TL;DR#
Vision-language models (VLMs) like CLIP struggle with domain shifts, often requiring costly labeled data for adaptation. This paper tackles this challenge by focusing on unsupervised multi-domain learning, where abundant unlabeled data spanning multiple domains is used to enhance VLM transferability. The authors observe inherent biases in CLIP’s visual and text encoders, where the visual encoder prioritizes domain over category information, and the text encoder shows a preference for domain-relevant classes. This leads to varied performance across different domains.
To address these issues, the paper proposes UMFC (Unsupervised Multi-domain Feature Calibration), a training-free and label-free method. UMFC calibrates both image and text features by estimating and removing domain-specific biases. Evaluated across various settings (unsupervised calibration, transductive learning, test-time adaptation), UMFC consistently outperforms CLIP and achieves state-of-the-art performance on par with methods requiring additional annotations or optimization. The method’s efficiency makes it highly practical for real-world scenarios with abundant unlabeled multi-domain data but limited labels.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with vision-language models due to its novel approach to improving model generalizability. It addresses the prevalent issue of domain shift, offering a training-free solution that is both cost-effective and efficient. The findings are relevant to numerous downstream applications and open up new avenues for research, especially in unsupervised domain adaptation and test-time adaptation. The proposed methodology and results have significant implications for developing more robust and adaptable vision-language systems.
Visual Insights#

🔼 This figure visualizes CLIP’s performance and inherent bias across different domains of the DomainNet dataset. Panel (a) shows the accuracy of CLIP across six different domains (clipart, infograph, painting, quickdraw, real, sketch), highlighting significant performance variations across domains even within the same class. Panel (b) displays a t-SNE visualization of image features extracted by CLIP’s image encoder, revealing that features from the same domain cluster together, indicating domain bias. Finally, panel (c) shows the distribution of predictions for several classes in the ‘quickdraw’ and ‘painting’ domains, demonstrating that CLIP’s textual encoder shows a domain-specific preference for certain classes.
read the caption
Figure 1: On DomainNet dataset, we visualize (a) The accuracy of CLIP on the six domains. (b) The image features extracted by CLIP's image encoder across different domains. The visualization show that CLIP exhibits inherent model bias. (c) The number of predictions for different classes on quickdraw and painting domains.
🔼 This table presents the results of different methods on the DomainNet dataset under unsupervised multi-domain calibration. It compares the performance of zero-shot CLIP (with fixed and ensemble prompts) and domain-specific prompts with methods using labeled data (CoOp and CLIP-Adapter). The results show the average accuracy across six different domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch) and highlight the performance improvement of the proposed UMFC method.
read the caption
Table 1: Results on DomainNet under multi-domain Unsupervised Calibration. CLIP denotes zero-shot CLIP with a fixed text prompt template 'a photo of a [class]', CLIP-E uses the ensemble prompt templates designed for Imagenet [39], CLIP-D uses the domain-specific templates, i.e., “a [domain] image of [class]”. CoOp and CLIP-Adapter are trained on multi-domain labeled data, e.g., 6 × 1 × 345 denotes the number of labeled data.
In-depth insights#
UMFC: Model Bias#
The heading ‘UMFC: Model Bias’ suggests an analysis of biases inherent within the Unsupervised Multi-domain Feature Calibration (UMFC) method itself. A thoughtful exploration would examine if UMFC, designed to mitigate biases in vision-language models like CLIP, introduces new biases or amplifies existing ones. The analysis would need to identify what types of biases UMFC might exhibit, such as a preference for certain domains or categories of data during calibration. It would also be crucial to evaluate how the calibration process affects different types of input data and whether it leads to equitable performance across various demographics or image styles. Ultimately, a discussion of UMFC’s model biases should assess whether the approach successfully achieves its goal of unbiased feature representation or if it inadvertently produces other undesirable biases, highlighting its limitations and potential areas for improvement.
