↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Most existing video understanding benchmarks are human-centric, neglecting the crucial role of animal-centric understanding in conservation and welfare. This limits the applicability of advanced multimodal video models to real-world ecological challenges. This lack of animal-focused benchmarks hinders the progress of AI in wildlife management and conservation efforts.
To address this gap, the researchers introduce Animal-Bench, a novel benchmark specifically designed for evaluating multimodal video models in animal-centric contexts. It contains 13 tasks, 7 major animal categories, and 819 species, using realistic scenarios and automated data processing. Their evaluation of 8 state-of-the-art models shows significant room for improvement, suggesting promising new avenues for future research and development.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the scarcity of animal-centric benchmarks in multimodal video understanding. This limitation hinders the development and application of models for vital conservation and animal welfare research. The benchmark’s novel approach will accelerate progress in animal-centric AI, driving innovation in wildlife monitoring and related fields.
Visual Insights#

This figure compares previous human-centric video understanding benchmarks with the proposed Animal-Bench. Previous benchmarks are shown to have limited animal representation and often employ simplified or unrealistic scenarios. In contrast, Animal-Bench is designed to be animal-centric, featuring diverse animal species in various realistic scenarios, encompassing 13 diverse tasks, including both common and special animal-specific tasks.
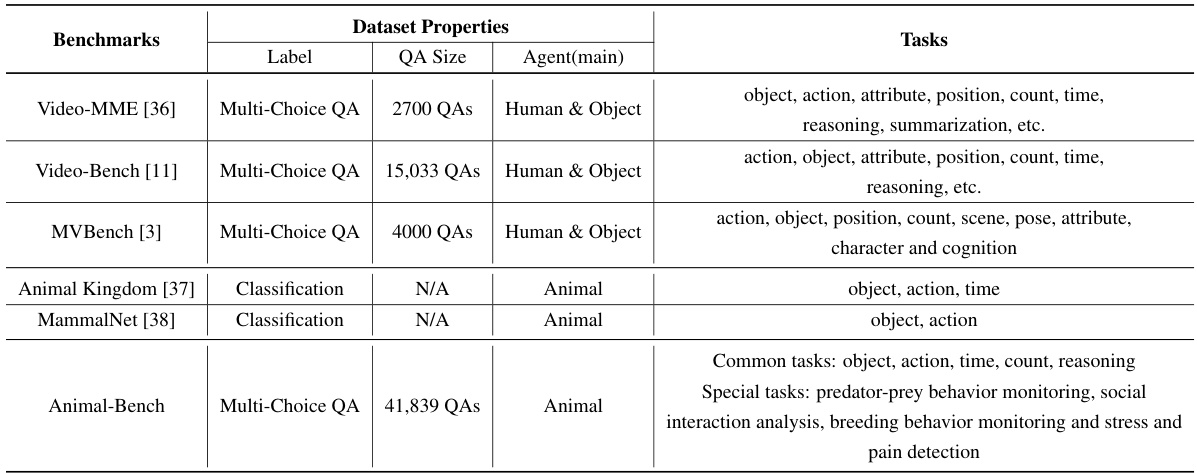
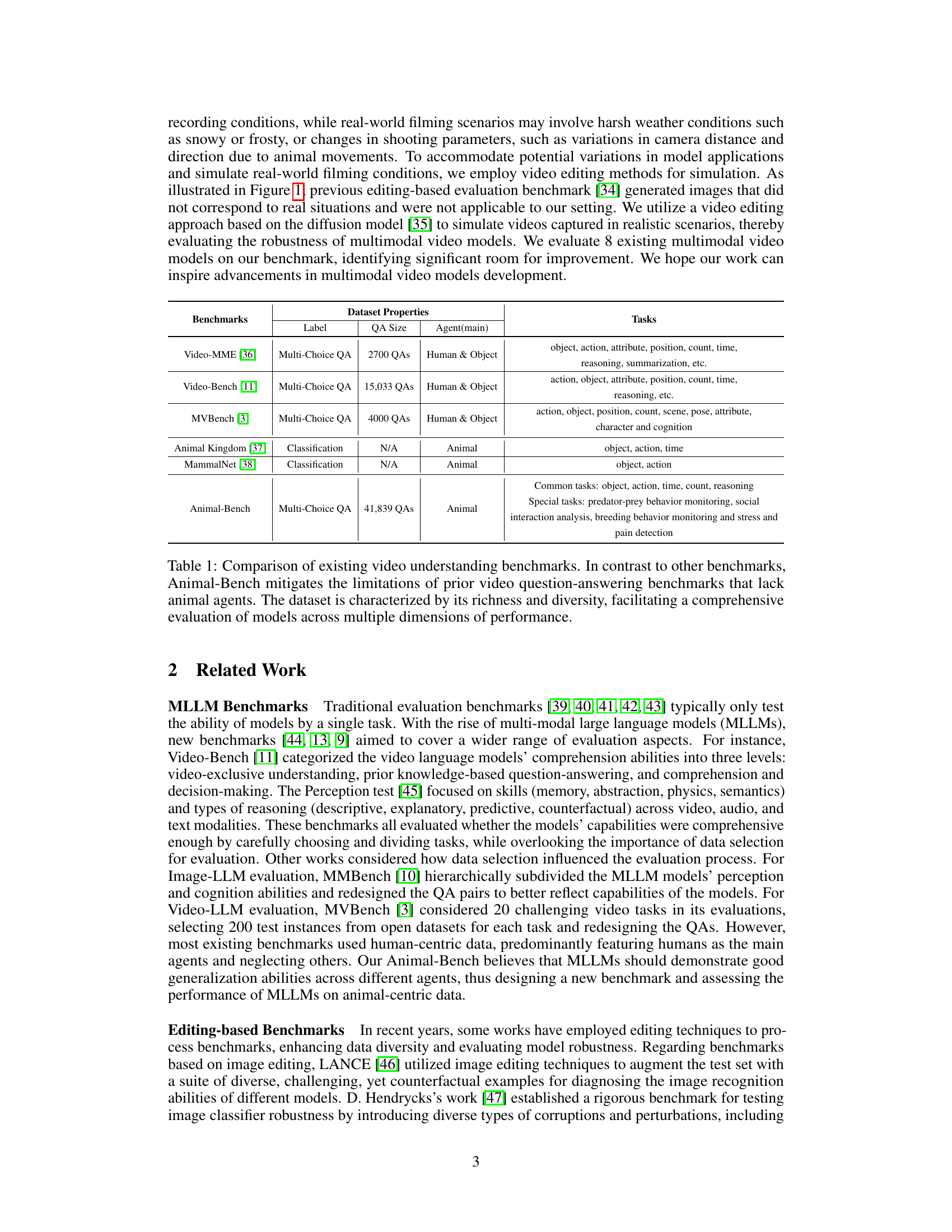
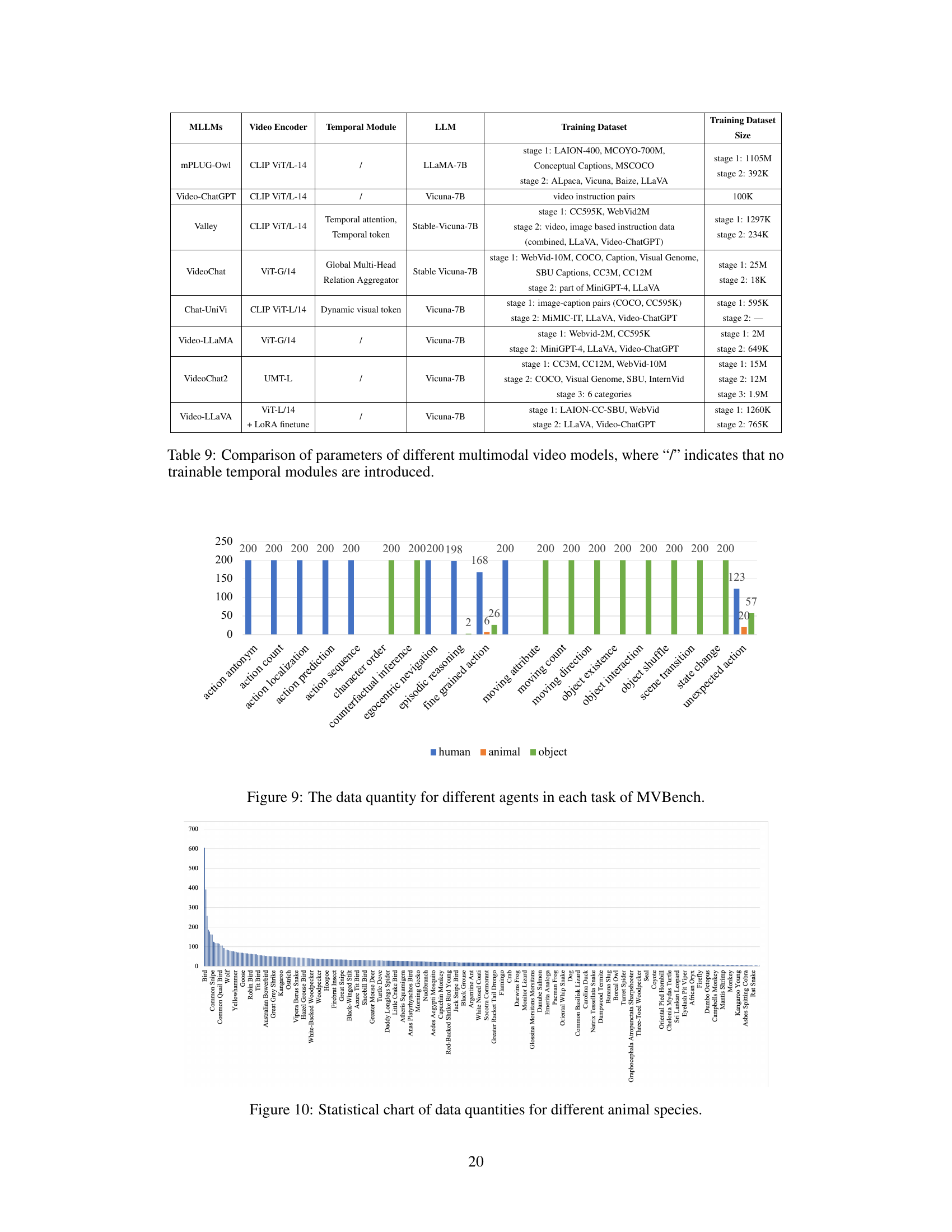
