↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current large language models (LLMs) demand substantial computational resources, hindering their practical deployment. Quantization, reducing the precision of model parameters, offers a potential solution but faces challenges, especially with activations containing outliers. This leads to accuracy loss when using simple quantization techniques.
QuaRot, a novel quantization scheme based on rotations, overcomes these limitations by rotating the LLM’s hidden states to eliminate outliers before quantization. This computationally invariant rotation simplifies the process, enabling lossless 4-bit quantization of all model components—weights, activations, and KV cache. The results show significant performance improvements, including a 3.33x speedup in prefill and a 3.89x memory saving during decoding on a 70B parameter LLM. Additionally, 6-bit and 8-bit models demonstrate lossless quantization using standard rounding.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in large language model (LLM) optimization and hardware acceleration. It presents QuaRot, a novel quantization technique achieving 4-bit inference in LLMs, significantly improving efficiency and opening new avenues for deploying LLMs on resource-constrained devices. Its impact is particularly relevant given the current focus on optimizing LLM inference for reduced cost and energy consumption.
Visual Insights#

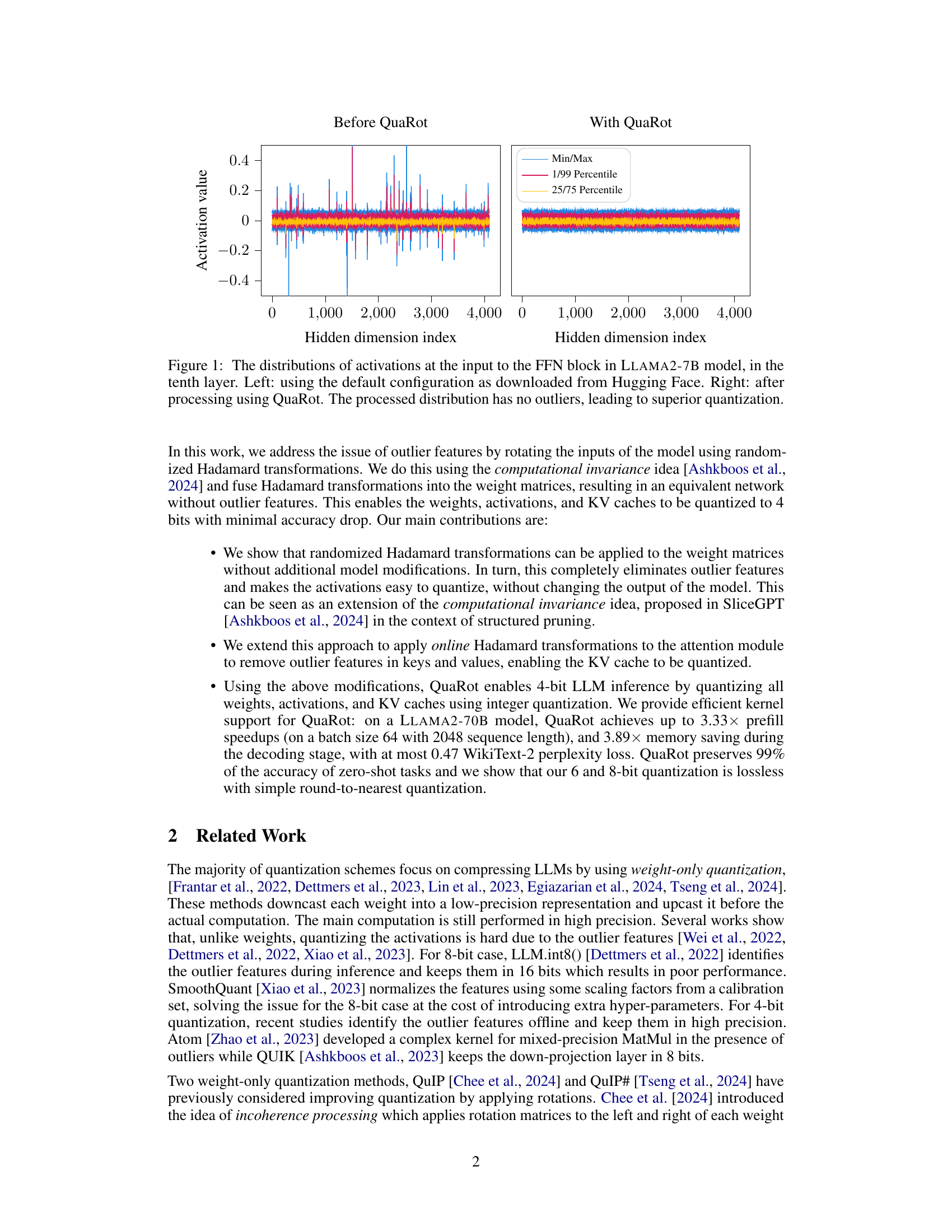
🔼 This figure compares the distribution of activations before and after applying the QuaRot technique. The left side shows the original distribution with many outlier data points. The right side shows the distribution after applying QuaRot, where the outliers have been eliminated, resulting in a more uniform distribution and improved quantization.
read the caption
Figure 1: The distributions of activations at the input to the FFN block in LLAMA2-7B model, in the tenth layer. Left: using the default configuration as downloaded from Hugging Face. Right: after processing using QuaRot. The processed distribution has no outliers, leading to superior quantization.

🔼 This table presents the WikiText-2 perplexity scores achieved by various 4-bit quantization methods on the LLAMA-2 language models. The models are tested with sequences of length 2048. The table compares QuaRot’s performance against SmoothQuant, OmniQuant, QUIK-4B, Atom-128G, and QuaRot-128G, highlighting the impact of different quantization techniques and outlier feature handling strategies on model accuracy.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
In-depth insights#
QuaRot’s Rotation#
QuaRot’s core innovation lies in its use of rotations, specifically randomized Hadamard transformations, to address the challenge of outlier values in LLMs during quantization. These rotations, applied to weights and activations, transform the data distribution to minimize the impact of extreme values, making subsequent quantization more effective. This clever approach avoids the need for outlier-specific handling or calibration datasets, which are common in other quantization methods. The computational invariance property ensures that these rotations don’t alter the model’s output, preserving accuracy while improving quantizability. Fusion of the transformations into weight matrices further optimizes computation by reducing the number of explicit rotation operations. This technique enables a truly end-to-end, 4-bit quantization of LLMs, encompassing all weights, activations, and KV caches, a notable achievement with significant implications for efficiency and deployment of LLMs.
