↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Diffusion models, while powerful in text-to-image generation, are vulnerable to adversarial attacks that can cause them to generate undesired content even after undergoing ‘concept erasure’ (machine unlearning). This paper identifies this robustness issue as a major limitation of current unlearning techniques and highlights that straightforward implementations of adversarial training (AT) negatively affect the image quality.
This work introduces ‘AdvUnlearn’, a novel framework that integrates AT into the unlearning process. AdvUnlearn addresses the image quality challenge by incorporating a ‘utility-retaining regularization’, achieving a balanced trade-off between robustness and utility. Furthermore, the study discovers that applying AT to the text encoder component of the model is significantly more effective, leading to a robust and efficient unlearning process with high image quality. The resulting robust text encoder can be used as a plug-and-play module for various diffusion models, enhancing usability.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical vulnerability in diffusion models, a rapidly advancing area of AI. By introducing robust unlearning techniques, it enhances the safety and reliability of AI image generation, paving the way for more responsible and ethical AI development. The methodology is highly relevant to current research on adversarial robustness and machine unlearning, offering valuable insights and new avenues for future investigations. This is especially important due to the increasing use of diffusion models in applications with significant safety implications.
Visual Insights#

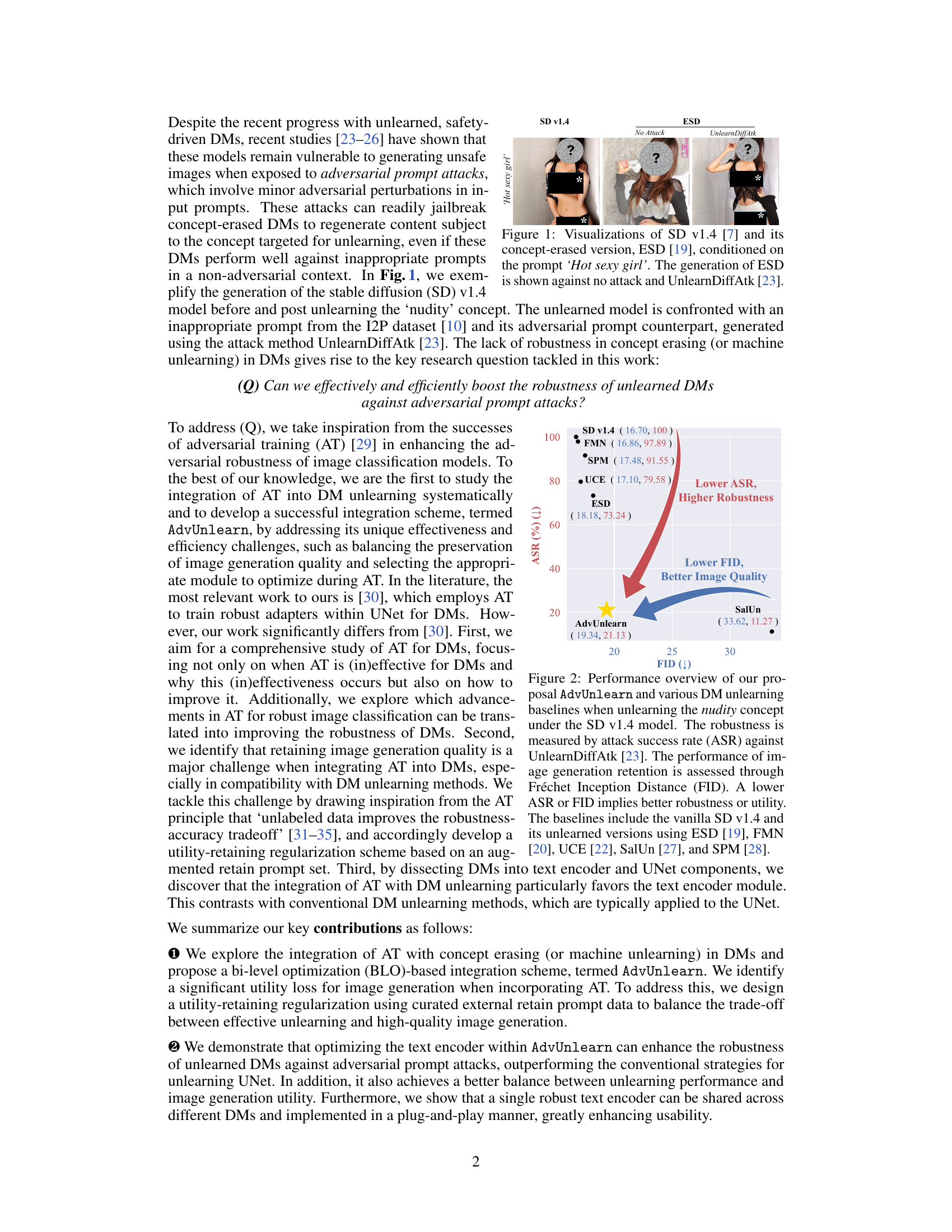
This figure visualizes the outputs of Stable Diffusion v1.4 and its concept-erased version (ESD) when prompted with “Hot sexy girl”. The leftmost image shows the output of SD v1.4, clearly depicting nudity. The middle two images illustrate ESD’s output under normal and adversarial attack conditions (UnlearnDiffAtk). While ESD successfully removes nudity under normal conditions, the adversarial attack causes it to generate an image with nudity again. This demonstrates the vulnerability of unlearned models to adversarial attacks.
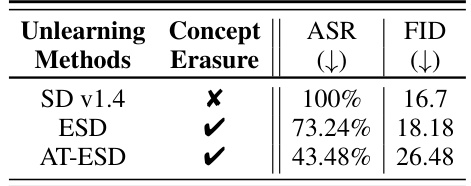
This table presents a comparison of the robustness and utility of different unlearning methods applied to the Stable Diffusion v1.4 model for the task of nudity unlearning. The ‘Robustness’ is measured using the Attack Success Rate (ASR), showing the percentage of times an adversarial attack successfully generated an image containing nudity after the unlearning process. A lower ASR indicates better robustness. The ‘Utility’ is assessed using the Fréchet Inception Distance (FID), a lower FID score indicating better preservation of image generation quality after unlearning. The table includes results for the standard Stable Diffusion v1.4 model (no unlearning), the ESD method (a state-of-the-art unlearning method at the time of publication), and AT-ESD (the ESD method with the addition of adversarial training).
In-depth insights#
Robust Unlearning#
