↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Diffusion models, while powerful, lack interpretable latent spaces like GANs, hindering fine-grained control. Existing personalization methods are computationally expensive, requiring tuning of the full model. This makes creating customized models difficult and limits their potential.
The paper proposes weights2weights (w2w), a novel method for modeling the weight space of fine-tuned diffusion models as a low-dimensional subspace. This enables three key applications: sampling (generating new models), editing (linearly manipulating attributes), and inversion (creating models from a single image). The w2w space is shown to be highly expressive, allowing for consistent identity generation, disentangled attribute editing, and robust handling of out-of-distribution images.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel approach to understand and manipulate the weight space of diffusion models, opening exciting avenues for model customization, editing, and generation of new models. This has significant implications for various applications, including image generation, editing, and personalization, making it a valuable resource for researchers in the field.
Visual Insights#

This figure illustrates the concept of weights2weights (w2w) space. It shows how a manifold of customized diffusion models can be represented as a subspace of weights. This subspace allows for three key operations: single image inversion (creating a model from a single image), identity editing (modifying an existing model), and sampling (generating new models with different instances of the same visual concept). Each operation consistently produces models that generate the intended subject.

This table presents a quantitative comparison of three different methods for editing identity attributes in images: prompting, Concept Sliders, and the proposed weights2weights (w2w) method. The comparison is based on three key metrics: ID Score (measuring identity preservation), LPIPS (measuring disentanglement), and CLIP Score (measuring semantic alignment). Higher ID Score and CLIP Score values are better while a lower LPIPS value is better. The table shows that the w2w method outperforms the other two methods across all three metrics for all the attributes tested (Gender, Chubby, Eyes). This demonstrates the superiority of the w2w approach in maintaining the identity while editing the attribute in a semantically meaningful and disentangled way.
In-depth insights#
w2w Space Intro#
The hypothetical “w2w Space Intro” section would ideally introduce the core concept of the weights2weights (w2w) space, a novel method for manipulating the weight space of diffusion models. It should highlight that w2w space is not a traditional latent space, but rather a meta-latent space that represents a manifold of pre-trained, customized diffusion models. The introduction should emphasize the controllability afforded by this space, showcasing how it enables the generation of entirely new models, editing existing ones by linearly traversing semantic directions within the space, and inverting single images into model weights, resulting in a new identity-encoding diffusion model. A key aspect would be explaining that the models in this space consistently generate variations of the target visual concept (e.g., identities, breeds), unlike single-image latent embeddings. Finally, the introduction should emphasize the innovative aspect of modeling the weight space itself, offering a new perspective on generative model manipulation, and suggesting the potential for broader applications in other visual domains.
Model Inversion#
Model inversion, within the context of generative models, is a crucial technique for understanding and manipulating the underlying latent spaces. The core idea revolves around mapping a given image or other data point back to its corresponding latent representation within the model’s learned space. This is inherently challenging because the mapping is often non-linear and high-dimensional, requiring sophisticated optimization strategies. Successful inversion unlocks several valuable applications. For instance, it enables editing of specific attributes of the input data by directly modifying the latent vector and regenerating the image. Further, model inversion can facilitate improved image generation by allowing control over specific aspects of the image beyond simple text prompts. However, the process is not always straightforward. Limitations include the computational cost of inversion and the potential for overfitting, producing results that are overly similar to the original data. Advanced techniques, such as regularization and constraints, can improve the robustness of the inversion method. The choice of inversion technique, the dimensionality of the latent space, and the complexity of the generative model itself all play critical roles in achieving accurate and faithful model inversion. The success of this method hinges on the power of the model and algorithm to capture the essential features of the data while being able to reconstruct an accurate representation in the latent space.
Edit Directions#
The concept of ‘Edit Directions’ in the context of a research paper on diffusion models likely refers to the identification and manipulation of latent space vectors that correspond to specific semantic attributes of generated images. These ‘directions’ are not randomly assigned but rather learned from data, potentially using techniques like linear classifiers or principal component analysis (PCA). Disentanglement is a crucial aspect, meaning these directions should ideally influence only a single attribute without significantly affecting others. The value of identifying such directions lies in the potential for fine-grained control over the generative process: to modify specific characteristics like adding a beard, changing hair color, altering facial expressions, etc., while keeping the underlying image representation largely consistent. The effectiveness of these methods depends heavily on the quality and diversity of the training data. The research likely explores the challenges in achieving true disentanglement in high-dimensional latent spaces and the trade-offs between fine-grained control and preserving the overall integrity and realism of the generated output. Interpretability is another significant goal — making the effects of each direction understandable and predictable.
Beyond Identity#
The heading ‘Beyond Identity’ suggests an exploration of the broader capabilities of the developed model beyond simply manipulating or generating human faces. This likely involves demonstrating the technique’s generalizability to other visual domains. The core idea is to show the method’s applicability to a wide variety of visual concepts, moving beyond the specific case of human identity. This could mean successfully applying the same methodology to different image categories, such as animals, objects, or even abstract art, demonstrating a more fundamental understanding of image manipulation at a latent level. The authors likely aim to highlight the model’s ability to create novel variations and edits within these diverse visual categories, demonstrating the technique’s potential as a general-purpose image generation and editing tool. This extension validates the robustness and flexibility of the underlying weight space manipulation technique, indicating its potential impact far beyond its initial application.
Future Work#
Future research directions stemming from this paper on interpreting the weight space of customized diffusion models could explore several promising avenues. Extending the weights2weights (w2w) framework to other visual modalities beyond images, such as video or 3D models, would significantly broaden its applicability and unlock new creative possibilities. Investigating the theoretical underpinnings of the w2w space is crucial to establish a stronger foundation for understanding its properties and limitations. This might involve formalizing the manifold structure, exploring its geometric properties, and developing analytical tools for better manipulation. Improving the efficiency of w2w space creation and inversion is essential for practical applications. Reducing computational costs and memory requirements would make the technique more accessible to a wider range of researchers and practitioners. Finally, addressing ethical considerations is paramount. The potential for misuse of this technology necessitates thorough investigation into safeguards and responsible deployment strategies to mitigate risks associated with identity manipulation or generation of deepfakes.
More visual insights#
More on figures

