↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning (RL) faces challenges in efficiently solving unseen, long-horizon tasks involving multiple subtasks. Existing pre-training methods often require extensive interactions to adapt to new tasks. This paper introduces MGPO, a method that uses pre-trained transformer-based policies to model sequences of goals. MGPO’s pre-training phase uses hindsight multi-goal relabeling and behavior cloning to enable modeling of diverse, long-horizon behaviors. This efficient online adaptation is achieved through prompt optimization, where the goal sequence (prompt) is optimized to improve task performance.
MGPO uses a multi-armed bandit framework to enhance prompt selection based on online trajectory returns. Experiments across diverse environments show MGPO’s significant advantages in sample efficiency, online adaptation, robustness, and interpretability compared to existing methods. This highlights the potential for efficient online adaptation in various real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach to online adaptation in reinforcement learning, a critical challenge in the field. MGPO significantly improves sample efficiency and online adaptation performance compared to existing methods, opening new avenues for research in long-horizon tasks and complex real-world applications. Its interpretability and robustness also address limitations of current techniques, making it a valuable contribution.
Visual Insights#
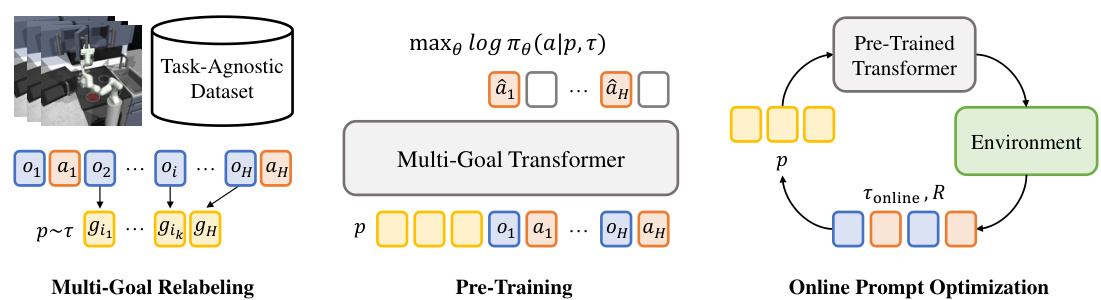
This figure illustrates the MGPO (Multi-Goal Transformers with Prompt Optimization) framework. The left side shows the pre-training phase where a multi-goal transformer is trained on a task-agnostic dataset using a technique called hindsight multi-goal relabeling. This process generates diverse goal sequences from existing trajectories. The middle section details the pre-training of the multi-goal transformer, which learns to map goal sequences (prompts) to action sequences. Finally, the right side depicts the online adaptation phase, where the prompt (goal sequence) is optimized using an online prompt optimization method to maximize returns in a new, unseen task.

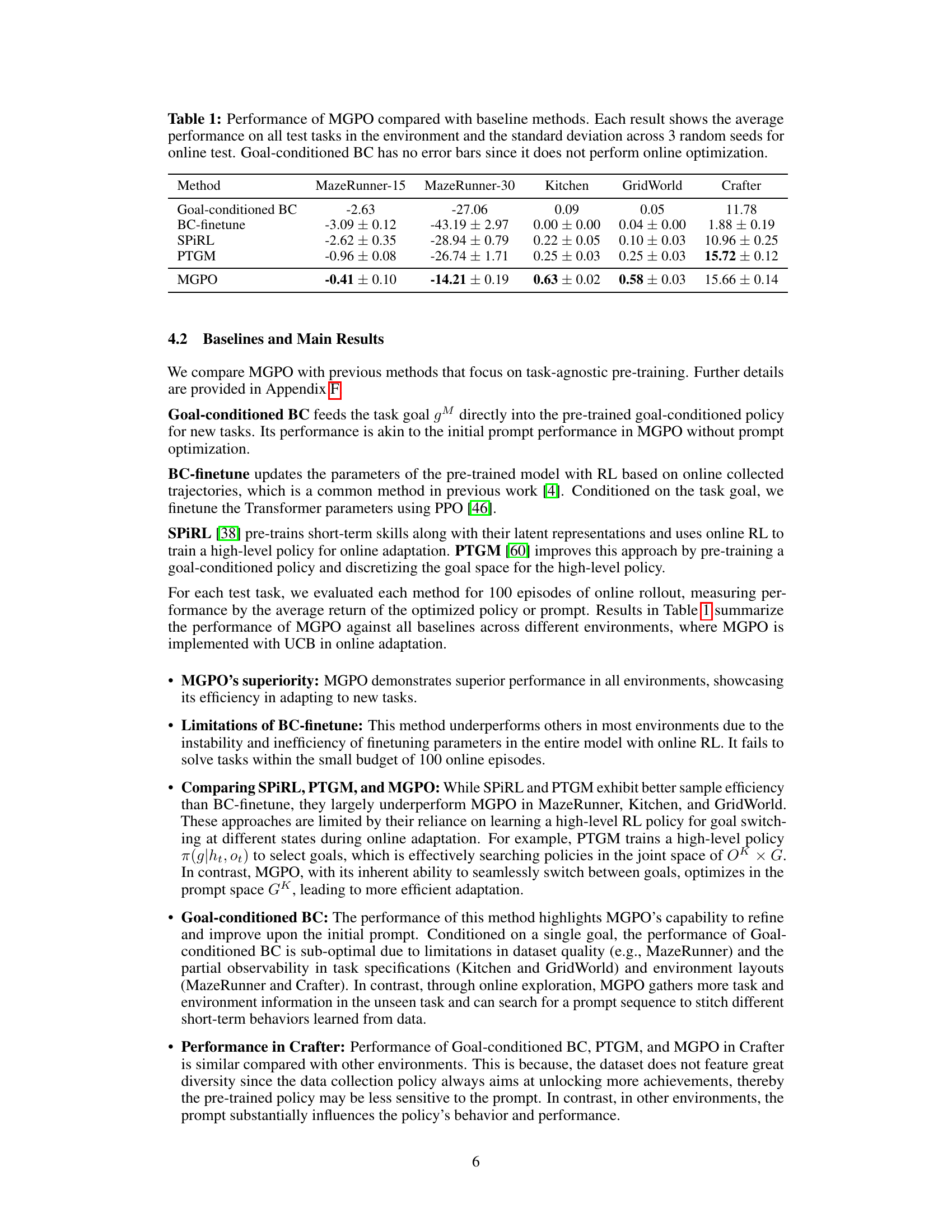
This table compares the performance of MGPO against several baseline methods across various environments (MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter). The metrics reported are the average performance across all test tasks within each environment and the standard deviation is calculated from 3 independent runs. Goal-conditioned BC serves as a simple baseline without online optimization, hence it doesn’t have error bars.
In-depth insights#
Prompt Optimization#