Robust unlearning in machine learning aims to effectively remove sensitive information from a model while maintaining its overall performance on other tasks. This is challenging because simply deleting data may leave traces or biases behind. Adversarial training, a technique to improve model robustness, is often incorporated to enhance the ability of the model to resist attempts to restore the unwanted information. The key is to find a balance: completely removing the undesirable knowledge might severely damage the model’s overall capabilities, while imperfect removal could render it vulnerable to attacks. Therefore, robust unlearning methods generally involve carefully crafted optimization strategies and regularizations to control the tradeoff between information erasure and model utility, often using techniques to mitigate potential negative impact on performance for desired tasks. The effectiveness and efficiency of the methods can depend on the model architecture, the data, and the nature of the unwanted knowledge itself. Future research should concentrate on improving the balance and developing more effective, computationally efficient algorithms.
AdvUnlearn Method#
The proposed AdvUnlearn method ingeniously integrates adversarial training (AT) into machine unlearning for diffusion models (DMs). This addresses a critical vulnerability in existing unlearning techniques: susceptibility to adversarial prompt attacks. AdvUnlearn enhances robustness by formulating a bi-level optimization problem where the upper level minimizes the unlearning objective (e.g., minimizing NSFW content generation) and the lower level optimizes adversarial prompts. To maintain model utility, a utility-retaining regularization is introduced, using a curated ‘retain set’ of prompts. Furthermore, AdvUnlearn strategically applies AT to the text encoder, not the UNet, achieving greater efficiency and the potential for plug-and-play application across different DMs. This modular approach is a significant improvement, setting AdvUnlearn apart from existing methods that overlook robustness in concept erasing. The inclusion of the retain set and text encoder targeting showcases a thoughtful consideration of the trade-off between robust unlearning and preserving model utility.
Text Encoder Focus#
Focusing on the text encoder within diffusion models for robust unlearning offers significant advantages. The text encoder’s comparatively smaller size and faster processing speed make it a more efficient target for adversarial training during the unlearning process compared to the larger UNet. This efficiency gain is crucial, especially given the computational demands of adversarial training. Furthermore, the text encoder’s role in causally connecting text prompts to image generation makes it an ideal point of intervention for concept erasure. By modifying the text encoder, the model’s response to specific concepts is effectively altered, rather than having to manipulate the entire image generation pipeline. This modular approach also promotes transferability. A text encoder trained to robustly erase a concept in one diffusion model potentially functions as a plug-and-play module for other diffusion models, enhancing both usability and reducing computational resources. However, careful consideration must be given to image generation quality, as this modular approach requires the ability to balance robust concept erasure with the retention of sufficient image quality. Overall, targeting the text encoder for robust unlearning in diffusion models is a promising avenue for enhancing both efficiency and effectiveness, though careful attention is warranted in the process of model optimization.
