TL;DR#
Machine translation (MT) struggles to produce high-quality and diverse translations, as model likelihood poorly correlates with human judgments of quality. Existing methods like reranking often overfit evaluation metrics or are limited by the initial candidate set’s quality. These issues hinder the generation of truly high-quality and diverse translations.
QUEST addresses these limitations by employing a Metropolis-Hastings algorithm that samples translations from a Gibbs distribution, using quality metrics as the energy function. This approach effectively generates multiple diverse translations from high-quality regions of the distribution. Experiments across various language pairs and large language models demonstrate QUEST’s superior performance, showcasing its ability to significantly improve the quality and diversity of machine translations compared to ancestral sampling.
Key Takeaways#
Why does it matter?#
This paper is important as it tackles the critical issue of generating high-quality and diverse machine translations, a challenge faced by many researchers in NLP and MT. It introduces a novel sampling method that addresses limitations of existing approaches and shows improvements in both quality and diversity of translations, opening avenues for future research in high-quality MT and other NLP tasks involving quality-aware sampling.
Visual Insights#
🔼 This figure illustrates the QUEST algorithm’s sampling process. It begins with an existing translation (yt). An index is randomly selected, and the portion of the translation after that index is discarded. A new continuation is generated from the language model, resulting in a candidate translation. The Metropolis-Hastings algorithm then determines if this candidate is accepted or rejected based on its quality score, moving to the next iteration. This process is repeated for a set number of iterations (T).
read the caption
Figure 1: QUEST samples an index from the current translation (yt), removes all elements to the right of the index, generates a new continuation, and then uses the Metropolis-Hastings acceptance criterion to decide whether to accept or reject the resulting new translation. The process continues for a fixed number of T iterations.

🔼 This algorithm details the QUEST method for sampling high-quality and diverse translations using the Metropolis-Hastings algorithm. It starts by sampling an initial response from the language model. Then, it iteratively samples an index from the current translation, generates a new continuation from the language model, and uses the Metropolis-Hastings acceptance criterion to decide whether to accept or reject the new translation. This process continues for a fixed number of iterations, and the accepted translations are returned. Hyperparameters control temperature, burn-in period, and the Gibbs distribution.
read the caption
Algorithm 1 Quality-Aware Metropolis-Hastings (QUEST) Sampling
In-depth insights#
QUEST Sampling#
The proposed QUEST sampling method offers a novel approach to generating high-quality and diverse machine translations by leveraging automatic quality metrics. Instead of relying on maximizing likelihood or solely reranking existing translations, QUEST uses the quality metric as the energy function of a Gibbs distribution, sampling translations proportionally to their quality. The method cleverly employs the Metropolis-Hastings algorithm, a Markov Chain Monte Carlo technique, to efficiently sample from this complex distribution. This avoids the limitations of likelihood-based sampling and addresses the over-reliance on noisy quality estimates often found in reranking approaches. QUEST shows promising results across different language pairs and decoder-only LLMs, producing high-quality and diverse translations, overcoming challenges faced by traditional methods.
MCMC in MT#
This research explores the application of Markov Chain Monte Carlo (MCMC) methods, specifically Metropolis-Hastings sampling, to the problem of machine translation (MT). The core idea is to leverage automatic quality metrics, rather than relying solely on model likelihood, to guide the sampling process. This addresses the limitations of traditional approaches that often produce repetitive or low-quality translations. By using the quality metric as an energy function in a Gibbs distribution, the method generates multiple diverse translations, effectively exploring high-quality regions of the translation space. The method’s novelty lies in its proposal distribution, which efficiently samples diverse and high-quality hypotheses by combining a randomly sampled index with the completion from a language model. This approach avoids the computational burdens of exhaustive enumeration and allows for the generation of diverse, high-quality translations. Experimental results demonstrate the effectiveness of the proposed MCMC approach across multiple language pairs and strong decoder-only LLMs, outperforming ancestral sampling in terms of quality and diversity.
