↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D scene understanding methods typically focus on individual tasks (e.g., semantic, instance segmentation), resulting in fragmented understanding and inefficient processing. These separated approaches also lack the ability to share knowledge between tasks, limiting their overall performance. A unified approach is needed to improve both efficiency and the comprehensiveness of 3D scene understanding.
UniSeg3D directly addresses these issues by proposing a unified framework that tackles six 3D segmentation tasks in parallel: panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation. This unified architecture uses queries to integrate different input modalities (point clouds, clicks, text) and a shared mask decoder to produce results for all six tasks. To further enhance performance, it incorporates knowledge distillation and contrastive learning methods to foster inter-task knowledge sharing. Experimental results demonstrate that UniSeg3D outperforms current state-of-the-art methods on multiple benchmarks, showcasing its effectiveness and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UniSeg3D, a unified framework that significantly improves 3D scene understanding. It addresses the limitations of task-specific models by enabling knowledge sharing and achieving state-of-the-art performance across six diverse segmentation tasks. This opens avenues for more efficient and comprehensive 3D scene analysis, benefiting various applications like robotics and autonomous driving.
Visual Insights#
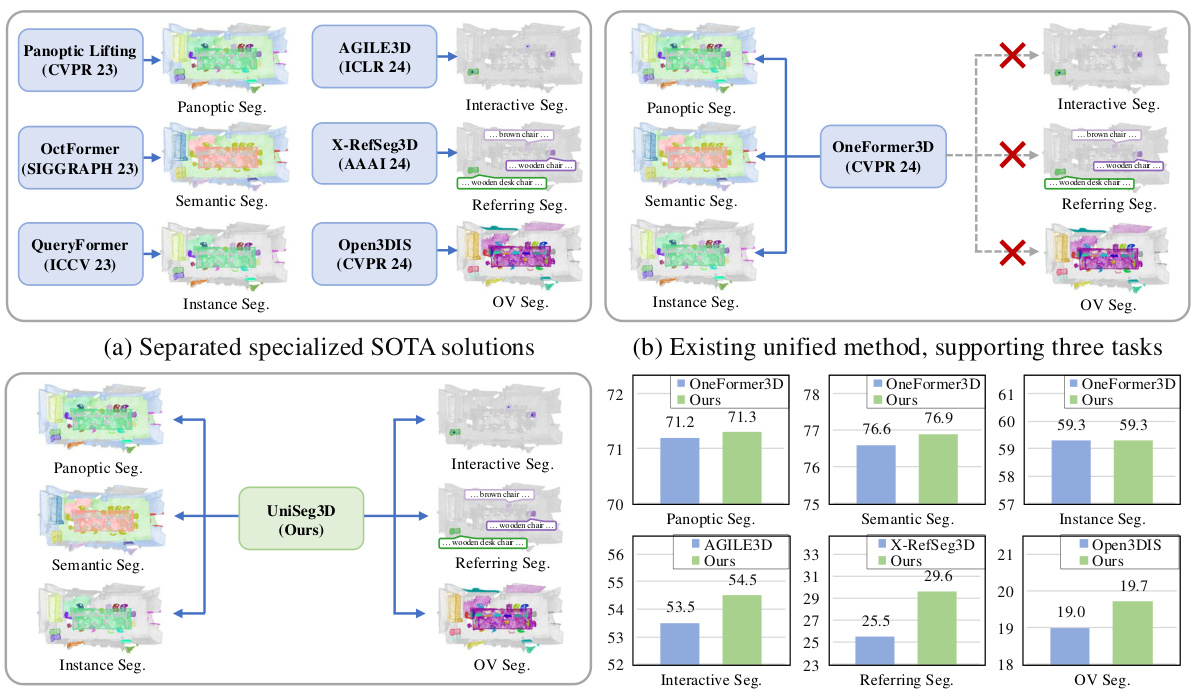
This figure compares the proposed UniSeg3D method with existing state-of-the-art (SOTA) approaches for 3D scene understanding. Subfigure (a) shows several specialized SOTA models, each designed for a single task (panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation). Subfigure (b) illustrates OneFormer3D, a recent unified method that handles three tasks (panoptic, semantic, and instance segmentation) in a single inference. In contrast, subfigure (c) presents UniSeg3D, the proposed unified framework which performs all six tasks in one inference. Finally, subfigure (d) provides a quantitative comparison showing UniSeg3D’s superior performance over other SOTA methods across all six tasks. The improvement highlights the effectiveness of the unified framework.

This table presents a comparison of the mask prediction performance for instance segmentation and interactive segmentation tasks. The mIoU (mean Intersection over Union) metric is used to quantify the accuracy of the mask predictions. Interactive segmentation, which incorporates user interaction in the form of visual prompts, significantly outperforms instance segmentation, highlighting the benefit of incorporating user feedback for improved segmentation accuracy.
In-depth insights#
UniSeg3D Framework#
The UniSeg3D framework presents a unified approach to 3D scene understanding, addressing the limitations of task-specific models. By integrating six segmentation tasks (panoptic, semantic, instance, interactive, referring, and open-vocabulary) within a single Transformer-based architecture, UniSeg3D promotes comprehensive scene understanding and efficient inference. The framework leverages inter-task knowledge sharing through mechanisms like knowledge distillation and contrastive learning, enhancing performance and generalizability. Uniqueness lies in its simultaneous handling of diverse tasks (including those using user input and textual descriptions), all while maintaining a relatively simple and elegant architecture. While experimental results demonstrate strong performance, future work could focus on further improving the efficiency and scalability of the model and exploring its potential in more complex, real-world 3D scenes.
