↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges when deploying models in real-world scenarios due to the coexistence of in-distribution data and unexpected out-of-distribution (OOD) data, including covariate-shift and semantic-shift data. Existing FL methods typically address either OOD generalization or OOD detection, but not both simultaneously. This limitation hinders the reliability and robustness of FL models in practical applications.
To address this, the paper introduces FOOGD, a novel federated learning framework. FOOGD estimates the probability density of each client and leverages this information to guide subsequent FL processes. It achieves this through two key components: SM3D, which estimates score models and detects semantic-shift data; and SAG, which regularizes feature invariance for generalization. The empirical results demonstrate that FOOGD effectively tackles both OOD generalization and detection, outperforming existing FL methods. This makes FOOGD a valuable tool for building more robust and reliable FL systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles a critical yet under-researched problem in federated learning: handling both out-of-distribution generalization and detection simultaneously. This is vital for deploying robust and reliable FL models in real-world scenarios which often involves non-IID data, covariate-shift data, and semantic-shift data. The proposed FOOGD framework offers a novel approach with significant advantages, paving the way for more dependable and adaptable FL systems. Its open-source nature further enhances accessibility and encourages community involvement in advancing the field.
Visual Insights#
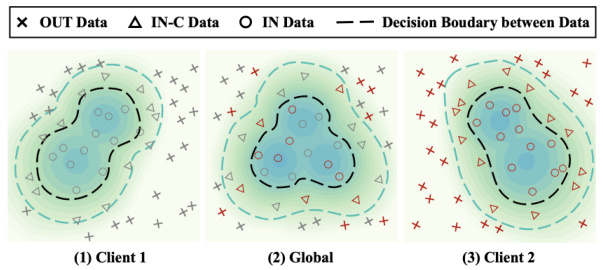
This figure illustrates the core idea behind the FOOGD method. It shows three plots representing the data distributions of two individual clients (Client 1 and Client 2) and the combined global distribution. Each plot displays data points categorized as IN (in-distribution), IN-C (in-distribution covariate shift), and OUT (out-of-distribution). The non-IID nature of the client distributions is evident, as each client has a different distribution of data points. The global distribution, in the center, aims to consolidate the information from both clients to provide a reliable and combined view of the overall data distribution for guiding the subsequent federated learning process.

This table presents the main results of the proposed FOOGD model and several baseline models on the Cifar10 dataset. It evaluates performance across three aspects: in-distribution (IN) accuracy, in-distribution with covariate shift (IN-C) accuracy using brightness as a representative covariate shift, and out-of-distribution (OUT) detection performance using LSUN-C as an out-of-distribution dataset. The metrics reported are accuracy (ACC), false positive rate at 95% true positive rate (FPR95), and area under the receiver operating characteristic curve (AUROC). The results are broken down by the degree of non-IID data distribution (α = 0.1, 0.5, and 5.0).
In-depth insights#
Fed-OOD Synergy#
The heading ‘Fed-OOD Synergy’ suggests a research area exploring the intersection of federated learning (Fed) and out-of-distribution (OOD) generalization/detection. Federated learning’s decentralized nature presents unique challenges for handling OOD data, as clients may encounter different types of OOD examples. A synergistic approach is needed because standard OOD techniques may not directly translate to the federated setting. Successful Fed-OOD synergy would likely involve novel methods for collaboratively estimating global data distributions from heterogeneous client data, robustly identifying OOD samples across clients, and developing algorithms that maintain both generalization performance on in-distribution data and robustness to OOD data within the constraints and privacy considerations inherent in federated learning. Research in this area would be crucial for deploying reliable and trustworthy FL models in real-world applications where unexpected data is inevitable.
SM3D Density#
The heading ‘SM3D Density’ suggests a method, SM3D, for estimating probability density. SM3D likely stands for a specific algorithm or model designed for this purpose, possibly incorporating score matching and maximum mean discrepancy (MMD) techniques. The approach may focus on handling complexities arising from decentralized data in a federated learning setting or from non-normalized, heterogeneous distributions. By combining these concepts, SM3D likely offers robust density estimation for challenging scenarios where traditional methods might fail. The use of MMD suggests that SM3D aims to estimate the density from a relatively small sample of data points, and to compare its estimated density to that generated from Langevin dynamics. This suggests that SM3D seeks to deal with cases where data is scarce or the distribution is complex or multimodal. The method likely produces a score value for each data point that indicates its probability density, which then may be used in downstream tasks such as anomaly detection or out-of-distribution data identification.
SAG Generalization#
The concept of ‘SAG Generalization’ in a federated learning context suggests a method designed to improve the generalization capabilities of the model across various client distributions. The approach likely involves regularizing the feature extractor to ensure it learns invariant features that are not overly specific to individual clients’ data. This is crucial in federated learning where data is decentralized and often non-independent and identically distributed (non-IID). A successful SAG generalization technique would mitigate the problem of overfitting to specific client data, thereby leading to enhanced model performance on unseen data from new clients or from unseen conditions within existing clients’ data. The method likely leverages techniques such as Stein’s identity, which are frequently used in score-based methods for density estimation, or other similar approaches to ensure consistency and robustness. The algorithm’s effectiveness will ultimately depend on the effectiveness of the regularization method, and its balance between encouraging diversity (to prevent overfitting) and promoting invariance (to ensure generalization).
Wild Data FL#
Federated learning (FL) in real-world scenarios faces the challenge of wild data, encompassing not only non-IID data distributions across clients but also out-of-distribution (OOD) data. This wild data includes both covariate shift (changes in data characteristics) and semantic shift (changes in data meaning). Traditional FL struggles with these complexities. Therefore, robust FL methods must account for OOD generalization (adapting to unseen data distributions) and OOD detection (identifying and handling OOD data points). Addressing the problem of wild data in FL requires developing models that are both robust to diverse data distributions and capable of identifying and handling OOD data without compromising privacy and communication efficiency. This necessitates innovative approaches to data representation, model training, and aggregation in FL to ensure reliable and effective model performance in challenging real-world deployments.