This figure illustrates the weights2weights (w2w) space as a meta-latent space. It contrasts the traditional generative latent space which controls single image instances with the w2w space which controls the model itself. The figure shows three applications of w2w space: sampling new models, editing existing models, and inverting a single image into a model. Each operation results in a new model that consistently generates the subject.
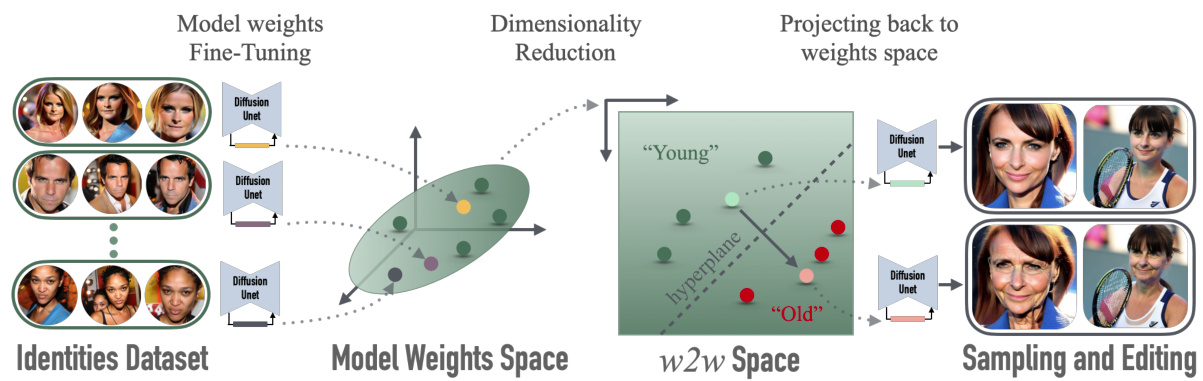
This figure illustrates the process of creating the weights2weights (w2w) space. It starts with a dataset of identities, each of which is used to fine-tune a diffusion model using Low-Rank Adaptation (LoRA). This results in a set of model weights. Dimensionality reduction (using PCA) is then applied, creating a lower-dimensional subspace called the w2w space. Finally, linear classifiers are trained to find interpretable directions within this space for editing.

This figure shows three examples of identities sampled from the w2w space, along with their nearest neighbor identities from the training set. The goal is to illustrate that the sampling process generates novel identities that are similar but not identical to existing ones. The figure also demonstrates that these new identities can be used in various contexts, just like the original training set identities.