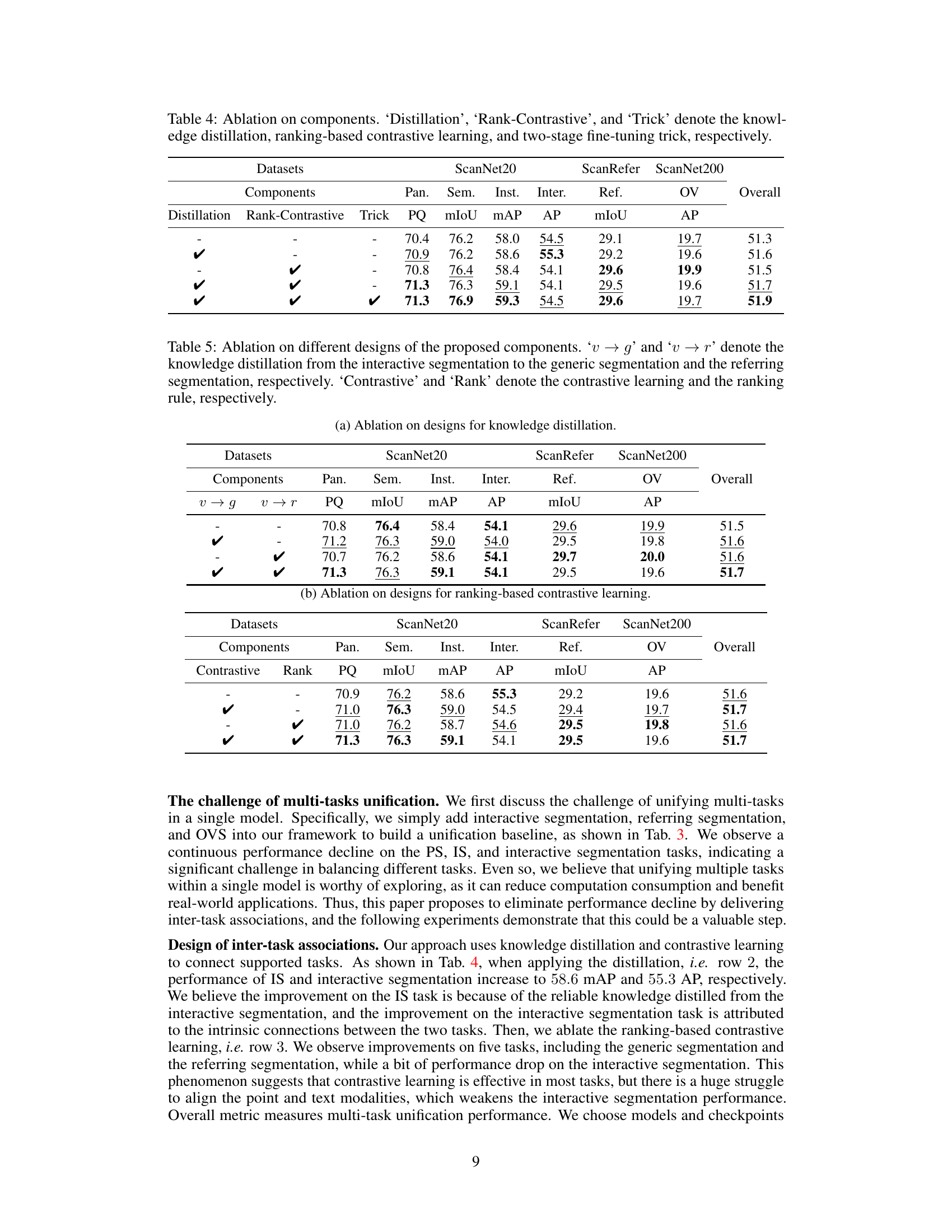
Multi-task Unification#
The concept of “Multi-task Unification” in a research paper would explore the benefits of training a single model to perform multiple related tasks simultaneously. This approach contrasts with traditional methods that train separate models for each task. Key advantages include improved efficiency (one model, one inference), potential for enhanced performance due to shared representations and knowledge transfer between tasks, and a more holistic understanding of the data. However, challenges exist. A unified model might compromise the performance of individual tasks compared to specialized models; careful design is needed to avoid negative transfer. Effective strategies to address these challenges often involve specialized architectural designs (e.g., shared layers, task-specific branches), and training methodologies like multi-task learning or knowledge distillation. The paper likely presents empirical evidence demonstrating the tradeoffs between efficiency and individual task accuracy, ultimately aiming to showcase the effectiveness and practicality of a unified approach.
Knowledge Distillation#
Knowledge distillation, in the context of deep learning, is a powerful technique that aims to transfer knowledge from a large, complex model (teacher) to a smaller, simpler model (student). This is particularly valuable when the teacher model is computationally expensive or difficult to deploy, such as large language models or complex vision transformers. The core idea is that the teacher model, having learned intricate patterns in the data, can guide the student model towards learning similar representations, often achieving surprisingly good performance despite its smaller size and simpler architecture. Several methods exist for transferring this knowledge, including the use of teacher model’s soft predictions (probabilities rather than hard labels) as training targets for the student, or through matching of intermediate layer representations. The benefits include reduced computational costs and faster inference, making the technology more accessible and deployable on resource-constrained devices. However, effective distillation often requires careful selection of the distillation method and the architecture of the teacher and student models. Challenges include choosing the right level of representation matching and preventing the student from simply memorizing the teacher’s output rather than truly learning the underlying patterns. Successfully tackling these challenges leads to highly efficient and performant student models, paving the way for wider adoption of complex models that might otherwise remain impractical due to resource limitations.
Contrastive Learning#
Contrastive learning, a self-supervised learning technique, plays a crucial role in the UniSeg3D framework by explicitly connecting vision and text modalities in the referring segmentation task. It addresses the challenge of the modality gap between visual point cloud data and textual descriptions. By comparing similar and dissimilar pairs of vision and text embeddings, the model learns to associate textual descriptions with their corresponding visual representations. Ranking-based contrastive learning enhances the model’s ability to distinguish between semantically similar but visually distinct instances, significantly improving the accuracy of referring segmentation. This approach leverages the inherent relationships between different tasks in the unified framework, promoting inter-task knowledge sharing and improved overall performance. The effectiveness of contrastive learning is validated through ablation studies, demonstrating a clear improvement in referring segmentation, confirming its importance within the UniSeg3D architecture.
