↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but resource-intensive. Adapting them to new tasks often requires extensive retraining, which is computationally expensive and prone to overfitting. Existing methods try to address this by only fine-tuning small parts of the model. However, they lack efficient strategies for identifying which parts are most relevant for a given task. This leads to suboptimal results.
The paper proposes LOFIT (Localized Fine-Tuning on LLM Representations), a novel technique that tackles this issue by first identifying the most crucial attention heads for a given task and then selectively fine-tuning only those heads. This drastically reduces the number of parameters needing adjustment, resulting in improved efficiency and reduced overfitting. Experiments on various tasks show LOFIT matches or even surpasses the performance of other methods while using significantly fewer parameters.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel parameter-efficient fine-tuning method, LOFIT, that significantly improves LLM adaptation for specific tasks. LOFIT’s approach of localized fine-tuning on a small subset of attention heads is both effective and efficient. This offers a new avenue for enhancing LLMs’ performance on various downstream tasks and addresses the challenges of resource constraints and overfitting in large model training.
Visual Insights#
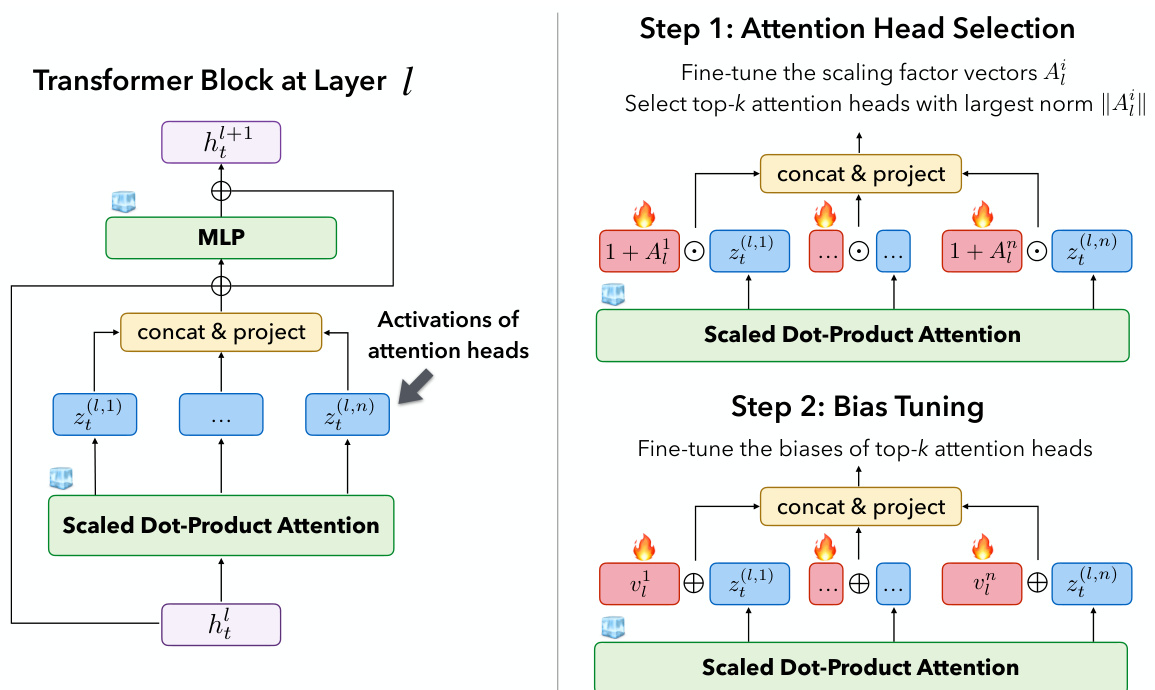
🔼 This figure illustrates the LOFIT methodology, a two-step process for modifying LLM representations. First, it selects a subset of attention heads deemed most important for a specific task. This is done by fine-tuning scaling factor vectors and selecting the top-k heads with the largest norm. Then, it fine-tunes bias vectors for these selected heads, which are added to the model’s hidden representations during inference. This localized approach uses far fewer parameters compared to other fine-tuning methods.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.
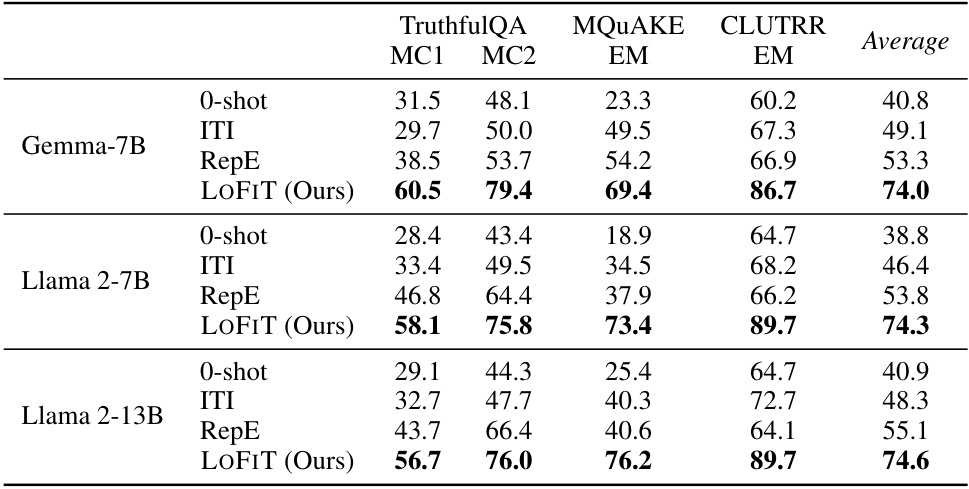
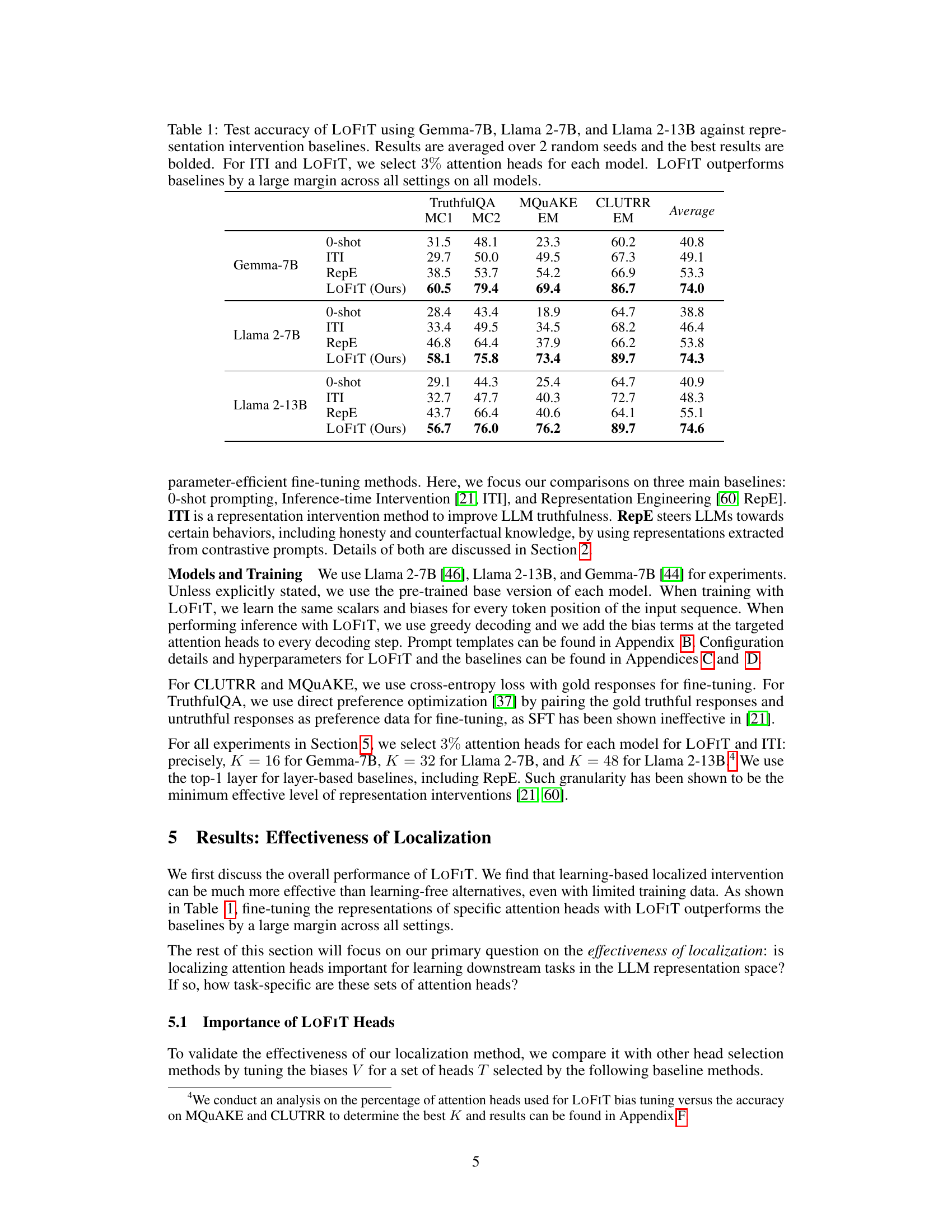
🔼 This table presents the test accuracy results of the LOFIT model compared to other representation intervention baselines (0-shot, ITI, RepE) across three different language models (Gemma-7B, Llama 2-7B, Llama 2-13B) and three different tasks (TruthfulQA, MQuAKE, CLUTRR). The results are averaged over two random seeds, and the best-performing model for each setting is bolded. For both ITI and LOFIT, only 3% of the attention heads were selected for intervention.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
In-depth insights#
LOFIT: Localized Tuning#
The concept of “LOFIT: Localized Tuning” presents a novel approach to fine-tuning large language models (LLMs). Instead of globally adjusting the model’s parameters, LOFIT focuses on identifying and modifying only a small subset of attention heads, deemed most relevant to a specific task. This localized approach offers several key advantages. First, it is computationally efficient, requiring significantly fewer parameters than global methods. Second, it enhances interpretability, by providing insight into which parts of the LLM are crucial for a given task. Third, it may lead to improved generalization, as overfitting is reduced by focusing on a task-specific set of parameters, instead of adjusting the entire network. The selection process for the attention heads is also critical, and the effectiveness of LOFIT hinges on identifying truly pertinent heads. However, challenges could arise in determining the optimal subset of attention heads, and the efficacy of the approach might depend heavily on the nature of the task and the architecture of the underlying LLM.
Head Selection Methods#