Future of FOOGD#
The future of FOOGD (Federated Out-of-distribution Generalization and Detection) appears promising, building upon its strengths in handling diverse real-world data. Improving privacy preservation mechanisms is crucial, possibly integrating differential privacy or homomorphic encryption to enhance security in decentralized settings. Extending FOOGD’s capabilities to more complex scenarios like those involving concept drift or evolving data distributions is a key area of future work. Addressing the computational overhead of FOOGD, particularly in large-scale deployments, could involve exploring more efficient algorithms or hardware acceleration. Theoretical analysis could be extended to provide tighter bounds on performance guarantees and clarify the interplay between different components. Benchmarking against a wider range of existing FL methods, especially those designed for specific OOD challenges, is necessary to solidify FOOGD’s position in the field. Finally, exploring applications in diverse domains beyond image classification, such as healthcare and natural language processing, would highlight FOOGD’s versatility and its potential for real-world impact.
More visual insights#
More on figures

The figure illustrates the FOOGD framework. Each client has a feature extractor for the main task, a SM3D module for OOD detection (estimating the score model using score matching and MMD), and a SAG module for OOD generalization (regularizing the feature extractor using Stein’s identity). The server aggregates the models from all clients to obtain a global distribution. The SM3D module generates samples to estimate the score function, which helps in identifying OOD data points in low-density areas. SAG aligns features from original and augmented data, helping to generalize better to covariate shift.
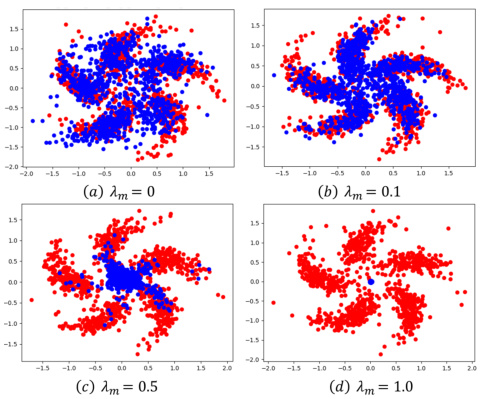
This figure illustrates the motivation behind the SM³D method. It shows how SM³D generates samples from a wider feature space to improve density estimation by leveraging Langevin dynamic sampling (LDS). The red points represent samples from the true data distribution, and the blue points represent samples generated by the LDS process. The different subfigures (a) to (d) show the results obtained with different values of λm, a trade-off coefficient that balances between score matching and maximum mean discrepancy (MMD). The results show how varying λm affects the density estimation, with λm = 0.1 providing the best balance between accuracy and coverage of the data distribution.