This table compares Animal-Bench with other existing video understanding benchmarks, highlighting the differences in their properties such as the main agent, task types, and dataset size. It emphasizes Animal-Bench’s focus on animals, richer diversity, and more comprehensive task evaluation.
In-depth insights#
Animal-centric Vision#
Animal-centric vision, a novel perspective in computer vision, shifts the focus from human-centered tasks to understanding and interpreting the visual world from the animals’ perspective. This approach involves developing algorithms and models that can analyze animal behavior, recognize animal species, and understand the context in which animals interact within their environments. Unlike traditional computer vision systems, animal-centric vision must tackle unique challenges: high variability in animal appearances, diverse behaviors, complex natural environments, and a lack of large-scale annotated datasets. To overcome these challenges, researchers are exploring innovative techniques like transfer learning, domain adaptation, and advanced deep learning architectures, potentially combined with sensor fusion to gather richer data from multiple sources. The potential benefits of animal-centric vision are substantial, ranging from improving conservation efforts through automated monitoring of wildlife populations and understanding their behavior, to enhancing animal welfare by detecting signs of stress or disease. It is important to note that this nascent field requires a strong ethical framework to ensure that the technological advancements are used responsibly and do not inadvertently harm the animals being studied.
Benchmarking Multimodal Models#
Benchmarking multimodal models presents unique challenges due to the inherent complexity of integrating different modalities (text, image, audio, video). Effective benchmarks must consider task diversity, encompassing a range of challenges that reflect real-world applications. Evaluation metrics need to go beyond simple accuracy, incorporating aspects like robustness to noise, generalization across datasets, and