↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-agent reinforcement learning (MARL) often struggles with the challenge of agents learning similar behaviors when sharing policy network parameters. This homogeneity hinders exploration and limits overall performance. Existing methods attempting to increase diversity through maximizing mutual information between trajectories and agent identities often suffer from inefficient exploration.
This paper introduces Contrastive Trajectory Representation (CTR), a novel method that addresses this limitation. CTR leverages contrastive learning to create distinguishable trajectory representations, encouraging diverse policies without sacrificing exploration efficiency. Experiments on various cooperative tasks demonstrate CTR’s significant performance improvement over state-of-the-art methods, showcasing its potential for more robust and scalable multi-agent systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for MARL researchers seeking to enhance multi-agent cooperation. It introduces a novel solution to the common problem of homogeneous agent behaviors in shared-policy networks, significantly improving performance and opening avenues for more efficient exploration. Its impact extends to various cooperative multi-agent tasks, particularly in complex scenarios with partial observability.
Visual Insights#

This figure illustrates the architecture of the Contrastive Trajectory Representation (CTR) model. The model consists of three main components: an encoder, an autoregressive model, and a contrastive learning module. The encoder maps the observation and action sequences of an agent to a latent representation. The autoregressive model then summarizes these latent representations to generate a trajectory representation for each agent. Finally, the contrastive learning module encourages the learning of distinguishable trajectory representations by maximizing the mutual information between the trajectory representations and identity representations of different agents. The trajectory representations are visualized as points on a hypersphere, with points representing different agents being spaced apart.

This table presents a comparison of the average returns achieved by different multi-agent reinforcement learning algorithms across three benchmark environments: Pac-Men (a custom grid-world environment), SMAC (StarCraft Multi-Agent Challenge), and SMACv2 (an upgraded version of SMAC). The algorithms compared include QMIX, MAPPO, MAVEN, EOI, QTRAN, SCDS, LIPO, FOX, and the proposed CTR method integrated with both QMIX and MAPPO. The results are averaged over five random seeds, with standard deviations reported to indicate variability. The table provides quantitative comparisons of algorithm performance across different levels of task difficulty (easy, hard, super hard).
In-depth insights#
Contrastive MARL#
Contrastive multi-agent reinforcement learning (MARL) tackles the challenge of agent homogeneity in cooperative settings where parameter sharing leads to similar agent behaviors. Contrastive methods, inspired by contrastive learning in representation learning, aim to improve multi-agent diversity by learning distinguishable trajectory representations. Instead of maximizing mutual information between trajectories and identities, contrastive approaches focus on creating an embedding space where trajectories of different agents are distinctly separated. This approach could improve exploration efficiency by encouraging agents to explore less-visited states. A key aspect of contrastive MARL is the use of contrastive loss functions, which encourage similar trajectories from the same agent to cluster together while pushing apart those of different agents. This leads to more varied policies, thereby enhancing overall performance in complex cooperative scenarios. Scalability may be an important factor to consider. While promising, challenges remain in fully decentralized applications and handling large numbers of agents effectively.
CTR Architecture#
The CTR (Contrastive Trajectory Representation) architecture is a novel framework designed to enhance multi-agent diversity in reinforcement learning by learning distinguishable trajectory representations. It leverages an encoder to map agent observations and actions into a latent space, followed by an autoregressive model that processes these latent representations to generate a comprehensive trajectory representation. Contrastive learning is then applied, comparing the trajectory representation to a learnable identity representation for each agent, maximizing the mutual information between them and enforcing distinguishable features among agents. This framework promotes exploration by encouraging agents to venture beyond repeatedly visited trajectories, ultimately leading to improved collaborative performance and overcoming the limitations of existing approaches that focus on simply maximizing mutual information between trajectories and identities. The encoder and autoregressive model work synergistically to capture both the immediate and historical context of the agent’s trajectory, enriching the representation. The contrastive learning component is crucial in driving diversity and effective exploration by pushing trajectory representations apart in the latent space, thereby addressing the homogeneity problem often observed in centralized multi-agent reinforcement learning setups. This overall design allows for the learning of diverse and exploratory policies while ensuring efficient exploration and overcoming the overfitting issue often associated with mutual-information based approaches.
