TL;DR#
Current Large Language Models (LLMs) struggle with reliably generating correct code, especially for complex tasks. Existing self-debugging methods primarily rely on prompting, which proves ineffective for smaller, open-source LLMs. This creates a need for more effective training techniques to enhance their self-debugging capabilities. The lack of high-quality training data for code explanation and refinement further exacerbates this challenge.
The research paper introduces LEDEX, a novel training framework designed to address these issues. LEDEX uses an automated pipeline to generate a high-quality dataset for code explanation and refinement. It then employs supervised fine-tuning (SFT) and reinforcement learning (RL) with a novel reward design to train LLMs. The results demonstrate significant improvements in the LLMs’ ability to self-debug, producing more accurate code and more useful explanations. These improvements are observed across multiple benchmarks and LLM architectures, highlighting the framework’s generalizability and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) for code generation and debugging. It introduces LEDEX, a novel framework that significantly improves LLMs’ self-debugging capabilities, addresses the lack of high-quality training data, and opens new avenues for research in automated code refinement and explanation generation. The model-agnostic nature of LEDEX further enhances its value to the broader research community. This work is particularly timely given the increasing focus on improving the reliability and robustness of LLM-based code generation systems.
Visual Insights#
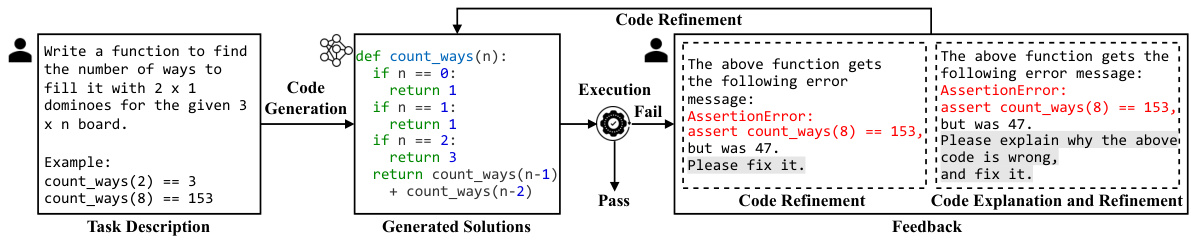
🔼 This figure illustrates the process of an LLM generating code and then self-debugging it. A user provides a programming task description to the LLM, which generates an initial code solution. This solution is then executed against unit tests. If it passes, the process ends. If it fails, the LLM is queried again, either directly for a refined solution or for a code explanation and subsequent refinement. This iterative process continues until the LLM produces a correct solution or the maximum number of iterations is reached.
read the caption
Figure 1: Pipeline of letting LLM generate code and self-debug.

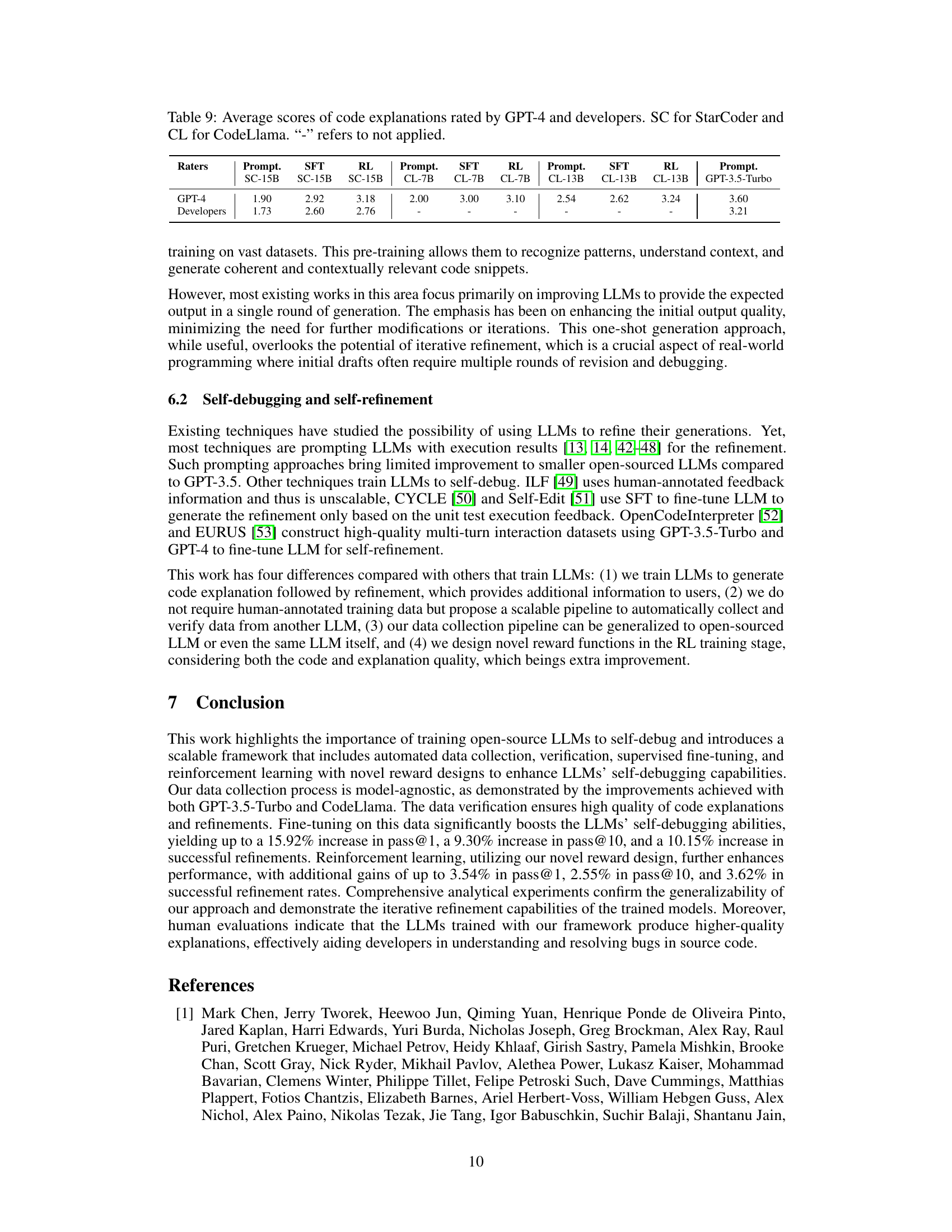
🔼 This table presents the results of data collection using pre-trained LLMs. For each dataset (MBPP Training, APPS Training, and CodeContest), it shows the number of unique problems, the number of correct solutions generated by the LLMs, the number of incorrect solutions, the number of successfully refined incorrect solutions by GPT-3.5-Turbo, and the success rate of refinement for each dataset.
read the caption
Table 1: Number of unique, correct, wrong solutions sampled from pre-trained LLMs, as well as the number of correct refinement generated by GPT-3.5-Turbo and its refinement rate on each dataset.