QE Metric Impact#
The impact of quality estimation (QE) metrics on machine translation is a double-edged sword. While metrics like COMET and BLEURT correlate well with human judgments, over-reliance on them during decoding can lead to models that optimize for the metric itself, potentially at the expense of true translation quality. This phenomenon, often called “gaming the metric,” results in translations that might score high on QE metrics but are less satisfactory to human evaluators. The study explores sampling methods to mitigate this risk, generating multiple high-quality translations and analyzing diversity. Using QE scores within a Gibbs distribution and employing Metropolis-Hastings sampling allows for exploration of a broader range of translations, reducing the risk of metric overfitting and improving output diversity, leading to higher-quality and more natural-sounding translations.
RLHF Connection#
The RLHF Connection section would explore the synergy between the proposed Quality-Aware Metropolis-Hastings (QUEST) sampling method and Reinforcement Learning from Human Feedback (RLHF). It would likely highlight how QUEST’s ability to generate diverse, high-quality translations addresses a key limitation of traditional RLHF approaches which often struggle with generating varied outputs. QUEST could be positioned as a superior sampling method for generating candidate translations within the RLHF framework, thus improving the quality of the reward model training data and ultimately, the performance of the downstream language model. The discussion might delve into how the automatic metrics used in QUEST can be integrated with human feedback in an RLHF setting, potentially improving the efficiency and efficacy of human evaluation. A key aspect would be demonstrating how QUEST avoids overfitting to the chosen metric, a problem inherent to many reward-model training paradigms. Ultimately, the RLHF Connection is expected to establish QUEST as a valuable tool in advanced MT training methods, bridging the gap between automated quality assessment and human preferences.
Future of QUEST#
The future of QUEST hinges on addressing its current limitations and expanding its capabilities. Computational efficiency is a major concern; the sequential nature of the Metropolis-Hastings algorithm makes it expensive for large-scale applications. Future work should explore alternative sampling methods or techniques to parallelize the process, perhaps leveraging advances in hardware or efficient approximation algorithms. The proposal distribution, currently focused on suffix modifications, could be generalized to allow for more diverse and impactful changes, increasing the speed of convergence to high-quality regions. Integration with more advanced quality estimation metrics is crucial; better QE metrics would reduce the risk of overfitting and lead to even higher-quality translations. The application scope could extend beyond machine translation to other NLP tasks, such as text summarization or generation, where the ability to sample high-quality and diverse outputs is equally valuable. Finally, rigorous empirical evaluation across diverse language pairs and models, using multiple quality metrics and examining the impact of various hyperparameters, is necessary to further solidify the practical impact of QUEST and identify areas for further improvement.
More visual insights#
More on figures
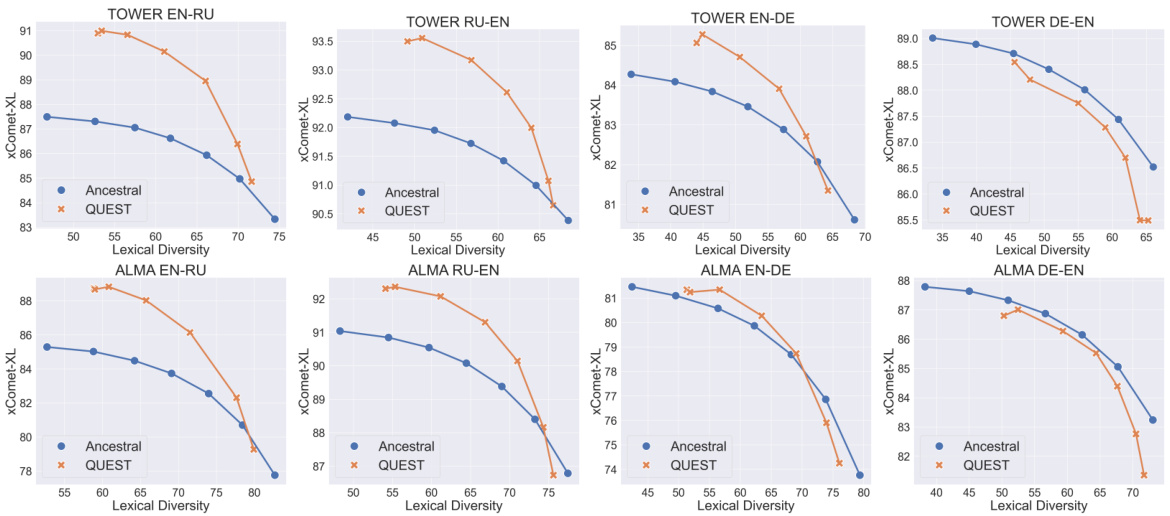
🔼 This figure compares the performance of QUEST and ancestral sampling methods on WMT23 datasets across different language pairs. Each point on the graph represents a different combination of hyperparameters used in the sampling process. The x-axis displays lexical diversity, and the y-axis shows the average quality of the generated translations as measured by xComet-XL. The results show that QUEST generally outperforms ancestral sampling in terms of quality, while achieving similar or better diversity.