SMAC Experiments#
The SMAC (StarCraft Multi-Agent Challenge) experiments section of a reinforcement learning research paper would likely detail the application of a novel algorithm to the benchmark SMAC environment. A thorough analysis would involve a description of the specific SMAC scenarios used (likely varying in difficulty), the performance metrics employed (e.g., win rate, reward, efficiency), and a comparison against established baselines. Key aspects to look for would include the methodology for agent training, including hyperparameters and training duration. The results section should present quantitative data showing the algorithm’s performance across different scenarios, including error bars to assess statistical significance. Crucially, any claims of superiority need to be supported by statistically robust evidence. A strong section would go beyond raw performance numbers, analyzing qualitative observations of agent behavior, providing insights into the algorithm’s strengths and limitations within the complex, dynamic SMAC setting. Finally, it should discuss the scalability and adaptability of the algorithm with varying numbers of agents and map sizes within SMAC.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, it would involve removing different parts of the proposed Contrastive Trajectory Representation (CTR) method to isolate the effects of each component. The key components to remove would likely include the autoregressive model, the identity representation, and the contrastive learning loss itself. By comparing the performance of the full CTR model to these ablated versions, the researchers can determine how each component influences multi-agent diversity and overall performance. The results would ideally show that each component plays a significant role, highlighting the efficacy of the proposed CTR method. Furthermore, variations in the experimental setup of the contrastive loss could be explored, for example, changing the number of negative samples used. A comprehensive ablation study provides strong evidence for the design choices made in developing the CTR model, ultimately strengthening the paper’s conclusions.
Future Works#