Prompt optimization, in the context of the provided research paper, is a crucial technique for achieving efficient online adaptation in reinforcement learning. The core idea is to treat a sequence of goals as a prompt, allowing a pre-trained transformer-based policy to efficiently adapt to new, unseen tasks by optimizing this prompt rather than fine-tuning the entire policy. This approach leverages the power of Transformers to model long sequences and enables efficient adaptation in long-horizon tasks. The optimization strategy is framed as a multi-armed bandit problem, enhancing sample efficiency and interpretability by using online trajectory returns to guide prompt selection. The paper explores two methods (UCB and Bayesian optimization) for optimizing the prompt sequence, effectively balancing exploration and exploitation. This focus on prompt optimization is a significant departure from existing methods that often rely on extensive online RL fine-tuning, improving efficiency and reducing the need for costly interactions with the environment. The results highlight the effectiveness of this paradigm shift, demonstrating that MGPO significantly surpasses existing methods in sample efficiency and performance.
MGPO Framework#
The MGPO framework introduces a novel approach to efficient online adaptation in reinforcement learning, particularly for long-horizon tasks. Its core innovation lies in leveraging pre-trained multi-goal Transformers to model sequences of goals, effectively conceptualized as prompts. This pre-training phase uses hindsight relabeling and behavior cloning to equip the policy with diverse, long-horizon behaviors aligned with various goal sequences. During online adaptation, prompt optimization, rather than extensive policy fine-tuning, is employed. This involves efficiently searching for the optimal sequence of goals to maximize task performance, formulated as a multi-armed bandit problem. The framework’s strength lies in its sample efficiency and enhanced interpretability compared to existing methods. By optimizing prompts, MGPO avoids the need for costly online reinforcement learning for high-level policy training, demonstrating significant advantages in various environments.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section would involve a critical examination of the methodologies employed, the types of experiments conducted, and the presentation and interpretation of the findings. It’s crucial to assess the statistical significance of the results, looking for p-values, confidence intervals, and effect sizes. The reproducibility of the experiments needs to be evaluated; were the methods clearly described? Were sufficient details provided to allow replication by other researchers? Generalizability is another key consideration. Do the results hold up across different datasets, environments, or parameter settings? Any limitations of the experimental design or analysis should be openly acknowledged. Finally, the discussion of the results should be insightful, moving beyond simple reporting to connect findings with theoretical expectations, and to address any unexpected or counter-intuitive outcomes. In short, a strong ‘Experimental Results’ section would present clear, statistically sound, and generalizable results, accompanied by a thoughtful and nuanced interpretation.
