TL;DR#
3D semantic segmentation struggles with the scarcity of labeled data across different domains. Existing methods either focus on domain adaptation (narrowing the gap between specific source and target domains) or domain generalization (building robust models applicable across various domains), but lack a unified solution. This paper introduces a groundbreaking universal method to address this limitation by efficiently mitigating the domain gap between 2D and 3D modalities. This is achieved via effective usage of pre-trained Visual Foundation Models (VFMs) which inherit target information and avoid unnecessary manipulation of the original visual space.
The proposed method, dubbed UniDSeg, introduces layer-wise learnable blocks to VFMs, alternately learning visual prompts (capturing 3D-to-2D transitional priors) and deep queries (constructing spatial tunability). This cross-modal learning framework significantly improves both domain adaptation and generalization performance across multiple datasets, showcasing superior results compared to existing state-of-the-art methods. UniDSeg’s universal approach provides a significant advancement in the field by offering a single method effective for various cross-domain 3D semantic segmentation tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UniDSeg, a novel and effective method for cross-domain 3D semantic segmentation. It addresses the crucial issue of limited labeled data by leveraging visual foundation models (VFMs), significantly advancing the field and opening new avenues for research in this crucial area of computer vision. The improved accuracy and generalizability have significant implications for various applications, including autonomous driving and robotics.
Visual Insights#

🔼 The figure shows the overall framework of the UniDSeg model, which is designed for both domain generalized (DG3SS) and domain adaptive (DA3SS) 3D semantic segmentation tasks. It consists of two main branches: a 2D network and a 3D network. The 2D network processes images and sparse depth maps from a camera and LiDAR, respectively, using a VFM-based encoder with several trainable modules. The 3D network processes LiDAR point clouds directly. Both branches feed into a cross-modal learning module that combines their predictions to generate the final 3D semantic segmentation results. The VFM-based encoder utilizes pre-trained Visual Foundation Models (VFMs) as the backbone to leverage their knowledge, while the trainable modules adapt to different domains. Point sampling is employed to ensure that only the visible points are processed in the cross-modal learning step.
read the caption
Figure 1: Overall framework of UniDSeg for DG3SS and DA3SS. The backbone of the VFM-based Encoder is frozen and only trains several learnable modules. “Samp.” means sampling of 2D features. Only the points falling into the intersected field of view are geometrically associated with multi-modal data.
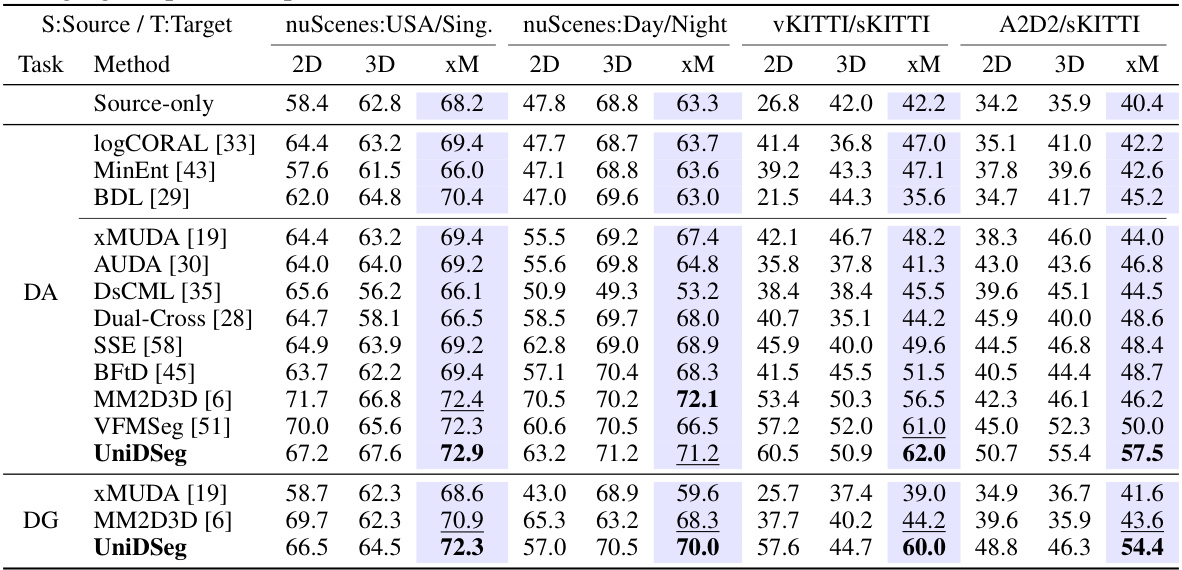
🔼 This table compares the performance of various multi-modal domain adaptive and generalized 3D semantic segmentation methods across four different scenarios. It shows the mean Intersection over Union (mIoU) scores for 2D and 3D networks, as well as an ensemble result combining both. The scenarios represent different challenges in adapting and generalizing 3D semantic segmentation models, such as changes in lighting, scene layout, and sensor setup.