The authors acknowledge the limitations of their centralized contrastive learning approach and propose several avenues for future work. Decentralized implementations are crucial for scalability and applicability to larger multi-agent systems. Further research should investigate alternative methods for handling the large number of negative samples required in contrastive learning, perhaps exploring more efficient sampling techniques or different loss functions altogether. Addressing the need for homogeneous behaviors in certain scenarios is also important; future work could focus on developing methods to dynamically balance diversity and homogeneity, adapting to task demands. Finally, exploring how the CTR method interacts with other techniques for improving MARL, such as curriculum learning or hierarchical reinforcement learning, could lead to significant performance gains. Extending CTR to handle continuous action spaces and more complex reward structures would broaden its applicability to a wider range of real-world problems.
More visual insights#
More on figures
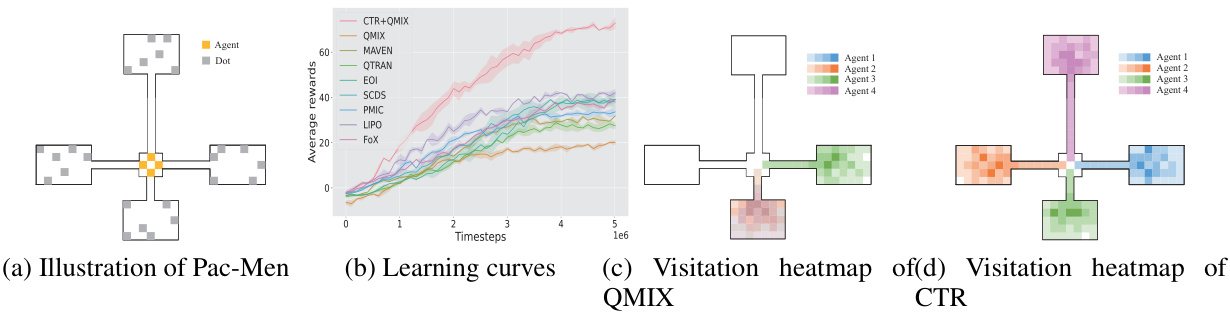
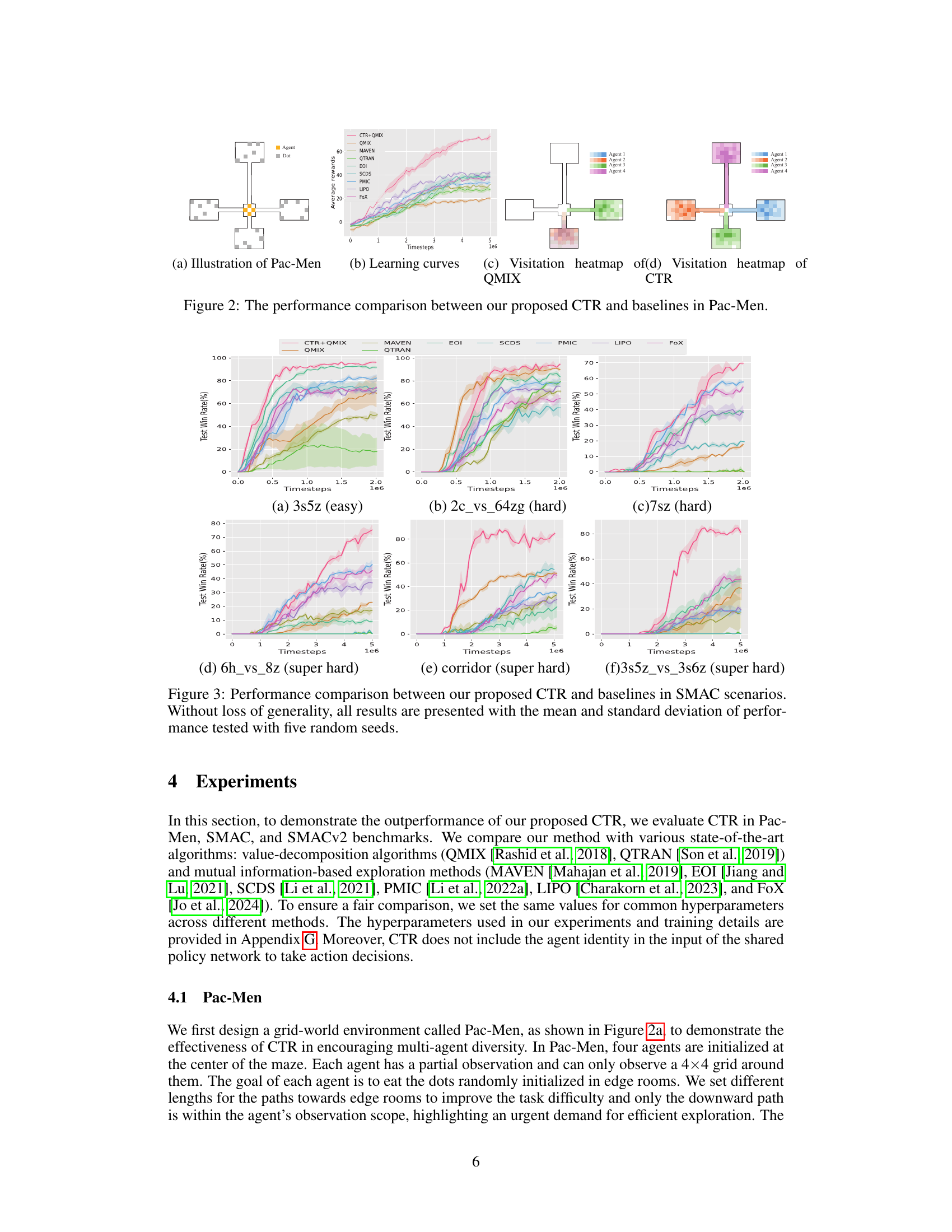
This figure shows the results of the Pac-Men experiment, comparing the performance of CTR with other baselines. Subfigure (a) illustrates the Pac-Men environment. Subfigure (b) presents learning curves, showing the average rewards over time for each algorithm. Subfigures (c) and (d) display visitation heatmaps for QMIX and CTR respectively. These heatmaps visualize where agents tend to explore the environment, highlighting the diversity promoted by CTR.
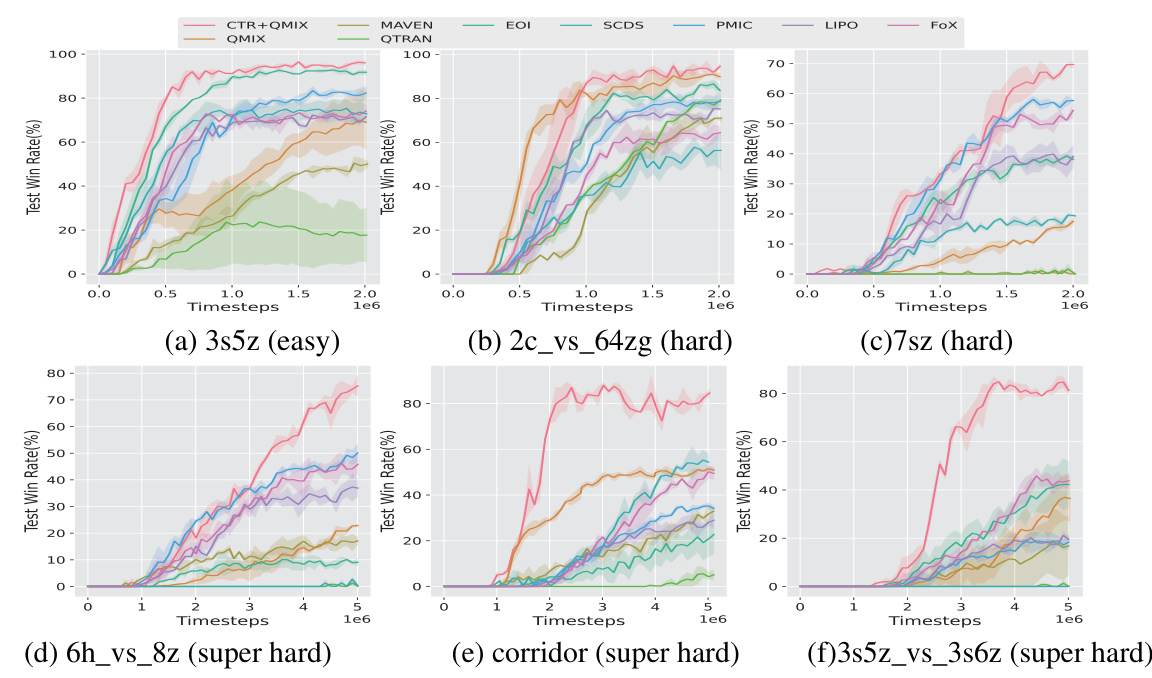
This figure compares the performance of the proposed CTR method with several baselines across six different StarCraft Multi-Agent Challenge (SMAC) scenarios. The scenarios range in difficulty from easy (3s5z) to super hard (6h_vs_8z, corridor, 3s5z_vs_3s6z). The results show that CTR consistently outperforms the baselines, particularly in the more challenging scenarios, suggesting that CTR is more effective at promoting multi-agent diversity and efficient exploration. The mean and standard deviation are shown for each scenario, based on five independent runs with different random seeds. The x-axis represents the number of timesteps during training, while the y-axis shows the test win rate.