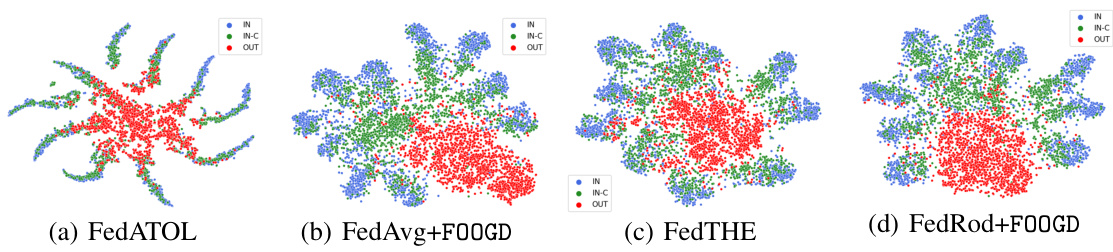
This figure uses t-distributed stochastic neighbor embedding (t-SNE) to visualize the data representations learned by four different federated learning methods: FedATOL, FedAvg+FOOGD, FedTHE, and FedRod+FOOGD. Each point represents a data sample, colored according to its class (IN, IN-C, or OUT). The visualizations illustrate how the different methods separate the three classes in the feature space. FOOGD is shown to improve the separation between the classes compared to baselines, indicating enhanced generalization and OOD detection capabilities.

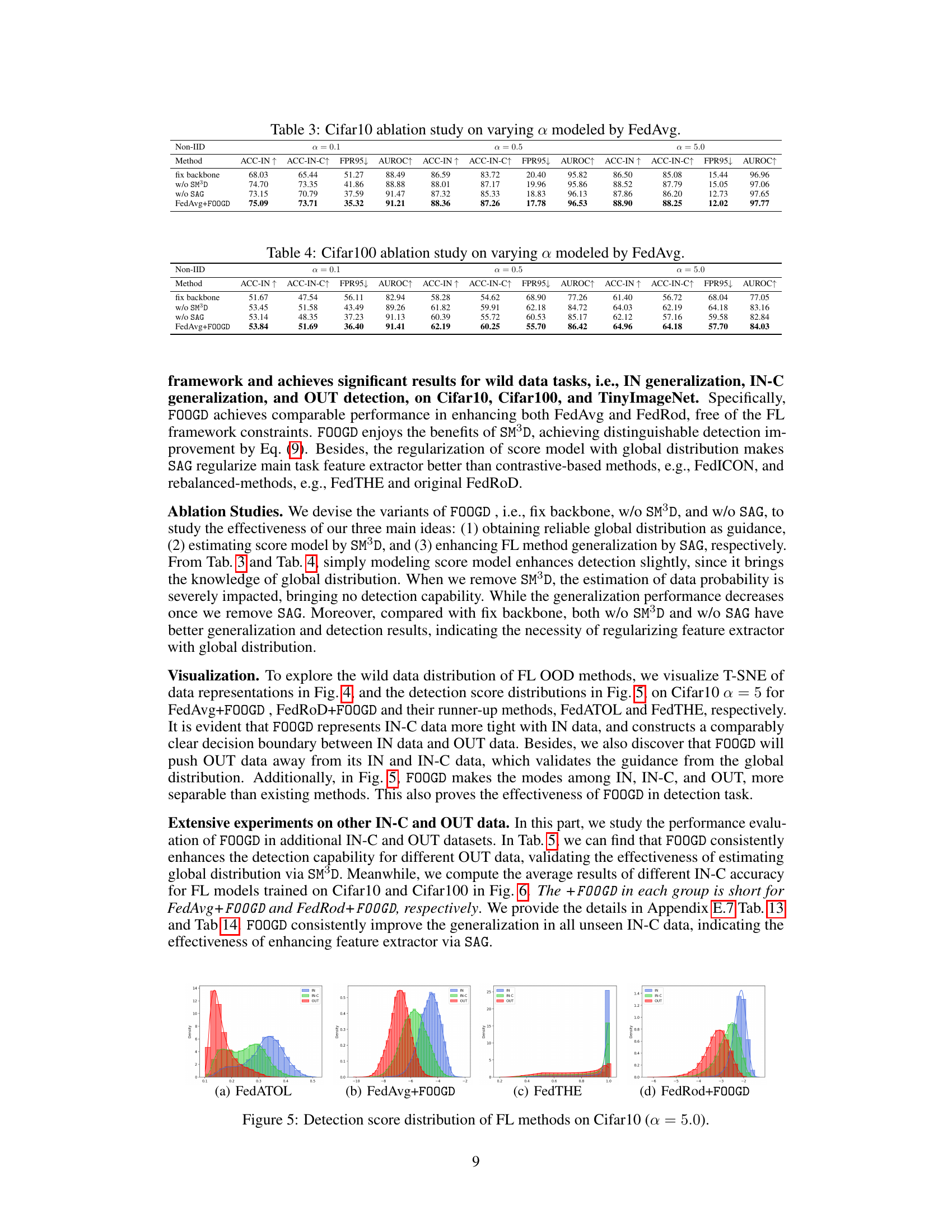
This figure visualizes the distribution of detection scores produced by four different federated learning methods on the CIFAR-10 dataset, where α=5.0 represents a relatively high degree of heterogeneity among client data distributions. The methods compared are FedATOL, FedAvg+FOOGD, FedTHE, and FedRod+FOOGD. The x-axis shows the detection scores and the y-axis represents the probability density. Each curve represents the distribution for in-distribution (IN), in-distribution covariate-shift (IN-C), and out-of-distribution (OUT) data. The figure helps illustrate how well each method separates IN, IN-C, and OUT data, indicating the effectiveness of the FOOGD framework in enhancing both generalization and detection capabilities for federated learning in the presence of wild data.
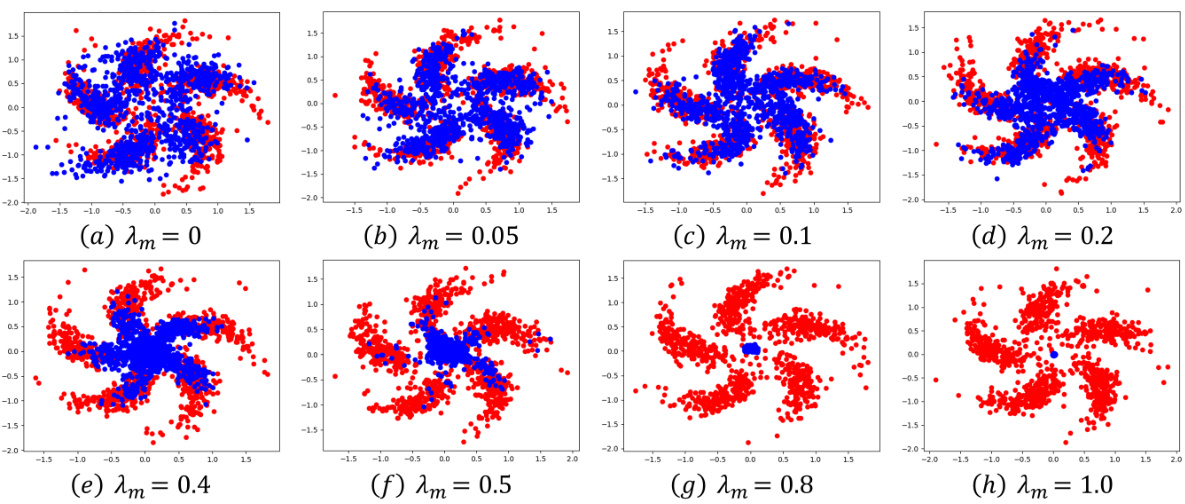
This figure shows the motivation behind using Langevin dynamic sampling (LDS) in the SM³D module of FOOGD. The red points represent samples from the true data distribution, while the blue points are generated using LDS, starting from random noise and iteratively updating based on the score model. The goal is to ensure that the generated samples broadly explore the feature space to mitigate issues associated with sparse or multimodal data when directly applying score matching, thereby improving the reliability of the density estimation.
