TL;DR#
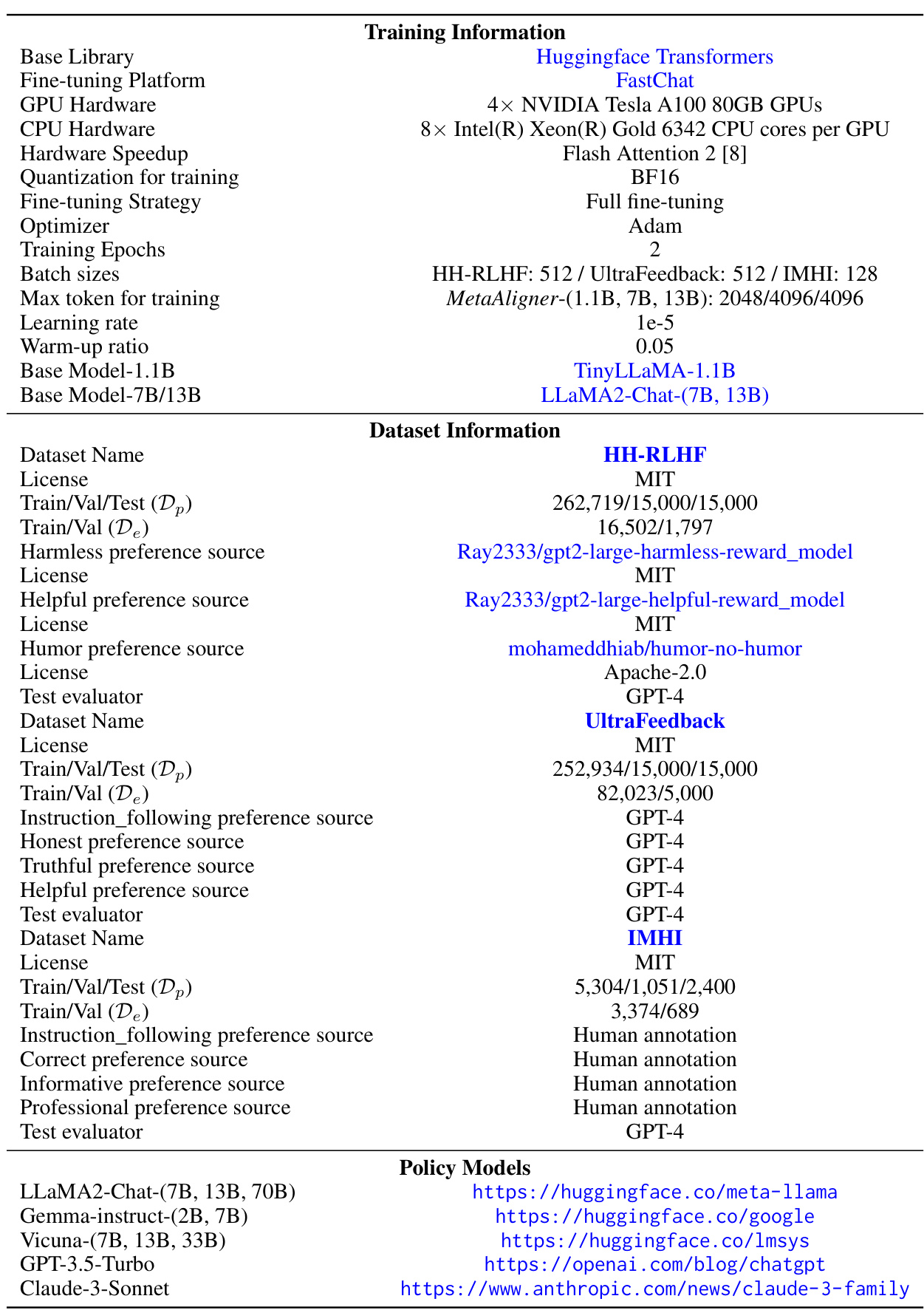
Current methods for aligning Large Language Models (LLMs) to diverse human preferences struggle with high computational costs and limited generalizability. They often require retraining for each new model and objective, hindering efficiency and adaptability. This limitation is particularly problematic with the rapid development and deployment of new LLMs and alignment objectives.
MetaAligner tackles these issues with a three-stage approach: dynamic objective reformulation, conditional weak-to-strong correction, and generalizable inference. This allows for policy-agnostic alignment, significantly reducing training costs, and enables flexible adaptation to unseen objectives. Experiments demonstrate that MetaAligner achieves substantial and balanced improvements in multi-objective alignment across multiple state-of-the-art models and a substantial reduction in GPU training hours. The successful zero-shot alignment on unseen objectives is a key breakthrough advancing the field toward generalizable multi-objective preference alignment.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multi-objective preference alignment of large language models (LLMs). It addresses the limitations of existing methods by introducing a policy-agnostic and generalizable approach. This opens avenues for more efficient and flexible LLM alignment, impacting various downstream applications. Its findings on zero-shot alignment for unseen objectives significantly advance the field.