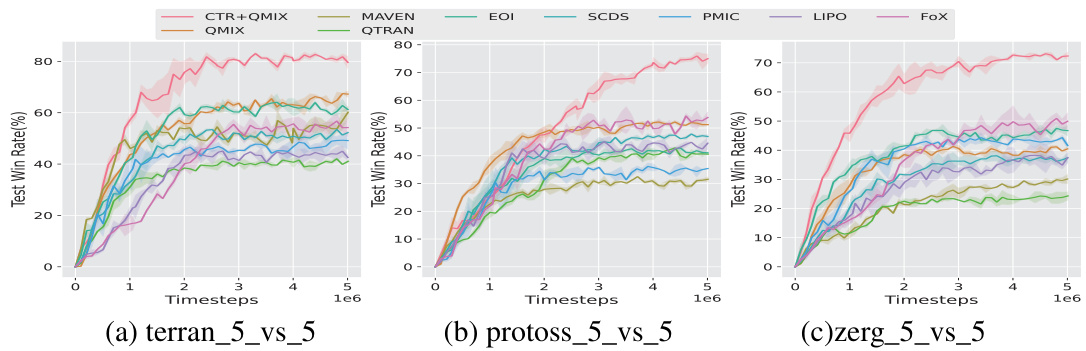
This figure compares the performance of CTR+QMIX against several other multi-agent reinforcement learning algorithms across three SMACv2 scenarios: terran_5_vs_5, protoss_5_vs_5, and zerg_5_vs_5. Each graph plots the test win rate (%) over time (timesteps) for each algorithm. The shaded area represents the standard deviation across multiple trials. This figure shows that CTR+QMIX generally outperforms the baselines in all three scenarios, highlighting its effectiveness in cooperative multi-agent tasks.

This figure visualizes the visitation heatmaps of different algorithms (MAVEN, EOI, SCDS, LIPO, FoX, and CTR+QMIX) in the terran_5_vs_5 scenario of SMACv2. The heatmaps illustrate where agents tend to concentrate their actions during gameplay. The purpose is to demonstrate the impact of each algorithm on exploration and diversity of agent behavior. Specifically, it shows whether agents explore the map effectively or get stuck in repetitive actions. The CTR+QMIX heatmap is expected to show a more even distribution of visits across the map, indicating better exploration compared to the other methods.
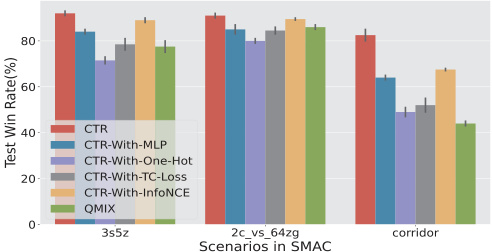
This figure shows the ablation study results on the SMAC benchmark. It compares the performance of the main CTR model against several variants where key components (autoregressive model, identity representation, and contrastive learning loss) have been removed or altered. The results demonstrate the importance of each component to the overall performance of the CTR method, highlighting the contribution of each element towards achieving better results compared to the baseline QMIX model.

This figure uses t-distributed stochastic neighbor embedding (t-SNE) to visualize the trajectory representations learned by different variants of the Contrastive Trajectory Representation (CTR) method and the baseline QMIX in the corridor scenario of the StarCraft Multi-Agent Challenge (SMAC). Each color represents a different agent. The visualization shows how the different methods result in different levels of distinguishability among trajectory representations. The CTR method, specifically, shows a clear separation of agents, indicative of its success in encouraging multi-agent diversity.