4-bit Quantization#
The research paper explores 4-bit quantization techniques for large language models (LLMs), a significant advancement in model compression. QuaRot, the proposed method, achieves this by employing randomized Hadamard transformations to eliminate outlier features in activations and weights before quantization. This innovative approach allows for end-to-end 4-bit quantization without sacrificing performance, as demonstrated by results on the LLAMA2 model. The computational invariance property employed ensures that despite the transformations, model output remains unaffected. Compared to other methods, QuaRot achieves superior performance, surpassing competitors in perplexity scores and maintaining near-lossless accuracy. Key advantages include minimal accuracy loss with significant memory and compute efficiency gains for inference, making it highly practical for deploying large LLMs in resource-constrained environments. Further analysis reveals that lossless 6-bit and 8-bit quantization can also be attained using simpler round-to-nearest methods. The research highlights the efficacy of QuaRot for both prefill and decoding phases of inference, improving upon existing approaches significantly.
Hadamard Transform#
The application of Hadamard transforms within the context of this research paper centers around their inherent properties as orthogonal matrices for enhancing the quantization process of Large Language Models (LLMs). By applying Hadamard transformations to weight matrices, the authors aim to reduce incoherence. This technique is critical because high incoherence makes weight quantization challenging, especially when targeting low-bit representations like 4-bits. The methodology uses randomized Hadamard matrices, offering efficiency advantages and avoiding the need for precise, deterministic Hadamard matrices. Crucially, the computational invariance theorem enables the integration of these transformations without altering the model’s output, making this an efficient approach to outlier elimination in activations. The extension of Hadamard transforms to the attention module further highlights its potential for improving the quantization of keys and values within the KV cache, ultimately impacting memory efficiency and inference speed. This strategic use of Hadamard transforms forms a core element of the proposed quantization method, effectively addressing the limitations of conventional approaches to quantizing LLMs.
LLM Efficiency#
Large Language Models (LLMs) are computationally expensive, demanding significant resources for both training and inference. LLM efficiency focuses on reducing this computational burden through various techniques. Quantization, a core method discussed, reduces the precision of model weights and activations, leading to smaller model sizes and faster processing. However, naive quantization can result in substantial accuracy loss. The paper explores innovative approaches like rotating the model’s inputs to mitigate this issue, enabling effective quantization without significant performance degradation. This is crucial for deploying LLMs on resource-constrained devices and reducing their environmental impact. Further efficiency gains are sought through optimized matrix multiplications and efficient cache management, which are critical aspects of inference speed. Future research should explore the trade-offs between different efficiency techniques and their impact on the overall LLM performance and applicability.
Future of QuaRot#
The future of QuaRot hinges on addressing its current limitations and exploring new applications. Extending QuaRot’s applicability beyond LLMs to other deep learning models is a key area for development, potentially impacting various domains including computer vision and speech recognition. Improving the quantization process for various hardware architectures, such as mobile GPUs, is crucial for broader adoption. Research into more efficient and accurate quantization techniques is also needed to minimize performance loss. Further exploration of the interplay between rotation and quantization, particularly the exploration of alternative orthogonal transformations beyond Hadamard, promises to unlock new performance gains. Developing a better understanding of how QuaRot impacts different model architectures will allow for its optimization and improved effectiveness. Combining QuaRot with other compression methods, such as pruning, might yield additional performance benefits. Finally, research should focus on addressing the challenges posed by long sequences and larger batch sizes inherent to many LLMs to improve scalability.
More visual insights#
More on figures

🔼 This figure shows the distribution of activations before and after applying the QuaRot method. The left panel shows the original distribution from the LLAMA2-7B model downloaded from Hugging Face, which exhibits several outliers (extreme values). The right panel shows the distribution after QuaRot processing, which successfully removes outliers by rotating the input data through Hadamard transformations. The removal of outliers makes quantization easier, leading to better results.
read the caption
Figure 1: The distributions of activations at the input to the FFN block in LLAMA2-7B model, in the tenth layer. Left: using the default configuration as downloaded from Hugging Face. Right: after processing using QuaRot. The processed distribution has no outliers, leading to superior quantization.
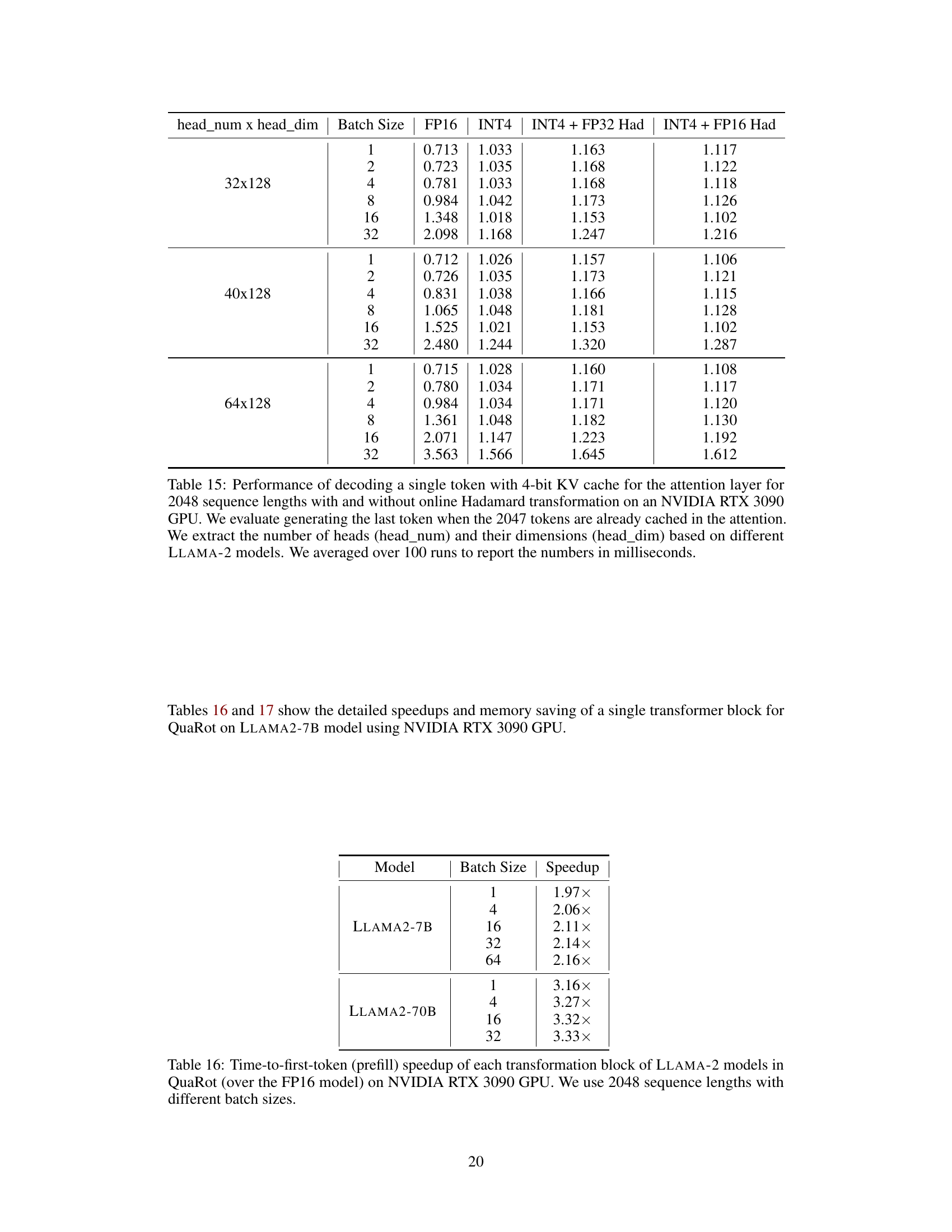
🔼 This figure shows a gated feed-forward network, a common component in large language models (LLMs). It illustrates the flow of data through the network, highlighting the operations performed at each stage including RMSNorm, linear transformations (Wgate, Wup, Wdown), and an activation function (σ). The caption emphasizes that before quantization, operations are typically performed at higher precision (32-bit or 16-bit).