Visual Insights#

🔼 This figure illustrates the three-stage paradigm of the Meta-Objective Aligner (MetaAligner). Stage 1 involves a dynamic objectives reformulation algorithm that reorganizes traditional alignment datasets to enable flexible alignment across various objectives. Stage 2 uses a conditional weak-to-strong correction paradigm, aligning weak policy model outputs to stronger, higher-preference outputs by incorporating and combining text descriptions of various alignment objectives. This allows plug-and-play inferences on any policy model, significantly reducing training costs. Stage 3 employs a generalizable inference method that flexibly adjusts target objectives by updating their text descriptions in prompts, facilitating alignment with unseen objectives. The figure visually represents the workflow with icons and text labels clarifying each step.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
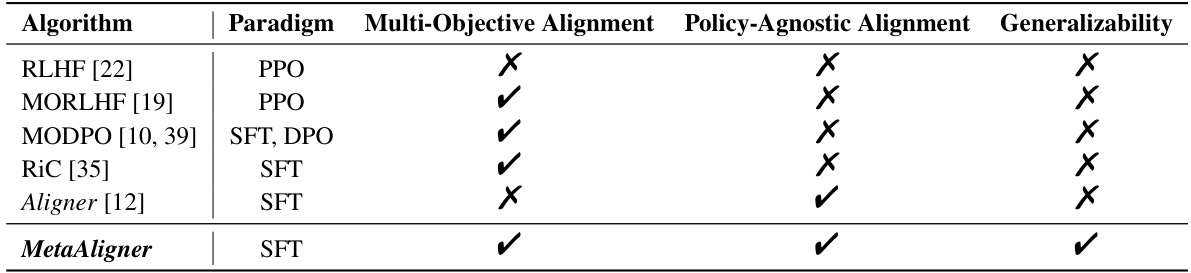
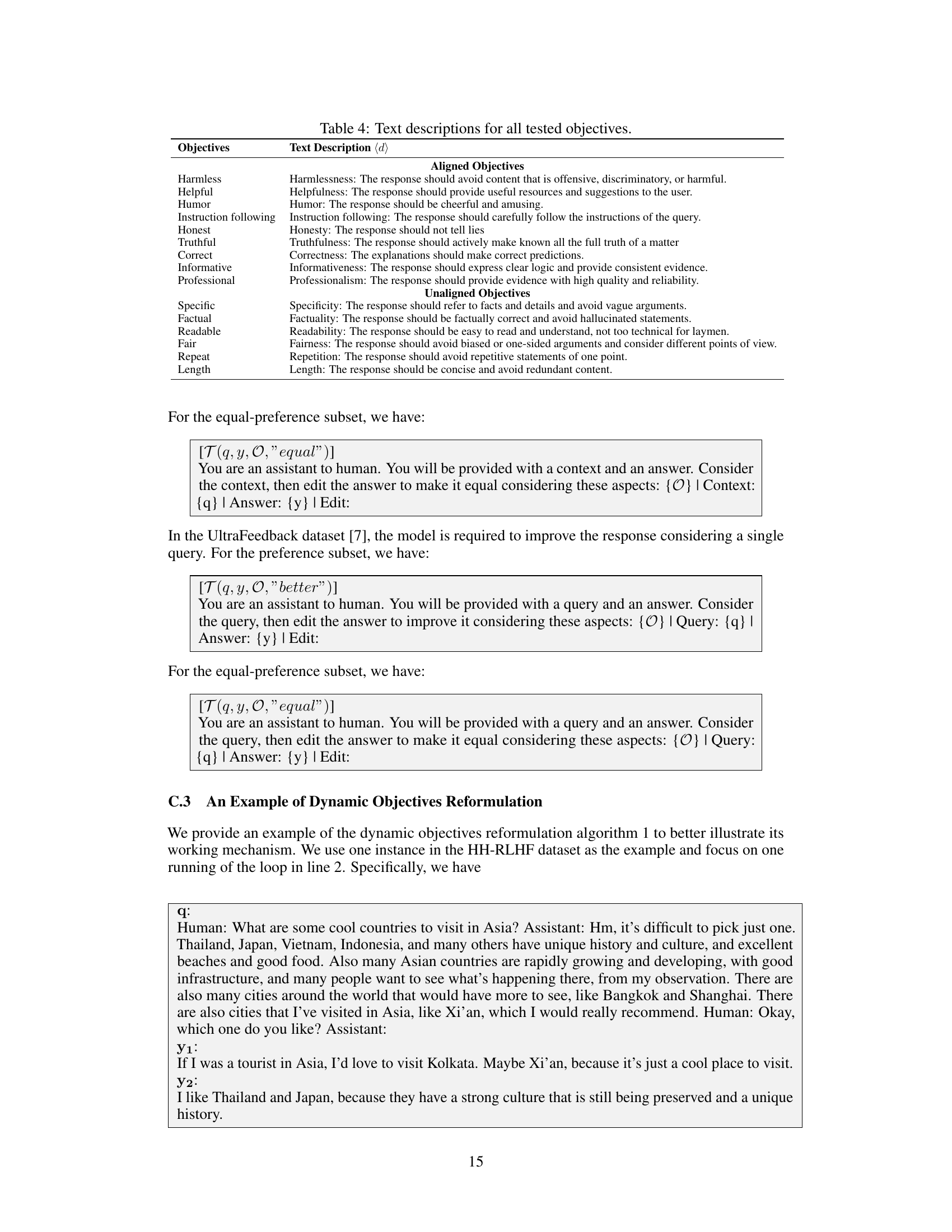
🔼 This table compares several multi-objective language model alignment methods, including the proposed MetaAligner, across three key features: the alignment paradigm used (e.g., reinforcement learning, supervised fine-tuning), whether the method is policy-agnostic (meaning it works regardless of the specific policy model being aligned), and whether the method generalizes to unseen objectives (i.e., can align to objectives it wasn’t explicitly trained on). A checkmark indicates that a method possesses the given feature, while an ‘X’ indicates it does not.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.
