↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Online reconstruction of dynamic scenes from streaming videos is challenging due to limitations in training, rendering, and storage efficiency. Existing methods like 3D Gaussian Splatting (3DGS) are prone to overfitting and inefficient storage. This leads to slow training and suboptimal rendering performance, hindering real-time applications.
HiCoM addresses these issues by employing a three-component approach: a compact and robust initial 3DGS representation, a hierarchical coherent motion mechanism for efficient motion learning, and continual refinement for adapting to the evolving scene. Parallel training further accelerates the process. HiCoM demonstrates significant improvements in learning efficiency, storage efficiency, and real-time performance compared to existing methods, paving the way for more efficient dynamic scene reconstruction and real-time free-viewpoint video applications.
Key Takeaways#
Why does it matter?#
This paper is significant for researchers working on real-time 3D scene reconstruction and free-viewpoint video generation. It addresses the limitations of existing methods by introducing a novel hierarchical approach and parallel processing. Its efficient framework, which improves learning efficiency and storage efficiency, is highly relevant to current research trends and offers new avenues for enhancing real-world applications and responsiveness.
Visual Insights#

This figure showcases the performance of the HiCoM framework in comparison to other state-of-the-art methods for streamable dynamic scene reconstruction. The left panels display results on two different datasets (N3DV and Meet Room), highlighting the video resolution, training time, rendering speed, storage, and PSNR (Peak Signal-to-Noise Ratio) achieved by HiCoM. The right panel presents a comparison of various methods based on their training time and average storage per frame (represented by circle size), with HiCoM demonstrating superior performance in both aspects.
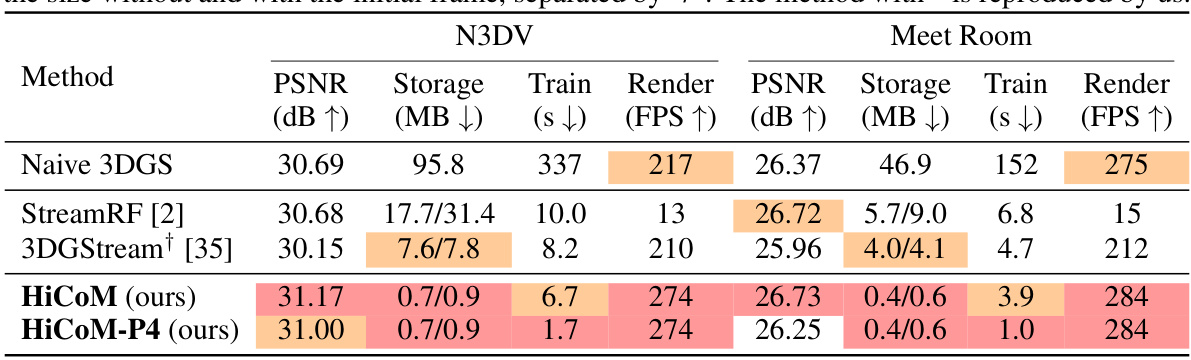
