TL;DR#
Panoramic semantic segmentation (PASS) is critical for scene understanding in 360° environments but faces challenges from image distortions and limited training data. Existing methods struggle with imbalanced representation of different scene elements and the ambiguity of monocular images, resulting in suboptimal performance, especially for smaller objects.
This paper tackles these issues with a novel approach. It reformulates PASS as two sub-problems: segmentation of over-sampled (planar) and under-sampled segments. It then uses joint optimization with depth estimation to enhance the over-sampled segments and a transformer-based context module to integrate different geometric representations (including a novel ‘vertical relative distance’ feature) for under-sampled segments. The resulting hybrid decoder achieves state-of-the-art results on several benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances indoor panoramic semantic segmentation, a crucial task for numerous applications, including autonomous vehicles and AR/VR. It proposes a novel approach that overcomes limitations of existing methods by integrating geometric information, leading to improved accuracy and robustness, especially in challenging indoor environments. This opens new avenues for research in multi-task learning and geometric deep learning for panoramic scene understanding.
Visual Insights#

🔼 This figure illustrates the proposed method’s approach to panoramic semantic segmentation. The input is a panoramic image. The problem is broken down into two sub-problems: estimating over-sampled segments (which are large, easily identifiable features such as floor and ceiling) and estimating under-sampled segments (smaller, more complex features such as chairs, tables, etc.). The final segmentation combines the results of these two sub-problems to provide a complete semantic segmentation of the entire scene. This approach allows the model to handle the challenges of size imbalance and distortion common in panoramic images more effectively.
read the caption
Figure 1: Panoramic segmentation problem can be re-formulated to the estimation of over-sampled segments: floor, ceiling and under-sampled segments: chair, table, bookcase, window, etc.
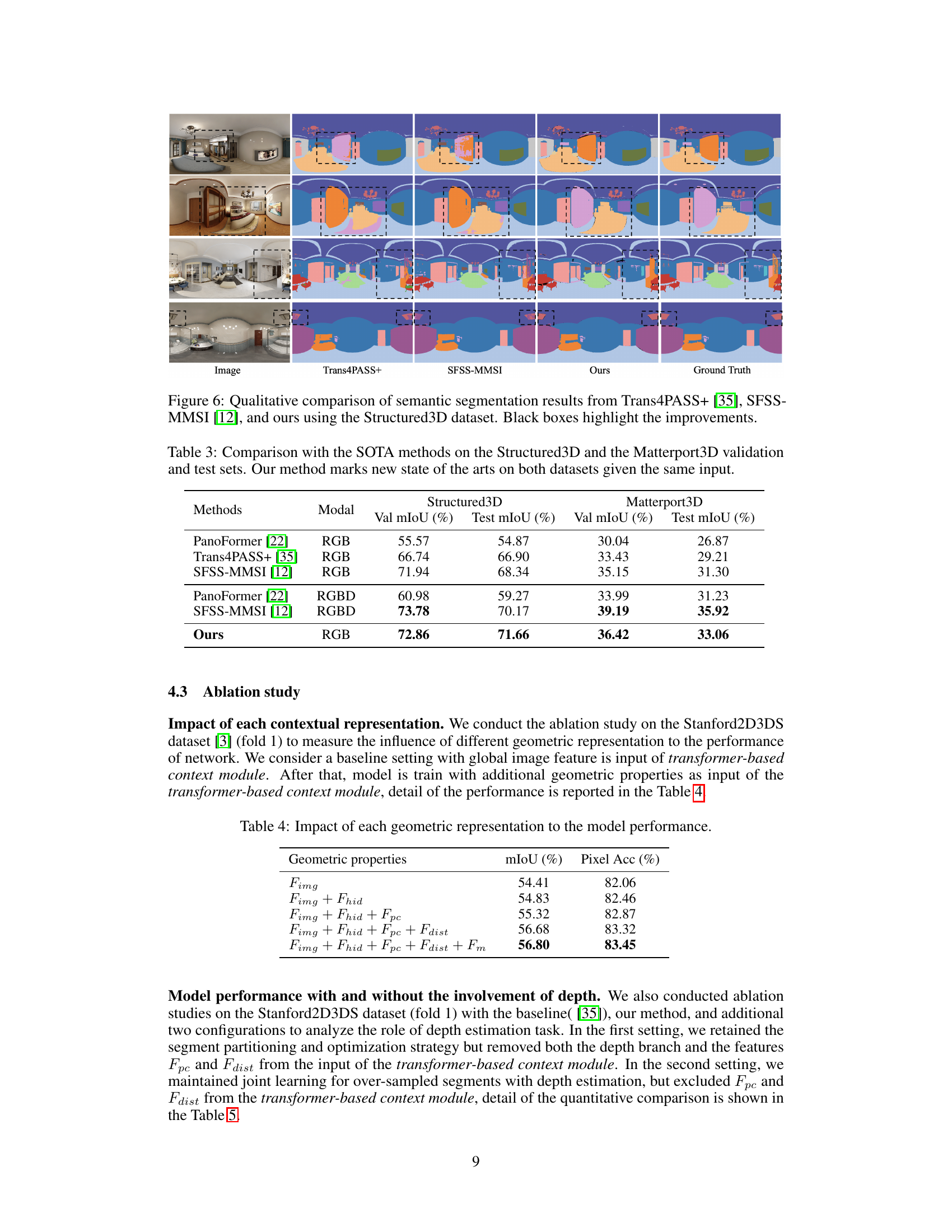
🔼 This table compares the performance of the proposed method with several state-of-the-art methods on the Stanford2D3DS dataset for panoramic semantic segmentation. It shows the average mean Intersection over Union (mIoU) across all three official folds and the mIoU specifically for fold 1. The results highlight the significant improvement achieved by the proposed method compared to existing approaches.