Feature Calibration#
Feature calibration, in the context of vision-language models, addresses the problem of domain shift, where a model trained on one data distribution performs poorly on another. The core idea is to adjust the model’s internal feature representations to be less sensitive to domain-specific characteristics and more focused on the underlying semantic content. This often involves training-free methods, which are computationally efficient, operating on existing pre-trained models without requiring further training data. Successful calibration techniques leverage unlabeled multi-domain data, identifying and mitigating biases in visual and textual encoders. This commonly involves estimating domain-specific biases from the features and subtracting them to obtain domain-invariant representations. A key challenge lies in effectively disentangling domain-specific information from class-discriminative information, which necessitates clever techniques that work without supervision. The impact is significant, enabling pre-trained models to generalize to new domains without needing costly and time-consuming fine-tuning.
Multi-Domain Tests#
A hypothetical ‘Multi-Domain Tests’ section in a research paper would likely explore the model’s performance across diverse datasets and scenarios. This is crucial for assessing generalization ability, a key metric for robust AI. The section should detail the specific datasets used, highlighting their differences in terms of image style, object diversity, and annotation quality. Quantitative results, such as accuracy, precision, and recall, should be presented for each domain, ideally with statistical significance measures. A comparative analysis of performance across domains would reveal potential biases or limitations, enabling a deeper understanding of the model’s strengths and weaknesses. The paper should also delve into qualitative observations, examining whether the error types differ significantly across domains, indicating domain-specific challenges. A thorough analysis, ideally including visualization of model outputs across various domains, would be beneficial. Finally, any domain adaptation techniques, and their effectiveness if applied, should be carefully evaluated.
Ablation Study#
An ablation study systematically removes components of a model or system to determine their individual contributions. In the context of a research paper, an ablation study on a machine learning model might involve removing layers from a neural network, disabling regularization techniques, or altering training data parameters. The goal is to isolate the effects of specific features and quantify their impact on the overall performance. A well-executed ablation study provides strong evidence for the necessity of particular design choices or techniques by showing a clear performance drop when they are removed. It strengthens the paper’s claims by demonstrating that improvements are not due to coincidental factors but result from the deliberate inclusion of the studied components. Conversely, if removing a component results in minimal impact, it suggests that particular component may be redundant and could potentially be simplified or removed to improve efficiency or reduce complexity. A detailed ablation study often involves multiple iterations, progressively removing and modifying different aspects of the model. This systematic approach is crucial for understanding the intricate workings of complex systems, helping to isolate the contribution of individual components and paving the way for improved designs and architectures in future work. Robust ablation studies are crucial for the credibility and reproducibility of the results.
Future of UMFC#
The future of UMFC (Unsupervised Multi-Domain Feature Calibration) appears bright, given its demonstrated ability to enhance the transferability of vision-language models without relying on labeled data. Future research could focus on improving the calibration process itself, perhaps by exploring more sophisticated clustering algorithms or incorporating domain-specific knowledge to refine bias estimation. Extending UMFC to other multimodal models, beyond vision-language, is another promising avenue. The method’s current reliance on clustering for domain identification might be improved using more nuanced techniques sensitive to subtle distributional shifts. Investigating the impact of different pre-training schemes and architectures on UMFC’s performance would further solidify its robustness and generalization capabilities. Finally, exploring applications in more complex downstream tasks, such as visual question answering, image captioning, and visual reasoning, would demonstrate UMFC’s real-world applicability and pave the way for broader adoption within the field of computer vision and natural language processing.