read the caption
Figure 2: The gated feed-forward network used in most LMs, including the pre-positioned RMSNorm. The input signal is divided by its norm, and re-scaled by parameters a. Two linear blocks, Wup and Wgate are applied. The activation function o is applied to the gated signal, and the two signals are element-wise multiplied together. The final linear block Wdown produces the output signal Y. Before quantization, different operations are performed either in single (32 bit) or half (16 bit) precision.

🔼 This figure illustrates the QuaRot method applied to a feed-forward network (FFN) in a Llama-style large language model. It shows how the weights and activations are processed to enable 4-bit quantization. The key elements are the absorption of RMSNorm scaling into the weight matrices, the rotation of the hidden state using Hadamard transformation (Q), the cancellation of this rotation through QT, 4-bit quantization of weights and activations, and a final on-the-fly Hadamard transform before the output is produced. This computational invariance allows for efficient low-bit inference.
read the caption
Figure 3: QuaRot applied to a LLaMa-style FFN. The RMSNorm scaling (a) has been absorbed into the weight matrices ((a) is a diagonal matrix with RMSNorm parameters). The hidden state X has been rotated by Q, which is canceled out by the absorption of QT into the first two weight matrices. All weights are stored in INT4, and all activations immediately before the weights are also quantized to INT4. The result of the matmul between the INT4 weights and activations on a TensorCore is INT32, which we immediately cast (and scale) to FP16 which is the default precision of the model. Whilst the signal is still in FP16, we perform a single on-the-fly Hadamard transform before quantizing and computing a (modified) down-proj, which results in a rotated output YQ.
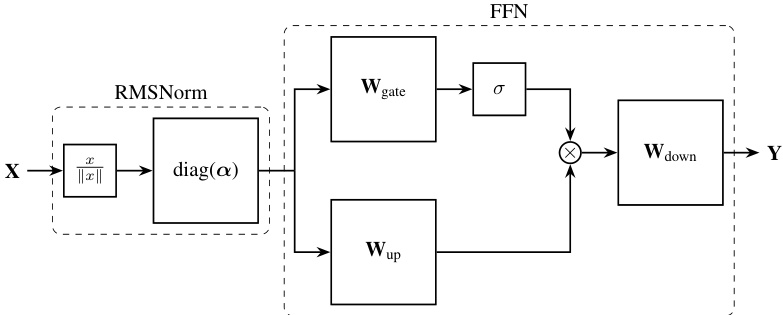
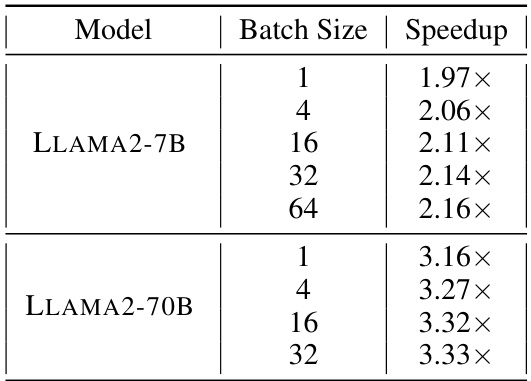
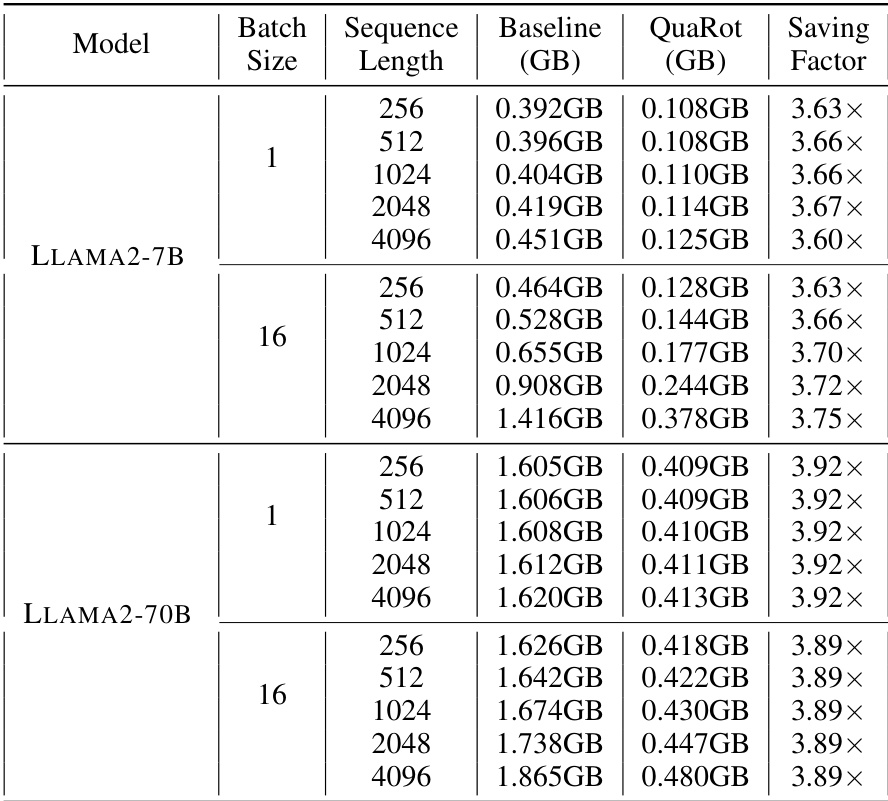
🔼 This figure shows the performance gains of QuaRot on LLAMA-2 models. The left panel displays speedups in the prefill stage (processing input prompts) for various batch sizes, showing that QuaRot significantly accelerates the process. The right panel illustrates memory savings during the decoding stage (generating text) for different sequence lengths, highlighting QuaRot’s efficiency in reducing memory consumption. Both panels demonstrate QuaRot’s effectiveness in improving both speed and efficiency of LLMs.
