↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The brain refines its neural structures even before sensory input, through spontaneous activity resembling noise. This process’s impact on machine learning is unclear; existing methods like backpropagation have biological implausibility issues due to weight transport, and feedback alignment is data-intensive and underperforms.
This study investigates pretraining neural networks with random noise, emulating prenatal brain activity. The researchers found that this significantly improves learning efficiency and generalization, comparable to backpropagation, by modifying forward weights to better match backward feedback. It also reduces weight dimensionality and meta-loss, enabling the network to learn simpler solutions and adapt readily to various tasks. This simple, yet efficient, method overcomes issues of existing techniques, offering a fast and robust approach to pretraining.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in neural networks and related fields because it presents a novel and biologically plausible pretraining method that significantly improves learning speed and robustness. It addresses the weight transport problem, a major hurdle in applying backpropagation biologically, and opens new avenues for exploring pre-training techniques and understanding brain development.
Visual Insights#
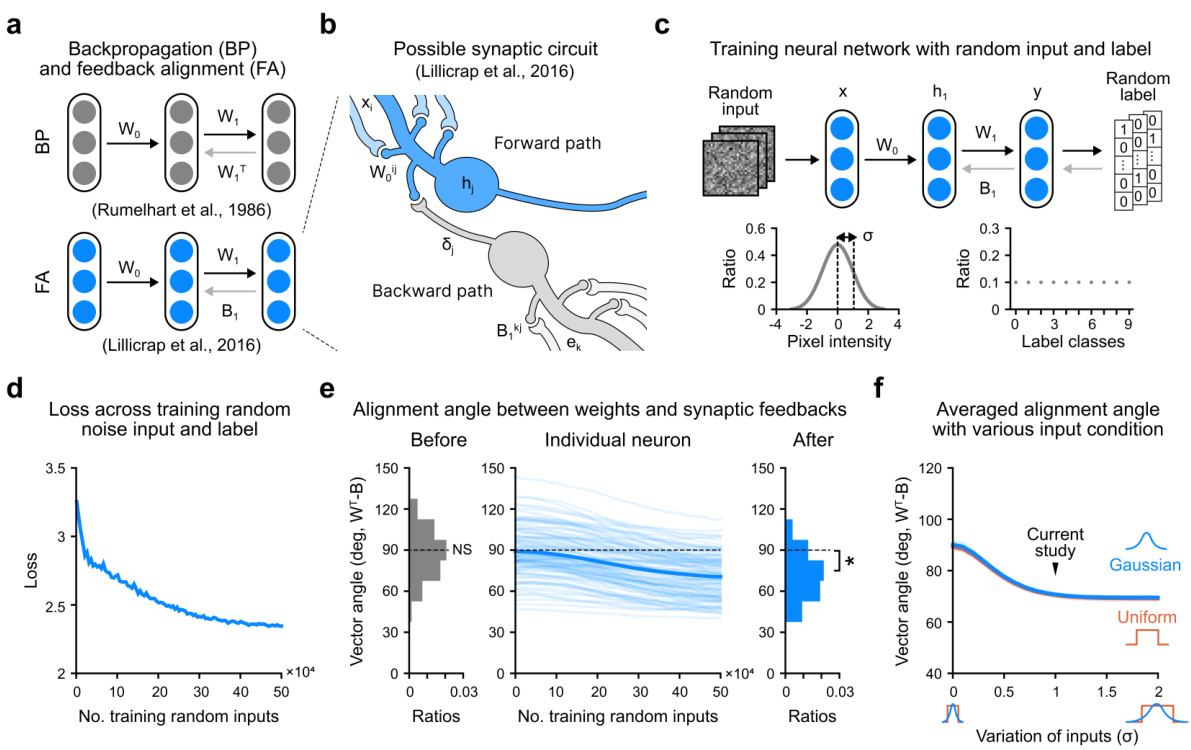