Effective head selection is crucial for the success of parameter-efficient fine-tuning methods like LOFIT. The paper explores several approaches, highlighting the importance of task-specific selection rather than relying on a universal set of heads. A key finding is that simply selecting the top-K heads based on magnitude of learned scaling factors proves effective. This suggests a strong correlation between the impact of a head on a specific task and the magnitude of its weights. Comparing this approach to alternatives such as random selection or using heads identified by other methods (e.g., ITI) demonstrates the superior performance of the proposed method. The localization step’s impact underscores the importance of considering task-specific characteristics when selecting the relevant attention heads. Different tasks, even related ones, may utilize different sets of attention heads, indicating that a more granular, task-aware approach is critical for optimizing performance.
LOFIT vs. Baselines#
A comparison of LOFIT against baselines offers crucial insights into its effectiveness. LOFIT’s superior performance across various tasks, especially with limited data, highlights its efficiency. The use of a smaller subset of attention heads, compared to other methods, contributes to its parameter efficiency. Analyzing the performance difference across models reveals how LOFIT adapts to different LLM architectures. A head-selection strategy is important for optimal performance, demonstrating that a task-specific focus improves model adaptation more effectively than general intervention. By comparing the outcomes of LOFIT with learning-free methods like Inference-Time Intervention, we uncover the advantages of learning-based approaches for achieving better performance. Investigating various baselines provides a solid foundation to assess the overall efficiency and capabilities of LOFIT.
Task-Specific Heads#
The concept of “Task-Specific Heads” in the context of large language model (LLM) fine-tuning is crucial. It posits that certain attention heads within an LLM are uniquely important for specific tasks. This contrasts with methods that uniformly modify the entire network, suggesting that a more targeted approach can be more effective and efficient. The localization of these task-specific heads is, therefore, a key step to improve performance and resource utilization. Identifying these heads allows for a smaller set of parameters to be fine-tuned, resulting in parameter-efficient fine-tuning (PEFT). This targeted approach also offers enhanced interpretability, as it highlights which parts of the model are actively involved in learning a particular task, thereby providing insights into the model’s internal mechanisms. However, the study also needs to investigate whether these specialized heads are truly task-specific or if they exhibit some degree of generalization across related tasks. The existence and nature of task-specific heads have significant implications for LLM optimization and interpretability.
Future Work#
Future research directions stemming from this LOFIT method could involve exploring its application to diverse LLM architectures beyond the decoder-only models examined. Investigating cross-lingual and multilingual adaptation capabilities of LOFIT would also be valuable. Furthermore, a deeper analysis into the interpretability of the selected heads and their relationship to specific task characteristics would enhance our understanding of the method’s mechanism. The effectiveness of LOFIT under different data conditions, such as scenarios with significantly larger or smaller datasets, needs to be thoroughly examined. Finally, combining LOFIT with other parameter-efficient fine-tuning methods could potentially produce even more efficient and effective fine-tuning strategies for LLMs.