read the caption
Table 1: Performance comparison of multi-modal domain adaptive and domain generalized 3D semantic segmentation methods in four typical scenarios. We report the mIoU results (with best and 2nd best) on the target testing set for each network as well as the ensemble result (i.e., xM) by averaging the predicted probabilities from the 2D and 3D networks.
In-depth insights#
UniDSeg Overview#
UniDSeg, a novel method for unified cross-domain 3D semantic segmentation, leverages the power of pre-trained Visual Foundation Models (VFMs). Instead of extensive fine-tuning, UniDSeg introduces learnable modules, namely Modal Transitional Prompting (MTP) and Learnable Spatial Tunability (LST), to the VFM backbone. MTP captures 3D-to-2D transitional priors and task-shared knowledge from the prompt space, guiding the model towards domain-invariant representations. LST enhances the ability to distinguish instances by dynamically adjusting the contextual features in the query space, further mitigating the domain gap. This approach of alternate learning of visual prompts and deep queries offers a parameter-efficient way to adapt VFMs to the specific task of 3D semantic segmentation across various domains. UniDSeg’s unified framework addresses both domain adaptation and domain generalization, demonstrating superior performance over state-of-the-art methods in extensive experiments.
VFM-based Encoder#
A VFM-based encoder leverages pre-trained Visual Foundation Models (VFMs) to efficiently learn representations for 3D semantic segmentation. Instead of fully training or fine-tuning the VFM, which risks losing pre-existing knowledge or overfitting to a specific domain, this approach adopts a parameter-efficient strategy. This often involves adding learnable modules (like learnable blocks or prompt tuning mechanisms) to the frozen VFM. This allows the model to inherit the VFM’s powerful feature extraction capabilities while adapting to the specific task of 3D segmentation. The core idea is to selectively update only a small subset of parameters, preserving the knowledge learned from massive datasets. This approach is particularly beneficial when dealing with limited labeled data or cross-domain challenges because the VFM provides a strong starting point and reduces the need for extensive training from scratch. Successfully integrating VFMs in this way offers a powerful approach to improve generalizability and reduce the domain gap in 3D semantic segmentation.
Prompt Tuning#
Prompt tuning, in the context of large language models and visual foundation models, involves modifying or adding prompts to guide the model’s behavior rather than directly training its parameters. This technique is parameter-efficient, requiring fewer updates compared to full fine-tuning. Visual prompts, often image patches or descriptive text, can be strategically designed to direct the model toward specific tasks or styles. The effectiveness of prompt tuning hinges on carefully crafting prompts that effectively capture the desired semantic information and contextual cues. Careful prompt engineering is crucial for success, as poorly designed prompts may lead to inadequate performance or unintended outputs. While prompt tuning offers advantages in terms of resource efficiency and faster training, it is not a replacement for full fine-tuning in all situations, particularly when substantial modifications of the model’s behavior are needed. The technique’s efficacy is highly dependent on the quality and relevance of the prompts provided. Future research will likely focus on automated prompt generation and optimization to enhance the usability and scalability of this promising method.