Future Work#
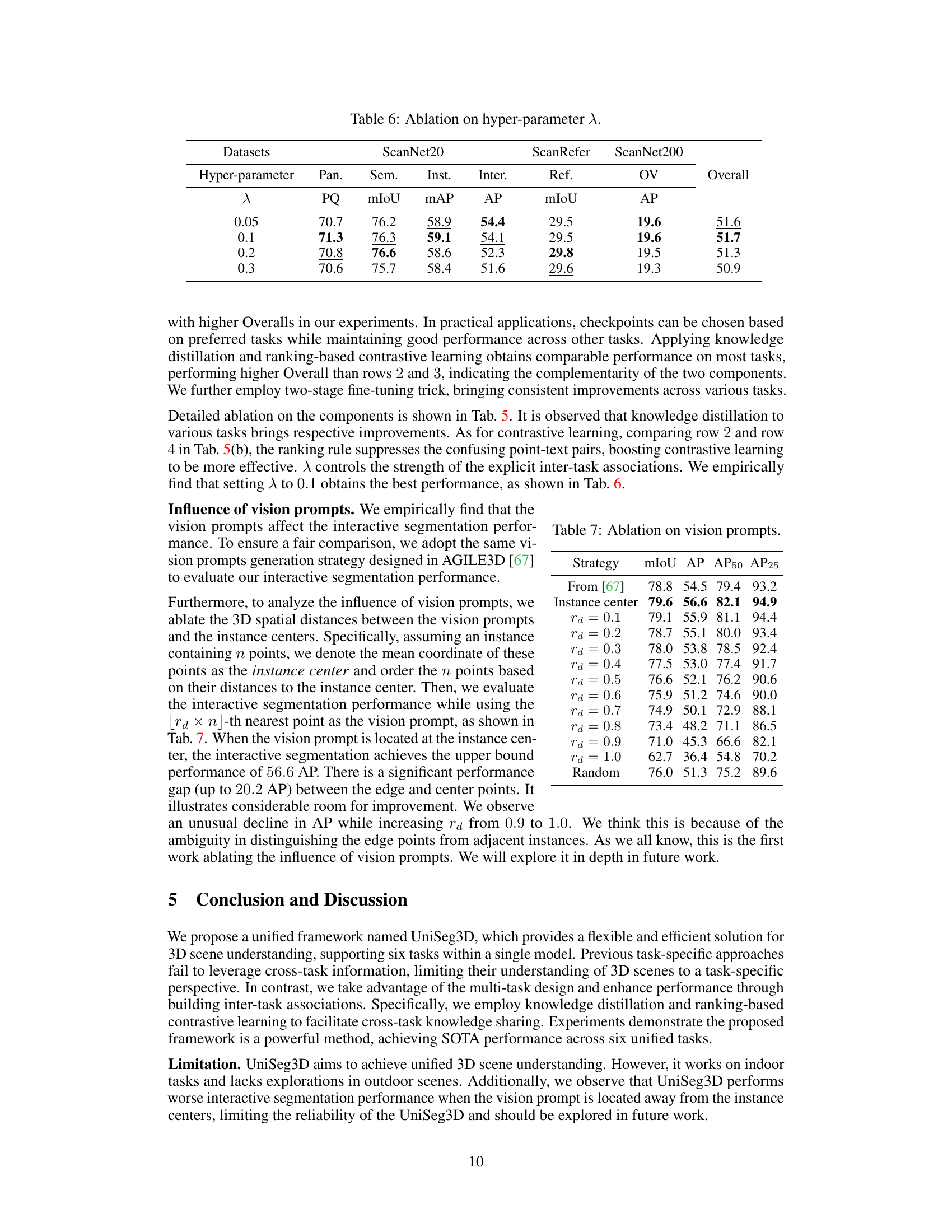
The ‘Future Work’ section of this research paper presents several promising avenues for extending the current research. Extending UniSeg3D to outdoor scenes is crucial, as the current model focuses on indoor environments. This expansion would require addressing the significant differences in data characteristics and complexity between indoor and outdoor scenes. Improving the robustness of the interactive segmentation module by reducing sensitivity to the precise location of user clicks is another key area. Investigating alternative prompt representations or incorporating uncertainty estimation could significantly enhance performance. Further exploration of the open-vocabulary capabilities of UniSeg3D using larger and more diverse datasets is also essential to demonstrate its broader applicability. This could involve incorporating advanced techniques for open-set recognition and leveraging external knowledge sources. Finally, a comprehensive analysis of the computational efficiency and scalability of the unified framework across different task combinations and datasets is necessary to assess its practical viability for real-world applications. The proposed research directions offer significant potential to solidify UniSeg3D’s position as a leading approach in 3D scene understanding.
More visual insights#
More on figures

This figure illustrates the architecture of the UniSeg3D model, a unified framework designed to handle six 3D scene understanding tasks simultaneously. The framework consists of three main modules: a point cloud backbone for processing point cloud data, prompt encoders for incorporating visual and textual information as prompts, and a mask decoder for generating predictions for all six tasks. The model leverages multi-task learning strategies, including knowledge distillation (transferring knowledge from interactive segmentation to other tasks) and contrastive learning (establishing connections between interactive and referring segmentation), to improve overall performance. The unified query mechanism allows for parallel processing of the various task inputs.
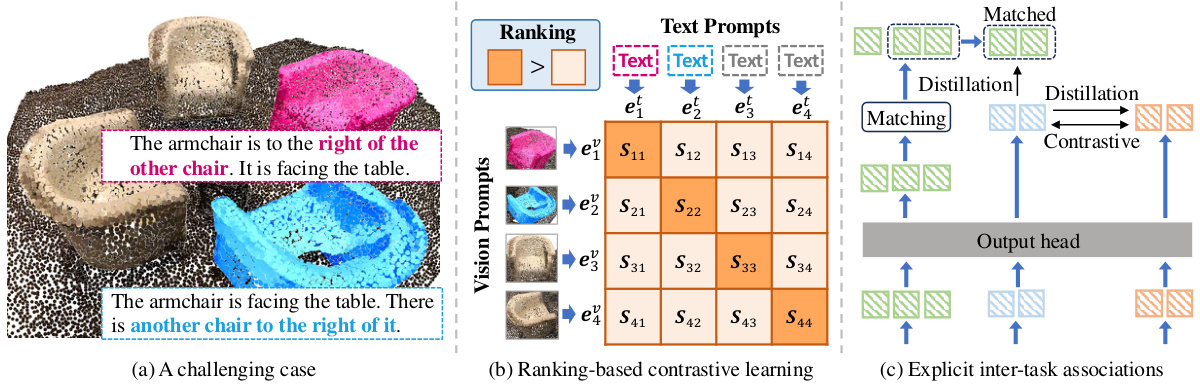
This figure illustrates how the UniSeg3D model handles the inter-task associations to improve its performance. Panel (a) shows a challenging scenario where distinguishing objects based on textual descriptions requires precise understanding of spatial relationships. Panel (b) details the ranking-based contrastive learning, where vision and text features of objects are compared to strengthen associations, ranking similar pairs higher. Panel (c) depicts knowledge distillation, transferring knowledge from interactive segmentation (a task that already has strong visual guidance) to other tasks to enhance their overall performance. The overall aim is to leverage the interdependencies between different segmentation tasks for improved performance.
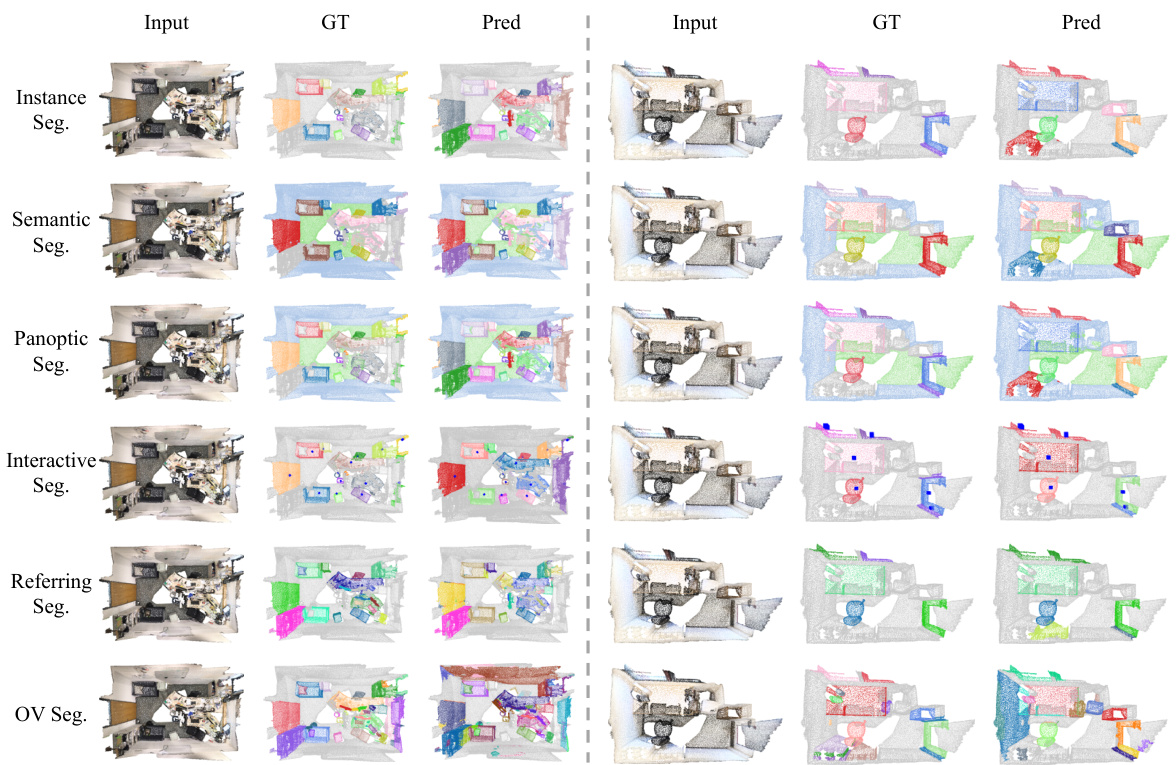
This figure shows a visualization of the segmentation results obtained by the UniSeg3D model on the ScanNet20 validation split. It provides a qualitative comparison of the model’s performance across six different 3D segmentation tasks: Instance Segmentation, Semantic Segmentation, Panoptic Segmentation, Interactive Segmentation, Referring Segmentation, and Open-Vocabulary Segmentation. For each task, the figure displays the input point cloud data, the ground truth segmentation masks, and the model’s predicted segmentation masks. This visual representation allows for a qualitative assessment of the model’s accuracy and effectiveness in performing the various segmentation tasks.