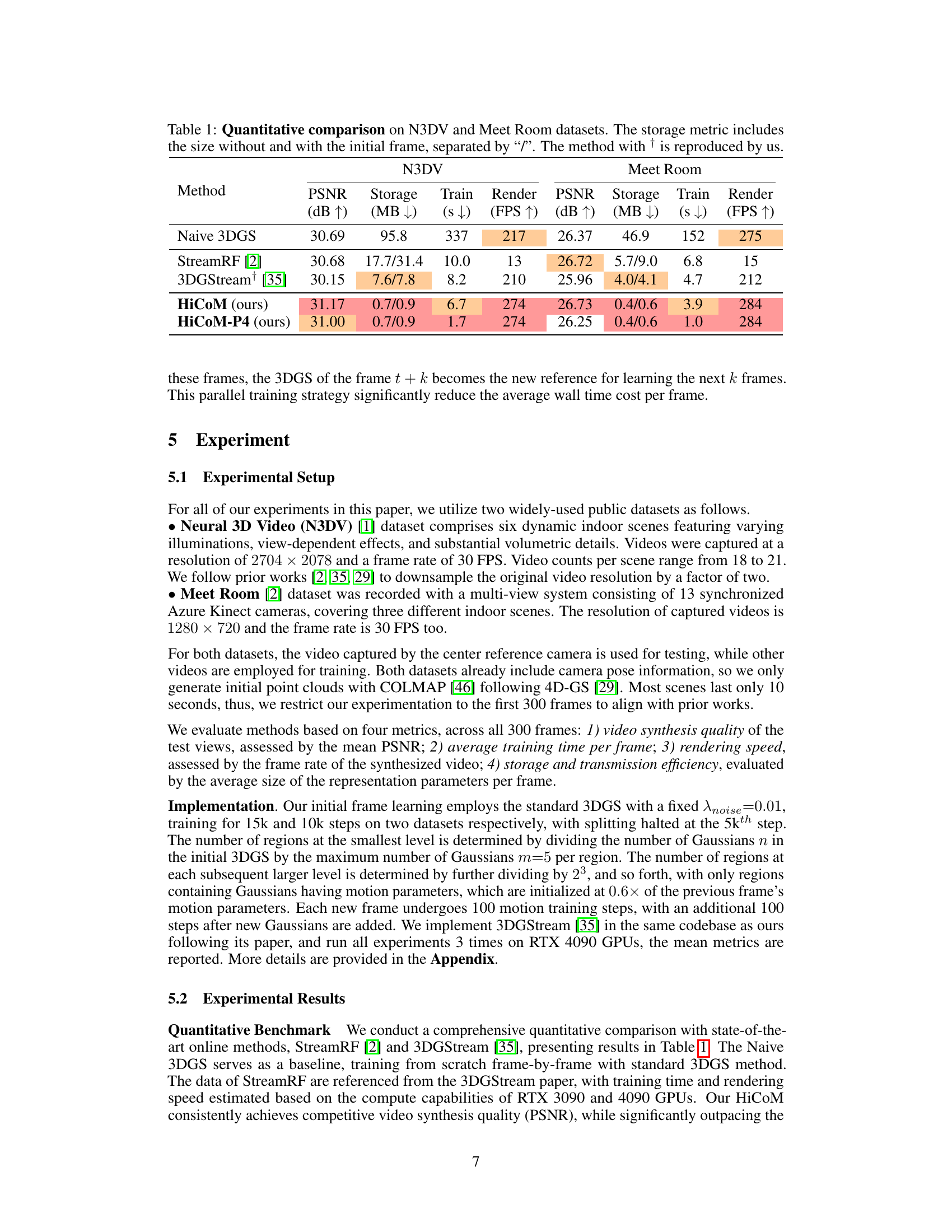
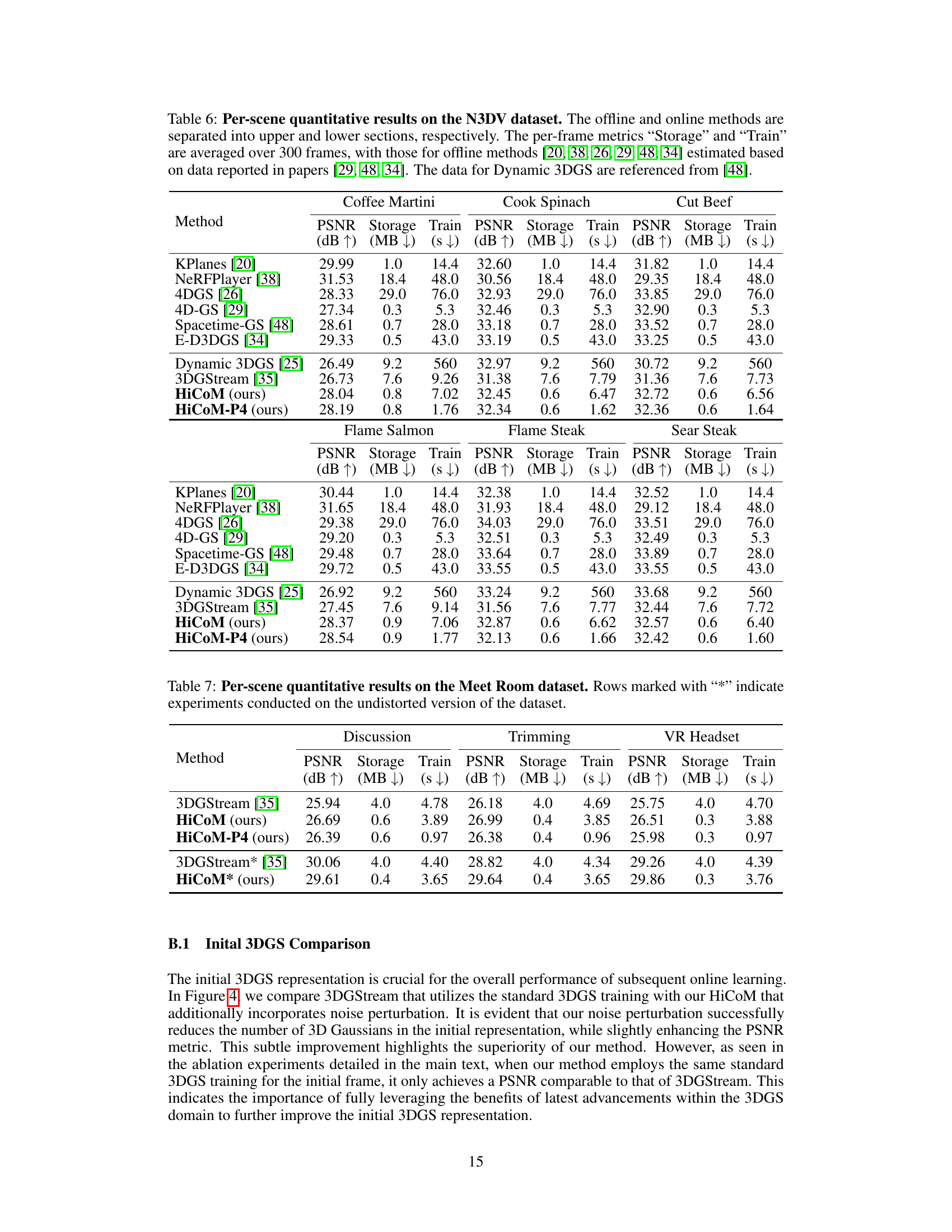
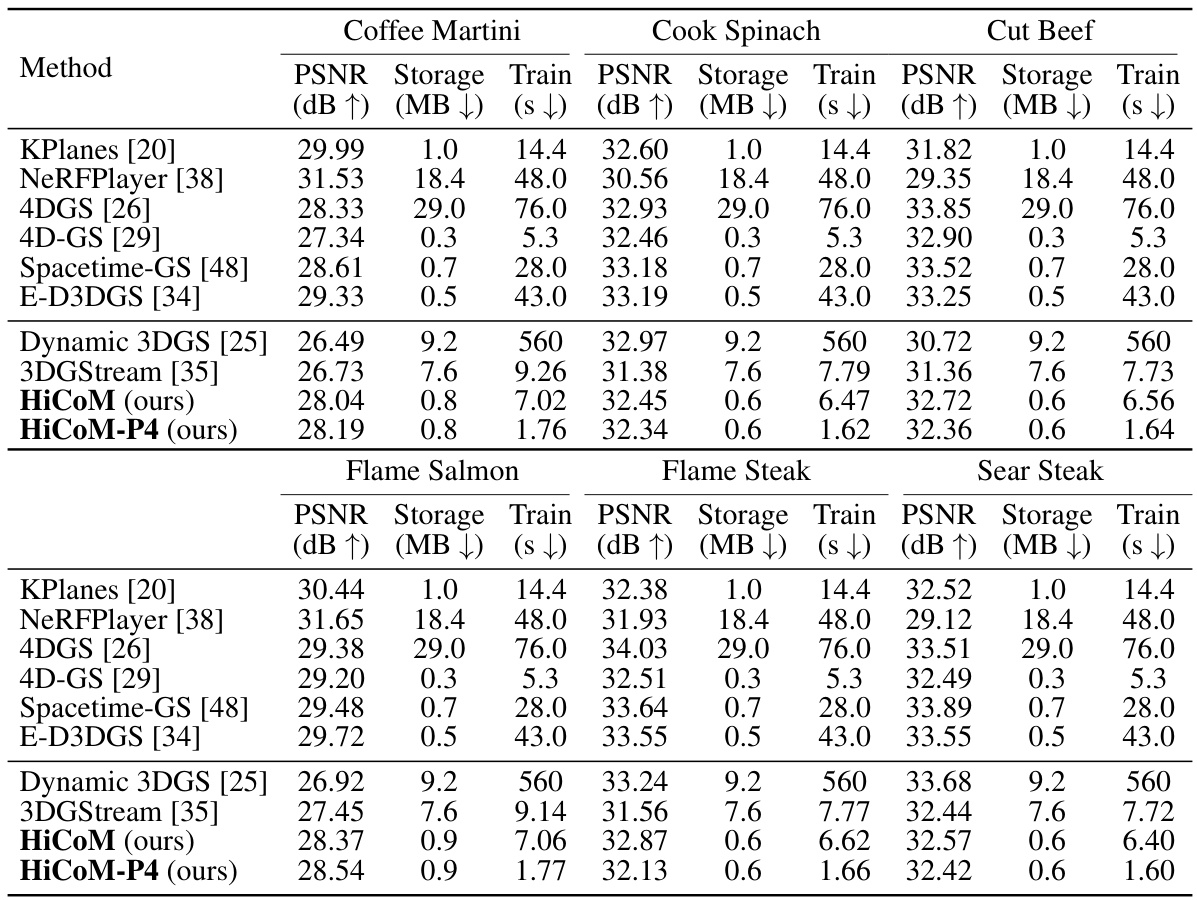
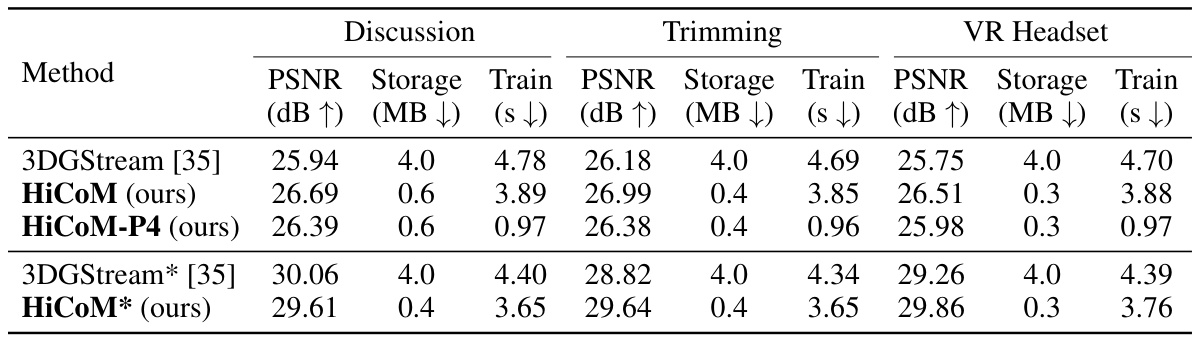
This table presents a quantitative comparison of different methods for dynamic scene reconstruction on two datasets: N3DV and Meet Room. The metrics used for comparison include PSNR (peak signal-to-noise ratio, a measure of image quality), storage (size of the model in MB), training time (in seconds), and rendering speed (in frames per second). The storage metric is further broken down into storage without and with the initial frame. One of the methods is a reproduction by the authors of the paper.
In-depth insights#
HiCoM Framework#
The HiCoM framework presents a novel approach to online dynamic scene reconstruction from multi-view video streams, addressing limitations in existing methods by focusing on efficiency and robustness. It leverages 3D Gaussian Splatting for its speed and efficiency, but enhances this base with three key innovations: First, a perturbation smoothing strategy during initial 3DGS representation learning creates a compact and robust initial model, reducing overfitting and promoting stability. Second, a hierarchical coherent motion mechanism efficiently models scene motion across frames, capturing motion at varying granularities using region-based motion parameters. This significantly reduces computational costs and maintains consistency across the scene. Finally, a continual refinement process ensures the model remains aligned with the evolving scene, dynamically adding and merging Gaussians, while simultaneously removing low-impact Gaussians to retain compactness. This framework allows for significantly faster training times and reduced data storage, thereby making it well-suited for real-time, streamable applications.
Perturbation Smoothing#
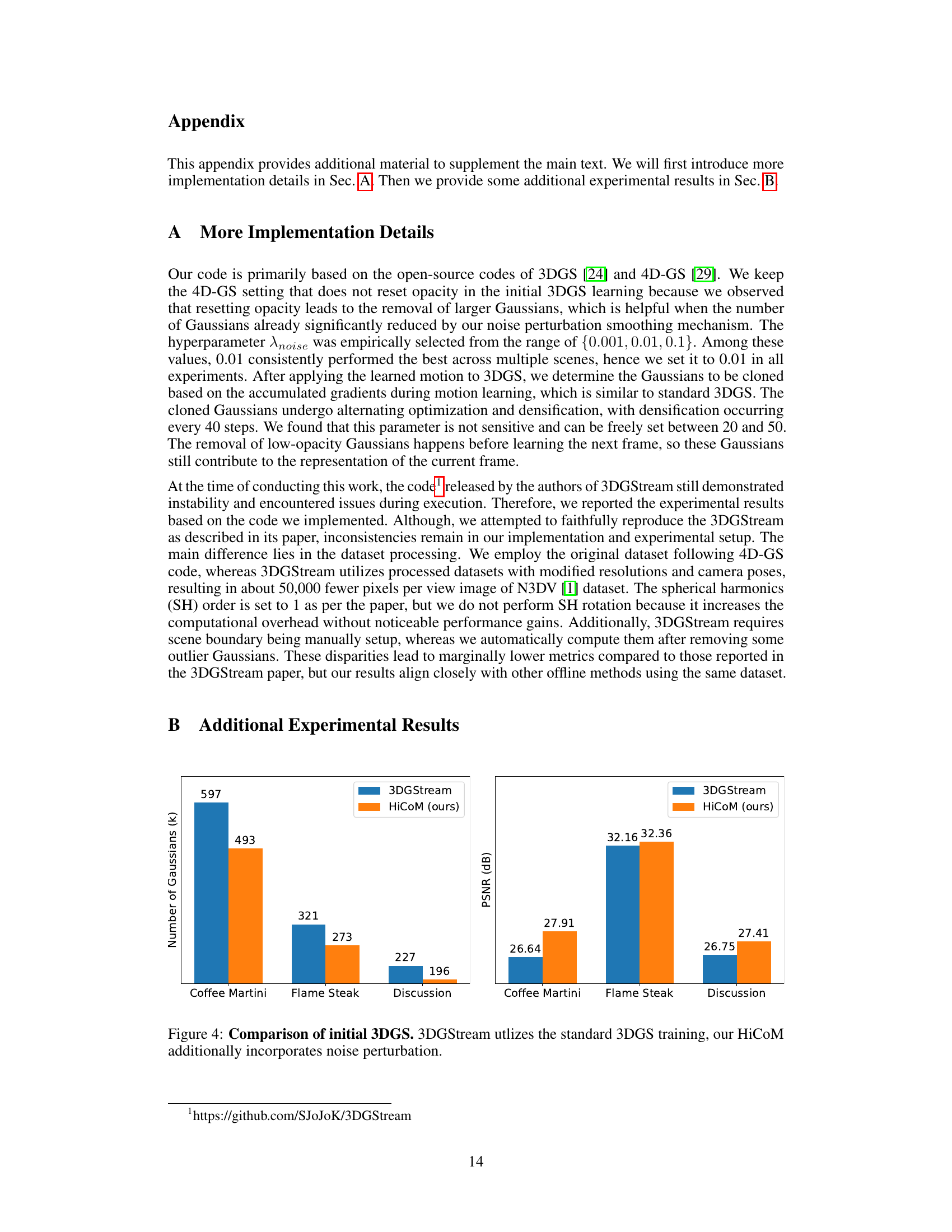