This figure compares three methods for editing subject attributes in generated images: prompting, Concept Sliders, and weights2weights (w2w). Each column shows the results of applying an edit (Woman, Chubby, Narrow Eyes) using each method. The w2w method is shown to preserve identity, apply the edit cleanly, and avoid unintended side effects. Concept Sliders tends to exaggerate the edits, leading to artifacts, and prompting often leads to unpredictable changes.

This figure demonstrates that multiple edits can be composed linearly in the w2w space. Each column shows samples generated from a model with different combinations of edits applied. The results show that combining multiple edits does not significantly affect the original identity or interfere with other visual elements, and that the edits remain consistent across different generations.

This figure shows the results of inverting single images into the weights2weights (w2w) space. The leftmost column shows the input images. Subsequent columns demonstrate that the inverted models can generate realistic and consistent identities across different generation seeds and prompts. Moreover, the identities can be seamlessly edited by linearly traversing along semantic directions in the w2w space. These edits also persist across different generations.

This figure demonstrates the ability of the w2w space to project out-of-distribution identities (e.g., cartoon, painting, animation) into realistic renderings with in-domain facial features. The generated samples highlight the model’s capacity to capture and reproduce key characteristics of the identities, even from unconventional sources. Further, these inverted identities maintain consistency when composed into novel scenes or rendered in different artistic styles.
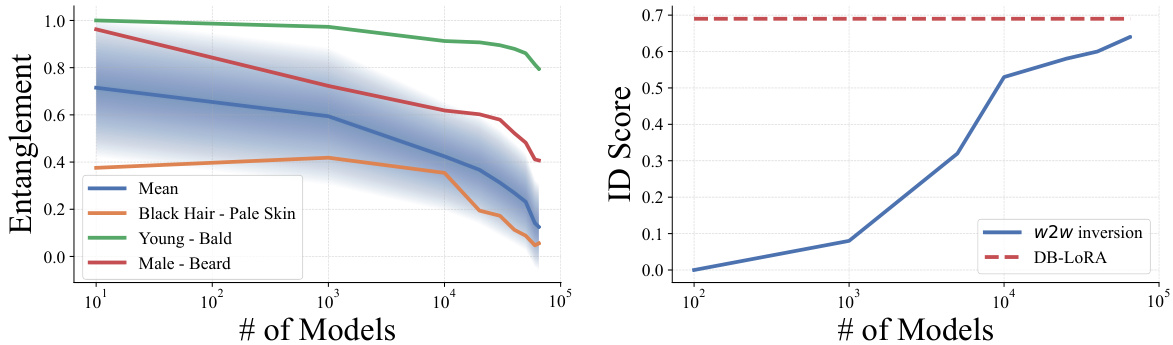
This figure shows the effect of scaling the number of models used to create the weights2weights space on the disentanglement of attribute directions and identity preservation. The left plot demonstrates how the entanglement (measured by cosine similarity between classifier directions) decreases as the number of models increases. The right plot shows how identity preservation (measured by ID score) increases as the number of models increases, approaching the performance of a multi-image DreamBooth model. Three specific attribute pairs are highlighted to illustrate the disentanglement trend.

This figure shows that the weights2weights method can be applied to visual concepts beyond human faces. Two examples are given: dog breeds and car types. For each, the authors created a dataset of models fine-tuned to different instances of the concept (dog breeds or car types). PCA was applied to the weights to find a lower-dimensional subspace. Linear classifiers were then trained to identify directions in this subspace corresponding to semantic attributes (like size for dogs or car type for cars). The resulting subspaces allow for controllable creation of models representing new variations of the concepts.

This figure demonstrates the ability of the w2w space to reconstruct an identity from a single image and further edit it by applying linear transformations in the weight space. The reconstructed identities maintain consistency across different generation seeds and prompts, highlighting the model’s ability to generate diverse and realistic images while preserving the core identity.

This figure shows several examples of identities generated from the w2w model, which is a model of the weight space of fine-tuned diffusion models. Each sampled identity is compared to its nearest neighbor from the training dataset. The comparison highlights that while the sampled identities share some characteristics with their nearest neighbors, they are also distinct and novel. This demonstrates the ability of the w2w model to generate diverse and realistic identities. The figure also shows that these sampled identities can be used in a variety of contexts, just like standard customized diffusion models.