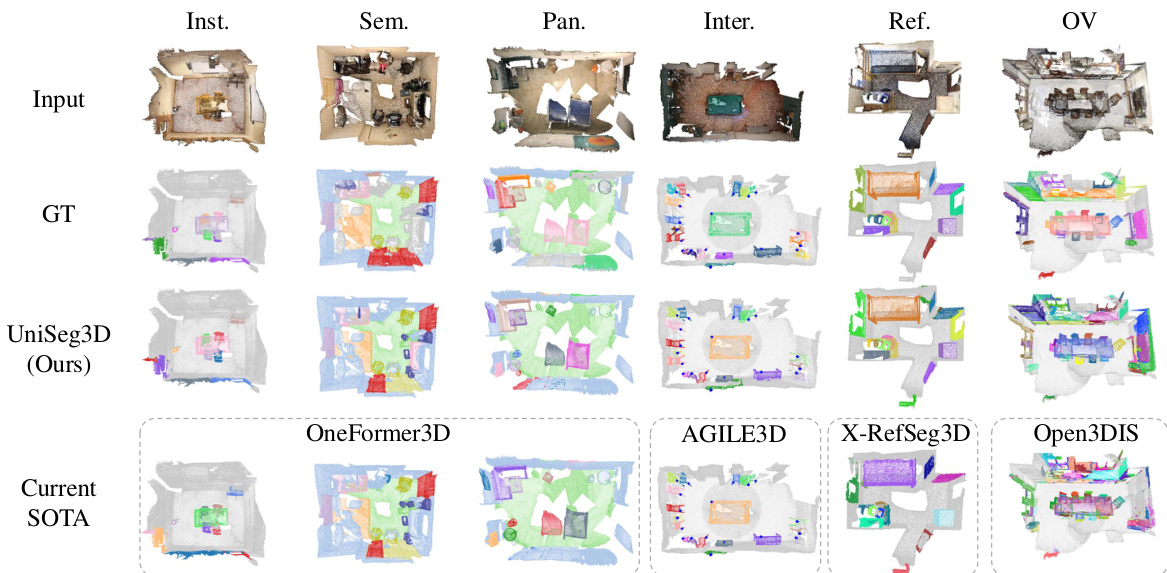
This figure compares the segmentation results of UniSeg3D with several state-of-the-art (SOTA) methods on the ScanNet20 validation split. It shows a visual comparison across six different 3D segmentation tasks: instance segmentation, semantic segmentation, panoptic segmentation, interactive segmentation, referring segmentation, and open-vocabulary segmentation. For each task and method, it displays the input point cloud data, the ground truth segmentation, and the model’s prediction. This allows for a direct visual assessment of UniSeg3D’s performance relative to the current SOTA methods in 3D scene understanding.

This figure compares the proposed UniSeg3D method with state-of-the-art (SOTA) approaches for 3D scene understanding. It shows that existing methods typically focus on individual tasks (a), while a recent unified model, OneFormer3D, handles only three tasks (b). In contrast, UniSeg3D offers a unified solution performing six different 3D segmentation tasks simultaneously (c) and outperforms all previous methods on these tasks (d). The six tasks include panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation. The figure highlights the efficiency and comprehensive nature of UniSeg3D.
More on tables
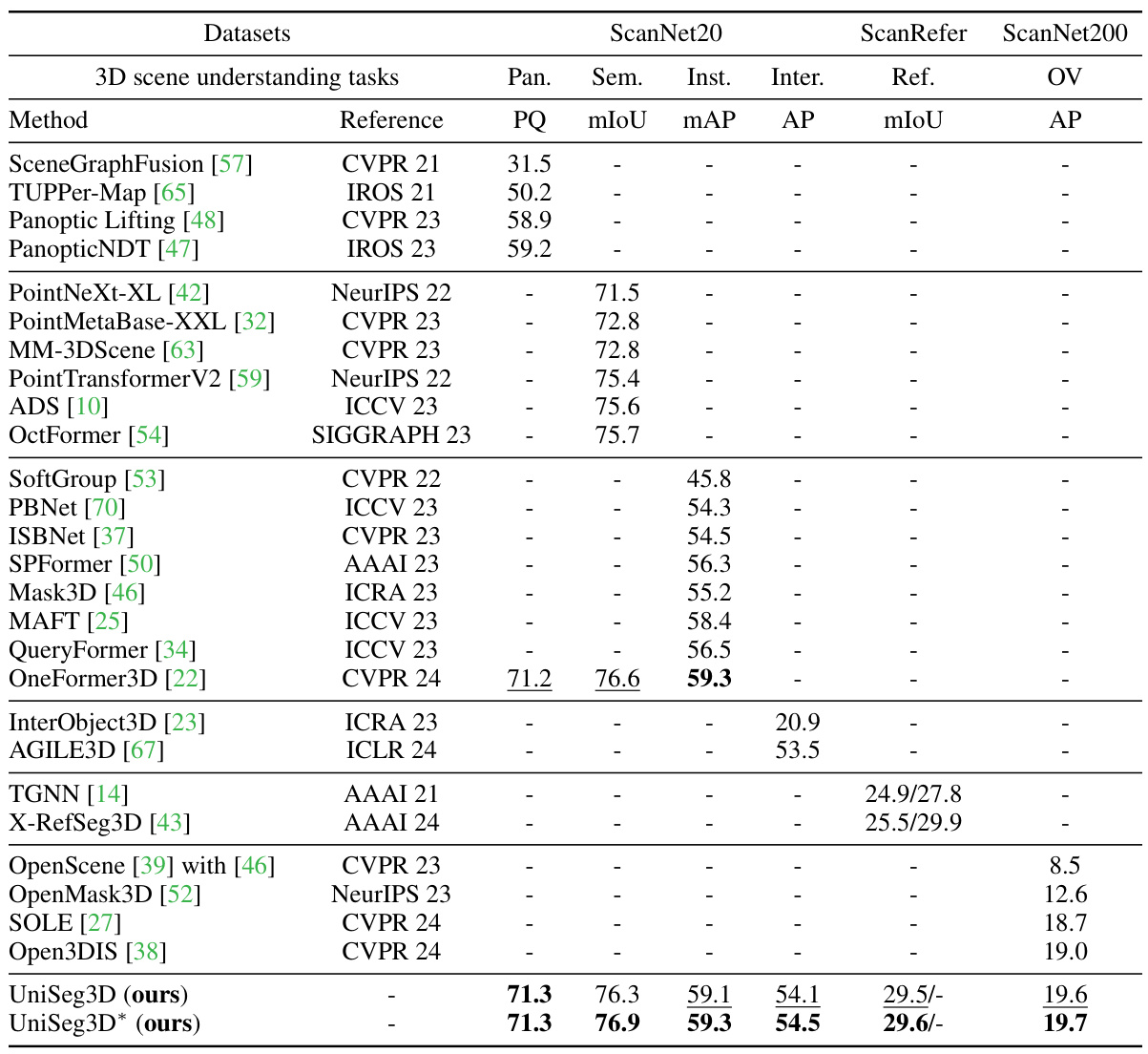
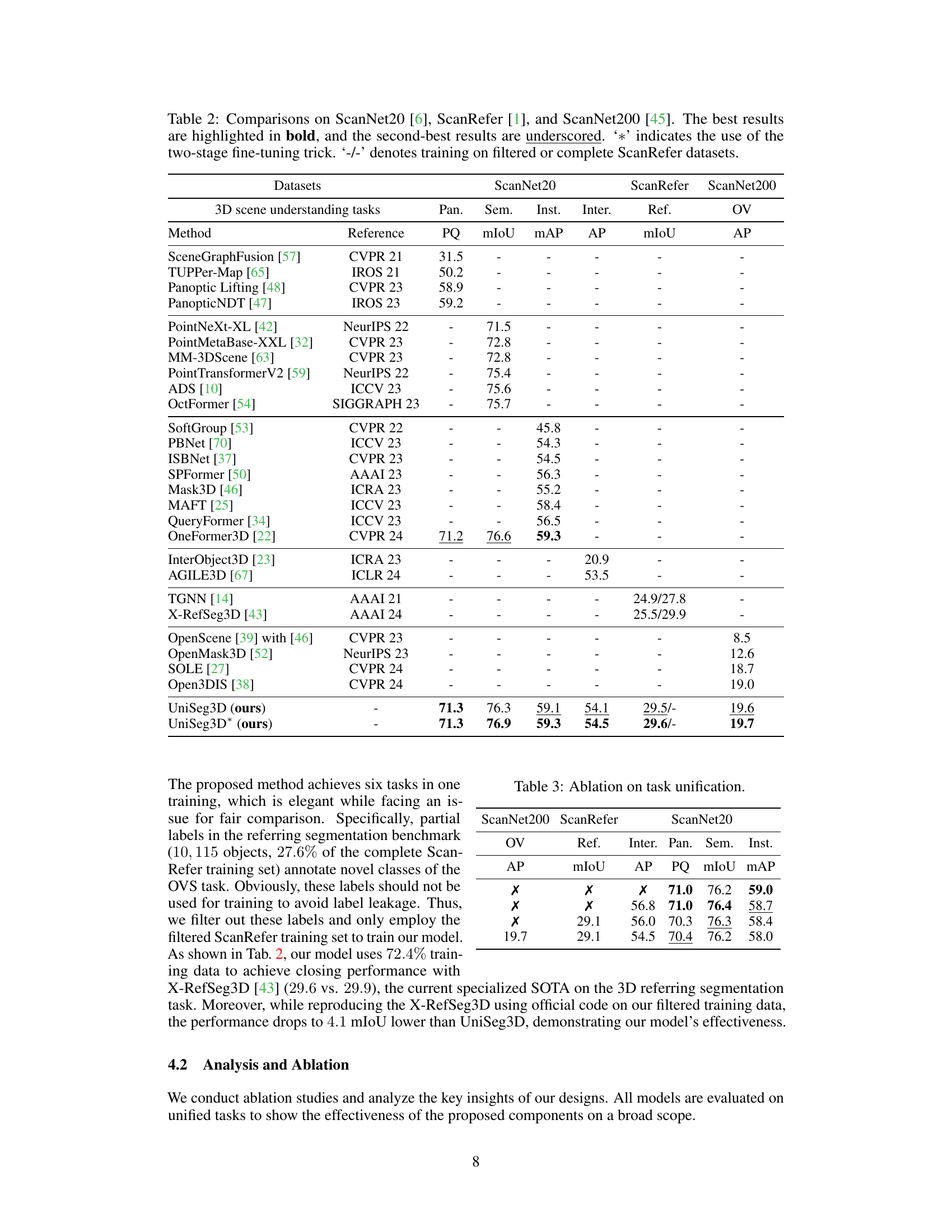