Cross-Domain Results#
A dedicated ‘Cross-Domain Results’ section would be crucial for evaluating a method’s ability to generalize across different domains. It should present quantitative metrics (e.g., mIoU, accuracy) comparing the method’s performance on various datasets representing distinct domains (e.g., synthetic vs. real, different sensor modalities). Visualizations showing qualitative results are essential for demonstrating the robustness and reliability of the method in handling domain shifts. A detailed analysis of the results is critical, exploring the impact of domain discrepancies on the method’s performance, as well as discussing any observed trends or patterns. Comparison with existing state-of-the-art methods in cross-domain settings is vital for establishing the novelty and effectiveness of the approach. Furthermore, the section should also cover the different experimental scenarios and the type of cross-domain tasks tackled. Error analysis should pinpoint any particular challenges faced by the method and possible avenues for future improvements.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending the framework to handle more diverse 3D data modalities, such as point clouds with varying density and noise levels, or incorporating RGB-D data, would significantly broaden its applicability. Another area of focus should be on improving efficiency and scalability, potentially through model compression techniques or more efficient training strategies. The development of more robust prompt engineering methods to further unlock the potential of Visual Foundation Models (VFMs) is also crucial. Finally, investigating the application of UniDSeg in more challenging real-world scenarios with diverse weather conditions, challenging lighting, or dynamic objects would rigorously validate its performance and robustness. Addressing these areas would consolidate UniDSeg’s position as a leading method in cross-domain 3D semantic segmentation.
More visual insights#
More on figures

🔼 This figure shows the architecture of the VFM-based encoder used in UniDSeg. It highlights two key learnable modules: Modal Transitional Prompting (MTP) and Learnable Spatial Tunability (LST). MTP utilizes sparse depth information and a low-frequency filtered image to generate 3D-to-2D transitional prompts. LST introduces learnable tokens to capture spatial relationships between instances. The VFM backbone’s parameters remain frozen during training, with only the parameters within these two modules being updated, making it a parameter-efficient approach.
read the caption
Figure 2: The architecture of VFM-based Encoder. We explore two layer-wise learnable blocks: (a) Modal Transitional Prompting and (b) Learnable Spatial Tunability. During training, only the parameters of two modules are updated while the whole ViT encoder layer is frozen.

🔼 This figure shows a qualitative comparison of the results obtained by the UniDSeg model on four different scenarios for Domain Generalized 3D Semantic Segmentation (DG3SS). Each scenario presents a different combination of source and target datasets. For each scenario, the image, the 2D and 3D segmentation results of the UniDSeg method are displayed side-by-side, along with the ground truth. The visual comparison highlights the model’s ability to generalize across diverse and unseen scenarios and achieve good segmentation performance in various scenes.
read the caption
Figure 3: Qualitative results of DG3SS. We showcase the ensembling result of four scenarios.
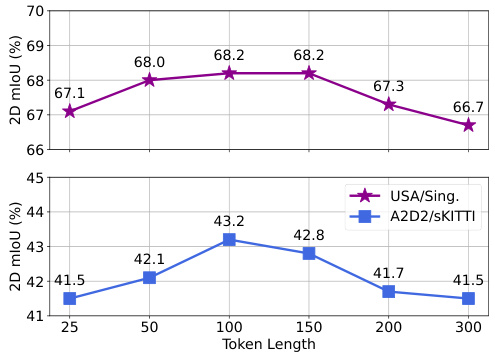
🔼 This figure shows the effect of the learnable token length on the 2D mIoU for two different scenarios: nuScenes: USA/Sing. and A2D2/sKITTI. The x-axis represents the token length, and the y-axis represents the 2D mIoU. The results show that increasing the token length leads to an increase in 2D mIoU, but beyond a certain point, increasing the token length does not result in further improvements. This suggests an optimal token length exists for maximizing performance.
read the caption
Figure 4: Effect of the learnable token length.

🔼 This figure shows a qualitative comparison of the proposed UniDSeg method against the 2DPASS method on the SemanticKITTI validation dataset. Three sample scenes are presented, each displaying the ground truth segmentation, the segmentation results from the 2DPASS method highlighting errors in red, and the segmentation results from the UniDSeg method, again showing errors in red. The comparison focuses on the accuracy of segmenting trees, bicyclists, and trucks, demonstrating that UniDSeg achieves better results.
read the caption
Figure 5: Qualitative results of our method on the validation set of SemanticKITTI. The misclassification points are signed in red.