In-depth insights#
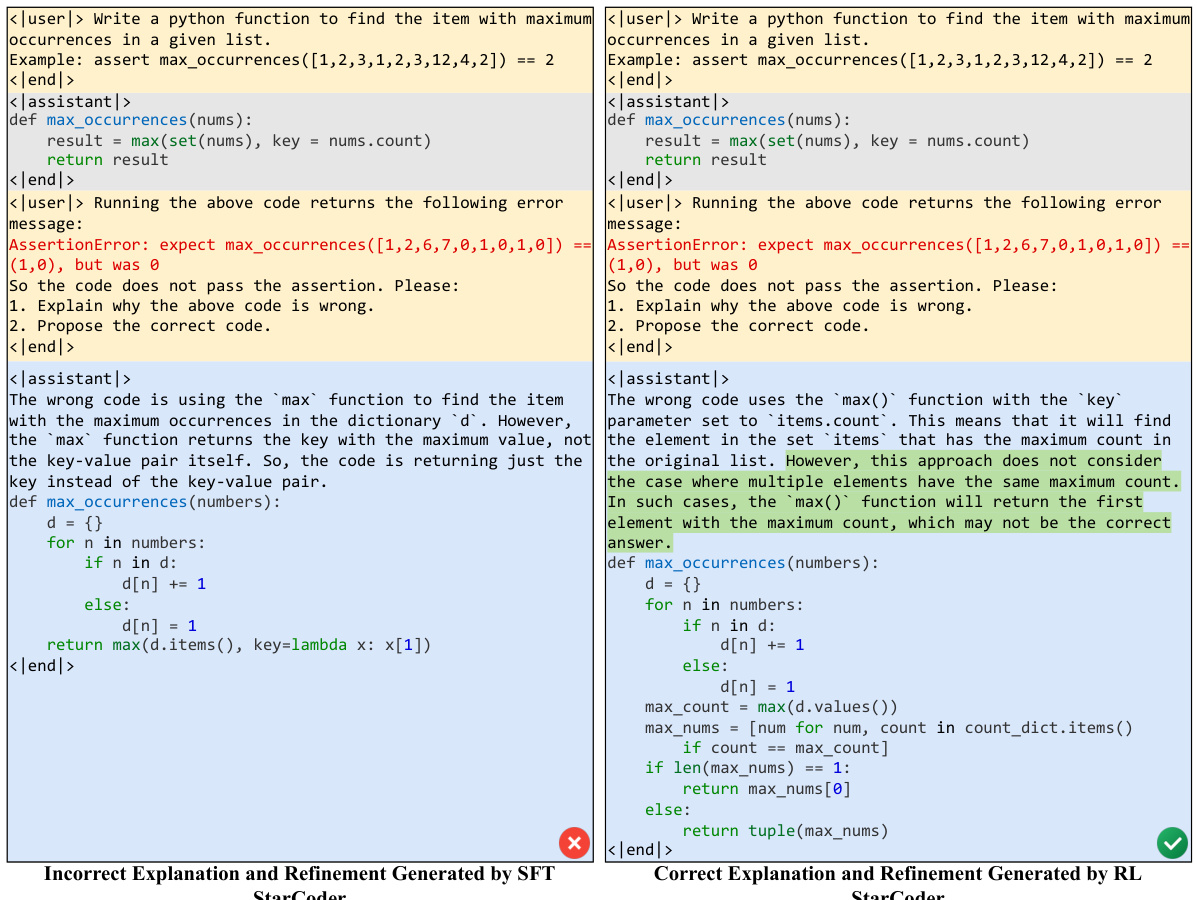
LLM Self-Debug#
LLM self-debugging is a crucial area of research focusing on enabling large language models (LLMs) to automatically identify and correct errors in their generated code. Current approaches often rely on prompting techniques, providing LLMs with examples or instructions to guide their debugging process. However, these methods have limitations, particularly with smaller, open-source LLMs, often failing to effectively identify and correct errors. A more effective approach involves training LLMs on a dataset of code explanations and refinements, allowing the model to learn from examples of successful self-debugging. This training process can significantly improve the LLM’s ability to analyze faulty code, understand the underlying error, and generate refined code solutions. Furthermore, reinforcement learning techniques can be used to enhance this training, improving the quality of the explanations and refinements. Overall, research in LLM self-debugging is exploring various techniques to enhance the capabilities of LLMs for code generation, addressing the challenging task of producing error-free code in complex programming scenarios. The ultimate goal is to build more robust and reliable LLMs capable of autonomous code generation and debugging.
LEDEX Framework#
The LEDEX framework presents a novel approach to enhancing the self-debugging capabilities of Large Language Models (LLMs) in code generation. Its core innovation lies in a two-pronged strategy: first, automatically collecting high-quality data for code explanation and refinement via iterative LLM querying and execution verification; second, utilizing this data to perform supervised fine-tuning (SFT) and reinforcement learning (RL), significantly boosting the model’s ability to diagnose, explain, and correct erroneous code. The framework’s automated data collection pipeline is highly scalable, overcoming limitations of prior methods that relied on manual annotation. The reward design in the RL stage is particularly noteworthy, incorporating metrics for both code explanation quality and unit test success, which leads to more insightful explanations and improved refinement accuracy. The framework’s model-agnostic nature is also key, demonstrated by successful application across diverse LLM backbones. Overall, LEDEX provides a significant advancement in LLM self-debugging, leading to more robust and reliable code generation.
Data Collection#
The effectiveness of any machine learning model hinges on the quality of its training data. The Data Collection phase is critical; poor data leads to poor models. A thoughtful approach is required, considering data sources, collection methods, and quality control. Automated methods can increase efficiency, but human oversight remains essential to ensure data accuracy and relevance. The process should prioritize data diversity to avoid bias and improve generalizability. Careful data cleaning and validation are crucial steps to ensure the dataset is ready for model training. Without a robust data collection strategy, even the most sophisticated model architecture will fail to perform optimally. The choice of data collection approach (e.g., manual, automated, crowdsourced) must be aligned with the available resources and research objectives. Ethical considerations are paramount to ensure data privacy and fairness.