This figure shows that multiple edits in the w2w space can be controlled in a continuous manner. The edits are applied to different identities, demonstrating that the edits are disentangled and do not interfere with other attributes. The edits are also persistent, meaning that they appear consistently across different generations.

This figure demonstrates that multiple edits can be applied to a single identity model using the w2w method. The edits are shown to be disentangled, meaning they don’t negatively affect other aspects of the generated image, and semantically aligned, meaning the changes accurately reflect the intended edit. The consistent appearance of the edits across different image samples highlights the reliability and stability of the w2w approach for generating edited images.

This figure demonstrates that multiple edits can be composed in the w2w space without significantly affecting the original identity or interfering with other concepts. The edits are consistent across different generations of images, using fixed random seeds.

This figure visualizes the effect of traversing along the first three principal components of the w2w space. Each row shows a series of images generated by varying the value of a single principal component while holding the others constant. The images demonstrate that the principal components influence multiple attributes of the generated identities, such as age, gender, and facial hair, highlighting the entanglement of these features in the model’s weight space. This entanglement motivates the use of linear classifiers to disentangle these attributes for more controlled editing.

This figure shows more examples of applying multiple edits to the same subject in the w2w space. The edits are shown in a sequential manner demonstrating how different attributes can be combined. Each row showcases a different subject and different sets of edits. The consistency of the identity across these edits is emphasized.

This figure illustrates the weights2weights (w2w) space, which is a subspace of weights from a collection of customized diffusion models. It shows how this space allows for three main operations: single image inversion (creating a model from a single image), identity editing (modifying characteristics within an existing model), and sampling (generating new models with novel instances of the visual concept).

This figure shows an example question from the user study on identity editing. Users are presented with an original image and three edited versions of the same image, each created using a different method. They are asked to choose the edited image that best satisfies the criteria of semantic alignment (in this case, ‘chubby’), identity preservation, and disentanglement. This helps to evaluate the performance of each method in terms of creating edits that are both semantically correct and visually pleasing.

This figure compares the results of three different methods for inverting a single image into a generative model: Dreambooth with LoRA trained on multiple images, Dreambooth with LoRA trained on a single image, and the proposed w2w inversion method. The results show that w2w inversion produces images that are more consistent with the input image in terms of identity and realism compared to the other methods. The w2w method is particularly effective at preserving the identity of individuals across varied poses and settings, highlighting its superior performance in generating realistic and consistent image generation.

This figure shows a qualitative comparison of the inversion results obtained using different methods: Dreambooth fine-tuned with LoRA on multiple images, Dreambooth fine-tuned with LoRA on a single image, and the proposed w2w inversion. For each method, the figure presents several generated images from the same input image. The results demonstrate that the w2w inversion method is better at preserving the identity and realism of the input image compared to the other two methods.

This figure compares the results of three different single-shot personalization methods: Celeb-Basis, IP-Adapter FaceID, and the proposed w2w method. The original image is shown on the left, and the results of each method are shown on the right, using the same prompt. It visually demonstrates the differences in identity preservation, image diversity, and alignment with the prompt between the methods.

This figure shows an example question used in a user study to evaluate the quality of identity edits. Users were presented with an original image and three edited versions (using different methods) and asked to select the best edit based on three criteria: semantic alignment, identity preservation, and disentanglement.

This figure shows three examples of out-of-distribution images (a portrait of Shakespeare, a dog, and a painting) being successfully inverted into the weights2weights space. The resulting models, when prompted, generate realistic images of the subjects in diverse settings. This demonstrates the ability of the model to handle various input styles while maintaining the core identity.