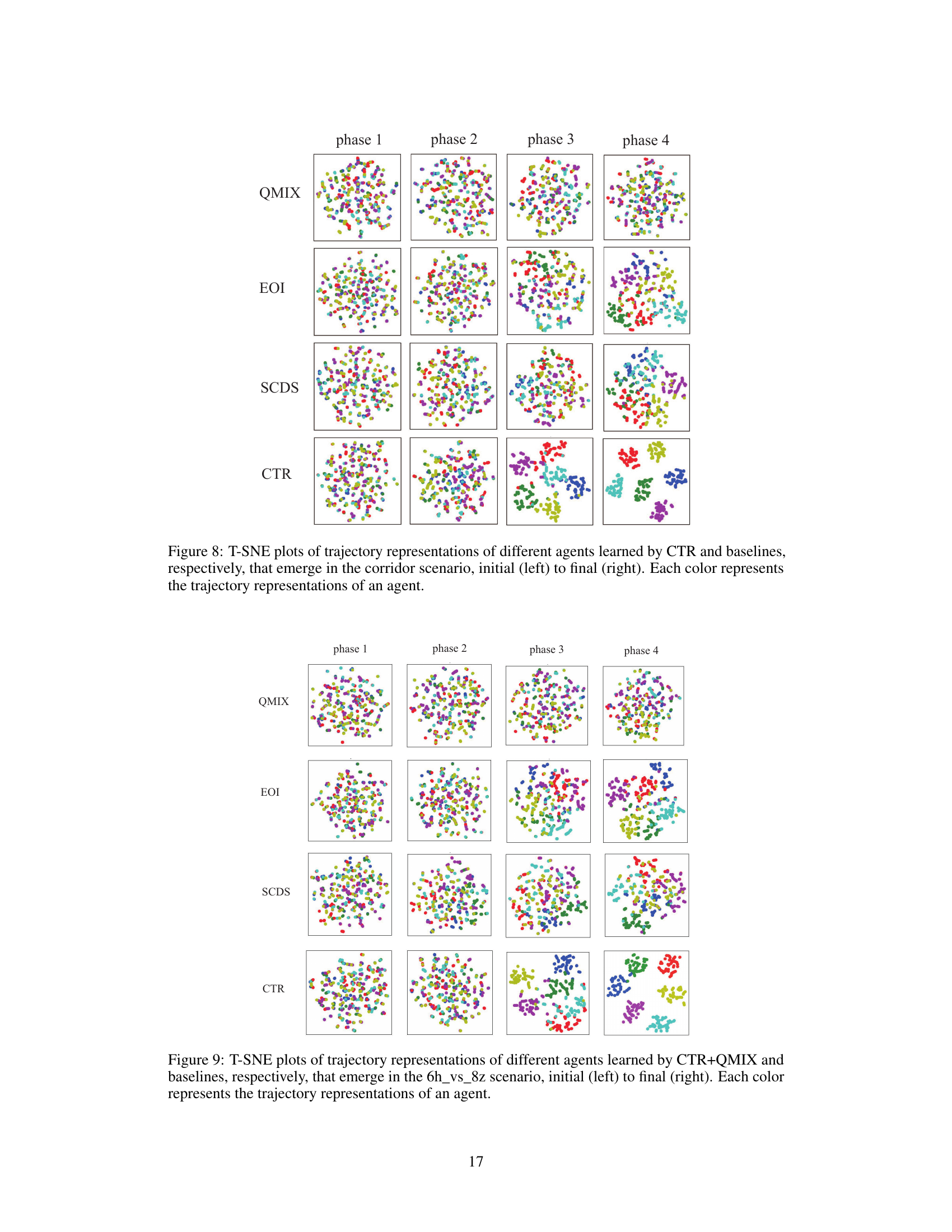
This figure shows the visualization of trajectory representations learned by different algorithms in the corridor scenario of SMAC. It uses t-SNE to reduce the dimensionality of the trajectory representations to two dimensions for visualization. Each point represents a trajectory, and each color represents a different agent. The figure is organized as a grid, with each row representing a different algorithm (QMIX, EOI, SCDS, and CTR), and each column representing a different phase of the game (from initial to final). The visualization helps to understand how the trajectory representations evolve over time and how they differ for different agents and algorithms. It provides evidence to support the claim that CTR leads to more distinguishable trajectory representations for different agents, especially compared to baselines like QMIX, EOI, and SCDS, which show more mixing of trajectories from different agents.