More visual insights#
More on figures

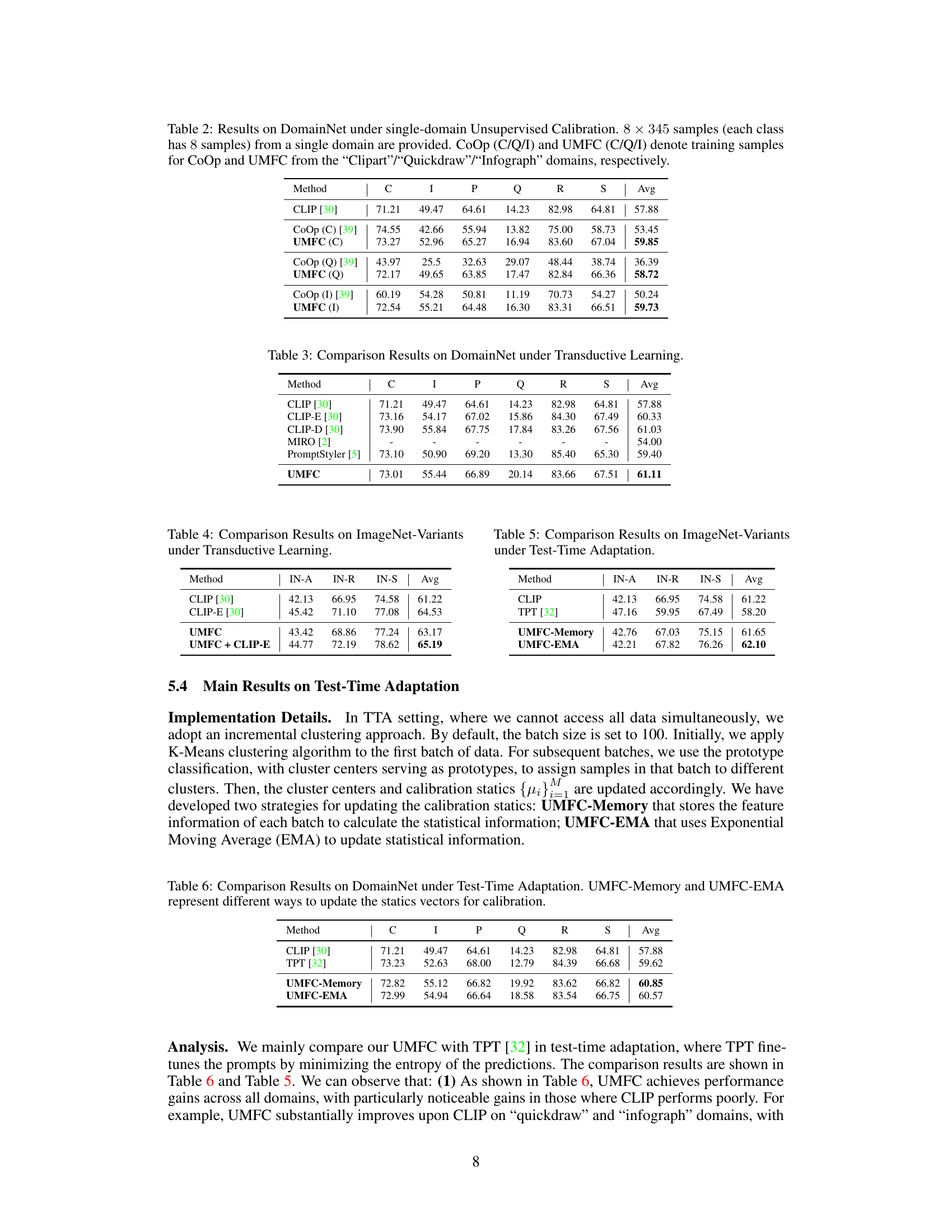
🔼 This figure shows the results of the proposed UMFC method. (a) is a t-SNE visualization of image features extracted by UMFC image encoder from different domains. It shows that UMFC successfully reduces the domain bias by aligning image feature distributions from different domains. (b) shows the classification probabilities of CLIP’s text features on different domains, comparing the uniform distribution, original CLIP and the calibrated CLIP by UMFC. It shows that UMFC also successfully reduces the text bias by making class probabilities more uniform across domains.
read the caption
Figure 2: On DomainNet dataset, we visualize (a) The image features extracted by UMFC image encoder across different domains. (b) The classification probabilities of CLIP’s text features on different domains.

