↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Many real-world applications rely on tabular data, but data scarcity and class imbalance hinder machine learning model performance. Traditional methods like SMOTE struggle with complex relationships within data. Large Language Models (LLMs) offer potential, but require extensive fine-tuning, risking overfitting. This increases the risk of poor performance.
The paper introduces EPIC, a novel prompting method. EPIC leverages LLMs’ in-context learning abilities, using balanced data samples and unique variable mapping in the prompts. This guides the LLMs to accurately generate synthetic data for all classes, handling imbalance effectively. Evaluation on real-world datasets demonstrated state-of-the-art classification performance and significantly improved generation efficiency. The method is model-agnostic, easy to implement, and practical for various applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in tabular data synthesis and imbalanced learning. It presents EPIC, a novel prompting method for LLMs, significantly improving synthetic data generation efficiency and ML classification performance, particularly for imbalanced datasets. This opens new avenues for leveraging LLMs in handling real-world data challenges and offers valuable prompt engineering guidelines for the research community.
Visual Insights#
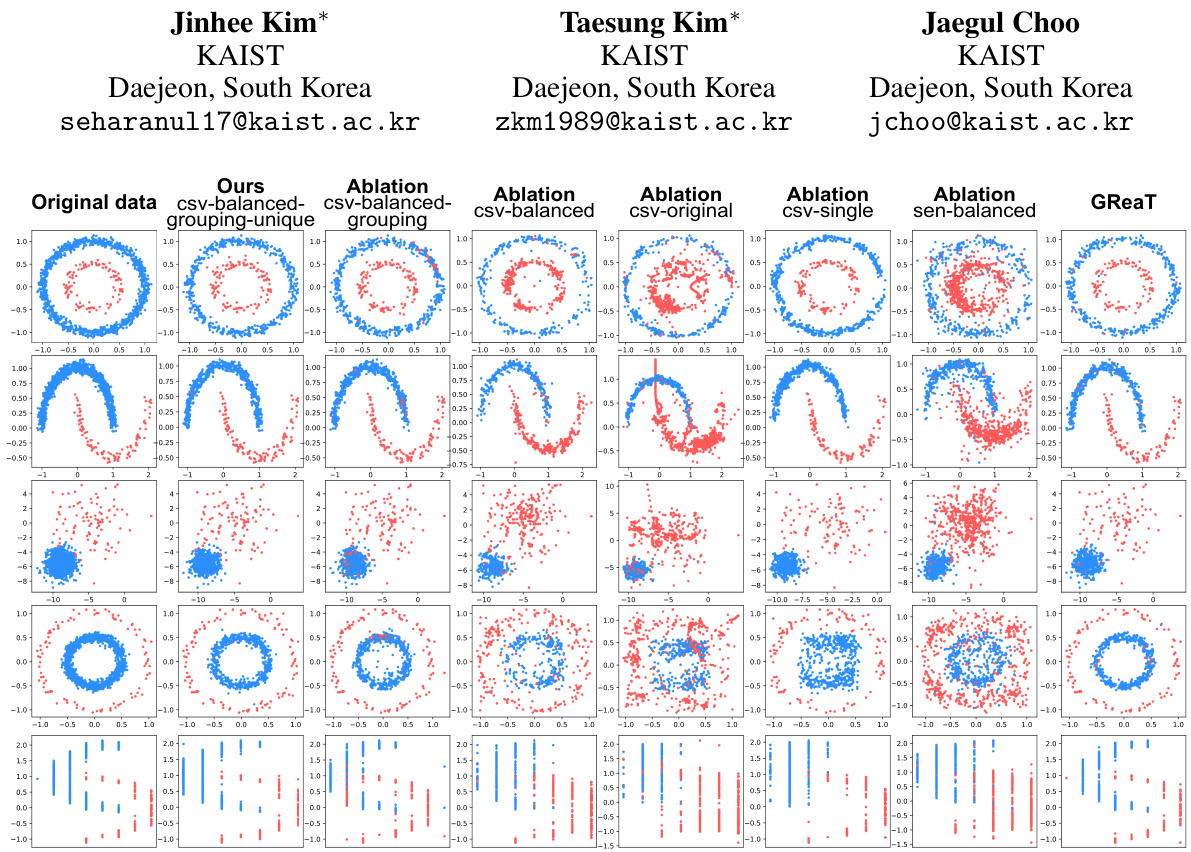
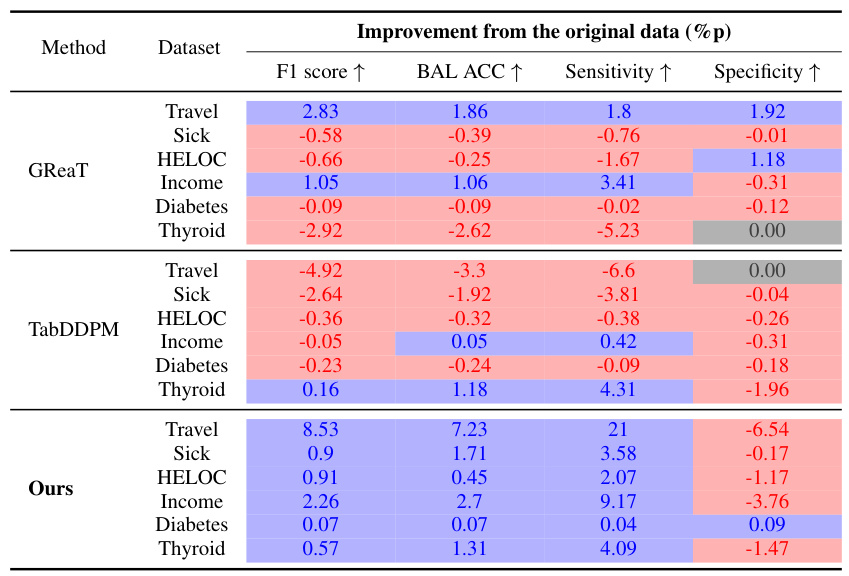
🔼 This figure showcases the results of generating synthetic data using different methods on a simple imbalanced dataset. The top row shows scatter plots for the original data and the synthetic data generated by the proposed EPIC method and several ablated versions (removing key components of the prompting technique) as well as the GReaT model, a baseline. Each row represents a different visualization of the data, highlighting different aspects like class separation, correlation between features, and data distribution. The EPIC method produces the clearest separation between classes, well-matched value ranges and maintains the feature correlations present in the original data, better than all of the baselines.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This table presents the results of machine learning classification experiments performed on six real-world datasets. For each dataset, the table shows the F1 score, Balanced Accuracy, Sensitivity, and Specificity achieved by various methods. The methods compared include using only the original data, augmenting the original data with synthetic data generated using different methods (TVAE, CTAB-GAN+, GReaT, TabDDPM), and using the proposed EPIC method. The number of synthetic samples added is also indicated. The table highlights the superior performance of the EPIC method in improving classification metrics, especially when compared to baselines.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.
In-depth insights#
Imbalanced Data Synth#
Addressing imbalanced datasets is crucial in machine learning, as traditional algorithms often struggle with skewed class distributions. Synthetic data generation offers a potential solution by augmenting the minority class, thus improving model performance. However, simply generating synthetic data may introduce artifacts or fail to accurately reflect the underlying data distribution. Effective methods must consider feature correlations, value ranges, and relationships between numerical and categorical variables, all while avoiding overfitting or generating unrealistic samples. This requires careful design, potentially leveraging techniques like in-context learning within large language models (LLMs) to better capture subtleties of the original data. Prompt engineering, which involves crafting specific instructions for the LLM, plays a vital role in steering the generation process and ensuring the synthetic data complements the original data effectively. Ultimately, success hinges on carefully balancing the benefits of increased data volume with the need to maintain data integrity and realistic feature representation.
