TL;DR#
Semi-supervised learning excels in classification but lags in regression due to challenges in directly applying existing techniques. This is mainly because regression models lack the confidence measures that are crucial for pseudo-labeling, a core component of many successful semi-supervised classification methods. Also, the low-density assumption, which plays a significant role in semi-supervised classification, is difficult to directly apply to regression.
RankUp tackles these challenges head-on. It uses an auxiliary ranking classifier to convert the regression task into a ranking problem, thus enabling integration with existing semi-supervised classification methods. Furthermore, Regression Distribution Alignment (RDA) refines pseudo-labels by aligning their distribution with the labeled data’s distribution, which further enhances performance. RankUp achieves state-of-the-art results across a wide range of regression tasks, showcasing the effectiveness of its approach and opening new directions for semi-supervised regression research.
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between semi-supervised learning in classification and regression tasks. It introduces a novel and effective method, RankUp, which is easily adaptable and achieves state-of-the-art results across various datasets. This opens new avenues for research in semi-supervised regression and provides valuable insights for improving the performance of regression models with limited labeled data.
Visual Insights#

🔼 This figure illustrates how the FixMatch algorithm is applied to the Auxiliary Ranking Classifier (ARC) for semi-supervised regression. The ARC transforms the regression task (age prediction) into a ranking task by comparing pairs of images. Unlabeled image pairs undergo both weak and strong augmentations. Each augmented pair is fed into the neural network, which outputs a ranking score. FixMatch uses a confidence threshold on this ranking prediction to generate pseudo-labels for the unlabeled data, which are then used to train the model. This process iteratively refines the model’s ability to perform accurate age prediction. The example uses the UTKFace dataset.
read the caption
Figure 1: Illustration of using FixMatch on the Auxiliary Ranking Classifier (ARC). This diagram uses the age estimation task as an example, where the goal is to predict the age of a person in an image. The auxiliary ranking classifier transforms this task into a ranking problem by comparing two images to determine which person is older. (Image sourced from the UTKFace dataset [37]).
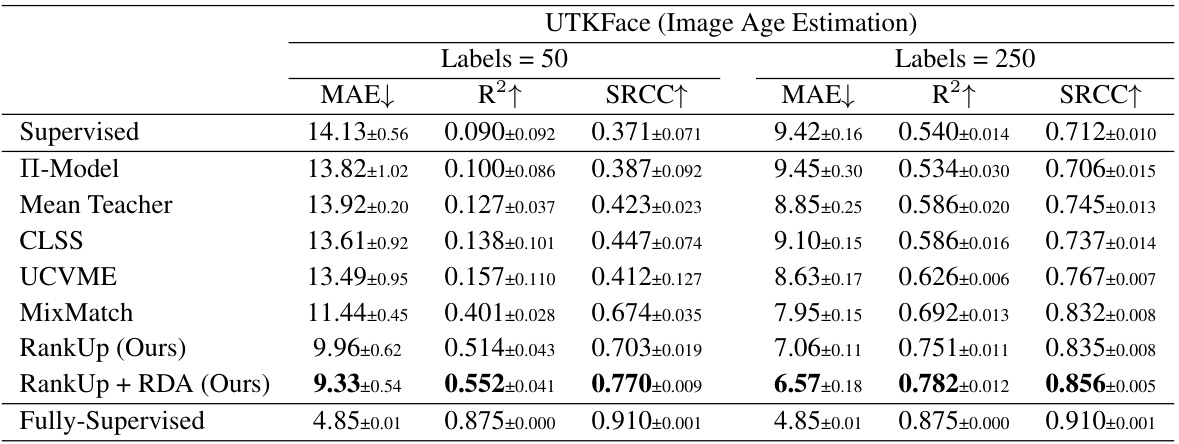
🔼 This table compares the performance of RankUp (with and without RDA) against other semi-supervised regression methods on the UTKFace dataset. Two experimental settings are used: 50 and 250 labeled images, with the rest treated as unlabeled. The table shows the MAE, R2, and SRCC scores for each method, allowing for a comparison of performance across different methods and label amounts. The fully supervised result using only labeled data and the fully supervised result using all data are also included as baselines.
read the caption
Table 1: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset, evaluated under two settings: 50 and 250 labeled samples, with the remaining images treated as unlabeled. The original UTKFace dataset comprises 18,964 training images.