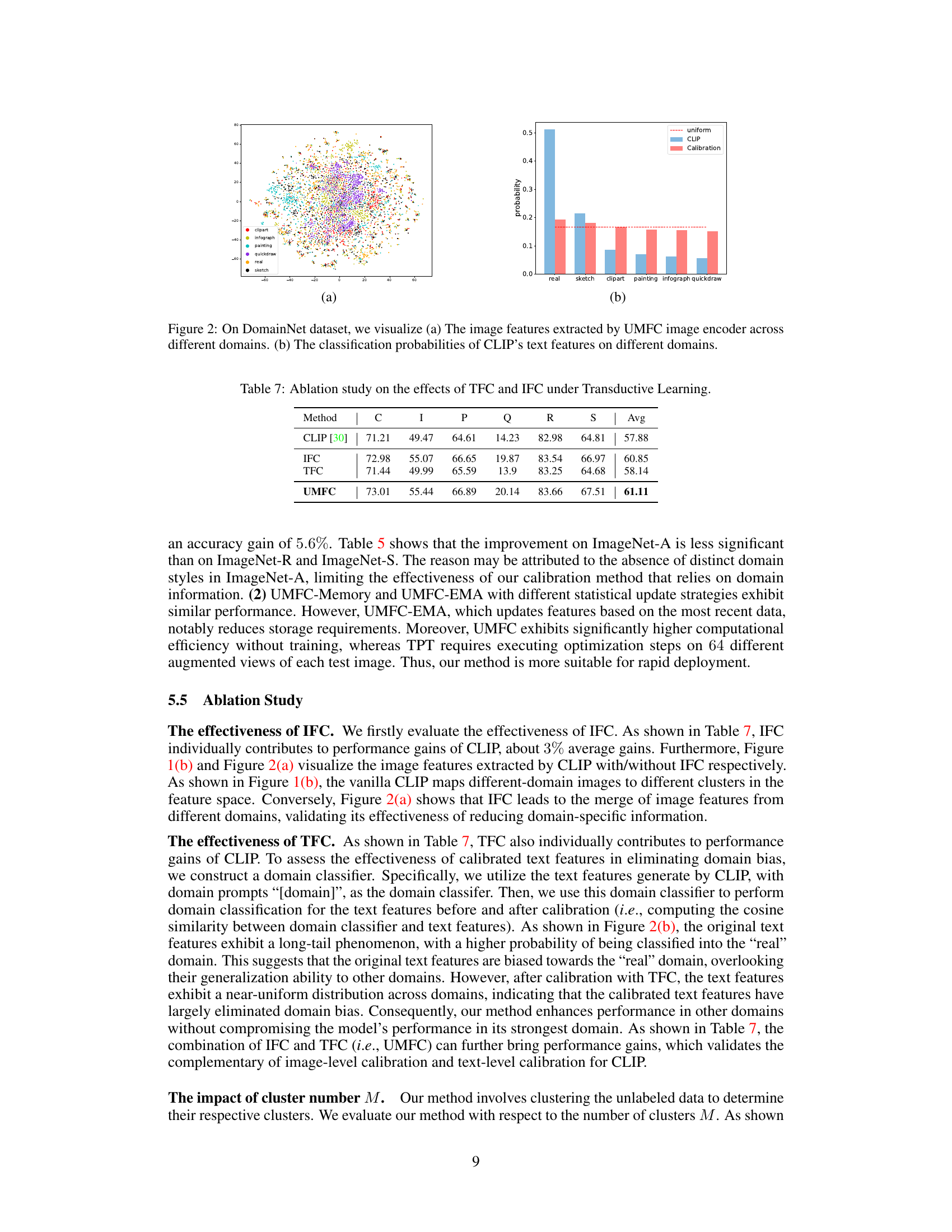
🔼 This figure visualizes image features extracted by various OpenCLIP models, demonstrating that the inherent bias of CLIP is not limited to a specific dataset or model architecture. The top row shows the feature distributions from models pre-trained on different datasets (LAION-80M, 400M, and 2B), while the bottom row shows the feature distributions from models pre-trained on the LAION-2B dataset with varying numbers of images and different model architectures (ViT-B-16 and ViT-B-32). In all cases, features from the same domain cluster together, indicating the domain bias observed in CLIP.
read the caption
Figure 3: Visualization of Image Features based on OpenCLIP series. (a) The OpenCLIP models are pre-trained with three different dataset (LAION-80M, LAION-400M and LAION-2B). (b) The OpenCLIP models are pre-trained on LAION-2B with different number of seen samples (3B, 34B) and architectures (ViT-B-16, ViT-B-32).