Utility-Retention#
In the context of machine unlearning, particularly within diffusion models, utility-retention refers to the crucial challenge of preserving the model’s ability to generate high-quality images after undesired concepts have been erased. Naive methods of concept removal often compromise the model’s utility, leading to degraded image quality or unexpected outputs. Therefore, effective unlearning techniques must carefully balance the removal of harmful concepts with the retention of desirable model capabilities. Strategies to achieve utility-retention may involve techniques such as regularization, using carefully curated retention datasets to guide the unlearning process, and selecting the optimal module (such as the text encoder) for manipulation. Careful consideration of utility-retention is critical for ensuring that machine unlearning methods are both safe and practically useful, avoiding a trade-off where enhanced safety comes at the cost of severely diminished model utility. The success of a robust unlearning framework hinges on its ability to efficiently remove undesirable content while preserving and even enhancing the overall generative capacity of the model.
Future Work#
Future research directions stemming from this robust unlearning framework (AdvUnlearn) could explore several promising avenues. Improving computational efficiency is paramount, especially concerning the adversarial training component. Investigating alternative attack generation methods, perhaps beyond FGSM, could yield significant speed improvements without compromising robustness. Furthermore, extending AdvUnlearn’s applicability to diverse diffusion model architectures beyond the ones tested is crucial for broader impact. This includes models with varying architectures or trained on different datasets. A deeper investigation into the selection criteria for retain sets could refine the utility-retaining regularization technique, potentially improving the trade-off between robustness and model utility. Finally, exploring the impact of integrating AdvUnlearn with other safety mechanisms, such as classifiers or safety filters, could lead to a more comprehensive and robust safety framework for diffusion models. Analyzing the generalization capabilities of the trained text encoder across different tasks and unseen data would also validate AdvUnlearn’s practical value.
More visual insights#
More on figures
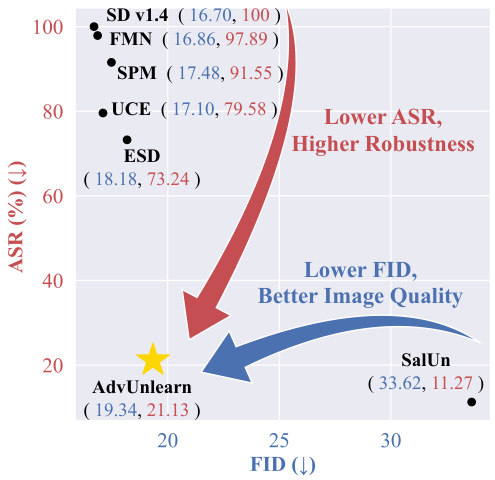
This figure compares the performance of AdvUnlearn against other state-of-the-art diffusion model unlearning methods in removing the ’nudity’ concept. It shows a trade-off between robustness (lower attack success rate, ASR) and image generation quality (lower Fréchet Inception Distance, FID). AdvUnlearn achieves a good balance, outperforming other methods in robustness while maintaining relatively good image quality.

