↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current deep learning models for change detection require large-scale labeled training data, hindering generalization to new change types and data distributions. This limitation necessitates the development of zero-shot change detection models which can generalize across unseen scenarios. This is a challenging problem in remote sensing and related fields due to the high cost of acquiring and labeling relevant datasets.
The proposed AnyChange model addresses this issue by using a training-free approach. It leverages the Segment Anything Model (SAM) and introduces a novel bitemporal latent matching technique. By revealing and exploiting semantic similarities within and between images, AnyChange enables SAM to perform zero-shot change detection. Extensive experiments demonstrate that AnyChange significantly outperforms existing methods on multiple benchmark datasets, achieving a new state-of-the-art. The model also features a point query mechanism for object-centric change detection.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in remote sensing and computer vision. It presents AnyChange, the first zero-shot change detection model, significantly advancing the field by enabling generalization to unseen change types and data distributions. This opens up new avenues for research in training-free adaptation methods and label-efficient supervised learning, impacting diverse applications like environmental monitoring and disaster assessment.
Visual Insights#
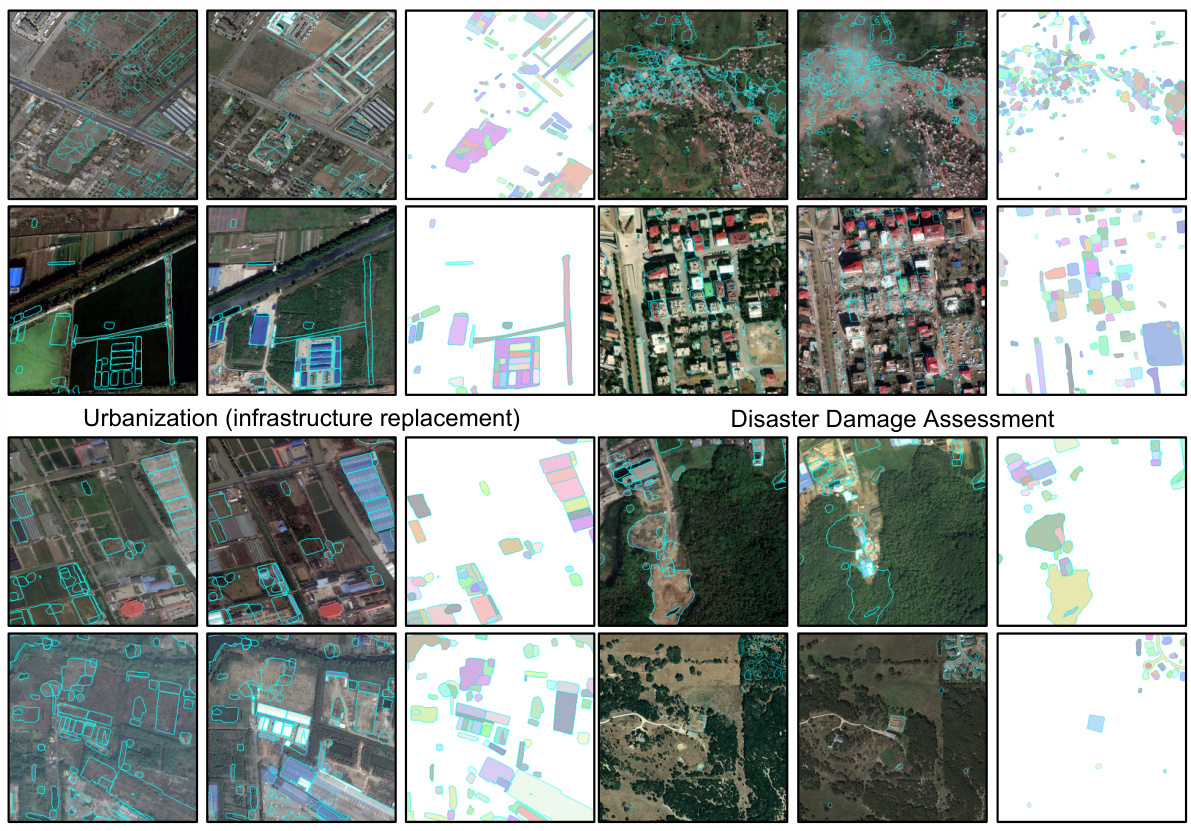
This figure showcases the AnyChange model’s zero-shot change detection capabilities across various real-world applications. Each row displays a different application (e.g., urbanization, disaster assessment), with three columns showing the before image, the after image, and a mask highlighting the changes detected. The cyan outlines on the images visually delineate the change areas, while the colored masks within the change areas differentiate individual changed objects.

