TL;DR#
Large-vocabulary object detectors (LVDs) struggle with recognizing objects across different domains due to variations in data distribution and vocabulary. Current domain adaptation methods often fall short in effectively addressing this challenge. This limitation necessitates the development of more advanced techniques to improve LVDs’ cross-domain performance.
The paper introduces Knowledge Graph Distillation (KGD), a novel method that extracts and transfers the knowledge graph from CLIP (a vision-language model) to LVDs. KGD consists of two stages: KG extraction using CLIP to encode data and their relations, and KG encapsulation that integrates this knowledge into LVDs. Experiments demonstrate KGD’s consistent superior performance across various benchmarks compared to state-of-the-art methods, highlighting its potential for applications needing robust object detection in varied conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in object detection and domain adaptation. It presents KGD, a novel technique that significantly improves the performance of large-vocabulary object detectors across various domains by leveraging the implicit knowledge graph within CLIP. This work opens new avenues for unsupervised domain adaptation, potentially impacting numerous applications relying on robust object recognition.
Visual Insights#
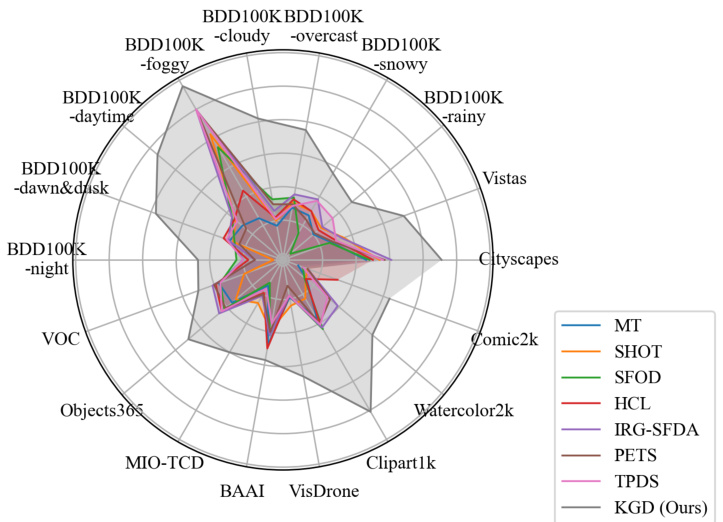
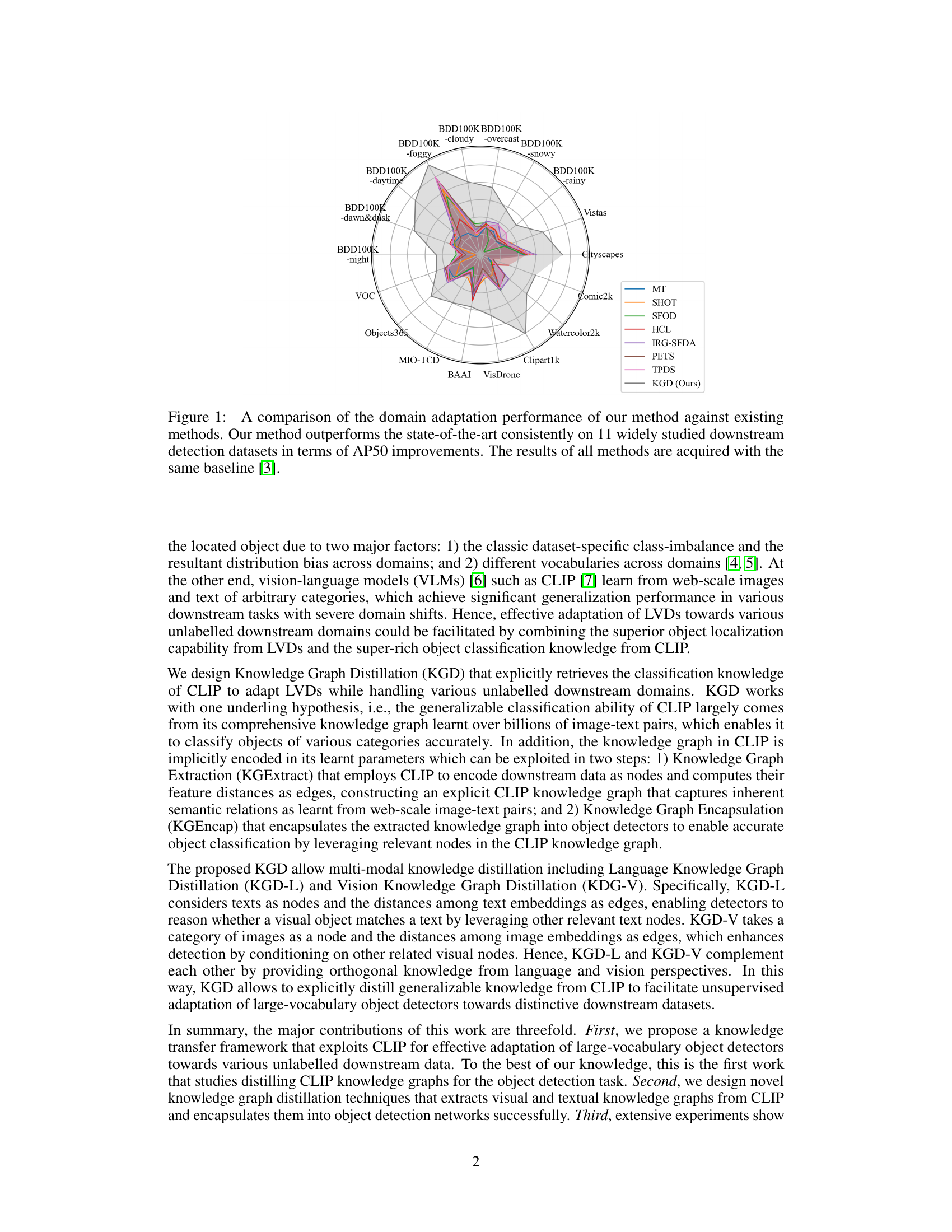
🔼 This radar chart compares the performance of the proposed Knowledge Graph Distillation (KGD) method with several existing domain adaptation methods across 11 different downstream datasets. The datasets represent various domains and conditions including autonomous driving under different weather and lighting, common objects, intelligent surveillance, and artistic illustrations. The chart shows that KGD consistently outperforms state-of-the-art methods, achieving significant improvements in average precision (AP50).
read the caption
Figure 1: A comparison of the domain adaptation performance of our method against existing methods. Our method outperforms the state-of-the-art consistently on 11 widely studied downstream detection datasets in terms of AP50 improvements. The results of all methods are acquired with the same baseline [3].
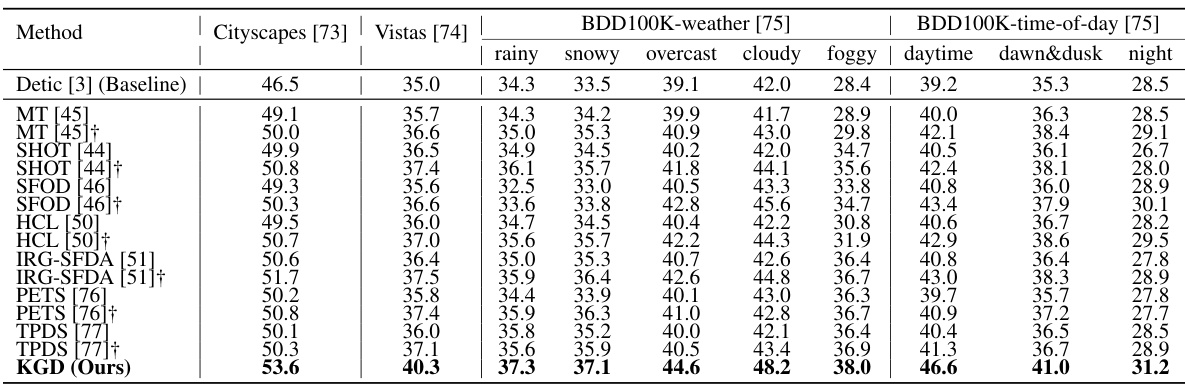
🔼 This table presents a comparison of the domain adaptation performance of the proposed method (KGD) against existing methods on 11 autonomous driving datasets under various weather and time conditions. The AP50 (Average Precision at 50% Intersection over Union) metric is used to evaluate the performance, and the results are compared with a common baseline. The ‘†’ symbol indicates that certain methods used WordNet and CLIP for enhanced performance.
read the caption