read the caption
Table 1: Comparison with state-of-the-art methods on the Stanford2D3DS dataset. Consistent with recent work, we report performance as the average mIoU across all three official folds (Avg mIoU) and on fold 1 specifically (F1 mIoU). Our approach demonstrates substantial improvements over both the baseline and existing methods.
In-depth insights#
PASS Redefined#
The heading ‘PASS Redefined’ suggests a novel approach to Panoramic Semantic Segmentation (PASS). A thoughtful analysis would delve into how this redefinition manifests. It likely involves innovative techniques to overcome traditional limitations of PASS, such as handling distortions in panoramic images and the scarcity of annotated data. This redefinition might entail a new conceptual framework, perhaps decomposing the problem into sub-tasks or adopting a multi-task learning strategy. The core contribution could lie in advanced geometric reasoning or using sophisticated deep learning architectures like transformers. Success would be measured by improvements in accuracy, efficiency, and robustness, potentially demonstrated on benchmark datasets. The redefined PASS could also incorporate novel geometric representations of the 3D scene for better contextual understanding or seamlessly integrate depth information. Ultimately, this redefinition aims to make PASS more practical for real-world applications by addressing key challenges in perception and scene understanding.
Geometric Deep Dive#
A hypothetical section titled “Geometric Deep Dive” in a research paper would likely involve a detailed exploration of how geometric principles and representations are leveraged to enhance the capabilities of a model. This could include a discussion of how 3D geometric information, such as point clouds or meshes, is incorporated into the model’s architecture. Specific techniques might involve the use of novel geometric loss functions, efficient data structures to handle 3D data, or specialized neural network layers designed to handle the unique challenges associated with 3D geometric data. The section would likely also address the methods used for incorporating geometric data into various model components such as encoders, decoders, or attention mechanisms. The effectiveness of the geometric approach would need to be thoroughly evaluated, perhaps through comparisons with non-geometric baselines, demonstrating improvements in accuracy or robustness. Furthermore, any limitations or shortcomings of the geometric approach, along with potential future directions for improvement, would likely be discussed, showcasing the work’s overall contribution to the field.