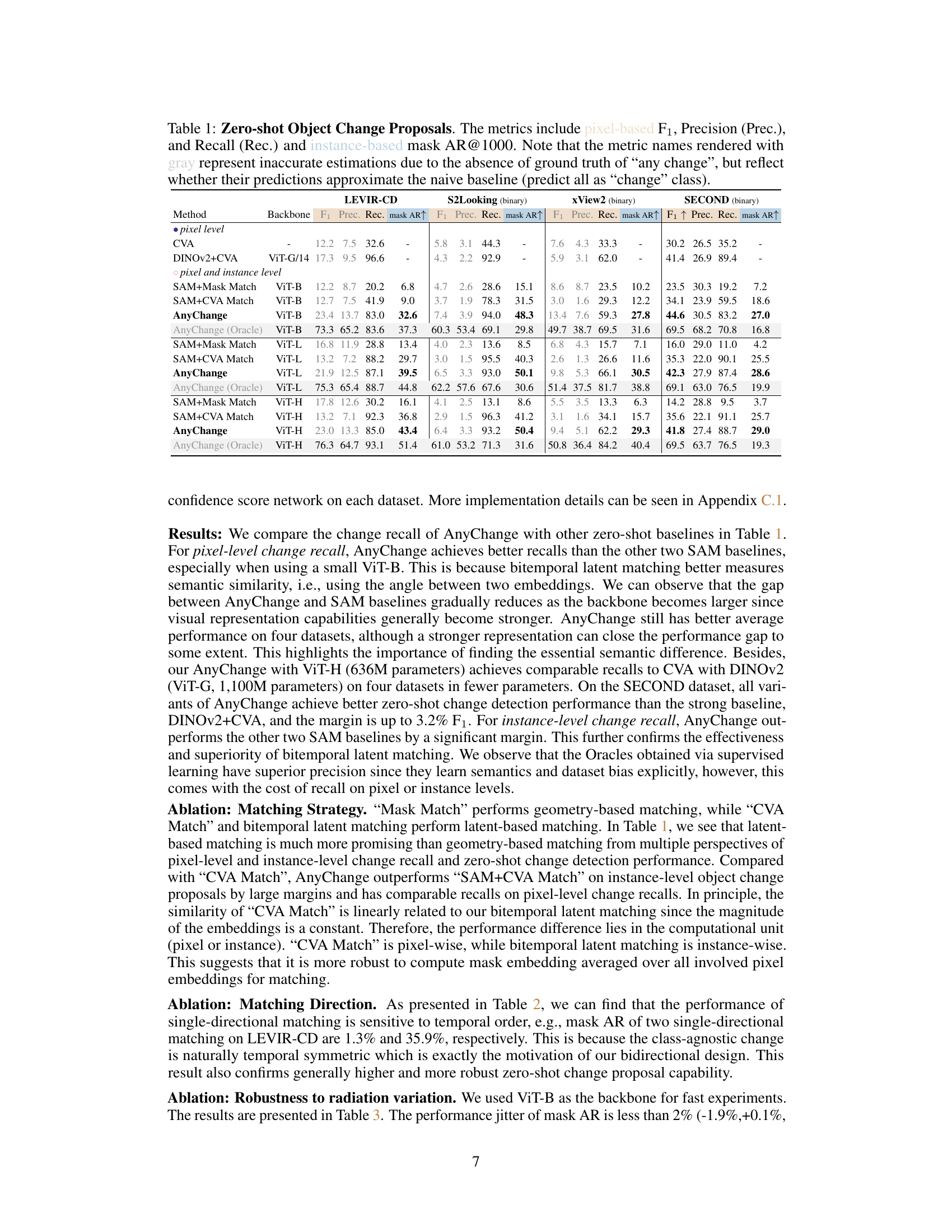
This table presents the results of zero-shot object change proposal experiments on four datasets (LEVIR-CD, S2Looking, xView2, SECOND). It compares the performance of AnyChange against several baseline methods (CVA, DINOV2+CVA, SAM+Mask Match, SAM+CVA Match) across different backbone models (ViT-B, ViT-L, ViT-H). The evaluation metrics include pixel-level F1 score, precision, recall, and instance-level mask Average Recall at 1000 (AR@1000). Metrics shaded gray indicate less reliable estimates due to the lack of ground truth for ‘any change’ but help assess whether model predictions are close to the naive approach of labelling everything as changed or unchanged.