In-depth insights#
RankUp’s Design#
RankUp’s design cleverly tackles the challenge of adapting semi-supervised learning to regression tasks. Its core innovation lies in introducing an auxiliary ranking classifier (ARC) that transforms the regression problem into a ranking problem. This is ingenious because existing semi-supervised techniques, largely designed for classification, can now be leveraged. The ARC operates concurrently with the primary regression model, creating a multi-task learning setup. The integration of FixMatch enhances the ARC’s performance by effectively utilizing unlabeled data through a confidence threshold mechanism. Furthermore, RankUp incorporates Regression Distribution Alignment (RDA) to refine pseudo-labels, improving the quality of training data. This dual-pronged approach, combining ARC and RDA, is elegant in its simplicity while achieving state-of-the-art results. The overall design is modular, allowing for easy experimentation with different semi-supervised classification methods and flexibility in tailoring the approach to specific regression tasks. The open-sourcing of code ensures reproducibility and fosters further research in semi-supervised regression.
RDA’s Alignment#
Regression Distribution Alignment (RDA) is a crucial technique in RankUp for refining pseudo-labels generated from unlabeled data. RDA’s core function is to align the distribution of these pseudo-labels with the distribution of the labeled data, assuming a similarity between the two. This alignment process is achieved through a three-step procedure: extracting the labeled data distribution, generating the pseudo-label distribution, and then aligning the two distributions by replacing pseudo-label values with their corresponding values from the labeled data. The effectiveness of RDA hinges on two assumptions: similar distributions between labeled and unlabeled data, and reasonably accurate ranking of pseudo-labels. While highly effective, RDA can be computationally expensive, necessitating techniques like creating a pseudo-label table and applying RDA less frequently to improve efficiency. Despite its limitations in cases with few distinct label values, RDA significantly enhances RankUp’s performance and bridges the gap between semi-supervised classification and regression methods.
ARC’s Mechanism#
The core of RankUp lies in its Auxiliary Ranking Classifier (ARC), a mechanism designed to transform the regression problem into a ranking task. Instead of directly predicting a continuous value, ARC focuses on learning the relative ordering between data points. This is cleverly achieved by creating pairs of samples and training a model to predict which sample has a higher value. Existing semi-supervised classification techniques can then be seamlessly integrated with ARC, since the ranking problem is essentially a binary classification task. This ingenious approach allows RankUp to leverage the strengths of established semi-supervised classification methods which are typically unavailable for regression tasks, specifically those employing confidence-based pseudo-labeling. The use of ARC is critical for enabling effective pseudo-label refinement via the Regression Distribution Alignment (RDA) component.
Method’s Limitations#
The core limitation of the proposed RankUp framework centers on its reliance on two key assumptions: the similarity of labeled and unlabeled data distributions, and the accuracy of pseudo-label rankings. The effectiveness of the Regression Distribution Alignment (RDA) component hinges directly on these assumptions. If the distributions significantly differ, or pseudo-label rankings are inaccurate, RDA’s ability to refine pseudo-labels diminishes, impacting the overall performance. This limitation is particularly evident in datasets with few distinct label values, as seen in the Yelp Review dataset, where RDA actually decreases performance. Another limitation is the increased computational cost associated with RDA, especially with larger datasets. The proposed strategies for mitigating this, like applying RDA only every T steps, represent a tradeoff between computational efficiency and performance optimization. Further research should investigate techniques to relax these assumptions and improve the computational efficiency of RDA, potentially through more robust methods for estimating data distributions or generating more reliable pseudo-labels.
Future Research#
Future research directions stemming from this work on semi-supervised regression could explore several promising avenues. Extending RankUp to handle multi-modal data would significantly broaden its applicability. Investigating alternative ranking loss functions beyond the pairwise ranking loss used in RankNet could potentially lead to performance improvements. A thorough investigation into the theoretical underpinnings of RDA, particularly its assumptions and limitations, is crucial. Developing more robust methods for handling noisy pseudo-labels is also important. Finally, exploring the integration of RankUp with other semi-supervised learning paradigms such as self-training or consistency regularization could yield powerful hybrid approaches. Addressing these points will advance the field of semi-supervised regression and enhance the practical applicability of RankUp.
More visual insights#
More on figures

🔼 This figure illustrates the process of Regression Distribution Alignment (RDA). It shows how the distribution of pseudo-labels generated by a model is aligned with the distribution of the labeled data. The alignment process involves three steps: (1) extracting the labeled data distribution, (2) generating the pseudo-label distribution, and (3) aligning the pseudo-label distribution with the labeled data distribution. The figure uses a histogram to represent the data distributions, where the x-axis represents the sample indices and the y-axis represents the label values. The figure effectively shows how the RDA process refines the pseudo-labels by aligning their distribution with the labeled data distribution.
read the caption
Figure 2: Illustration of RDA: This example includes three labeled data pairs {(xi, yi)}i=0 and five unlabeled data points with corresponding pseudo-labels {(ui, ŷi)}i=0. Each data pair is represented by a single bar in the graph. The x-axis indicates the sample indices, while the y-axis represents their corresponding regression label values. The orange bars demonstrate the process of obtaining the labeled data distribution, the blue bars illustrate how the pseudo-label distribution is formed, and the yellow bars show the aligned pseudo-labels after applying RDA.