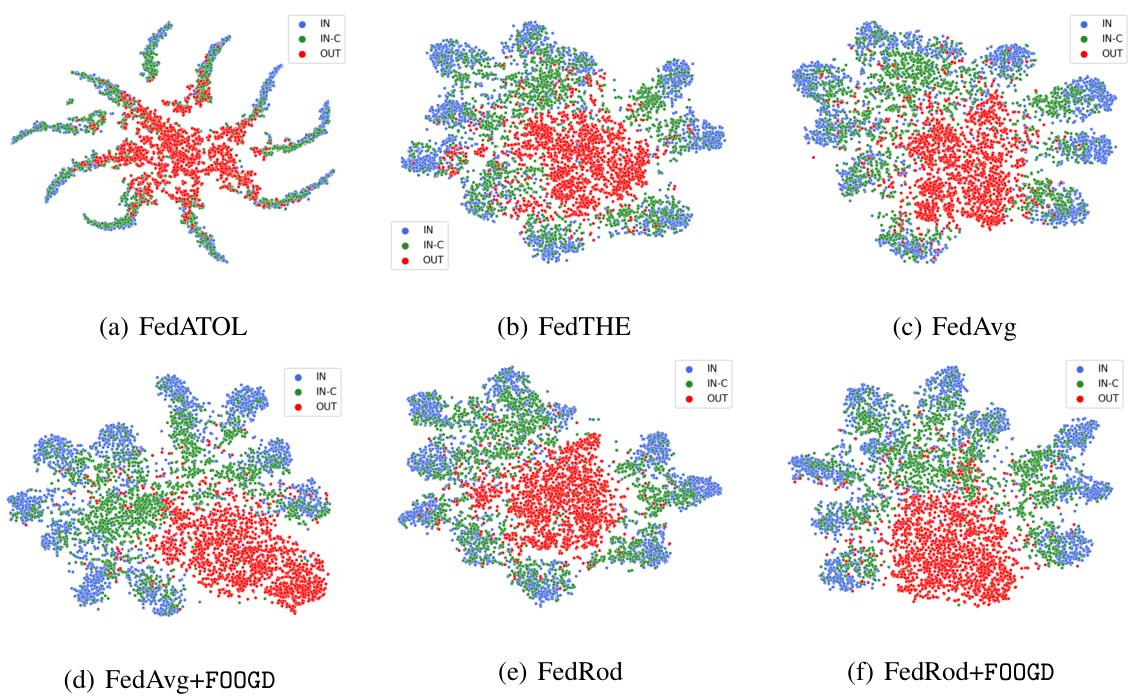
This figure shows the t-distributed stochastic neighbor embedding (t-SNE) visualizations of the feature representations from FedAvg, FedRod, and their corresponding versions combined with FOOGD. The visualizations illustrate the clustering of in-distribution (IN), in-distribution covariate-shift (IN-C), and out-of-distribution (OUT) data points in the feature space. The goal is to demonstrate how FOOGD improves the separation and clustering of these data types compared to the baseline methods.
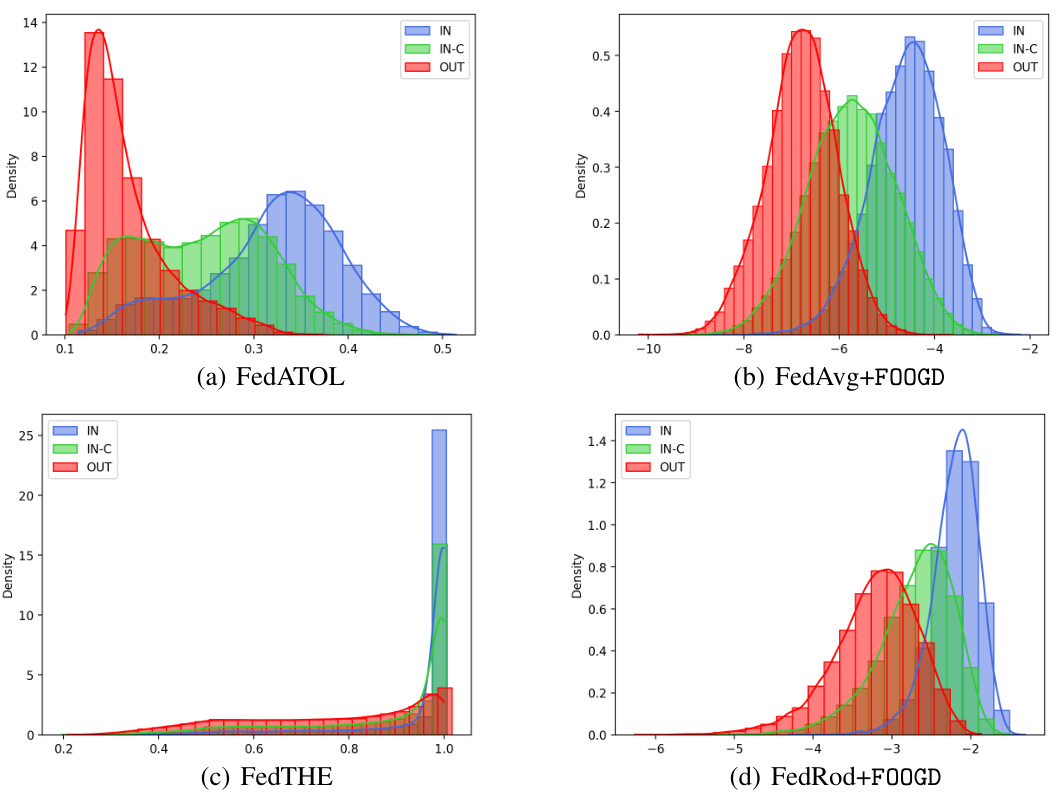
This figure visualizes the distribution of detection scores for different data types (IN, IN-C, OUT) using four different federated learning methods: FedATOL, FedAvg+FOOGD, FedTHE, and FedRod+FOOGD. The x-axis represents the detection score, and the y-axis represents the density. The distributions show how well each method separates in-distribution (IN) and in-distribution covariate shift (IN-C) data from out-of-distribution (OUT) data. FOOGD methods clearly show better separation of OUT data from IN and IN-C data compared to the baseline methods. The figure illustrates the effectiveness of the FOOGD framework in improving the detection of out-of-distribution data.