The concept of ‘Perturbation Smoothing’ in the context of 3D Gaussian Splatting for dynamic scene reconstruction is a clever regularization technique. By adding noise to the Gaussian’s position during training, it prevents overfitting to limited training views, a common problem when dealing with dynamic scenes captured by a sparse set of cameras. This controlled perturbation acts as a smoothing agent, guiding the model towards a more robust and generalizable representation. The reduced risk of overfitting translates to a more compact and efficient initial 3D Gaussian Splatting representation, requiring fewer Gaussians to capture the scene accurately. This, in turn, leads to faster convergence during subsequent frame learning, and significantly lower storage and transmission requirements, making the overall framework more efficient and effective for real-time applications. The perturbation smoothing is not merely a technique to improve performance, but also crucial for creating a solid foundation upon which the coherent motion mechanisms are applied, allowing the algorithm to smoothly and accurately capture the scene dynamics.
Motion Mechanism#
The effectiveness of a motion mechanism in reconstructing dynamic scenes hinges on its ability to accurately capture and model temporal changes. A robust mechanism should handle both smooth, gradual movements and sudden, abrupt shifts, adapting to varying scene complexities. Computational efficiency is crucial, minimizing memory usage and processing time. The ideal system would incorporate a representation that easily handles updates and merges new information seamlessly into the existing model, ensuring a compact and efficient representation of the evolving scene. Furthermore, a successful mechanism should exhibit generalizability, performing well across diverse scene types and qualities. The ability to accurately predict future frames, based on learned motion patterns, is also critical for real-time applications and efficient storage. Finally, the system should be resilient to noise and missing data, maintaining accuracy and stability even with incomplete or imperfect observations.
Continual Refinement#