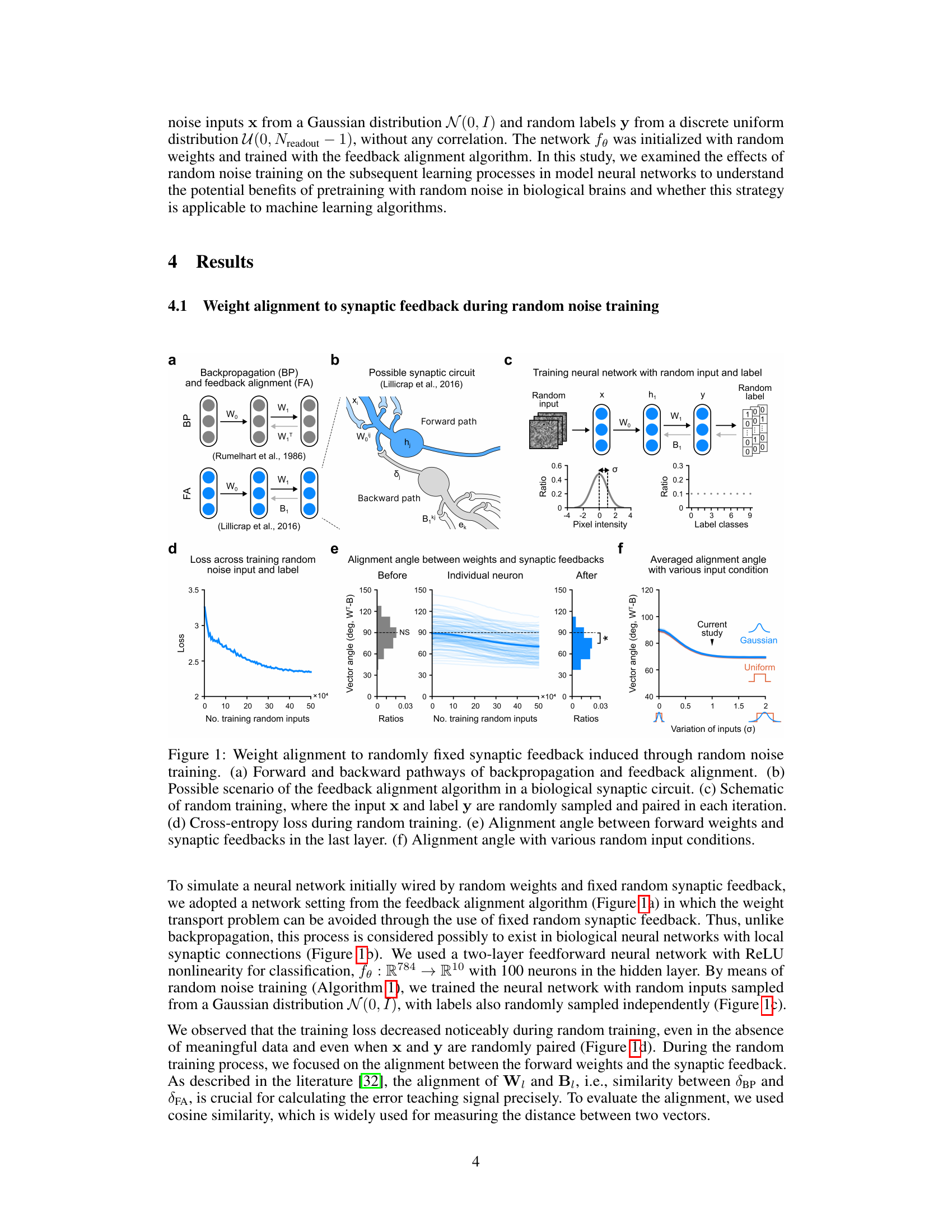
This figure shows the results of experiments on weight alignment during random noise training using a neural network with feedback alignment. Panel (a) compares the pathways of backpropagation and feedback alignment. Panel (b) illustrates a possible biological interpretation of the feedback alignment mechanism. Panel (c) details the random input and label generation process. Panel (d) plots the cross-entropy loss during random noise training. Panels (e) and (f) show the alignment angle between forward weights and synaptic feedback weights at different stages of training and under various input conditions. The results demonstrate that random noise training aligns the network weights to the fixed random feedback weights.

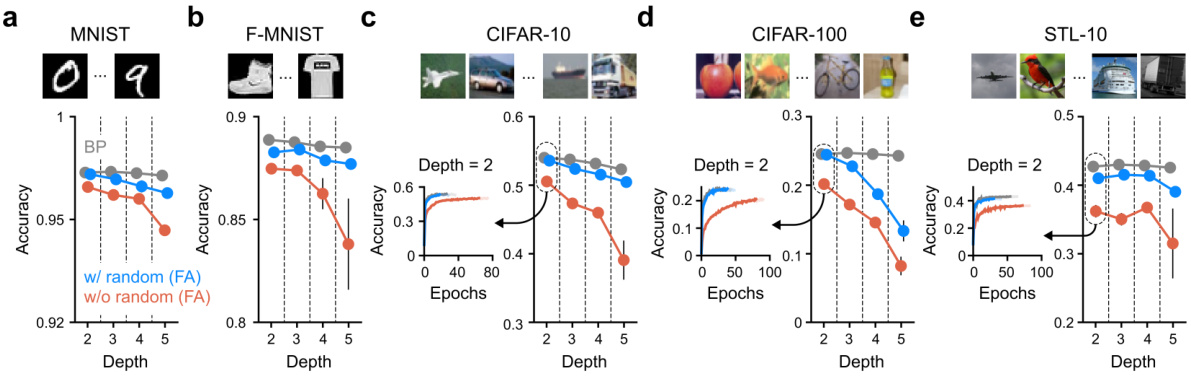
This table presents the classification accuracy of a two-layer neural network model on five different image datasets: MNIST, Fashion-MNIST, CIFAR-10, CIFAR-100, and STL-10. The accuracy is shown for three different training methods: backpropagation (BP), feedback alignment without random noise pretraining (w/o), and feedback alignment with random noise pretraining (w/). Each result is the average of three trials, with the standard deviation provided to indicate variability. The table also notes that more extensive results using networks of varying depths are available in the Appendix.