More visual insights#
More on figures
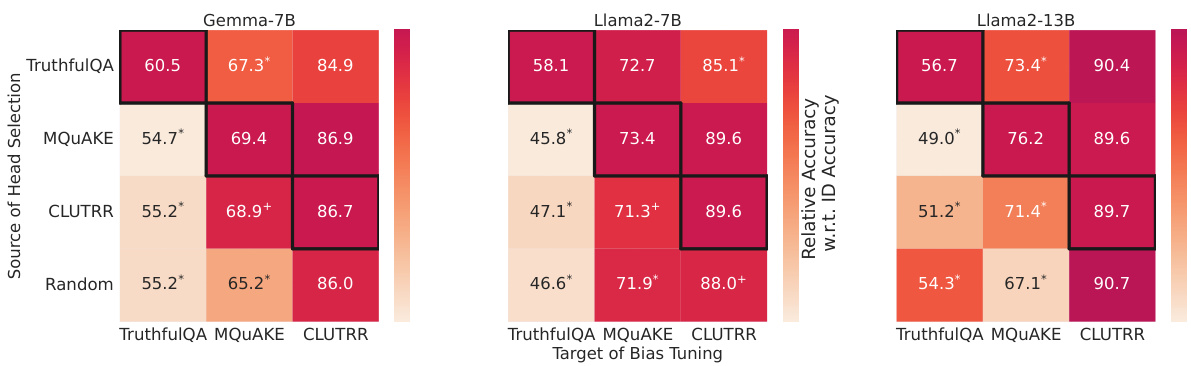
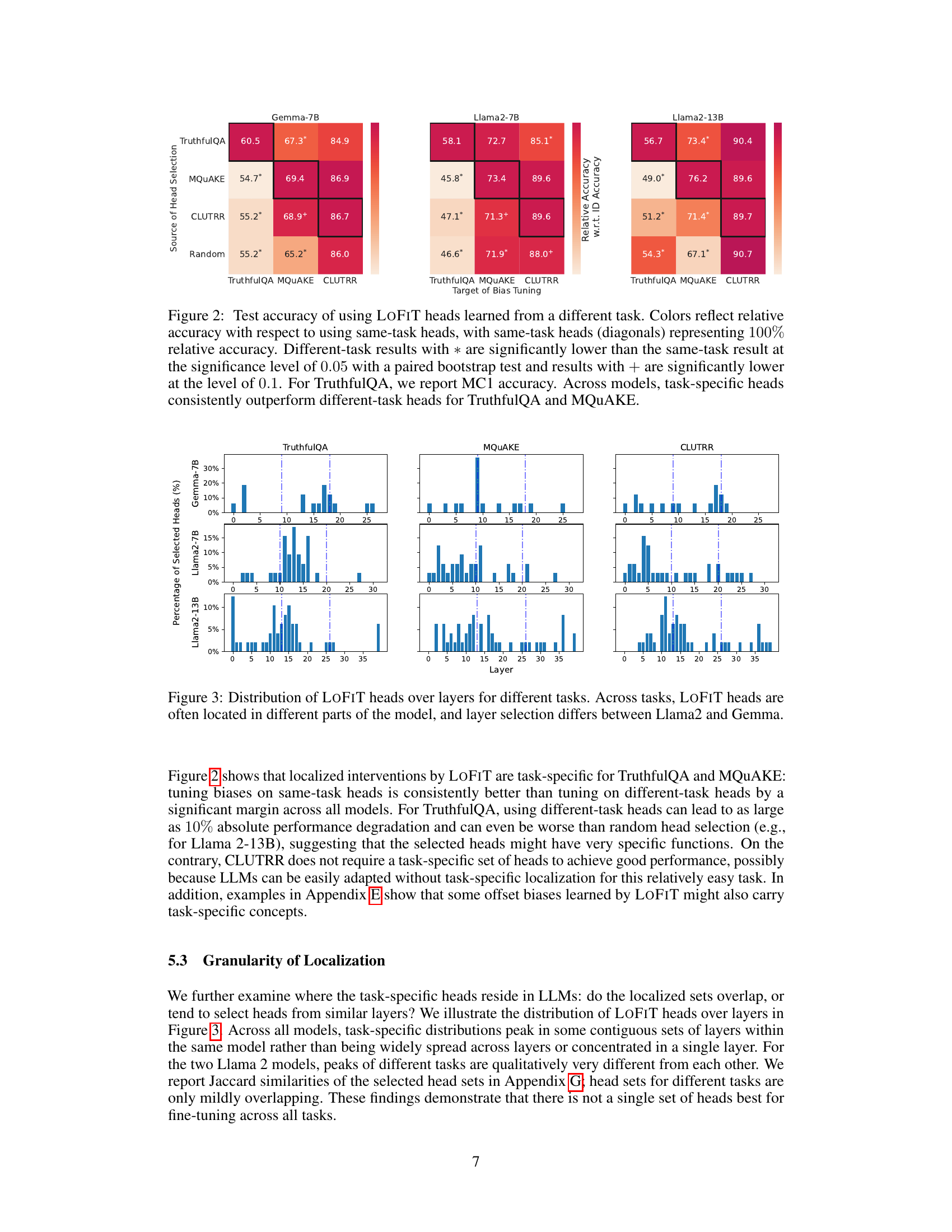
🔼 This figure shows the results of an experiment evaluating the task specificity of LOFIT’s attention head selection. It compares the performance of using attention heads selected for a specific task versus using heads selected for a different task. The results demonstrate that using task-specific heads consistently leads to significantly higher accuracy compared to using heads from other tasks across multiple models and datasets. This highlights the importance of LOFIT’s task-specific localization.
read the caption
Figure 2: Test accuracy of using LOFIT heads learned from a different task. Colors reflect relative accuracy with respect to using same-task heads, with same-task heads (diagonals) representing 100% relative accuracy. Different-task results with * are significantly lower than the same-task result at the significance level of 0.05 with a paired bootstrap test and results with + are significantly lower at the level of 0.1. For TruthfulQA, we report MC1 accuracy. Across models, task-specific heads consistently outperform different-task heads for TruthfulQA and MQUAKE.
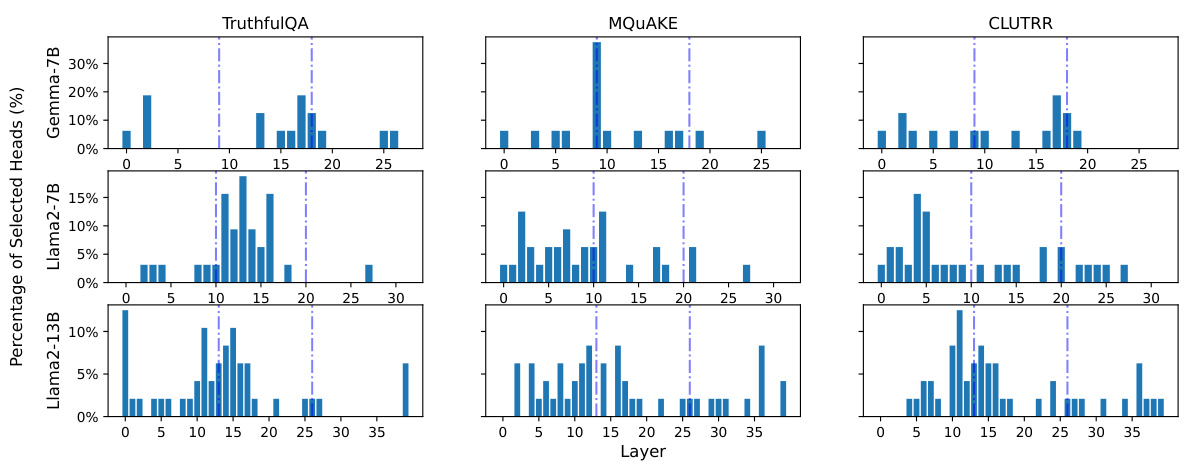
🔼 This figure shows the distribution of the selected attention heads across different layers of the language models for three different tasks: TruthfulQA, MQuAKE, and CLUTRR. The graphs illustrate that the selected heads are not uniformly distributed across the layers, and the distribution varies depending on the task and the model used (Llama 2 7B, Llama 2 13B, and Gemma 7B). This supports the paper’s claim that LOFIT’s head selection is task-specific and not generalized.
read the caption
Figure 3: Distribution of LOFIT heads over layers for different tasks. Across tasks, LOFIT heads are often located in different parts of the model, and layer selection differs between Llama2 and Gemma.