Reward Design#
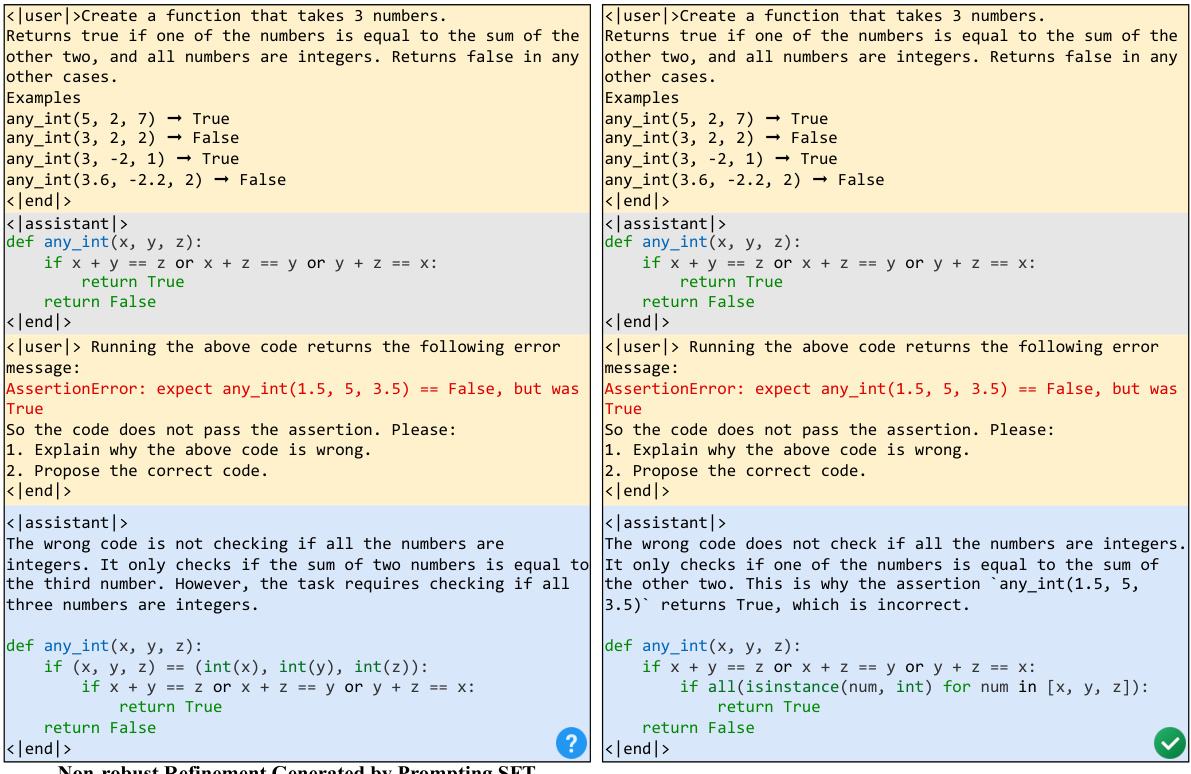
Reward design in reinforcement learning (RL) for code generation models is crucial for effective self-debugging. A well-designed reward function should balance several key factors: accuracy of code refinement (e.g., measured by unit test success and code similarity to ground truth), quality and relevance of code explanations (perhaps using metrics like BLEU score or semantic similarity), and efficiency/conciseness of the debugging process. The challenge lies in effectively weighting these potentially competing objectives. For example, rewarding only successful code refinement might lead to models that generate overly simplistic solutions. Conversely, focusing excessively on explanation quality could hinder optimization for correct code. Therefore, a sophisticated reward function often incorporates multiple components, potentially with different weighting schemes depending on the task and model capabilities. Iterative refinement adds complexity because the reward for later iterations may depend not just on the final result but also on the progress made throughout the refinement process. Finally, the need for data efficiency and scalability in training necessitates carefully chosen rewards that can effectively leverage a limited amount of high-quality training data. A robust reward design is critical for achieving significant improvements in the self-debugging and code explanation capabilities of LLMs.
Iterative Refinement#
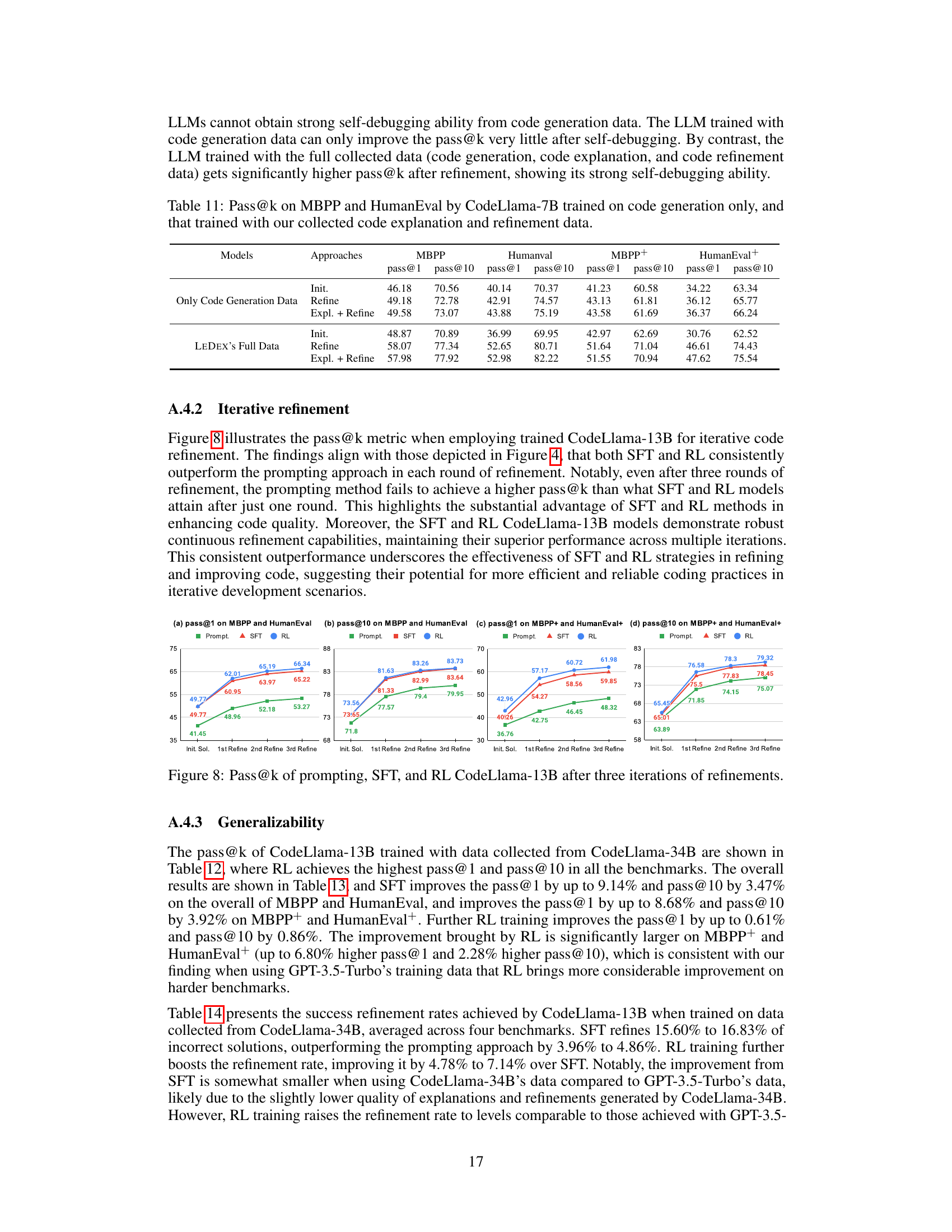
The concept of iterative refinement in large language models (LLMs) for code generation is crucial for improving accuracy and addressing the inherent challenges of producing correct code in a single attempt. Iterative refinement allows the LLM to learn from mistakes, using feedback from execution results or human evaluation to iteratively refine its generated code. This process mimics human debugging, where developers typically undergo multiple rounds of refinement. High-quality datasets are vital for effectively training LLMs for iterative refinement. These datasets should include not only successful refinement trajectories but also failed attempts, coupled with detailed explanations, which enable the model to understand its errors better. The effectiveness of iterative refinement hinges on the design of rewards in reinforcement learning (RL) training, which should carefully balance code correctness with the quality of explanations. Model-agnostic approaches that can be applied across different LLM architectures (such as StarCoder and CodeLlama) without requiring reliance on powerful teacher models are particularly valuable to enhance wider adoption and democratize the development of self-debugging capabilities in LLMs.