This table presents a comparison of the UniSeg3D model’s performance against state-of-the-art (SOTA) methods on three benchmark datasets: ScanNet20, ScanRefer, and ScanNet200. The comparison covers six 3D scene understanding tasks: panoptic segmentation, semantic segmentation, instance segmentation, interactive segmentation, referring segmentation, and open-vocabulary segmentation. The table highlights the best and second-best results for each task and dataset, indicating UniSeg3D’s superior performance across multiple tasks and datasets. The ‘*’ denotes the results obtained when using a two-stage fine-tuning trick, while ‘-/-’ signifies results obtained using either a filtered or complete version of the ScanRefer dataset.

This table presents the ablation study on the task unification in the UniSeg3D model. It shows the impact of including each of the six tasks (panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation) on the overall performance. The results demonstrate that unifying all six tasks in a single model leads to a performance improvement, though not always uniformly across the different tasks.
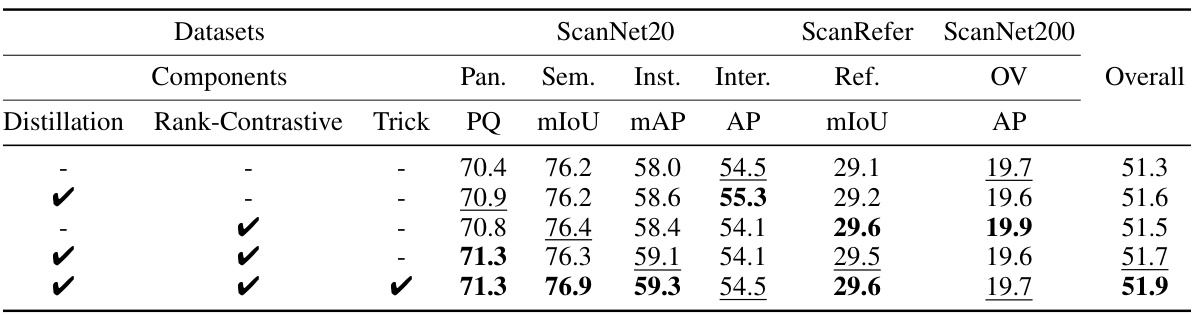
This table presents the ablation study results on different components of the UniSeg3D model. It shows the performance (PQ, mIoU, mAP, AP) on six different 3D segmentation tasks (Panoptic, Semantic, Instance, Interactive, Referring, and Open-Vocabulary) across three datasets (ScanNet20, ScanRefer, and ScanNet200). Each row represents a different combination of the three components: knowledge distillation, ranking-based contrastive learning, and two-stage fine-tuning. The ‘Overall’ column shows the average performance across all tasks and datasets for each configuration.