In-depth insights#
Policy-Agnostic Alignment#
Policy-agnostic alignment in large language models (LLMs) represents a significant advancement towards creating more generalizable and adaptable AI systems. The core idea is to decouple the alignment process from the specific parameters of a particular policy model. Traditional methods often require retraining the alignment model for every new policy model, resulting in substantial computational costs and limitations in scalability. A policy-agnostic approach, however, allows the alignment algorithm to work effectively regardless of the underlying policy, enabling seamless integration with new models without extensive retraining. This significantly reduces training costs and development time, making it a crucial step toward more practical and efficient LLM alignment. Furthermore, policy agnosticism contributes to improved generalizability, as the alignment algorithm can adapt to a wider range of objectives and tasks without requiring explicit model-specific adaptations. This is vital for creating robust and adaptable AI systems that can handle evolving user expectations and societal values.
Weak-to-Strong#
The concept of “Weak-to-Strong” in the context of AI alignment suggests a paradigm shift in how we approach improving language models. Instead of directly training a model to produce perfect outputs, a weak-to-strong correction paradigm focuses on refining existing, imperfect outputs. This strategy acknowledges that perfectly training a model from scratch to fulfill diverse, often contradictory objectives is computationally expensive and challenging. Aligning weaker models with a secondary model, or a Meta-model as in this case, offers the ability to enhance model outputs in a more efficient and cost-effective manner, particularly for diverse or unseen objectives. The Meta-model learns to correct or transform outputs, moving them towards higher-quality responses that better align with human preferences. This approach is particularly promising for integrating with existing models, avoiding the high computational cost of retraining models entirely, and enabling flexible alignment across numerous objectives.
Generalizable Inference#
The concept of “Generalizable Inference” in the context of multi-objective language model alignment is crucial for creating adaptable and robust AI systems. It signifies the ability of an alignment model to effectively adjust to unseen objectives without retraining, demonstrating true generalization capabilities. This is achieved by making the model objective-agnostic, meaning it is not tied to specific policy model parameters. The approach presented relies on flexible adjustments through text-based descriptions of objectives within prompts, enabling in-context learning. The implications are significant: reducing retraining costs and enabling alignment with closed-source models, overcoming a major limitation of existing methods. This step towards generalizable multi-objective preference alignment is a substantial advancement, allowing for the dynamic addition and adaptation to new alignment goals without extensive computational costs. The successful zero-shot performance on previously unseen objectives underscores the power of this approach and paves the way for more adaptable and versatile AI assistants.
Multi-Objective Alignment#
Multi-objective alignment in large language models (LLMs) tackles the challenge of aligning models with diverse and often conflicting human values. Existing methods often rely on static objective functions, limiting their adaptability to new or unforeseen preferences. The key challenge lies in effectively balancing multiple, potentially competing, objectives during the training process. This requires innovative approaches beyond simple reward aggregation, as direct optimization may lead to suboptimal solutions. Dynamic or adaptive methods, capable of adjusting the weight or priority of different objectives based on context or performance feedback, are crucial. These might include meta-learning techniques that learn to align to new objectives efficiently or reinforcement learning approaches that handle complex reward landscapes better. Furthermore, achieving generalizability is paramount; a robust multi-objective alignment method should be able to effectively handle new, unseen objectives without retraining the core model. This could involve in-context learning methods or the development of more flexible and adaptable model architectures.
Future of Alignment#
The future of alignment research necessitates a multifaceted approach. Moving beyond static, pre-defined objectives is crucial. Dynamic, adaptable systems that learn and evolve alongside user preferences are needed. Policy-agnostic methods, like the MetaAligner, offer a promising path by decoupling alignment from specific model parameters, reducing retraining costs and improving generalizability. However, scalability and computational efficiency remain significant hurdles, particularly when dealing with massive language models and numerous alignment objectives. Addressing these challenges requires innovation in algorithm design, potentially through more efficient training paradigms or leveraging techniques from transfer learning. Equally important is exploring the ethical dimensions of alignment, ensuring fairness, preventing harm, and mitigating potential biases. The long-term vision demands generalizable alignment, enabling effective alignment across unseen objectives and contexts, a capability that is still largely unexplored. This will involve developing robust methods that can adapt to evolving human values and expectations, further blurring the line between alignment and ongoing model improvement.
