qualitative comparison of human rendering results on simulated and real-world occlusions using different methods. The left side shows results from the ZJU-MoCap dataset with simulated occlusions, while the right side shows results from the OcMotion dataset with real-world occlusions. Each column represents: Input (occluded human), GauHuman (GH), OccGauHuman (OGH), OccFusion (Ours), and Reference (Ref). The figure visually demonstrates the superior performance of OccFusion in handling occlusions and generating high-quality renderings.

This figure compares the results of the Refinement Stage with and without using in-context inpainting. It showcases that the in-context inpainting method significantly improves the quality of the rendered human, especially in occluded areas. The red arrows highlight the key differences between the two approaches, demonstrating how in-context inpainting effectively fills in missing details and creates a more realistic representation.

This figure compares the results of training the OccFusion model with complete, occluded, and in-painted human masks. The results show that although using in-painted masks introduces some inconsistency compared to using complete masks, the final rendering quality remains largely unaffected. This demonstrates the robustness of the OccFusion method to variations in input data.

This figure shows the results of novel view synthesis using InstantMesh, a method that conditions on the least occluded frame from a video sequence to reconstruct a complete 3D human model. The results highlight the discrepancies that still exist in the generated views, even after attempting to recover the missing parts from the least occluded frame. The red circles highlight areas where the reconstruction is incomplete or inaccurate compared to the reference image.
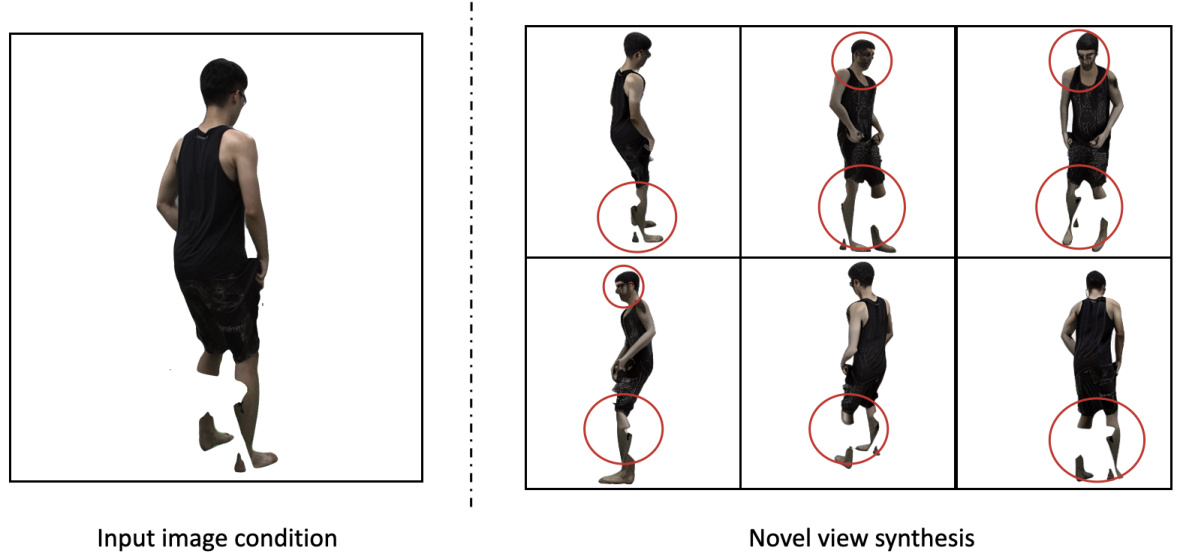
This figure shows the results of novel view synthesis using InstantMesh, a method that conditions on a single image. The input image shows a person with significant occlusions. The results demonstrate that while InstantMesh can generate novel views, it struggles with the occluded regions, leading to inconsistencies such as missing or incomplete limbs. The red circles highlight areas where the model produces inaccurate or missing details.
More on tables
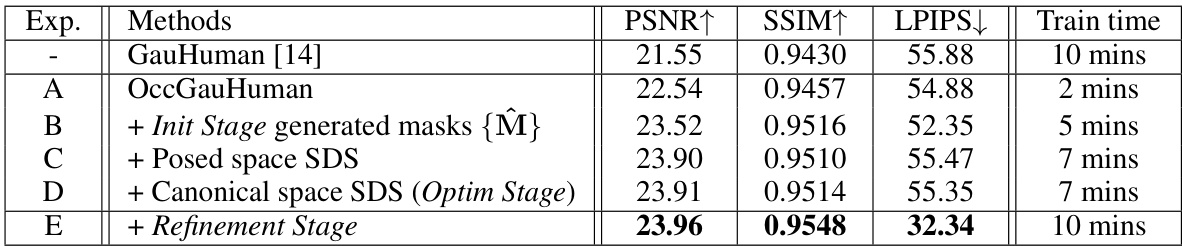
This table presents a quantitative comparison of different human rendering methods on two benchmark datasets: ZJU-MoCap and OcMotion. The methods are evaluated based on three metrics: PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher PSNR and SSIM values indicate better rendering quality, while a lower LPIPS value indicates better perceptual similarity to the ground truth. The table highlights the best and second-best performing methods for each metric and dataset.

This table presents a quantitative comparison of different methods for human rendering on two datasets: ZJU-MoCap and OcMotion. The metrics used are PSNR (higher is better), SSIM (higher is better), and LPIPS (lower is better). LPIPS values are scaled by a factor of 1000 for easier comparison. The table highlights the best and second-best performing methods for each metric on each dataset, indicating the relative performance of OccFusion compared to other state-of-the-art techniques.
Full paper#