Table 1: Benchmarking over autonomous driving datasets under various weather and time conditions. † signifies that the methods employ WordNet to retrieve category definitions given category names, and CLIP to predict classification pseudo labels for objects. We adopt AP50 in evaluations. The results of all methods are acquired with the same baseline [3] as shown in the first row.
In-depth insights#
Cross-Domain LVDs#
Cross-domain Large Vocabulary Object Detectors (LVDs) represent a significant challenge in computer vision. Standard LVDs, trained on large, general datasets, often struggle to generalize well to new, unseen domains due to domain shift—variations in data distribution, object appearance, and background context. This necessitates the development of robust adaptation techniques. A key area of focus is unsupervised domain adaptation, where labeled data is scarce in the target domain, requiring methods to leverage unlabeled target data for model improvement. Effective cross-domain LVDs would need to address both object localization (finding objects accurately, often robust to variations in appearance across domains) and object classification (correctly identifying the objects, requiring effective handling of domain-specific vocabularies and class imbalances). Promising approaches might include techniques like knowledge distillation from vision-language models, adversarial training, or self-training methods, all aiming to bridge the gap between source and target domains and achieve higher accuracy in diverse, real-world scenarios.
Knowledge Graph Distillation#
Knowledge Graph Distillation (KGD) is a novel technique for adapting large-vocabulary object detectors (LVDs) to diverse downstream domains. KGD leverages the implicit knowledge graph (KG) within a vision-language model like CLIP, explicitly extracting this knowledge and transferring it to the LVD. This addresses the challenge of LVDs struggling with cross-domain object recognition due to variations in data distribution and vocabulary. The process involves two stages: KG extraction, using CLIP to encode data as nodes and feature distances as edges; and KG encapsulation, integrating the extracted KG into the LVD for improved cross-domain classification. KGD’s strength lies in its ability to utilize both visual and textual KGs independently, providing complementary information for accurate object localization and classification. The effectiveness of KGD is demonstrated through experiments showing consistent outperformance of state-of-the-art methods across various benchmarks.
CLIP Knowledge Transfer#