In-depth insights#
Zero-Shot Change#
The concept of “Zero-Shot Change” in the context of a research paper likely refers to a model’s ability to detect changes between images without explicit training on those specific change types. This is a significant advancement because traditional change detection methods heavily rely on large labeled datasets of various change instances. A zero-shot capable model would generalize to unseen change scenarios, offering flexibility and efficiency. The core challenge lies in designing model architectures and training strategies that enable this generalization. The success of a zero-shot change detection model hinges upon the ability to extract and learn robust features representative of ‘change’ itself, irrespective of the specific nature of the change. This might involve leveraging pre-trained models and transfer learning to leverage existing knowledge about image features, or employing innovative techniques to capture semantic similarities across diverse image pairs. The evaluation of such a model requires careful selection of benchmarks and metrics that can comprehensively assess performance in various zero-shot situations. Ultimately, the implications of a successful zero-shot change detection system are significant, promising streamlined workflows and wider applicability in remote sensing, medical imaging and other domains.
Bitemporal Latent#
The concept of “Bitemporal Latent Matching” suggests a novel approach to change detection in image sequences. It leverages the latent space of a pre-trained model, likely a vision transformer like the Segment Anything Model (SAM), to identify changes without explicit training on change detection data. The core idea is to compare latent representations (embeddings) of image regions from two different time points. Instead of relying on pixel-level differences, which can be sensitive to noise, the method focuses on semantic similarities, thereby enabling robust zero-shot generalization to various change types. By revealing and exploiting intra- and inter-image semantic similarities in the latent space, this technique endows the model with the ability to detect change instances in a training-free way. The success of this approach hinges on the quality of the latent representations: they must capture high-level semantic information that is stable across different time points and robust to minor variations. The effectiveness likely depends on both the model’s architecture and the quality of the pre-training data, as well as the employed similarity metric.
Point Query#
The ‘Point Query’ mechanism significantly enhances the AnyChange model, enabling object-centric change detection. Instead of generating class-agnostic change masks, which might include irrelevant changes, this method allows users to interactively guide the model by specifying points of interest. This focuses the change detection process on specific objects, drastically improving precision by filtering out unrelated changes. By leveraging SAM’s point prompt capability, it seamlessly integrates with AnyChange’s bitemporal latent matching. The effectiveness is demonstrated through experiments showing substantial improvement in F1 score when a point query is used. This interactive functionality makes AnyChange far more practical for real-world applications requiring precise object-level change analysis, such as disaster damage assessment, where the user can quickly specify areas of interest for detailed inspection. This interactive capability bridging the gap between fully automated class-agnostic change detection and precise interactive object-level analysis positions AnyChange as a highly adaptable tool for various change detection tasks.
AnyChange Model#
The AnyChange model presents a novel approach to zero-shot change detection, a significant advancement in remote sensing image analysis. Its training-free adaptation method, bitemporal latent matching, leverages semantic similarities within and between images in the latent space of the Segment Anything Model (SAM), enabling zero-shot generalization to unseen change types and data distributions. This is a crucial departure from traditional methods that rely on extensive training data for specific change types, offering a highly efficient and flexible solution. The model’s capability to handle both pixel-level and instance-level change detection, along with its object-centric change detection via a point query mechanism, further enhances its versatility and usability. AnyChange demonstrates superior performance on established benchmarks, highlighting its potential to revolutionize various applications needing change detection in remote sensing, notably in geoscience and disaster management. The model’s training-free nature also reduces computational costs and annotation efforts, making it more accessible and impactful.
Future Directions#
Future research could explore enhancing AnyChange’s capabilities for handling diverse data modalities beyond imagery, such as incorporating LiDAR or multispectral data for a more robust change detection system. Improving the model’s ability to discern subtle changes, particularly in scenarios with low resolution or significant variations in lighting and weather conditions, is crucial. Investigating different latent matching techniques and exploring advanced architectures could further enhance the zero-shot generalization capabilities. Developing methods for uncertainty quantification in the predicted change masks would increase the reliability of AnyChange and build user trust. Finally, research should focus on addressing the potential biases inherited from the foundation model and devising strategies to mitigate these biases for fair and equitable applications, broadening the applicability of this promising technique.