Prompt Engineering#
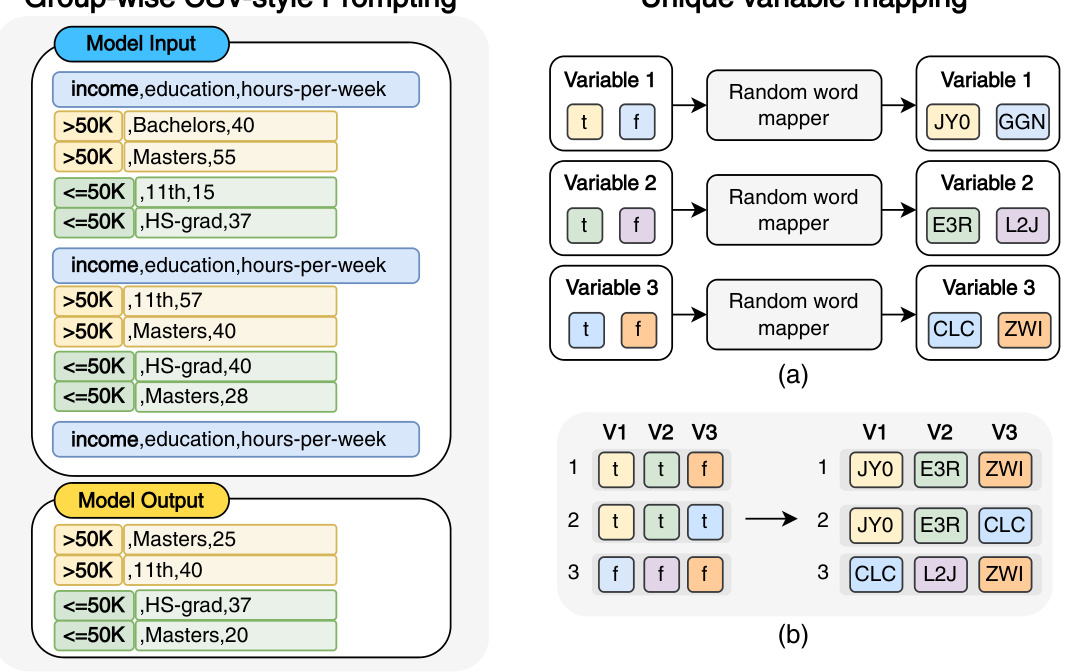
Prompt engineering plays a crucial role in effectively leveraging large language models (LLMs) for tabular data generation, particularly when dealing with imbalanced datasets. Careful prompt design is essential to guide the LLM in generating realistic synthetic data that accurately captures feature correlations and represents minority classes adequately. The choice of data format (e.g., CSV vs. sentence-style), class presentation (single-class vs. multi-class, balanced vs. unbalanced ratios), variable mapping (original values vs. unique mappings), and task specification (explicit instructions vs. completion triggering) significantly impacts the quality and efficiency of the generated data. The study highlights the effectiveness of balanced, grouped data samples combined with unique variable mappings in ensuring clear distinction and variability among variables, ultimately leading to improved model performance. Further research should explore optimal strategies for handling large datasets within the token limitations of LLMs and investigate the generalizability of prompt design principles across various model architectures.
LLM-based Data Gen#
LLM-based data generation represents a paradigm shift in synthetic data creation. Leveraging the in-context learning capabilities of large language models offers the potential to generate high-quality, diverse datasets, especially valuable for addressing class imbalance issues prevalent in many real-world applications. Prompt engineering plays a crucial role, with careful design of prompts significantly impacting the quality and characteristics of generated data. While model-agnostic approaches are preferred, different LLMs may exhibit varying performance, necessitating careful consideration of model selection. Balanced data representation within prompts is key for accurate minority class generation, alongside unique variable mapping to enhance data variability and avoid repetitive patterns. However, challenges remain, such as potential biases in generated data reflecting the biases present in training data, and limitations in fully representing complex data distributions, particularly in very large datasets where only subsets can be used for prompt examples. Future research should focus on optimizing prompt design for enhanced data quality and efficiency, and also exploring the integration of LLMs with existing generative models to combine the strengths of both approaches.
EPIC’s Strengths#
EPIC demonstrates several key strengths. Its model-agnostic nature allows for flexibility in choosing the underlying LLM, adapting to various models and resource constraints. The simplicity and ease of implementation are significant advantages, requiring minimal preprocessing and making it accessible to researchers with varying levels of expertise. Improved generation efficiency is another key benefit, producing high-quality data faster than comparable methods. Furthermore, robustness and practicality are underscored by its strong performance across diverse, real-world datasets, even in the face of class imbalances. Finally, the state-of-the-art classification performance achieved when using synthetic data generated by EPIC highlights its effectiveness in enhancing machine learning workflows.
Future Research#
Future research directions stemming from this work could explore more sophisticated prompt engineering techniques to further enhance the quality and diversity of synthetic tabular data generated by LLMs. Investigating the impact of different LLM architectures and sizes on the effectiveness of EPIC is also warranted. A key area to explore is handling complex data patterns, such as multi-modal data or data with extensive missing values. Further work should focus on the development of robust evaluation metrics that go beyond standard classification performance to fully capture the quality of the synthetic data and its suitability for various downstream tasks. Finally, research on the ethical implications of using LLMs for data generation, particularly concerning bias mitigation and ensuring data privacy, is crucial for responsible deployment of this technology.
More visual insights#
More on figures
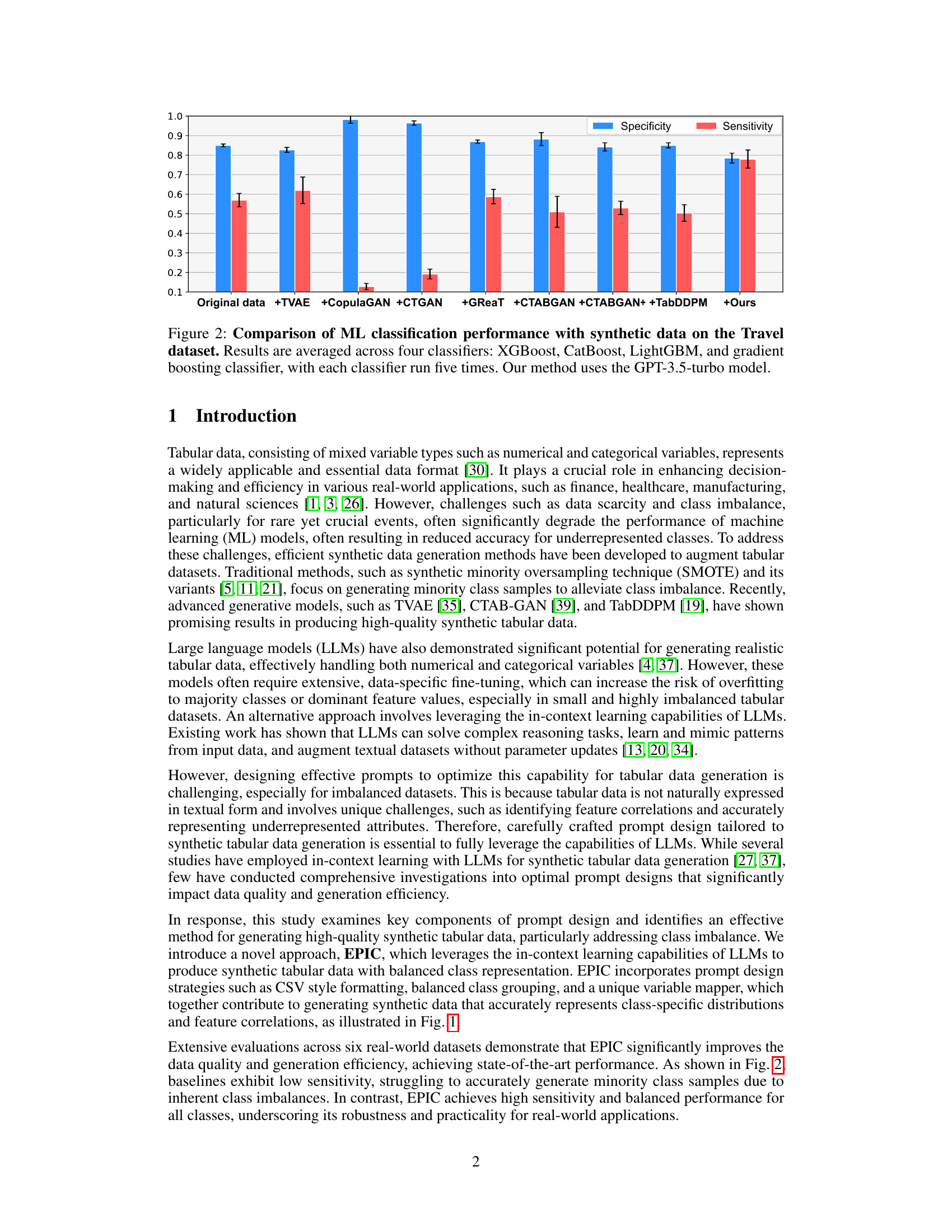
🔼 This figure compares the performance of several machine learning (ML) classifiers trained on synthetic datasets generated using different methods, including the proposed EPIC method. The classifiers used are XGBoost, CatBoost, LightGBM, and gradient boosting. The performance metric is averaged across these four classifiers, each run five times, to show the robustness of the results. The EPIC method uses the GPT-3.5-turbo model for synthetic data generation.
read the caption
Figure 2: Comparison of ML classification performance with synthetic data on the Travel dataset. Results are averaged across four classifiers: XGBoost, CatBoost, LightGBM, and gradient boosting classifier, with each classifier run five times. Our method uses the GPT-3.5-turbo model.
🔼 This figure shows the results of generating synthetic data using different methods on an imbalanced toy dataset. The first row displays the original data, while subsequent rows show the synthetic data generated by the proposed method (Ours) and several ablated versions. The last row showcases data with a more complex relationship between numerical and categorical features. The figure highlights the superior performance of the proposed method in generating realistic synthetic data that accurately represents both majority and minority classes, preserving feature correlations and overall data distribution.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.