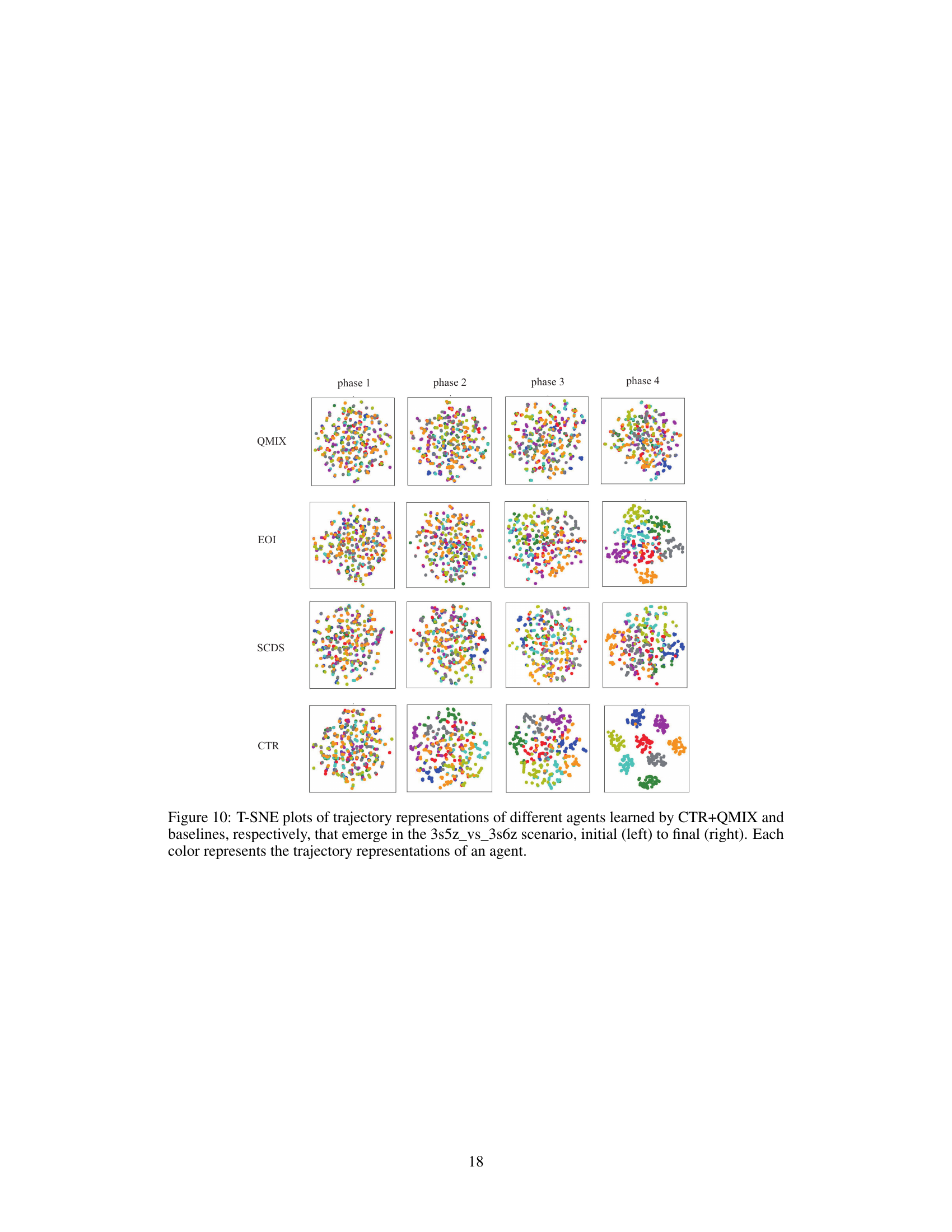
This figure shows the trajectory representations of different agents in the corridor scenario of SMAC, visualized using t-SNE. It compares the trajectory representations learned by CTR with those from QMIX, EOI, and SCDS. The four columns represent different phases of the game (initial to final), and each color represents a different agent. The visualization aims to demonstrate how CTR creates more distinguishable trajectory representations among agents compared to the baselines. The distinct clustering of points in the CTR plots shows that CTR generates more diverse and separable trajectory representations leading to more efficient exploration compared to the baseline methods.