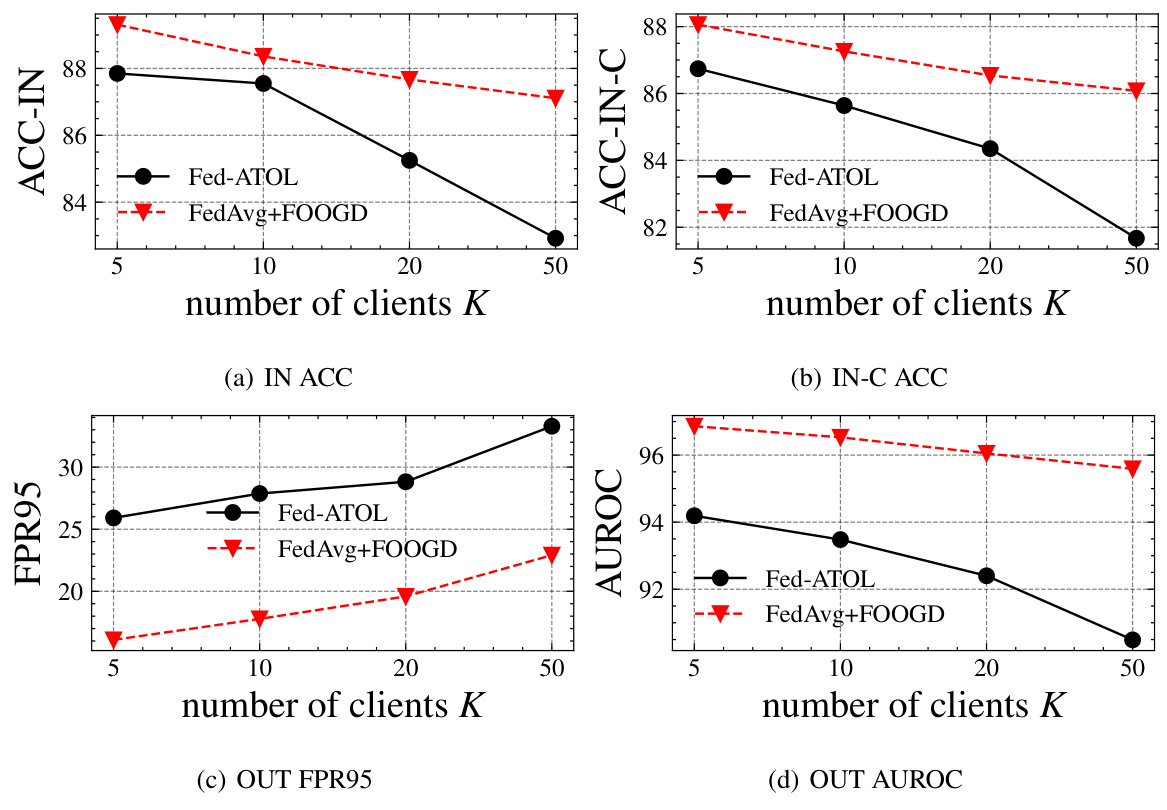
This figure shows the impact of the number of participating clients (K) on the performance of Fed-ATOL and FedAvg+FOOGD. Subfigures (a) and (b) illustrate the accuracy on in-distribution (IN) and covariate-shift (IN-C) data, respectively. (c) and (d) display the false positive rate at 95% true positive rate (FPR95) and the area under the receiver operating characteristic curve (AUROC) for out-of-distribution (OUT) data detection. The results suggest that increasing the number of clients generally improves performance, but the effect is more pronounced for FedAvg+FOOGD, particularly in terms of OUT data detection.
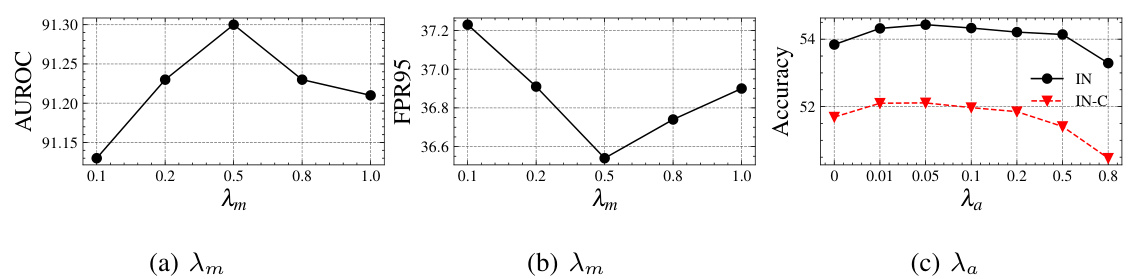
This figure shows the impact of hyperparameters λm and λα on the performance of the FOOGD model. λm is the trade-off coefficient between score matching and maximum mean discrepancy (MMD) loss in the SM³D module, balancing the exploration of the feature space with the accuracy of density estimation. λα is the regularization strength in the SAG module, controlling the alignment between original and augmented features for generalization. The plots illustrate how varying these parameters affects the AUROC score (a), FPR95 (b), and both IN and IN-C accuracies (c) on a Cifar-10 dataset, demonstrating the optimal parameter settings for balancing detection and generalization.
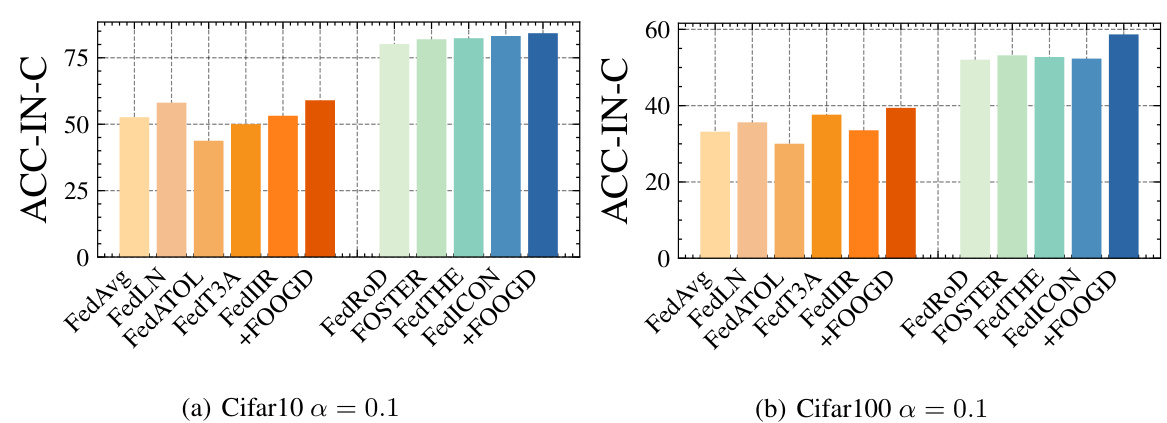
This figure shows the impact of the number of participating clients (K) on the performance of different federated learning methods for in-distribution (IN) and out-of-distribution (OOD) data. The plots illustrate the accuracy for IN and IN-C data (measuring generalization), and the false positive rate at 95% true positive rate (FPR95) and area under the ROC curve (AUROC) for OOD detection. It demonstrates how the performance of various algorithms, including FOOGD, changes as the number of clients increases.