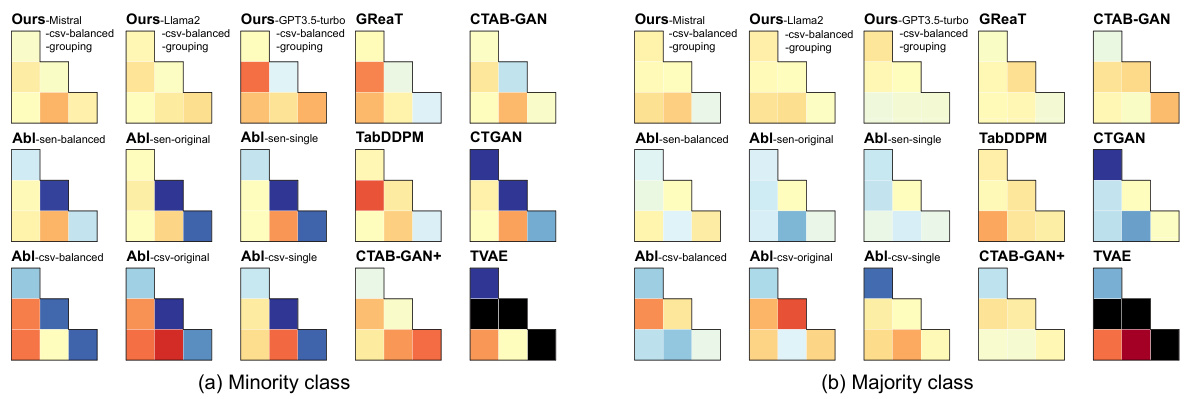
🔼 This figure compares the correlation matrices of categorical variables between real and synthetic datasets generated by different methods, including the proposed EPIC method and several baseline methods. The comparison is performed separately for the minority and majority classes of the Travel dataset. The color intensity represents the magnitude of the difference in correlation, with red indicating a positive difference (synthetic data has a higher correlation) and blue indicating a negative difference (synthetic data has a lower correlation). Black cells indicate that the correlation is not measured because only one unique value was generated for the corresponding variable in the synthetic data. The figure helps to visualize how effectively different methods capture the feature relationships present in the real dataset.
read the caption
Figure 4: Difference between Cramér's V correlation matrices of real and synthetic datasets for categorical variables in the Travel dataset. More intense colors indicate larger differences, with positive differences shown in red and negative differences shown in blue. Black indicates where the correlation is not measured since only one unique value is generated for those variables.
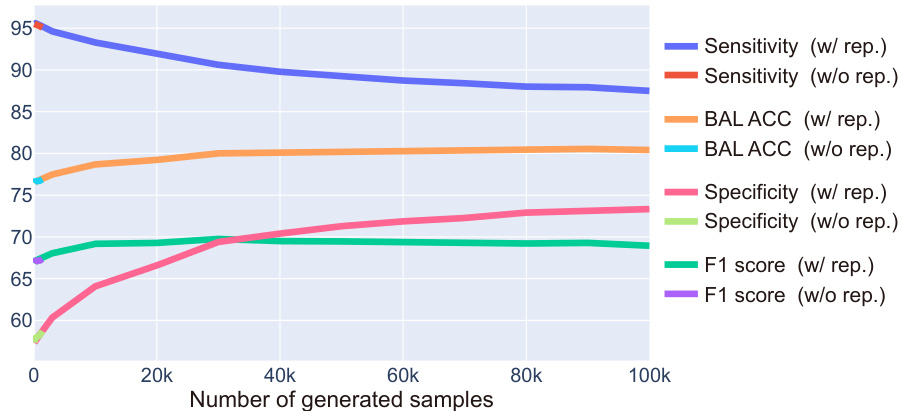
🔼 This figure shows the effect of adding synthetic data generated using the EPIC method to the original Income dataset, comparing two sampling methods: with replacement and without replacement. The x-axis represents the number of synthetic samples added, while the y-axis displays various classification metrics (Sensitivity, Balanced Accuracy, Specificity, and F1-score). The plot illustrates how these metrics change with increasing numbers of synthetic samples, and how the choice of sampling method affects performance. The results suggest that using replacement sampling leads to better performance overall.
read the caption
Figure 6: Classification performance on the Income dataset when synthetic data generated by our proposed method are added to the original dataset. We experiment with varying synthetic sample sizes, comparing data sampling methods: with replacement (w/ rep.) and without replacement (w/o rep.). EPIC samples with replacement. GPT-3.5-turbo is used for the experiment.
🔼 This figure shows the results of generating synthetic data using the proposed EPIC method and several ablated versions, as well as the GReaT model, on a simple imbalanced dataset. The plots visually compare the generated data distributions to the original data, highlighting the EPIC method’s ability to accurately capture feature correlations, distinct class boundaries, and overall data distribution. Improvements over ablated versions and GReaT are shown.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.
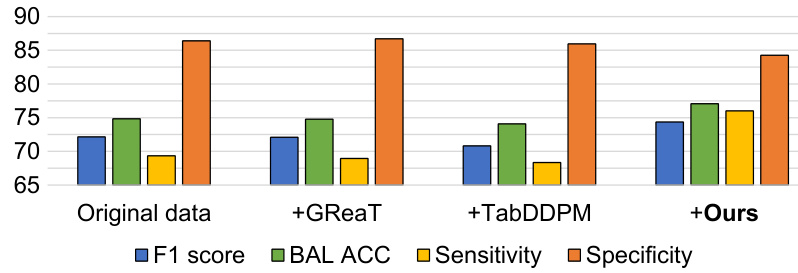
🔼 This figure compares the performance of the proposed method against the closest baselines (GReaT and TabDDPM) across six real-world datasets. It shows the F1 score, balanced accuracy, sensitivity, and specificity for each method and dataset, providing a visual representation of the overall classification performance improvements achieved by the proposed method. The bars visually represent how each metric changes after adding synthetic data generated by each approach to the original data. The results highlight the consistent and significant performance improvement of the proposed method across various datasets.
read the caption
Figure 8: Average classification results across six datasets compared with the closest baselines.

🔼 This figure displays the results of generating synthetic data on a toy dataset with imbalanced classes using different methods, including the proposed EPIC method and its ablated versions, as well as the GReaT model. The visualization shows scatter plots illustrating various aspects of data quality, including class separation, feature correlations, value ranges, and the handling of numerical and categorical features. The EPIC method demonstrates improvements in data quality compared to its ablated versions and the GReaT model.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This figure showcases the results of generating synthetic data for an imbalanced dataset using the proposed EPIC method and several ablated versions. Each subplot displays a scatter plot of the generated data, illustrating the model’s ability to create distinct class boundaries, maintain accurate feature correlations, and achieve a balanced distribution of data points across all classes. The improvements over the ablated versions and GReaT highlight EPIC’s effectiveness in handling imbalanced data.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.