🔼 This figure illustrates the architecture of the VFM-based encoder used in UniDSeg. It shows two learnable blocks added to a frozen Vision Transformer (ViT) backbone. The first block, Modal Transitional Prompting (MTP), leverages 3D-to-2D transitional prior information from sparse depth and image inputs to create visual prompts. The second block, Learnable Spatial Tunability (LST), learns deep queries that interact with the prompts to improve feature generalization. Only the parameters of these two modules are updated during training; the ViT backbone remains frozen to preserve pre-trained knowledge.
read the caption
Figure 2: The architecture of VFM-based Encoder. We explore two layer-wise learnable blocks: (a) Modal Transitional Prompting and (b) Learnable Spatial Tunability. During training, only the parameters of two modules are updated while the whole ViT encoder layer is frozen.

🔼 This figure shows additional qualitative results for the nuScenes:Day/Night scenario in the domain adaptive 3D semantic segmentation task (DA3SS). It presents comparisons between the image, 2D prediction, 3D prediction, the average of 2D and 3D predictions, and the ground truth. Red rectangles highlight specific regions of interest where the predictions are compared to the ground truth, providing a visual assessment of the model’s performance in various lighting conditions.
read the caption
Figure 7: Additional qualitative results of nuScenes:Day/Night scenario for DA3SS.

🔼 This figure shows additional qualitative results for the Day/Night scenario of the nuScenes dataset, focusing on domain adaptive 3D semantic segmentation. It presents comparisons between the input image, 2D and 3D prediction outputs from the UniDSeg model, and the ground truth. Red boxes highlight areas where differences are notable, illustrating the model’s performance in handling variations in lighting conditions. The legend provides a color-coded key to the different semantic classes.
read the caption
Figure 7: Additional qualitative results of nuScenes:Day/Night scenario for DA3SS.

🔼 This figure shows additional qualitative results for the Day/Night scenario of the nuScenes dataset in the Domain Adaptive 3D Semantic Segmentation task. It presents a comparison between the image, 2D prediction, 3D prediction, the average of 2D and 3D predictions, and the ground truth. Red boxes highlight areas of misclassification, enabling a visual assessment of the model’s performance in different conditions.
read the caption
Figure 7: Additional qualitative results of nuScenes:Day/Night scenario for DA3SS.

🔼 This figure shows additional qualitative results of the nuScenes:Day/Night scenario for Domain Adaptive 3D Semantic Segmentation (DA3SS). It presents comparisons between the 2D and 3D predictions of the UniDSeg model against ground truth. The images highlight areas where the model’s predictions differ from the ground truth, indicating the model’s strengths and weaknesses in various aspects of semantic segmentation.
read the caption
Figure 7: Additional qualitative results of nuScenes:Day/Night scenario for DA3SS.
More on tables
🔼 This table compares the performance of various multi-modal domain adaptive and domain generalized 3D semantic segmentation methods across four scenarios. It shows mean Intersection over Union (mIoU) results for 2D and 3D networks separately, and also an ensemble result (‘xM’) that combines their predictions. The scenarios represent different domain adaptation and generalization challenges involving changes in lighting, scene layout, and sensor configurations.
read the caption
Table 1: Performance comparison of multi-modal domain adaptive and domain generalized 3D semantic segmentation methods in four typical scenarios. We report the mIoU results (with best and 2nd best) on the target testing set for each network as well as the ensemble result (i.e., xM) by averaging the predicted probabilities from the 2D and 3D networks.