More visual insights#
More on figures
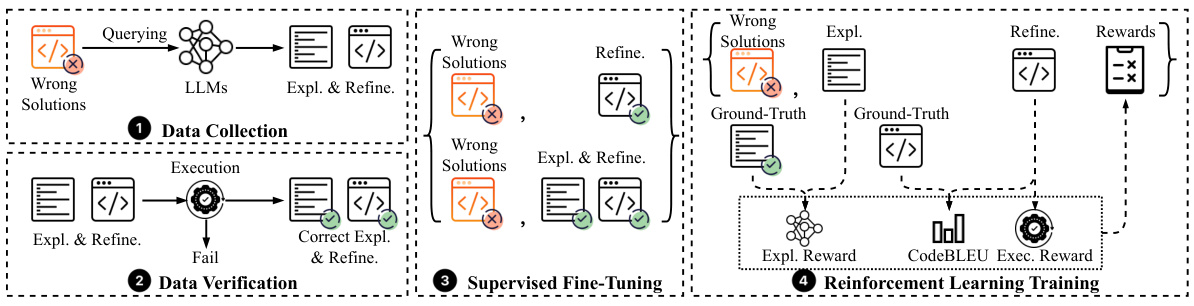
🔼 This figure shows the overall workflow of the LEDEX framework. It starts with data collection, where wrong solutions are generated by LLMs and then verified for correctness. The correct explanations and refinements are collected and used for supervised fine-tuning. Finally, reinforcement learning is used to further improve the quality of the generated code explanations and refinements.
read the caption
Figure 2: Overview of LEDEX.

🔼 This figure shows the distributions of various metrics used in the reward design of the reinforcement learning (RL) component in LEDEX. Specifically, it presents histograms visualizing the CodeBLEU scores (code similarity), unit test passing rates (execution success), sentiment similarity scores of code explanations (explanation quality), the final refinement code reward, and the explanation reward. Each histogram allows comparison of these scores for correct versus incorrect code explanations and refinements.
read the caption
Figure 3: The CodeBLEU scores, unit test cases passing rate, sentiment similarity of wrong code explanations, final refinement code reward, and the explanation reward of the training data.
🔼 This figure presents a flowchart illustrating the LEDEX framework’s four main stages: (1) Data Collection, where code explanations and refinements are generated and filtered; (2) Data Verification, where the quality of collected data is checked; (3) Supervised Fine-Tuning (SFT), where the model is trained on the verified dataset; and (4) Reinforcement Learning (RL) Training, where the model’s performance is further improved using reinforcement learning techniques. Each stage is depicted with corresponding actions and data flows, clarifying the process of collecting and using high-quality data to train LLMs for self-debugging.
read the caption
Figure 2: Overview of LEDEX.
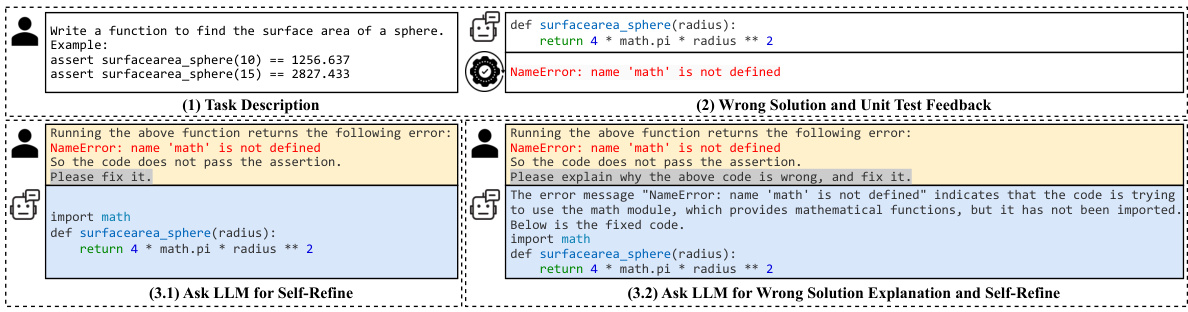
🔼 This figure shows a pipeline illustrating how an LLM generates code, and then self-debugs it. First, a user provides a programming task description to the LLM. The LLM generates a solution (code), which is then verified through execution against unit tests. If the code fails the tests, feedback is collected. The feedback informs a new query prompting the LLM to refine the code. This process may iterate until the LLM produces a correct solution or a maximum number of iterations is reached. Two prompt designs are highlighted. One is asking directly for code refinement; another is a chain-of-thought approach that first requests an explanation of the error in the wrong code, before asking for refinement.
read the caption
Figure 1: Pipeline of letting LLM generate code and self-debug.
🔼 This figure shows the pipeline of the LEDEX framework. It starts with data collection, where wrong solutions are generated and verified. The verified data is then used for supervised fine-tuning and reinforcement learning to train the LLMs. The trained LLMs generate code explanations and refinements. Finally, the model is evaluated on various benchmarks.
read the caption
Figure 2: Overview of LEDEX.