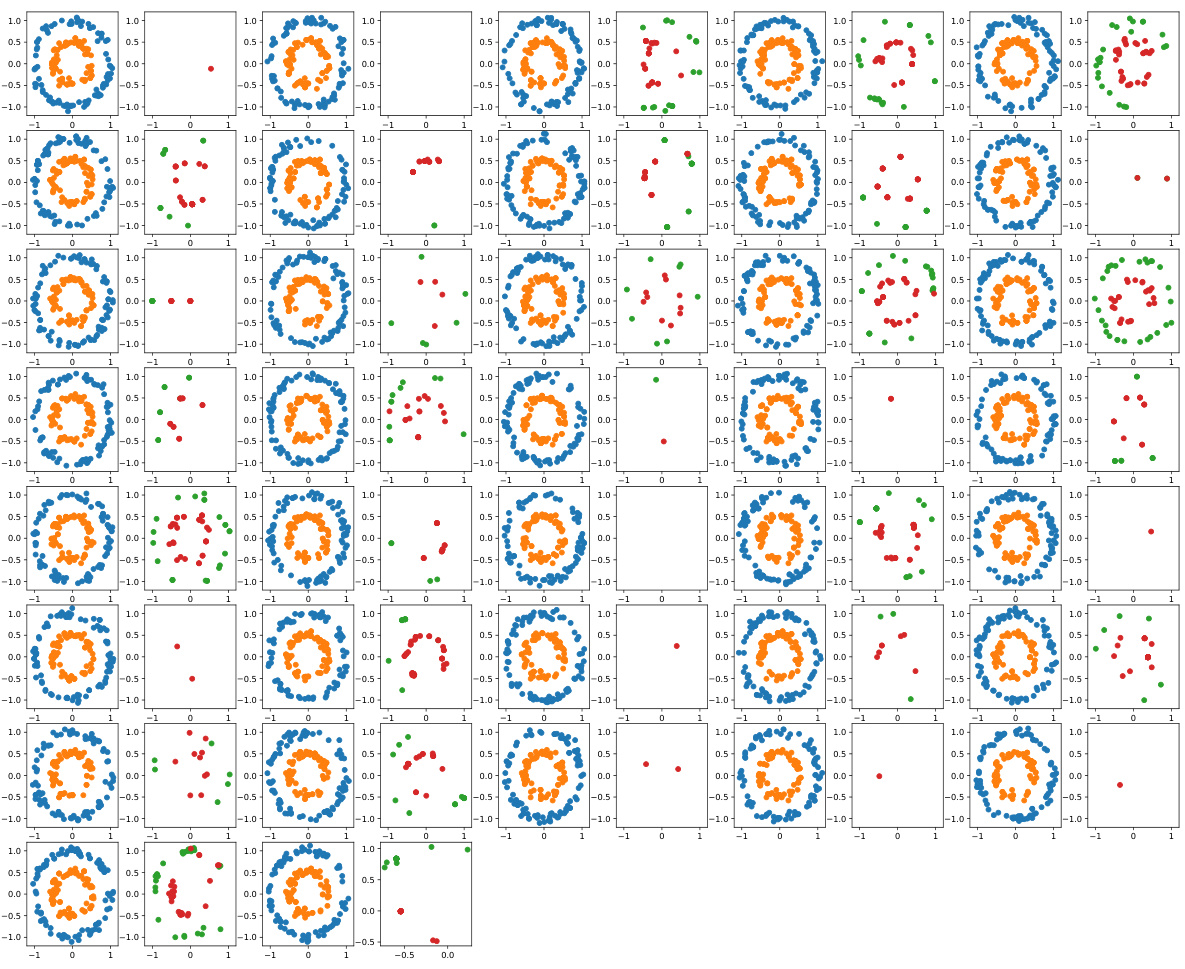
🔼 This figure shows the results of generating synthetic data for an imbalanced dataset using different methods. The original imbalanced dataset is shown alongside the results obtained using the proposed method (ours) and several ablated versions of the method. Each subplot visualizes the generated data points for a specific feature combination or feature type, highlighting the differences in how well each approach captures the underlying data distribution, class separation, and feature correlations. The proposed method demonstrates improved performance across several key aspects: distinct class separation, accurate feature correlations, appropriate value ranges, and comprehensive data distribution coverage.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This figure displays the results of generating synthetic data for an imbalanced toy dataset using different methods, including the proposed EPIC method and several ablated versions. The visualization shows scatter plots for various feature combinations, comparing the original data with the synthetic data generated by each method. The EPIC method demonstrates superior performance in capturing distinct class boundaries, accurate feature correlations, well-matched value ranges, robust numerical-categorical relationships, and comprehensive data distribution coverage compared to the other methods. The ablated versions highlight the importance of each component of the EPIC approach.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This figure displays the results of generating synthetic data for an imbalanced dataset using the proposed EPIC method and several ablated versions. The plots visualize the generated data’s performance across five key aspects: distinct class boundaries, accurate feature correlations, matched value ranges, robust numerical-categorical relationships, and comprehensive data distribution coverage. The results show EPIC’s superior performance compared to ablated versions and the GReaT model.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.
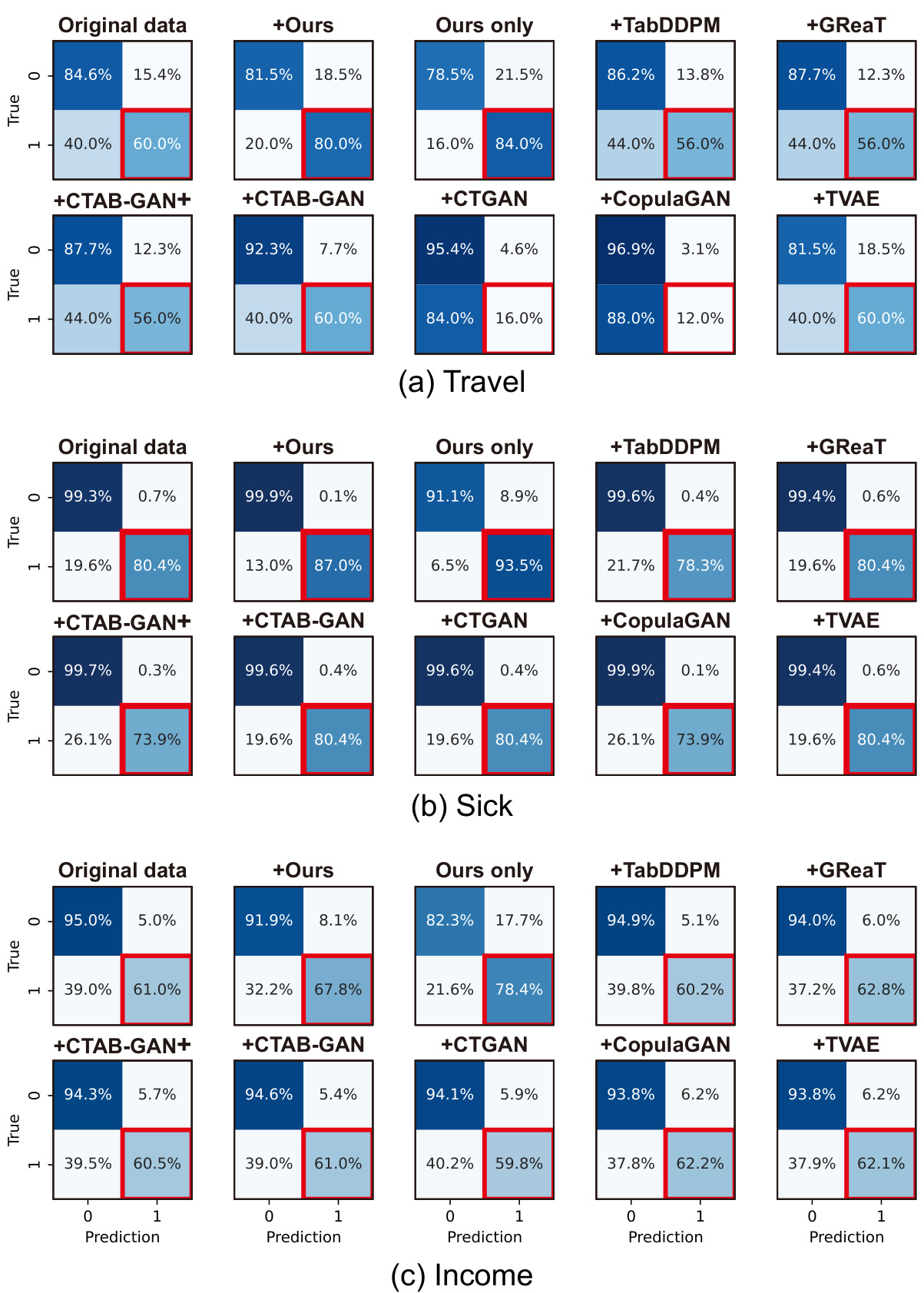
🔼 This figure showcases the effectiveness of the proposed EPIC method for generating synthetic tabular data, especially for imbalanced datasets. It presents a comparison of data generated by EPIC and its ablated versions, alongside a fine-tuned GReaT model, on a toy dataset with clear majority and minority classes. The results highlight EPIC’s ability to produce synthetic data with well-defined class boundaries, accurate feature correlations, matched value ranges, robust handling of numerical and categorical relationships, and comprehensive data distribution coverage. The improvements seen in EPIC over its ablated versions and GReaT demonstrate the significance of the proposed prompting techniques.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This figure shows the results of generating synthetic data for an imbalanced toy dataset using different methods. The top row displays the original data and the results produced by the proposed method (Ours). Subsequent rows show results from ablated versions of the proposed method, where different components of the prompting technique have been removed. The final row shows results for the GReaT model. The plots visualize the generated data, demonstrating how the proposed method achieves better separation of classes, correlation between features, and data distribution coverage than the other methods.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.

🔼 This figure showcases the results of generating synthetic data for an imbalanced dataset using the proposed EPIC method and several ablated versions. It visually demonstrates the method’s ability to create synthetic data that accurately reflects the characteristics of the original data, including distinct class separation, accurate feature correlations, well-matched value ranges, and robust handling of numerical and categorical variables. The improvements achieved by EPIC compared to its ablated versions and GReaT are evident in the visualization.
read the caption
Figure 1: Generation results on an imbalanced toy dataset with majority and minority classes. Our approach, leveraging in-context learning with LLMs, achieves (1) distinct class boundaries, (2) accurate feature correlations, (3) well-matched value ranges, (4) robust numerical-categorical relationships (last row), and (5) comprehensive data distribution coverage, with improvements over its ablated versions and the fine-tuned GReaT model [4]. Complete results are available in Appendix B.3.