read the caption
Figure 2: Average quality vs. diversity on WMT23 datasets. Different points represent different hyperparameter values. QUEST outperforms ancestral sampling in six out of eight settings.
🔼 This figure compares the performance of QUEST and ancestral sampling on eight different language pairs from the WMT23 dataset. The x-axis represents the lexical diversity, while the y-axis represents the average quality measured using the xCOMET-XL metric. Each set of four plots shows the results for different language directions (English to another language and vice versa) for two different models, TOWER and ALMA. The plots show that, for most language pairs and models, QUEST achieves better or comparable translation quality with higher lexical diversity compared to ancestral sampling. This illustrates the ability of QUEST to generate higher quality and more diverse translations compared to the baselines.
read the caption
Figure 2: Average quality vs. diversity on WMT23 datasets. Different points represent different hyperparameter values. QUEST outperforms ancestral sampling in six out of eight settings.
🔼 This figure shows the comparison results of average quality against lexical diversity between the QUEST and ancestral sampling methods on WMT23 datasets. Different points in the graph represent different hyperparameter values used in each method. The results indicate that, for six out of eight dataset and model combinations, QUEST achieved superior quality-diversity trade-offs compared to ancestral sampling.
read the caption
Figure 2: Average quality vs. diversity on WMT23 datasets. Different points represent different hyperparameter values. QUEST outperforms ancestral sampling in six out of eight settings.
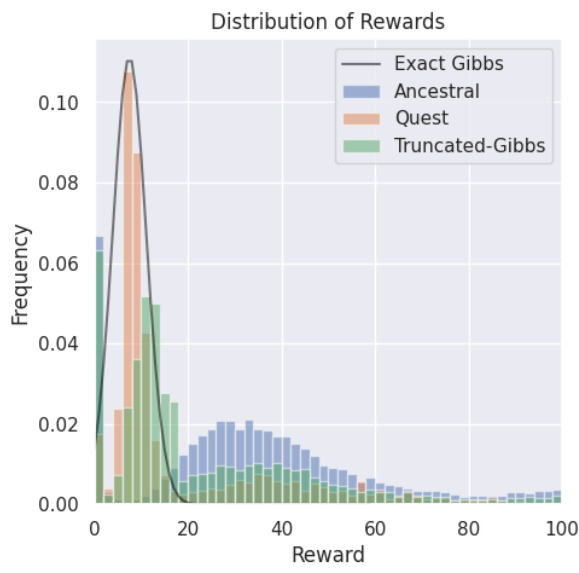
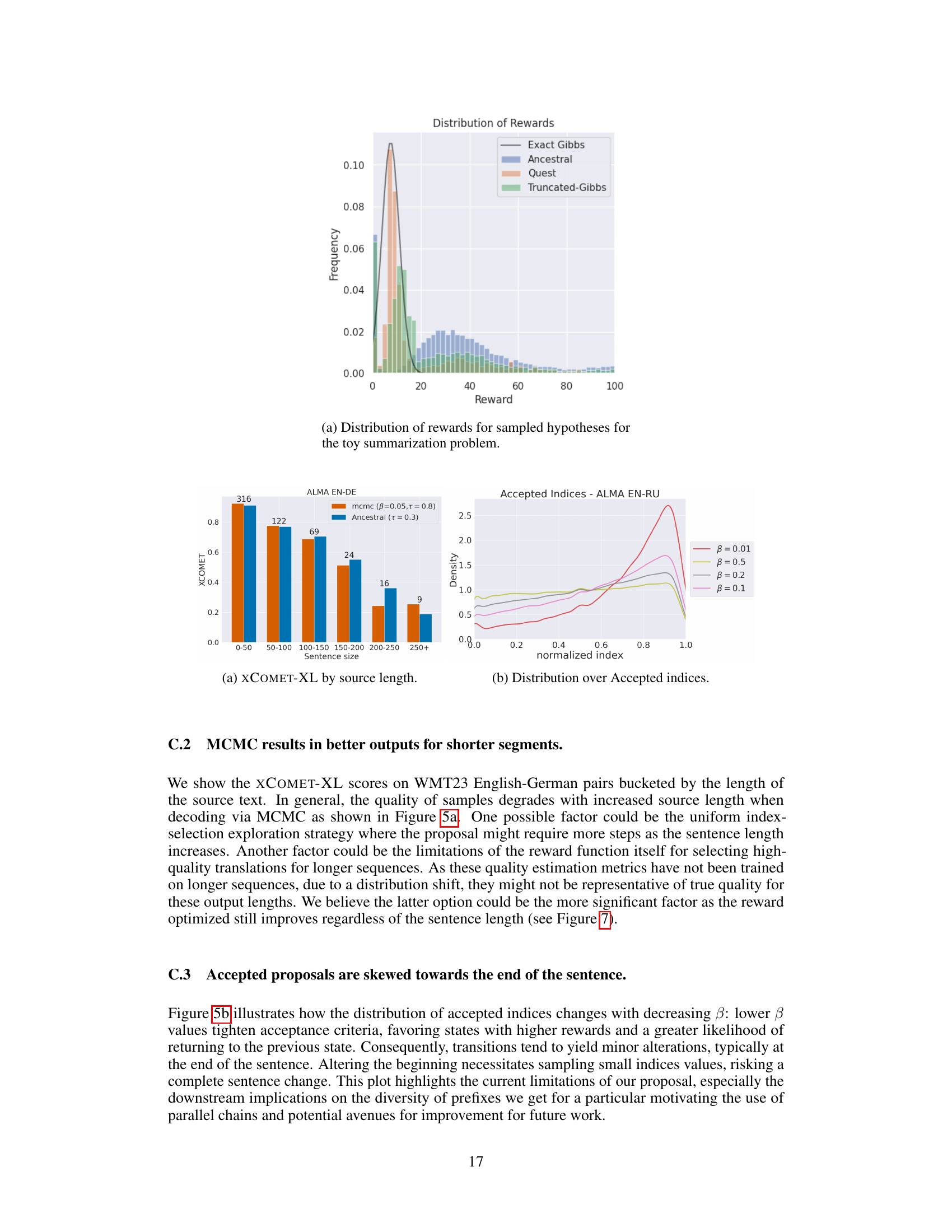
🔼 This figure shows the distribution of rewards obtained from different sampling methods in a toy summarization problem where the ground truth reward is known. The methods compared are: Exact Gibbs (the true distribution), Ancestral sampling, QUEST sampling, and Truncated-Gibbs sampling. The x-axis represents the reward, and the y-axis represents the frequency. The figure illustrates that QUEST sampling provides a better approximation of the true reward distribution, outperforming Ancestral and Truncated Gibbs sampling, which tend to sample from lower reward regions.
read the caption
Figure 4: Distribution of rewards for sampled hypotheses for the toy summarization problem.