🔼 This figure shows the overall workflow of the LEDEX framework. It starts with data collection, where wrong code solutions are generated by LLMs, and then these are filtered and verified. High-quality data is then used for supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance LLMs’ self-debugging capabilities. The final output is LLMs that can better self-debug and explain code.
read the caption
Figure 2: Overview of LEDEX.
🔼 This figure shows the overview of the LEDEX framework, which consists of four main stages: 1. Data Collection and Verification; 2. Supervised Fine-tuning; 3. Reinforcement Learning Training; and 4. Data Validation. The framework uses an automated pipeline to collect high-quality code explanation and refinement data, then leverages supervised fine-tuning and reinforcement learning to enhance LLMs’ self-debugging capabilities, resulting in more accurate code refinements and insightful code explanations. The data verification step ensures high quality and reduces noise in the training data. The figure uses icons and arrows to show the data flow and connections between these stages.
read the caption
Figure 2: Overview of LEDEX.

🔼 This figure presents a visual overview of the LEDEX framework. It shows the different stages involved, starting with data collection and verification, followed by supervised fine-tuning and reinforcement learning. Each stage is represented by a block with a brief description of the process and the data flow between the stages. The figure provides a concise representation of the LEDEX pipeline, illustrating how the framework collects high-quality code explanation and refinement data and then uses this data to train LLMs for better self-debugging and code explanation.
read the caption
Figure 2: Overview of LEDEX.
🔼 This figure shows the overview of the LEDEX framework. It illustrates the four main steps involved in the process: 1. Data Collection, which involves querying LLMs and verifying responses; 2. Data Verification; 3. Supervised Fine-Tuning, which uses the collected data to train the model; and 4. Reinforcement Learning Training, which further enhances the model’s performance. The diagram visually depicts the flow of data and the different stages of training.
read the caption
Figure 2: Overview of LEDEX.
🔼 This figure presents a flowchart illustrating the LEDEX framework. The framework comprises four main stages: (1) Data Collection, where code explanation and refinement trajectories are generated and filtered via execution verification; (2) Data Verification, where the quality of collected data is validated; (3) Supervised Fine-Tuning (SFT), where the model is fine-tuned using the high-quality dataset; and (4) Reinforcement Learning (RL), where the model’s performance is further enhanced using reinforcement learning with a novel reward design. The flowchart visually depicts the data flow and processing steps within the LEDEX framework, providing a clear overview of the entire process.