read the caption
Figure 4: Performance of the QuaRot kernel on a single transformer block of LLAMA-2 models using NVIDIA RTX 3090 GPU. Left: For the speedup results, we evaluate using sequence length 2048 with different batch sizes. Right: Peak memory saving during decoding of 50 tokens with different prefill sequence lengths using batch size 16.
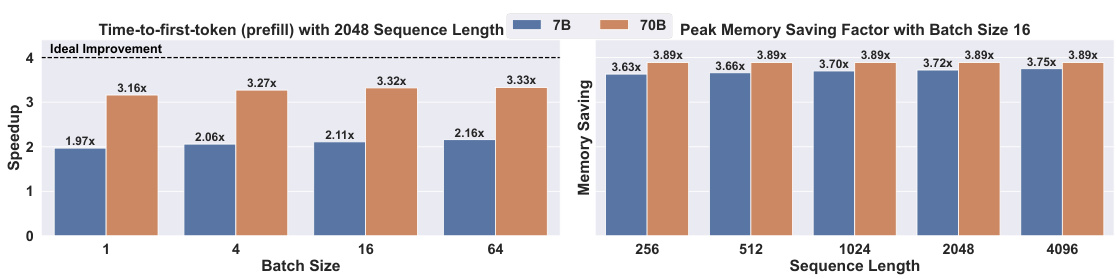
🔼 This figure shows a flow diagram of a self-attention block, a common component in large language models (LLMs). It details the flow of information during training, pre-filling, and inference. Key elements highlighted include the RMSNorm, query (Wq), key (Wk), value (Wv) projections, the RoPE (Rotary Positional Embedding) mechanism, the multi-head attention operation itself, and the KV cache. The solid arrows represent the main flow during each stage, whereas the dashed arrows illustrate the interactions with the KV cache, particularly during the generation phase.
read the caption
Figure 5: Flow diagram of a self-attention block as used in most LMs, including the pre-positioned RMSNorm. Solid arrows represent flow during training, prefill and inference of each token. Dashed arrows show access to and from the KV cache, used at generation-time. The RoPE block computes relative positional embeddings.