More visual insights#
More on figures

🔼 This figure provides a visual overview of the Meta-Objective Aligner’s three-stage process. Stage 1 involves the reformulation of raw datasets into dynamic objective datasets. Stage 2 shows the conditional weak-to-strong correction, where a base model and MetaAligner work together to align weak model outputs to strong outputs based on specified objectives. Stage 3 highlights the generalizable inference, allowing alignment to new objectives simply by updating the text descriptions within prompts.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
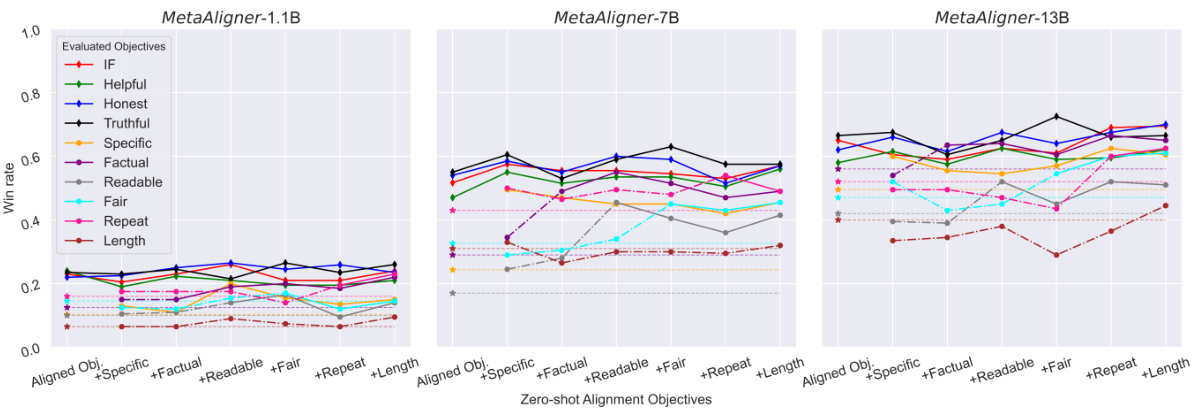
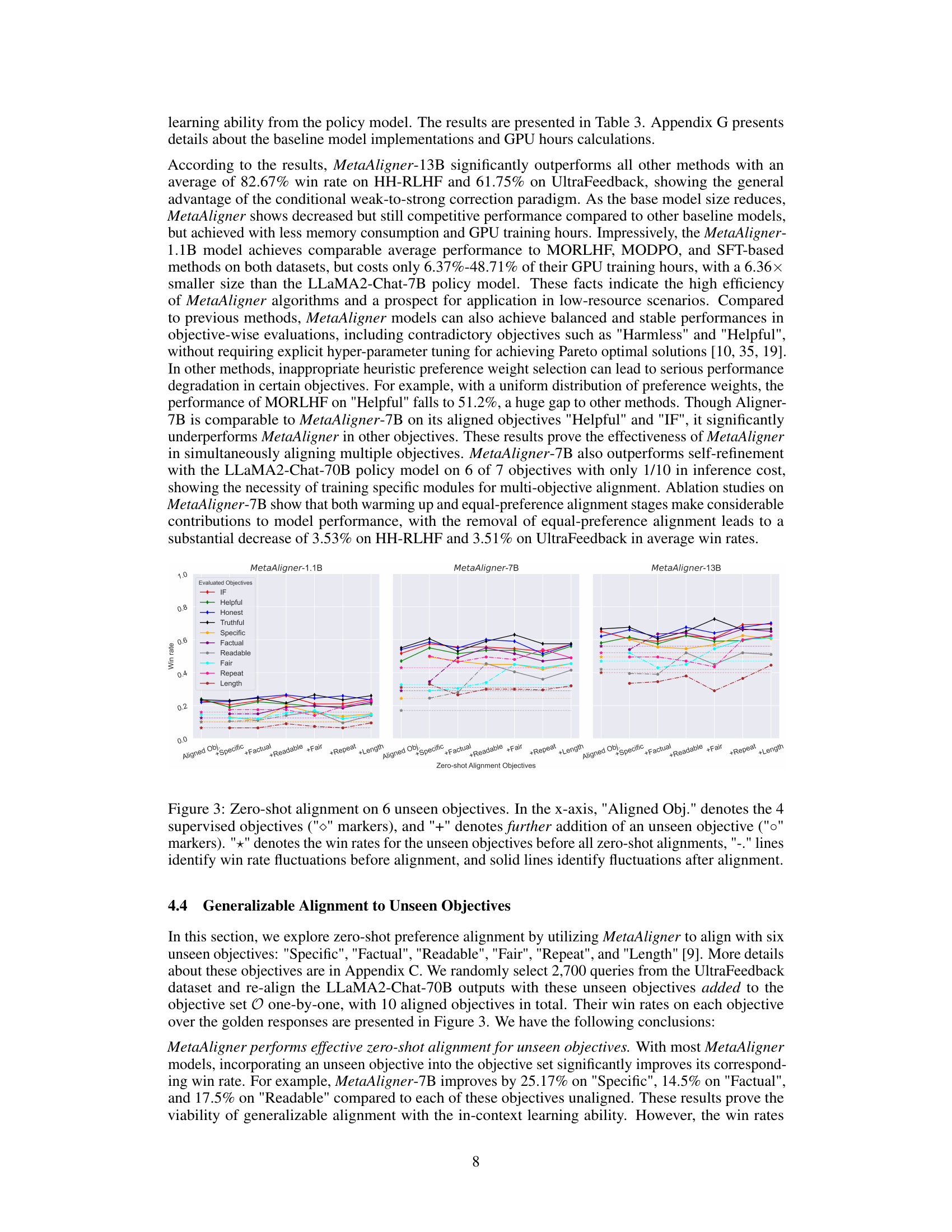
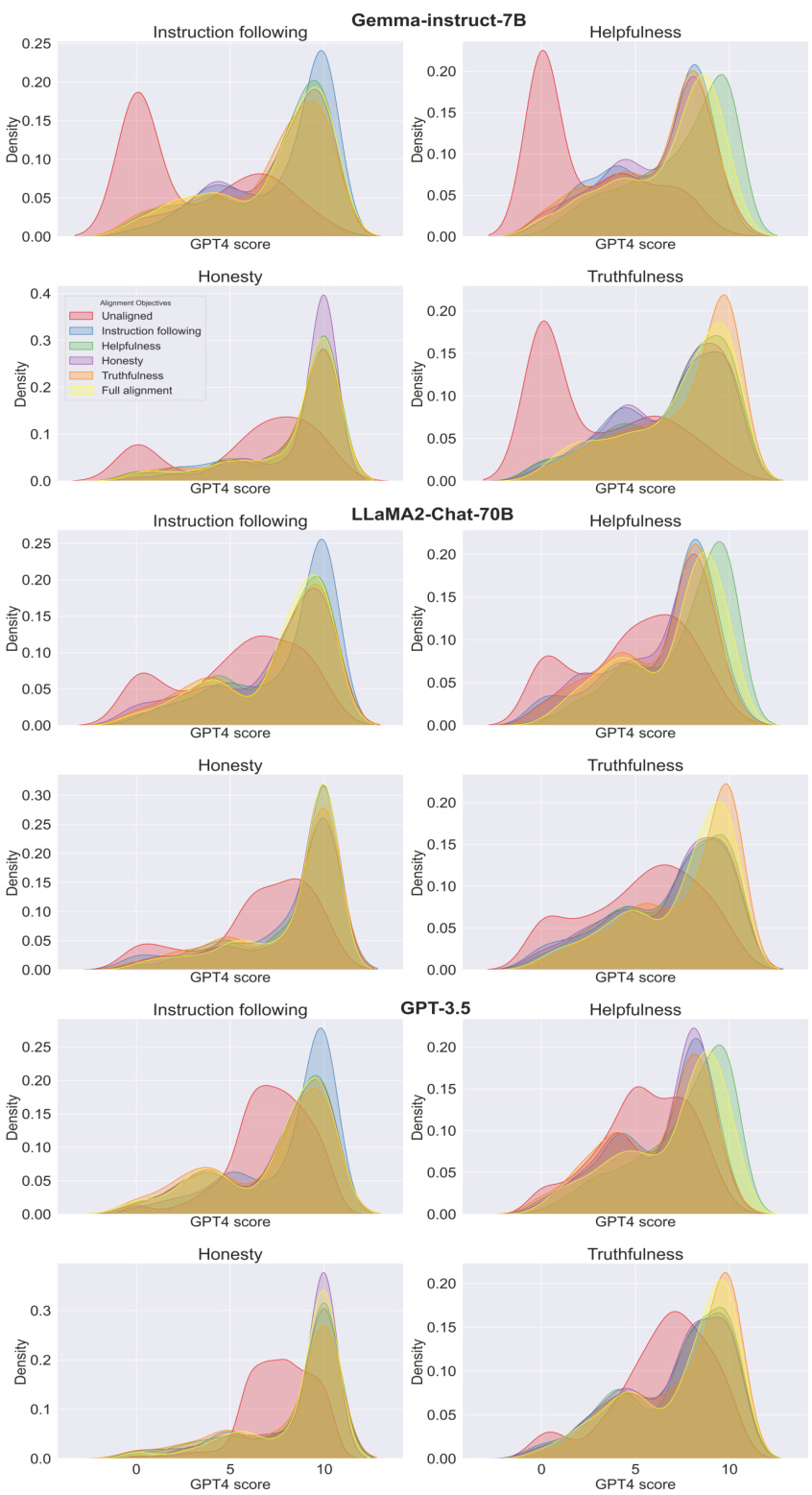
🔼 This figure shows the results of zero-shot alignment experiments using MetaAligner on six unseen objectives. The x-axis shows the progression of adding unseen objectives one by one to the existing set of four aligned objectives. The y-axis represents the win rate achieved. The markers show the win rate for each objective. The dashed lines track the win rate changes before zero-shot alignment, while the solid lines show win rate changes after the zero-shot alignment. The overall trend indicates improved performance on both aligned and unseen objectives, illustrating the generalizability of MetaAligner.
read the caption
Figure 3: Zero-shot alignment on 6 unseen objectives. In the x-axis, 'Aligned Obj.' denotes the 4 supervised objectives ('◊' markers), and '+' denotes further addition of an unseen objective ('0' markers). '+' denotes the win rates for the unseen objectives before all zero-shot alignments, '-.' lines identify win rate fluctuations before alignment, and solid lines identify fluctuations after alignment.