read the caption
Figure 2: Overview of LEDEX.

🔼 This figure shows the overview of the LEDEX framework, which includes four main steps: (1) Data Collection: querying LLMs and verifying responses; (2) Data Verification: filtering data based on execution; (3) Supervised Fine-tuning: using high-quality data for training; and (4) Reinforcement Learning Training: further optimizing with novel reward mechanisms.
read the caption
Figure 2: Overview of LEDEX.

🔼 This figure presents a flowchart illustrating the LEDEX framework. It outlines the stages involved in data collection (querying LLMs for wrong solutions, filtering via execution verification), supervised fine-tuning (using the collected dataset), and reinforcement learning (using a novel reward design). Each stage is visually depicted, helping to explain the steps involved in the automated pipeline that improves LLMs’ self-debugging capabilities.
read the caption
Figure 2: Overview of LEDEX.
More on tables
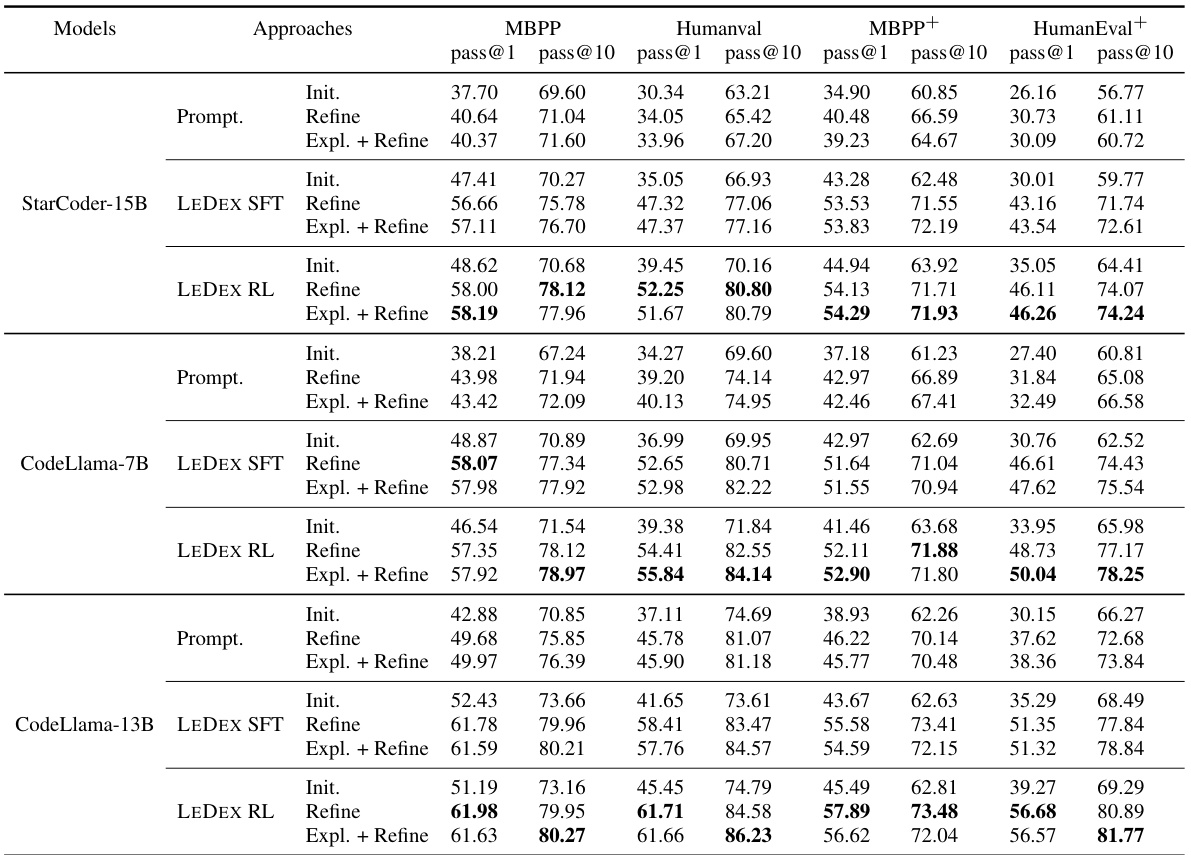
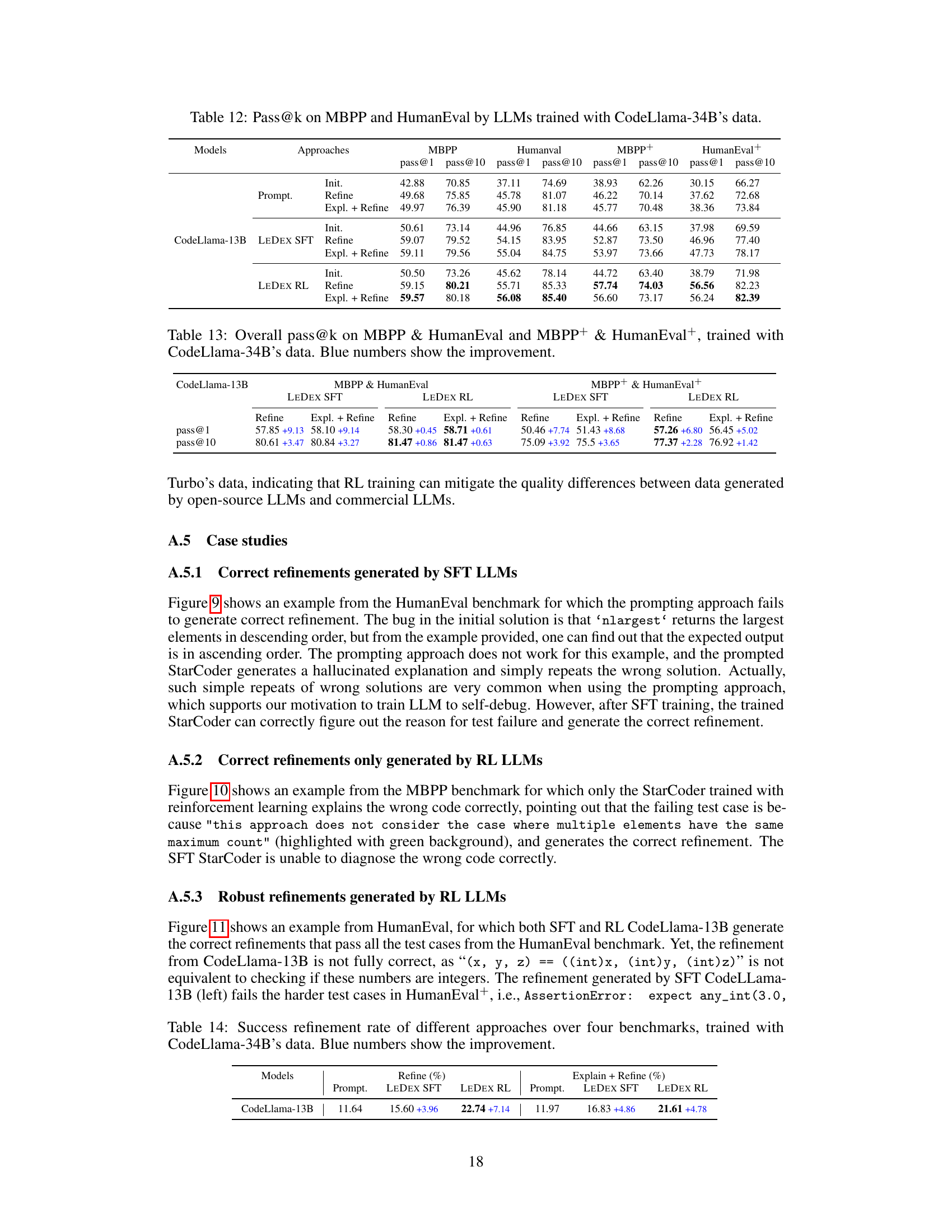
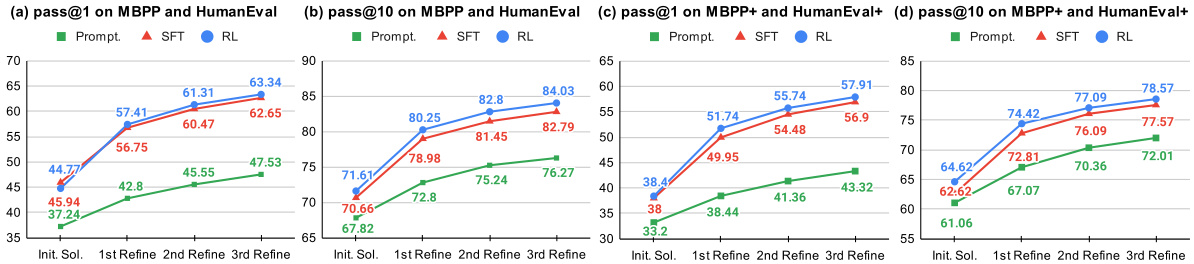
🔼 This table presents the performance of different LLMs (StarCoder-15B, CodeLlama-7B, and CodeLlama-13B) on four code generation benchmarks (MBPP, HumanEval, MBPP+, and HumanEval+). The results are shown for initial solutions, solutions refined directly, and solutions refined with explanations. The ‘pass@k’ metric indicates the percentage of tasks for which the model generates a correct solution within the top k attempts. The bolded numbers highlight the best performance for each LLM on each benchmark.
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.
🔼 This table presents the results of the Pass@k metric for both initial and refined solutions across four different benchmarks (MBPP, HumanEval, MBPP+, and HumanEval+). The table is broken down by model architecture (StarCoder-15B, CodeLlama-7B, CodeLlama-13B), approach (initial solution, refinement only, explanation and refinement), and metric (pass@1, pass@10). The best performance achieved by each model on each benchmark is highlighted in bold. This allows for a direct comparison of the effectiveness of different models and approaches at generating accurate code solutions, both initially and through iterative refinement.
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.