efficiency. Furthermore, dataset bias needs careful consideration, as skewed data can lead to misleading results. Addressing these challenges requires a multifaceted approach, including the development of standardized evaluation protocols, the creation of diverse and representative datasets, and the adoption of sophisticated evaluation metrics that capture the nuances of multimodal understanding. Transparency and reproducibility are also crucial to ensure the credibility and reliability of benchmark results.
Robustness Evaluation#
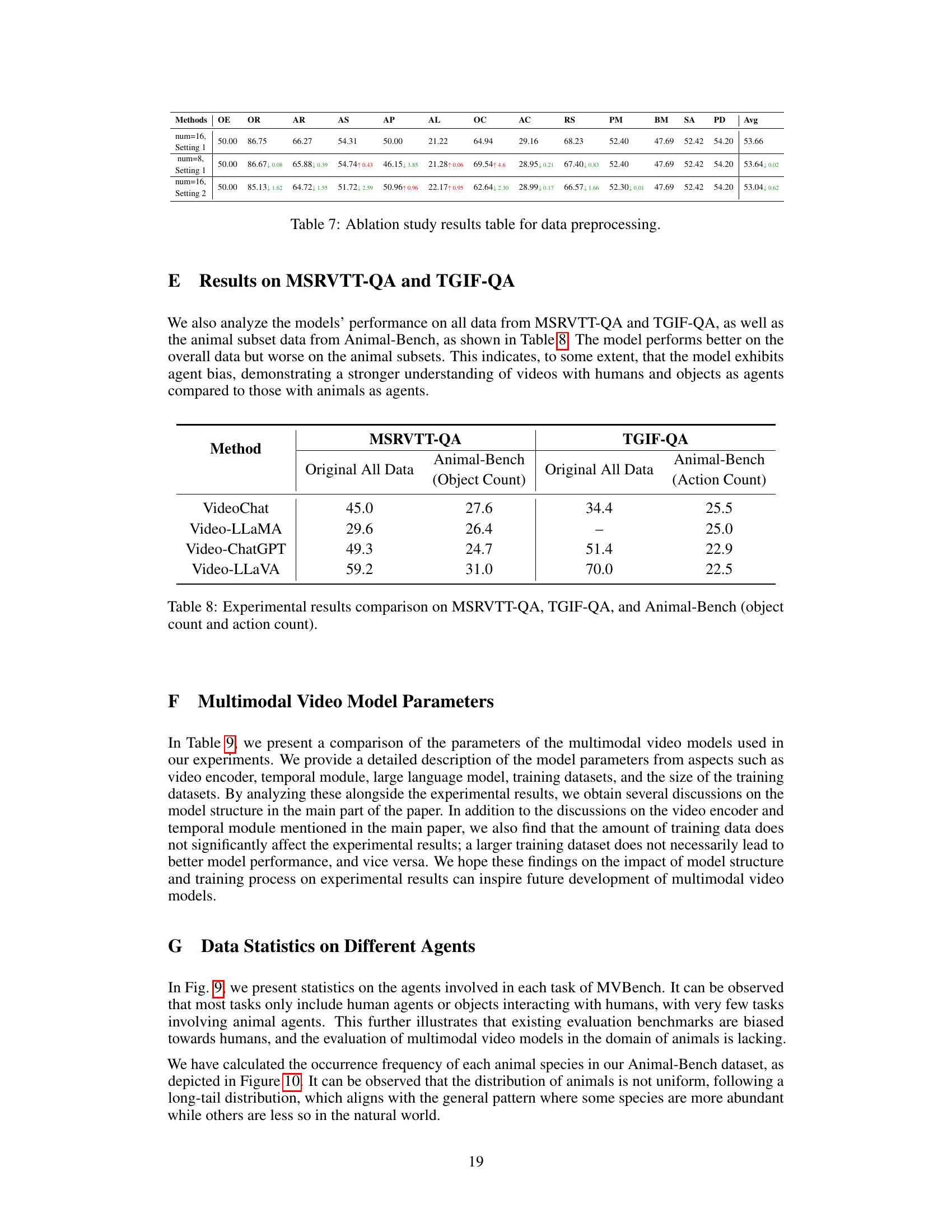
The robustness evaluation section of this research paper is crucial for assessing the reliability and real-world applicability of the proposed Animal-Bench benchmark. It investigates how well the evaluated models perform under various challenging conditions, simulating real-world scenarios like weather changes and variations in shooting parameters. This rigorous testing is essential because models trained on ideal datasets often fail to generalize to the messy complexities of real-world data. The use of video editing techniques to simulate these scenarios is a particularly strong methodological choice, providing more realistic and impactful results than simpler image-based approaches. The results reveal varying degrees of robustness across different models, highlighting areas where models struggle and suggesting avenues for future model improvement. This robustness testing is key to ensuring that Animal-Bench is a truly useful tool for driving progress in animal-centric video understanding.
Data Processing Pipeline#
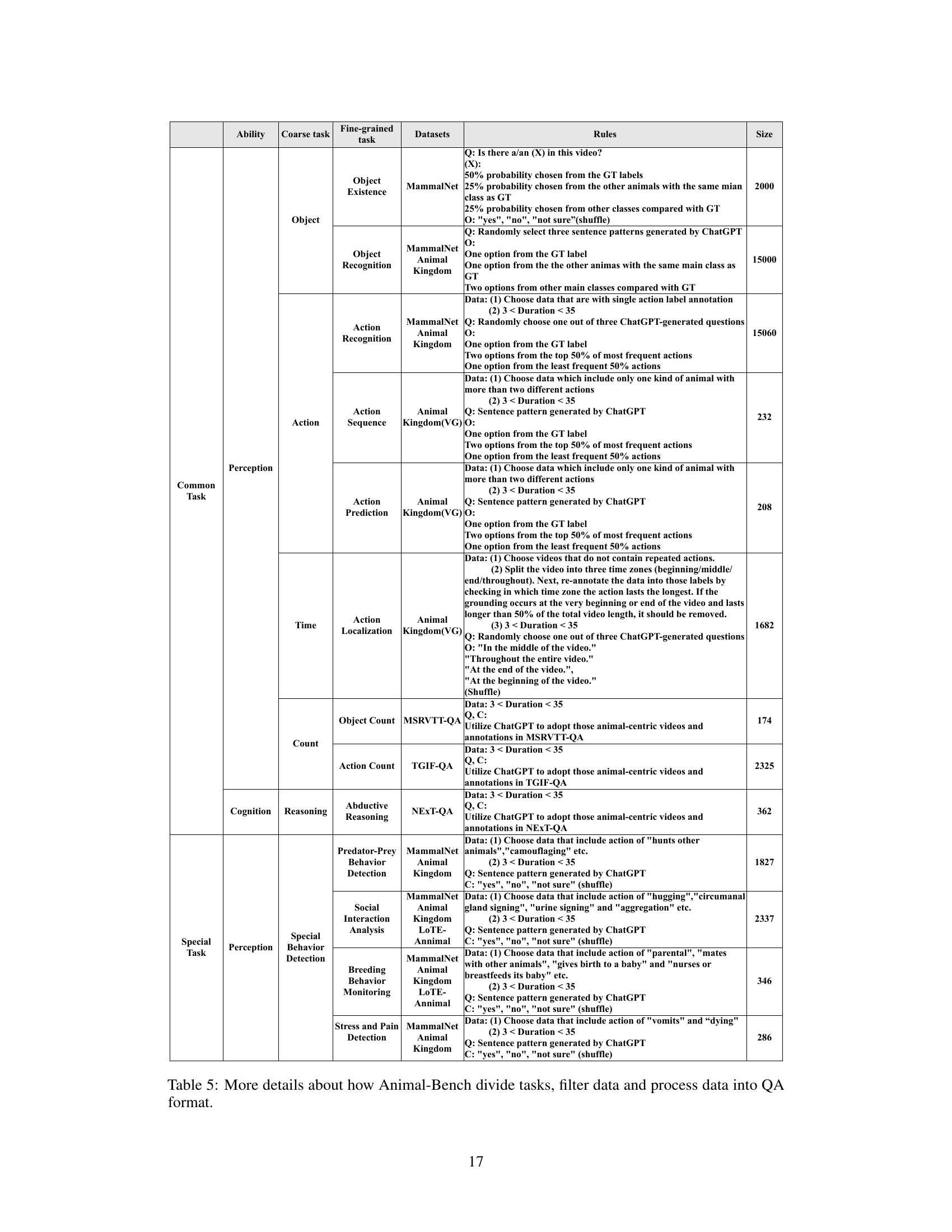
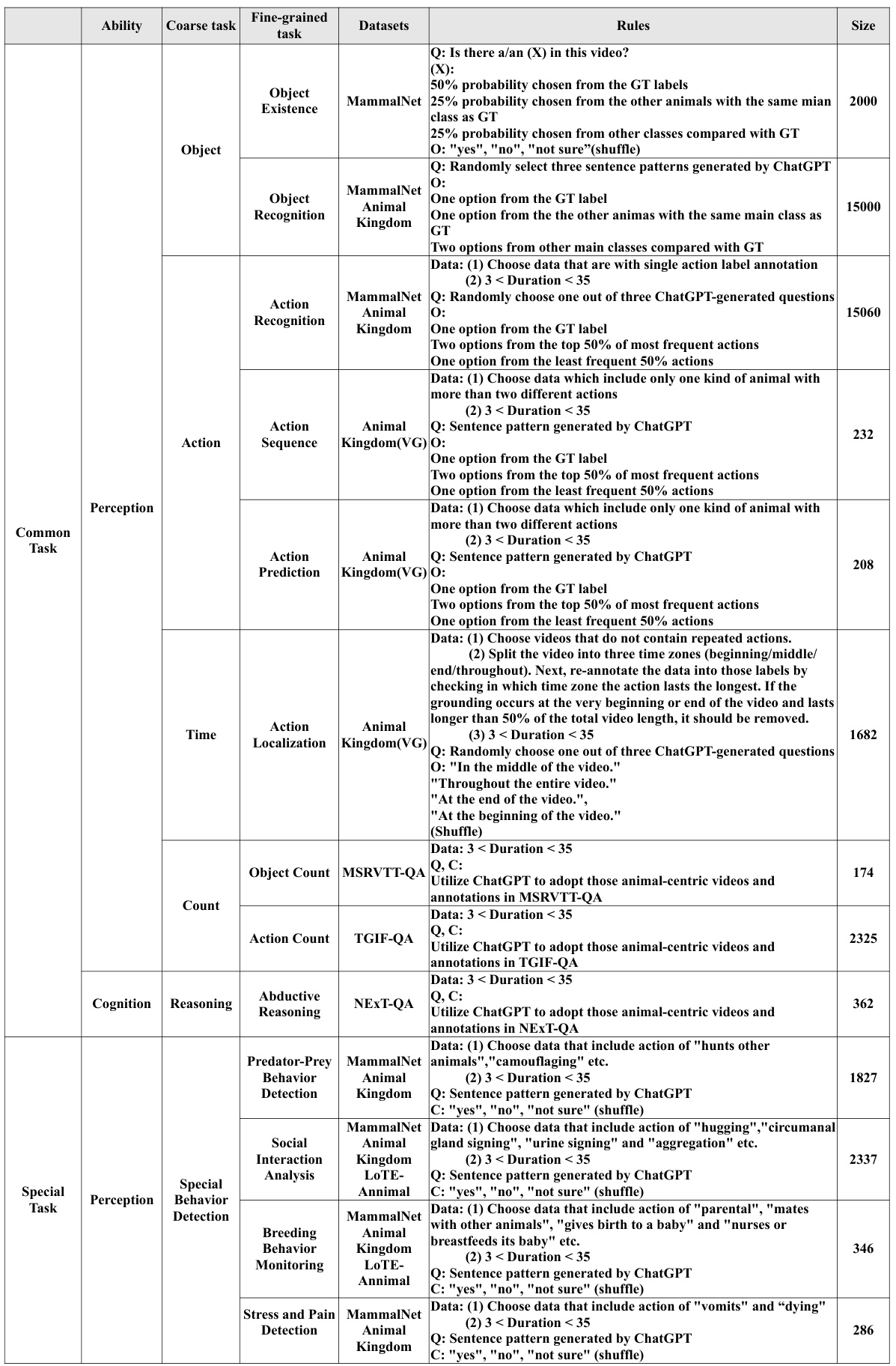
A robust data processing pipeline is crucial for any machine learning project, especially one involving complex data like video. The Animal-Bench pipeline, as described, appears well-structured, prioritizing automation to reduce human bias and improve efficiency. The pipeline’s stages, from initial data filtering