This figure shows how synthetic datasets were created for fine-tuning the model for different identities. It highlights the use of a CelebA image as a starting point, which is then used to generate a consistent set of images for training. This process ensures that the model learns a consistent representation of each identity.
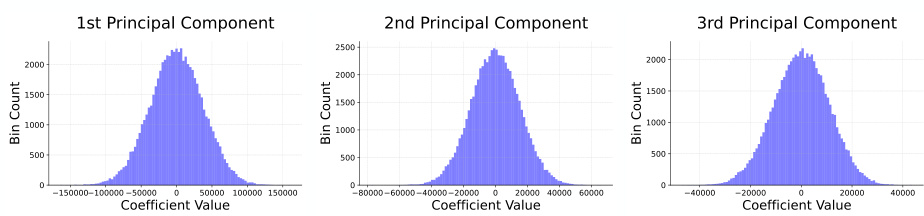
This figure shows the histograms of the coefficients for the first three principal components obtained through PCA on the model weights. The distributions appear roughly Gaussian, suggesting independence among the principal components which supports the modelling assumption used to sample new models.
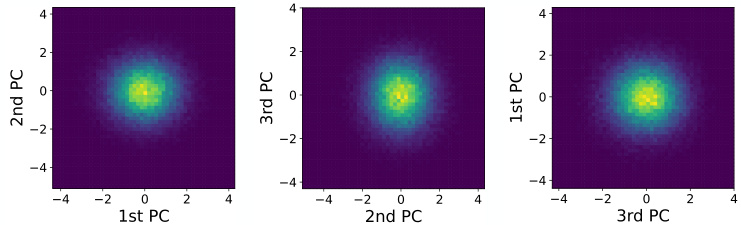
This figure shows the pairwise joint distributions of the first three principal components after rescaling them to unit variance. The near-circular shapes in the plots indicate that the components are roughly independent, which supports the assumption made in the paper that they can be modeled as independent Gaussians.

This figure shows the results of applying different numbers of principal components to the task of adding a goatee to faces in images. Using only 100 principal components, the results are coarse and change several attributes at once. With 1000 principal components, the editing is much more focused and only changes the addition of a goatee. Using 10,000 principal components doesn’t improve results significantly.

This figure shows the results of inverting a single image into the w2w space using different numbers of principal components (PCs). The image on the left is the input image. The results on the right show that using 10,000 PCs produces images that are both realistic and preserve the identity of the input image, without overfitting. Using fewer PCs (1000) underfits the data and using more PCs (20,000) overfits, causing the generated images to be less realistic and consistent.
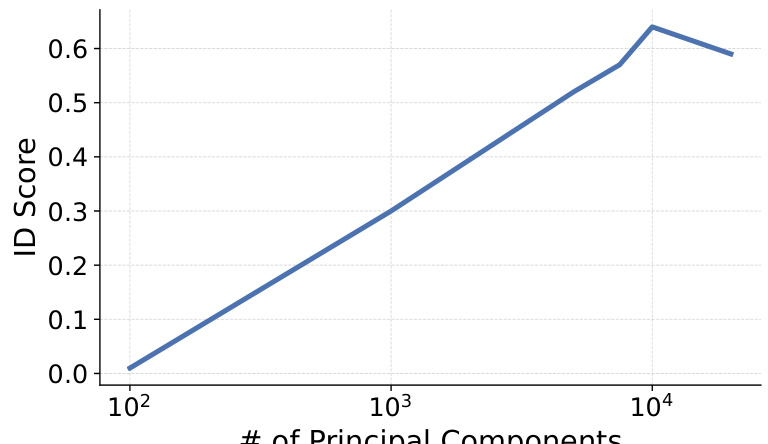
This figure shows a plot of identity preservation (ID score) against the number of principal components used in the w2w inversion method. The x-axis represents the number of principal components, while the y-axis represents the average ID score achieved on 100 inverted FFHQ (high-resolution face) images. The plot demonstrates that as the number of principal components increases, identity preservation improves, suggesting that a higher-dimensional subspace better captures the nuances of individual identities.

This figure shows how traversing along the first three principal components of the weights2weights space affects the generated images. Each row represents a traversal along one of the components, showing changes in attributes like age, gender, and facial hair. The entanglement of these attributes highlights the need for disentanglement techniques, like using linear classifiers to find separating hyperplanes, to control individual features more effectively.