🔼 This figure compares the t-SNE visualizations of feature representations from three different semi-supervised regression methods: a supervised model, MixMatch, and RankUp (without RDA). Each visualization shows a scatter plot where each point represents a data point in the feature space, colored by its corresponding regression label (age in this case). The visualizations demonstrate the effectiveness of RankUp in creating a better separation between data points of different ages compared to the other methods. This separation is better aligned with the low-density assumption in semi-supervised learning, highlighting one of the underlying reasons for RankUp’s strong performance.
read the caption
Figure 3: Comparison of t-SNE visualizations of feature representations for different semi-supervised regression methods on evaluation data. The supervised model is displayed on the left, MixMatch is in the center, and RankUp (without RDA) is shown on the right.
More on tables
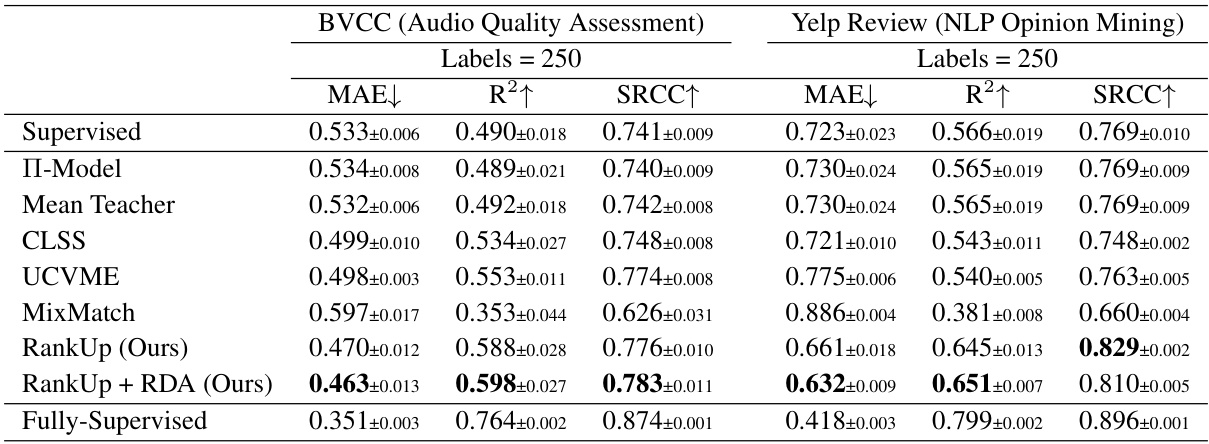
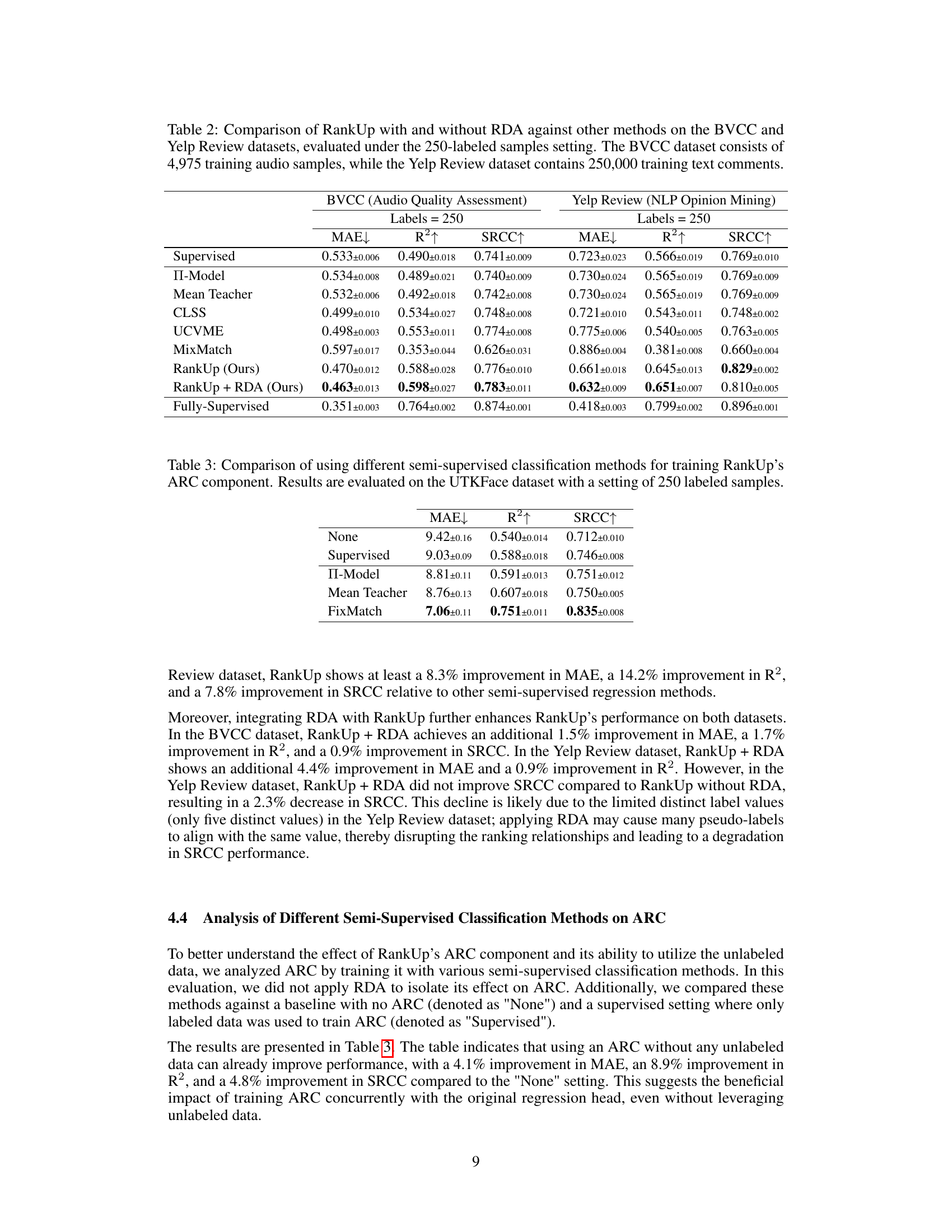
🔼 This table presents a comparison of RankUp with and without RDA against other semi-supervised regression methods on two datasets: BVCC (Audio Quality Assessment) and Yelp Review (NLP Opinion Mining). Both datasets use 250 labeled samples for training. The table shows the MAE, R-squared (R2), and Spearman Rank Correlation Coefficient (SRCC) for each method. This allows for a comparison of the performance across different methods and the impact of incorporating RDA into the RankUp model.
read the caption
Table 2: Comparison of RankUp with and without RDA against other methods on the BVCC and Yelp Review datasets, evaluated under the 250-labeled samples setting. The BVCC dataset consists of 4,975 training audio samples, while the Yelp Review dataset contains 250,000 training text comments.