🔼 This figure illustrates the three stages of the Meta-Objective Aligner (MetaAligner): dynamic objectives reformulation, conditional weak-to-strong correction, and generalizable inference. The first stage shows how raw datasets are processed to create dynamic objective datasets used to train the model to align across different objectives. The second stage depicts how the model corrects weak outputs from policy models to approach strong outputs with higher preferences. The third stage highlights the model’s ability to generalize to unseen objectives by adjusting the text description of the objectives in the prompt. The diagram visually represents the three-stage process and the flow of data through each stage.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
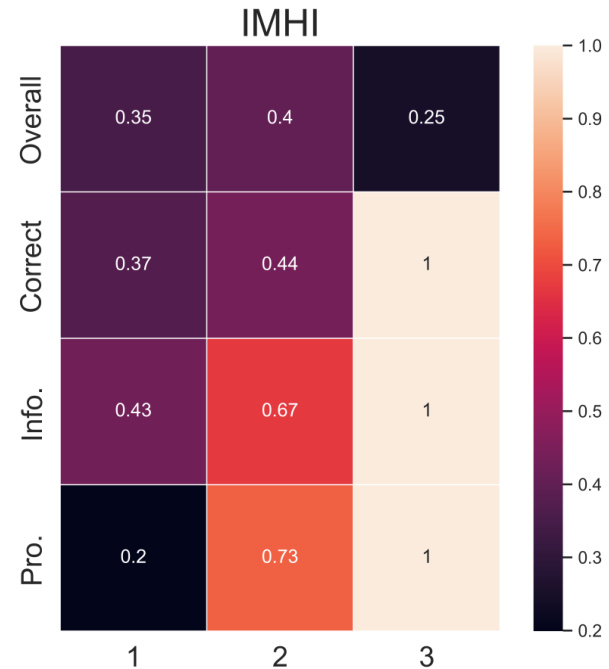
🔼 The figure displays heatmaps visualizing the distribution of objectives across different dataset categories. The columns represent the number of objectives in each data sample, while the rows detail individual objective distributions (including an ‘Overall’ row showing the total distribution). This helps illustrate the balance (or imbalance) of objectives in the training data and the representation of each objective across different dataset sizes.
read the caption
Figure 2: Heatmaps of the objective distributions. The columns categorize samples according to the sizes of their objective set. For the lines, 'Overall' shows their distributions in the training data. Other lines show objective-wise distributions across different categories in the columns.