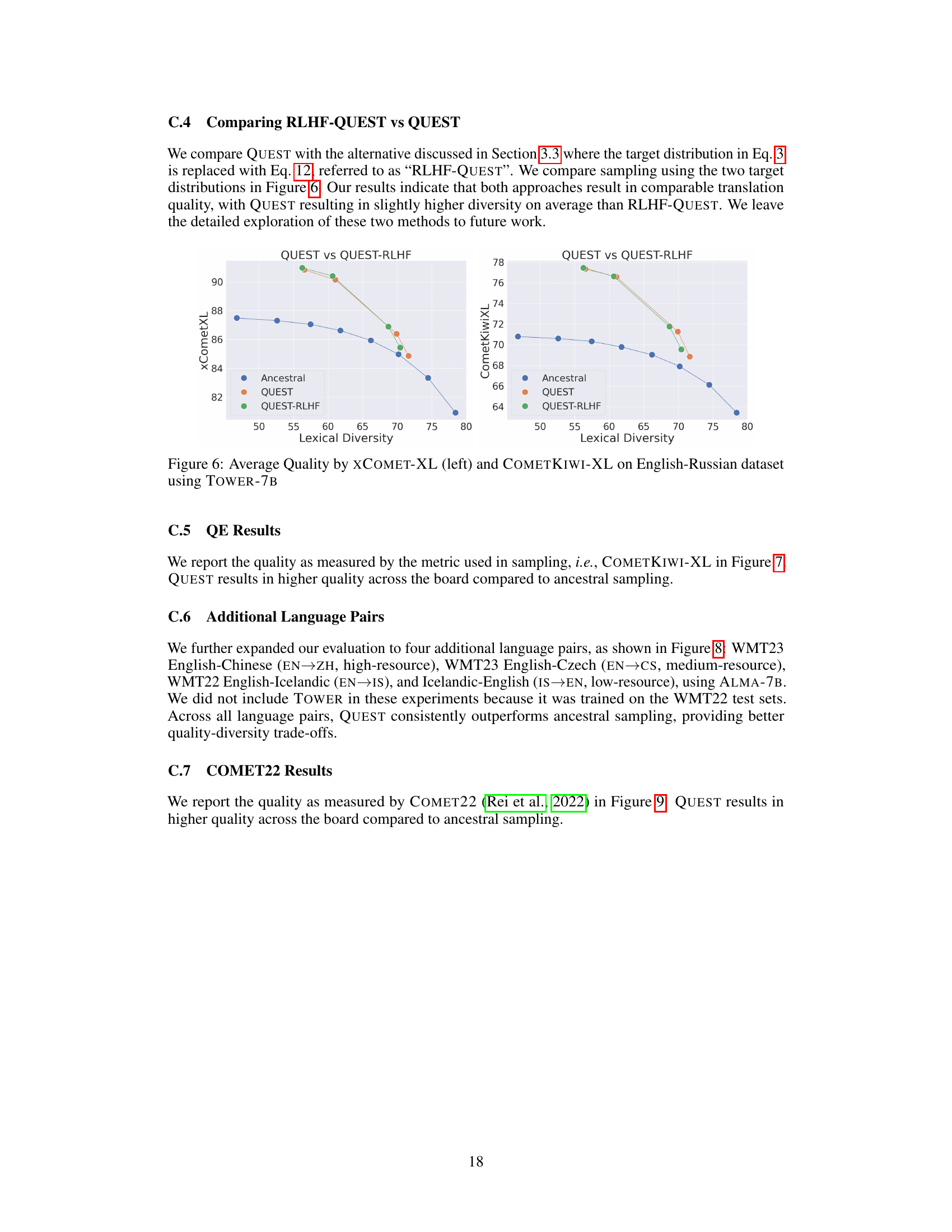
🔼 This figure shows the trade-off between the average quality of translations (measured by XCOMET-XL) and their lexical diversity (measured by PAIRWISE-BLEU) on several language pairs from the WMT23 dataset. Different points on the graph represent different hyperparameter settings used in the QUEST and ancestral sampling methods. The results illustrate how QUEST achieves better trade-offs, typically showing better quality and diversity compared to ancestral sampling.
read the caption
Figure 5: Average quality (XCOMET-XL) vs. diversity (PAIRWISE-BLEU) on WMT23 datasets. Different points represent different hyperparameter values.