Hybrid Decoder#
The concept of a ‘Hybrid Decoder’ in the context of a panoramic semantic segmentation model suggests a powerful and flexible approach. It likely combines the strengths of different decoding architectures to overcome limitations inherent in processing panoramic imagery. A common strategy would be to merge a high-resolution branch, which preserves fine-grained detail crucial for object recognition, with a transformer-based context module. The transformer excels at capturing long-range dependencies and global contextual information, vital for understanding the spatial relationships between objects within a wide field of view. This combination addresses challenges of distortion and scale variations inherent in panoramic images. The high-resolution branch handles smaller objects and details missed by the global context module, while the transformer resolves ambiguities and improves segmentation accuracy by leveraging the broader image context. This hybrid approach is expected to offer improved accuracy and robustness compared to using either branch alone. By effectively combining the merits of multiple decoding methods, the hybrid decoder provides a more holistic understanding of the scene, enabling more precise and complete semantic segmentation of indoor panoramic images.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper provides crucial evidence supporting the study’s claims. A strong benchmark focuses on comparing the proposed method against state-of-the-art techniques using widely-accepted datasets and metrics. Quantitative results, presented with clarity and precision, including metrics like mean Intersection over Union (mIoU) and precision/recall, should form the core of this section. It is vital to carefully select relevant metrics that directly assess the method’s strengths and accurately reflect its performance. Furthermore, a robust benchmark should address potential weaknesses. The section needs to discuss the limitations of the methodology and datasets, acknowledging factors affecting the results such as dataset size, diversity, and noise. Qualitative analysis, such as visual comparisons of segmented images, offers valuable insight and enhances the understanding of the quantitative findings. By including such details, this section strengthens the overall credibility and impact of the research.
Future of PASS#