🔼 This figure illustrates the three-stage paradigm of the Meta-Objective Aligner (MetaAligner). Stage 1 involves dynamic objectives reformulation, where a raw dataset is processed to create warm-up, equal-preference, and contrastive subsets. Stage 2 performs conditional weak-to-strong correction, where a base model and MetaAligner are used to align weak outputs of a target policy model with stronger outputs, incorporating human feedback. Stage 3 enables generalizable inference, where unseen objectives can be handled by adjusting text descriptions within prompts. The diagram visually represents the flow of data and the interaction between the different components.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.

🔼 This figure provides a visual representation of the Meta-Objective Aligner’s three-stage process: 1) Dynamic Objectives Reformulation, where raw data is processed to create dynamic-objective datasets for flexible alignment across objectives; 2) Conditional Weak-to-Strong Correction, where weak outputs from fixed policy models are corrected to achieve stronger outputs with higher preferences in alignment objectives; 3) Generalizable Inference, where unseen objectives are handled through prompt adjustments, facilitating flexible alignment with unseen objectives. The figure shows the flow of data through each stage and highlights key components of the Meta-Objective Aligner.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
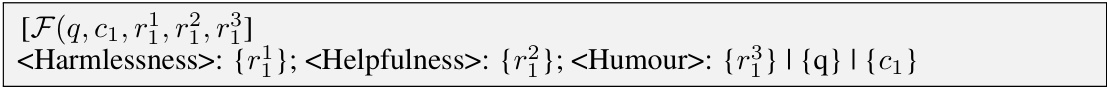
🔼 This figure shows a three-stage paradigm of the Meta-Objective Aligner. Stage 1 is dynamic objectives reformulation, which involves reorganizing traditional alignment datasets to supervise the model on performing flexible alignment across different objectives. Stage 2 is conditional weak-to-strong correction, which aligns the weak outputs of fixed policy models to approach strong outputs with higher preferences in the corresponding alignment objectives. Stage 3 is generalizable inference, which flexibly adjusts target objectives by updating their text descriptions in the prompts. The figure also illustrates the flow of data and processing through each stage.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
🔼 The figure shows a three-stage paradigm of the Meta-Objective Aligner. Stage 1 is ‘Dynamic Objectives Reformulation’, which reorganizes traditional alignment datasets to supervise the model on performing flexible alignment across different objectives. Stage 2 is ‘Conditional Weak-to-Strong Correction’, which aligns weak outputs of fixed policy models to approach strong outputs with higher preferences in the corresponding alignment objectives. Stage 3 is ‘Generalizable Inference’, which flexibly adjusts target objectives by updating their text descriptions in the prompts. The figure also includes an illustration of how the three stages work together to align the language model with multiple objectives.
read the caption
Figure 1: Illustrations of Meta-Objective Aligner, which follows a three-stage paradigm.
More on tables

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across several key characteristics. These characteristics include the alignment paradigm used (e.g., Reinforcement Learning from Human Feedback, Supervised Fine-Tuning), whether the method supports multi-objective alignment, whether the method is independent of the target policy model parameters (policy-agnostic), and whether the method can align to unseen objectives (generalizable). A checkmark indicates that the method possesses the given characteristic.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

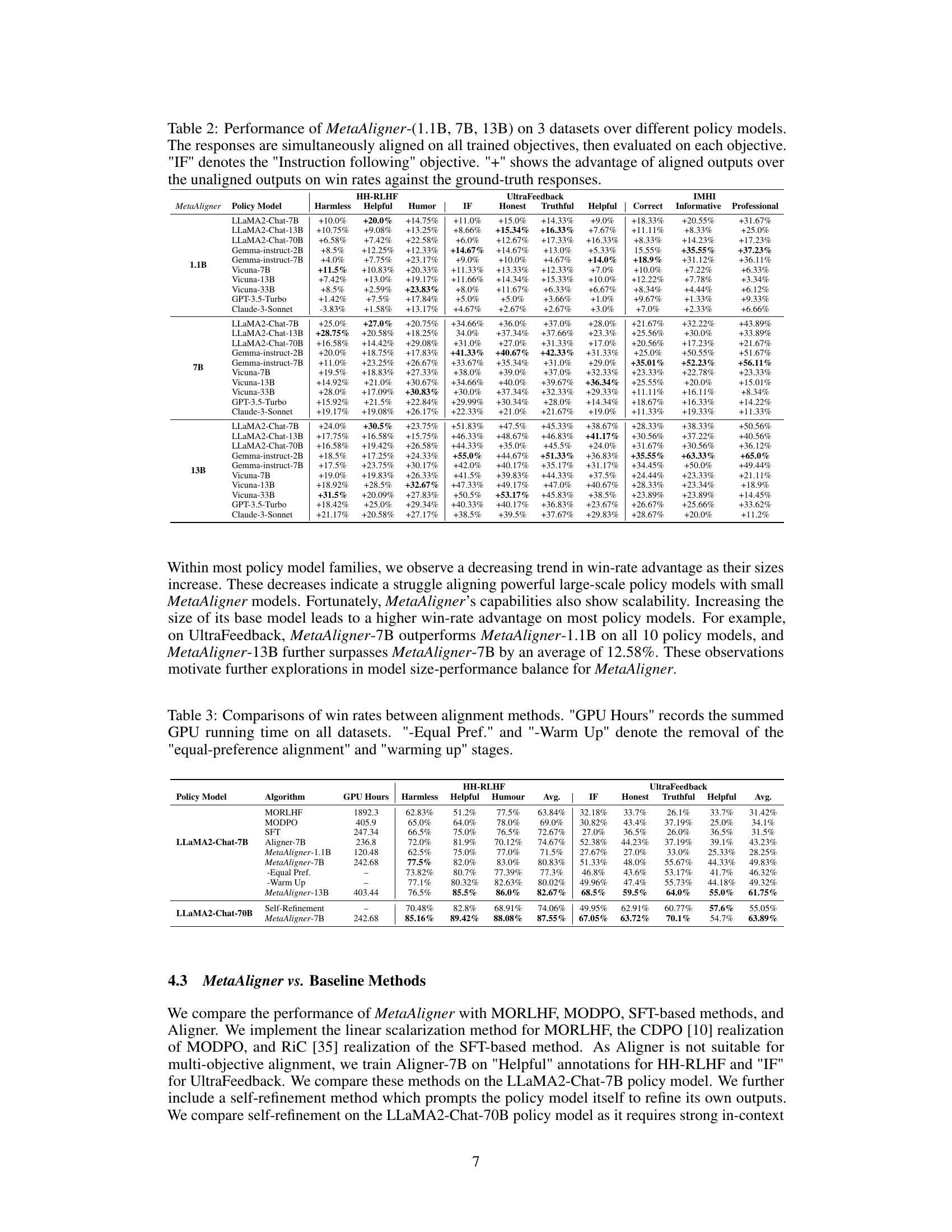
🔼 This table presents the performance of three different sized MetaAligner models (1.1B, 7B, and 13B parameters) across three datasets (HH-RLHF, UltraFeedback, and IMHI) and multiple policy models. For each combination of MetaAligner model, dataset, and policy model, the win rate improvement on each objective is shown. A positive percentage indicates improvement over unaligned responses, showing the effectiveness of MetaAligner in improving the alignment of various language models. The ‘IF’ objective refers to ‘Instruction Following’.