More visual insights#
More on figures
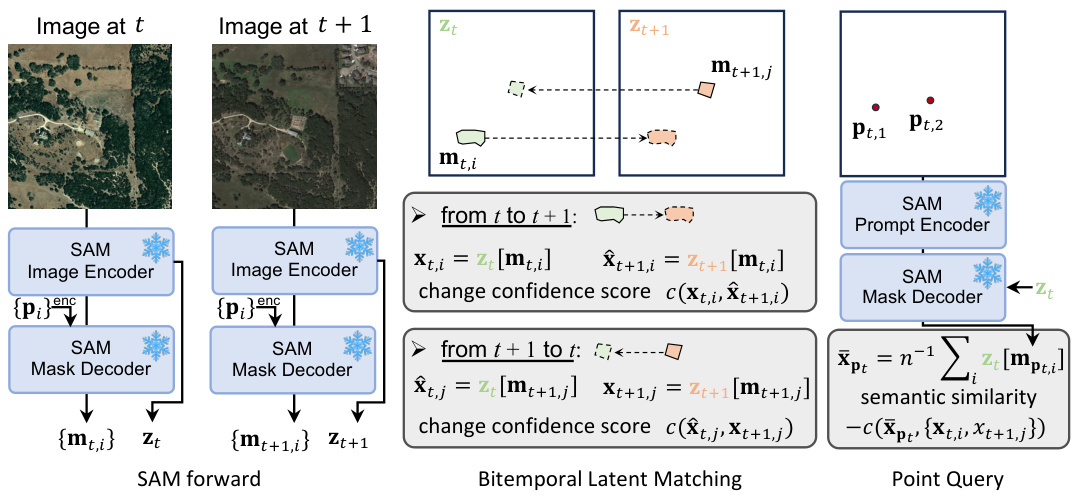
This figure illustrates the AnyChange model’s architecture. It shows how the Segment Anything Model (SAM) is used as a base, with bitemporal latent matching for zero-shot change detection and a point query mechanism for object-centric change detection. The process begins with SAM processing the images to produce object masks and image embeddings. Then, a bidirectional matching step (bitemporal latent matching) compares the embeddings to assess the change confidence score for each proposed change. This is followed by a top-k selection or thresholding for change detection. Finally, a point query mechanism allows users to select specific areas of interest, which helps refine the change detection results by leveraging semantic similarities to filter class-agnostic masks and pinpoint object-centric changes.

This figure provides empirical evidence supporting the existence of semantic similarities within and between satellite images at different times. Part (a) shows intra-image similarity using PCA visualization and point queries on a single image to demonstrate that objects of the same category have similar embeddings in SAM’s latent space. Part (b) shows inter-image similarity by using object proposals from one image as queries to match proposals in another image from the same location but at a different time, showing consistent results and semantic similarity persists even with temporal differences.

This figure provides empirical evidence supporting the existence of semantic similarities within and between satellite images at different times using the Segment Anything Model (SAM). The left panel (a) shows intra-image similarity, demonstrating how objects of the same category in a single image have similar representations in SAM’s latent space (visualized via PCA and a probing experiment). The right panel (b) shows inter-image similarity, demonstrating that object proposals from an image at one time point (t1) can be successfully matched to similar objects in an image from the same location at a different time point (t2). This similarity is crucial for the AnyChange model’s ability to perform zero-shot change detection.

This figure demonstrates the effectiveness of the point query mechanism in AnyChange. The leftmost column shows the images at time t and t+1, respectively. The remaining columns demonstrate how the change masks generated by AnyChange change with different numbers of point queries. When no point query is used (i.e., the second column), AnyChange generates class-agnostic change masks, which represent all types of change. Using point queries allows the model to focus on specific semantic objects of interest. As the number of point queries increases, the change masks become more accurate and focused on the objects that are specified using the point queries.

This figure showcases AnyChange’s zero-shot change detection capabilities across various geoscience applications. Each row displays a before image, an after image, and a corresponding change mask. The change mask highlights areas where changes have occurred, with different colors indicating distinct changes. The cyan outlines show the boundaries of these change areas clearly on the before and after images.