More on tables
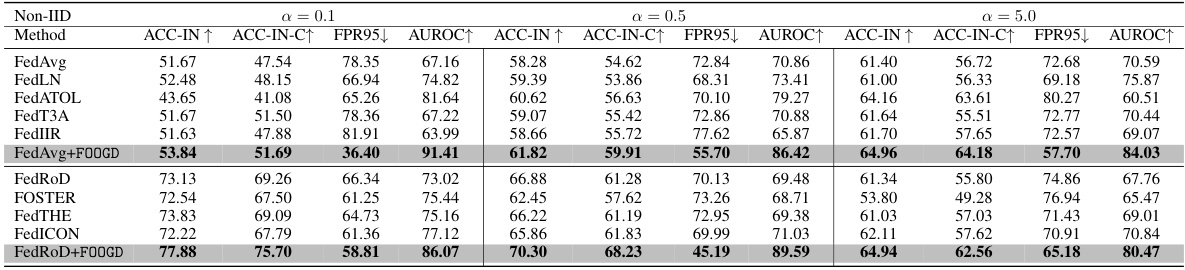
This table presents the main results of the proposed FOOGD method and several baseline methods on the Cifar10 dataset for federated out-of-distribution (OOD) detection and generalization. The results are broken down by the non-IID degree (alpha), showing ACC-IN (accuracy on in-distribution data), ACC-IN-C (accuracy on in-distribution covariate-shift data), FPR95 (false positive rate at 95% true positive rate), and AUROC (area under the ROC curve). It compares FOOGD’s performance against various other federated learning methods, both with and without explicit OOD handling.

This ablation study investigates the impact of removing key components of the FOOGD model (SM³D and SAG) on its performance across different levels of data heterogeneity (α). The results show the accuracy (ACC-IN, ACC-IN-C) on in-distribution and covariate-shift data, along with the false positive rate at 95% true positive rate (FPR95) and area under the ROC curve (AUROC) for out-of-distribution detection. By comparing the performance of the full FOOGD model to versions with either SM³D or SAG removed, or with the backbone fixed, the study reveals the importance of each component for effective handling of both in-distribution and out-of-distribution data. The varying α values represent different degrees of data heterogeneity across clients in the federated learning setting.

This table presents the ablation study results on the Cifar10 dataset for different α values, using FedAvg as the baseline model. It shows the impact of removing specific components of FOOGD (fix backbone, w/o SM³D, w/o SAG) on the model’s performance in terms of accuracy (ACC-IN and ACC-IN-C) and out-of-distribution detection (FPR95 and AUROC). The results highlight the individual contribution of each component of FOOGD and their synergistic effect on overall performance.