More on tables

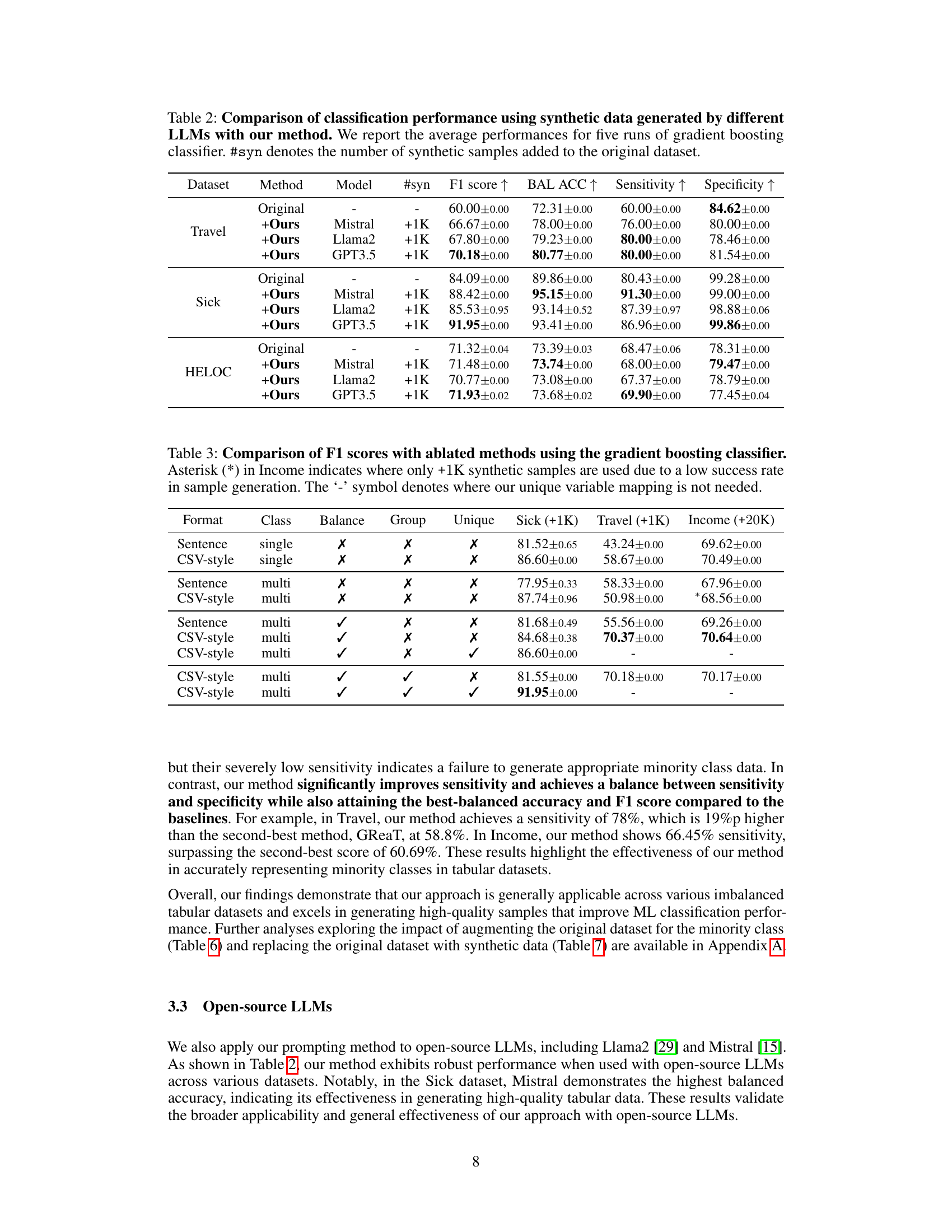
🔼 This table presents a comparison of classification performance achieved using synthetic data generated by different Large Language Models (LLMs) in conjunction with the proposed EPIC method. The results are averaged across five runs of a gradient boosting classifier, a common machine learning algorithm for tabular data. The table shows the F1 score, Balanced Accuracy, Sensitivity, and Specificity metrics for each LLM (Mistral, Llama2, GPT3.5) and the original dataset, with the addition of synthetic samples (+1K). This allows for the assessment of the effectiveness of the proposed method in enhancing the performance of different LLMs on various datasets.
read the caption
Table 2: Comparison of classification performance using synthetic data generated by different LLMs with our method. We report the average performances for five runs of gradient boosting classifier. #syn denotes the number of synthetic samples added to the original dataset.
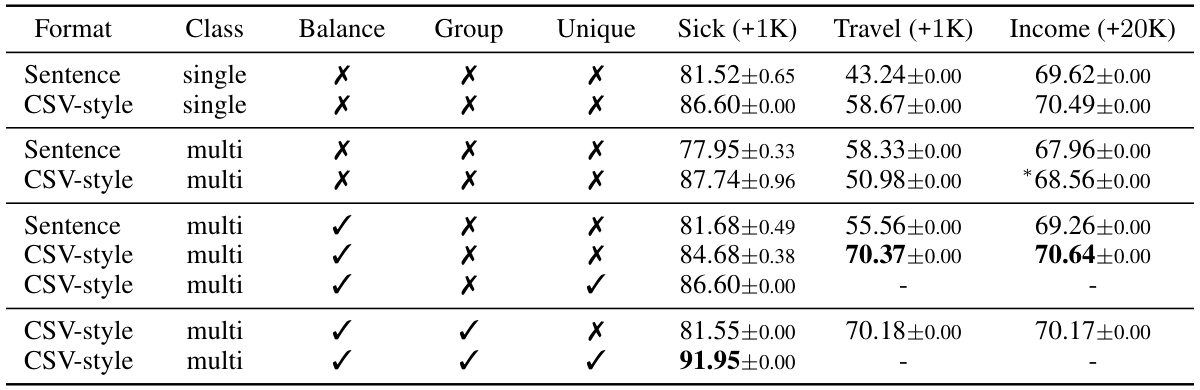
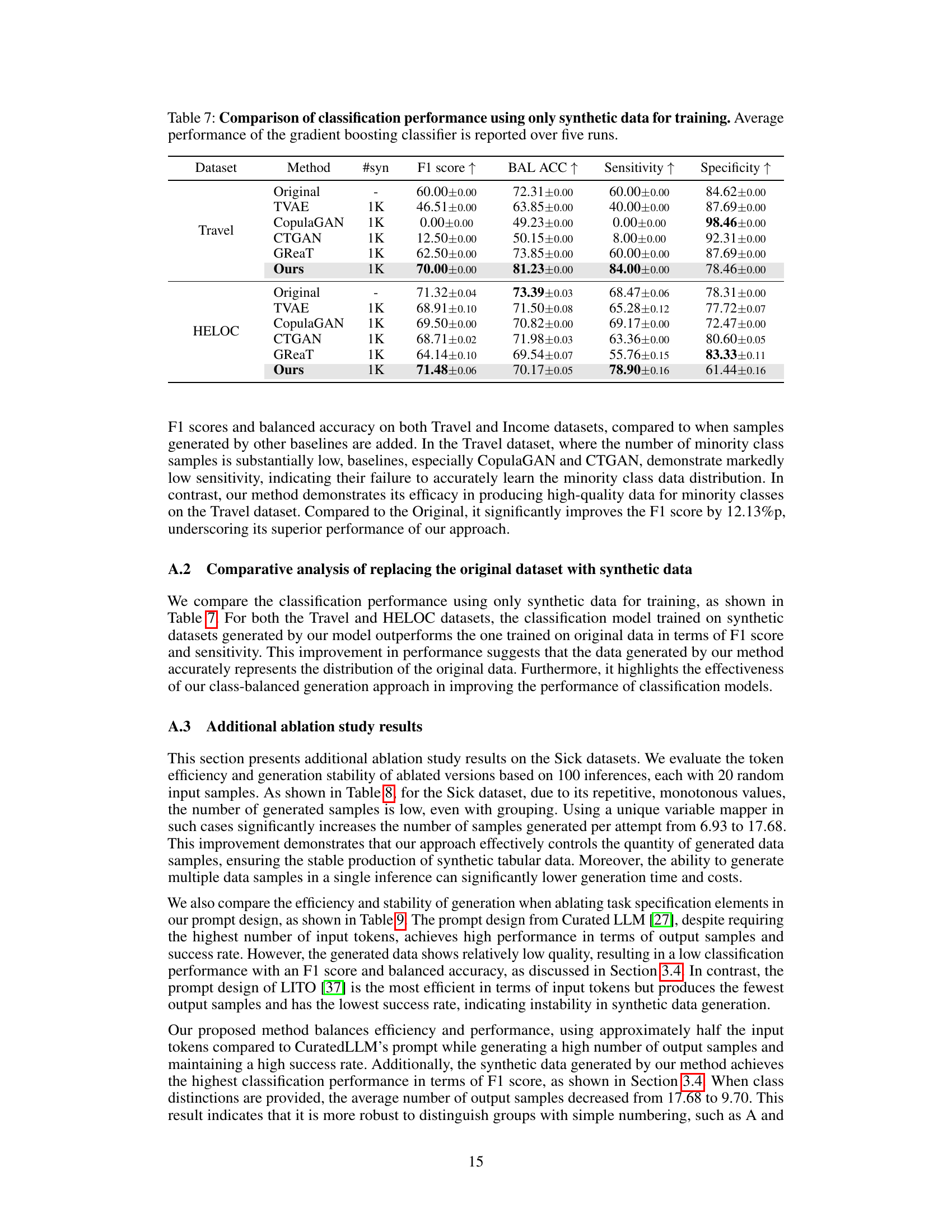
🔼 This table presents the results of an ablation study on the impact of different prompt design choices on the F1 score of a gradient boosting classifier. The study varied several factors, including the data format (sentence vs. CSV-style), class presentation (single vs. multi-class), class balance (original vs. balanced), group-wise prompting, and the use of unique variable mapping. The results are shown for three datasets: Sick, Travel, and Income. The asterisk (*) indicates that for the Income dataset, only 1K synthetic samples were used due to a lower success rate in generation. The dashes (-) indicate that a certain feature wasn’t applicable to that specific ablation experiment.