🔼 This table compares the performance of RankUp’s ARC component when trained using different semi-supervised classification methods against a baseline with no ARC and a supervised setting. It shows how using semi-supervised learning methods to train the ARC component improves performance over supervised-only training. The results are evaluated using the Mean Absolute Error (MAE), R-squared (R2), and Spearman Rank Correlation Coefficient (SRCC) metrics.
read the caption
Table 3: Comparison of using different semi-supervised classification methods for training RankUp's ARC component. Results are evaluated on the UTKFace dataset with a setting of 250 labeled samples.

🔼 This table presents the results of a comparison of RankUp with and without RDA against other semi-supervised regression methods on the UTKFace dataset using 2000 labeled samples. The table shows the mean absolute error (MAE), R-squared (R2), and Spearman rank correlation coefficient (SRCC) for each method. Lower MAE is better, while higher R2 and SRCC are better. The results demonstrate that RankUp consistently outperforms existing semi-supervised regression methods, and the addition of RDA provides further improvements.
read the caption
Table 4: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset with 2000 labeled samples.
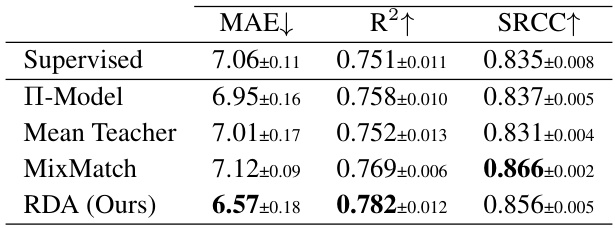
🔼 This table compares different semi-supervised regression methods on the performance of training RankUp’s regression output using 250 labeled samples from the UTKFace dataset. The methods compared include Supervised (only labeled data), Π-Model, Mean Teacher, MixMatch, and RDA (Regression Distribution Alignment). The results are presented in terms of MAE (Mean Absolute Error), R2 (Coefficient of Determination), and SRCC (Spearman Rank Correlation Coefficient). The table shows how different semi-supervised methods affect the regression output part of the RankUp model, illustrating the potential benefits of using different semi-supervised learning approaches in enhancing the performance of regression tasks.
read the caption
Table 5: Comparison of using different semi-supervised regression methods for training RankUp's regression output. Results are evaluated on UTKFace dataset with a setting of 250 labeled samples.