Ablation Study#
An ablation study systematically removes or modifies components of a model to assess their individual contributions. In this context, an ablation study on a prompt optimization method might involve removing elements such as the multi-armed bandit algorithm or changing the type of prompt optimization (e.g., replacing a genetic algorithm with Bayesian optimization). The results would reveal the impact of each component on the overall performance, isolating the effectiveness of each individual contribution. For instance, removing the multi-armed bandit might reduce the model’s efficiency in finding optimal prompts, and comparing performance with and without the bandit algorithm directly quantifies its value. Similarly, switching optimization methods helps to understand the strengths and weaknesses of different approaches. By isolating individual elements, ablation studies provide strong evidence for design choices and highlight which parts are most crucial for achieving optimal results. This enables researchers to improve model designs, focus on essential features, and justify design decisions. Moreover, robustness analysis can be performed by evaluating the effects of different data sets or changes in model parameters; this helps assess the dependability and consistency of the proposed method.
Future Work#
Future research directions stemming from this paper could explore several key areas. Scaling MGPO to larger, more complex datasets and real-world environments is crucial for demonstrating its practical applicability beyond simulations. Addressing the limitations of relying on offline data by incorporating online data collection and integrating online RL techniques would enhance robustness and adaptability. Further investigation into improving the interpretability and robustness of the prompt optimization methods is vital. This includes exploring alternative optimization strategies and developing techniques to mitigate the effects of out-of-distribution prompts. Finally, a thorough analysis of the broader societal impacts, including potential risks and mitigation strategies, is essential for responsible development and deployment of this technology.
More visual insights#
More on figures
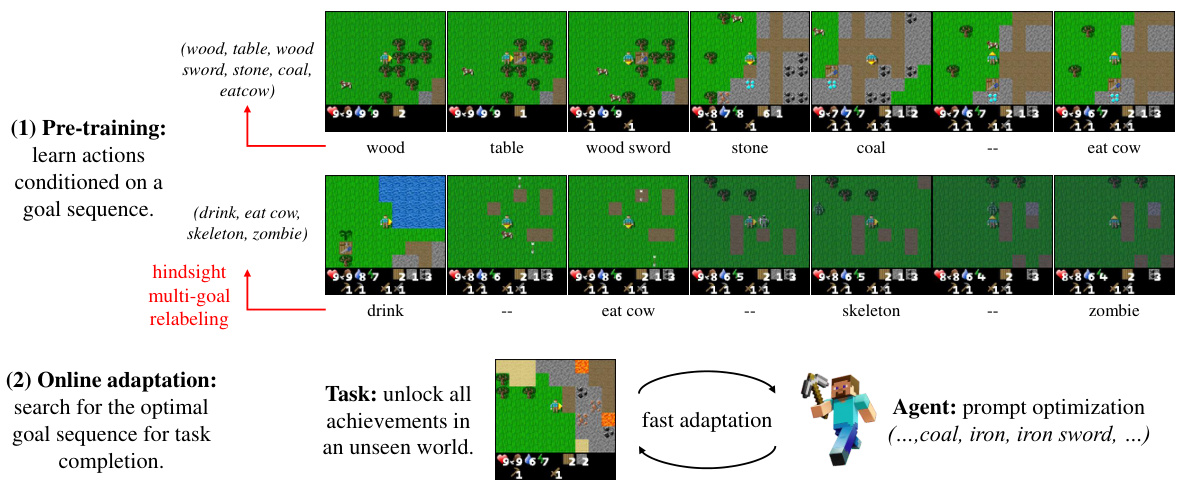
This figure illustrates the MGPO (Multi-Goal Transformers with Prompt Optimization) framework. It shows the two main stages: pre-training and online prompt optimization. Pre-training uses a task-agnostic dataset and techniques like hindsight multi-goal relabeling and behavior cloning to train a Transformer-based policy capable of handling long-term behaviors. During online adaptation, the framework optimizes the sequence of goals (the ‘prompt’) to maximize returns in the unseen task. This optimization is done through a multi-armed bandit process, leveraging returns from online trajectories to guide the selection of goal sequences.
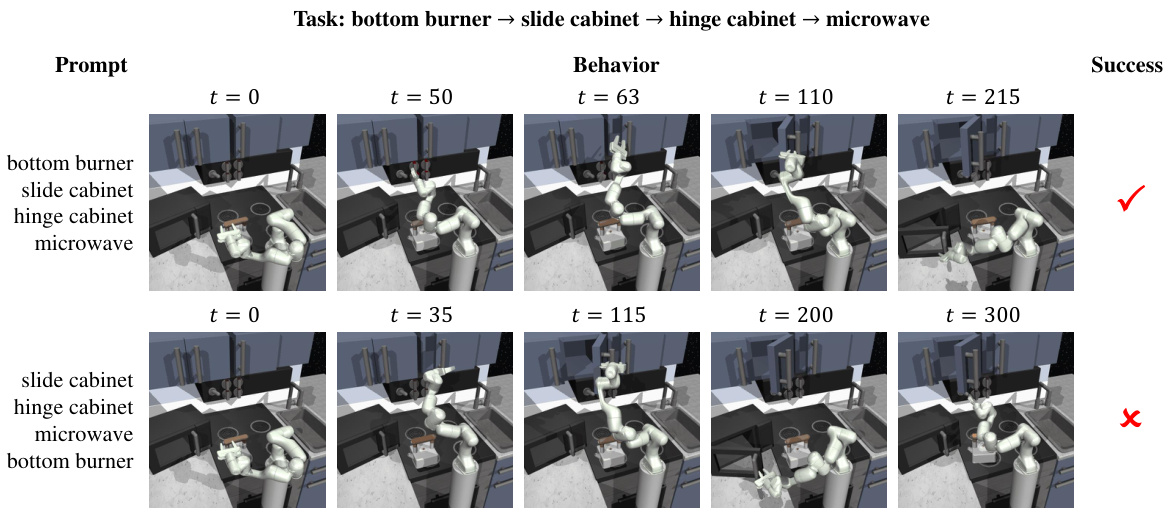
This figure shows two examples of how the order of goals in the prompt affects the agent’s behavior and success in completing a task within the Kitchen environment. The top row depicts a successful trial, where the agent correctly performs the actions specified by the goal sequence in the prompt. The bottom row shows a failed trial, where an incorrect ordering of goals in the prompt leads the agent to perform actions that do not complete the task successfully. The image highlights the importance of sequential goal ordering in long-horizon tasks.
