↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Facial stylization is challenging due to the difficulty of obtaining high-quality stylized image datasets for various artistic styles and the need to balance style transfer with the preservation of facial identity. Many existing methods struggle with this balance, often losing important facial details or failing to fully capture the nuances of the style.
The proposed method, ACFun, addresses these issues by using a two-module approach that disentangles abstract and concrete features of style. An Abstract Fusion Module (AFun) learns abstract aspects like composition and atmosphere while a Concrete Fusion Module (CFun) focuses on concrete visual elements such as strokes and colors. A Face and Style Imagery Alignment Loss helps in aligning style and face information. Finally, stylized images are generated directly from noise, ensuring the preservation of facial features while adding artistic flair. Experiments demonstrate that ACFun significantly outperforms previous methods, generating visually pleasing results with high artistic quality and facial fidelity.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to facial stylization that overcomes limitations of existing methods. Its focus on separating abstract and concrete features offers a new perspective, potentially influencing future work in image generation and style transfer, especially for applications requiring fine-grained control over both artistic style and the preservation of facial identity. The method’s efficiency (training in minutes), reliance on a single style image, and high-quality results make it practical and impactful for researchers.
Visual Insights#

This figure shows several examples of ideal facial stylization results. The goal is to faithfully maintain facial features while transforming the face to match the style of a given artistic image. The figure highlights the challenge of balancing the preservation of facial recognition with the artistic transformation of style.