The future of Panoramic Semantic Segmentation (PASS) hinges on addressing current limitations. Improving the efficiency and scalability of current models is crucial, particularly when dealing with high-resolution panoramic images. Developing more robust methods for handling the inherent distortions and variations in panoramic data, such as those from different camera types or environmental conditions, is also key. Furthermore, exploring novel geometric representations beyond those currently used could significantly enhance accuracy, especially in complex scenes with multiple overlapping objects. Integrating PASS with other vision tasks, like depth estimation and object detection, in a unified framework will improve scene understanding and enable new applications in areas such as autonomous driving and augmented reality. Finally, the creation of larger, more diverse datasets, particularly those with comprehensive annotations that account for real-world scenarios, is critical for training highly accurate and generalizable PASS models. Ultimately, the success of PASS depends on a concerted effort in these areas, leading to broader adoption across various fields.
More visual insights#
More on figures
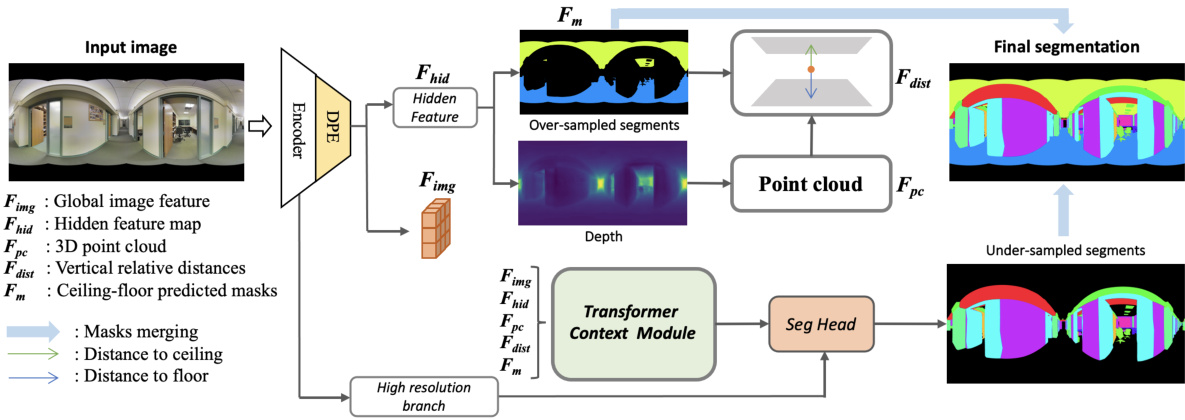
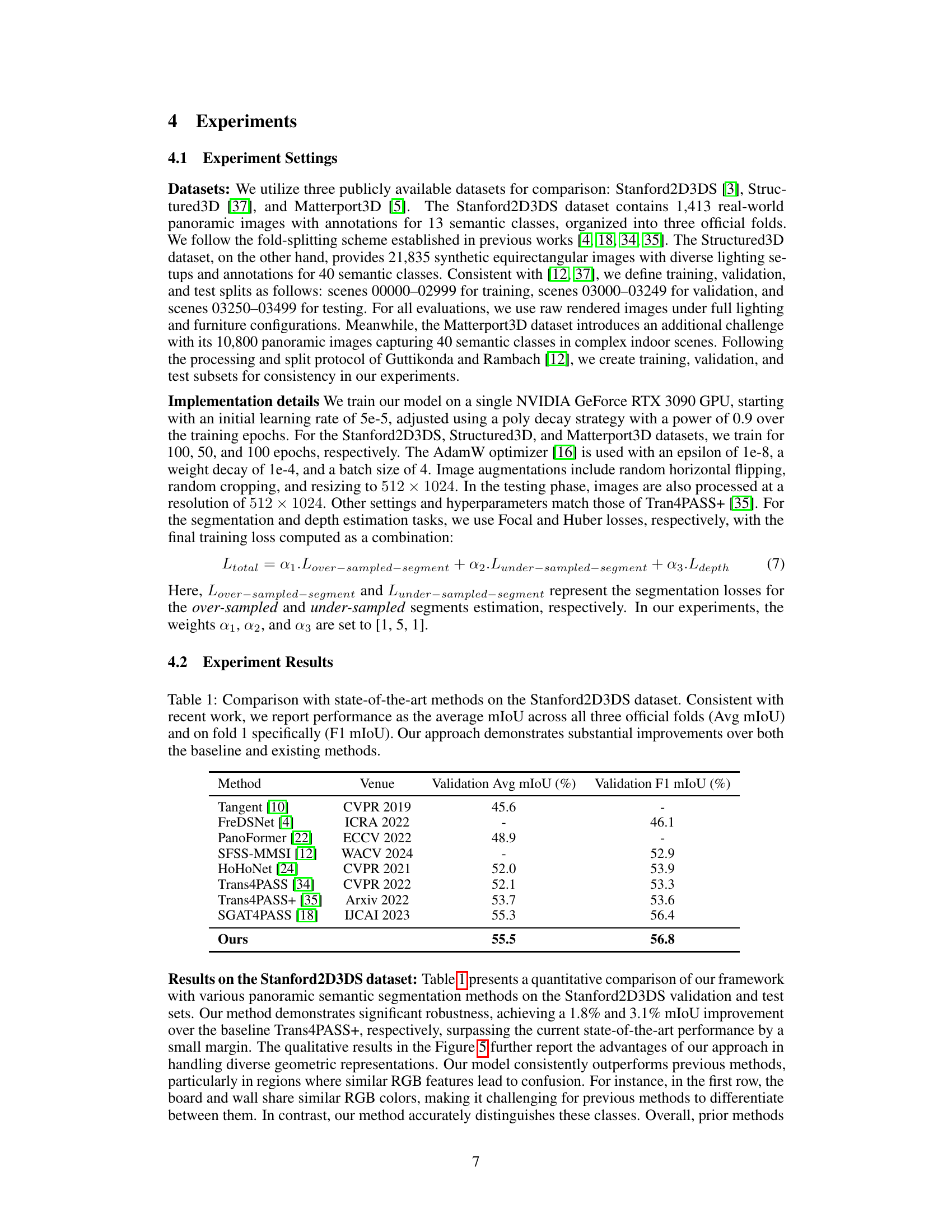
🔼 This figure illustrates the overall architecture of the proposed method for indoor panoramic semantic segmentation. It consists of three main parts: an encoder that processes the input image and generates feature maps, a branch focusing on over-sampled segments (like floors and ceilings) which also estimates depth, and a hybrid decoder that combines high-resolution features with a transformer-based context module to estimate the under-sampled segments. The process concludes by merging the segment estimations to create the final segmentation map.
read the caption
Figure 2: The proposed framework consists of three main modules: an encoder for extracting image features, a branch that estimates over-sampled segments alongside dense depth estimation, and a hybrid decoder for estimating under-sampled segments before a merging process to obtain the final segmentation result.

🔼 This figure illustrates the proposed method for panoramic semantic segmentation. The input is a panoramic image, which is divided into two groups: over-sampled segments (floor and ceiling), and under-sampled segments (other scene elements such as chairs, tables, etc.). The over-sampled segments are enhanced using a depth estimation task, and the under-sampled segments are estimated using a transformer-based context module that leverages the geometric properties of the scene. Finally, the estimated segments are merged to produce the final segmentation result.
read the caption
Figure 1: Panoramic segmentation problem can be re-formulated to the estimation of over-sampled segments: floor, ceiling and under-sampled segments: chair, table, bookcase, window, etc.