The ‘Continual Refinement’ process described in the paper is a crucial component of their online 3D scene reconstruction framework. It addresses the limitations of simply relying on motion prediction alone by acknowledging that dynamic scenes evolve gradually, exceeding the capacity of motion estimation to capture all details. The strategy involves identifying regions with significant discrepancies between the learned motion and the actual scene changes, indicated by high gradients. New Gaussians are strategically added to these areas, improving the accuracy of the 3D model. Importantly, these newly added Gaussians are not discarded at the end of each frame. Instead, they are integrated into the initial 3DGS representation, ensuring consistency across frames and maintaining a compact scene representation over time. This continual refinement, in conjunction with a strategy for removing low-impact Gaussians, maintains the balance between accuracy and efficiency, preventing excessive model growth that could slow down rendering and learning speed. The continual adjustment process is therefore key for handling gradual changes and major updates in the scene, leading to more stable, robust, and temporally coherent 3D reconstruction results.
Parallel Training#
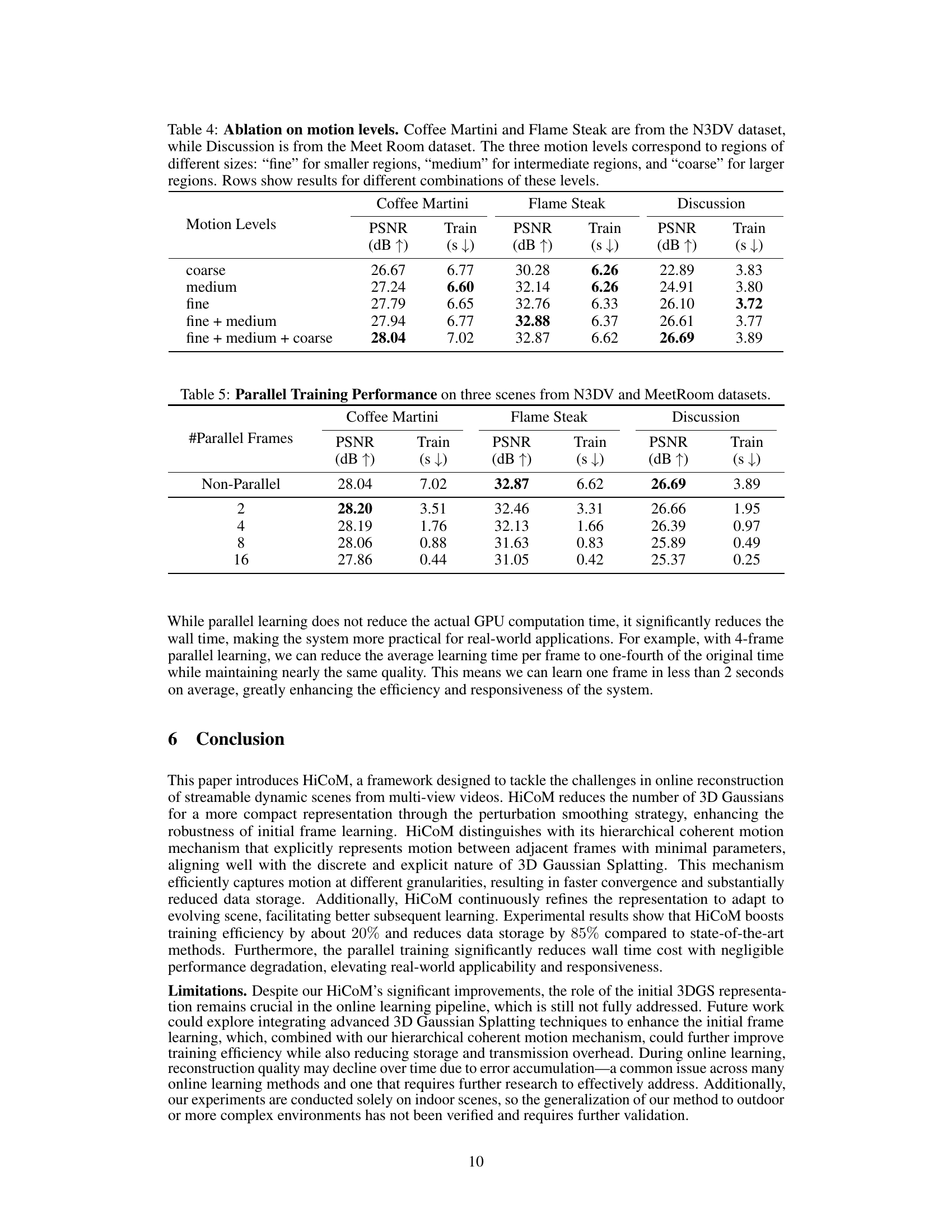
The section on “Parallel Training” explores a significant efficiency enhancement. Instead of processing frames sequentially, the authors propose training multiple frames concurrently. This parallel processing leverages the inherent similarity between consecutive frames in dynamic scenes, treating a base frame as a reference to predict subsequent frames. This strategy reduces training time dramatically. However, the effectiveness is not unbounded; increasing the number of parallel frames beyond a certain point leads to performance degradation due to accumulating discrepancies between the reference and subsequent frames. Optimal performance seems to exist at an intermediate level of parallelism, suggesting a balance between efficiency gains and error accumulation. The authors’ careful analysis of this trade-off and its impact on overall quality highlights the nuanced nature of parallel training in this context.