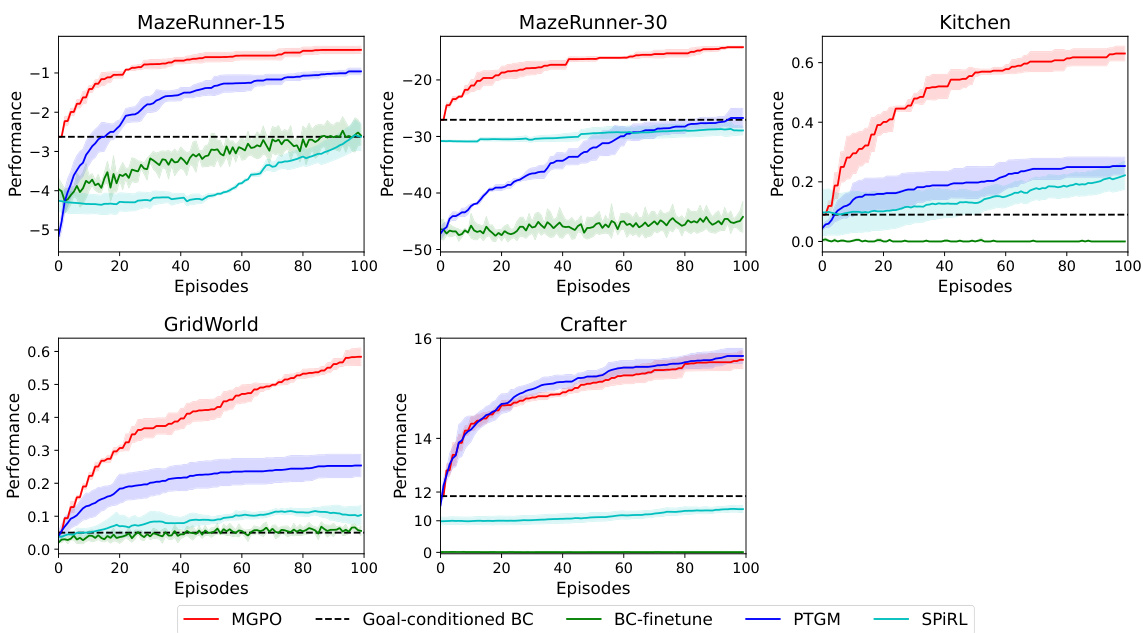
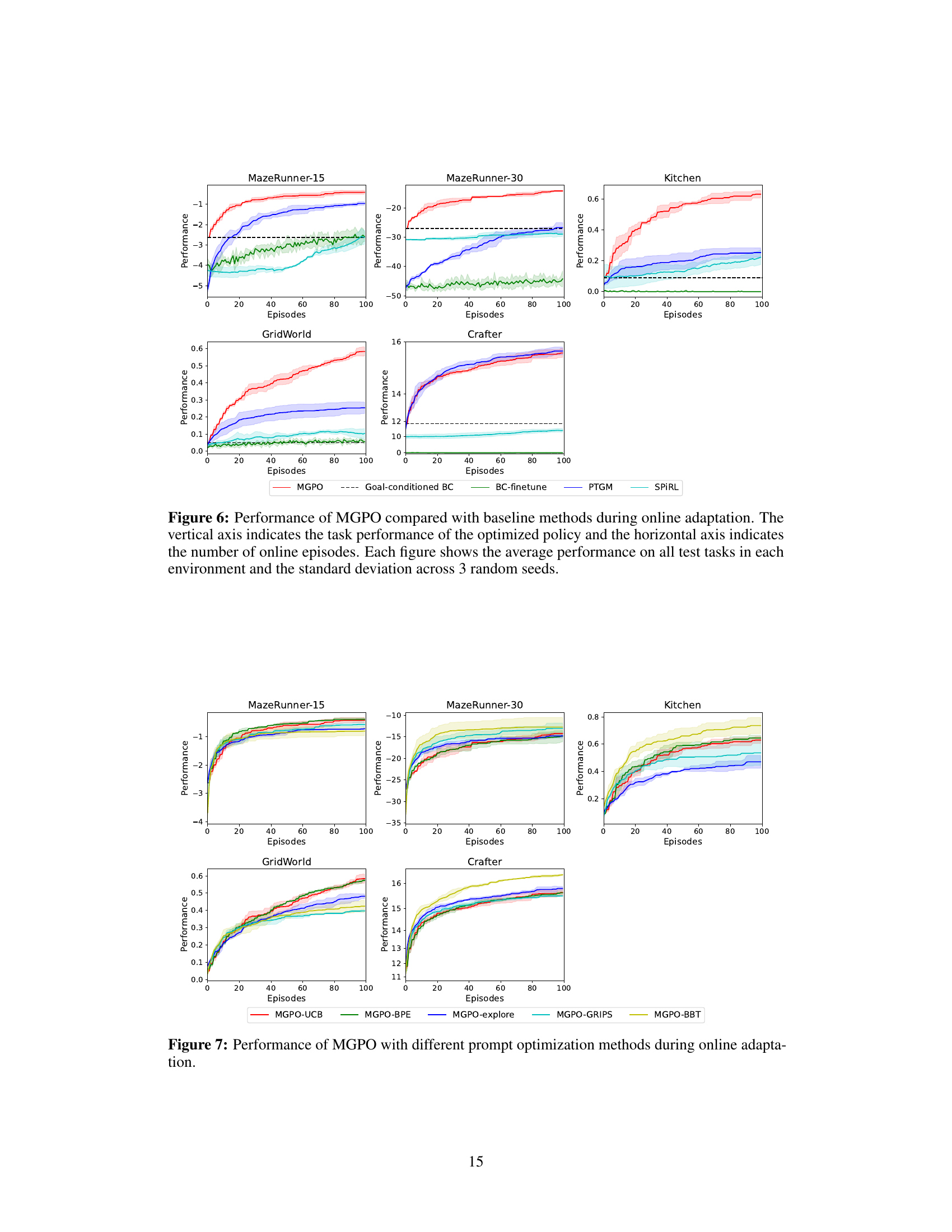
This figure compares the performance of MGPO against several baseline methods across five different environments during online adaptation. The x-axis represents the number of online episodes, and the y-axis shows the average performance on all test tasks within each environment. Error bars represent the standard deviation across three random seeds. The figure clearly demonstrates MGPO’s superior performance and sample efficiency compared to the baselines in most environments.
This figure compares the online adaptation performance of MGPO against several baseline methods across five different environments (MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter). The