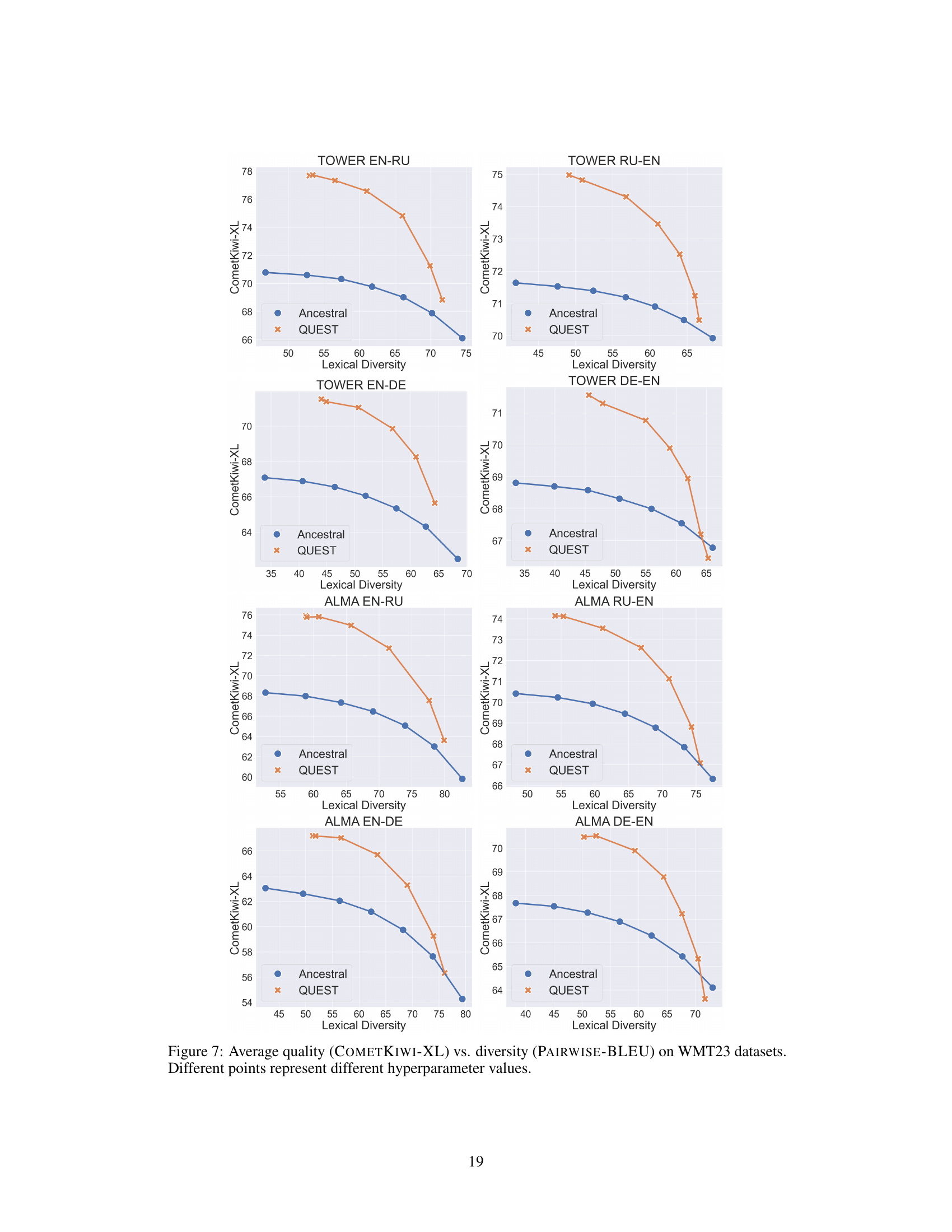
🔼 This figure compares the performance of three different methods: Ancestral sampling, QUEST, and RLHF-QUEST, across different levels of lexical diversity. Both the XCOMET-XL (left panel) and COMETKIWI-XL (right panel) metrics are used to evaluate translation quality. The results show that QUEST generally outperforms ancestral sampling in terms of quality, and that RLHF-QUEST offers comparable performance to QUEST. The x-axis represents lexical diversity, while the y-axis shows the average quality score.