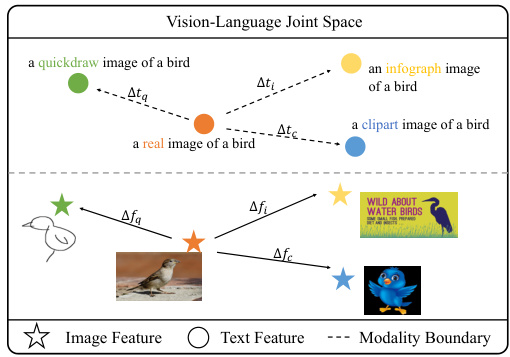
🔼 This figure illustrates the core idea behind the Text Feature Calibration Module in UMFC. It shows that the directional shift between different domains (e.g., from ‘real’ to ‘quickdraw’ images) in the image embedding space is similar to the directional shift in the text embedding space. This observation supports UMFC’s approach of using image features to estimate and counteract bias in text encoders, thereby improving domain generalization.
read the caption
Figure 4: The domain transition direction between texts is similar to that between images.
More on tables

🔼 This table presents the results of unsupervised calibration experiments on the DomainNet dataset. It compares the performance of the proposed UMFC method against the baseline method CoOp when only a limited amount of labeled data from a single domain (Clipart, Quickdraw, or Infograph) is available. The table shows the average accuracy across six domains for each method. The numbers in parentheses following CoOp and UMFC indicate the source domain for the limited training data.
read the caption
Table 2: Results on DomainNet under single-domain Unsupervised Calibration. 8 × 345 samples (each class has 8 samples) from a single domain are provided. CoOp (C/Q/I) and UMFC (C/Q/I) denote training samples for CoOp and UMFC from the 'Clipart'/'Quickdraw'/'Infograph' domains, respectively.
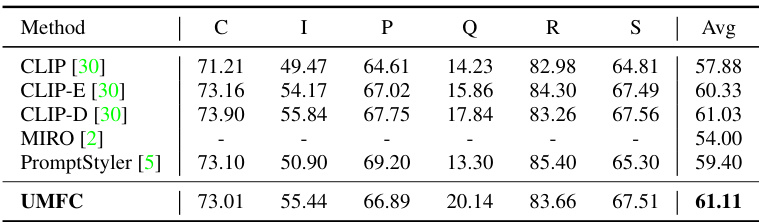
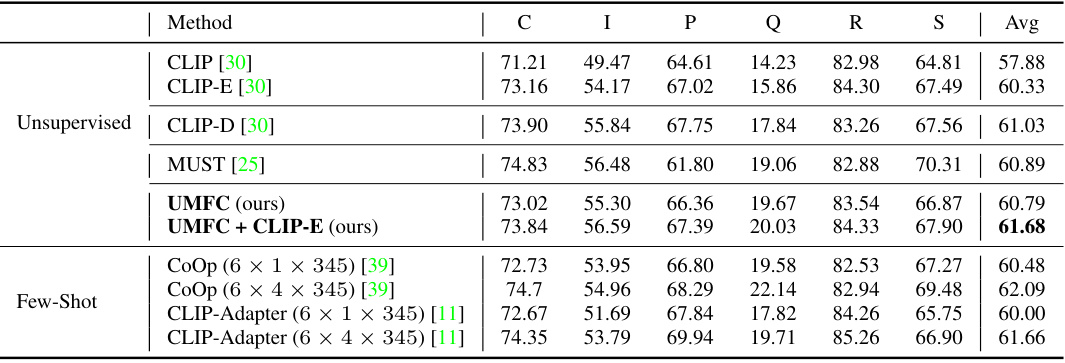
🔼 This table presents the results of multi-domain unsupervised calibration experiments on the DomainNet dataset. It compares the performance of several methods, including the zero-shot CLIP with fixed and ensemble prompts, a domain-specific prompt version, and two few-shot learning approaches (CoOp and CLIP-Adapter). The results are presented as average accuracy across six domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch) and show the impact of unsupervised calibration on improving model generalizability.
read the caption
Table 1: Results on DomainNet under multi-domain Unsupervised Calibration. CLIP denotes zero-shot CLIP with a fixed text prompt template 'a photo of a [class]', CLIP-E uses the ensemble prompt templates designed for Imagenet [39], CLIP-D uses the domain-specific templates, i.e., “a [domain] image of [class]'. CoOp and CLIP-Adapter are trained on multi-domain labeled data, e.g., 6 × 1 × 345 denotes the number of labeled data.