The concept of “CLIP Knowledge Transfer” in a research paper would likely explore how the knowledge encoded within the CLIP (Contrastive Language–Image Pre-training) model can be effectively leveraged to enhance other vision tasks, such as object detection. A key aspect would be identifying the nature of the knowledge transfer. Is it the transfer of visual features, semantic understanding, or a combination of both? The methods employed could range from distillation techniques (transferring CLIP’s knowledge to a student network) to knowledge graph construction (representing CLIP’s knowledge structure explicitly and transferring relevant portions). Another important area would be evaluating the effectiveness of the transfer. Benchmarking against state-of-the-art methods on standard datasets and analyzing the impact on specific metrics (like precision, recall, and mAP) would be crucial for demonstrating success. Finally, a thoughtful discussion of the limitations of this approach and potential future research directions would enhance the paper’s contribution.
Multi-Modal KG#
A multi-modal knowledge graph (KG) in the context of a research paper likely integrates information from diverse data modalities, such as text, images, and potentially others like audio or sensor data. The core strength lies in its ability to represent complex relationships between entities from these different sources, going beyond simple pairwise links. This richer representation can unlock new capabilities in various applications. For example, in the context of a large vocabulary object detector, a multi-modal KG could connect visual features of objects (from images) with textual descriptions (from a knowledge base or captions). This fusion of information enables more robust and accurate object classification, particularly when dealing with novel or unseen objects. Furthermore, a well-designed multi-modal KG can explicitly model semantic relationships, enabling more sophisticated reasoning and knowledge transfer. Challenges likely include effective integration of heterogeneous data sources, scalable KG construction techniques, and development of efficient algorithms for querying and reasoning within the complex graph structure.
Future of KGD#
The future of Knowledge Graph Distillation (KGD) appears bright, given its strong performance in adapting large-vocabulary object detectors (LVDs). Future research could explore more sophisticated graph structures, moving beyond simple pairwise relationships to capture richer semantic information. Integrating diverse knowledge sources beyond CLIP, such as other vision-language models or structured knowledge bases, would enhance KGD’s adaptability and robustness. Improving KG extraction efficiency is crucial for scaling KGD to even larger datasets and more complex domains. Research into different graph neural network architectures could unlock further performance gains, while exploring ways to handle uncertainty and noise in the knowledge graphs is vital for improving reliability. Finally, developing KGD for tasks beyond object detection, such as semantic segmentation or video understanding, would broaden its impact and demonstrate its versatility as a general-purpose domain adaptation technique.
More visual insights#
More on figures