read the caption
Table 3: Comparison of F1 scores with ablated methods using the gradient boosting classifier. Asterisk (*) in Income indicates where only +1K synthetic samples are used due to a low success rate in sample generation. The '-' symbol denotes where our unique variable mapping is not needed.
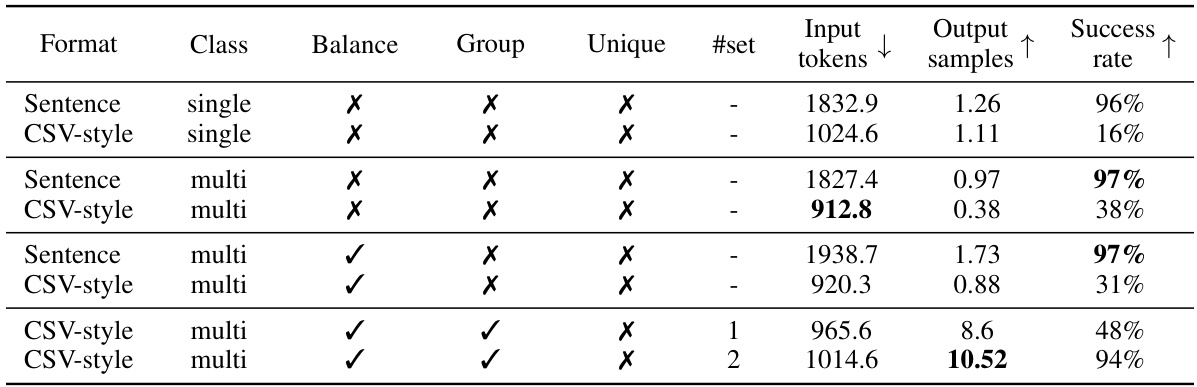
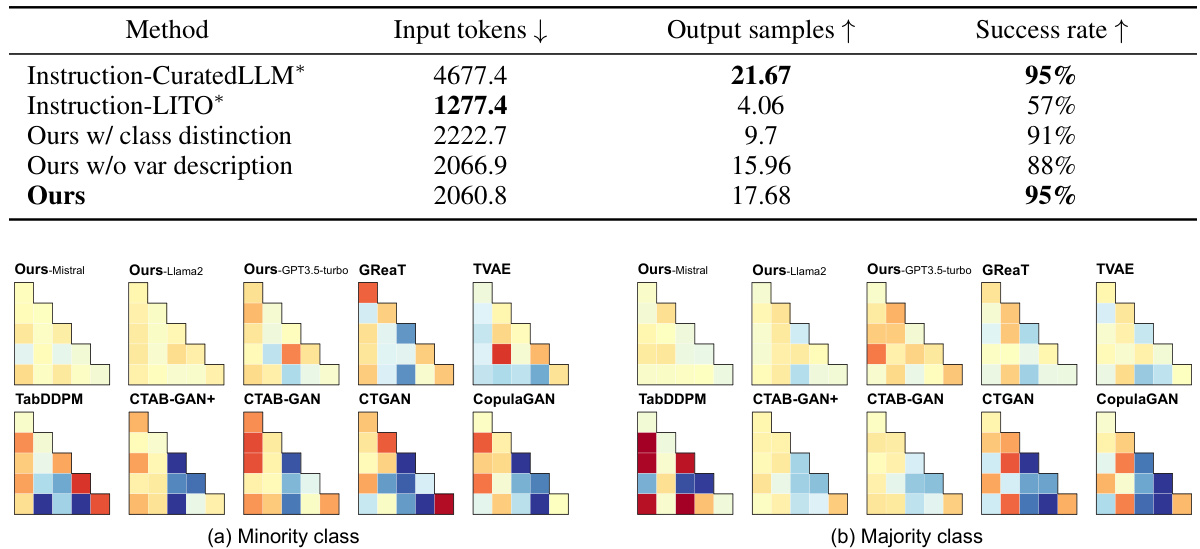
🔼 This table presents a comparison of the generation efficiency of different prompting methods on the Income dataset. The experiment involved 100 inferences, each using 20 random input samples. The table shows the number of input tokens required for each prompt, the average number of synthetic samples generated per inference, and the success rate (percentage of inferences that generated at least one valid sample). Different prompting methods are compared, varying in terms of sentence vs. CSV style formatting, single vs. multi-class generation, balanced vs. unbalanced class ratios, group-wise vs. non-group-wise data samples, and whether unique variable mapping was used.
read the caption
Table 4: Comparison of generation efficiency with ablated methods on the Income dataset. Results are based on 100 inferences, each with 20 random input samples. Input tokens indicates the number of tokens required in the LLM prompt for a fixed number of input samples. Output samples shows the average number of synthetic samples generated per iteration. Success rate measures the ratio of inferences that generate at least one valid data sample.

🔼 This table presents a comparison of the F1 score, balanced accuracy, sensitivity, and specificity achieved by different methods for generating synthetic data and augmenting the Sick dataset for classification tasks. The methods compared are Instruction-CuratedLLM, Instruction-LITO, Ours with class distinction, Ours without variable description, and Ours (the proposed method). The number of synthetic samples (#syn) added to the original dataset is 1k for all methods. The table highlights the impact of task specification elements (including instructions given to the LLM) on the classification performance of the augmented datasets.
read the caption
Table 5: Comparison of classification performance on the Sick dataset for task specification elements in prompt design. Results are averaged across XGBoost, CatBoost, LightGBM, and gradient boosting classifier. Methods marked with an asterisk (*) use the prompt designs proposed in the respective papers. #syn denotes the number of synthetic samples added to the original dataset.

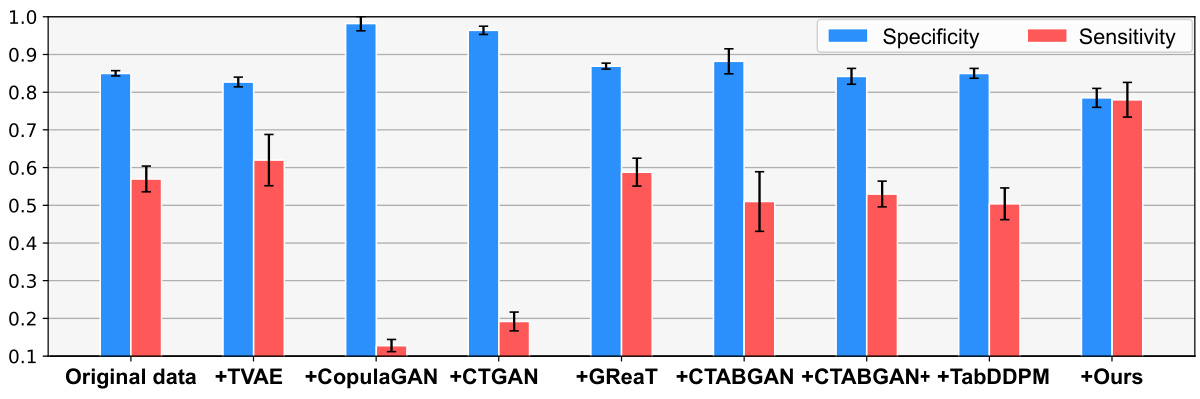
🔼 This table presents a comparative analysis of different methods for augmenting minority classes in imbalanced datasets. It shows the performance of the gradient boosting classifier after applying various techniques, including SMOTE, SMOTENC, TVAE, CopulaGAN, CTGAN, GReaT, and the proposed method, EPIC. The results are presented as averages across five runs and include F1 score, Balanced Accuracy, Sensitivity, and Specificity for each method. The goal is to demonstrate how well each method balances the class distribution and impacts the classification performance.
read the caption
Table 6: Comparison of binary classification performance when augmenting the minority class with synthetic data to balance class sizes. Average performance of the gradient boosting classifier is reported over five runs. #syn denotes the number of synthetic samples added to the original dataset.