x-axis represents the number of online episodes, and the y-axis represents the average task performance. Error bars show standard deviations across three random seeds. The figure demonstrates MGPO’s superior performance and faster convergence compared to other methods.
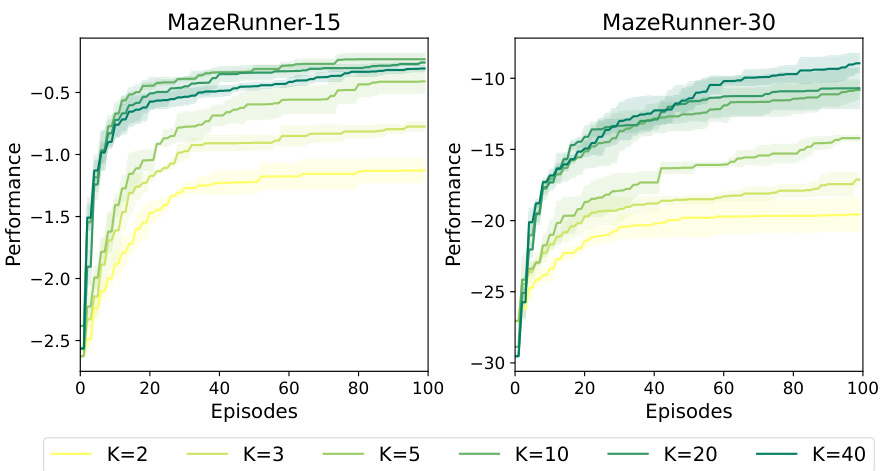
The figure displays additional results from an ablation study on the maximal prompt length K in the MGPO model. It shows the performance of MGPO on MazeRunner-15 and MazeRunner-30 environments with different values for K (2, 3, 5, 10, 20, and 40). This provides a more detailed view of how increasing prompt length affects the performance of MGPO during online adaptation. The shaded areas represent the standard deviation across multiple runs.