based on task-specific criteria and diverse animal categories to automated question-answer pair generation, demonstrate a focus on scalability and reproducibility. Filtering rules are key here, ensuring data consistency and relevance across various tasks. The use of ChatGPT for QA pair generation is a clever approach, leveraging large language models’ capabilities, although potential biases inherent in such models should be acknowledged and mitigated. The pipeline’s success hinges on its capacity to generate high-quality, task-relevant question-answer pairs at scale, making it suitable for benchmarking multiple models effectively. Future improvements might focus on incorporating more sophisticated methods for bias detection and mitigation within the automated QA generation process.
Future Research#
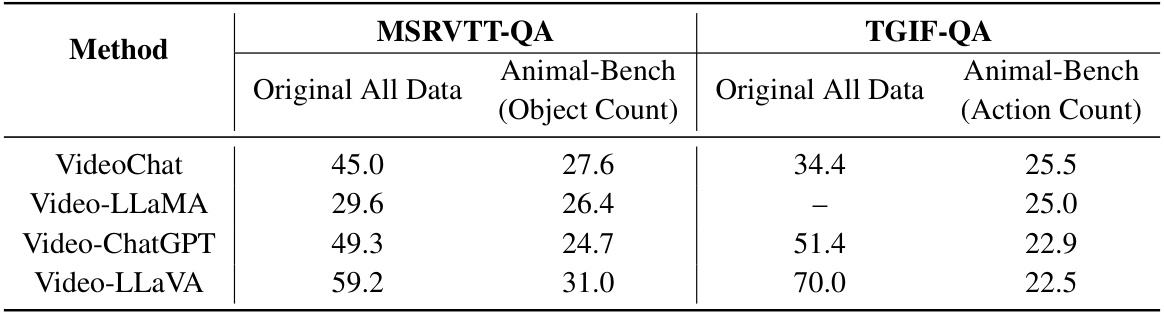
Future research directions stemming from the Animal-Bench benchmark could involve developing more robust models less susceptible to variations in weather, shooting parameters, and animal movements. This might entail exploring advanced video processing techniques or incorporating data augmentation strategies to better simulate real-world conditions. Another important area is improving temporal understanding. Current models struggle with tasks requiring strong temporal reasoning; thus, research on better temporal modeling architectures, or training methods to enhance temporal awareness, is warranted. Furthermore, there is a need for reducing agent bias: future benchmarks should strive for more balanced representation of animal species, moving away from a predominantly human-centric focus. Finally, research could explore ways to leverage Animal-Bench to address specific conservation challenges. Developing models capable of automatically identifying stressed or diseased animals, or predicting predator-prey interactions, would make a significant contribution to conservation efforts.
More visual insights#
More on figures