More visual insights#
More on figures
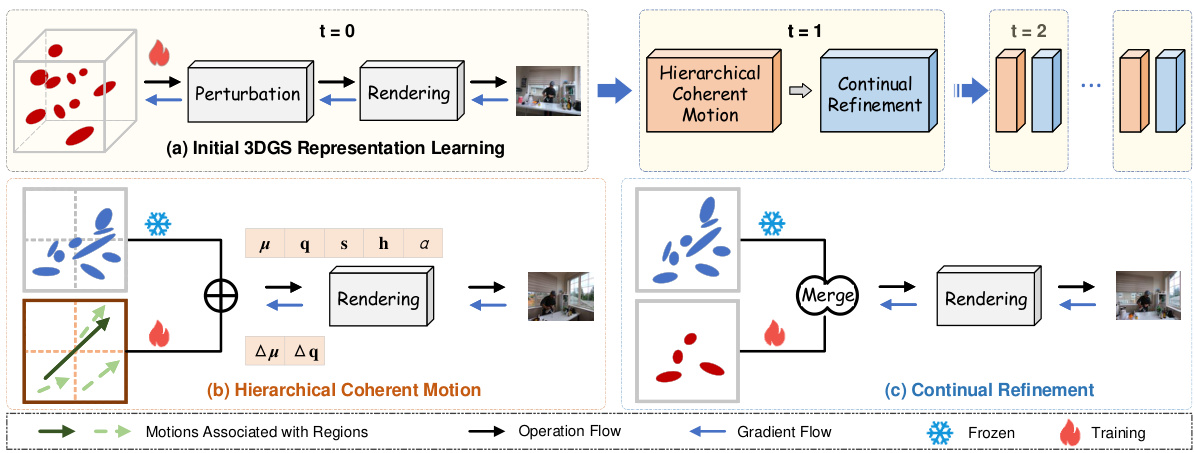
This figure illustrates the HiCoM framework’s three main stages: 1. Initial 3DGS representation learning uses perturbation smoothing for a compact and robust starting point. 2. Hierarchical Coherent Motion efficiently learns motion across frames using a hierarchical approach, leveraging consistency within and between regions. 3. Continual Refinement refines the 3DGS with additional Gaussians and removes low-impact ones to maintain model compactness and accuracy, adapting to evolving scenes. This process iteratively refines the model for each new frame.

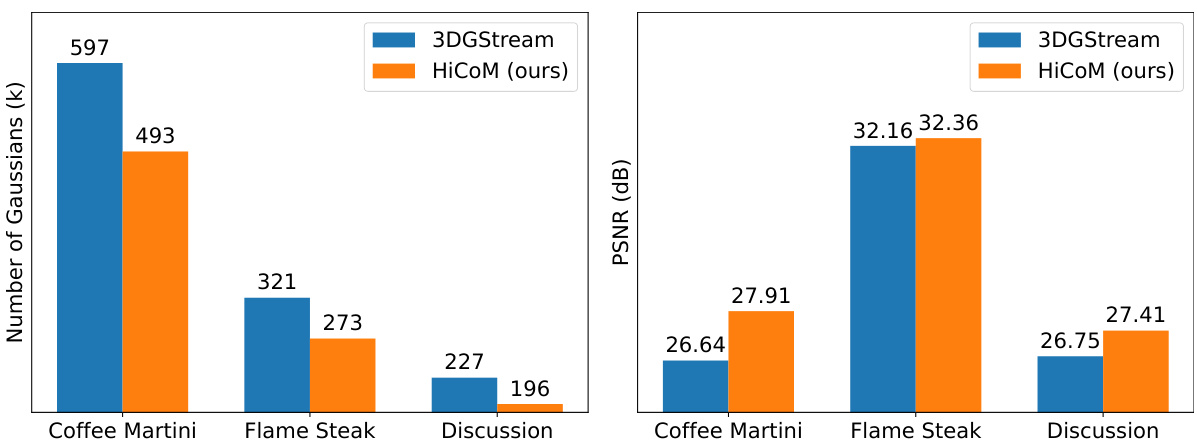
This figure compares the results of the proposed HiCoM method with those of 3DGStream and ground truth on the Coffee Martini scene. It shows six frames (1st, 61st, 121st, 181st, 241st, and 300th) from the test video. Red boxes highlight areas with significant temporal motion to illustrate the improved temporal coherence of HiCoM compared to 3DGStream and ground truth.
This figure illustrates the HiCoM framework’s workflow. It starts by creating a compact initial 3D Gaussian Splatting (3DGS) representation using perturbation smoothing. Subsequent frames are processed iteratively. The Hierarchical Coherent Motion mechanism efficiently updates the 3DGS based on learned motion, and the Continual Refinement step adds and merges Gaussians to maintain accuracy. This iterative process continues until the entire video is processed.