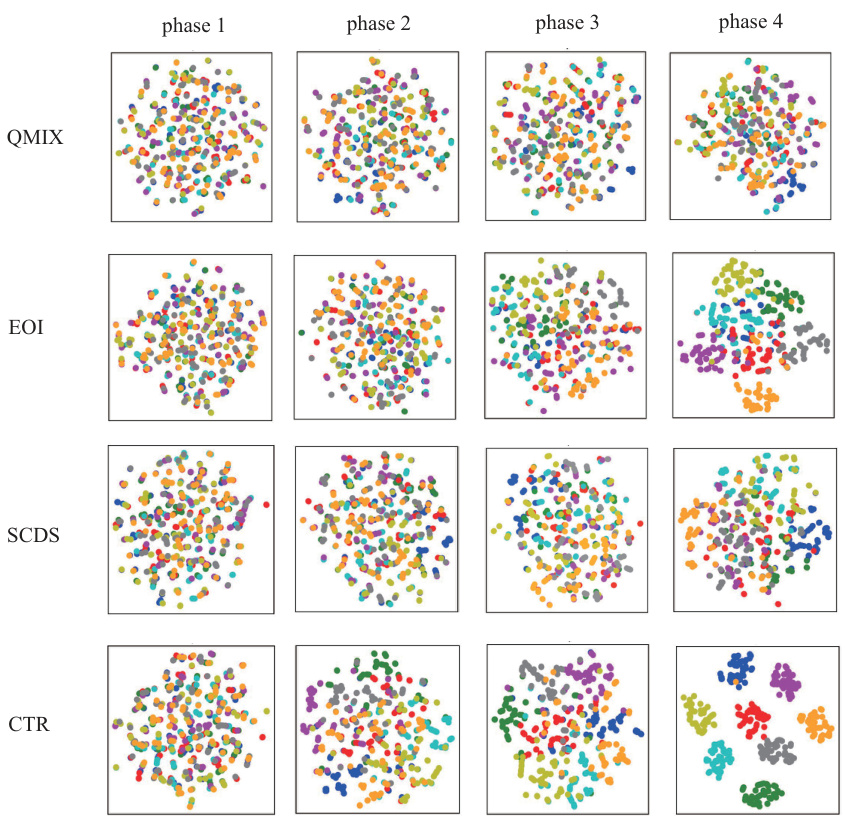
This figure shows the visualization of trajectory representations using t-SNE for different agents trained by four different methods (QMIX, EOI, SCDS, and CTR). The visualization is shown for four different phases (phase 1 to phase 4) of the training process in the corridor scenario. Each color represents an individual agent. The plots illustrate how the trajectory representations of different agents evolve over time and how well separated they are by each method. The figure aims to demonstrate the effectiveness of CTR in creating distinguishable trajectory representations compared to baselines.

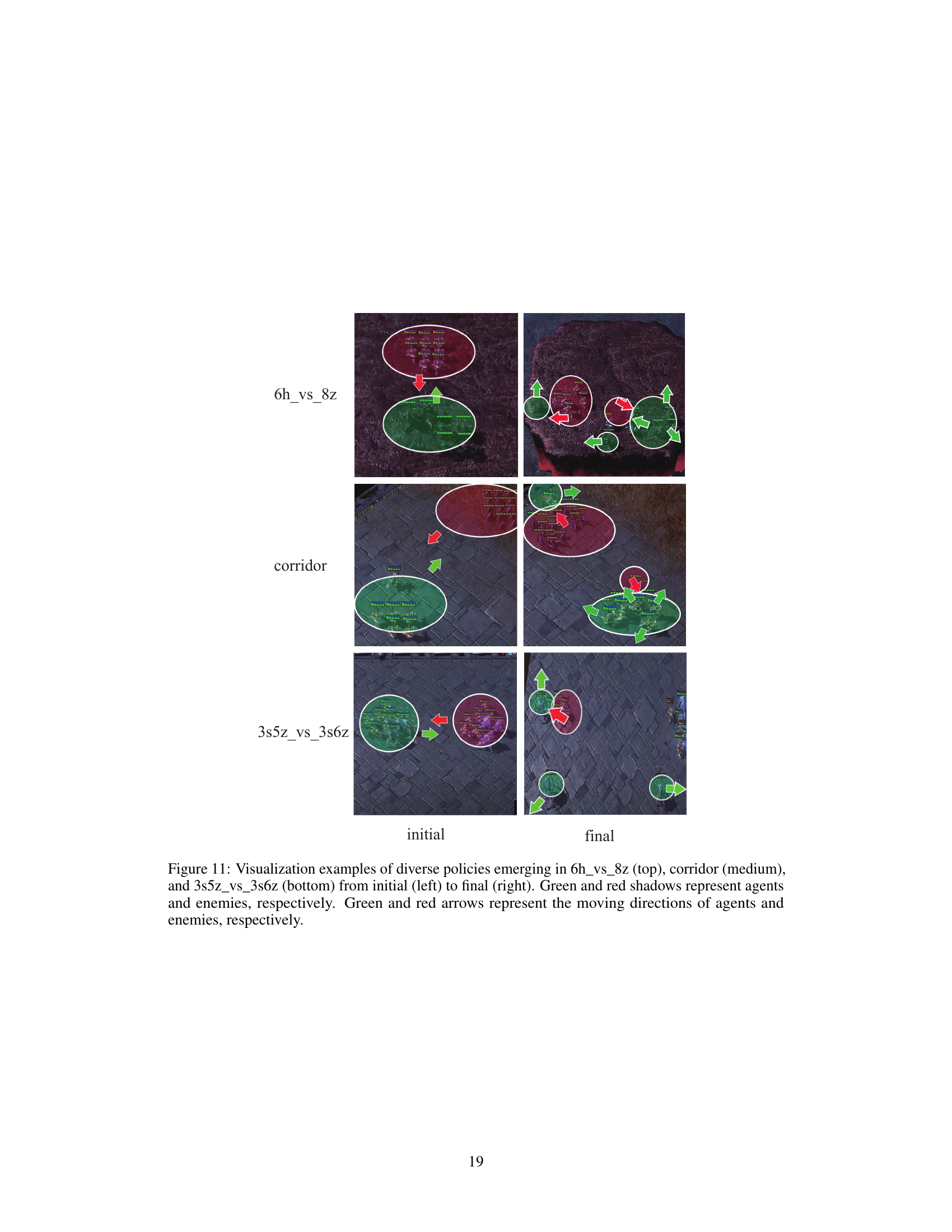
This figure visualizes examples of diverse policies learned by the CTR model in three different SMAC scenarios. It shows the initial and final states of each scenario, highlighting the different strategies employed by the agents to defeat the enemies. Green represents the agents and red represents enemies. Arrows indicate their moving directions. The diverse policies demonstrate the effectiveness of CTR in encouraging multi-agent diversity and efficient exploration.
More on tables
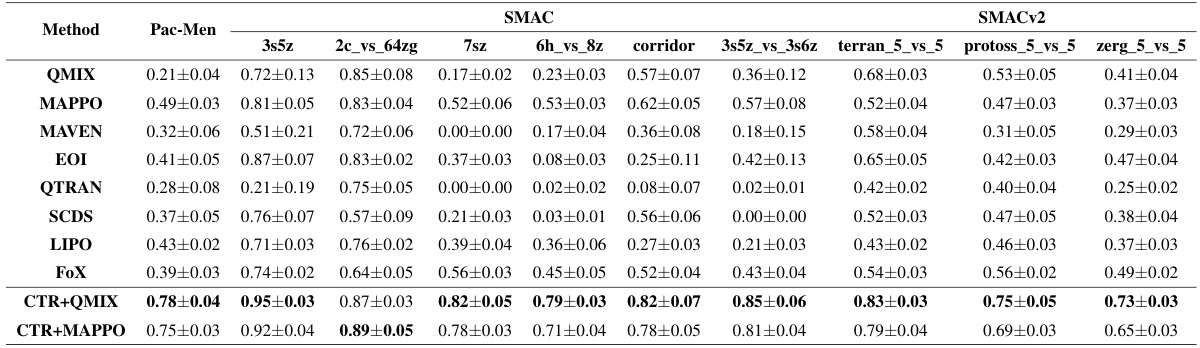
This table presents the average returns achieved by different multi-agent reinforcement learning algorithms across three environments: Pac-Men, SMAC, and SMACv2. The results show the mean performance and standard deviation for each algorithm across five independent runs with different random