🔼 This figure illustrates the QuaRot method applied to the attention component of a transformer network. It shows how the input hidden state is rotated using a Hadamard matrix (Q), and how this rotation is absorbed into the weight matrices to maintain computational invariance. The figure highlights the quantization of weights, activations, and the KV cache to 4 bits, showcasing the flow of data through the attention mechanism. The dashed lines indicate the interaction with the KV cache.
read the caption
Figure 6: QuaRot applied to an attention component. The RMSNorm scaling a is absorbed into the input weight matrices, and the hidden state has been rotated by Q in the same way as for the FFN block (see previous figure). Colored labels show the bit-width of each flow, and dashed lines show the flow to/from the KV cache.
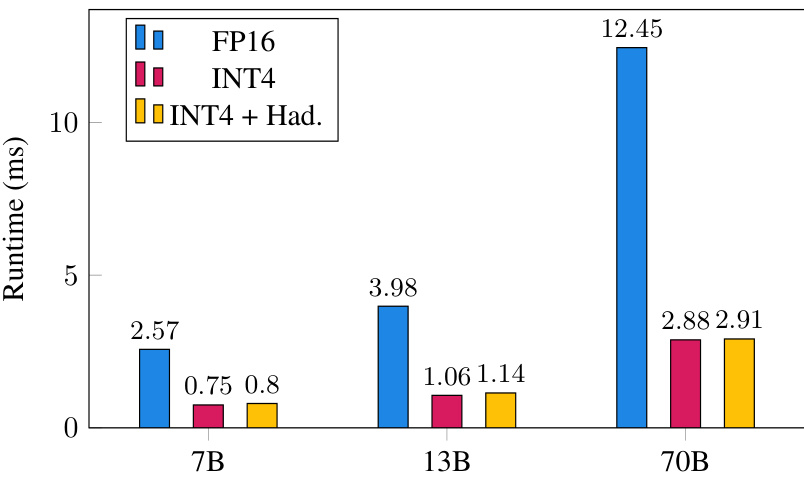
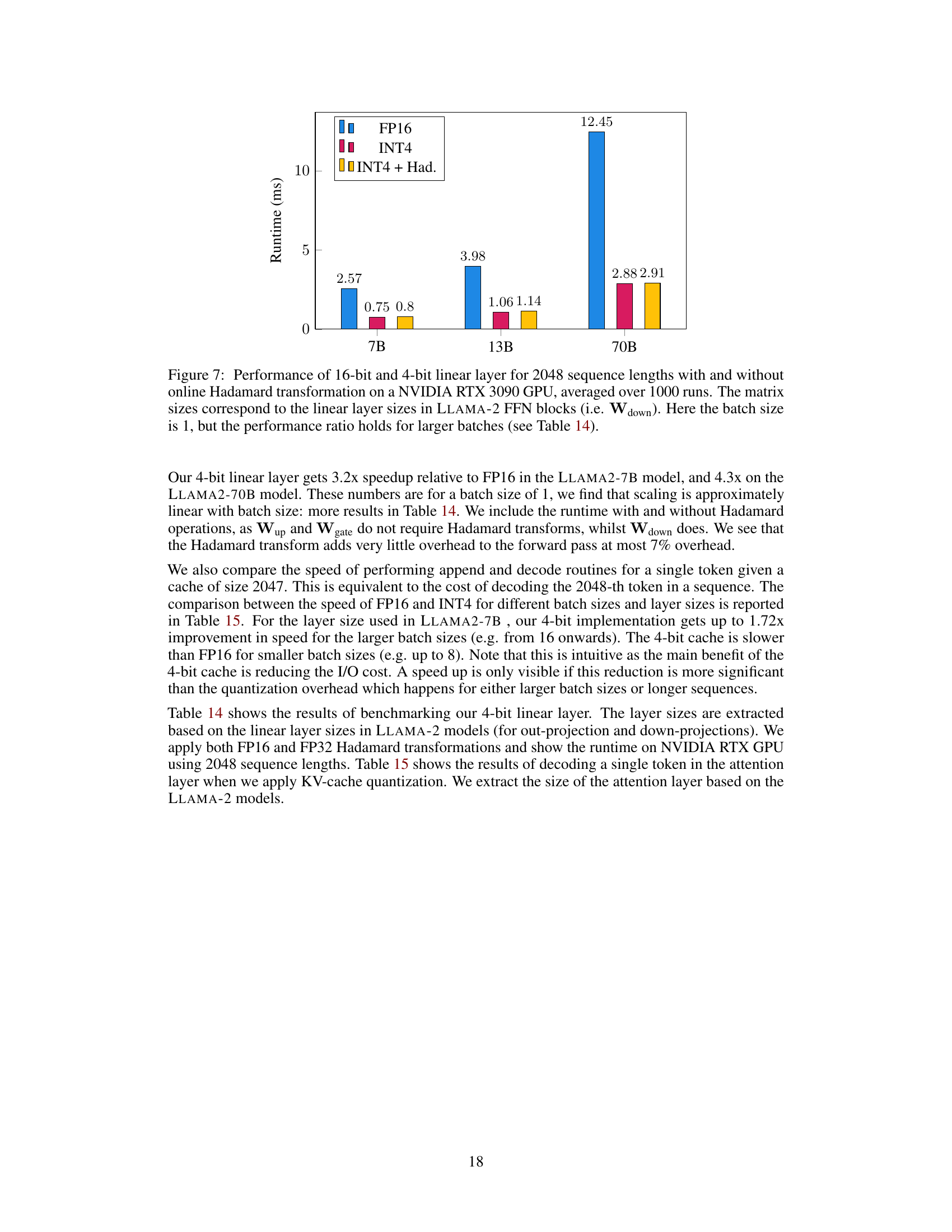
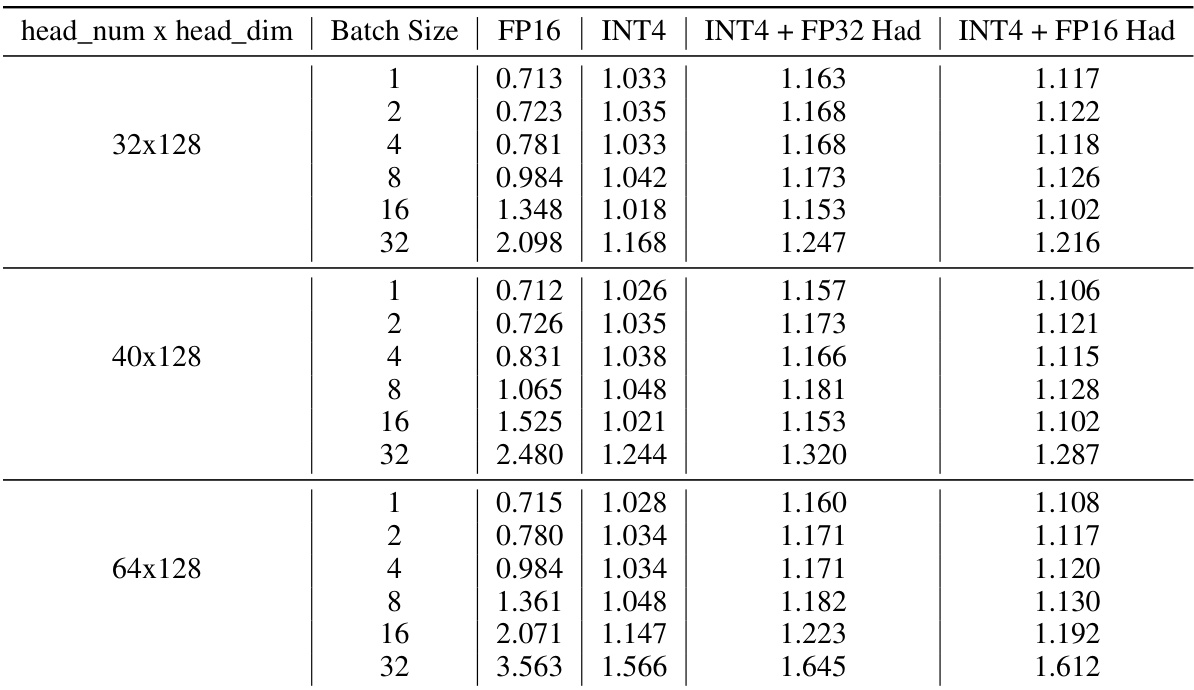
🔼 This figure compares the performance of 16-bit and 4-bit linear layers with and without online Hadamard transformations for different LLAMA-2 model sizes (7B, 13B, and 70B parameters). The runtime is measured in milliseconds and averaged over 1000 runs with a batch size of 1. The results show significant speedup with 4-bit quantization, especially for larger models.
read the caption
Figure 7: Performance of 16-bit and 4-bit linear layer for 2048 sequence lengths with and without online Hadamard transformation on a NVIDIA RTX 3090 GPU, averaged over 1000 runs. The matrix sizes correspond to the linear layer sizes in LLAMA-2 FFN blocks (i.e. Wdown). Here the batch size is 1, but the performance ratio holds for larger batches (see Table 14).