This figure presents a qualitative comparison of video frames generated by the proposed HiCoM method and the 3DGStream method against ground truth (GT) data for five different scenes from the N3DV dataset. The selected frames (1st, 61st, 121st, 181st, 241st, and 300th) showcase the temporal coherence and motion handling capabilities of each method. Red boxes highlight regions with significant temporal changes to facilitate visual comparison.
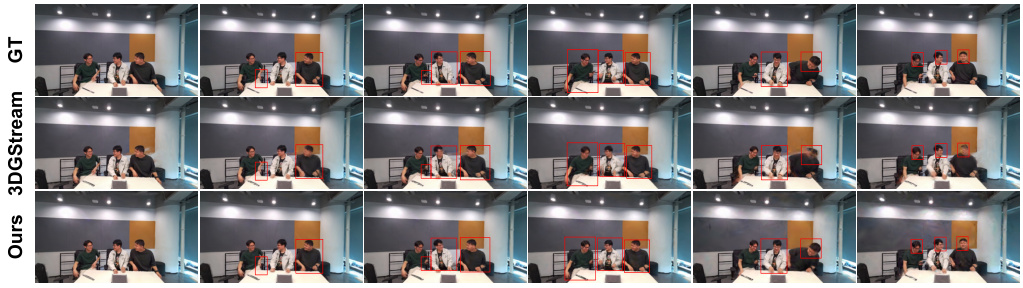
This figure compares the visual quality of the Coffee Martini scene reconstruction from three methods: the proposed HiCoM, 3DGStream, and the ground truth. It shows six frames (1st, 61st, 121st, 181st, 241st, and 300th) from the test video. Red boxes highlight regions with significant dynamic motions, such as a person’s head and hands, demonstrating HiCoM’s improved temporal coherence and closer match to the ground truth compared to 3DGStream.

This figure shows a qualitative comparison of the Coffee Martini scene reconstruction results between the proposed HiCoM method, the 3DGStream method, and the ground truth. It displays six frames (1st, 61st, 121st, 181st, 241st, and 300th) from the video sequence. Red boxes highlight areas with significant motion to emphasize the temporal coherence achieved by HiCoM in comparison to 3DGStream. The results demonstrate HiCoM’s superior performance in capturing dynamic elements and maintaining temporal consistency.

This figure compares the qualitative results of the Coffee Martini scene reconstruction using three different methods: ground truth (GT), 3DGStream, and the proposed HiCoM method. Six frames (1st, 61st, 121st, 181st, 241st, and 300th) from the test video are shown, highlighting areas with significant temporal motion using red boxes. The results demonstrate that the HiCoM method achieves better temporal coherence and more closely matches the ground truth compared to 3DGStream.

This figure illustrates the HiCoM framework’s three main stages: 1. Initial 3DGS representation learning using a perturbation smoothing strategy to obtain a compact and robust initial representation. 2. Hierarchical Coherent Motion, which leverages the non-uniform distribution and local consistency of 3D Gaussians to efficiently learn motion across frames. 3. Continual Refinement, which involves adding and merging Gaussians to maintain consistency with evolving scenes. The figure shows the workflow and data flow for each stage.