This figure shows that the proposed method can be extended to other visual concepts besides human identities. Two examples are given: dog breeds and car types. For each concept, a linear subspace is created using PCA on a dataset of fine-tuned diffusion models. Linear classifiers then identify semantic edit directions within these subspaces, enabling controlled modifications of the generated models (e.g., changing a dog’s size or a car’s color).
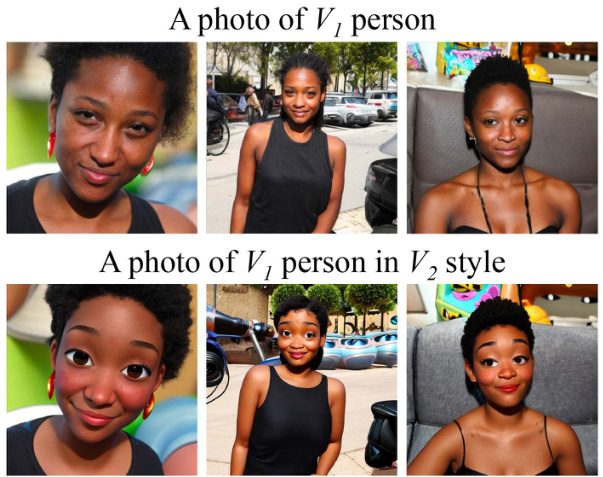
This figure demonstrates the merging of two different types of models: one from the weights2weights (w2w) space, and another fine-tuned to generate images in a specific style (Pixar). The merging process is shown to be a simple addition of the model weights, resulting in images that combine elements of both models. This highlights the potential for combining models from different training processes and conceptual spaces.

This figure shows the results of injecting edited weights at different timesteps (T) during the image generation process. It demonstrates a trade-off between preserving the original context of the image and the strength of the applied edit. Using smaller timesteps (e.g., T=600) results in better context preservation, but the edit is less pronounced. Conversely, larger timesteps (e.g., T=1000) result in a stronger edit, but might negatively impact the overall context of the image.
More on tables
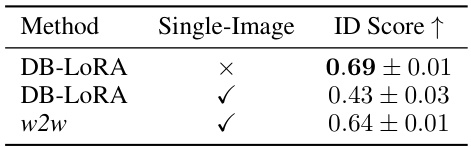
This table compares the identity preservation performance of three different methods: Dreambooth with LoRA trained on multiple images, Dreambooth with LoRA trained on a single image, and the proposed w2w inversion method. The ID Score metric is used to evaluate identity preservation, with higher scores indicating better performance. The results show that w2w inversion achieves comparable performance to Dreambooth trained on multiple images, while significantly outperforming Dreambooth trained on a single image. This demonstrates the effectiveness of w2w inversion in encoding identities from limited data.
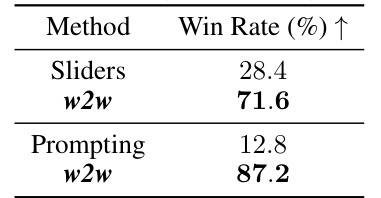
This table presents a quantitative comparison of three different methods for editing subject attributes in images: w2w, Concept Sliders, and prompting. The comparison is based on three criteria: identity preservation (how well the edited image maintains the original identity), disentanglement (how well the edit is separated from other visual elements), and semantic alignment (how well the edit matches the intended semantic meaning). The results show that w2w outperforms the other methods on all three criteria, indicating that it is a more effective method for editing subject attributes in a disentangled and semantically aligned manner.

This table compares the efficiency and identity preservation of three different methods for inverting a single image into a model: Dreambooth with LoRA (trained on a single image and multiple images), and the proposed w2w inversion method. It shows the number of parameters optimized, the optimization time, and the resulting identity fidelity (higher is better). The w2w inversion method is significantly faster than the Dreambooth method, while achieving comparable identity fidelity.
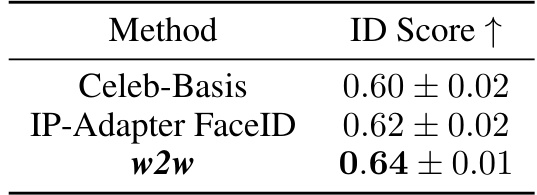
This table compares the identity preservation performance (ID Score) of three different single-shot personalization methods: Celeb-Basis, IP-Adapter FaceID, and the proposed w2w method. The ID Score metric quantifies how well the generated images preserve the identity of the input image, with higher scores indicating better preservation. The results show that the w2w method achieves the highest ID Score, suggesting its superior ability to reconstruct identities from single images.

This table presents the results of a user study comparing the performance of three different methods for inverting an image into a model’s weight space: w2w, Celeb-Basis, and IP-Adapter FaceID. The win rate indicates the percentage of times users preferred w2w over the other methods based on identity preservation, prompt alignment and diversity of generated images.
Full paper#