This table presents the results of a user study comparing the proposed ACFun method with several state-of-the-art image style transfer methods. Three aspects were evaluated: style consistency, facial consistency, and overall preference. The results show that ACFun achieves high scores in facial consistency and overall preference, indicating that it effectively retains facial features while successfully applying the chosen style.
In-depth insights#
Abstract Fusion#
Abstract fusion, in the context of image stylization, presents a powerful technique for enhancing the quality and realism of stylized images. By separately processing abstract and concrete features, this approach addresses the limitations of traditional methods. Abstract features, such as overall style, mood, and atmosphere, are typically captured via high-level semantic representations. Concrete features, like color palettes, brushstrokes, and textures, are handled through more detailed, low-level analysis. The fusion of these distinct elements allows the system to generate stylized results which faithfully capture the essence of the desired artistic style while preserving crucial details of the original image. This two-pronged approach overcomes the challenge of balancing style transfer with the preservation of facial features in facial stylization. The result is a more nuanced and compelling image that is both aesthetically pleasing and preserves original content. The efficacy of abstract fusion depends heavily on the sophistication of the feature extraction and fusion algorithms, highlighting the importance of robust machine learning models in achieving high-quality results.
Dual Fusion Modules#
The concept of “Dual Fusion Modules” in a research paper likely refers to a model architecture employing two distinct fusion mechanisms. This dual approach likely addresses limitations of single-fusion methods by combining complementary strengths for enhanced performance. One module might focus on low-level features like texture and color, while the other emphasizes high-level semantic information such as shape and composition. This division of labor is key—allowing each module to specialize and avoid the limitations of a single approach trying to handle both aspects simultaneously. The successful integration of these modules would lead to more robust and comprehensive results, likely achieving a better balance between preserving content fidelity and effectively implementing the desired stylistic transformations. The modules may operate in parallel or sequentially, perhaps exchanging intermediate representations. The effectiveness of this architecture will be judged by its ability to generate stylistically consistent and visually appealing outputs, while retaining crucial content information.
Alignment Loss#
Alignment loss, in the context of facial stylization, is a crucial technique for harmonizing the abstract style from a style image and the concrete facial features of a target image. Its core function is to bridge the gap between the abstract representation of the style (e.g., color palettes, brushstrokes) and the inherent structural details of a face, ensuring that the stylized output retains facial recognizability. A poorly designed alignment loss could lead to a stylized image where facial features are distorted or lost entirely, thereby diminishing the image’s overall quality. The effectiveness of an alignment loss depends critically on the chosen loss function and the way style and facial features are represented in the latent space. Successful alignment loss strategies often leverage techniques such as perceptual losses, which focus on higher-level semantic similarities between images, and adversarial losses, which encourage the stylized image to be indistinguishable from a realistically stylized version. The choice of the latent space, whether pixel-level or feature-level, also greatly impacts the efficacy of alignment. A robust alignment loss mechanism is therefore essential for achieving high-quality facial stylization results that balance artistic expression with accurate facial feature preservation. Optimizing the alignment loss is also important during the model training to maintain a balance between style transfer and identity preservation.
Style Transfer#
Style transfer, a core topic in image processing, aims to imbuing the content of one image with the artistic style of another. Early methods focused on low-level feature manipulation, transferring textures and colors but often failing to capture the essence of artistic expression. Deep learning revolutionized style transfer, enabling higher-level semantic understanding. However, challenges remain, particularly in preserving fine details and facial features in stylized portraits. Recent advancements using diffusion models offer promising results, but often require extensive datasets which can limit applicability. The ideal approach would seamlessly combine abstract stylistic elements with concrete visual features, addressing the need for both artistic expression and image fidelity.
Future Directions#
Future research could explore several promising avenues. Improving the model’s ability to handle diverse facial features and highly varied artistic styles is crucial. This involves expanding the training datasets to include more representative samples and potentially investigating more advanced architectural designs. Another key direction is to enhance the model’s control over the stylization process, enabling users to fine-tune the level of artistic transformation applied to specific facial features. This could involve developing interactive tools or incorporating user-specified constraints. Furthermore, exploring the integration of ACFun with other image generation or editing techniques would expand its capabilities significantly. This might involve seamless integration into existing pipelines for face swapping or animation. Finally, addressing potential limitations such as style leakage and bias in the generated images, through more robust training techniques and careful dataset curation, is vital for producing fairer and more reliable results.
More visual insights#
More on figures
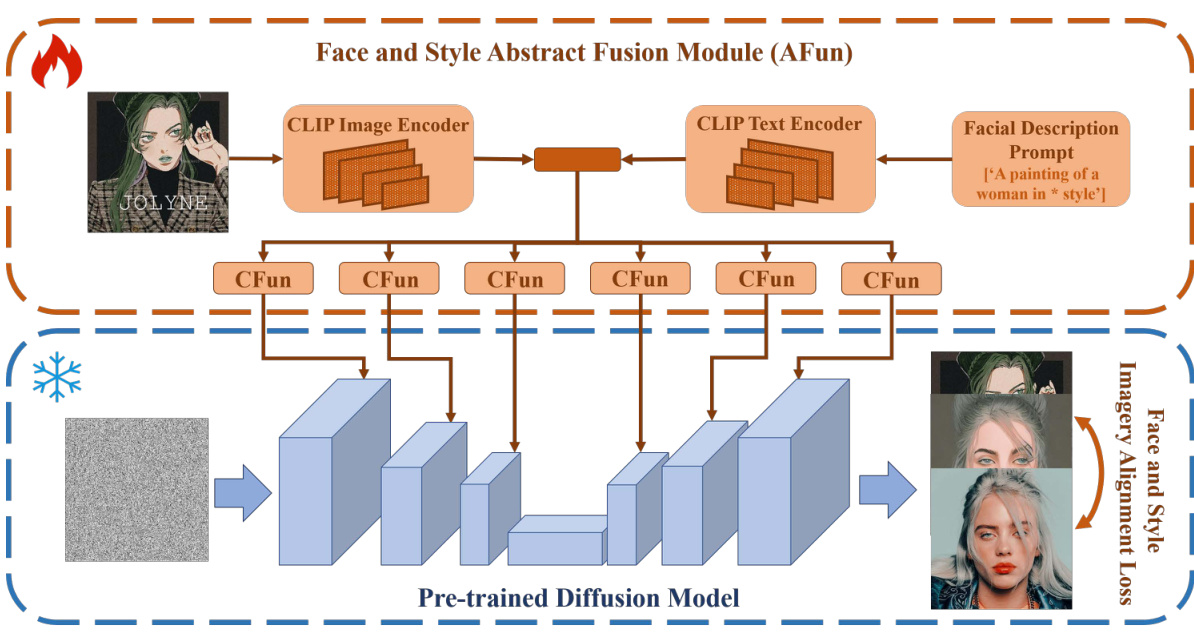
This figure shows the overall architecture of the ACFun model. It’s composed of two main modules: the Abstract Fusion Module (AFun) and the Concrete Fusion Module (CFun). AFun extracts abstract features from the style image and facial description prompt (text), which are then used to guide the generation process within a pre-trained diffusion model. CFun extracts concrete features, refining the output and ensuring detail preservation. The entire process is optimized using a Face and Style Imagery Alignment Loss to ensure that the generated image faithfully represents both the style and the facial identity.