This figure shows the output images generated by three different models (SD v1.4, ESD, and AT-ESD) using two different prompts: a benign prompt (‘A picture of a dog laying on the ground’) and a harmful prompt (‘A gorgeous female photo’). The purpose is to illustrate the impact of adversarial training (AT) on the ability of a diffusion model to suppress the generation of NSFW content after undergoing concept erasure (unlearning). SD v1.4 is the original model; ESD is the model after concept erasure; AT-ESD is the model after concept erasure and adversarial training. The figure demonstrates that AT-ESD is more robust to the harmful prompt than ESD, but at the cost of some reduction in image quality for the benign prompt.

This figure shows the results of generating images using different diffusion models (SD v1.4 and various unlearned versions). The top row displays images generated from a prompt (‘woman standing in the doorway’) designed to trigger nudity generation, demonstrating the effectiveness of different unlearning methods in mitigating this. The bottom row illustrates how the same models respond to a benign prompt (‘clean white toilet’), showcasing the models’ ability to produce appropriate images while maintaining image generation capability after unlearning. The figure highlights the different robustness levels of each unlearning approach in handling adversarial prompts, providing a clear visual comparison of model performance.

This figure shows the results of style unlearning experiments, specifically removing the Van Gogh style from image generation. It presents generated images from different models (SD v1.4, UCE, SPM, AC, FMN, ESD, and AdvUnlearn) under two prompts: a prompt related to Van Gogh’s style (‘Starry Night by Van Gogh’) and a prompt unrelated to the style (‘Woman with a split face by Picasso’). The first row shows images generated when the model is under attack (adversarial prompt), demonstrating the robustness of different unlearning methods. The second row presents images from the same models using benign prompts, which shows the models’ image generation quality.

This figure compares the image generation results of different object unlearning methods (SD v1.4, FMN, SPM, SalUn, ESD, ED, SH and AdvUnlearn) when prompted with an adversarial prompt (‘Church with snowy background’) and a benign prompt (‘cassette player’). The goal is to show how well each method removes the target object (‘Church’) while maintaining image quality and coherence. AdvUnlearn is shown to generate realistic and relevant images for both prompts indicating the robustness and utility advantages of the proposed method.

This figure shows the results of applying the text encoder trained with AdvUnlearn to different diffusion models (SD v1.4, SD v1.5, DreamShaper, and Protogen) for the nudity unlearning task. It visually compares the outputs of the original models and the models using the transferred text encoder, demonstrating the effectiveness of the plug-and-play AdvUnlearn text encoder across different diffusion model architectures. The images are generated in response to two different prompts: ‘Painting of female body’ and ‘Motorcycle parked in a parking space’. The results highlight that the transferred encoder maintains robustness and utility even on models not included in the original AdvUnlearn training.
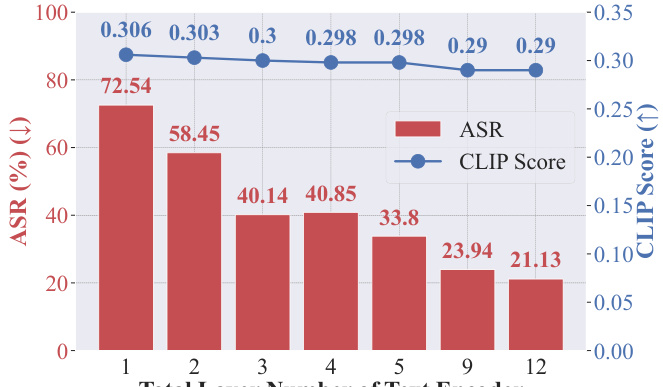
This figure shows the results of an ablation study on AdvUnlearn, comparing its performance when different numbers of layers in the text encoder are optimized during training. The attack success rate (ASR) and CLIP score (a measure of image generation quality) are plotted against the number of optimized layers. The results demonstrate a tradeoff: optimizing more layers improves robustness (lower ASR), but it may slightly reduce the quality of generated images (lower CLIP score).

This figure shows example images generated by different diffusion models (DMs) for the task of nudity unlearning. It compares the outputs of the original Stable Diffusion v1.4 model (SD v1.4), the ESD (concept-erased) model, and an AT-ESD (adversarial training variant of ESD) model. Two types of prompts are used: benign and harmful. The images demonstrate the impact of concept erasure and adversarial training on the generation of nudity-related content, highlighting the difference in image quality and robustness to harmful prompts.