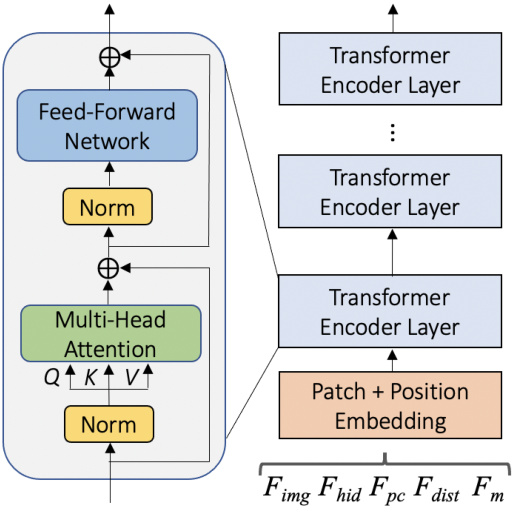
🔼 This figure shows the architecture of the transformer-based context module, a key component of the hybrid decoder in the proposed framework for Indoor Panoramic Semantic Segmentation. The module integrates multiple geometric representations of the scene, including the global image feature (Fimg), hidden features from the over-sampled segment estimation (Fhid), 3D point cloud (Fpc), vertical relative distances (Fdist), and predicted floor-ceiling masks (Fm). These features are concatenated and fed into a stack of transformer encoder layers to capture contextual relationships and geometric information. The output of the context module is then combined with features from a high-resolution branch to produce refined semantic masks for the under-sampled segments.
read the caption
Figure 4: Transformer based context module

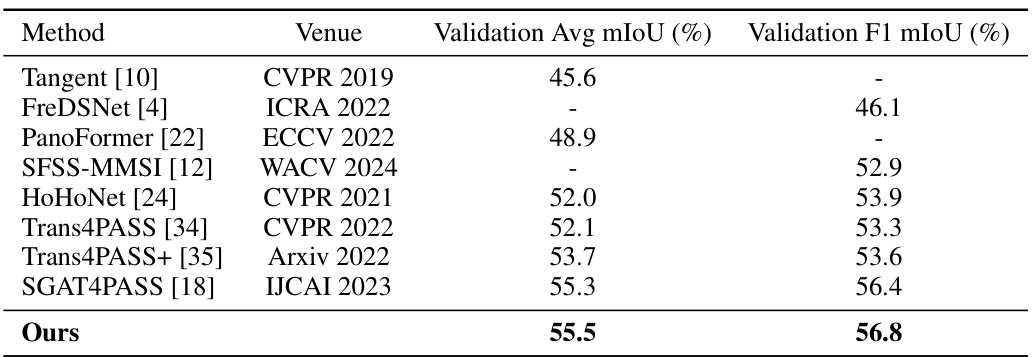
🔼 This figure displays a qualitative comparison of semantic segmentation results on the Stanford2D3D dataset. It shows the results from three different methods: Trans4PASS+, SGAT4PASS, and the authors’ proposed method. The ground truth segmentation is also included for comparison. Black boxes highlight the areas where the authors’ method shows improvement over the other two methods. The images show that the authors’ method achieves better segmentation, especially in areas with complex geometric structures and smaller objects.
read the caption
Figure 5: Qualitative comparison of semantic segmentation results from Trans4PASS+ [35], SGAT4PASS [18], and ours using the Stanford2D3D dataset. Black boxes highlight the improvements. Zoom for the better view.

🔼 This figure compares the qualitative results of semantic segmentation on the Stanford2D3DS dataset between three different methods: Trans4PASS+, SGAT4PASS, and the proposed method in the paper. The figure shows several example images alongside their respective segmentation masks generated by each method. The black boxes highlight areas where the proposed method shows improvement over the other two. The comparison emphasizes the ability of the proposed method to handle more complex and diverse indoor scenes by accurately segmenting smaller and more intricate objects compared to baseline methods.
read the caption
Figure 5: Qualitative comparison of semantic segmentation results from Trans4PASS+ [35], SGAT4PASS [18], and ours using the Stanford2D3D dataset. Black boxes highlight the improvements. Zoom for the better view.