This table presents the main results of the proposed FOOGD model and several baseline models on the Cifar10 dataset for federated out-of-distribution (OOD) detection and generalization. It shows the accuracy (ACC) for in-distribution (IN) data and covariate-shift (IN-C) data (using brightness as a proxy for IN-C), as well as the false positive rate at 95% true positive rate (FPR95) and area under the receiver operating characteristic curve (AUROC) for out-of-distribution (OUT) data (using LSUN-C as a representative OUT dataset). Results are provided for different levels of non-IID data distribution (α = 0.1, 0.5, 5.0) among clients.
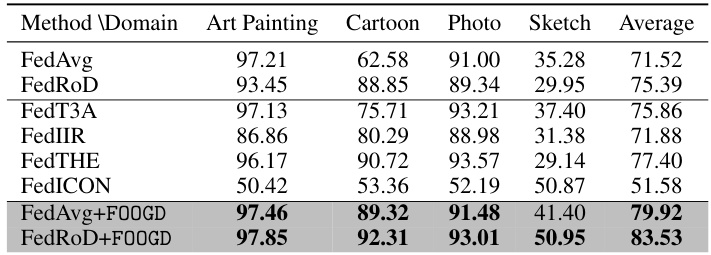
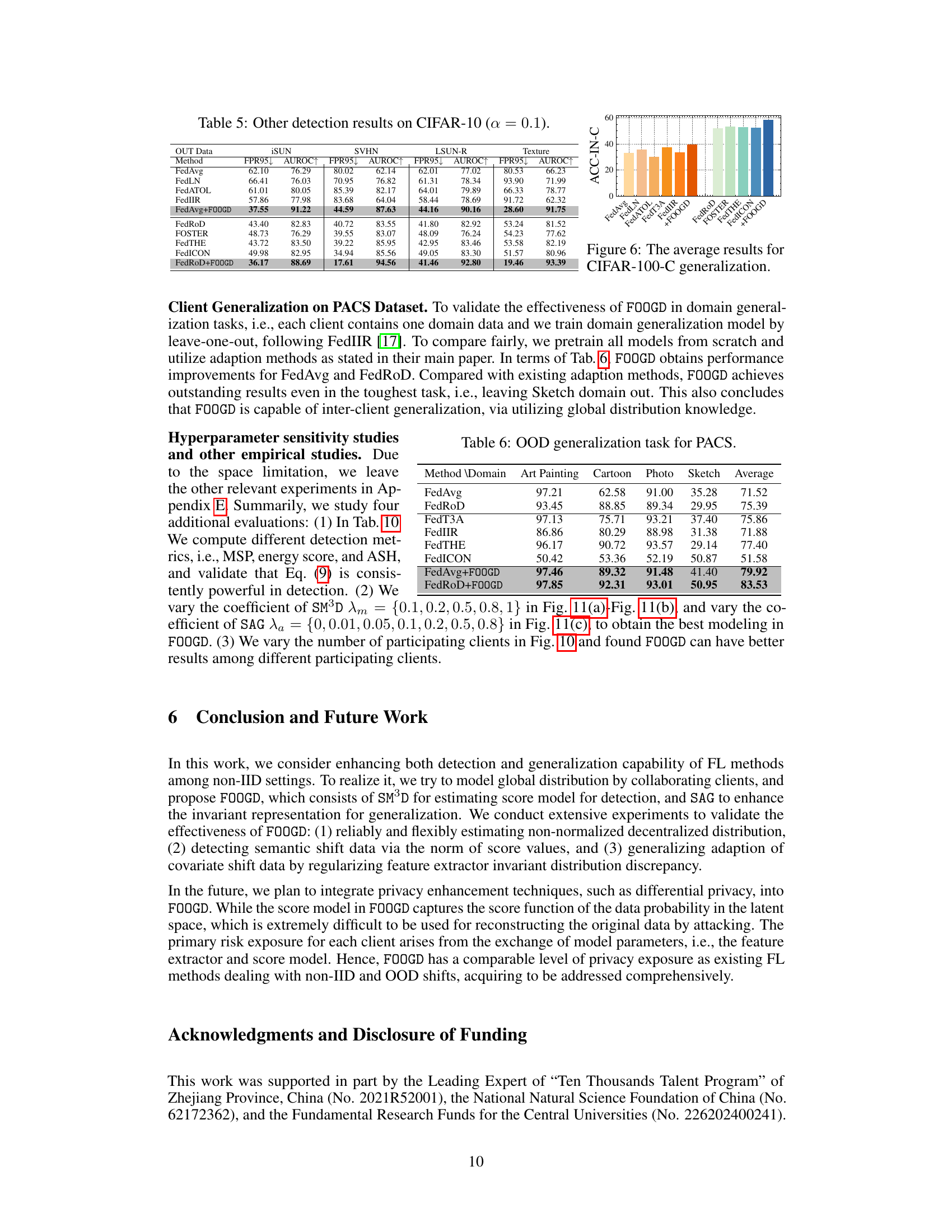
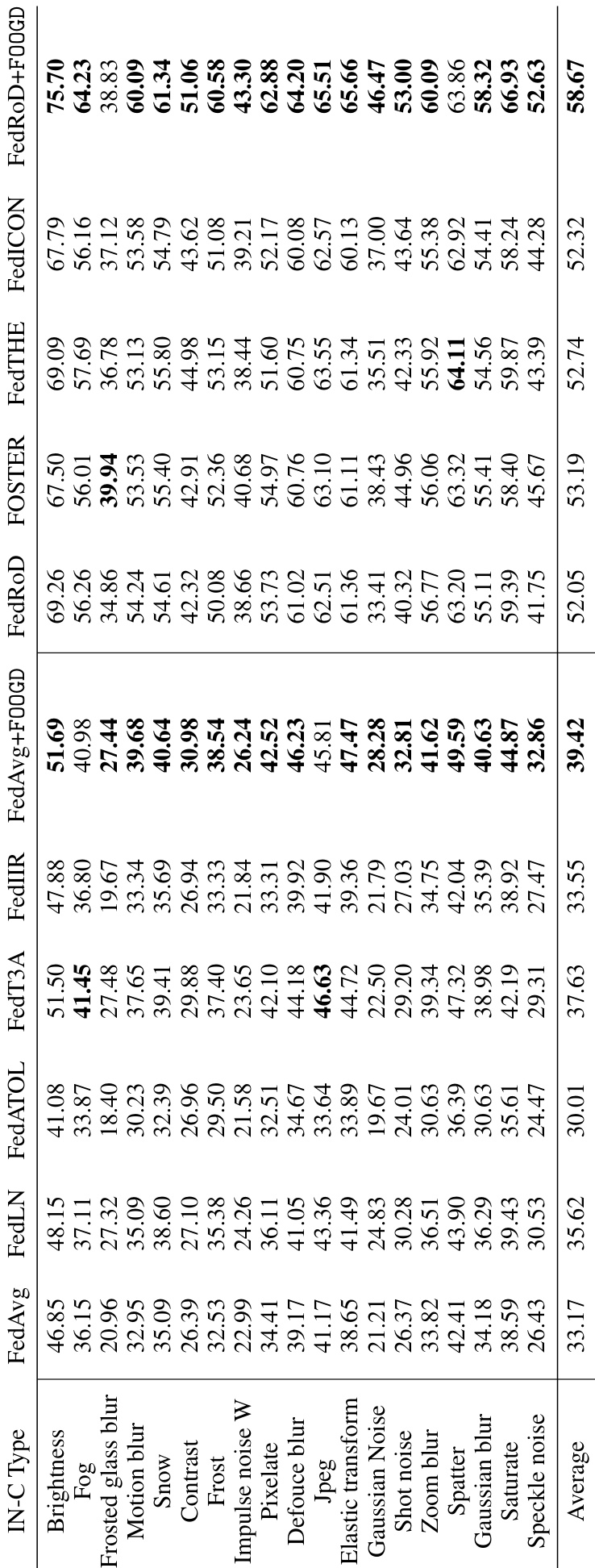
This table presents the results of out-of-distribution generalization experiments conducted on the PACS dataset. The table shows the average accuracy of different federated learning methods (FedAvg, FedRoD, FedT3A, FedIIR, FedTHE, FedICON, FedAvg+FOOGD, and FedRoD+FOOGD) when evaluating generalization performance on unseen domains (Art, Painting, Cartoon, Photo, and Sketch). Each method’s performance is evaluated by leaving out one of the domains during training and testing on the left-out domain. The results showcase the improvement in generalization capability achieved by incorporating the FOOGD method into the existing federated learning approaches (FedAvg and FedRoD).
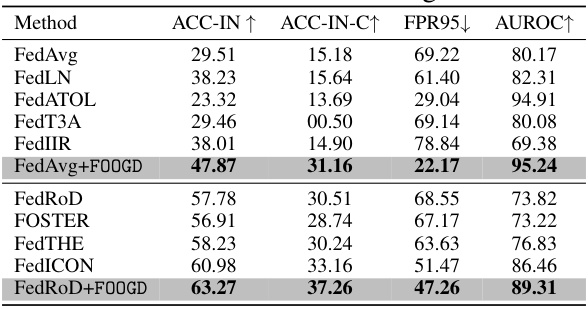
This table presents the main results of the proposed FOOGD method and several baseline methods on the TinyImageNet dataset. The metrics used for evaluation include accuracy on in-distribution (IN) data, accuracy on covariate-shift (IN-C) data, false positive rate at 95% true positive rate (FPR95), and area under the receiver operating characteristic curve (AUROC). The results demonstrate the effectiveness of FOOGD for both OOD generalization and OOD detection, outperforming various baseline methods.