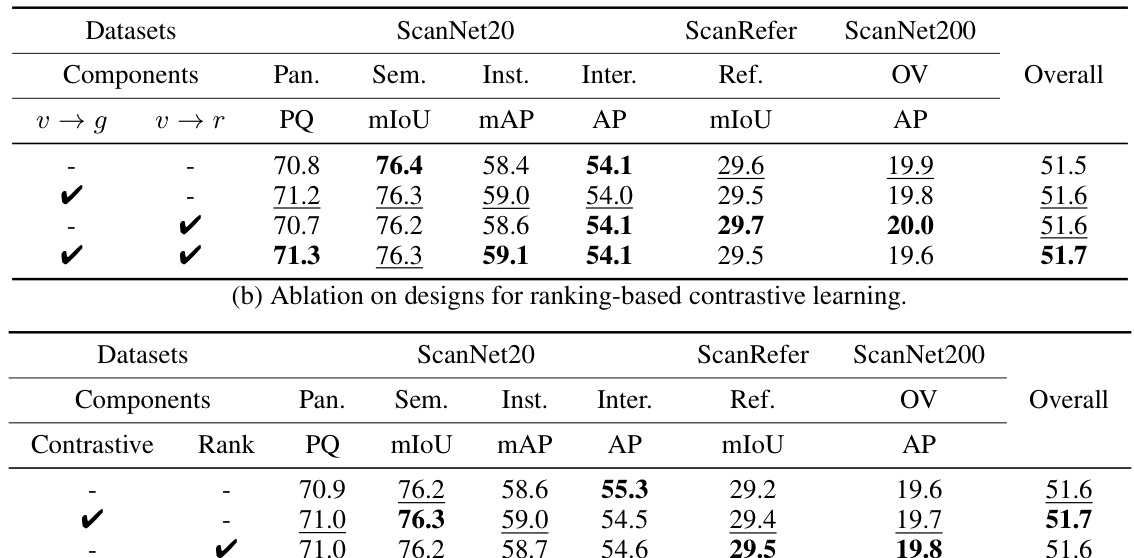
This table presents the ablation study results on different designs of the proposed components for improving the performance of the UniSeg3D model. It shows the impact of knowledge distillation from interactive segmentation to generic and referring segmentation (‘v → g’ and ‘v → r’), contrastive learning (‘Contrastive’), and the ranking rule (‘Rank’) on various metrics for different tasks (Panoptic Segmentation, Semantic Segmentation, Instance Segmentation, Interactive Segmentation, Referring Segmentation, and Open-Vocabulary Segmentation) across three datasets (ScanNet20, ScanRefer, and ScanNet200). Each row represents a different combination of the proposed components, enabling a comprehensive analysis of their individual and combined effects on the model’s performance.
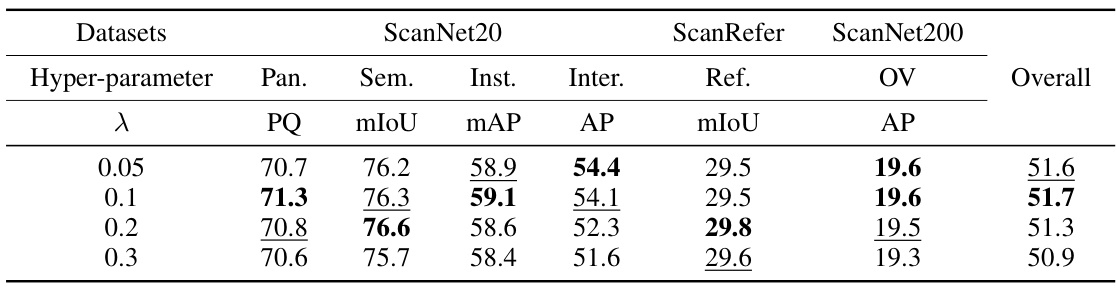
This table presents the ablation study on the hyper-parameter λ, which balances the basic losses and inter-task association losses in the training objective function. The results show the performance of the UniSeg3D model across various tasks (Panoptic Segmentation, Semantic Segmentation, Instance Segmentation, Interactive Segmentation, Referring Segmentation, and Open-Vocabulary Segmentation) on three benchmark datasets (ScanNet20, ScanRefer, and ScanNet200) for different values of λ (0.05, 0.1, 0.2, and 0.3). The Overall column represents the average performance across all six tasks.
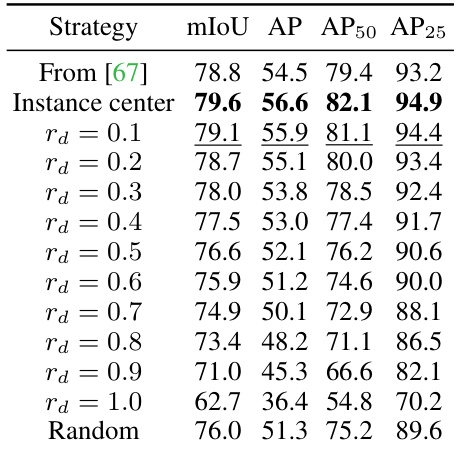
This table presents the ablation study on vision prompts in the interactive segmentation task. It shows the impact of using different strategies for selecting the vision prompt, including using the instance center, points at varying distances from the center (rd), and random point selection. The results are evaluated using mIoU, AP, AP50, and AP25 metrics. The goal is to determine the optimal strategy for selecting vision prompts to improve interactive segmentation performance.