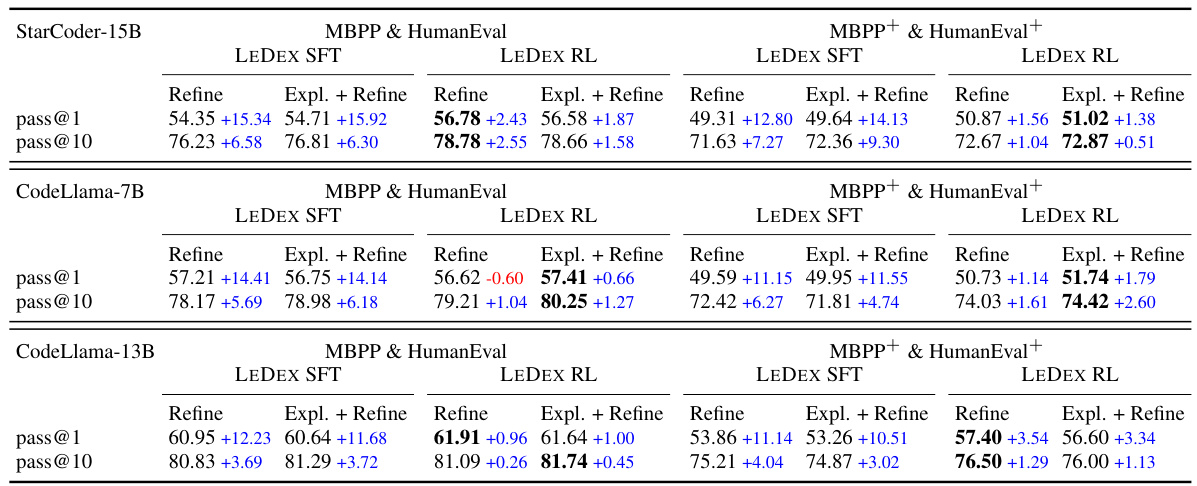
🔼 This table presents the success rates of code refinement across four benchmarks (MBPP, HumanEval, MBPP+, HumanEval+) for three different LLMs (StarCoder-15B, CodeLlama-7B, CodeLlama-13B). The success rate is calculated as the percentage of incorrect initial solutions that were successfully refined to a correct solution. Three approaches are compared: prompting, supervised fine-tuning (SFT) with LEDEX, and reinforcement learning (RL) with LEDEX. The blue numbers highlight the percentage point improvement gained by each technique over the prompting approach.
read the caption
Table 4: Success refinement rates over four benchmarks. Blue numbers show the improvement.

🔼 This table presents the performance of different LLMs on four code generation benchmarks (MBPP, HumanEval, MBPP+, HumanEval+) using three different approaches: initial solutions (without refinement), refinement using a single attempt, and refinement with explanation. The Pass@k metric shows the percentage of times the correct code was generated within the top k attempts. The table showcases the performance improvements achieved after employing the self-debugging method, specifically after applying supervised fine-tuning (SFT) and reinforcement learning (RL). The bolded values indicate the best performance achieved by each model architecture on each benchmark.
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.

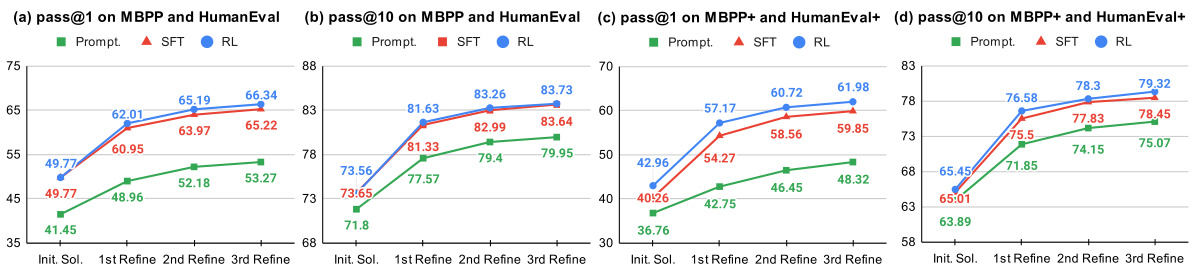
🔼 This table presents the overall performance of different LLMs across four benchmarks (MBPP, HumanEval, MBPP+, HumanEval+) after applying supervised fine-tuning (SFT) and reinforcement learning (RL). It shows the improvement in pass@1 and pass@10 metrics, comparing the results of using prompting alone, SFT, and RL. The color-coding (blue for improvement, red for deterioration) highlights the performance gains or losses at each stage of training.
read the caption
Table 3: Overall pass@k on MBPP & HumanEval and MBPP+ & HumanEval+. Blue or red numbers show the improvement or deterioration: SFT is compared to prompting, and RL is compared to SFT.
🔼 This table presents the performance of three different large language models (LLMs) on four code generation benchmarks. The models were tested with three different approaches: initial solution generation, refinement using only refinement prompts, and refinement using explanation and refinement prompts. The results are given in terms of Pass@1 and Pass@10 metrics, showing the percentage of times the model produced a correct solution within the top 1 and top 10 solutions generated, respectively. The table highlights the best performance achieved by each LLM on each benchmark using each method. The bolded numbers represent the best performance among all methods for each model and benchmark.
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.

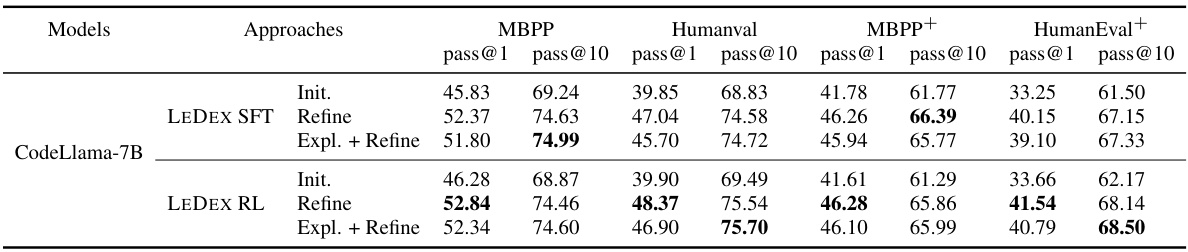
🔼 This table presents the overall performance of CodeLlama-7B model trained using self-bootstrapped data (data generated by the model itself). It compares the performance of the model using three different approaches: prompting, supervised fine-tuning (SFT), and reinforcement learning (RL). The performance is measured using the pass@1 and pass@10 metrics across four benchmarks: MBPP, HumanEval, MBPP+, and HumanEval+. Blue numbers indicate improvements over the previous method, while red numbers indicate performance degradation.
read the caption
Table 8: Overall pass@k on MBPP & HumanEval and MBPP+ & HumanEval+, trained with self-bootstrapped data. Blue or red numbers show the improvement or deterioration.

🔼 This table presents the average scores given by GPT-4 and human developers to the code explanations generated by different LLMs (StarCoder-15B, CodeLlama-7B, CodeLlama-13B, and GPT-3.5-Turbo) using three different approaches: prompting, supervised fine-tuning (SFT), and reinforcement learning (RL). The scores range from 1 to 5, where 1 indicates a completely incorrect or misleading explanation and 5 denotes a correct explanation that also provides helpful hints. The table allows for a comparison of explanation quality across different models and training methods.
read the caption
Table 9: Average scores of code explanations rated by GPT-4 and developers. SC for StarCoder and CL for CodeLlama. '-' refers to not applied.