🔼 This figure shows a qualitative comparison of semantic segmentation results on the Stanford2D3D dataset, comparing the proposed method against Trans4PASS+ and SGAT4PASS. Each row presents an input image and the corresponding segmentation masks generated by each method, along with the ground truth. Black boxes highlight areas where the proposed method shows improvements. The figure demonstrates the effectiveness of the proposed approach in handling challenging scenarios, such as differentiating between objects with similar appearances (e.g., boards and walls) and accurately segmenting smaller objects, unlike previous methods which tend to focus on larger segments.
read the caption
Figure 5: Qualitative comparison of semantic segmentation results from Trans4PASS+ [35], SGAT4PASS [18], and ours using the Stanford2D3D dataset. Black boxes highlight the improvements. Zoom for the better view.

🔼 This figure illustrates the conversion process from an equirectangular image to a spherical image. It shows how a pixel (u,v) in the 2D equirectangular image projection maps to a point (ρ,θ,φ) in 3D spherical coordinates. This conversion is a crucial step in the proposed method, allowing for the use of geometric information in the panoramic semantic segmentation task. The figure also shows the relationship between the width (W) and height (h) of both the equirectangular and spherical images and how these dimensions relate to the spherical coordinate system.
read the caption
Figure 8: Convert equirectangular image to spherical image. Image is adjusted from Ai et al. [1].

🔼 This figure illustrates the overall architecture of the proposed method for indoor panoramic semantic segmentation. It comprises three main modules: an encoder to extract image features, a branch for simultaneously estimating over-sampled segments (floor and ceiling) and dense depth, and a hybrid decoder (combining a high-resolution branch and a transformer-based context module) for estimating under-sampled segments. Finally, the results from both branches are merged to produce the final segmentation.
read the caption
Figure 2: The proposed framework consists of three main modules: an encoder for extracting image features, a branch that estimates over-sampled segments alongside dense depth estimation, and a hybrid decoder for estimating under-sampled segments before a merging process to obtain the final segmentation result.

🔼 This figure shows the overall architecture of the proposed method for indoor panoramic semantic segmentation. It’s composed of three main modules: an encoder to extract image features, a branch to concurrently estimate over-sampled segments (floor and ceiling) and dense depth, and a hybrid decoder which combines a high-resolution branch and a transformer-based context module to estimate under-sampled segments. Finally, a merging step combines the over-sampled and under-sampled segment estimations to generate the final segmentation result.
read the caption
Figure 2: The proposed framework consists of three main modules: an encoder for extracting image features, a branch that estimates over-sampled segments alongside dense depth estimation, and a hybrid decoder for estimating under-sampled segments before a merging process to obtain the final segmentation result.
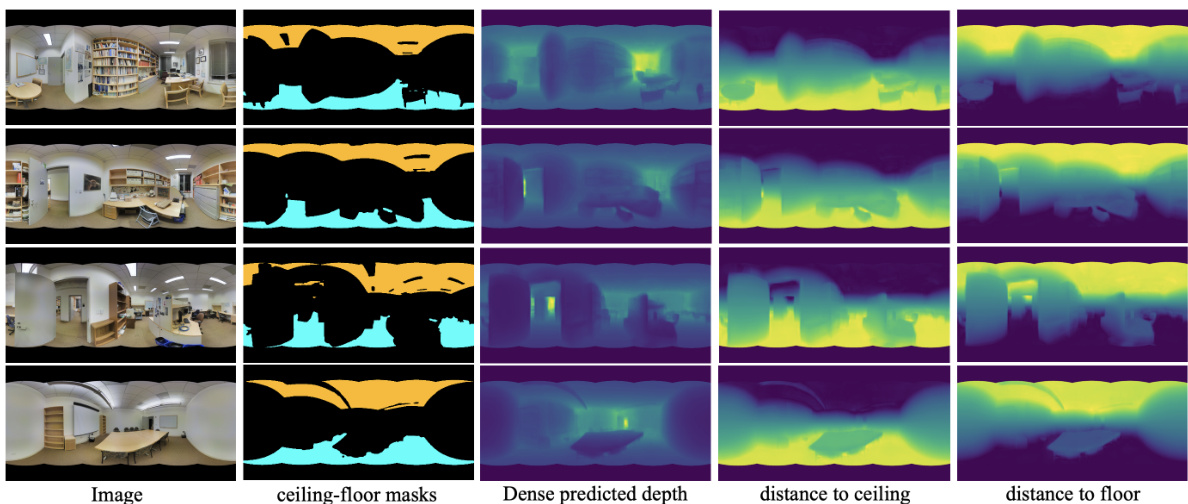
🔼 This figure shows four example images from the dataset and their corresponding ceiling and floor masks, along with the dense depth prediction and the calculated distances to ceiling and floor. The color gradients in the distance maps visually represent the distances, ranging from light (far) to dark (near). This illustrates how the proposed method effectively estimates these distances, which is crucial for differentiating between objects located at different heights in the scene. This information is utilized in the semantic segmentation process to improve performance, particularly in areas with objects positioned closely to the floor or ceiling.