More on tables
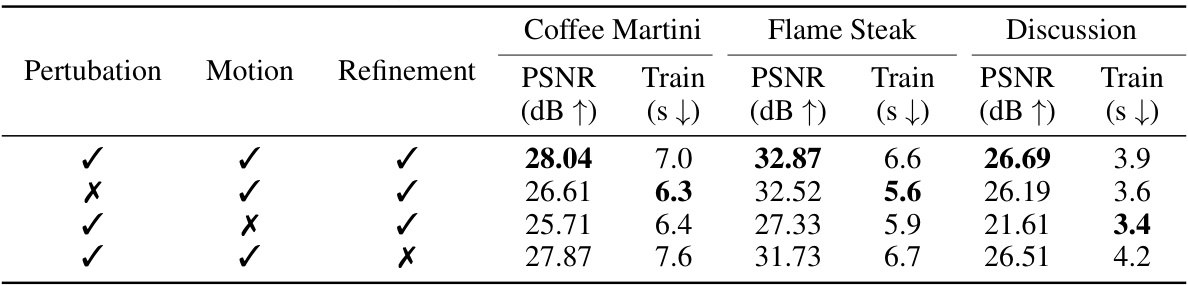
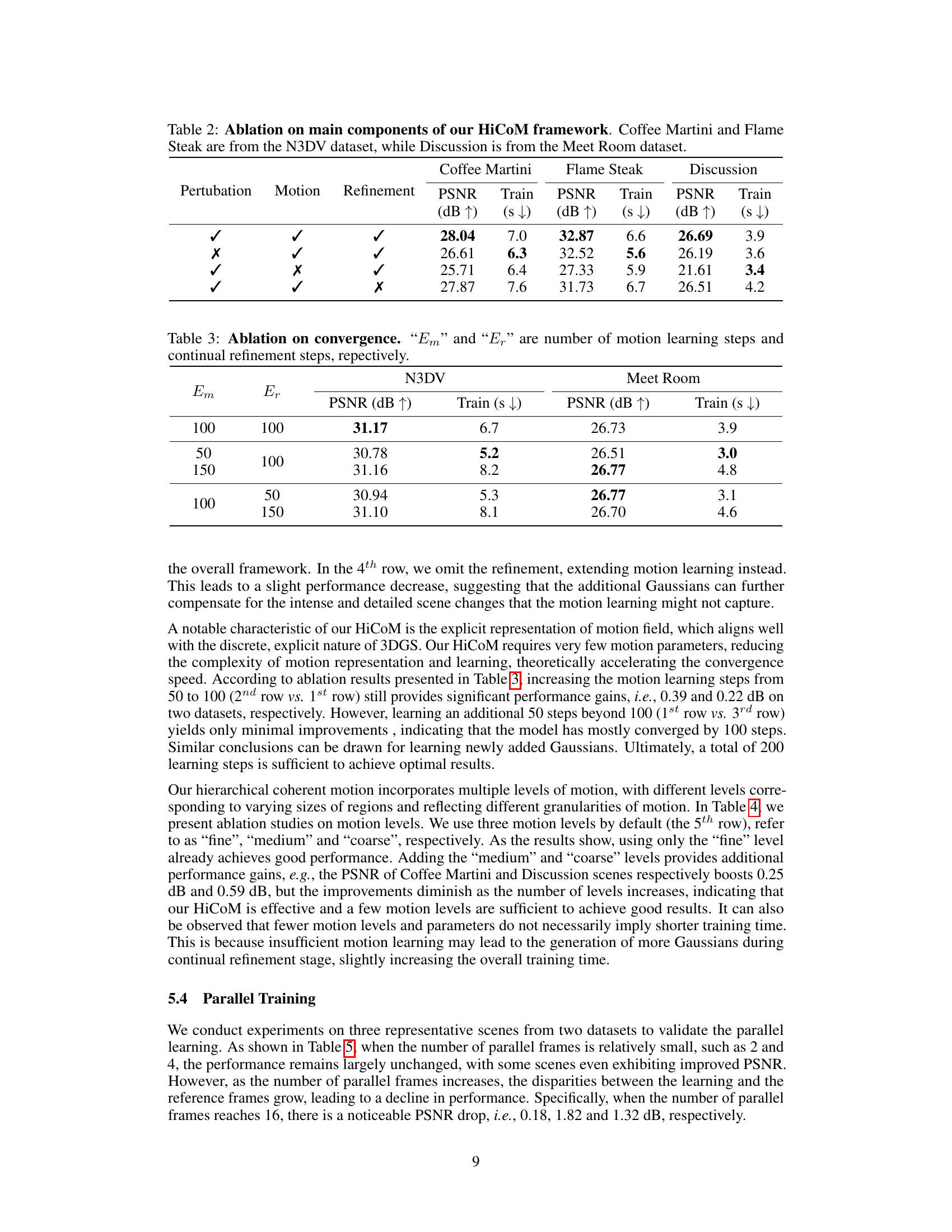
This table presents the ablation study results on three key components of the HiCoM framework: perturbation, motion, and refinement. It shows the impact of each component on the PSNR (peak signal-to-noise ratio) and training time for three different scenes from two datasets: Coffee Martini and Flame Steak from N3DV, and Discussion from MeetRoom. The results demonstrate the contribution of each component to the overall performance of the HiCoM framework.
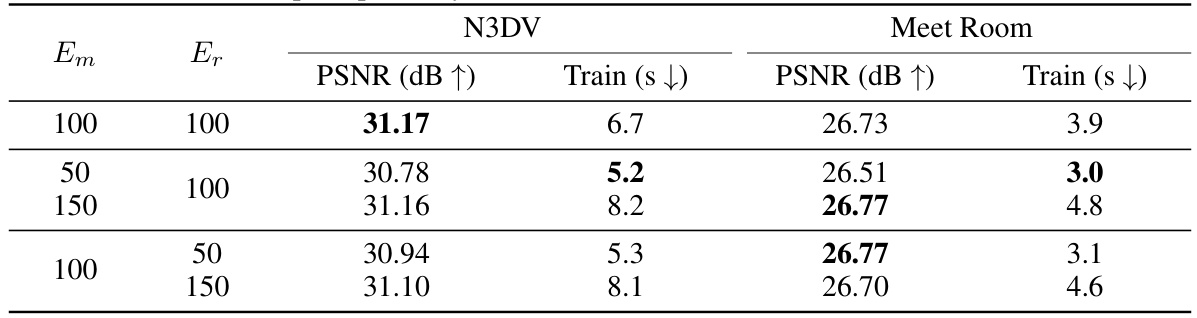
This table presents the ablation study on the convergence of the HiCoM framework by varying the number of motion learning steps (Em) and continual refinement steps (Er). It shows how different combinations of Em and Er affect the PSNR (peak signal-to-noise ratio) and training time on the N3DV and Meet Room datasets. The results demonstrate the impact of these two hyperparameters on the model’s performance and convergence.
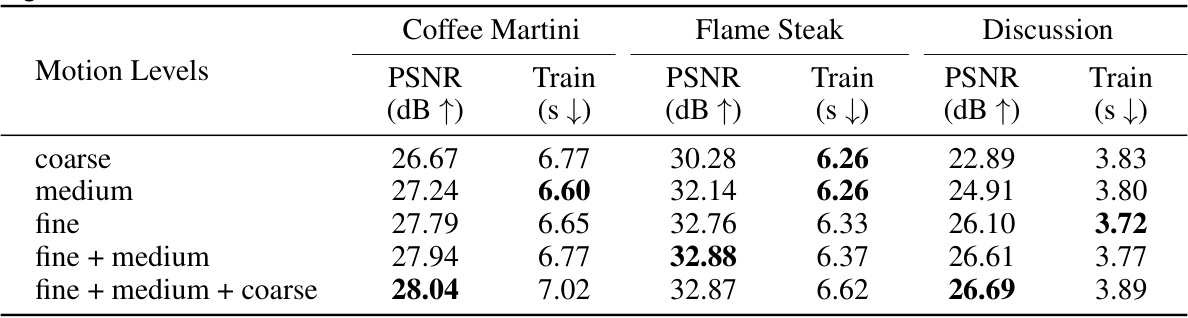
This table presents the ablation study on the impact of different motion levels in the HiCoM framework on three scenes from two datasets. It shows the PSNR (peak signal-to-noise ratio) and training time for various combinations of motion levels (coarse, medium, fine). The results help determine the optimal level of granularity for motion modeling in the HiCoM architecture.
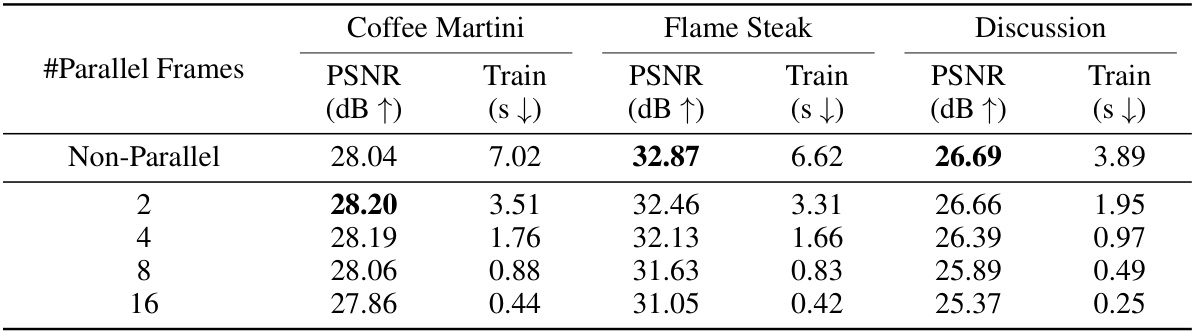
This table presents the results of experiments evaluating the impact of parallel training on the model’s performance. It shows the PSNR (peak signal-to-noise ratio) and training time (in seconds) for three different scenes (Coffee Martini, Flame Steak, and Discussion) from the N3DV and Meet Room datasets. The results are presented for different numbers of parallel frames (2, 4, 8, 16) and compared to the non-parallel training approach. The table highlights the trade-off between training speed and performance accuracy as the number of parallel frames increases.