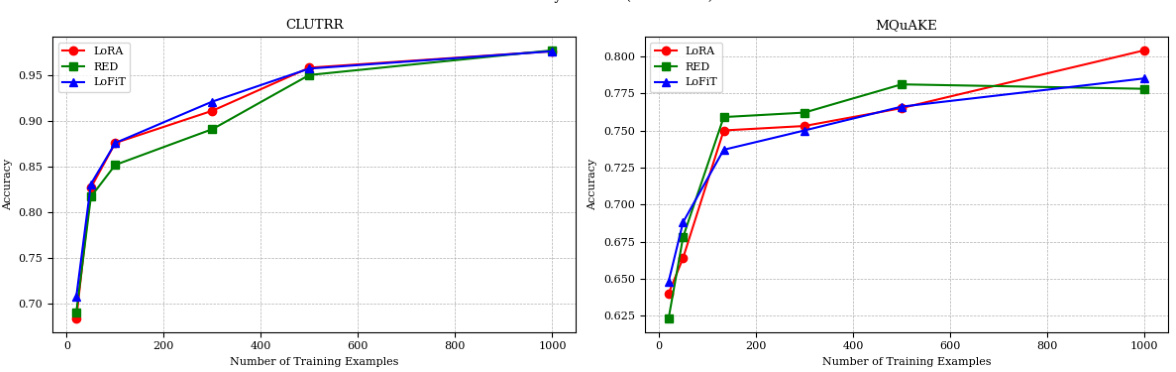
🔼 This figure shows the performance of LOFIT against LoRA and RED on CLUTRR and MQUAKE datasets with varying numbers of training examples. LOFIT demonstrates superior data efficiency in low-data regimes (less than 100 examples) and remains competitive with LoRA and RED using significantly fewer parameters when more data is available (300 or more examples).
read the caption
Figure 4: LOFIT performance using different numbers of training examples n on CLUTRR and MQUAKE with Llama 2-7B. For LOFIT, we tune 10% of the attention heads. Results are averaged over two runs. In the low data settings (n < 100), LOFIT is more data efficient than LoRA and RED. For n ≥ 300, LOFIT is still comparable to LoRA and RED with fewer parameters.

🔼 The figure shows the architecture of LOFIT, which consists of two main steps. First, it selects a subset of attention heads that are important for a specific task by fine-tuning scaling factor vectors on attention heads. Second, it fine-tunes offset bias vectors that are added to the representations of those selected attention heads. Only the tuned biases are used in the final model. This approach is designed to be parameter-efficient and to localize the impact of fine-tuning on the LLM.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.

🔼 The figure shows the two-step process of LOFIT. First, attention head selection is performed by fine-tuning scaling factor vectors and selecting the top-k heads with the largest norm. Then, bias tuning is done by fine-tuning bias vectors for these selected heads. The final model only uses the tuned biases.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.

🔼 The figure shows the two-step framework of LOFIT. First, it selects a subset of attention heads using a learnable scaling factor. Then, it learns offset vectors to add to the hidden representations of the selected heads. The final model only uses the tuned biases. This localized approach is more parameter-efficient compared to other methods.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.

🔼 This figure illustrates the LOFIT methodology, which involves two main steps. First, it selects a subset of attention heads that are important for a specific task using a learned scaling factor. Second, it fine-tunes the biases of those selected attention heads by adding offset vectors to the hidden representations. The pre-trained weights of the transformer language model remain frozen throughout the process. Only the tuned biases are used in the final LOFIT model.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.
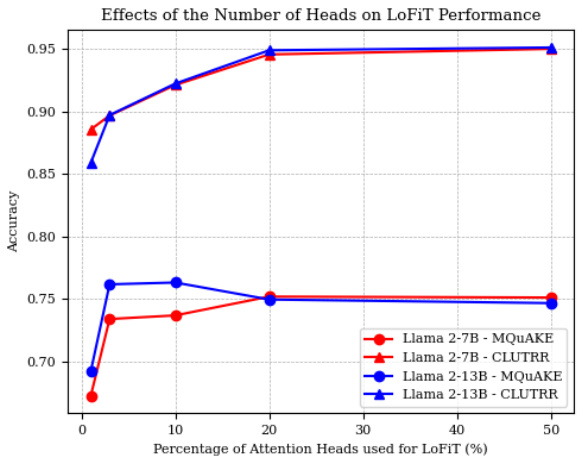
🔼 This figure shows how the model’s performance changes depending on the percentage of attention heads used for fine-tuning during the bias tuning stage of LOFIT. The x-axis represents the percentage of attention heads used, and the y-axis shows the accuracy. The results show that accuracy improves as more attention heads are used, but only up to a certain point (around 10-20%). After this point, increasing the number of heads does not significantly improve accuracy. This suggests that a limited set of attention heads is most effective for fine-tuning and that including too many heads may lead to diminishing returns or even negative effects.
read the caption
Figure 5: The effects of the percentage of attention heads K used for LOFIT Bias Tuning on LOFIT performance. Results are averaged over two runs. The test accuracy increases with K when K < 10% and plateaus when K reaches 10% - 20%.

🔼 This figure shows the distribution of the selected attention heads across different layers for three different tasks (TruthfulQA, MQuAKE, and CLUTRR) and for three different LLMs (Gemma-7B, Llama 2-7B, and Llama 2-13B). Each bar represents the percentage of selected heads in a particular layer. The figure visually demonstrates that the task-specific attention heads selected by LOFIT are not randomly distributed across the layers. Instead, their distribution varies across different tasks and models, suggesting task-specific localization of the heads. This supports the paper’s claim of task-specificity in LOFIT.
read the caption
Figure 3: Distribution of LOFIT heads over layers for different tasks. Across tasks, LOFIT heads are often located in different parts of the model, and layer selection differs between Llama2 and Gemma.