read the caption
Table 2: Performance of MetaAligner-(1.1B, 7B, 13B) on 3 datasets over different policy models. The responses are simultaneously aligned on all trained objectives, then evaluated on each objective. 'IF' denotes the 'Instruction following' objective. '+- ' shows the advantage of aligned outputs over the unaligned outputs on win rates against the ground-truth responses.

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across three key features: whether the method is policy-agnostic (meaning it works regardless of the specific policy model used), whether it supports multi-objective alignment, and whether it can generalize to unseen objectives (zero-shot alignment). Each method is evaluated against these three criteria using checkmarks.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across three key features: whether the method uses a multi-objective approach, whether the alignment is independent of the policy model parameters, and whether the method can generalize to unseen objectives (zero-shot alignment). The table helps to highlight the unique advantages of MetaAligner by showing that it is both policy-agnostic and generalizable, unlike other methods.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across three key characteristics: the alignment paradigm used (e.g., reinforcement learning, supervised fine-tuning), whether the method is policy-agnostic (meaning it works regardless of the specific language model used), and its generalizability to unseen objectives (i.e., can it align to new objectives without retraining). The table shows that MetaAligner is unique in that it’s both policy-agnostic and generalizable.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares different language model alignment methods, including MetaAligner, across several key features. These features are whether the method uses multiple objectives, is independent of the target policy model’s parameters (policy-agnostic), and whether it can align to unseen objectives (generalizable). A checkmark indicates that the method possesses that feature.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares several existing multi-objective language model alignment methods (RLHF, MORLHF, MODPO, RiC, Aligner) with the proposed MetaAligner method. The comparison is made across three key features: whether the method uses a multi-objective alignment paradigm, whether the alignment is independent of the target policy model’s parameters (policy-agnostic), and whether the method can generalize to unseen objectives (generalizability). A checkmark indicates that a method possesses the given feature.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across several key characteristics. These characteristics assess whether the methods are policy-agnostic (independent of the policy model’s parameters), support multi-objective alignment, and can generalize to unseen objectives (zero-shot alignment). A checkmark indicates that the method possesses the given characteristic.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table presents the performance of three different sizes of the MetaAligner model (1.1B, 7B, and 13B parameters) across three datasets (HH-RLHF, UltraFeedback, and IMHI) and multiple policy models. The ‘+’ symbol indicates the percentage improvement in win rate achieved by MetaAligner over the unaligned outputs for each objective. The table shows that MetaAligner improves the win rates on multiple objectives across different policy models and that the performance generally improves with the size of the MetaAligner model.
read the caption
Table 2: Performance of MetaAligner-(1.1B, 7B, 13B) on 3 datasets over different policy models. The responses are simultaneously aligned on all trained objectives, then evaluated on each objective. 'IF' denotes the 'Instruction following' objective. '+' shows the advantage of aligned outputs over the unaligned outputs on win rates against the ground-truth responses.