🔼 This table presents the performance comparison of different methods on the ImageNet-Variants dataset under the transductive learning setting. The methods compared are CLIP, CLIP-E (an ensemble of CLIP prompts), UMFC (Unsupervised Multi-domain Feature Calibration), and UMFC combined with CLIP-E. The results are presented as the average accuracy across three ImageNet-Variants subsets: IN-A, IN-R, and IN-S. It demonstrates the effectiveness of UMFC in improving the performance of CLIP-based models on this challenging dataset.
read the caption
Table 4: Comparison Results on ImageNet-Variants under Transductive Learning.
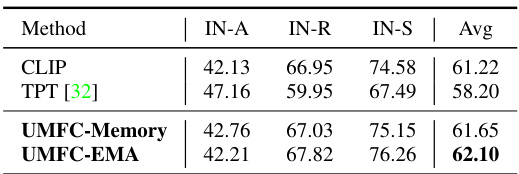
🔼 This table presents the comparison of different methods’ performance on ImageNet-Variants under Test-Time Adaptation setting. It shows the average accuracy across three ImageNet variants (IN-A, IN-R, IN-S) for CLIP, TPT, and two variants of UMFC (UMFC-Memory and UMFC-EMA). The results highlight the performance improvement achieved by UMFC compared to the baseline methods.
read the caption
Table 5: Comparison Results on ImageNet-Variants under Test-Time Adaptation.
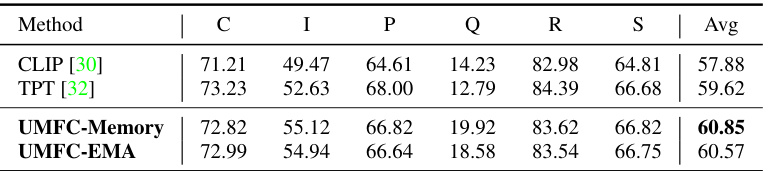
🔼 This table presents the results of the Test-Time Adaptation experiments on the DomainNet dataset. It compares the performance of CLIP, TPT, and two variants of the UMFC method (UMFC-Memory and UMFC-EMA) across six domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch). The key difference between UMFC-Memory and UMFC-EMA lies in how they update the statistical information used for calibration. The table shows that both UMFC methods achieve higher accuracy than CLIP and TPT, indicating that the proposed calibration method is effective in adapting to the test-time setting even when data arrives in batches.
read the caption
Table 6: Comparison Results on DomainNet under Test-Time Adaptation. UMFC-Memory and UMFC-EMA represent different ways to update the statics vectors for calibration.

🔼 This table presents the ablation study results on the effects of the Text Feature Calibration (TFC) and Image Feature Calibration (IFC) modules under the transductive learning setting. It shows the performance of CLIP, IFC only, TFC only, and UMFC (combining both IFC and TFC) across different domains (C, I, P, Q, R, S) of the DomainNet dataset. The average accuracy across all domains is also provided for each method, demonstrating the individual and combined impact of IFC and TFC on the overall performance.
read the caption
Table 7: Ablation study on the effects of TFC and IFC under Transductive Learning.

🔼 This table presents the results of the UMFC method on the DomainNet dataset under the transductive learning setting. It shows how the average accuracy varies across six different domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch) as the number of clusters (M) used in the UMFC algorithm is changed. The purpose is to demonstrate the robustness of the UMFC method to the choice of the hyperparameter M.
read the caption
Table 8: The impact of cluster number M on DomainNet under Transductive Learning.