This figure compares previous video understanding benchmarks with the newly proposed Animal-Bench. The left side shows that previous benchmarks largely focused on humans and objects, with limited representation of animals and often using simplified, unrealistic scenarios. The right side illustrates Animal-Bench, highlighting its strengths: a diverse range of animal agents, inclusion of various realistic scenarios, and a comprehensive set of 13 tasks encompassing common tasks shared with human-centric benchmarks and additional tasks specifically relevant to animal conservation.

This figure illustrates the Animal-centric Data Processing Pipeline. It begins with selecting various datasets and identifying the relevant tasks (common and special). Then, data filtering is applied based on data diversity and temporal sensitivity, ensuring animal-centric data and appropriate video lengths for time-related tasks. Finally, a question-answer pair generation process is undertaken, utilizing automated question generation and task-based option design to ensure effective evaluation.

This figure illustrates the process of simulating variations in shooting parameters using a diffusion model. The process begins with encoding transformed images and their masks using a Variational Autoencoder (VAE). These encodings are then passed through a diffusion model for denoising, resulting in a refined representation. Finally, a guided frame selection module and frame blending module are used to generate the final simulated video, which incorporates realistic variations in shooting parameters like camera distance and angle.

This figure shows the average decrease in model accuracy across four types of variations (snow, frost, direction, and distance) for four different multimodal video models. The models are tested on simulated real-world scenarios to evaluate their robustness. The chart displays the relative accuracy drop for each variation. It helps illustrate the models’ sensitivity to different kinds of changes in the video data.

This figure visualizes the results of simulating changes in shooting parameters using video editing techniques. It shows the original frames, the frames selected as guides, and the final edited frames, highlighting the effects of simulated distance and direction variations on the video’s appearance. The red boxes in the guided and final frames help focus on the key areas where changes were applied. The overall effect is to simulate more realistic, less controlled video-recording conditions.
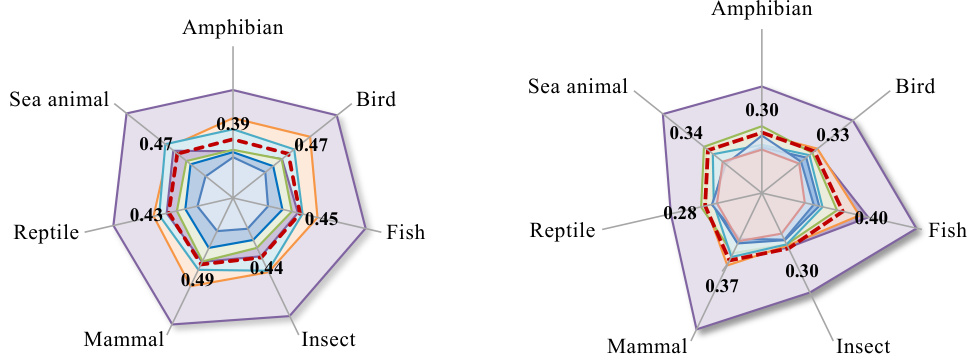
This radar chart visualizes the performance of different multimodal video models on object and action recognition tasks, categorized across seven major animal categories (mammal, bird, reptile, amphibian, fish, insect, and sea animal). Each axis represents a category, and the radial distance from the center indicates the accuracy achieved by a specific model for that category. The chart facilitates a comparison of model performance across diverse animal types, highlighting strengths and weaknesses in recognizing particular animal categories.