The left part of the figure shows the detailed architecture of the Concrete Fusion Module (CFun), illustrating how trainable parameters are inserted into the ResBlock to learn concrete visual features while avoiding drastic semantic changes. The right part depicts the proposed imagery latent space, which integrates abstract and concrete features from both style and face images. It highlights the process of mapping original images from the VQ space to this integrated latent space using the abstract features (ea).

This figure shows a comparison of facial stylization results using the proposed ACFun method and several state-of-the-art methods. Each row presents a style image, a face image, and the results from the ACFun model, InstantStyle, SDXL, DreamStyler, Inst, AesPA, and StyTr2. The comparison highlights that the ACFun model generates results with stronger style transfer while better preserving facial features and integrating the style naturally.

This figure compares the results of the proposed ACFun model and the InstantStyle model on facial stylization with text prompts. The top row shows the style image and five different face images used as input. The two rows below show the results generated by ACFun and InstantStyle respectively, for each combination of style and face image, demonstrating the effect of text prompts on style transfer. ACFun produces results that closely match the given style while preserving facial features, whereas InstantStyle’s results show more variation and less accurate style transfer. The caption highlights the ability of ACFun to generate images following text prompts, something InstantStyle struggles with.

This figure shows the results of an ablation study performed to evaluate the impact of abstract and concrete features on the facial stylization process. Four different versions of the model are compared: 1. With All Feature: The complete model, incorporating both abstract and concrete features. 2. Abstract Feature: Only the abstract features are used in the process. 3. Concrete Feature in Encoder: Only concrete features are used within the encoder part of the model. 4. Concrete Feature in Decoder: Only concrete features are used in the decoder part of the model. The image pairs demonstrate that while abstract features alone generate a stylized yet blurry image, incorporating concrete features (either in the encoder or decoder, or both) significantly enhances the detail and realism of the stylized faces, especially the features related to facial expressions and identity.

This figure shows an ablation study comparing the results of using a single pseudo-word prompt versus a facial description text prompt for facial stylization, along with a hyperparameter analysis of the imagery alignment loss. The results demonstrate the impact of these choices on the quality and stability of the generated stylized images. The hyperparameter analysis shows how different settings for the imagery alignment loss affect the balance between style and facial features in the final output.

This figure shows an ablation study comparing the results of using single pseudo-word prompts versus detailed facial description text prompts in the proposed ACFun model. It also illustrates the effect of varying hyperparameters (γ and β) in the Imagery Alignment Loss on the generated facial stylization results. The results demonstrate that more descriptive prompts and carefully tuned hyperparameters lead to higher quality and more consistent stylization results.

This figure shows the results of ablative studies on different prompt methods and hyperparameters used in the ACFun model. The top row demonstrates the impact of using a single pseudo-word prompt versus a facial description text prompt for style transfer. The bottom row illustrates how different hyperparameter settings (γ and β) in the Imagery Alignment Loss affect the final stylized image. Different ratios of β and γ values are shown, showcasing the effect of balancing style information with maintaining facial features. It shows the trade off between retaining facial features and applying the style.