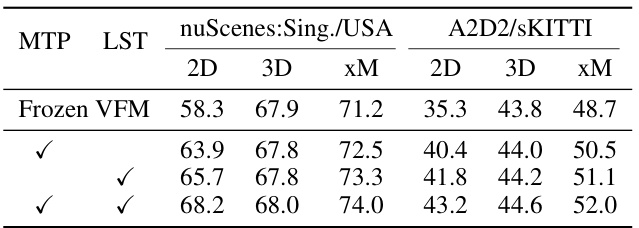
🔼 This ablation study analyzes the impact of Modal Transitional Prompting (MTP) and Learnable Spatial Tunability (LST) on the performance of UniDSeg using the ViT-B backbone for domain generalized 3D semantic segmentation (DG3SS). It shows the 2D, 3D, and ensemble (xM) mIoU scores for two scenarios: nuScenes:Sing./USA and A2D2/sKITTI. The results demonstrate that both MTP and LST contribute significantly to the overall performance, with the combination of both yielding the best results.
read the caption
Table 3: Ablation study on the effectiveness of significant components in UniDSeg with the ViT-B backbone for DG3SS task.

🔼 This table compares the performance of various multi-modal domain adaptive and generalized 3D semantic segmentation methods across four different scenarios (nuScenes: USA/Sing., nuScenes: Day/Night, VKITTI/SKITTI, A2D2/SKITTI). It shows the mean Intersection over Union (mIoU) for 2D and 3D networks individually, as well as a combined (ensemble) result (xM). The scenarios represent different challenges in domain adaptation and generalization, allowing for a comprehensive evaluation of the methods’ capabilities.
read the caption
Table 1: Performance comparison of multi-modal domain adaptive and domain generalized 3D semantic segmentation methods in four typical scenarios. We report the mIoU results (with best and 2nd best) on the target testing set for each network as well as the ensemble result (i.e., xM) by averaging the predicted probabilities from the 2D and 3D networks.

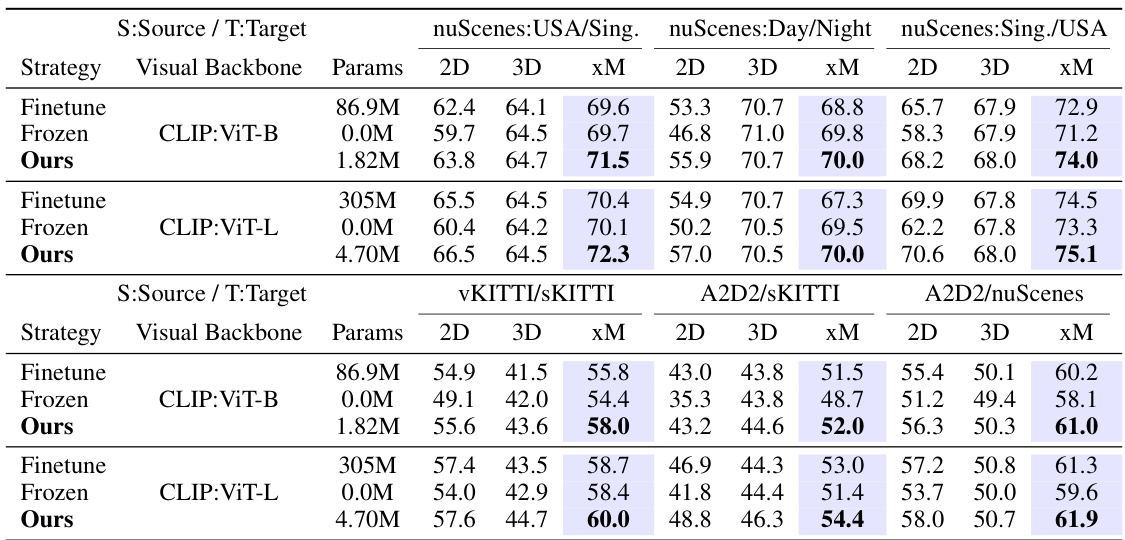
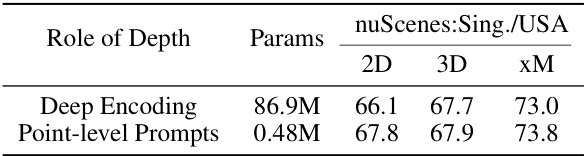
🔼 This table compares the number of parameters in different 2D backbones (CLIP:ViT-B, CLIP:ViT-L, SAM:ViT-L) used in the UniDSeg model. It shows the total number of parameters, the number of trainable parameters (only in MTP and LST modules), and the cost (percentage of trainable parameters relative to fine-tuning the entire encoder). The table highlights the efficiency of the proposed method, which requires only a small fraction of the parameters to be trained compared to fine-tuning the whole encoder.
read the caption
Table 7: The parameters and computational costs of CLIP-based and SAM-based 2D backbones. 'Cost' means the percentage of trainable parameters in MTP and LST compared to fine-tuning the whole encoder consumed.