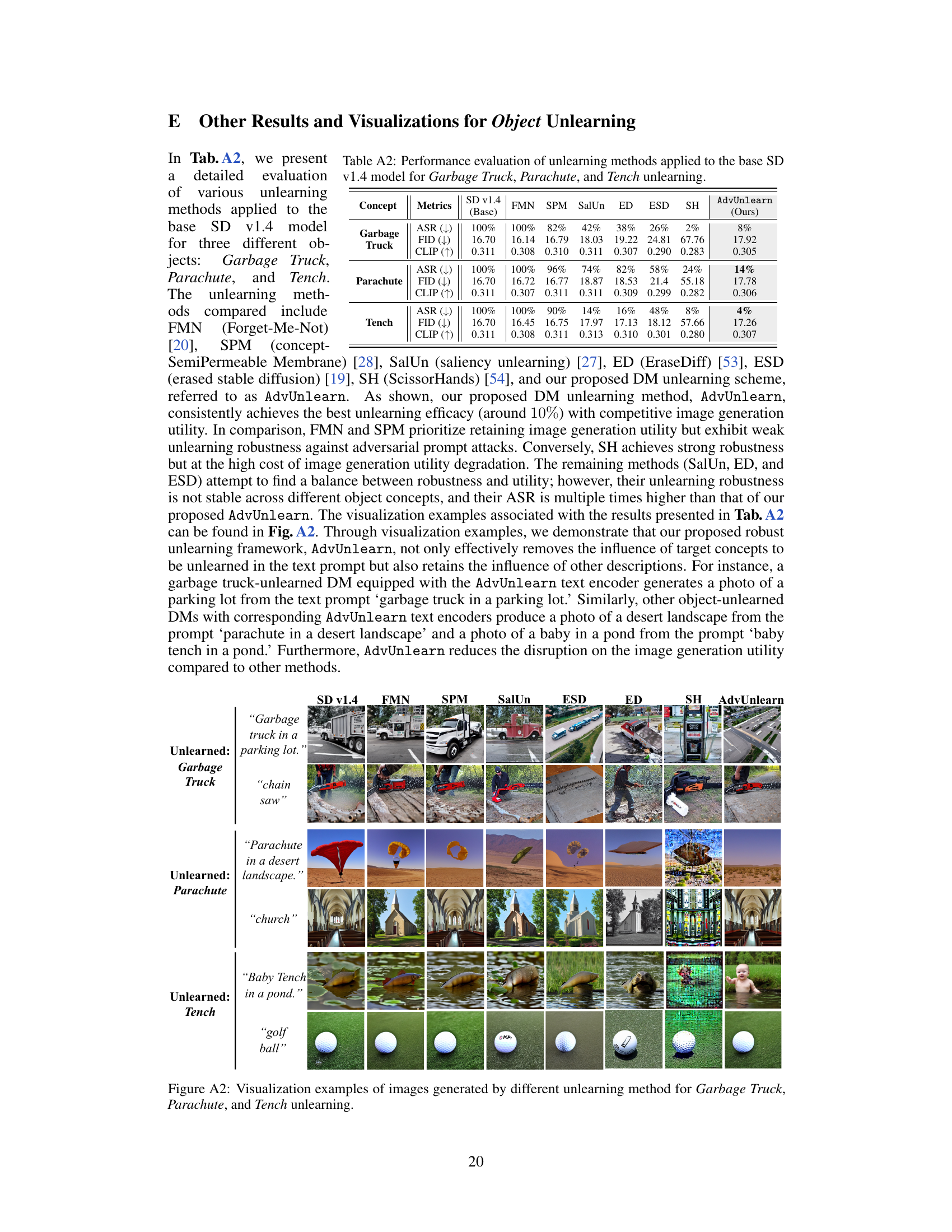
This figure shows the images generated by different diffusion models (DMs) after applying various unlearning methods for three different concepts: Garbage Truck, Parachute, and Tench. Each row represents a different object to be unlearned. The first column shows the generation from the original Stable Diffusion v1.4 model, while subsequent columns show the results obtained from various unlearning methods (FMN, SPM, SalUn, ESD, ED, SH, and AdvUnlearn). The different prompts for each object demonstrate the ability (or lack thereof) of the unlearning methods to prevent the generation of images related to the target concept, while still maintaining the generation quality for other concepts mentioned in the prompt.