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) framework. KGD is a two-stage process: First, it extracts knowledge graphs (KGs) from CLIP, a vision-language model. These KGs include a language KG (LKG) based on text and a vision KG (VKG) based on image features. Second, KGD encapsulates the extracted KGs into a large-vocabulary object detector to improve object classification. The figure shows the data flow, highlighting the use of WordNet to enrich the LKG, CLIP for encoding data and computing feature distances, and GCN for incorporating knowledge graph information into object detection.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) method. KGD consists of two stages: Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract uses CLIP to create knowledge graphs (KGs) from downstream data, including a Language KG (LKG) and a Vision KG (VKG). These KGs capture semantic relationships from CLIP. KGEncap then integrates these KGs into a large-vocabulary object detector to improve object classification across domains. The figure highlights the flow of information, showing how image and text data are processed by CLIP to generate the KGs, which are then used to enhance the object detector’s performance.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) framework. KGD consists of two main stages: Knowledge Graph Extraction (using CLIP to create language and vision knowledge graphs) and Knowledge Graph Encapsulation (transferring the knowledge graphs into a large-vocabulary object detector for improved classification). The figure shows how CLIP encodes downstream data, building both language and vision knowledge graphs, and how these graphs are integrated and used for improved object detection accuracy.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) framework. KGD consists of two main stages: Knowledge Graph Extraction and Knowledge Graph Encapsulation. In the extraction stage, CLIP is used to encode downstream data into nodes and compute feature distances as edges to create both language (LKG) and vision (VKG) knowledge graphs. These graphs capture semantic relationships present in CLIP. The encapsulation stage then transfers these KGs into the LVD for improved cross-domain object classification. The framework supports both image and text data, using LKG and VKG to offer complementary knowledge for better LVD adaptation.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) method proposed in the paper. KGD has two main stages: Knowledge Graph Extraction and Knowledge Graph Encapsulation. The extraction stage uses CLIP to create knowledge graphs (KGs) from downstream data, representing both language (LKG) and visual (VKG) aspects. These KGs capture semantic relationships learned by CLIP. The encapsulation stage integrates these KGs into a large-vocabulary object detector (LVD) to improve its object classification ability. The process is designed to handle multiple unlabeled downstream domains by using both language and visual information.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.