In-depth insights#
Noise Pre-training#
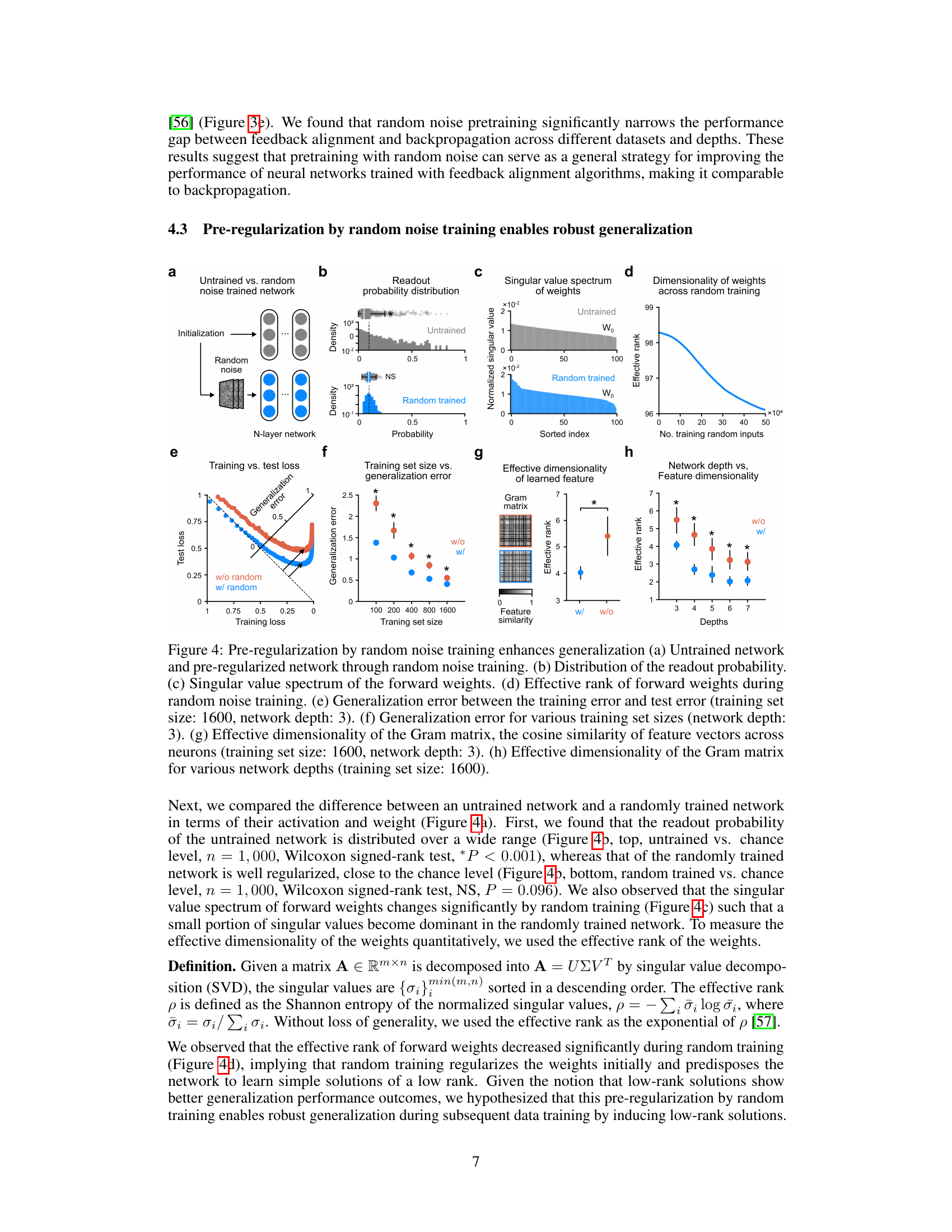
The concept of ‘Noise Pre-training’ in the context of neural networks is fascinating. It proposes leveraging random noise during a pre-training phase to improve the learning efficiency and robustness of the network. This approach is particularly intriguing given its potential biological plausibility, mirroring the brain’s spontaneous neural activity before sensory input. The method appears to work by pre-aligning the network’s forward weights to match the backward feedback signals, thus facilitating efficient error propagation during subsequent training. This pre-alignment reduces the need for weight transport, a key challenge in biologically-inspired learning algorithms. Furthermore, noise pre-training seems to act as a form of pre-regularization, decreasing the effective dimensionality of weights and promoting learning of simpler, low-rank solutions, which generally leads to better generalization. The results suggest that this strategy can enhance both in-distribution and out-of-distribution generalization, leading to faster learning and improved robustness. This method may hold the key to developing more efficient and biologically plausible neural network training paradigms.