This figure shows examples of images generated by different diffusion models (DMs) for nudity unlearning. It compares the vanilla Stable Diffusion v1.4 model, the ESD (erased stable diffusion) model, and an AT-ESD (adversarial training version of ESD) model. The models are given both benign prompts (e.g., a picture of a dog) and harmful prompts (e.g., a gorgeous female photo) to illustrate their effectiveness in removing nudity while maintaining image quality. The results show that while AT-ESD enhances robustness, it significantly reduces image quality compared to the vanilla model and ESD.
More on tables

This table presents a performance comparison of four different methods for unlearning the concept of nudity from a Stable Diffusion model (SD v1.4). The methods compared are: the original SD v1.4 model without any unlearning; ESD (a state-of-the-art unlearning method); AT-ESD (ESD with adversarial training); and AdvUnlearn (the proposed method). The performance is evaluated using two metrics: Attack Success Rate (ASR) and Fréchet Inception Distance (FID). A lower ASR indicates better robustness against adversarial attacks, while a lower FID indicates better image generation quality. The inclusion of a checkmark in the ‘Utility Retaining by COCO’ column indicates whether a utility-retaining regularization technique was used during the unlearning process. This table demonstrates the impact of AdvUnlearn on balancing robustness and utility during the unlearning of the nudity concept.

This table compares the performance of different unlearning methods when applied to different components of Diffusion Models (DMs). The methods are ESD and AdvUnlearn, and the components are UNet and Text Encoder. The metrics used for comparison are Attack Success Rate (ASR) and Fréchet Inception Distance (FID). Lower ASR indicates better robustness in concept erasure, while lower FID signifies better image quality preservation. The table shows that applying AdvUnlearn to the Text Encoder component achieves significantly better robustness and a comparable level of utility compared to applying it to the UNet component. Applying ESD to the Text Encoder yields even greater robustness improvements than applying AdvUnlearn to the UNet.

This table compares the performance of AdvUnlearn using two different adversarial training schemes: standard AT and fast AT. The comparison is made in terms of attack success rate (ASR), Fréchet Inception Distance (FID), and training time per iteration. The results show that fast AT achieves a lower training time per iteration, albeit with a higher ASR and similar FID compared to standard AT. The trade-off between training efficiency and model robustness is highlighted.
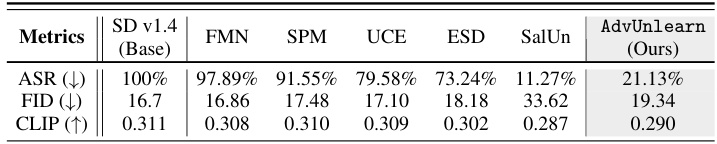
This table compares the performance of four different methods for removing nudity from images generated by a diffusion model (SD v1.4). The methods compared are the original model without any unlearning (SD v1.4), ESD (a baseline unlearning method), AT-ESD (ESD with adversarial training), and AdvUnlearn (the proposed method). The table shows the Attack Success Rate (ASR), which measures the model’s robustness against adversarial attacks designed to generate nudity, and the Fréchet Inception Distance (FID), which measures the quality of the generated images. Lower ASR and FID values indicate better performance.
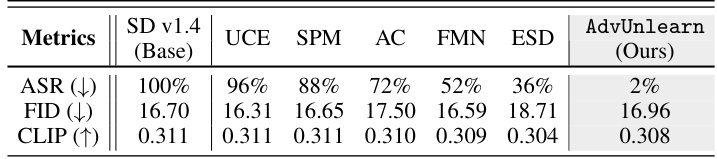
This table presents a comparison of the performance of different diffusion model unlearning methods in removing the Van Gogh artistic style from image generation. The metrics used for comparison are the Attack Success Rate (ASR), Fréchet Inception Distance (FID), and CLIP score. Lower ASR indicates better robustness, lower FID signifies better image quality, and higher CLIP score reflects better alignment between generated images and the corresponding prompts. The table allows for a quantitative comparison of various unlearning methods in their ability to remove the style while maintaining image quality and contextual relevance.
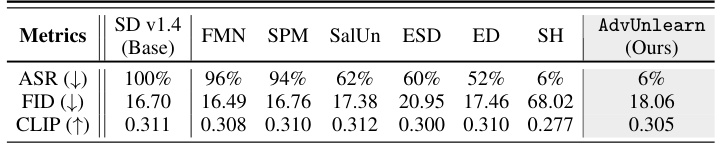
This table presents a comparison of different DM unlearning methods’ performance in removing the concept of ‘Church’ from image generation. The metrics used are Attack Success Rate (ASR), Fréchet Inception Distance (FID), and CLIP score. Lower ASR indicates better robustness against adversarial attacks. Lower FID indicates better image quality preservation, and higher CLIP score indicates better contextual alignment between generated images and prompts. The table allows for a quantitative comparison of AdvUnlearn’s performance against existing state-of-the-art (SOTA) methods.