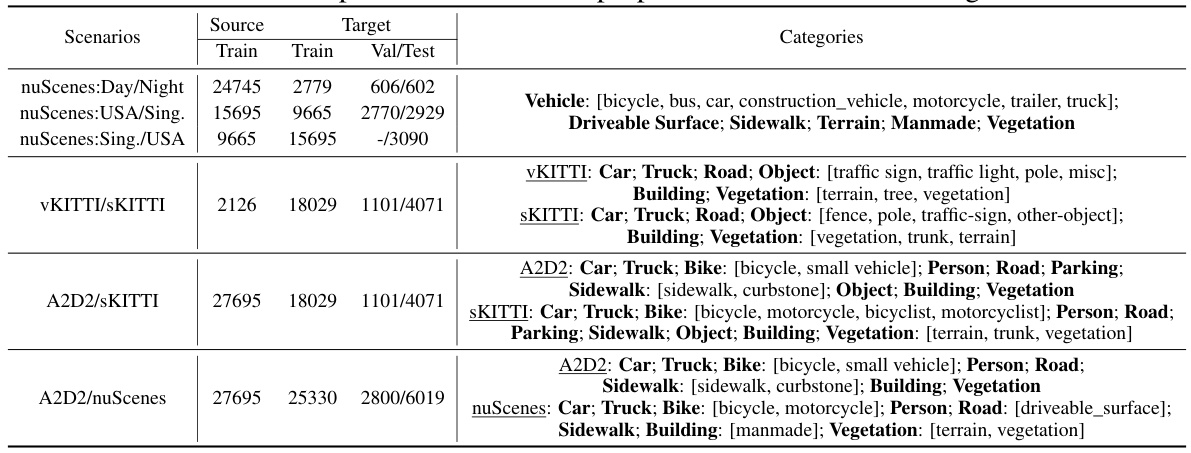
🔼 This table presents a comparison of different methods for 3D semantic segmentation, categorized into domain adaptive and domain generalized tasks. It shows the mean Intersection over Union (mIoU) scores achieved by various methods on four different scenarios (nuScenes: USA/Sing, nuScenes: Day/Night, vKITTI/SKITTI, A2D2/SKITTI). The results are broken down by 2D and 3D networks, and an ensemble result (xM) is also provided, combining the predictions of both networks. This allows for a comprehensive comparison of different techniques across various datasets and scenarios.
read the caption
Table 1: Performance comparison of multi-modal domain adaptive and domain generalized 3D semantic segmentation methods in four typical scenarios. We report the mIoU results (with best and 2nd best) on the target testing set for each network as well as the ensemble result (i.e., xM) by averaging the predicted probabilities from the 2D and 3D networks.
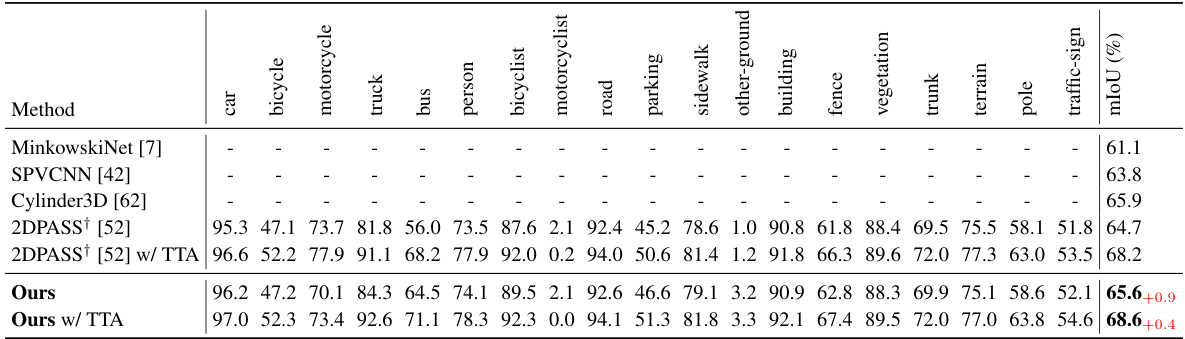
🔼 This table presents a comparison of fully-supervised 3D semantic segmentation methods on the SemanticKITTI validation set. It shows the Intersection over Union (IoU) for each class (car, bicycle, motorcycle, truck, bus, person, bicyclist, motorcyclist, road, parking, sidewalk, other-ground, building, fence, vegetation, trunk, terrain, pole, traffic-sign) for different methods. The methods compared include MinkowskiNet, SPVCNN, Cylinder3D, and 2DPASS (with and without Test-Time Augmentation). The table also includes results for the proposed ‘Ours’ method, showing its performance with and without test-time augmentation.