More on tables
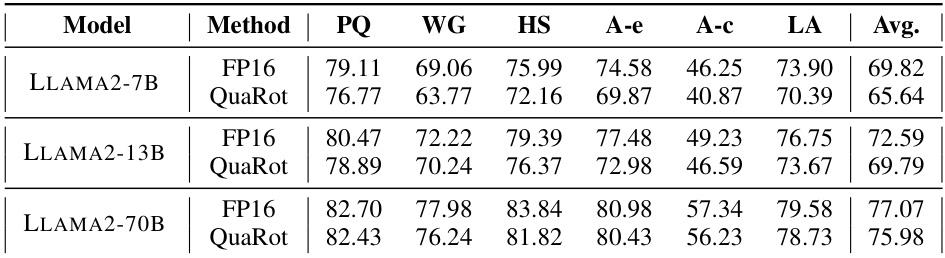
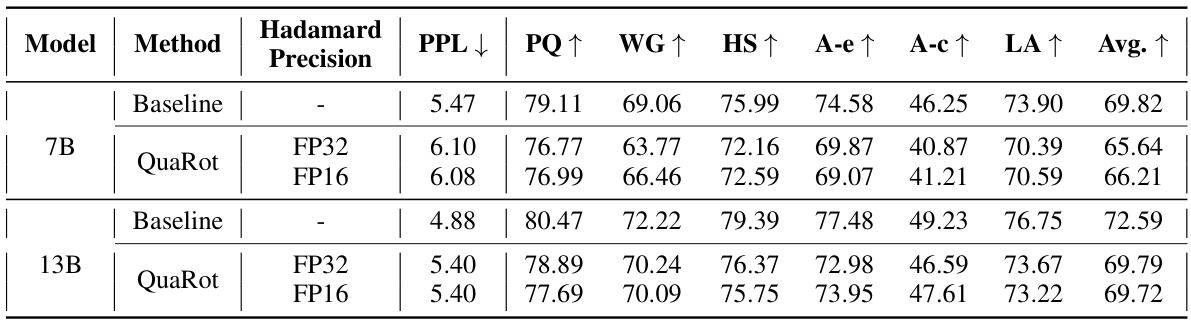
🔼 This table presents the zero-shot accuracy results of LLAMA-2 models (7B, 13B, and 70B parameters) that use QuaRot for 4-bit quantization (weights, activations, and KV cache). The accuracy is measured across six different zero-shot tasks: PIQA, WinoGrande, HellaSwag, Arc-Easy, Arc-Challenge, and LAMBADA. The table compares the accuracy of the quantized models (QuaRot) to the original, full-precision models (FP16).
read the caption
Table 2: Zero-shot accuracy of LLAMA-2 models with 4-bit (A4W4KV4) QuaRot on PIQA (PQ), WinoGrande (WG), HellaSwag (HS), Arc-Easy (A-e), Arc-Challenge (A-c), and LAMBADA (LA).

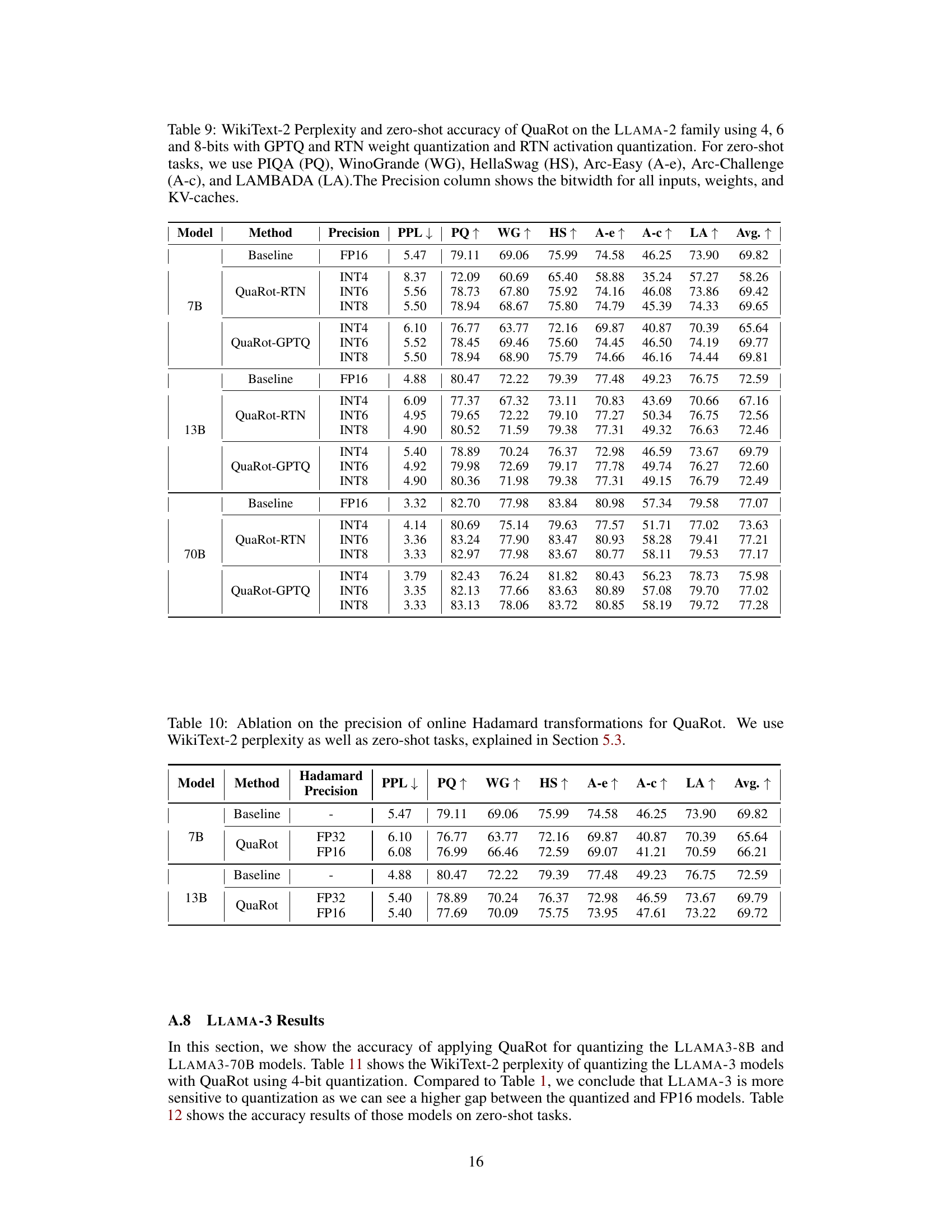
🔼 This table presents the results of QuaRot using 4 and 8 bits with round-to-nearest quantization for weights and activations on the LLAMA-2 family of models. It shows the WikiText-2 perplexity and zero-shot accuracy on six different tasks: PIQA, WinoGrande, HellaSwag, Arc-Easy, Arc-Challenge, and LAMBADA. All weights, activations, and caches are quantized.
read the caption
Table 3: WikiText-2 Perplexity and zero-shot accuracy of QuaRot on the LLAMA-2 family using 4- and 8-bits with Round-to-Nearest (RTN) weights and activation quantization. For zero-shot tasks, we use PIQA (PQ), WinoGrande (WG), HellaSwag (HS), Arc-Easy (A-e), Arc-Challenge (A-c), and LAMBADA (LA). We quantize all weights, activations, and caches.