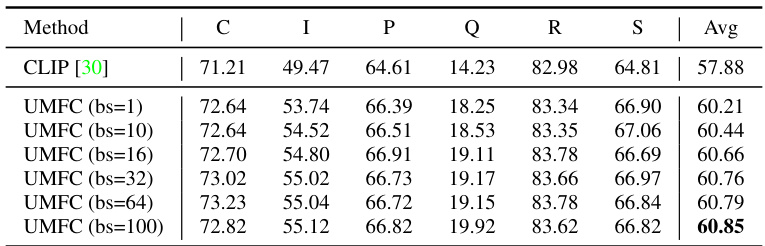
🔼 This table shows the performance comparison of different methods on the DomainNet dataset under the test-time adaptation setting. It compares the performance of CLIP, TPT, UMFC-Memory, and UMFC-EMA across six different domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch). UMFC-Memory and UMFC-EMA are two different variations of the UMFC algorithm, distinguished by how they update their statistical vectors during the calibration process. The table highlights the effectiveness of UMFC in adapting to new data without requiring training, demonstrating improvement over CLIP and TPT in most domains.
read the caption
Table 6: Comparison Results on DomainNet under Test-Time Adaptation. UMFC-Memory and UMFC-EMA represent different ways to update the statics vectors for calibration.
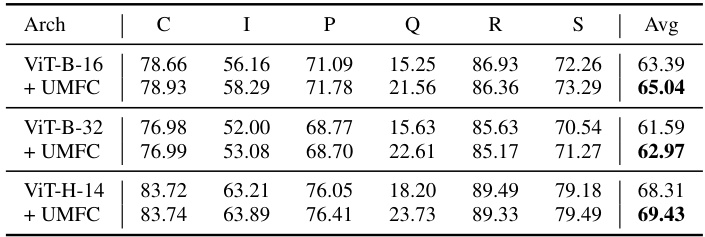
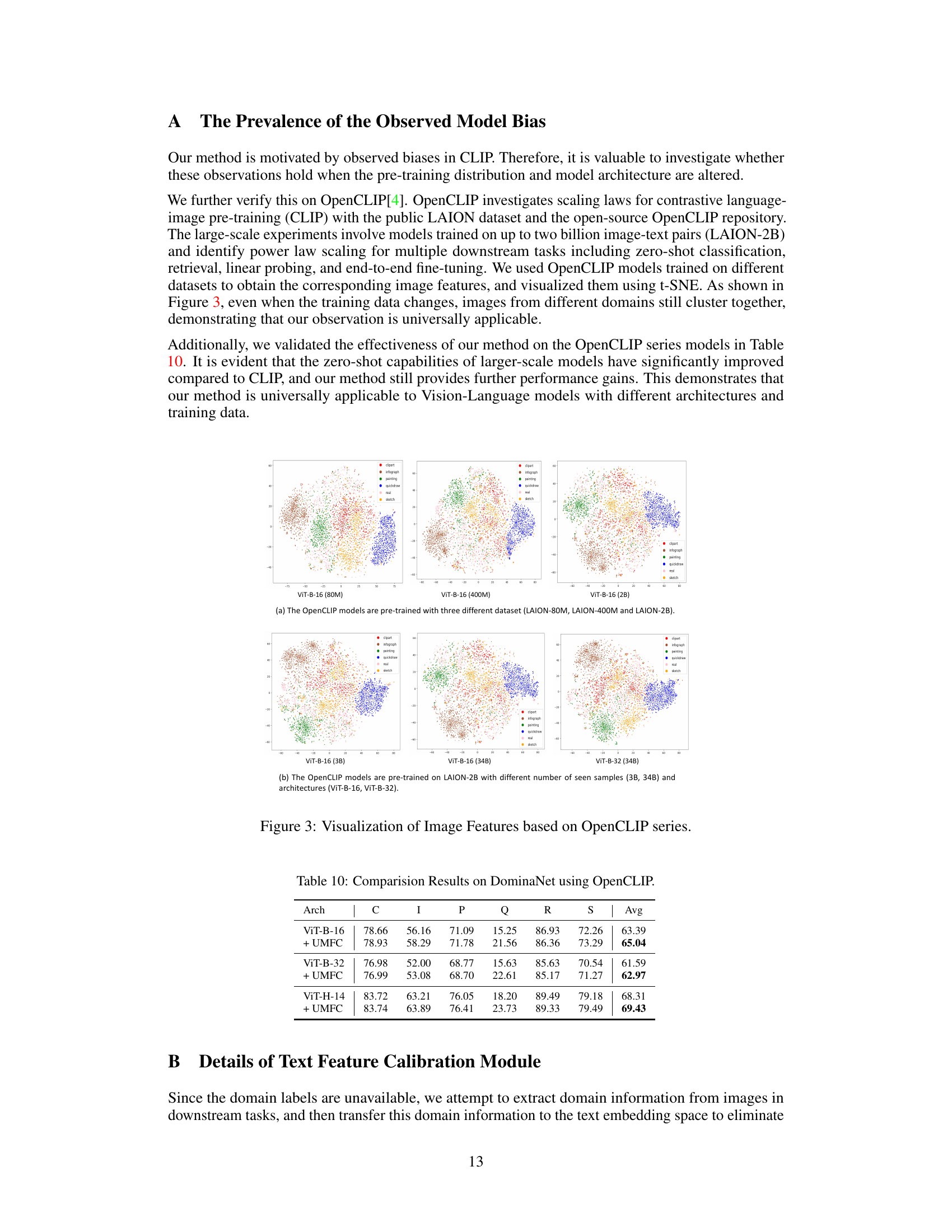
🔼 This table presents the comparison results on the DomainNet dataset using OpenCLIP models with different architectures (ViT-B-16, ViT-B-32, ViT-H-14). For each architecture, the table shows the average accuracy across six domains (Clipart, Infograph, Painting, Quickdraw, Real, Sketch) before and after applying the UMFC method. The results demonstrate the improvement in accuracy achieved by UMFC across various architectures, highlighting its generalizability and effectiveness.
read the caption
Table 10: Comparision Results on DominaNet using OpenCLIP.