This table quantitatively compares the proposed HiCoM framework with existing methods (Naive 3DGS, StreamRF, and 3DGStream) on the N3DV and Meet Room datasets. The metrics used for comparison are PSNR (peak signal-to-noise ratio, measuring reconstruction quality), storage (in MB, reflecting memory efficiency), training time (in seconds, indicating learning speed), and rendering speed (in FPS, representing real-time capability). The storage metric is presented as two values separated by a forward slash; the first value indicates storage without the initial frame, and the second includes the initial frame’s size. One of the methods was reproduced by the authors for fair comparison.
This table presents a quantitative comparison of different methods for dynamic scene reconstruction on two datasets: N3DV and Meet Room. The metrics compared include PSNR (peak signal-to-noise ratio, a measure of image quality), storage size (in MB), training time (in seconds), and rendering speed (in frames per second). The storage metric is broken down into the size without the initial frame and the size with the initial frame, providing a more nuanced view of storage requirements. One method was reproduced by the authors of the paper for comparison.

This table presents the mean and standard deviation of PSNR values across three runs of the HiCoM and 3DGStream methods on the N3DV dataset, using the same random seed (0). It demonstrates the consistency and stability of the proposed HiCoM method compared to 3DGStream across different scenes.

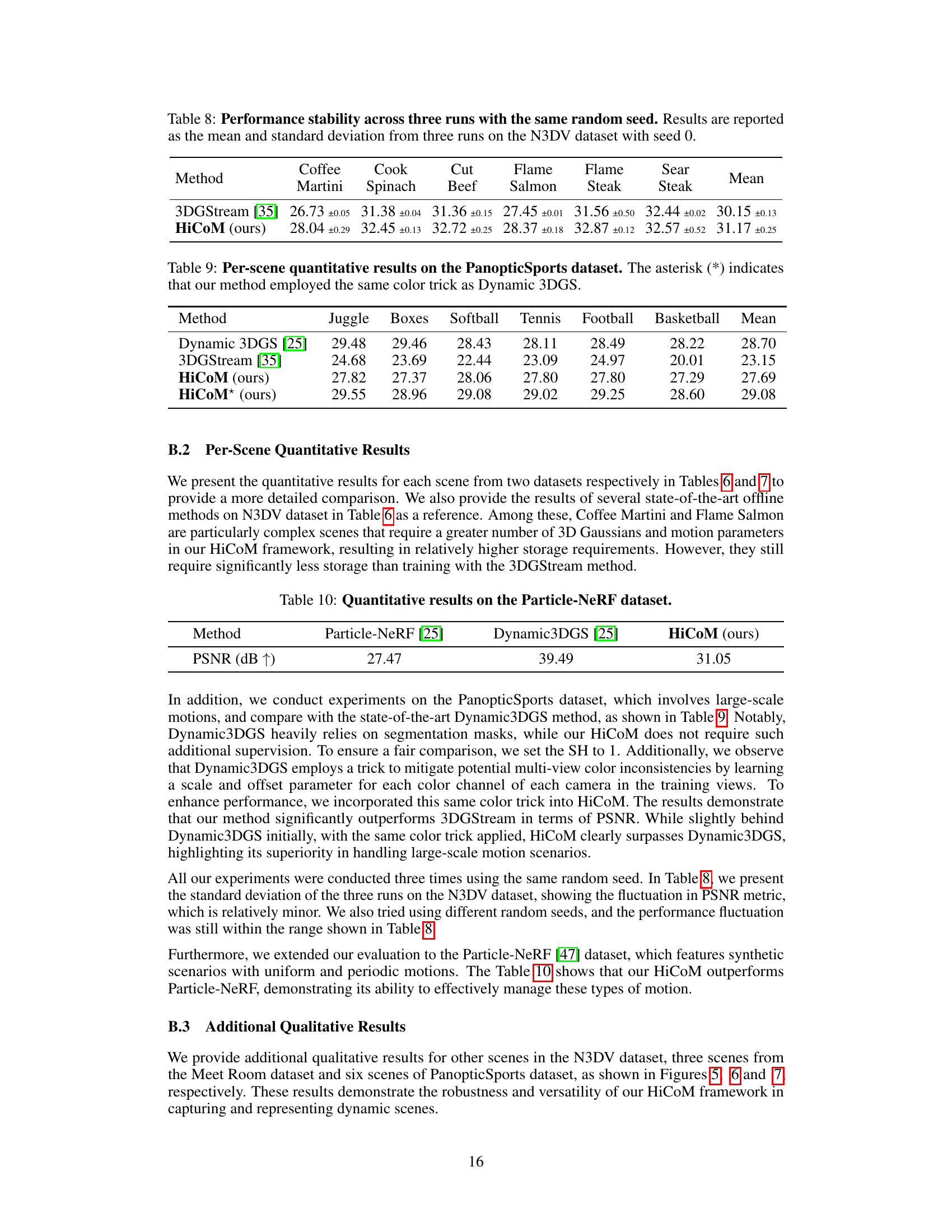
This table presents a per-scene quantitative comparison of different methods on the PanopticSports dataset. It shows the PSNR (Peak Signal-to-Noise Ratio) scores achieved by Dynamic 3DGS [25], 3DGStream [35], the proposed HiCoM method, and a variation of HiCoM(*) that uses the same color correction technique as Dynamic 3DGS. The results are broken down by scene (Juggle, Boxes, Softball, Tennis, Football, Basketball) and averaged to provide an overall mean PSNR.

This table presents a quantitative comparison of different methods for dynamic scene reconstruction on two datasets: N3DV and Meet Room. The metrics compared include PSNR (peak signal-to-noise ratio, a measure of image quality), storage (memory usage), training time, and rendering speed (frames per second). Storage is broken down into the size without and with the initial frame. One method was reproduced by the authors for comparison.
Full paper#