🔼 This table presents the WikiText-2 perplexity scores achieved by various 4-bit quantization methods on LLAMA-2 models with a sequence length of 2048. It compares QuaRot’s performance against SmoothQuant and OmniQuant, highlighting QuaRot’s ability to quantize all weights, activations, and KV caches to 4 bits without significant performance loss. The table also includes results using group-wise quantization with different group sizes (128G).
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.

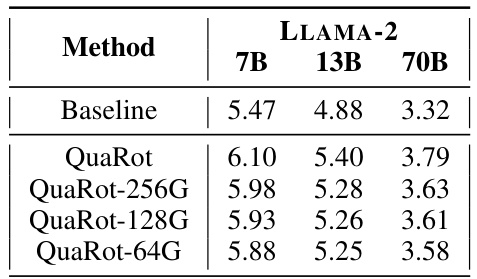
🔼 This table presents the WikiText-2 perplexity scores achieved by QuaRot when using different bit precisions for the key (K bits) and value (V bits) components of the KV cache. The results are shown for three different LLAMA-2 models (7B, 13B, and 70B parameters). The table demonstrates how the model’s performance varies depending on the bit precision allocated to the keys and values in the KV cache, highlighting the trade-off between model accuracy and memory efficiency.
read the caption
Table 6: WikiText-2 perplexity with various KV cache precision using QuaRot.
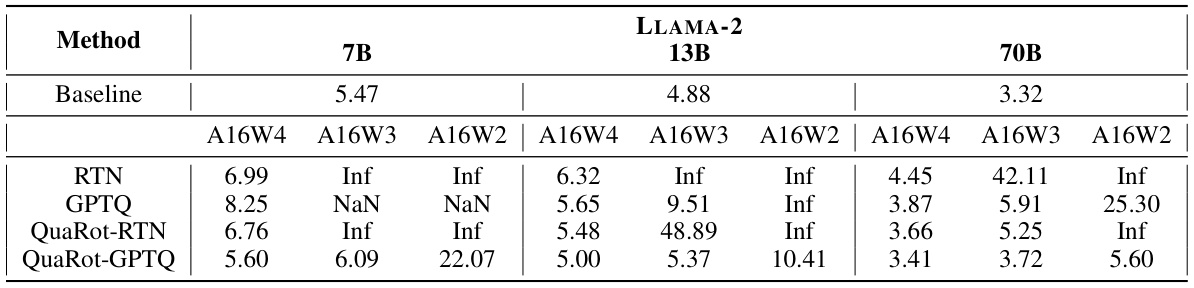
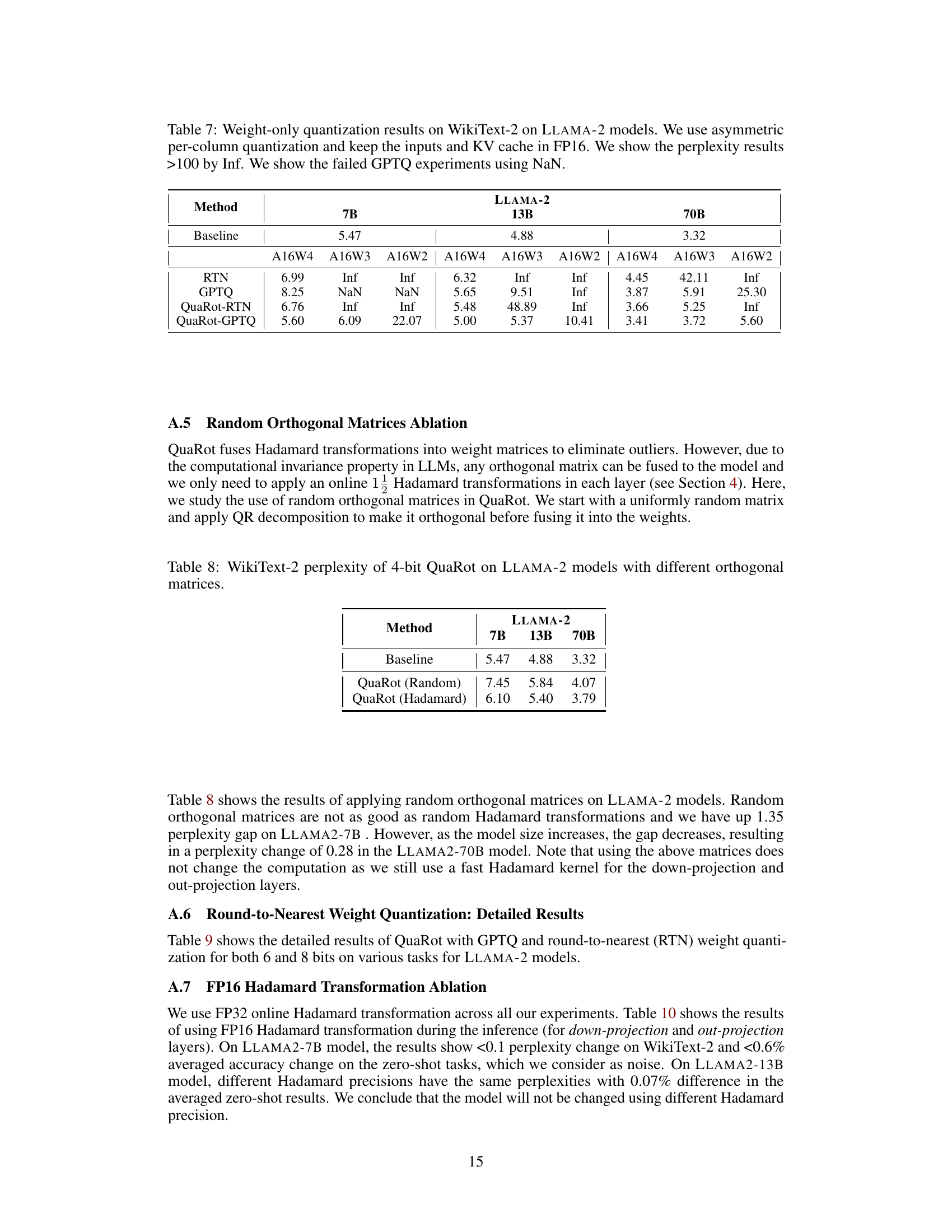
🔼 This table presents the results of applying weight-only quantization methods (RTN and GPTQ) to LLAMA-2 models of varying sizes (7B, 13B, and 70B parameters). It shows the WikiText-2 perplexity achieved with different quantization bit-widths (A16W4, A16W3, A16W2 representing 16-bit activations and 4, 3, and 2-bit weights, respectively). The results showcase the impact of QuaRot on the performance of weight-only quantization, demonstrating improved perplexity compared to standard RTN and GPTQ in several configurations.
read the caption
Table 7: Weight-only quantization results on WikiText-2 on LLAMA-2 models. We use asymmetric per-column quantization and keep the inputs and KV cache in FP16. We show the perplexity results >100 by Inf. We show the failed GPTQ experiments using NaN.