read the caption
Figure 12: More examples of distance to ceiling and distance to floor masks, where light to dark colors represent distances from far to near.
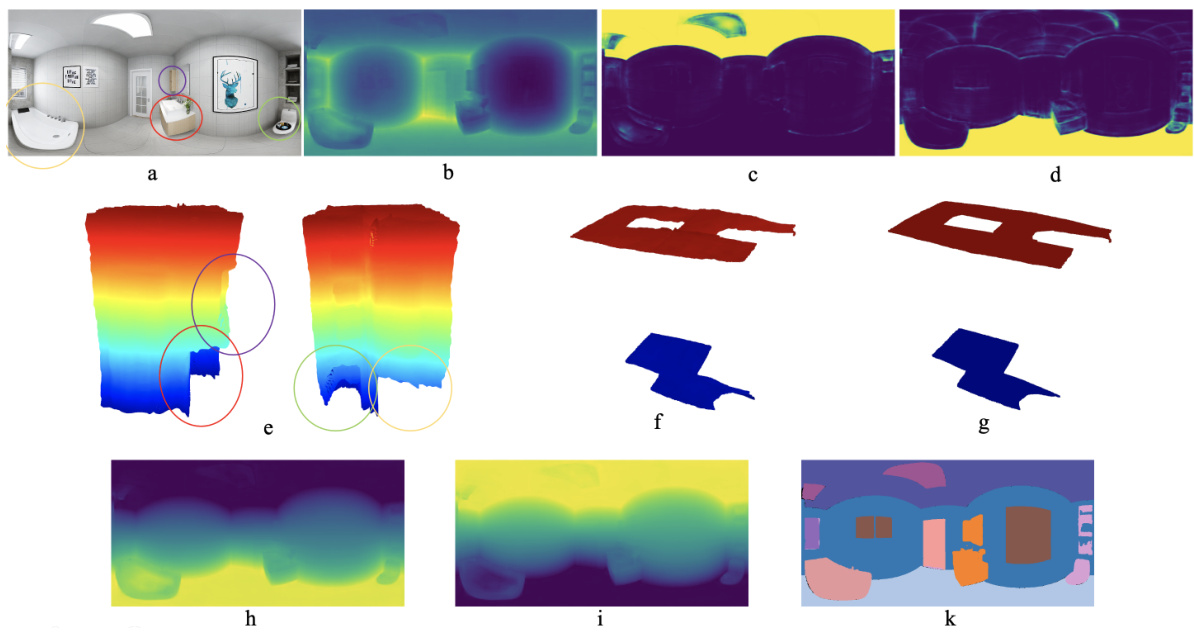
🔼 This figure visualizes the step-by-step process of the proposed method. It starts with an input image (a), then shows the predicted depth (b), ceiling mask before softmax (c), floor mask before softmax (d), and different views of the point cloud (e). Next, it shows the ceiling and floor in 3D visualization (f), the planes of the ceiling and floor in 3D coordinates (g), the distance of 3D points to the ceiling plane (h), the distance of 3D points to the floor plane (i), and finally the final segmentation (k).
read the caption
Figure 13: a) Input image. b) Predicted depth. c) Ceiling mask before softmax. d) Floor mask before softmax. e) Different views of pointcloud constructed from predicted depth. f) Ceiling and floor in 3D visualization. g) Planes of ceiling and floor in 3D coordinates after applying least square method. h) Distance of 3D points to ceiling plane. i) Distance of 3D points to floor plane. k) Final segmentation.