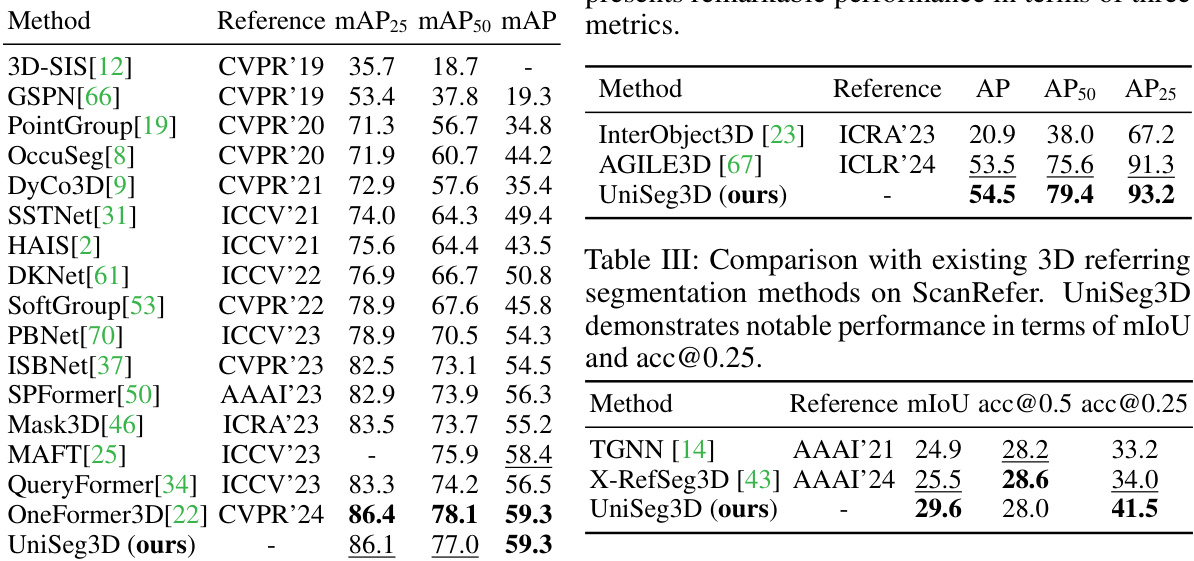
This table presents a comparison of the UniSeg3D model’s performance against state-of-the-art (SOTA) methods on three benchmark datasets: ScanNet20, ScanRefer, and ScanNet200. It shows the performance of UniSeg3D and other methods across multiple 3D scene understanding tasks, including panoptic, semantic, instance, interactive, referring, and open-vocabulary segmentation. The results highlight UniSeg3D’s superior performance and ability to unify these diverse tasks within a single model. The use of a two-stage fine-tuning technique is also noted, and differences in training data are indicated.
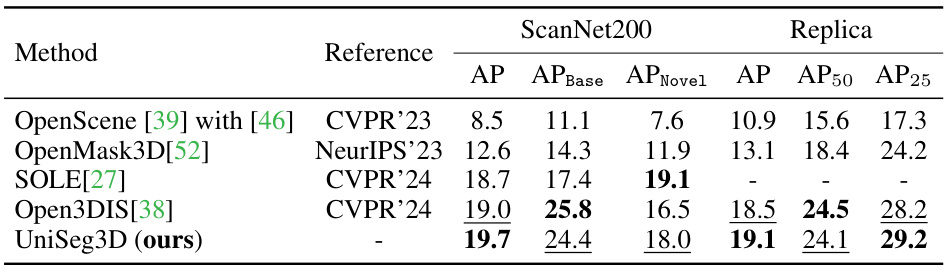
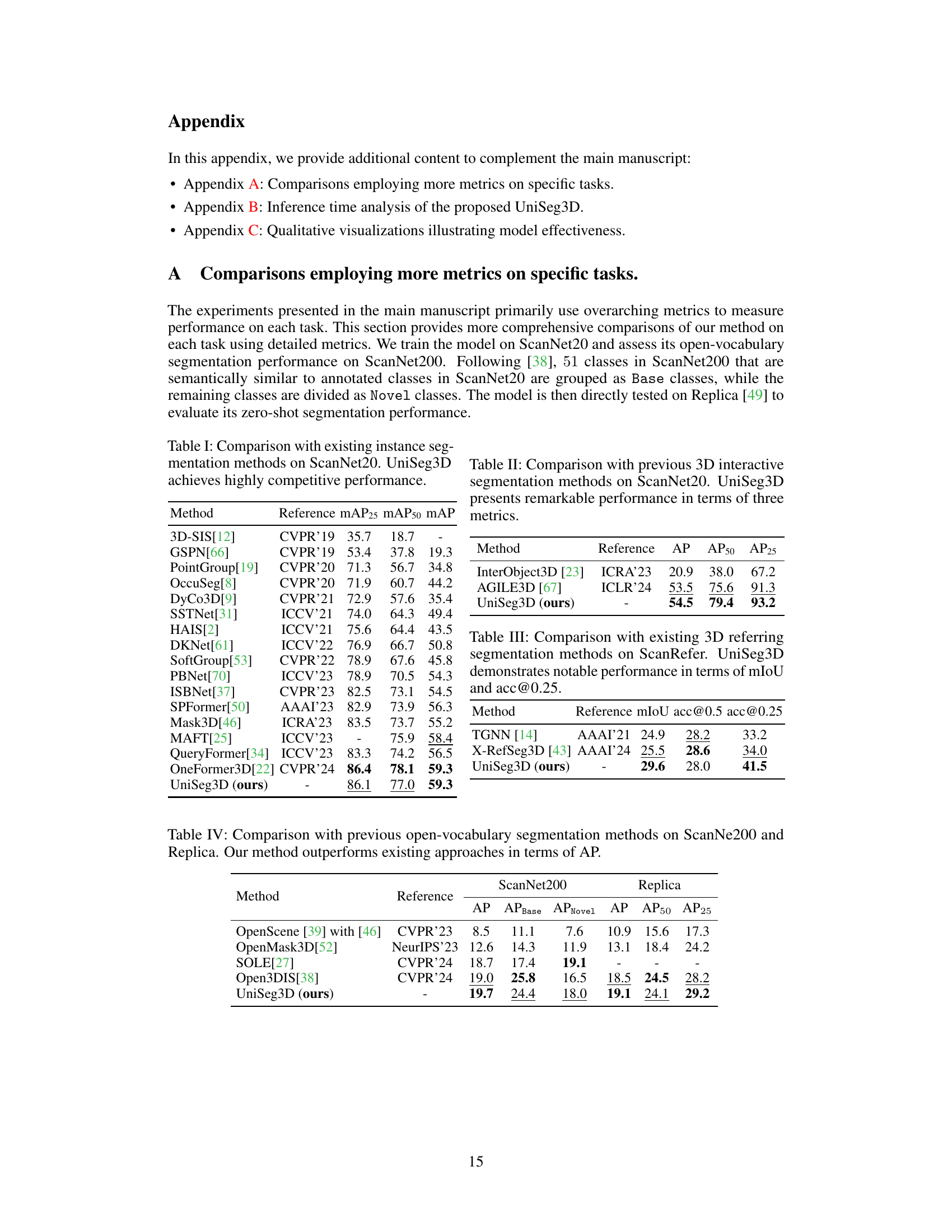
This table compares the performance of UniSeg3D against state-of-the-art (SOTA) methods for open-vocabulary segmentation on two benchmark datasets: ScanNet200 and Replica. The table presents Average Precision (AP) scores, broken down by AP for base classes and novel classes (ScanNet200 only), as well as AP at different IoU thresholds (AP50, AP25) for Replica. UniSeg3D demonstrates superior performance compared to the other methods.