read the caption
Table 9: Fully-supervised 3D semantic segmentation results on the SemanticKITTI validation set. We report per-class IoU. “†” denotes the reproduced result referring to the official codebase. “w/ TTA” means using test-time augmentation in the inference stage.
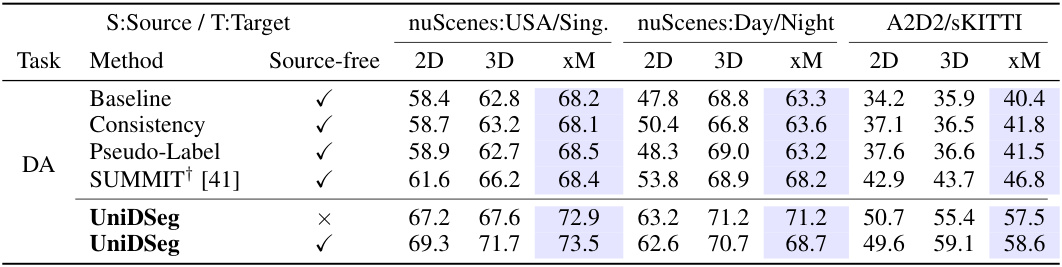
🔼 This table compares the performance of different Source-Free Domain Adaptive 3D Semantic Segmentation (SFDA3SS) methods across three scenarios: nuScenes: USA/Sing, nuScenes: Day/Night, and A2D2/sKITTI. The performance is measured using mean Intersection over Union (mIoU) for 2D, 3D, and a combined (xM) approach. The table also includes a baseline, consistency, and pseudo-label methods for comparison, along with the results for the SUMMIT method from prior work. The xM results combine the probabilities from both 2D and 3D networks. It highlights the performance of UniDSeg, both with and without access to source-free data.
read the caption
Table 10: Performance comparison of SFDA3SS methods in three typical scenarios. “†” denotes the reproduced result referring to the official codebase, as the different category splits applied in the same adaptation scenario.

🔼 This table compares the performance of several multi-modal domain adaptive 3D semantic segmentation methods when re-trained with pseudo-labels. It shows the mean Intersection over Union (mIoU) results for different methods across four scenarios: nuScenes:USA/Sing, nuScenes:Day/Night, vKITTI/SKITTI, and A2D2/SKITTI. The scenarios represent different domain adaptation challenges. The results are presented separately for 2D and 3D segmentation, as well as a combined (XM) result.
read the caption
Table 11: Performance comparison of multi-modal domain adaptive 3D semantic segmentation methods with pseudo-label ('PL') re-training on four typical scenarios.
🔼 This table compares the performance of various multi-modal domain adaptive and domain generalized 3D semantic segmentation methods across four different scenarios. The mIoU (mean Intersection over Union) is reported for 2D and 3D networks separately, as well as a combined (ensemble) result. The scenarios represent different domain adaptation and generalization challenges.
read the caption
Table 1: Performance comparison of multi-modal domain adaptive and domain generalized 3D semantic segmentation methods in four typical scenarios. We report the mIoU results (with best and 2nd best) on the target testing set for each network as well as the ensemble result (i.e., xM) by averaging the predicted probabilities from the 2D and 3D networks.
Full paper#



