🔼 This figure illustrates the Knowledge Graph Distillation (KGD) framework. KGD consists of two main stages: Knowledge Graph Extraction (using CLIP to encode data as nodes and distances as edges to create LKG and VKG) and Knowledge Graph Encapsulation (transferring the extracted knowledge graphs into the object detector for improved classification). The figure highlights the interplay between language and vision knowledge graphs, showing how they complement each other for better cross-domain adaptation.
read the caption
Figure 2: Overview of the proposed Knowledge Graph Distillation (KGD). KGD comprises two consecutive stages including Knowledge Graph Extraction (KGExtract) and Knowledge Graph Encapsulation (KGEncap). KGExtract employs CLIP to encode downstream data as nodes and considers their feature distances as edges, explicitly constructing KGs including language knowledge graph (LKG) and vision knowledge graph (VKG) that inherit the rich semantic relations in CLIP. The dashed reddish lines between LKG and VKG represent the cross-modal edges that connect the nodes between vision and language modalities, enabling the integration of both language and visual information. KGEncap transfers the extracted KGs into the large-vocabulary object detector to enable accurate object classification over downstream data. Besides, KGD works for both image and text data and allow extracting and transferring vision KG (VKG) and language KG (LKG), providing complementary knowledge for adapting large-vocabulary object detectors for handling various unlabelled downstream domains.
More on tables
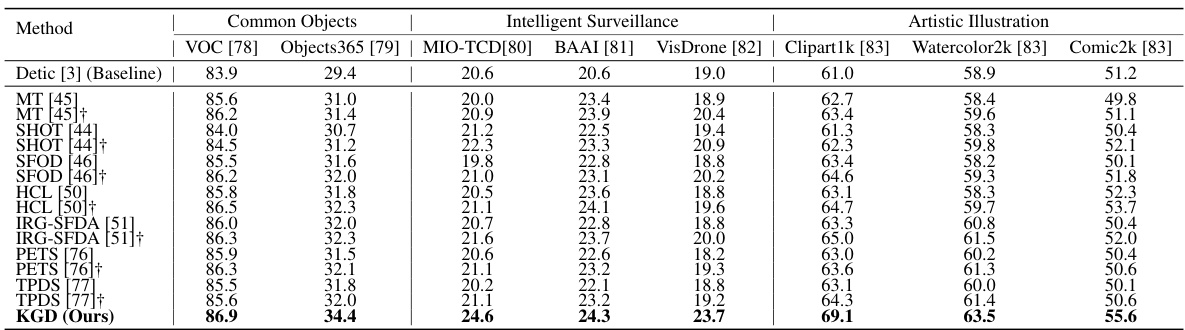
🔼 This table compares the performance of the proposed KGD method against several state-of-the-art domain adaptation methods on three different types of datasets: common objects, intelligent surveillance, and artistic illustration. The results are reported in terms of Average Precision at 50% Intersection over Union (AP50), a standard metric for object detection. The baseline method used for comparison is Detic [3]. The ‘+’ symbol indicates that the methods used both WordNet and CLIP.
read the caption
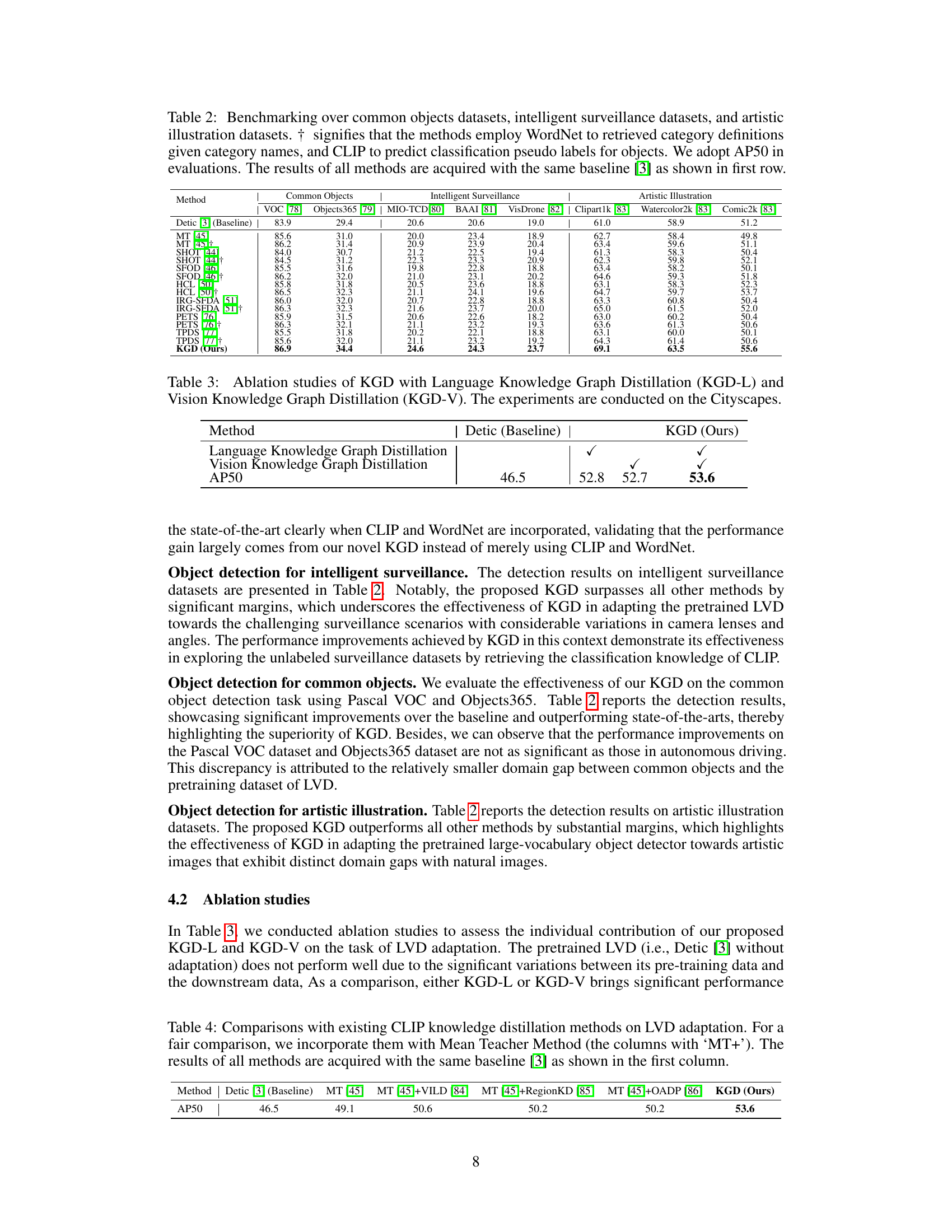
Table 2: Benchmarking over common objects datasets, intelligent surveillance datasets, and artistic illustration datasets. † signifies that the methods employ WordNet to retrieved category definitions given category names, and CLIP to predict classification pseudo labels for objects. We adopt AP50 in evaluations. The results of all methods are acquired with the same baseline [3] as shown in first row.