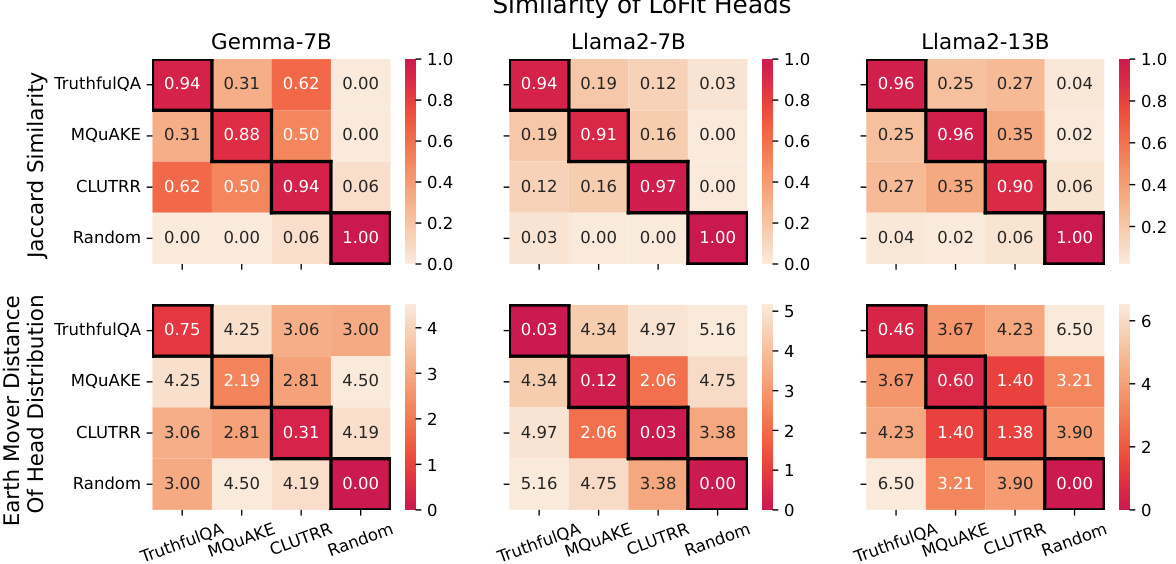
🔼 This figure displays the results of an experiment testing the impact of using task-specific attention heads versus non-task-specific heads in the LOFIT model. The diagonal shows the accuracy when the same task heads were used for both training and testing. Off-diagonal values show the accuracy when heads selected for one task (e.g., TruthfulQA) were used to fine-tune the model for a different task (e.g., MQuAKE). The results demonstrate that using task-specific heads significantly improves model accuracy compared to using heads from a different task or random head selection, highlighting the importance of localization for optimal performance.
read the caption
Figure 2: Test accuracy of using LOFIT heads learned from a different task. Colors reflect relative accuracy with respect to using same-task heads, with same-task heads (diagonals) representing 100% relative accuracy. Different-task results with * are significantly lower than the same-task result at the significance level of 0.05 with a paired bootstrap test and results with + are significantly lower at the level of 0.1. For TruthfulQA, we report MC1 accuracy. Across models, task-specific heads consistently outperform different-task heads for TruthfulQA and MQUAKE.

🔼 This figure illustrates the LOFIT methodology, which involves two main steps. First, it selects a subset of attention heads deemed most important for a specific task by fine-tuning scaling factors and choosing the heads with the largest norm of these factors. Second, it fine-tunes offset (bias) vectors for these selected heads. Only the learned biases are incorporated into the final model, making it a parameter-efficient method. The pre-trained weights of the transformer language model remain frozen throughout the process.
read the caption
Figure 1: LOFIT methodology. LOFIT freezes all pre-trained weights of a transformer language model and uses two sets of lightweight parameters to modify the LLM representations in two steps: Attention Head Selection and Bias Tuning. Only the tuned biases are used in the final model.
More on tables

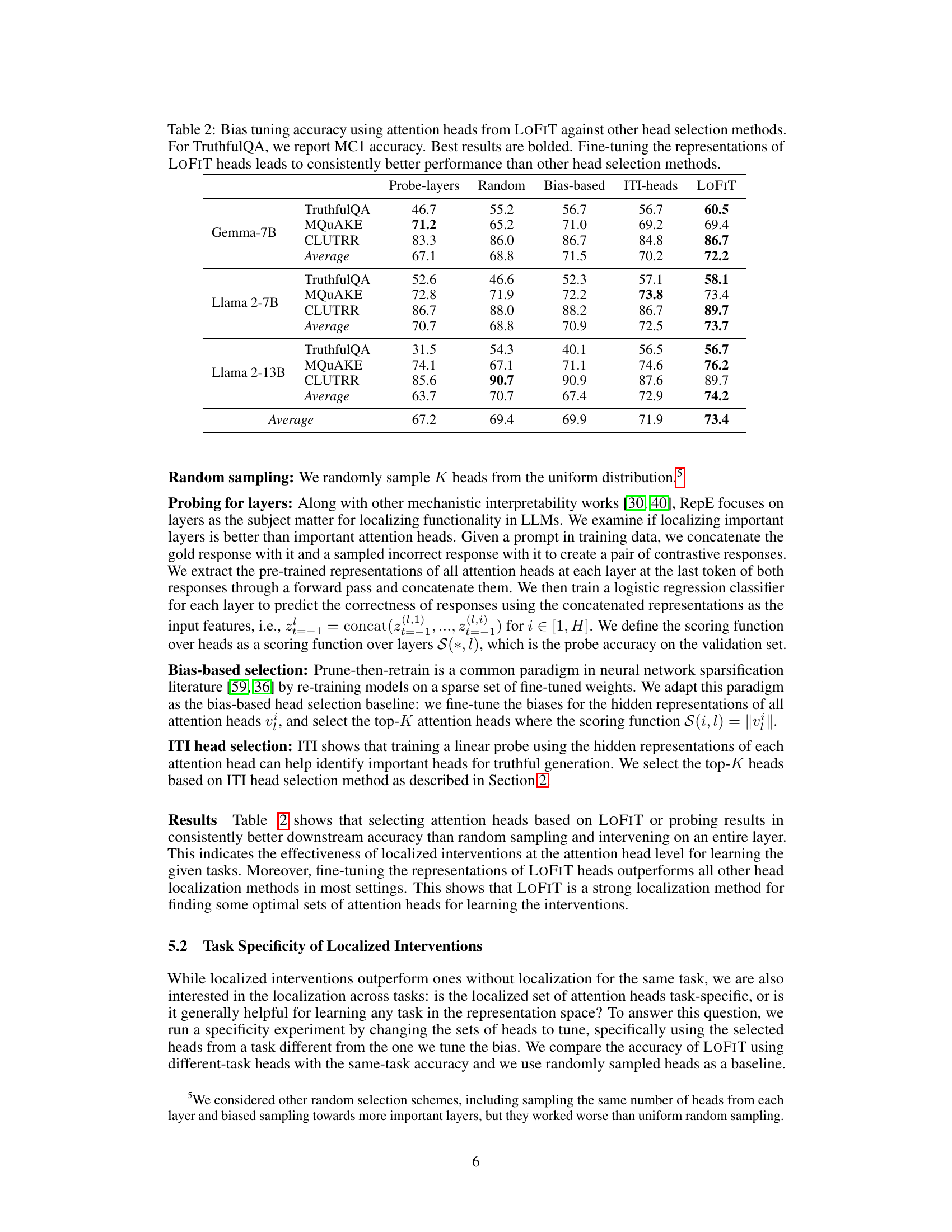
🔼 This table compares the accuracy of bias tuning using attention heads selected by different methods: LOFIT, random sampling, probing layers, bias-based selection, and ITI-heads. It shows the accuracy achieved on three tasks: TruthfulQA (MC1 accuracy reported), MQUAKE (EM), and CLUTRR (EM), for three different language models: Gemma-7B, Llama 2-7B, and Llama 2-13B. The results demonstrate that LOFIT consistently outperforms other head selection methods across all tasks and models.
read the caption
Table 2: Bias tuning accuracy using attention heads from LOFIT against other head selection methods. For TruthfulQA, we report MC1 accuracy. Best results are bolded. Fine-tuning the representations of LOFIT heads leads to consistently better performance than other head selection methods.