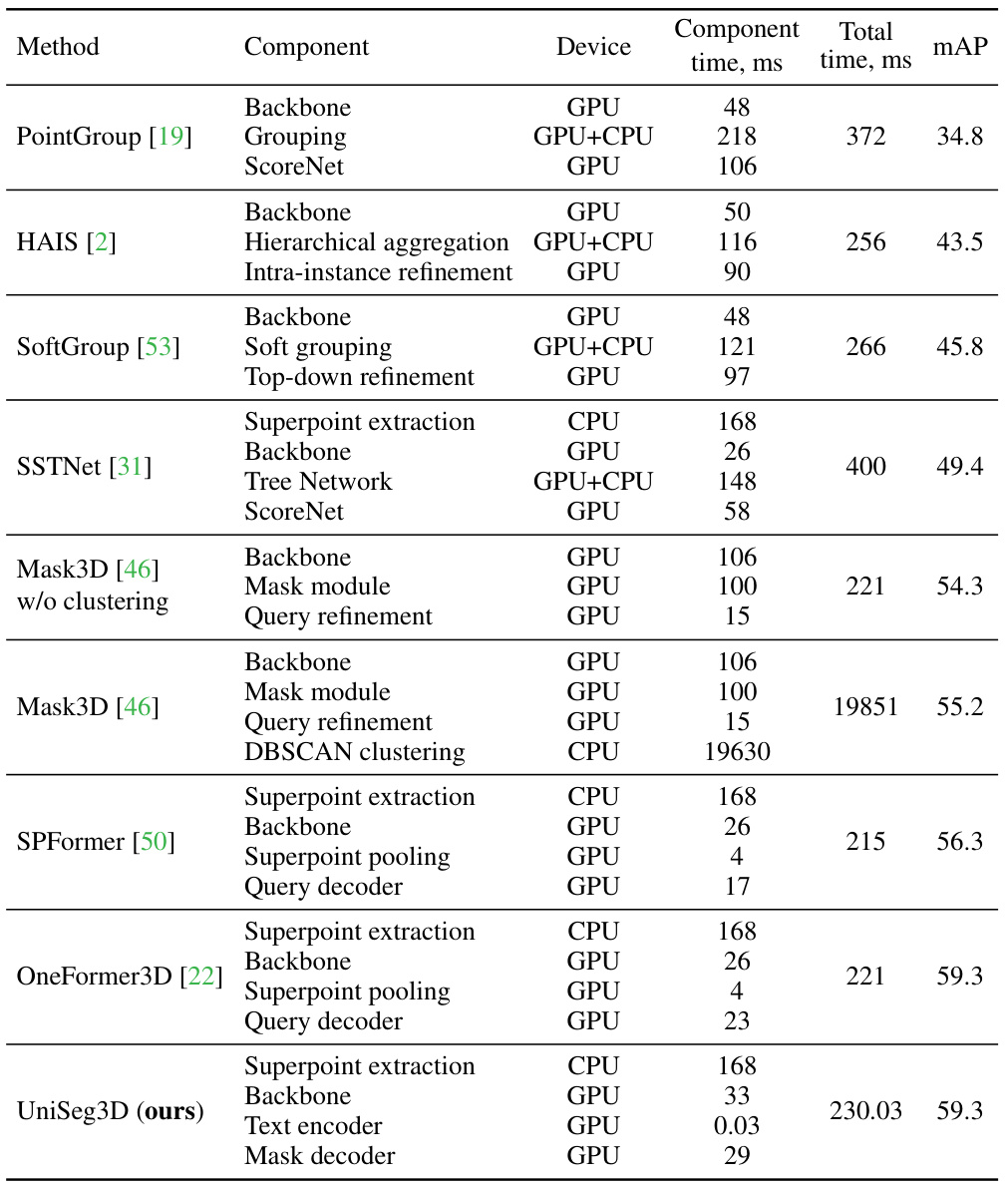
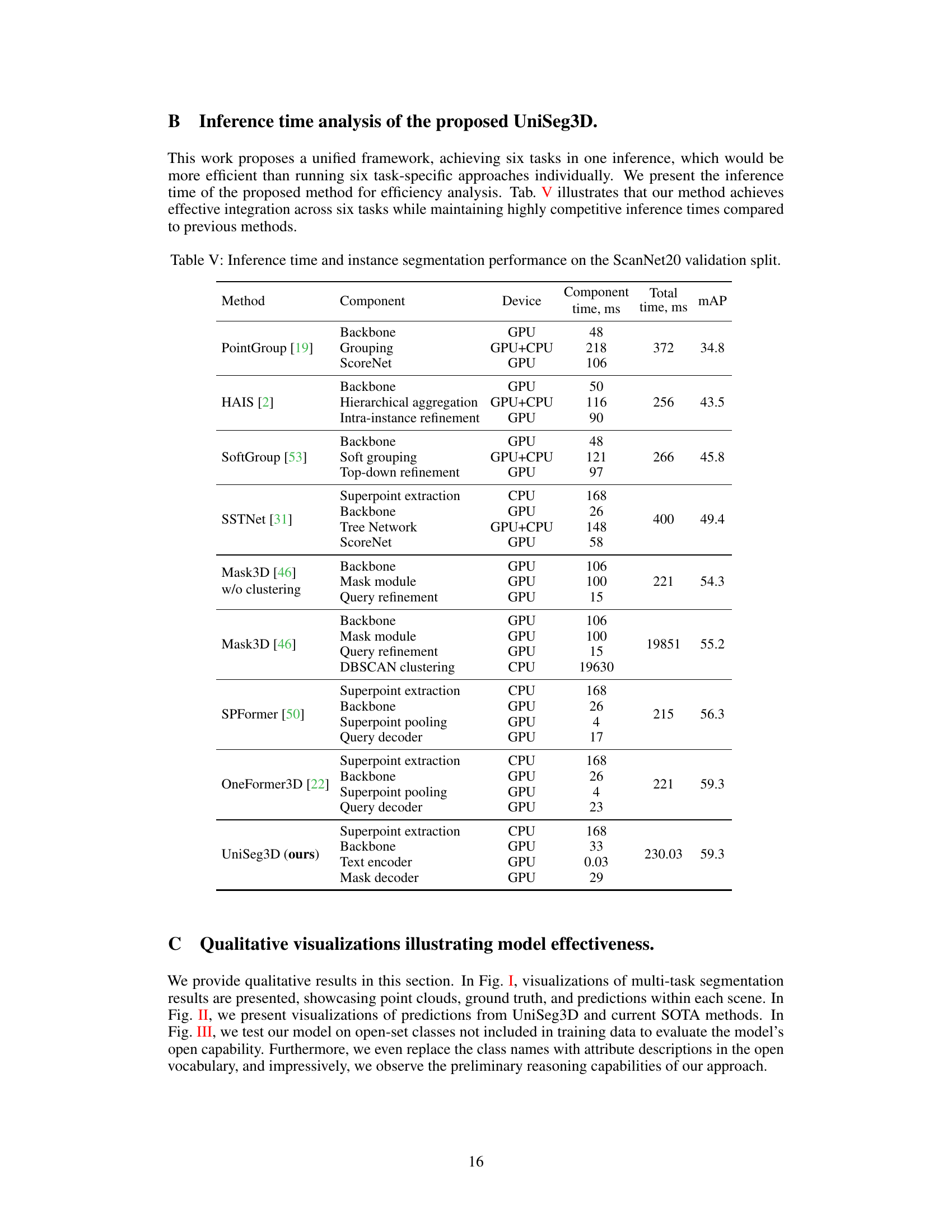
This table compares the inference time and instance segmentation performance of UniSeg3D against other state-of-the-art methods on the ScanNet20 validation dataset. It breaks down the inference time for each component (backbone, grouping, refinement, etc.) and the total inference time for each model, providing a detailed comparison of computational efficiency across different approaches.
Full paper#