🔼 This table presents the ablation study results for the Knowledge Graph Distillation (KGD) method. It shows the impact of using Language Knowledge Graph Distillation (KGD-L) and Vision Knowledge Graph Distillation (KGD-V) separately and together on the Cityscapes dataset. The baseline is Detic [3] without any adaptation, and the results are measured using the AP50 metric.
read the caption
Table 3: Ablation studies of KGD with Language Knowledge Graph Distillation (KGD-L) and Vision Knowledge Graph Distillation (KGD-V). The experiments are conducted on the Cityscapes.

🔼 This table compares the proposed KGD method with other state-of-the-art CLIP knowledge distillation methods for Large Vocabulary Object Detector (LVD) adaptation. It shows the AP50 (Average Precision at 50% Intersection over Union) improvement achieved by each method over a baseline Detic [3] model on the Cityscapes dataset. The comparison highlights KGD’s superior performance.
read the caption
Table 4: Comparisons with existing CLIP knowledge distillation methods on LVD adaptation. For a fair comparison, we incorporate them with Mean Teacher Method (the columns with 'MT+'). The results of all methods are acquired with the same baseline [3] as shown in the first column.

🔼 This table presents the ablation study of different Language Knowledge Graph Distillation (KGD-L) strategies. It compares the performance of using only category names, WordNet synset definitions, and WordNet hierarchy for LKG extraction. The results show that using WordNet hierarchy for LKG extraction yields the best performance, suggesting its effectiveness in capturing comprehensive language knowledge for improved object classification. The experiments were conducted on the Cityscapes dataset.
read the caption
Table 5: Study of different KGD-L strategies. The experiments are conducted on the Cityscapes.

🔼 This table presents an ablation study on the Cityscapes dataset to analyze the impact of different strategies within the Language Knowledge Graph Distillation (KGD-L) component of the proposed Knowledge Graph Distillation (KGD) method. Specifically, it compares the performance of using just feature distance for LKG encapsulation versus the full LKG encapsulation method. The results highlight the effectiveness of the complete LKG encapsulation approach in improving the AP50 score.
read the caption
Table 6: Study of different KGD-L strategies. The experiments are conducted on the Cityscapes.

🔼 This table presents the ablation study of different KGD-V strategies on the Cityscapes dataset. It compares the performance of using a static VKG, a dynamic VKG without smoothing, and a dynamic VKG with smoothing. The results show the AP50 scores for each method, highlighting the impact of the dynamic VKG and smoothing on the overall performance.
read the caption
Table 7: Studies of different KGD-V strategies. The experiments are conducted on the Cityscapes.

🔼 This table shows the result of parameter study on the impact of pseudo label generation threshold (τ) on the performance of KGD. The experiment is conducted on the Cityscapes dataset, varying τ from 0.15 to 0.35. The AP50 (Average Precision at 50% Intersection over Union) metric is used to evaluate the performance.
read the caption
Table 8: Parameter analysis of KGD for the pseudo label generation threshold τ.

🔼 This table shows the result of the parameter study for λ in Equation (12) of the paper. The authors varied λ from 0.99 to 0.999999 and measured the AP50 performance on the Cityscapes dataset. The results show that an appropriate value of λ (0.9999) is necessary to balance prompt updating and noise reduction.
read the caption
Table 9: Parameter analysis of KGD for λ.

🔼 This table presents the results of a parameter study on the effect of the α parameter in the KGD model on the AP50 metric. Different values of α were tested on the Cityscapes dataset. The results show that an optimal value of α exists, with performance degrading when the value is too high or too low.
read the caption
Table 10: Parameter analysis of KGD for α.

🔼 This table presents the ablation study results of the proposed Knowledge Graph Distillation (KGD) method. It shows the performance improvements achieved by using only Language Knowledge Graph Distillation (KGD-L), only Vision Knowledge Graph Distillation (KGD-V), and the combination of both KGD-L and KGD-V. The experiments were conducted on four different datasets: Cityscapes, BAAI, VOC, and Clipart1k, demonstrating the effectiveness and complementarity of both KGD-L and KGD-V in improving the performance of object detection.
read the caption
Table 11: Ablation studies of KGD with Language Knowledge Graph Distillation (KGD-L) and Vision Knowledge Graph Distillation (KGD-V). The experiments are conducted on the Cityscapes, BAAI, VOC, and Clipart1k.