🔼 This table compares the performance of RankUp, with and without RDA, against other semi-supervised regression methods on the UTKFace dataset for image age estimation. Two different label settings are used: 50 and 250 labeled images, with the rest treated as unlabeled data. The results are evaluated using MAE, R2, and SRCC metrics. It shows the effectiveness of RankUp, especially when labeled data is scarce, and the additional boost provided by integrating RDA.
read the caption
Table 1: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset, evaluated under two settings: 50 and 250 labeled samples, with the remaining images treated as unlabeled. The original UTKFace dataset comprises 18,964 training images.
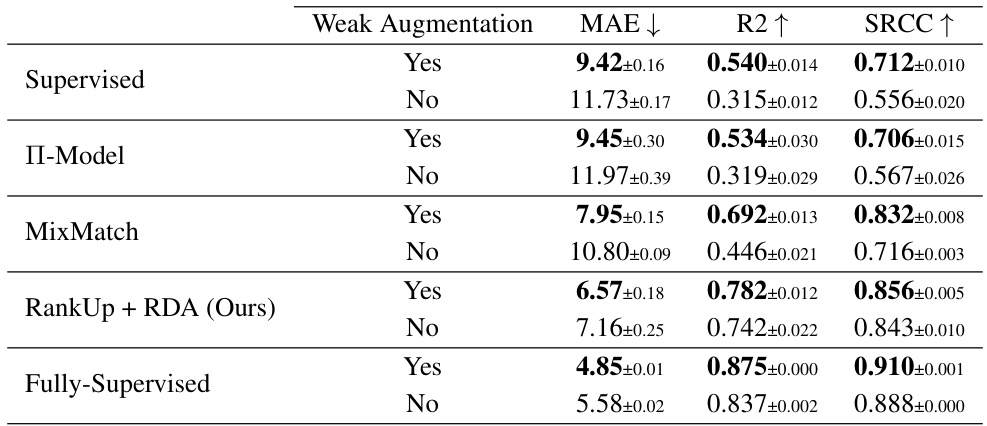
🔼 This table compares the performance of RankUp (with and without RDA) against other semi-supervised regression methods on the UTKFace dataset. Two experimental settings are used: one with 50 labeled images and another with 250 labeled images. The remaining images are treated as unlabeled data. The table shows the Mean Absolute Error (MAE), the R-squared (R2) score, and the Spearman Rank Correlation Coefficient (SRCC) for each method in both settings. Lower MAE is better, higher R2 and SRCC are better.
read the caption
Table 1: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset, evaluated under two settings: 50 and 250 labeled samples, with the remaining images treated as unlabeled. The original UTKFace dataset comprises 18,964 training images.

🔼 This table compares the performance of RankUp, with and without RDA, against other semi-supervised regression methods on the UTKFace dataset. Two experimental settings are used: one with 50 labeled images and another with 250. The table shows the Mean Absolute Error (MAE), R-squared (R2), and Spearman Rank Correlation Coefficient (SRCC) for each method in both settings. The fully supervised results (using all data) and a supervised baseline (using only the labeled data) are also provided for comparison.
read the caption
Table 1: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset, evaluated under two settings: 50 and 250 labeled samples, with the remaining images treated as unlabeled. The original UTKFace dataset comprises 18,964 training images.

🔼 This table compares the performance of RankUp (with and without RDA) against other semi-supervised regression methods on the UTKFace dataset. The comparison is done under two different settings: one with 50 labeled samples and another with 250 labeled samples. The remaining images in each setting are used as unlabeled data. The table shows the MAE, R-squared (R2), and Spearman Rank Correlation Coefficient (SRCC) for each method in both settings, providing a quantitative evaluation of the effectiveness of RankUp compared to existing methods. A fully supervised setting (using all labeled data) is also included as a benchmark.
read the caption
Table 1: Comparison of RankUp with and without RDA against other methods on the UTKFace dataset, evaluated under two settings: 50 and 250 labeled samples, with the remaining images treated as unlabeled. The original UTKFace dataset comprises 18,964 training images.
Full paper#