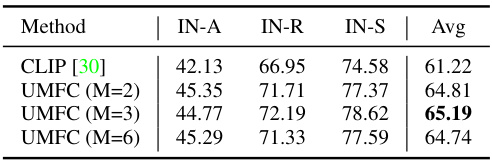
🔼 This table presents the results of the UMFC method on the ImageNet-Variants dataset under the transductive learning setting. It shows the impact of varying the number of clusters (M) used in the clustering algorithm on the performance of the model. The performance is evaluated across three subsets of ImageNet-Variants (IN-A, IN-R, and IN-S) and an average across the three. The table shows that the performance of the model is relatively stable across different numbers of clusters, suggesting that the method is robust to the choice of this hyperparameter.
read the caption
Table 11: The impact of cluster number M on ImageNet-Variants under Transductive Learning.
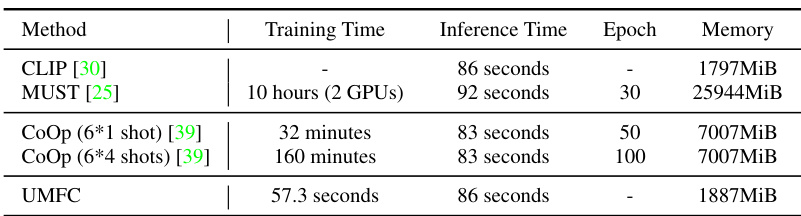
🔼 This table compares the training time, inference time, number of epochs, and memory usage of different methods under the transductive learning setting. It shows that UMFC has significantly lower computational costs compared to other methods like CLIP, MUST, and CoOp, making it a more efficient approach.
read the caption
Table 12: Computation Cost under Transductive Learning.

🔼 This table compares the computation cost (inference time and memory usage) of the proposed UMFC method and the baseline TPT method in the Test-Time Adaptation (TTA) setting. UMFC shows significantly lower inference time and memory consumption.
read the caption
Table 13: Computation Cost under Test-Time Adaptation.
Full paper#