read the caption
Figure 6: Average Quality by XCOMET-XL (left) and COMETKIWI-XL on English-Russian dataset using TOWER-7B

🔼 This figure compares the performance of QUEST and ancestral sampling methods for machine translation on the WMT23 benchmark across various language pairs and model settings. The x-axis represents lexical diversity, which is a measure of the variety of words used in the generated translations. The y-axis shows the average quality of the translations, as measured by the COMET-XL metric. Each point represents a different set of hyperparameters used in the sampling process. The figure demonstrates that QUEST generally produces higher-quality translations with comparable diversity compared to the ancestral sampling method.
read the caption
Figure 2: Average quality vs. diversity on WMT23 datasets. Different points represent different hyperparameter values. QUEST outperforms ancestral sampling in six out of eight settings.

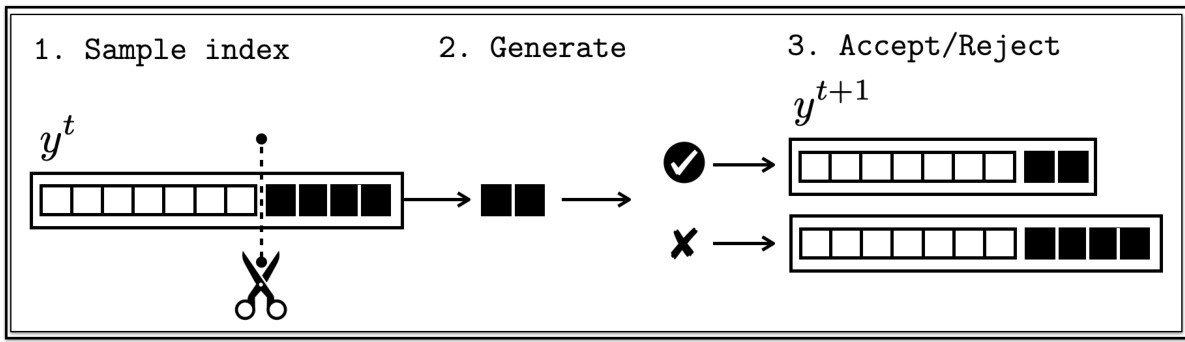
🔼 This figure displays the trade-off between translation quality and lexical diversity achieved by the QUEST and ancestral sampling methods across different language pairs from the WMT23 benchmark. The x-axis represents lexical diversity, calculated using pairwise BLEU scores, indicating the variety of translations produced. The y-axis shows the average translation quality measured using the COMETKIWI-XL metric. Each plot corresponds to a specific language pair and model (TOWER or ALMA). Multiple points in each plot correspond to different hyperparameter settings, showcasing the effect of hyperparameter tuning on the quality-diversity trade-off. The figure highlights the performance of QUEST in achieving higher quality translations while maintaining reasonable diversity compared to ancestral sampling.
read the caption
Figure 7: Average quality (COMETKIWI-XL) vs. diversity (PAIRWISE-BLEU) on WMT23 datasets. Different points represent different hyperparameter values.

🔼 This figure compares the performance of QUEST and ancestral sampling on eight different language pairs from the WMT23 dataset. The x-axis represents lexical diversity, a measure of how different the generated translations are from each other. The y-axis represents the average quality of the generated translations, measured using COMET-XL. Each point on the graph represents a different setting of hyperparameters used in the sampling methods. The results show that QUEST generally achieves higher quality than ancestral sampling, particularly in six out of the eight language pair settings. This suggests that QUEST is more effective at generating high-quality and diverse translations.
read the caption
Figure 2: Average quality vs. diversity on WMT23 datasets. Different points represent different hyperparameter values. QUEST outperforms ancestral sampling in six out of eight settings.
Full paper#