This figure demonstrates the impact of using point queries in the AnyChange model for object-centric change detection. It shows how the model’s output changes as the number of point queries increases, progressing from class-agnostic change masks (no point query) to more focused and accurate change detection as more point queries are used.

This figure demonstrates the point query mechanism of the AnyChange model. It shows how class-agnostic change masks (without a point query) can be refined to focus on object-centric changes by specifying points of interest. The left column displays pre-event imagery, the middle column displays post-event imagery, and the right column shows the corresponding change masks. The rows illustrate different query scenarios: no query, a single point query, and multiple point queries, demonstrating how the precision of change detection improves with additional semantic information from user-provided points.
More on tables

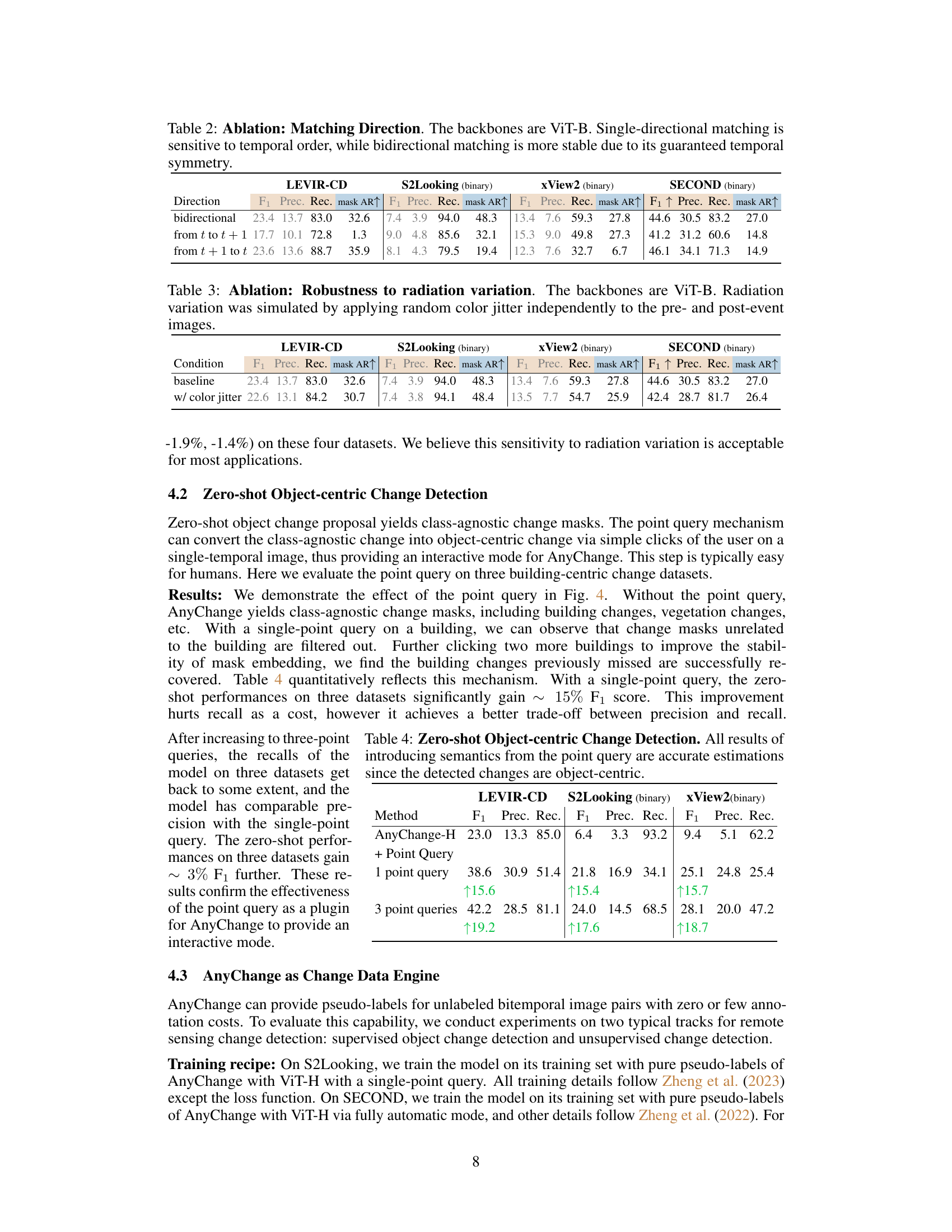
This table presents the ablation study of matching direction in the AnyChange model. It compares the performance of bidirectional matching against two single-directional matching strategies (from t to t+1 and from t+1 to t). The results show that bidirectional matching is more robust and achieves better performance across all four datasets (LEVIR-CD, S2Looking, xView2, and SECOND) and metrics (F1, Precision, Recall, and mask AR@1000). The superior performance of bidirectional matching is attributed to its inherent temporal symmetry, which is crucial for effectively capturing change events in bitemporal remote sensing images.