seeds. Pac-Men is a simpler grid-world environment designed for this paper, while SMAC (StarCraft Multi-Agent Challenge) and SMACv2 are well-known benchmarks for cooperative MARL. The table allows readers to directly compare the performance of the proposed CTR method (CTR+QMIX and CTR+MAPPO) against several state-of-the-art baselines across a variety of task complexities.

This table compares the performance of CTR+QMIX and QMIX in four homogeneous StarCraft II scenarios where agents benefit from using similar policies (focus fire). The scenarios vary in the number of units on each team, demonstrating the effectiveness of CTR even when homogeneous strategies are optimal. The results show CTR+QMIX consistently outperforms QMIX in these scenarios.

This table presents the performance comparison between CTR+QMIX and QMIX in four SMACv2 scenarios with varying numbers of agents (5 vs 5, 10 vs 10, 15 vs 15, and 20 vs 20). It demonstrates the scalability of the CTR method, showing that it maintains high performance even with a significant increase in the number of agents, whereas QMIX’s performance declines dramatically.

This table lists the hyperparameters used in the experiments for the Pac-Men, SMAC, and SMACv2 environments. It shows the settings for hidden dimension, learning rate, optimizer, target update frequency, batch size, and the alpha (α) values for the contrastive learning loss in both CTR+QMIX and CTR+MAPPO. The epsilon annealing time is also specified for each environment.
Full paper#