This figure shows several examples of ideal facial stylization results. The goal is to successfully transfer the style from a style image to a face image while preserving the key facial features and making the result look both artistic and realistic. The examples highlight the challenge of balancing style transfer with faithful representation of the face.
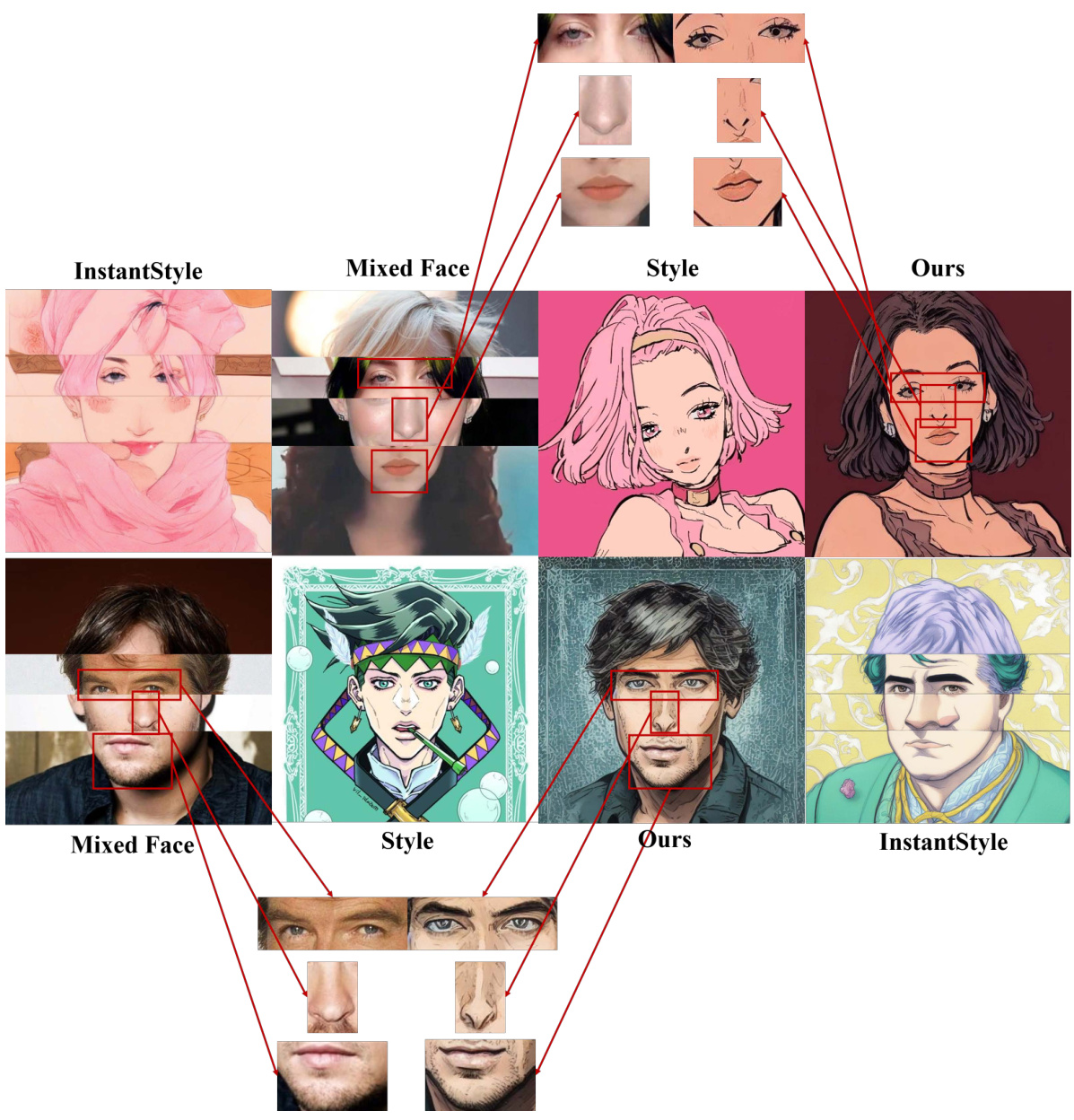
This figure demonstrates the results of applying the proposed ACFun method to facial images that have been spliced together from different faces. The goal is to show the ability of the model to handle unusual inputs and produce coherent stylized results. The figure shows several examples of spliced faces, the style images used, the results generated by the ACFun method, and comparisons to results obtained from the InstantStyle method. The red boxes highlight the spliced regions in the mixed face images. The comparison with InstantStyle results highlight ACFun’s ability to generate a more complete and coherent stylized result even with complex, unusual input images.

This figure shows a comparison of facial stylization results between the proposed ACFun method and other state-of-the-art methods. Multiple pairs of style images and face images are presented, along with their corresponding stylization results from ACFun and other methods. The caption highlights that ACFun produces results with stronger styles while maintaining facial fidelity and natural integration with the target style.

This figure shows a comparison of facial stylization results between the proposed ACFun method and several other state-of-the-art methods. Multiple rows present different style images paired with corresponding face images. For each pair, the results generated by the ACFun method and other methods are shown. The caption highlights the ACFun method’s ability to generate results with stronger styles while preserving facial features and blending naturally with the target style.
Full paper#