More on tables

🔼 This table compares the performance of the proposed method’s depth estimation with FreDSNet [35] using several metrics: Mean Relative Error (MRE), Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), logarithmic RMSE (RMSElog), and three relative accuracy measures (δ₁, δ₂, δ₃). Lower values for MRE, MAE, and RMSE indicate better accuracy, while higher values for δ₁, δ₂, and δ₃ are better.
read the caption
Table 2: Quantitative comparison of depth estimation task.
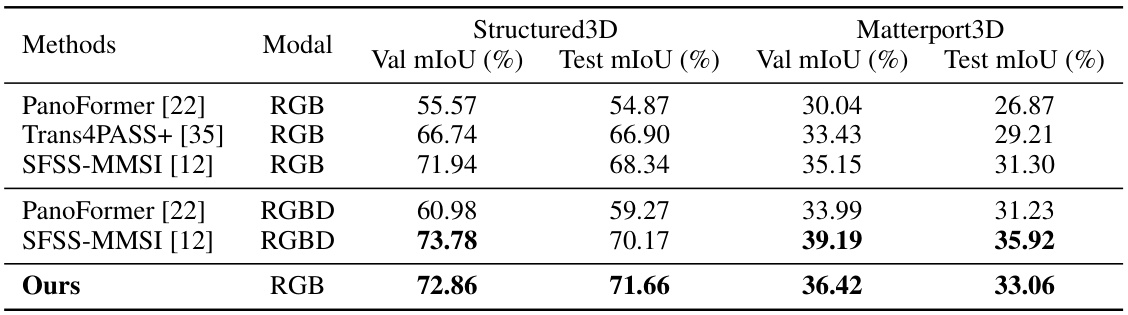
🔼 This table compares the performance of the proposed method against state-of-the-art (SOTA) methods on two benchmark datasets for panoramic semantic segmentation: Structured3D and Matterport3D. The comparison is done using both RGB and RGBD modalities. The table shows that the proposed method achieves new state-of-the-art results on both datasets, surpassing previous methods in terms of mean Intersection over Union (mIoU) on both validation and test sets.
read the caption
Table 3: Comparison with the SOTA methods on the Structured3D and the Matterport3D validation and test sets. Our method marks new state of the arts on both datasets given the same input.

🔼 This table presents the ablation study results on the Stanford2D3DS dataset (fold 1). It shows the effect of adding different geometric properties (Fhid, Fpc, Fdist, Fm) to the input of the transformer-based context module on the model’s performance, measured by mIoU and Pixel Accuracy. The baseline uses only the global image feature (Fimg). The results demonstrate the incremental improvement in performance as more geometric information is incorporated.
read the caption
Table 4: Impact of each geometric representation to the model performance.

🔼 This table compares the proposed method’s performance on the Stanford2D3DS dataset against other state-of-the-art methods. It shows the mean Intersection over Union (mIoU) scores, both averaged across all three folds and specifically for fold 1. The results highlight the superior performance of the proposed approach.
read the caption
Table 1: Comparison with state-of-the-art methods on the Stanford2D3DS dataset. Consistent with recent work, we report performance as the average mIoU across all three official folds (Avg mIoU) and on fold 1 specifically (F1 mIoU). Our approach demonstrates substantial improvements over both the baseline and existing methods.
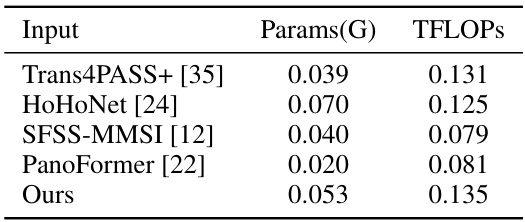
🔼 This table compares the number of parameters and TFLOPs (floating point operations per second) for different models used for panoramic semantic segmentation. It provides a measure of the computational cost of each model, indicating the model’s size and processing power needed for training and inference.
read the caption
Table 6: Computational complexity comparison with input size: 512 × 1024 × 3.
Full paper#