This figure compares previous benchmarks with the Animal-Bench proposed in the paper. The left side shows that existing benchmarks have limitations, focusing primarily on humans and objects with simplified, unrealistic scenarios. Animal-Bench, on the other hand (right side), is designed to evaluate multimodal video models in real-world contexts using diverse animal agents and realistic scenarios, including 13 distinct tasks.
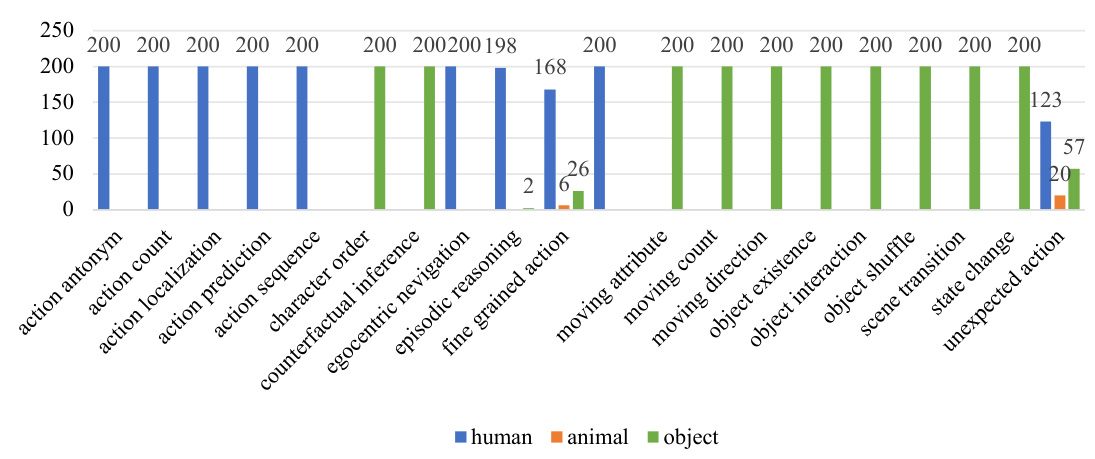
This figure compares previous human-centric video understanding benchmarks with the newly proposed Animal-Bench. It highlights the limitations of existing benchmarks, such as limited animal representation and unrealistic scenarios. In contrast, Animal-Bench offers a more comprehensive and realistic evaluation, encompassing diverse animal agents, various realistic scenarios, and 13 diverse tasks.

This figure compares previous benchmarks with the proposed Animal-Bench. Previous benchmarks are criticized for their limited representation of animal agents (only 1% animal data in MVBench example) and use of unrealistic, simplified scenarios (often created through artificial image editing). In contrast, Animal-Bench features diverse animal agents across various realistic scenarios and 13 diverse tasks designed to comprehensively evaluate multimodal video models in animal-centric video understanding.

This figure shows example frames from videos used in the Animal-Bench benchmark. It demonstrates how the researchers simulated real-world filming conditions by applying video editing techniques to add simulated snow, frost, variations in camera distance and direction. The original frames are shown alongside the edited versions to illustrate the changes.

This figure shows examples of simulated video frames to demonstrate the effects of varying weather conditions (snow and frost) and shooting parameters (distance and direction) on video quality. The goal was to enhance the realism of the Animal-Bench benchmark by simulating the variability encountered in real-world animal video recordings.

This figure shows the results of simulating changes in shooting parameters (distance and direction) using video editing techniques. It demonstrates how these changes affect the appearance of the video frames, showing the original frames, the frames after applying the guided frame selection and the final frames. The images showcase the process of simulating realistic scenarios like changes in shooting distance, potentially due to animal movements.

This figure shows the effects of simulating changes in shooting parameters (distance and direction) using video editing techniques. The left side shows the original video frames, while the right illustrates the modified frames after applying the editing process to simulate changes in proximity to the camera and the direction of shooting. These changes are designed to make the video evaluation more realistic and robust, reflecting conditions found in real-world animal video recordings.

This figure shows the results of simulating changes in shooting parameters using video editing techniques. It visually demonstrates the effects of varying shooting distance and direction on the resulting videos. The ‘Original’ column shows the original frames. The ‘Distance variation’ column demonstrates the effect of simulated changes in camera distance to the subject (closer or farther). The ‘Direction variation’ column illustrates how changes in camera angle alter the captured video. The image demonstrates the use of a diffusion model to simulate realistic scenarios, such as weather conditions and shooting parameters, for evaluating the robustness of multimodal video models.

This figure shows the results of simulating changes in shooting parameters (distance and direction) using video editing techniques. The original frames are shown alongside frames with simulated changes, demonstrating the effects of varying camera proximity and angle on the captured video. Each row represents a different animal, showing how the simulation alters the appearance of the video.

This figure shows examples of simulated video frames to illustrate the effects of various video editing techniques. Specifically, it displays how the simulated changes in weather (snow and frost) and shooting parameters (distance and direction) alter the appearance of the original video frames. The goal is to create more realistic and challenging video data for evaluating the robustness of multimodal video models.

This figure shows the effects of simulating changes in shooting parameters (distance and direction) using video editing techniques. The left side displays the original video frames, and the right side shows the frames after applying the simulation. The results illustrate how the simulated changes affect the appearance of the animal in the video, which can impact the model’s ability to accurately recognize and classify the animal.