🔼 This table presents a comparison of machine learning (ML) classification performance results. It compares the performance of four different classifiers (XGBoost, CatBoost, LightGBM, and Gradient Boosting) when synthetic data generated by various methods (TVAE, CopulaGAN, CTGAN, CTABGAN, CTABGAN+, GReaT, TabDDPM, and the proposed ‘Ours’ method) are added to the original dataset. The results are averaged across five runs for each classifier, and the complete results with standard deviations are available in the appendix. The table allows for assessing how different synthetic data generation methods impact ML classification performance, particularly in the context of imbalanced datasets.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.
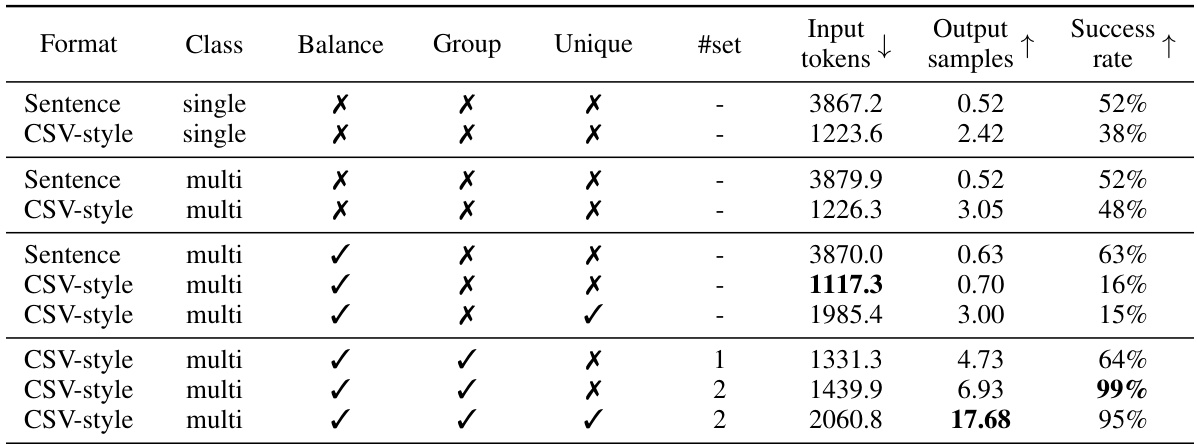
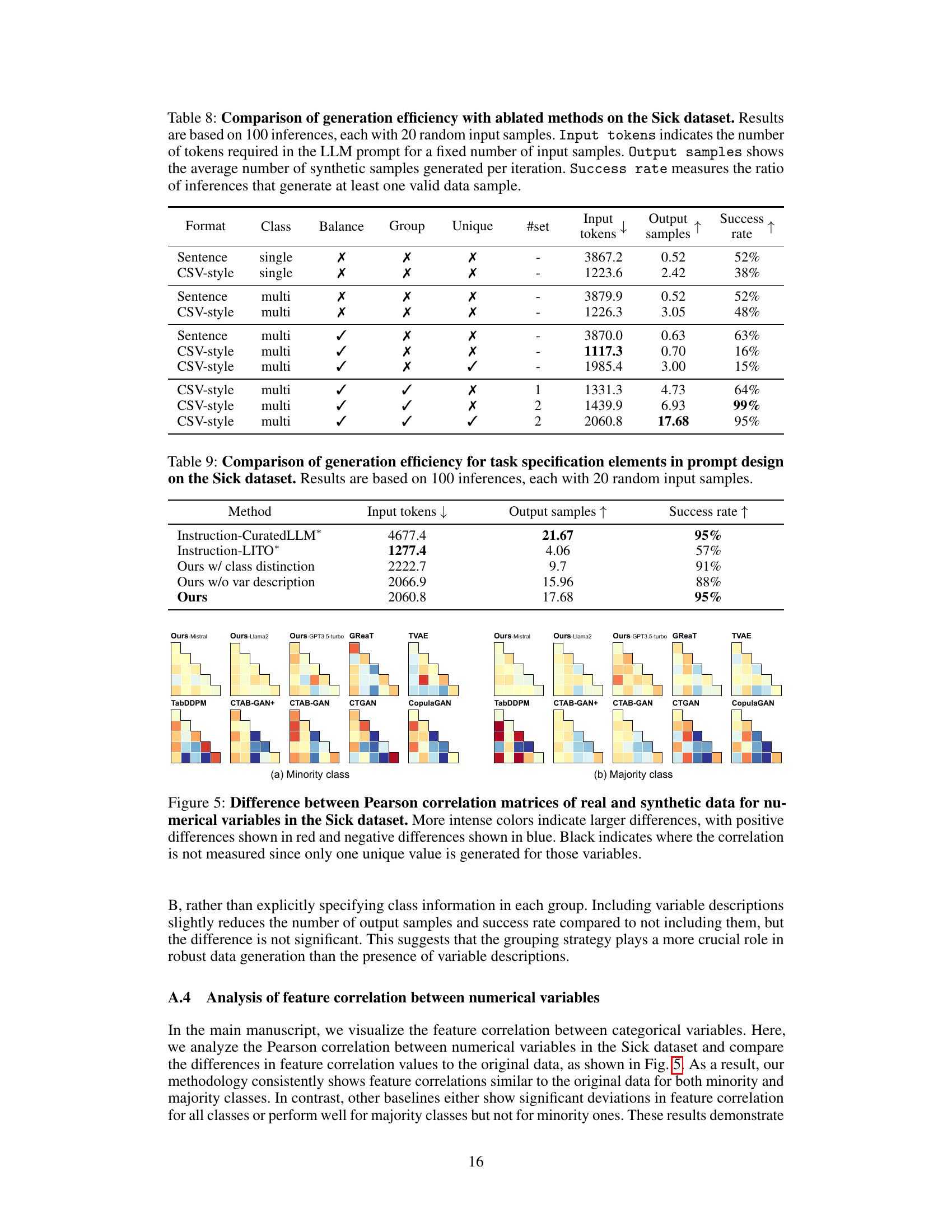
🔼 This table presents the results of an ablation study conducted on the Sick dataset to evaluate the impact of different prompt design choices on the efficiency of synthetic data generation using LLMs. It shows how various factors such as data format (Sentence vs. CSV), class presentation (single vs. multi-class), class balancing, grouping, and unique variable mapping affect the number of input tokens required, the number of synthetic samples generated per inference, and the overall success rate of the generation process. The results provide insights into designing more efficient prompts for LLM-based synthetic data generation.
read the caption
Table 8: Comparison of generation efficiency with ablated methods on the Sick dataset. Results are based on 100 inferences, each with 20 random input samples. Input tokens indicates the number of tokens required in the LLM prompt for a fixed number of input samples. Output samples shows the average number of synthetic samples generated per iteration. Success rate measures the ratio of inferences that generate at least one valid data sample.