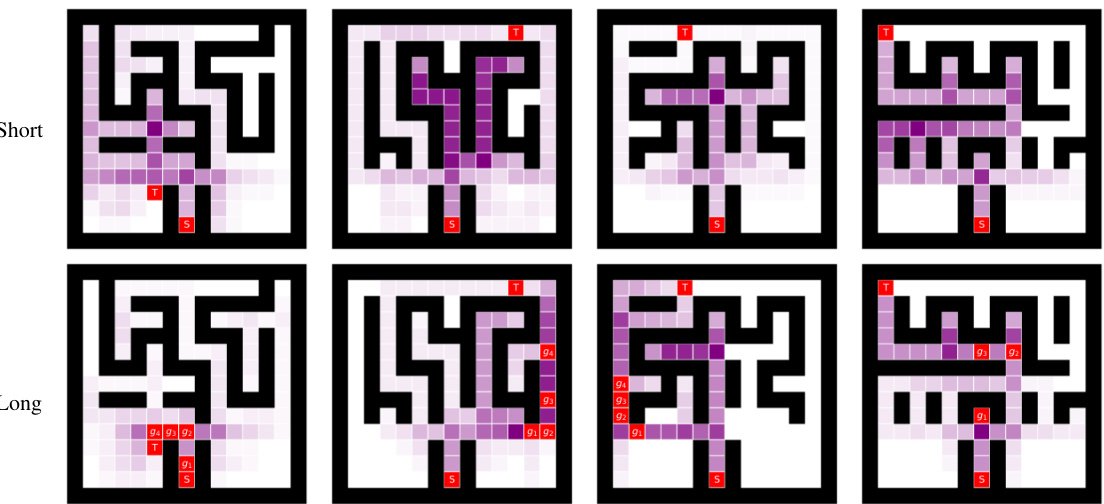
This figure shows the impact of prompt length on exploration vs. exploitation. Shorter prompts (length 1) lead to more diverse exploration of the maze, while longer prompts (length 5) guide the agent toward a more direct path to the goal, demonstrating the effect of prompt length on the agent’s behavior.

This figure visualizes how MGPO-UCB, a method for efficient online adaptation in reinforcement learning, refines its strategy over time. It shows the evolution of optimized prompts (sequences of goals) and the agent’s behavior in a MazeRunner-15 environment. Initially, exploration is focused on the left side, but as rewarding paths on the right are discovered, the prompts and subsequent policy adapt accordingly. The visualization clearly illustrates how the optimized prompts guide the agent towards improved task performance, achieving an effective solution after 40 episodes.