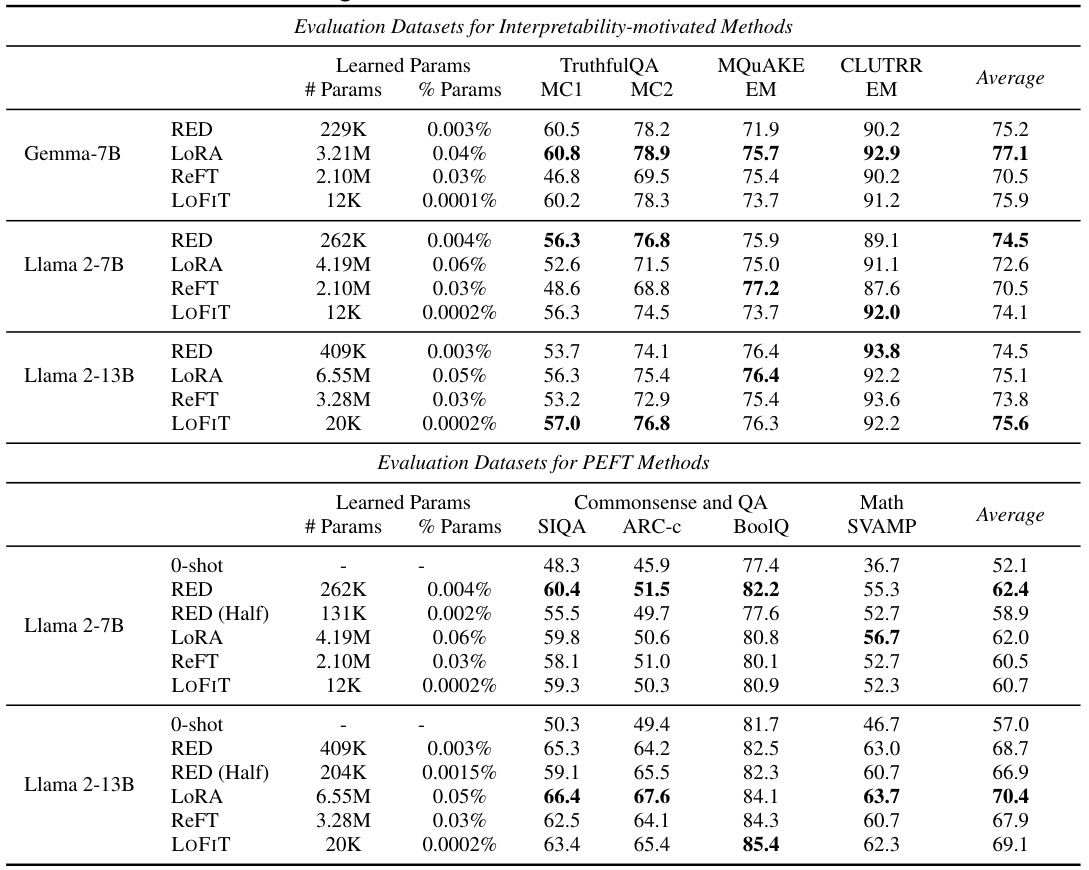
🔼 This table presents the test accuracy results of the LOFIT model, along with three comparison baselines (0-shot, ITI, RepE) on three different language models (Gemma-7B, Llama 2-7B, Llama 2-13B). The results are averaged over two random seeds, and the best-performing method for each metric is highlighted in bold. For ITI and LOFIT, only 3% of the attention heads were modified. The table demonstrates that LOFIT significantly outperforms the baseline methods across all models and evaluation metrics.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
🔼 This table presents the test accuracy results for the LOFIT model compared to various representation intervention baselines on three different language models: Gemma-7B, Llama 2-7B, and Llama 2-13B. The results are averaged across two runs, and the best-performing model is highlighted in bold. For both Inference-Time Intervention (ITI) and LOFIT, only 3% of attention heads were selected for modification. The table demonstrates that LOFIT consistently outperforms all baselines across various tasks and model sizes.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
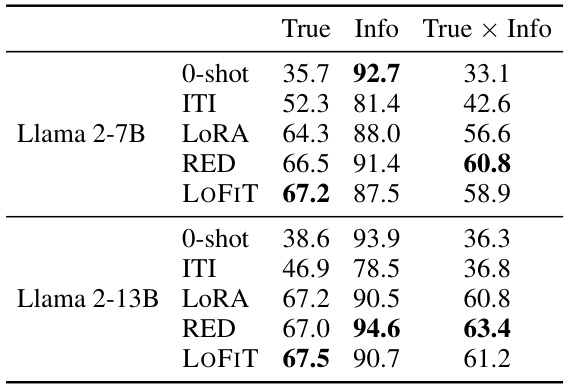
🔼 This table shows the out-of-domain generalization performance of LOFIT on Llama 2-7B-Chat after fine-tuning on TruthfulQA. It compares LOFIT’s performance on several out-of-domain question answering benchmarks (TriviaQA, NQ, MMLU) using zero-shot prompting, against its in-domain performance (TruthfulQA) and the performance of other methods (ITI, RED, LORA). The ‘No-FT’ row shows the baseline performance of the model without any fine-tuning. The results highlight LOFIT’s ability to maintain good performance on unseen tasks after fine-tuning on a specific task, unlike other methods that might suffer performance degradation on out-of-domain tasks.
read the caption
Table 5: Out-of-domain generalization performance of LOFIT on Llama 2-7B-Chat after fine-tuning on TruthfulQA. 0-shot prompts are used for OOD evaluation. 'No-FT' represents the base model without being fine-tuned on TruthfulQA. In-domain evaluation results on TruthfulQA are also included for reference. Compared to PEFT methods, LOFIT better preserves the existing capabilities of the base model after being fine-tuned across all settings.

🔼 This table presents the test accuracy results for three different language models (Gemma-7B, Llama 2-7B, and Llama 2-13B) across three different tasks (TruthfulQA, MQuAKE, and CLUTRR). The performance of LOFIT is compared against three baselines: 0-shot, ITI (Inference-time Intervention), and RepE (Representation Engineering). The results show that LOFIT significantly outperforms the baselines in all cases, demonstrating its effectiveness.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.