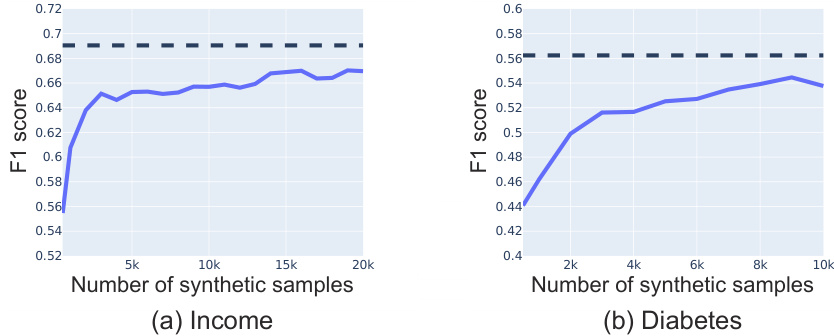
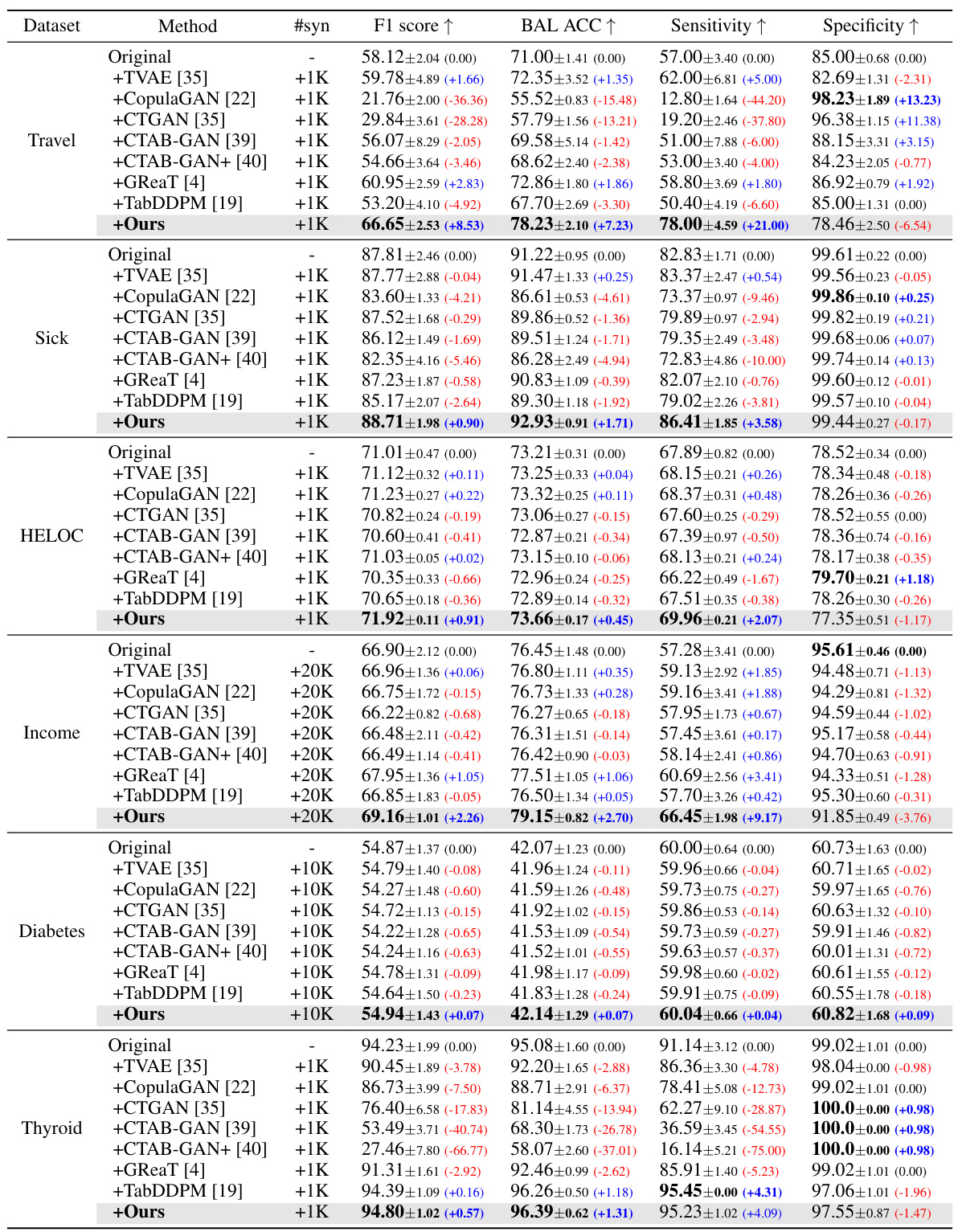
🔼 This table shows the percentage point improvement in F1 score, balanced accuracy, sensitivity, and specificity achieved by adding synthetic data generated using the proposed EPIC method compared to the original dataset for each of the six datasets used in the study (Travel, Sick, HELOC, Income, Diabetes, and Thyroid). Positive values indicate improvements, while negative values indicate decreases in performance compared to using only the original data. The table highlights the consistent improvements achieved by the EPIC method across various datasets and metrics.
read the caption
Table 10: Performance improvement after adding synthetic data to the original dataset. Results are reorganized from Table 1 of our main manuscript.
🔼 This table presents a comparison of machine learning (ML) classification performance results when synthetic data generated by different methods are added to the original dataset. The results are averaged over four different classifiers, each run five times. It shows the F1 score, Balanced Accuracy (BAL ACC), Sensitivity, and Specificity for various methods including TVAE, CTAB-GAN+, GReaT, TabDDPM, and the proposed method EPIC. The table allows for a comparison of the performance gains or losses when using synthetic data generated by different methods, providing insights into the effectiveness and potential benefits or drawbacks of each approach.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.

🔼 This table compares the F1 scores achieved by several robust tabular classification models (XGBoost, LightGBM, CatBoost, GB, TabPFN, T-Table, and TabR) on the Travel dataset. The comparison is made using three different scenarios: the original dataset alone, the original dataset augmented with synthetic data generated by the proposed EPIC method, and the original dataset augmented with synthetic data from the TabDDPM and GReaT methods. The results illustrate the performance improvement achieved by using the EPIC synthetic data generation method.
read the caption
Table 11: Comparison of F1 scores using robust tabular classification models. GB refers to gradient boosting classifier.

🔼 This table presents the details of the six real-world public tabular datasets used in the paper’s experiments. For each dataset, it lists the number of classes, the number of categorical features, the number of numerical features, the total number of samples, and the domain from which the dataset originates. This information is crucial for understanding the context and scope of the experimental evaluations performed in the paper.
read the caption
Table 12: Dataset details used in this study.

🔼 This table presents the results of machine learning (ML) classification experiments comparing the performance of various methods when synthetic data is added to the original dataset. Four different classifiers (XGBoost, CatBoost, LightGBM, and gradient boosting classifier) were used, each run five times. The table shows the F1 score, balanced accuracy, sensitivity, and specificity for each method on different datasets (Travel, Sick, HELOC, Income, Diabetes, and Thyroid). The ‘Original’ row shows the performance of the original dataset without added synthetic data, and other rows show the performance when synthetic data generated by different methods (TVAE, CopulaGAN, CTGAN, GReaT, TabDDPM, and the proposed ‘Ours’ method) are added. The complete results including standard deviations and the results of all the baseline methods are available in Appendix F.2.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.

🔼 This table presents a comparison of machine learning classification performance results obtained using four different classifiers (XGBoost, CatBoost, LightGBM, and Gradient Boosting Classifier) on six real-world datasets. For each dataset, the table shows the F1 score, balanced accuracy, sensitivity, and specificity achieved by the original dataset, and by augmenting the original data with synthetic data generated using various methods, including TVAE, CTAB-GAN+, GReaT, TabDDPM, and the proposed EPIC approach. Each model is run five times, and the results are averaged. The table highlights the performance improvement achieved by EPIC compared to other methods, particularly its ability to enhance both sensitivity and balanced accuracy.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.

🔼 This table presents a comparison of machine learning (ML) classification performance when synthetic data generated by different methods (TVAE, CopulaGAN, CTGAN, GReaT, CTABGAN, CTABGAN+, TabDDPM, and the proposed EPIC method) are added to the original dataset. The results are averaged across four classifiers (XGBoost, CatBoost, LightGBM, and gradient boosting classifier) with each classifier run five times. The table shows the F1 score, Balanced Accuracy, Sensitivity, and Specificity for each method across multiple datasets. Higher values indicate better performance. Appendix F.2 provides more detailed results, including standard deviation values.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.

🔼 This table presents a comparison of machine learning (ML) classification performance results across six different datasets. For each dataset, the performance of the original dataset is compared against the performance after adding synthetic data generated using various methods, including TVAE, CopulaGAN, CTGAN, GReaT, CTABGAN, CTABGAN+, TabDDPM, and the proposed method (Ours). The metrics used for evaluation include F1 score, Balanced Accuracy (BAL ACC), Sensitivity, and Specificity. The number of synthetic samples added is indicated as #syn. The results show that the proposed method consistently achieves better performance compared to the baseline methods.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.

🔼 This table presents the results of machine learning classification performance experiments. Synthetic data generated using different methods (TVAE, CopulaGAN, CTGAN, GReaT, CTABGAN, CTABGAN+, TabDDPM, and the proposed ‘Ours’ method) were added to six real-world datasets (Travel, Sick, HELOC, Income, Diabetes, Thyroid). The performance of four different classifiers (XGBoost, CatBoost, LightGBM, Gradient Boosting Classifier) was measured using metrics like F1 score, Balanced Accuracy (BAL ACC), Sensitivity, and Specificity. The results show how each synthetic data generation method affects the classification performance compared to using only the original data. The complete results with standard deviations are available in Appendix F.2.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.
🔼 This table presents a comparison of machine learning (ML) classification performance when synthetic data generated by various methods are added to the original dataset. The results are averaged across four different classifiers (XGBoost, CatBoost, LightGBM, and Gradient Boosting Classifier), each run five times for robustness. The table shows the F1 score, balanced accuracy, sensitivity, and specificity for each method on six different datasets (Travel, Sick, HELOC, Income, Diabetes, Thyroid). The ‘+Ours’ row represents the performance of the proposed EPIC method, with improvements highlighted. Complete results, including standard deviations, are available in the appendix for detailed analysis.
read the caption
Table 1: Comparison of ML classification performance with synthetic data are added to the original dataset. Results are averaged across four classifiers, with each model run five times. Complete results, including all baselines and standard deviation values, are provided in Appendix F.2.
Full paper#