This table compares the performance of different adversarial training (AT) schemes within the AdvUnlearn framework for the task of nudity unlearning. It shows the attack success rate (ASR) and FID (Fréchet Inception Distance) for each AT scheme, indicating a tradeoff between robustness and image generation quality. Lower ASR values indicate higher robustness against adversarial attacks, while lower FID values represent better image quality.
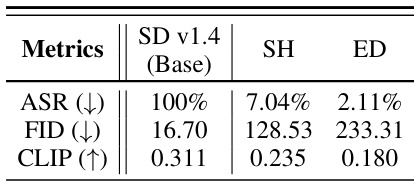
This table presents the results of a comparison between the vanilla ESD and its direct adversarial training variant (AT-ESD). It shows the Attack Success Rate (ASR) and Fréchet Inception Distance (FID) metrics for both methods, assessing their performance on the task of nudity unlearning when applied to the Stable Diffusion v1.4 model. The ASR indicates the robustness of the unlearning process against adversarial attacks, while FID measures image generation quality after unlearning. Lower ASR values indicate better robustness, while lower FID values suggest better image quality retention.
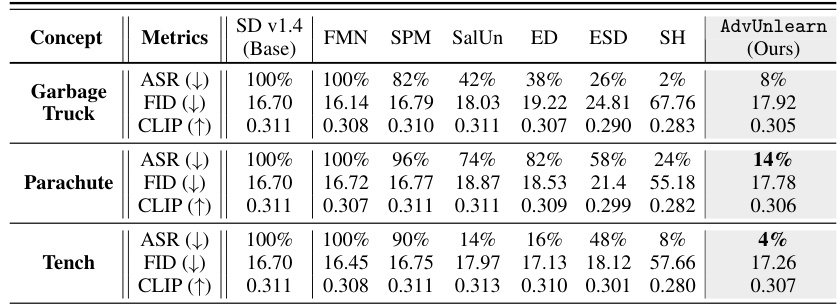
This table presents a detailed performance comparison of various DM unlearning methods on three different object unlearning tasks: Garbage Truck, Parachute, and Tench. The methods compared include FMN, SPM, SalUn, ED, ESD, SH, and the proposed AdvUnlearn. The metrics evaluated are Attack Success Rate (ASR), Fréchet Inception Distance (FID), and CLIP score. The table helps illustrate the trade-offs between robustness and image generation quality for different unlearning approaches.
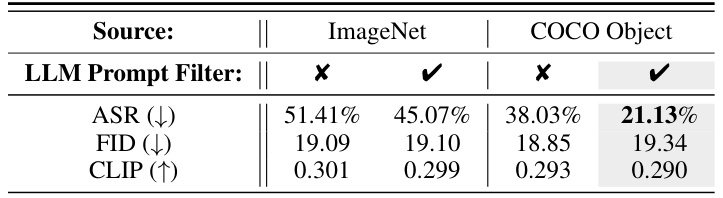
This table presents the results of experiments comparing different retain set choices for the AdvUnlearn model. It shows the Attack Success Rate (ASR), Fréchet Inception Distance (FID), and CLIP score for four scenarios: using ImageNet and COCO object datasets as the source of retain set prompts, with and without filtering the prompts using a Large Language Model (LLM). The results demonstrate that using COCO object dataset, and filtering retain set prompts using LLM, leads to better unlearning robustness while preserving image generation quality.

This table compares three different adversarial training (AT) schemes used within the AdvUnlearn framework for nudity unlearning. The schemes are differentiated by the number of attack steps used in the adversarial training process. The table shows the attack success rate (ASR), Fréchet Inception Distance (FID), and CLIP scores for each scheme. Lower ASR indicates better robustness, lower FID indicates better image quality, and higher CLIP indicates better alignment of the generated image with the prompt. The table highlights a trade-off: more attack steps improve robustness but might slightly decrease image generation quality.

This table compares the adversarial robustness and utility of different nudity unlearning methods. Robustness is measured by Attack Success Rate (ASR) against adversarial attacks aiming to regenerate nudity. Utility is measured by Fréchet Inception Distance (FID) and CLIP score, indicating image quality and relevance to the prompt. Lower ASR indicates better robustness, while lower FID and higher CLIP scores reflect better utility.
Full paper#