This ablation study demonstrates the robustness of the AnyChange model to variations in radiation. The table presents the performance metrics (F1 score, precision, recall, and mask AR@1000) across four different datasets (LEVIR-CD, S2Looking (binary), xView2 (binary), and SECOND (binary)). The ‘baseline’ row shows the results without any added radiation variation. The ‘w/ color jitter’ row shows the results with random color jitter applied to both pre- and post-event images, simulating radiation variations. The relatively small change in performance metrics indicates that AnyChange is robust to these variations.
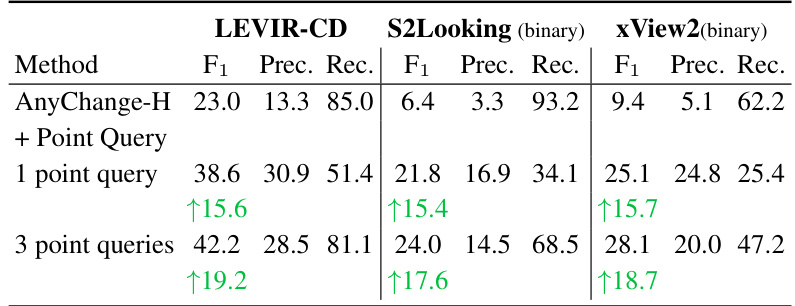
This table presents the results of zero-shot object-centric change detection experiments. It compares the performance of the AnyChange model with and without the point query mechanism. The metrics used are F1 score, precision, and recall for LEVIR-CD, S2Looking (binary), and xView2 (binary) datasets. The improvement in performance is shown when using one and three points as queries for object-centric change detection. The results show a significant gain in F1 score with the point query, but a trade-off between precision and recall when using a single point. Adding more points improves the recall and maintains the precision improvement.

This table compares the performance of AnyChange with other state-of-the-art change detection methods on the S2Looking dataset for supervised object change detection. It shows the F1 score, precision, recall, number of parameters, and floating point operations (FLOPs) for each method, along with the backbone network used (ResNet-18 or MiT-B1) and the amount of labeled pixels used for fine-tuning (100%, 1%, or 0.1%). AnyChange achieves comparable performance to models trained on 100% of the labeled data, while only using a very small fraction (3500 pixels).
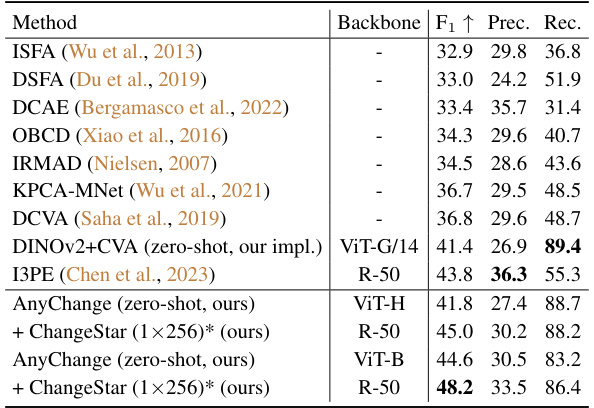
This table compares the performance of AnyChange with other state-of-the-art unsupervised change detection methods on the SECOND dataset. It shows the F1 score, precision, and recall for each method, highlighting AnyChange’s superior performance, especially when combined with ChangeStar. The table demonstrates AnyChange’s effectiveness as a zero-shot approach and also showcases the performance boost achievable by leveraging pseudo-labels generated by AnyChange for supervised training.
Full paper#