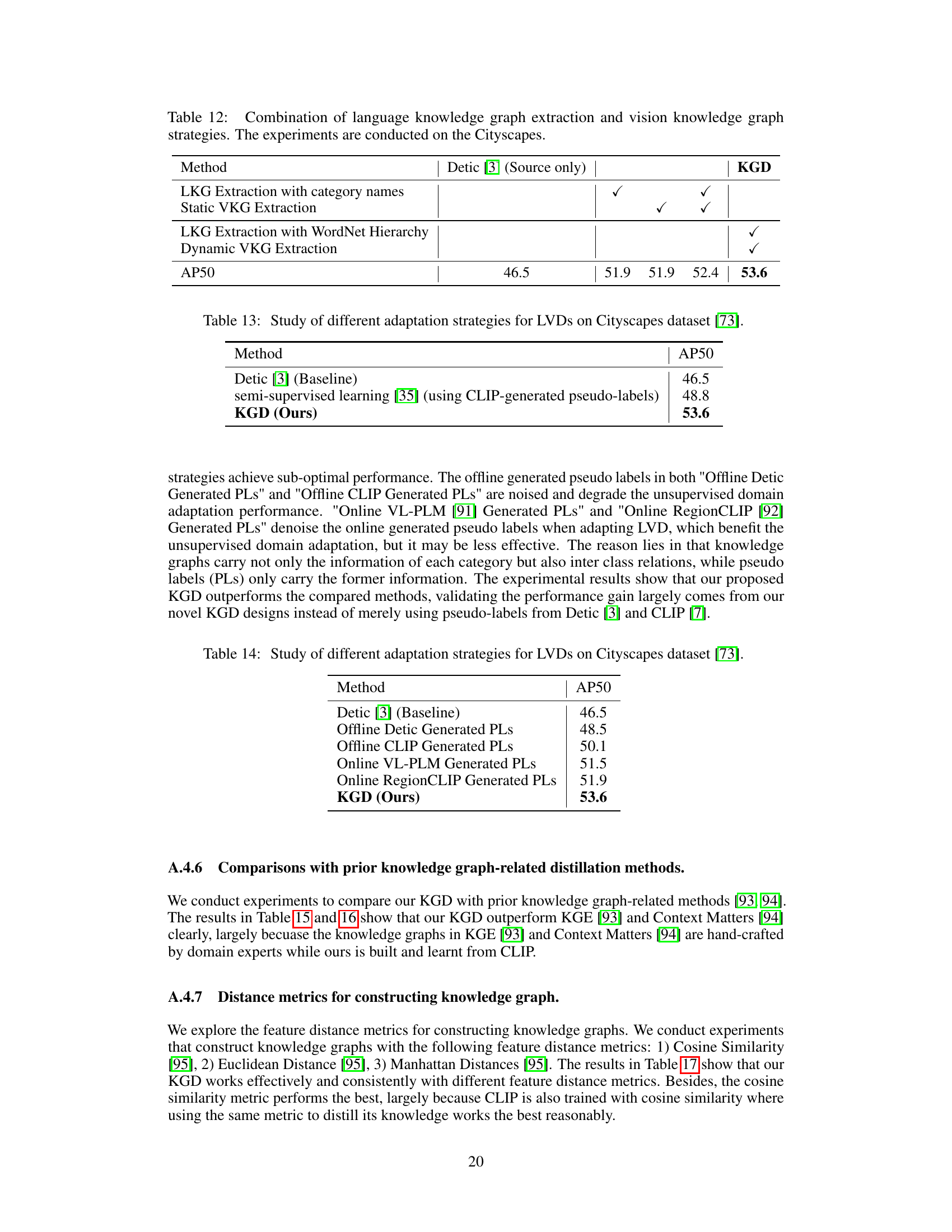
🔼 This table presents ablation study results on the Cityscapes dataset, comparing different combinations of language knowledge graph (LKG) extraction and vision knowledge graph (VKG) extraction methods within the Knowledge Graph Distillation (KGD) framework. It shows the impact of using WordNet hierarchy for LKG extraction and dynamic VKG extraction on the overall performance (AP50).
read the caption
Table 12: Combination of language knowledge graph extraction and vision knowledge graph strategies. The experiments are conducted on the Cityscapes.

🔼 This table shows the ablation study results of the proposed Knowledge Graph Distillation (KGD) method. It compares the performance of KGD using only language knowledge graph distillation (KGD-L), only vision knowledge graph distillation (KGD-V), and both combined. The results demonstrate the individual contributions and complementary effects of both language and vision knowledge graph distillation in improving the performance of object detection.
read the caption
Table 3: Ablation studies of KGD with Language Knowledge Graph Distillation (KGD-L) and Vision Knowledge Graph Distillation (KGD-V). The experiments are conducted on the Cityscapes.
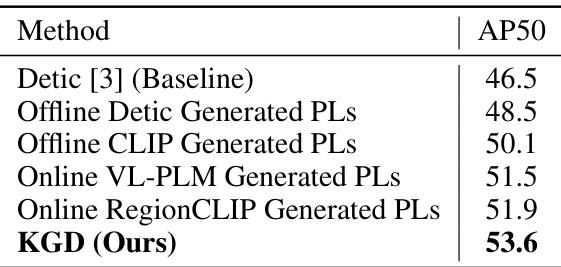
🔼 This table compares the performance of different adaptation strategies for large vocabulary object detectors (LVDs) on the Cityscapes dataset. It shows the AP50 (average precision at 50% Intersection over Union) for various methods, including the baseline Detic [3], several methods using different pseudo-label generation strategies (offline Detic, offline CLIP, online VL-PLM, online RegionCLIP), and finally the proposed Knowledge Graph Distillation (KGD) method. The table highlights the superior performance of KGD compared to other approaches in adapting the LVD to this specific dataset.
read the caption
Table 14: Study of different adaptation strategies for LVDs on Cityscapes dataset [73].

🔼 This table presents a comparison of the domain adaptation performance of the proposed Knowledge Graph Distillation (KGD) method against existing state-of-the-art methods on 11 widely used downstream detection datasets related to autonomous driving. The datasets are categorized by weather (rainy, snowy, overcast, cloudy, foggy) and time of day (daytime, dawn/dusk, night). The results are reported in terms of AP50 improvements over a baseline method. The ‘+’ symbol next to some methods indicates that WordNet and CLIP were used in conjunction with that method.
read the caption
Table 1: Benchmarking over autonomous driving datasets under various weather and time conditions. † signifies that the methods employ WordNet to retrieve category definitions given category names, and CLIP to predict classification pseudo labels for objects. We adopt AP50 in evaluations. The results of all methods are acquired with the same baseline [3] as shown in the first row.