This figure shows the results of simulating changes in shooting parameters using video editing techniques. The left side shows the original video frames, followed by examples of the ‘distance variation’ and ‘direction variation.’ These variations simulate realistic scenarios where the camera distance and angle change due to animal movement or other real-world conditions. The right side shows simulated snowy and frosty weather conditions, demonstrating how the model’s performance is affected by varied shooting parameters and environmental factors. By examining these variations, researchers aim to better understand the model’s robustness in real-world situations.
More on tables
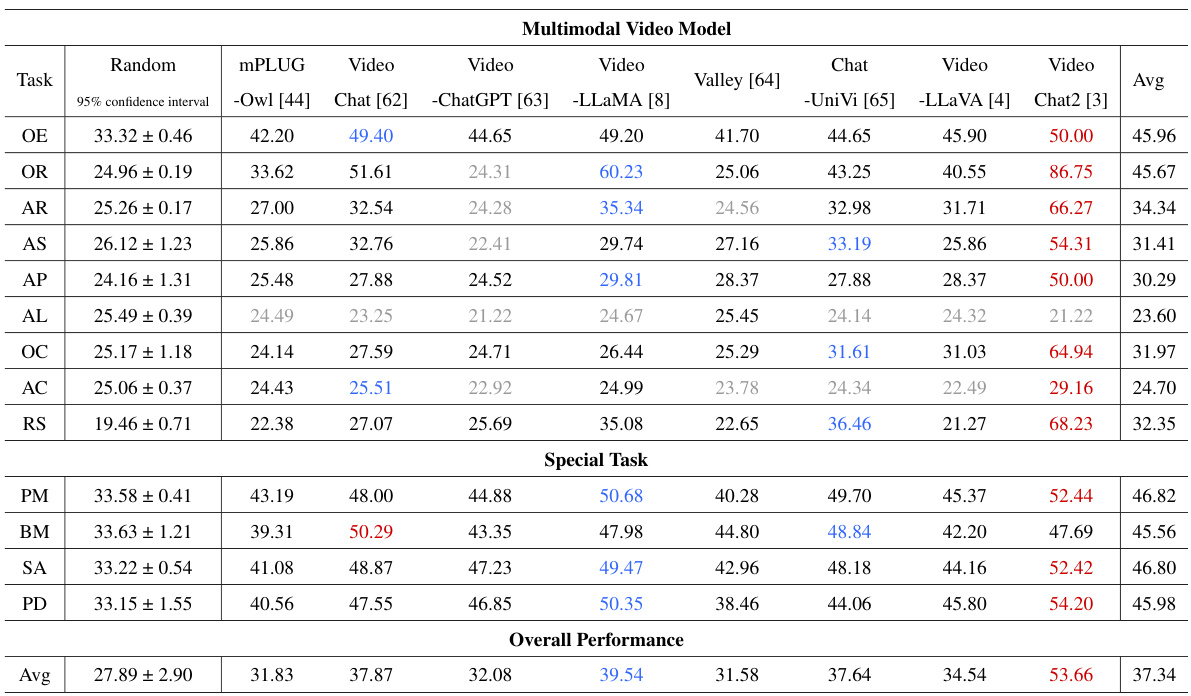
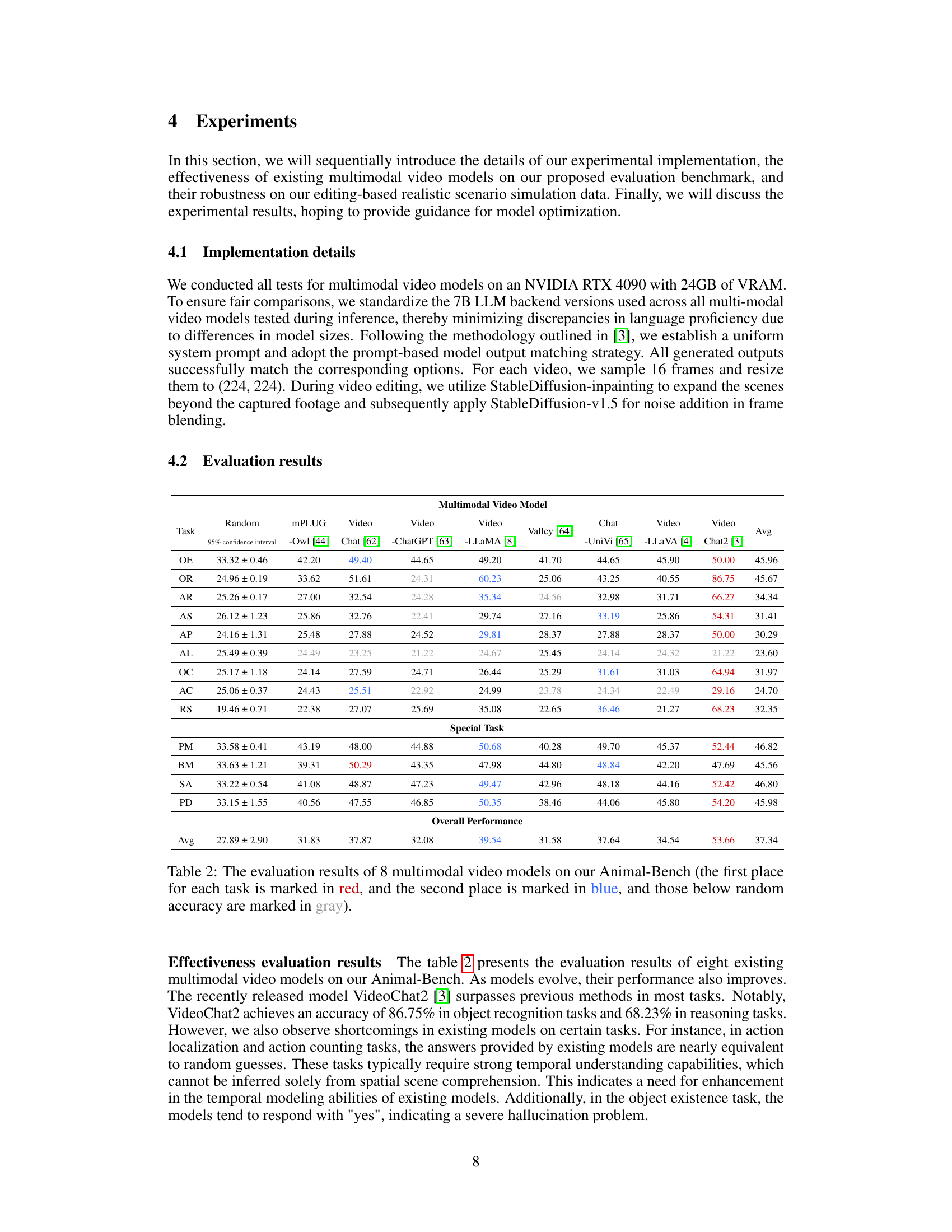
This table presents the performance of eight existing multimodal video models on the Animal-Bench benchmark. The benchmark consists of 13 tasks designed to evaluate different aspects of animal-centric video understanding. The table shows the accuracy of each model for each task, highlighting the top two performing models for each task. Models significantly underperforming random accuracy are indicated in gray.
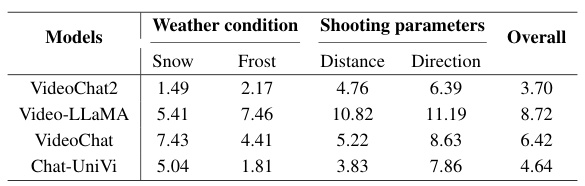
This table presents the sensitivity analysis results of four top-performing multimodal video models to four different types of simulated real-world data variations: snowy weather, frosty weather, shooting distance variation, and shooting direction variation. The results are expressed as the relative decrease in accuracy (%) for each model and each variation type. It provides insight into the robustness of these models against real-world challenges.