More on tables
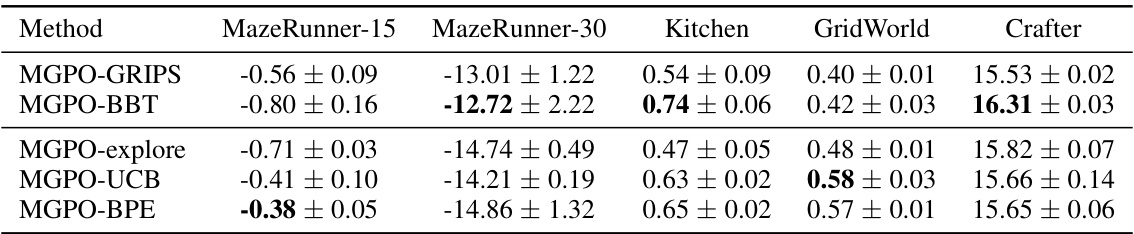
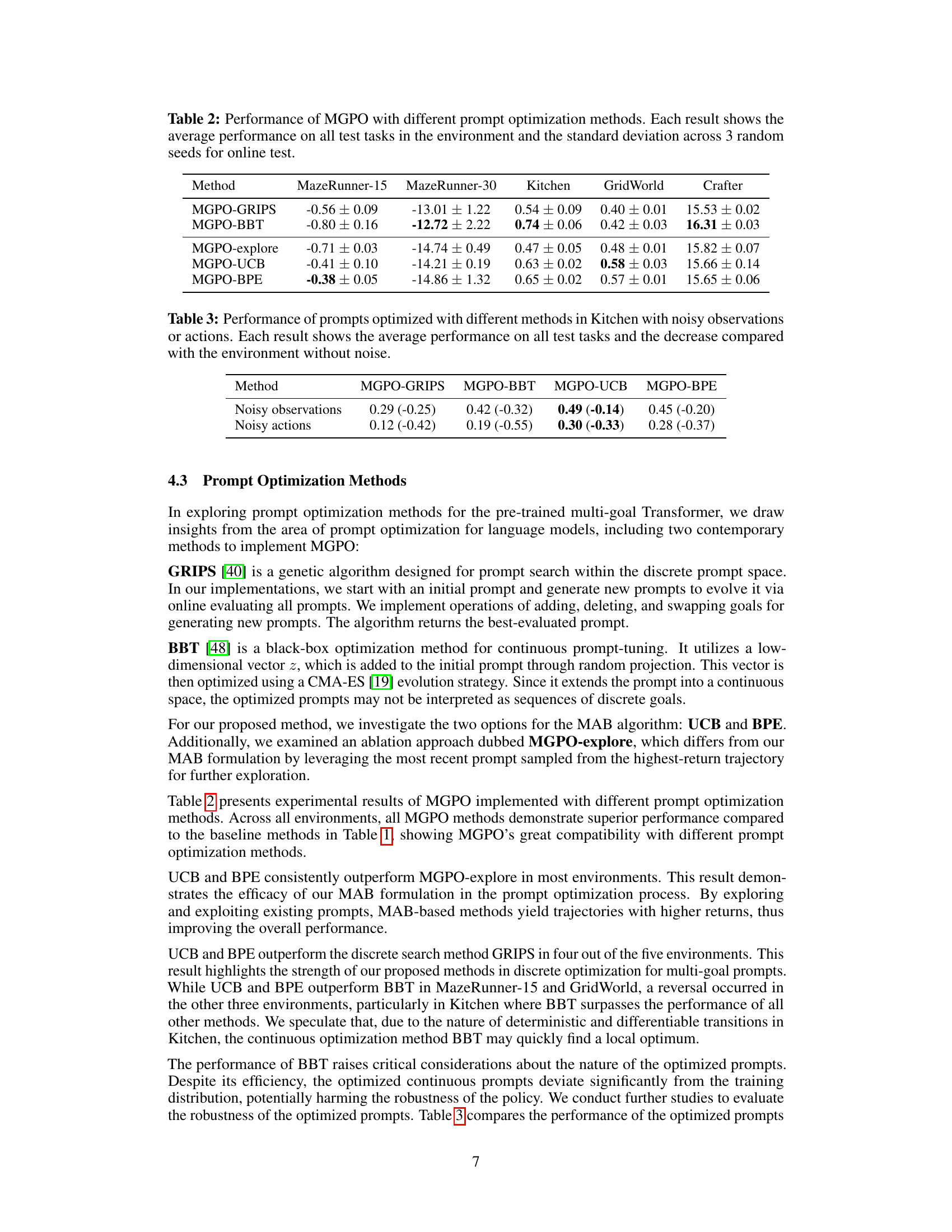
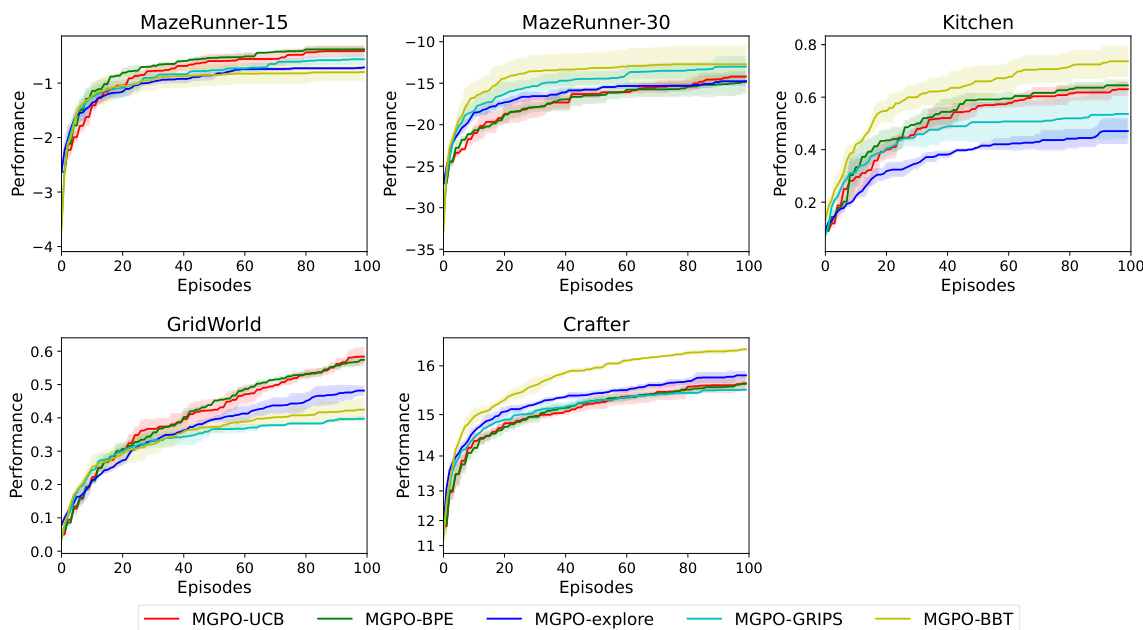
This table presents the average performance and standard deviation across three random seeds of MGPO using five different prompt optimization methods (GRIPS, BBT, explore, UCB, and BPE) on four different environments (MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter). The results demonstrate the performance of each prompt optimization strategy in the online adaptation phase of MGPO.

This table presents the performance of different prompt optimization methods (GRIPS, BBT, UCB, BPE) in the Kitchen environment under noisy conditions. It shows the average performance on all test tasks and the performance decrease compared to a noise-free environment. The results are useful for comparing the robustness of different methods to noisy observations and actions.