🔼 This table compares the performance of the proposed KGD method against several state-of-the-art domain adaptation methods on three types of datasets: common objects, intelligent surveillance, and artistic illustrations. The results are measured using AP50 (Average Precision at 50% Intersection over Union), a common metric in object detection. The ‘†’ symbol indicates methods that leverage WordNet for category definition retrieval and CLIP for pseudo label generation.
read the caption
Table 2: Benchmarking over common objects datasets, intelligent surveillance datasets, and artistic illustration datasets. † signifies that the methods employ WordNet to retrieved category definitions given category names, and CLIP to predict classification pseudo labels for objects. We adopt AP50 in evaluations. The results of all methods are acquired with the same baseline [3] as shown in first row.

🔼 This table presents the results of an ablation study comparing different distance metrics used in constructing the knowledge graph (KG) within the Knowledge Graph Distillation (KGD) framework. The experiment was conducted on the Cityscapes dataset, and the performance is measured by the Average Precision at 50% Intersection over Union (AP50). The results show that the choice of distance metric has a relatively small impact on the overall performance.
read the caption
Table 17: Study of different distance metrics for constructing KG. The experiments are conducted on the Cityscapes dataset.

🔼 This table presents a detailed comparison of the training and inference time, memory usage, and computational overhead of several domain adaptive detection methods, including the proposed KGD, on a single RTX 2080Ti GPU. The methods compared include various baselines and state-of-the-art approaches. The use of WordNet and CLIP in some methods is indicated with a dagger symbol (†). The table provides a comprehensive performance comparison across all methods, highlighting the efficiency and resource requirements of the proposed KGD compared to existing approaches.
read the caption
Table 18: Training and inference time analysis of all the compared methods. The experiments are conducted on one RTX 2080Ti. † signifies that the methods employ WordNet to retrieve category descriptions given category names, and CLIP to predict classification pseudo labels for objects.
🔼 This table presents a comparison of the domain adaptation performance of the proposed Knowledge Graph Distillation (KGD) method against existing methods on 11 widely-used downstream detection datasets related to autonomous driving. The datasets are categorized by weather (rainy, snowy, overcast, cloudy, foggy) and time of day (daytime, dawn & dusk, night). The performance metric used is AP50 (Average Precision at 50% Intersection over Union). The ‘†’ symbol indicates methods that leverage WordNet and CLIP for enhanced performance. The results are benchmarked against a common baseline [3], which is included in the first row of the table.
read the caption
Table 1: Benchmarking over autonomous driving datasets under various weather and time conditions. † signifies that the methods employ WordNet to retrieve category definitions given category names, and CLIP to predict classification pseudo labels for objects. We adopt AP50 in evaluations. The results of all methods are acquired with the same baseline [3] as shown in the first row.

🔼 This table shows the performance improvement when using KGD with several open-vocabulary detectors on the Cityscapes dataset. The baseline performance of each detector is compared to its performance when combined with KGD, demonstrating KGD’s effectiveness across different detection models. The AP50 metric is used to evaluate performance.
read the caption
Table 20: Experiments with Open-Vocabulary Detectors over Cityscapes dataset. We adopt AP50 in evaluations. We can observe that our proposed KGD can also improve the performance of OVDs (e.g., GLIP [96], VILD [84], RegionKD [85], UniDet [97], and RegionCLIP [92]) significantly, validating the generalization ability of our KGD on different detectors.

🔼 This table presents a comparison of the proposed KGD method against existing state-of-the-art domain adaptation methods across eleven diverse downstream detection datasets. It highlights the consistent superior performance of KGD in terms of AP50 (average precision at 50% IoU), demonstrating its effectiveness in adapting pre-trained large vocabulary object detectors to various domains.
read the caption
Table 21: Aggregate results over 11 widely studied datasets. † signifies that the methods employ WordNet to retrieve category definitions given category names, and CLIP to predict classification pseudo labels for objects. The results of all methods are acquired with the same baseline [3] as shown in the first column.

🔼 This table presents a breakdown of the performance of the Detic model [3] on the Cityscapes dataset [73], analyzing its object detection capabilities by separating object localization and classification accuracy. It shows the standard AP50 metric, and two additional metrics that isolate the contributions of localization and classification independently. The improvement shown in parentheses highlights the effect of correcting either classification or localization errors on the overall AP50 score.
read the caption
Table 22: Benchmarking Detic over Cityscapes [73] dataset with AP50, Category-agnostic AP50, and GT bounding box-corrected AP50.
Full paper#