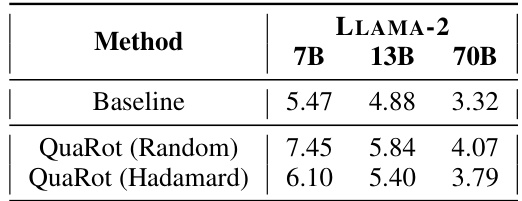
🔼 This table presents the results of applying random orthogonal matrices instead of Hadamard matrices in QuaRot for 4-bit quantization on LLAMA-2 models of various sizes. It compares the perplexity scores achieved using random orthogonal matrices against those obtained using Hadamard matrices, highlighting the impact of matrix choice on model performance.
read the caption
Table 8: WikiText-2 perplexity of 4-bit QuaRot on LLAMA-2 models with different orthogonal matrices.

🔼 This table compares the performance of QuaRot against other 4-bit quantization methods on the WikiText-2 language modeling benchmark, using LLAMA-2 models of various sizes (7B, 13B, and 70B parameters). It shows the perplexity scores achieved by each method, highlighting QuaRot’s superior performance with minimal loss compared to the baseline, even without needing to identify and retain outlier features in higher precision. Group-wise quantization results are also included for comparison.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
🔼 This table presents a comparison of different quantization methods on the WikiText-2 language modeling task using LLAMA-2 models. The models are quantized to 4 bits, and the table shows the resulting perplexity scores. The comparison includes baseline performance, SmoothQuant, OmniQuant, and QUIK, highlighting the performance of QuaRot with and without group-wise quantization.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.

🔼 This table presents the WikiText-2 perplexity results for different quantization methods applied to LLAMA-3 models. The models used 2048 sequence lengths. The baseline results are compared against QuaRot and QuaRot-128G which uses group-wise quantization with a group size of 128. The table shows the impact of different quantization techniques on model performance for both 8B and 70B parameter models.
read the caption
Table 11: WikiText-2 perplexity results on 4-bit quantization of LLAMA-3 models with 2048 sequence length. 128G shows the group-wise quantization with group size 128.

🔼 This table presents the zero-shot accuracy results for LLAMA-3 models (8B and 70B parameters) after applying the QuaRot quantization method. The accuracy is measured across six different tasks: PIQA, WinoGrande, HellaSwag, Arc-Easy, Arc-Challenge, and LAMBADA. The table compares the performance of the original FP16 models to the performance after applying QuaRot quantization.
read the caption
Table 12: Zero-shot accuracy of LLAMA-3 models with 4-bit QuaRot on PIQA (PQ), WinoGrande (WG), HellaSwag (HS), Arc-Easy (A-e), Arc-Challenge (A-c), and LAMBADA (LA).
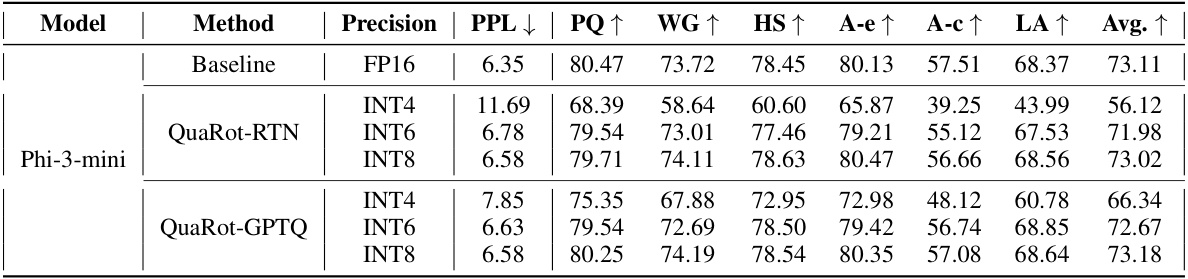
🔼 This table presents a comparison of different quantization methods on the WikiText-2 benchmark using LLAMA-2 models with a sequence length of 2048 tokens. It shows the perplexity achieved by various methods, including the proposed QuaRot method, SmoothQuant, OmniQuant, and QUIK. The table highlights the impact of different quantization techniques and the elimination of outlier features on model performance. The ‘Outlier Features’ column refers to the number of features retained in higher precision to accommodate outliers.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.

🔼 This table presents a comparison of different 4-bit quantization methods on the WikiText-2 dataset using LLAMA-2 models. It shows the perplexity scores achieved by various methods, including SmoothQuant and OmniQuant, comparing the number of outlier features retained at higher precision. The table highlights QuaRot’s performance, demonstrating its ability to achieve low perplexity with no outlier features retained.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
🔼 This table compares the performance of QuaRot against other state-of-the-art 4-bit quantization methods on the WikiText-2 benchmark using LLAMA-2 models. It shows the perplexity scores achieved by different methods, highlighting QuaRot’s superior performance with minimal loss compared to the baseline (full precision). The table also includes results for group-wise quantization, demonstrating QuaRot’s effectiveness across various quantization strategies.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
🔼 This table compares the performance of QuaRot against other state-of-the-art 4-bit quantization methods on the WikiText-2 language modeling benchmark using LLAMA-2 models of varying sizes (7B, 13B, and 70B parameters). It shows the perplexity scores achieved, highlighting QuaRot’s superior performance with minimal loss in accuracy compared to methods that require keeping outlier features in higher precision or those using other quantization techniques.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128.Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
🔼 This table presents the results of 4-bit quantization experiments on the LLAMA-2 language model using different quantization methods, including QuaRot, SmoothQuant, and OmniQuant. The models are evaluated on the WikiText-2 dataset using a sequence length of 2048. The table compares the perplexity scores (a measure of the model’s accuracy) achieved by each method and highlights the impact of outlier feature handling on the results. The group-wise quantization results (128G) demonstrate the effect of varying group sizes on model performance. QuaRot’s performance is particularly emphasized due to its capability of quantizing all weights, activations, and KV caches in 4-bits.
read the caption
Table 1: WikiText-2 perplexity results on 4-bit quantization of LLAMA-2 models with 2048 sequence length. We extract the results for SmoothQuant and OmniQuant results of [Shao et al., 2023]. 128G shows the group-wise quantization with group size 128. Here, we quantize all weights, activations, and caches in 4-bits in QuaRot.
Full paper#