This table compares Animal-Bench with other existing video understanding benchmarks, highlighting Animal-Bench’s unique focus on animal agents and its rich, diverse dataset. It emphasizes Animal-Bench’s more comprehensive evaluation across multiple performance dimensions compared to human-centric benchmarks which lack animal data and focus primarily on humans and objects.
This table compares Animal-Bench with other existing video understanding benchmarks, highlighting the unique characteristics of Animal-Bench. It shows that unlike other benchmarks which primarily focus on human or object agents, Animal-Bench centers on animal agents, offering a richer and more diverse dataset for evaluating models’ performance across various dimensions.

This table compares Animal-Bench with other existing video understanding benchmarks, highlighting Animal-Bench’s unique focus on animal agents and its richer, more diverse dataset. It provides a quantitative comparison of the number of question-answer pairs and the types of agents primarily featured (human, animal, object) in each benchmark, showcasing Animal-Bench’s comprehensive evaluation across various performance dimensions.

This table presents the performance of eight existing multimodal video models on the Animal-Bench benchmark across thirteen tasks. The tasks are categorized into common tasks (shared with human-centric benchmarks) and special tasks (related to animal conservation). The table shows the accuracy of each model for each task. Models with higher accuracy are shown in red and blue to highlight top performers. Gray indicates performance worse than random chance.
This table compares Animal-Bench with other existing video understanding benchmarks. It highlights that Animal-Bench addresses limitations of previous benchmarks by focusing on animal agents instead of primarily humans and objects, improving the diversity and richness of the data to comprehensively evaluate model performance.
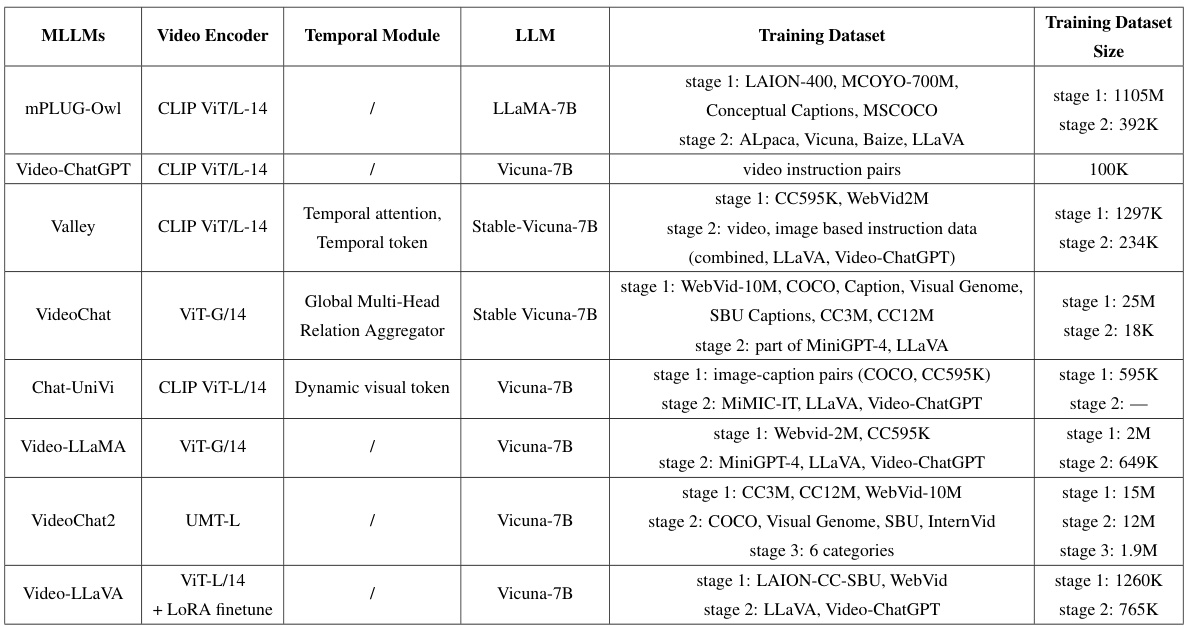
This table compares Animal-Bench with other existing video understanding benchmarks, highlighting the key differences and advantages of Animal-Bench. Animal-Bench focuses on animal agents, unlike others that predominantly feature humans or objects, offering a more comprehensive evaluation across various tasks and model capabilities. The table showcases differences in the main agents included in the data, the number of questions and answers used for evaluation and highlights the inclusion of ‘common’ and ‘special’ tasks.
Full paper#