🔼 This table compares different language model alignment methods, including MetaAligner, across several key features. It highlights whether each method supports multi-objective alignment, is independent of the target policy model’s parameters (policy-agnostic), and can generalize to unseen objectives (zero-shot alignment). The table helps illustrate the unique advantages of MetaAligner compared to existing approaches.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares several multi-objective language model alignment methods, including MetaAligner, across three key aspects: the alignment paradigm used (e.g., reinforcement learning, supervised fine-tuning), whether the method is policy-agnostic (meaning it doesn’t depend on the specific policy model’s parameters), and whether it exhibits generalizability (the ability to align to unseen objectives without retraining). It highlights MetaAligner’s unique advantages in being both policy-agnostic and generalizable.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.
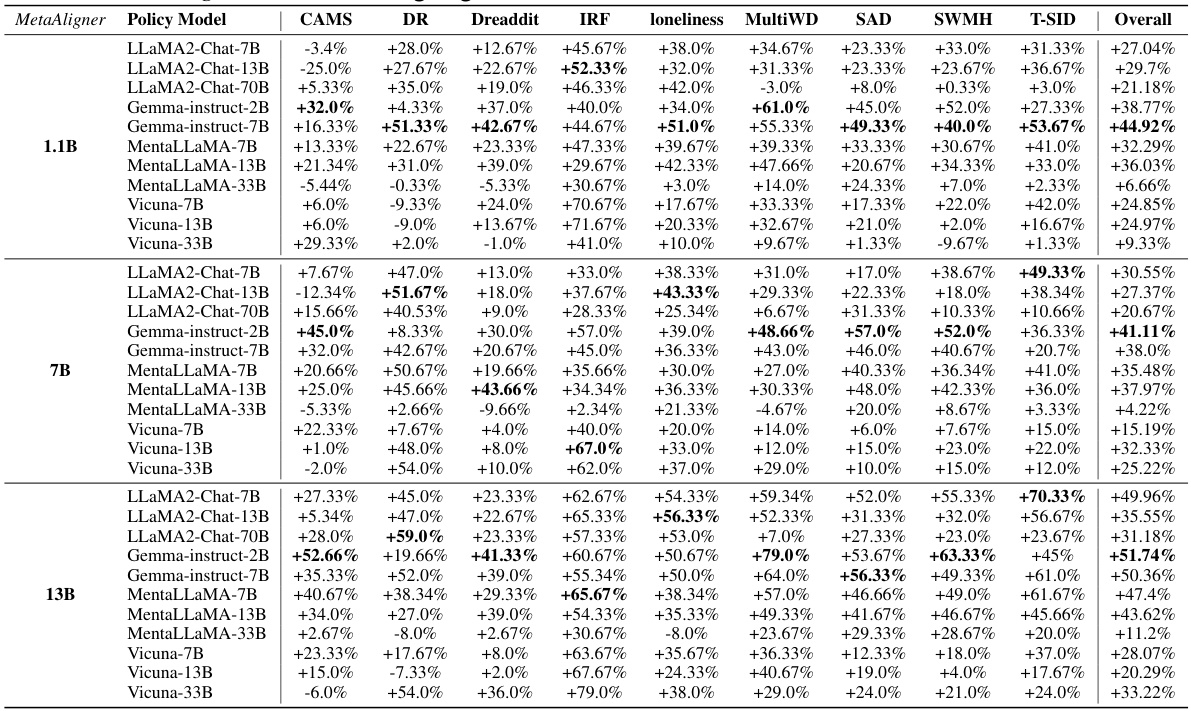
🔼 This table presents the performance of three different sized MetaAligner models (1.1B, 7B, and 13B parameters) on three datasets (HH-RLHF, UltraFeedback, and IMHI). The results show the win-rate improvement achieved by MetaAligner for each objective across ten state-of-the-art policy models. The ‘+’ symbol indicates the percentage increase in win rate for the aligned outputs compared to the unaligned outputs. The table highlights the improvements MetaAligner provides for multi-objective alignment in several different language model settings.
read the caption
Table 2: Performance of MetaAligner-(1.1B, 7B, 13B) on 3 datasets over different policy models. The responses are simultaneously aligned on all trained objectives, then evaluated on each objective. 'IF' denotes the 'Instruction following' objective. '+* shows the advantage of aligned outputs over the unaligned outputs on win rates against the ground-truth responses.

🔼 This table compares different language model alignment methods (RLHF, MORLHF, MODPO, RiC, Aligner, and MetaAligner) across several key features. These features include the underlying paradigm used (e.g., reinforcement learning, supervised fine-tuning), whether the method supports multi-objective alignment, whether it’s policy-agnostic (meaning it works independently of the specific policy model used), and whether it generalizes to unseen objectives (zero-shot alignment). MetaAligner is shown to be unique in its combination of policy-agnostic and generalizable multi-objective capabilities.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares different language model alignment methods, including MetaAligner, across several key features. These features are whether the method uses a multi-objective approach, whether the alignment is dependent on the target policy model parameters (policy-agnostic), and whether the method can generalize to unseen objectives (zero-shot alignment). A checkmark indicates that the method possesses the specified feature. The table highlights MetaAligner’s unique combination of multi-objective alignment, policy-agnostic nature, and generalizability.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.

🔼 This table compares different language model alignment methods, including MetaAligner, across several key features. These features are whether the method uses multiple objectives, whether the method is independent of the policy model parameters (policy-agnostic), and whether it can generalize to objectives it has not been trained on (generalizability). This allows for a direct comparison of MetaAligner’s novel features against existing approaches.
read the caption
Table 1: Comparisons between previous alignment methods and MetaAligner on different features. 'Policy-Agnostic Alignment' means the alignment algorithm is independent of the target policy model parameters, and 'Generalizability' denotes zero-shot alignment capability on unseen objectives.
Full paper#