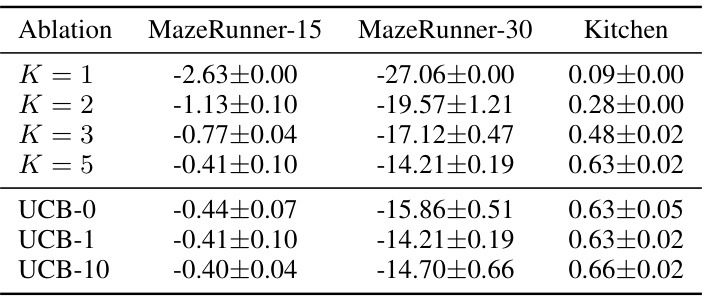
This table presents the results of an ablation study conducted on the Multi-Goal Transformers with Prompt Optimization (MGPO) method. The study investigated the impact of two key factors: the maximal prompt length (K) and the hyperparameter (c) used in the Upper Confidence Bound (UCB) algorithm for prompt optimization. The results are shown for three different environments: Maze Runner-15, Maze Runner-30, and Kitchen. The table allows for a comparison of MGPO’s performance under different settings of K and c, facilitating an understanding of their relative contributions to the overall performance of the model.

This table shows the ablation study result of MGPO-UCB on varying dataset quality. The datasets are collected using A* algorithm with a maximum of n goal switches per episode as A*-n, and datasets from a random exploration policy as Random. The results show that MGPO achieves better performance trained on A*-2 datasets than A*-1, indicating its efficacy with data containing diverse long-horizon behaviors. The comparatively lower performance on the A*-4 dataset in MazeRunner-30 and Random datasets suggests MGPO’s reliance on the quality of data collection policies.
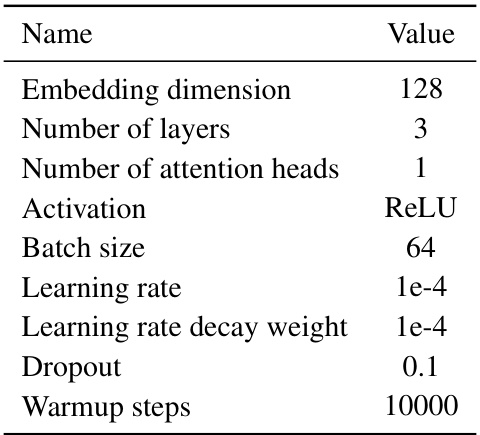
This table compares the performance of the proposed MGPO method against several baseline methods across various environments (Maze Runner-15, Maze Runner-30, Kitchen, GridWorld, and Crafter). The results show the average performance and standard deviation across three random seeds for each method on all test tasks within each environment. Goal-conditioned BC serves as a baseline representing performance without online optimization, thus it lacks error bars.

This table compares the performance of the proposed method MGPO against several baseline methods across various tasks. The metrics used are the average performance and standard deviation of the return obtained across three different random seeds for each method on all test tasks in the environment. The goal-conditioned BC baseline is included, but lacks error bars because it does not perform any online optimization.

This table presents the average performance and standard deviation across three random seeds for five different methods (Goal-conditioned BC, BC-finetune, SPiRL, PTGM, and MGPO) on four different tasks (Maze Runner-15, Maze Runner-30, Kitchen, GridWorld, and Crafter). Goal-conditioned BC serves as a baseline representing the initial performance before online optimization. The table highlights the significant improvement in performance achieved by MGPO compared to existing methods in all tasks.
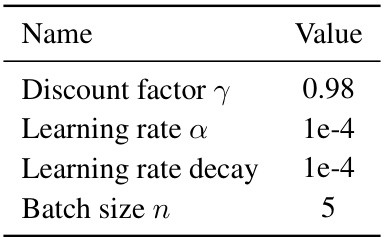
This table compares the performance of the proposed MGPO method against several baseline methods across four different environments (MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter). The performance is measured by the average return obtained during online adaptation, using 100 episodes. Error bars represent standard deviations across three random seeds. The goal-conditioned BC baseline serves as a reference, representing performance without online optimization.

This table compares the performance of the BC-finetune baseline method using two different reinforcement learning algorithms: REINFORCE and PPO. The results are shown for five different environments: MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter. The average performance and standard deviation across three random seeds are provided for each environment and algorithm.

This table presents a comparison of the proposed MGPO method against several baseline methods across various environments (MazeRunner-15, MazeRunner-30, Kitchen, GridWorld, and Crafter). The metrics shown represent the average performance and standard deviation across three random seeds during online testing. Goal-conditioned BC serves as a baseline representing performance without online optimization and thus shows no error bars.

This table compares the performance of the proposed method MGPO against several baseline methods across various environments. The results show the average performance and standard deviation across three random seeds for each environment. Goal-conditioned BC, which doesn’t use online optimization, is included as a baseline for comparison.
Full paper#