This table presents the ablation study results on the Cifar10 dataset using FedAvg, varying the non-IID degree (α). It shows the impact of removing key components of FOOGD (SM³D and SAG) on the model’s performance across different non-IID settings. The metrics ACC-IN, ACC-IN-C, FPR95, and AUROC are evaluated to assess the model’s performance in terms of in-distribution accuracy, out-of-distribution generalization, false positive rate, and area under the ROC curve, respectively.

This table presents the ablation study results on the Cifar100 dataset using FedAvg, varying the non-IID degree α (0.1, 0.5, and 5.0). It shows the impact of removing key components of the FOOGD method (SM³D and SAG) on the model’s performance across different metrics including ACC-IN (in-distribution accuracy), ACC-IN-C (in-distribution covariate shift accuracy), FPR95 (false positive rate at 95% true positive rate), and AUROC (area under the receiver operating characteristic curve). By comparing the results across different α values and with/without SM³D and SAG, the table demonstrates the effectiveness of each component in achieving robust performance under varying levels of data heterogeneity and out-of-distribution data.
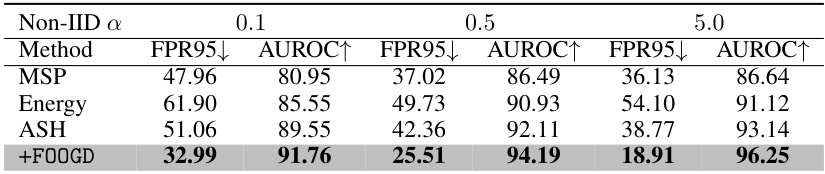
This table compares the performance of different outlier detection metrics (MSP, Energy, ASH) against the proposed FOOGD method on the CIFAR-10 dataset under varying non-IID settings (α = 0.1, 0.5, and 5.0). It shows the False Positive Rate at 95% true positive rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for each metric, highlighting the superior performance of FOOGD in terms of lower FPR95 and higher AUROC, indicating improved outlier detection accuracy.
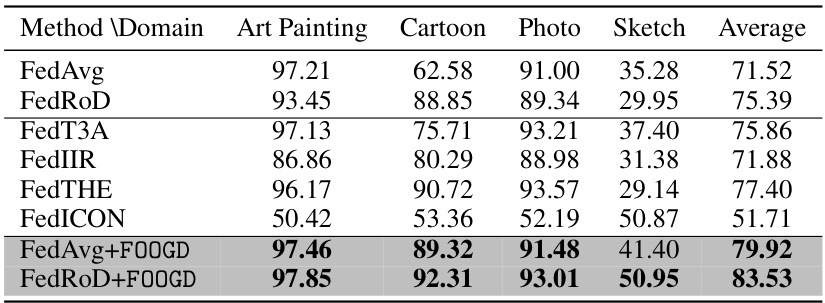
This table presents the results of out-of-distribution (OOD) generalization experiments conducted on the PACS dataset. The results are broken down by domain (Art, Painting, Cartoon, Photo, Sketch), showing the average accuracy for several federated learning methods. The table compares the performance of standard methods (FedAvg, FedRoD, FedT3A, FedIIR, FedTHE, and FedICON) against the proposed method (FOOGD) when combined with FedAvg and FedRoD. The average accuracy across all domains is also shown for each method.

This table presents the results of out-of-distribution (OOD) detection experiments conducted on the CIFAR-10 dataset with a non-IID data distribution parameter α set to 0.1. It compares the performance of various federated learning methods in detecting OOD data from different sources (ISUN, SVHN, LSUN-R, Texture). The metrics used for evaluation are the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic Curve (AUROC), both of which are commonly used to assess the effectiveness of OOD detection.

This table presents the performance comparison of different federated learning methods for out-of-distribution (OOD) generalization and detection on the CIFAR-10 dataset. The metrics reported include the accuracy on in-distribution (IN) data (ACC-IN), the accuracy on covariate-shift in-distribution (IN-C) data (ACC-IN-C), the false positive rate at 95% true positive rate (FPR95), and the area under the receiver operating characteristic curve (AUROC). The results are broken down by different levels of non-IID data distribution (α = 0.1, 0.5, 5.0), showing the impact of data heterogeneity on the performance of the various methods. The methods compared include several baseline federated learning techniques as well as the proposed FOOGD method, highlighting its superior performance.
This table presents the main results of the proposed FOOGD method and several baseline methods on the Cifar10 dataset. The performance is evaluated across three levels of non-IID data distribution (α = 0.1, 0.5, 5.0) and three metrics: accuracy on in-distribution (IN) data, accuracy on covariate-shift in-distribution (IN-C) data (using brightness as a proxy), false positive rate at 95% true positive rate (FPR95), and area under the ROC curve (AUROC) for out-of-distribution (OUT) data (using LSUN-C as OUT). The table highlights the improvement achieved by FOOGD in terms of generalization and detection compared to the baseline methods.

This table presents the performance comparison of different federated learning methods on CIFAR-10 dataset. It evaluates the performance in terms of accuracy on in-distribution (IN) data, accuracy on covariate-shift in-distribution (IN-C) data, false positive rate at 95% true positive rate (FPR95), and area under the ROC curve (AUROC) for out-of-distribution (OUT) data. The results are shown for different levels of non-IID data distribution among clients (alpha = 0.1, 0.5, 5.0).

This table presents the performance comparison of different federated learning methods on the CIFAR-10 dataset in terms of in-distribution accuracy (ACC-IN), out-of-distribution generalization accuracy (ACC-IN-C), and out-of-distribution detection performance (FPR95 and AUROC). The results are categorized by the non-IID degree (α) which represents the level of data heterogeneity among clients.
Full paper#