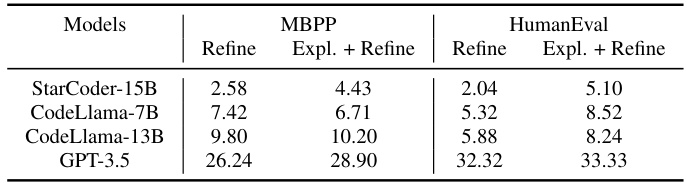
🔼 This table presents the success rate of self-refinement for four different LLMs (StarCoder-15B, CodeLlama-7B, CodeLlama-13B, and GPT-3.5) using two different prompting strategies: one where the LLM directly generates the refinement and another where it first explains why the code is incorrect before generating the refinement. The results are shown for two benchmarks, MBPP and HumanEval. The table highlights the limited self-refinement capabilities of open-source LLMs compared to GPT-3.5.
read the caption
Table 10: The success rate of self-refinement using greedy decoding.
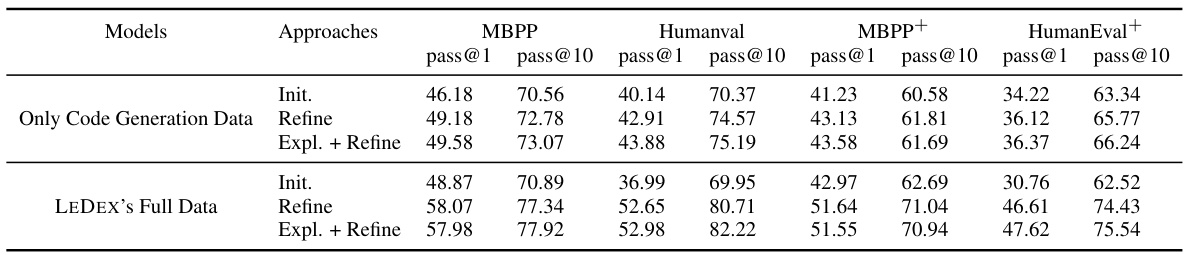
🔼 This table presents the performance of different LLMs (StarCoder-15B, CodeLlama-7B, and CodeLlama-13B) on four code generation benchmarks (MBPP, HumanEval, MBPP+, and HumanEval+). It shows the pass@1 and pass@10 scores for both the initial solutions generated by the LLMs and the refined solutions obtained after applying the LEDEX framework. The ‘best’ performance for each LLM on each benchmark is highlighted in bold. The table also shows results for different prompting approaches (‘Init.’, ‘Refine’, ‘Expl.+Refine’) and training methods (SFT, RL).
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.
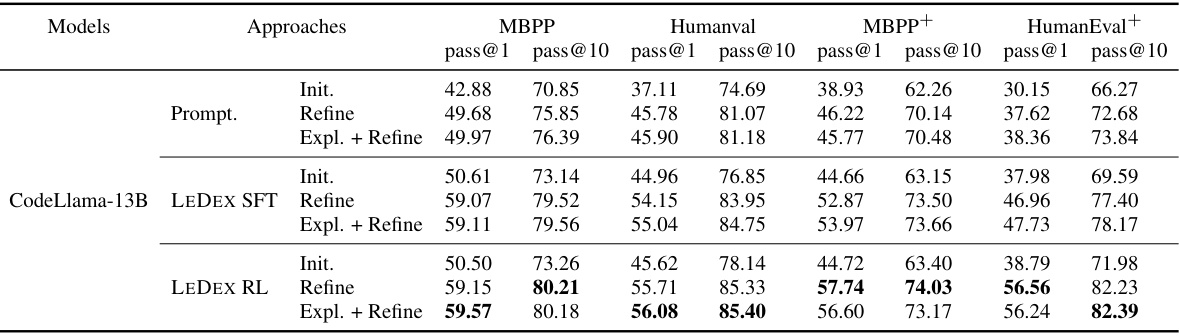
🔼 This table presents the performance of different LLMs (StarCoder-15B, CodeLlama-7B, and CodeLlama-13B) on four code generation benchmarks (MBPP, HumanEval, MBPP+, and HumanEval+). It shows the pass@1 and pass@10 scores for both the initial solutions generated by the LLMs and the refined solutions obtained after applying different self-debugging techniques (prompting, supervised fine-tuning (SFT), and reinforcement learning (RL)). The best performance for each LLM on each benchmark is highlighted in bold, allowing for easy comparison of the effectiveness of different approaches.
read the caption
Table 2: Pass@k of initial and refined solutions on four benchmarks. Each backbone's best performance on every benchmark is bolded.

🔼 This table presents the overall performance of different LLMs (StarCoder-15B, CodeLlama-7B, and CodeLlama-13B) across four benchmarks (MBPP, HumanEval, MBPP+, and HumanEval+) using three different approaches (Prompting, Supervised Fine-Tuning (SFT), and Reinforcement Learning (RL)). The pass@1 and pass@10 metrics are shown, indicating the percentage of tasks where the model generated a correct solution within the top 1 and top 10 attempts, respectively. Blue numbers highlight the improvements observed in each approach, comparing SFT against prompting and RL against SFT. The table helps in understanding the effectiveness of the LEDEX framework in improving LLMs’ code generation and refinement capabilities.
read the caption
Table 3: Overall pass@k on MBPP & HumanEval and MBPP+ & HumanEval+. Blue or red numbers show the improvement or deterioration: SFT is compared to prompting, and RL is compared to SFT.

🔼 This table shows the success rates of code refinement for three different LLMs (StarCoder-15B, CodeLlama-7B, and CodeLlama-13B) across four benchmark datasets. It compares three different approaches: prompting, supervised fine-tuning (SFT) with LEDEX, and reinforcement learning (RL) with LEDEX. The ‘Refine’ column shows results where the model is directly prompted to refine code, while the ‘Explain + Refine’ column shows results where the model first explains the bug and then refines the code. The blue numbers highlight the improvement in success rate achieved by SFT and RL compared to the baseline prompting method.
read the caption
Table 4: Success refinement rates over four benchmarks. Blue numbers show the improvement.

🔼 This table presents the average scores given by GPT-4 and human developers to code explanations generated by different LLMs. The scores range from 1 to 5, with higher scores indicating better correctness and helpfulness. The LLMs evaluated include StarCoder-15B, CodeLlama-7B, and CodeLlama-13B, across different training approaches (Prompting, SFT, and RL). The table shows that the LLMs trained with the proposed LEDEX framework generally receive higher scores than those trained only with prompting.
read the caption
Table 9: Average scores of code explanations rated by GPT-4 and developers. SC for StarCoder and CL for CodeLlama. '-' refers to not applied.
Full paper#