🔼 This table compares the performance of LOFIT against three baselines (0-shot, ITI, and RepE) across three different language models (Gemma-7B, Llama 2-7B, and Llama 2-13B) on three different tasks (TruthfulQA, MQuAKE, and CLUTRR). The results show that LOFIT significantly outperforms the baselines, demonstrating its effectiveness in improving LLM performance.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
🔼 This table presents the test accuracy results of the LOFIT model, compared against other representation intervention baselines (0-shot, ITI, RepE), across three different large language models (Gemma-7B, Llama 2-7B, Llama 2-13B) and three different downstream tasks (TruthfulQA, MQUAKE, CLUTRR). Results are averaged over two random seeds for each model and task, with the best performance highlighted in bold. A key aspect of the comparison is the consistent superior performance of LOFIT which uses only 3% of the attention heads in each model.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
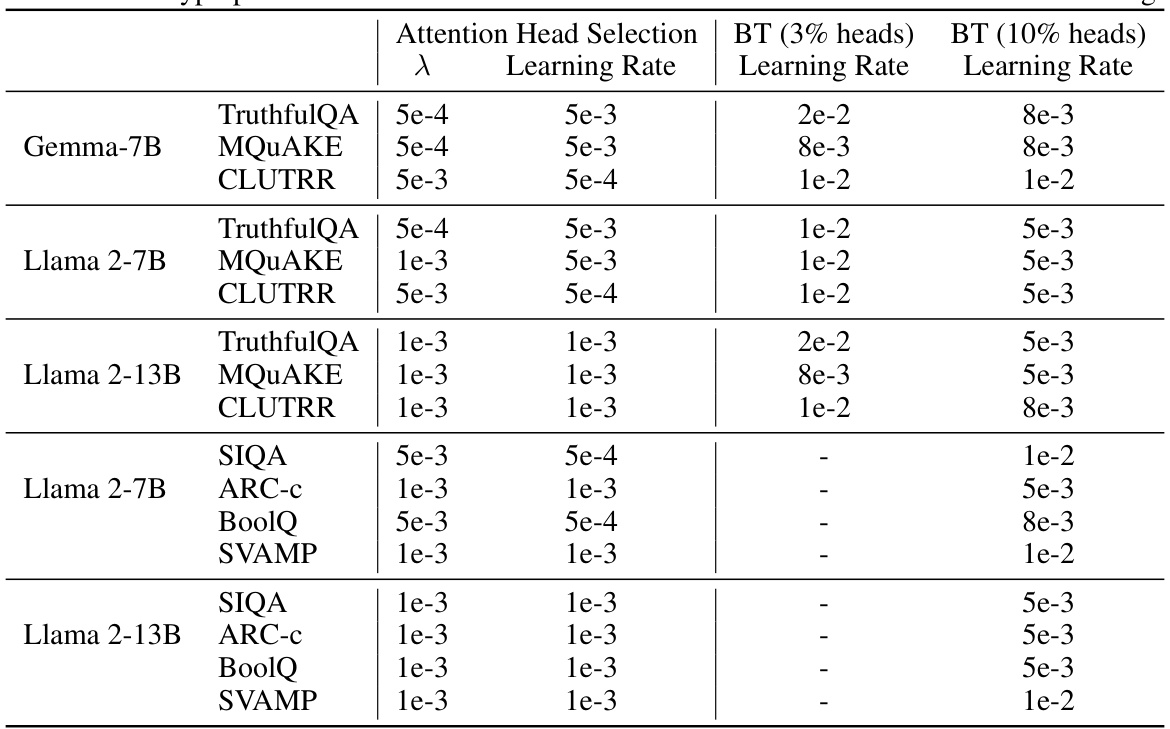
🔼 This table presents the test accuracy results of the LOFIT model compared to other representation intervention baselines across three different language models (Gemma-7B, Llama 2-7B, and Llama 2-13B) on three tasks: TruthfulQA, MQuAKE, and CLUTRR. The results are averaged over two random seeds, and the best-performing model is highlighted in bold. For the ITI and LOFIT models, only 3% of the attention heads were selected for each language model. The table clearly shows that LOFIT significantly outperforms the baselines on all tasks and models.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
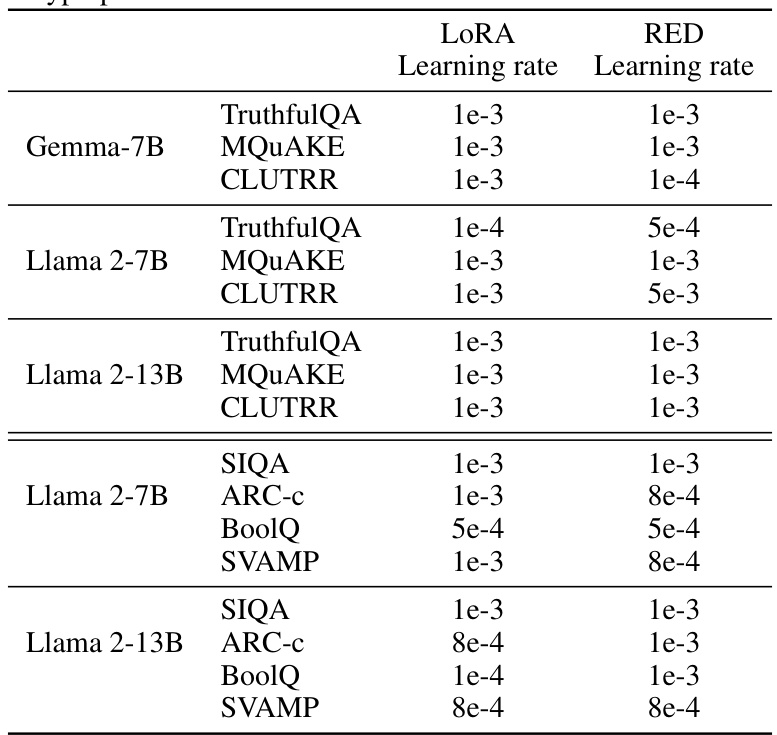
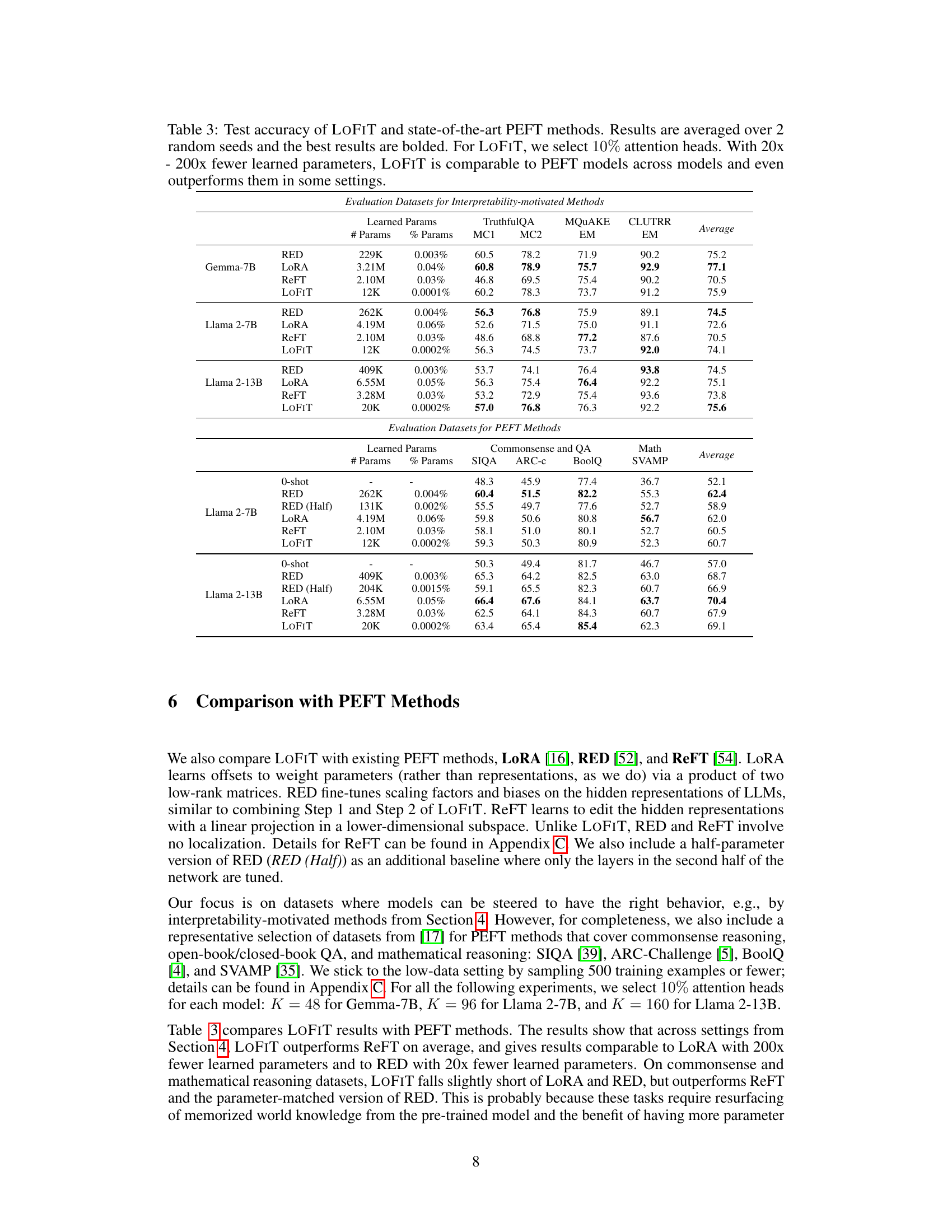
🔼 This table compares the performance of LOFIT against other parameter-efficient fine-tuning (PEFT) methods such as LoRA, RED, and ReFT across various tasks and language models. It highlights LOFIT’s comparable performance despite using significantly fewer parameters (20x-200x fewer). The results demonstrate LOFIT’s competitiveness even with substantially reduced parameter modifications.
read the caption
Table 3: Test accuracy of LOFIT and state-of-the-art PEFT methods. Results are averaged over 2 random seeds and the best results are bolded. For LOFIT, we select 10% attention heads. With 20x-200x fewer learned parameters, LOFIT is comparable to PEFT models across models and even outperforms them in some settings.
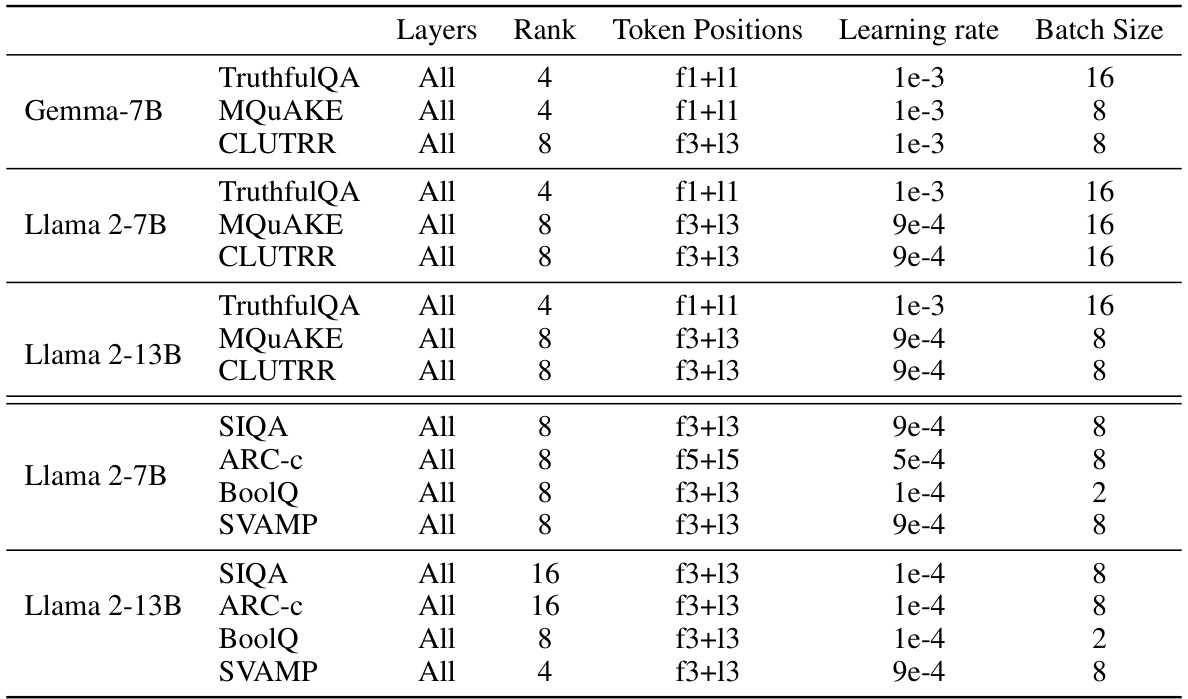
🔼 This table compares the performance of LOFIT against other representation intervention methods (ITI and RepE) across three different language models (Gemma-7B, Llama 2-7B, and Llama 2-13B) on three different downstream tasks (TruthfulQA, MQuAKE, and CLUTRR). The results show that LOFIT significantly outperforms the baseline methods on all tasks and across all models, even when using only 3% of the attention heads.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.

🔼 This table presents the test accuracy results of the LOFIT model and its baselines (O-shot, ITI, and RepE) on three different datasets (TruthfulQA, MQUAKE, and CLUTRR) using three different language models (Gemma-7B, Llama 2-7B, and Llama 2-13B). The results show that LOFIT significantly outperforms all the baselines across all datasets and models. The performance is averaged over two random seeds, and the best results are highlighted in bold. For fair comparison, both LOFIT and ITI use 3% of the attention heads.
read the caption
Table 1: Test accuracy of LOFIT using Gemma-7B, Llama 2-7B, and Llama 2-13B against representation intervention baselines. Results are averaged over 2 random seeds and the best results are bolded. For ITI and LOFIT, we select 3% attention heads for each model. LOFIT outperforms baselines by a large margin across all settings on all models.
Full paper#