Feedback Alignment#
Feedback alignment offers a biologically plausible alternative to backpropagation for training deep neural networks. Unlike backpropagation, which relies on the computationally expensive and biologically implausible process of weight transport, feedback alignment uses fixed, random feedback weights to transmit error signals. This simplifies the learning process and makes it more biologically realistic. While feedback alignment generally performs less accurately than backpropagation, studies show that pretraining networks with random noise significantly improves feedback alignment’s performance, approaching levels comparable to backpropagation. This suggests that random noise might mimic the brain’s spontaneous neural activity during development, which plays a crucial role in establishing efficient network structures. The mechanism involves modifying forward weights to better align with feedback signals, thus enhancing error correction and learning efficiency. This alignment improves generalization, allowing for better performance on unseen data and robust handling of novel out-of-distribution samples. Therefore, feedback alignment, especially when coupled with random noise pretraining, presents a promising avenue for developing more biologically realistic and efficient deep learning algorithms.
Weight Alignment#
The concept of weight alignment is central to understanding how feedback alignment (FA) works as a biologically plausible alternative to backpropagation. In FA, random feedback weights are used instead of copying forward weights, and successful learning depends on the forward weights aligning with the transpose of these random feedback weights. This alignment, achieved during training, allows for effective error propagation, mimicking backpropagation’s functionality without needing the biologically implausible weight transport. The paper investigates how pretraining a network with random noise influences weight alignment. The authors hypothesize and demonstrate that this pre-training aligns forward weights to match feedback weights more effectively, leading to faster learning and improved generalization performance. This alignment is not simply a result of random chance; the study shows a directional shift in weights during training towards better alignment, which is crucial for the success of the FA algorithm. Random noise pretraining acts as a form of pre-regularization, leading to simpler solutions and enhanced robustness in the network’s ability to generalize to unseen data. The resulting weight alignment thus appears to be a key factor for the effectiveness of noise-based pre-training in this deep learning context.
Robust Generalization#
The concept of “Robust Generalization” in machine learning centers on building models that maintain high accuracy even when faced with unseen data or noisy inputs. This is crucial because real-world data is often messy and differs from training datasets. The paper likely explores techniques to achieve this, potentially including regularization methods that prevent overfitting, data augmentation to expose the model to various data variations, and ensemble methods to combine predictions from multiple models. It might also investigate the impact of feature selection or dimensionality reduction to focus on the most relevant and stable features. A key aspect is likely the evaluation of generalization performance using metrics beyond simple accuracy, such as uncertainty quantification or robustness to adversarial attacks. The role of pre-training, perhaps with random noise as suggested by the paper’s title, could be a significant contributor, potentially leading to models that are more adaptable and less sensitive to minor data deviations. Ultimately, the research aims to improve the reliability and trustworthiness of machine learning models in real-world applications.
Fast Task Learning#
Fast task learning, a critical aspect of artificial intelligence, seeks to enable systems to rapidly adapt and master new tasks. This contrasts with traditional approaches that often require extensive training data and time. The core challenge lies in efficiently transferring knowledge or skills acquired from previous tasks to accelerate learning on subsequent ones. Approaches to fast task learning often leverage techniques like transfer learning, where pre-trained models on large datasets are fine-tuned for specific tasks; meta-learning, focusing on learning how to learn and optimizing learning strategies themselves; and few-shot learning, aiming to achieve high performance with minimal training examples. The success of fast task learning depends on the inherent transferability of knowledge between tasks, the effectiveness of the knowledge transfer mechanisms, and the design of algorithms that facilitate efficient adaptation. Further research is crucial to improve the speed, accuracy, and robustness of fast task learning, ideally bridging the gap between artificial intelligence systems and biological learning capabilities. The goal is to create AI agents that demonstrate human-like adaptability and rapid skill acquisition.
More visual insights#
More on figures
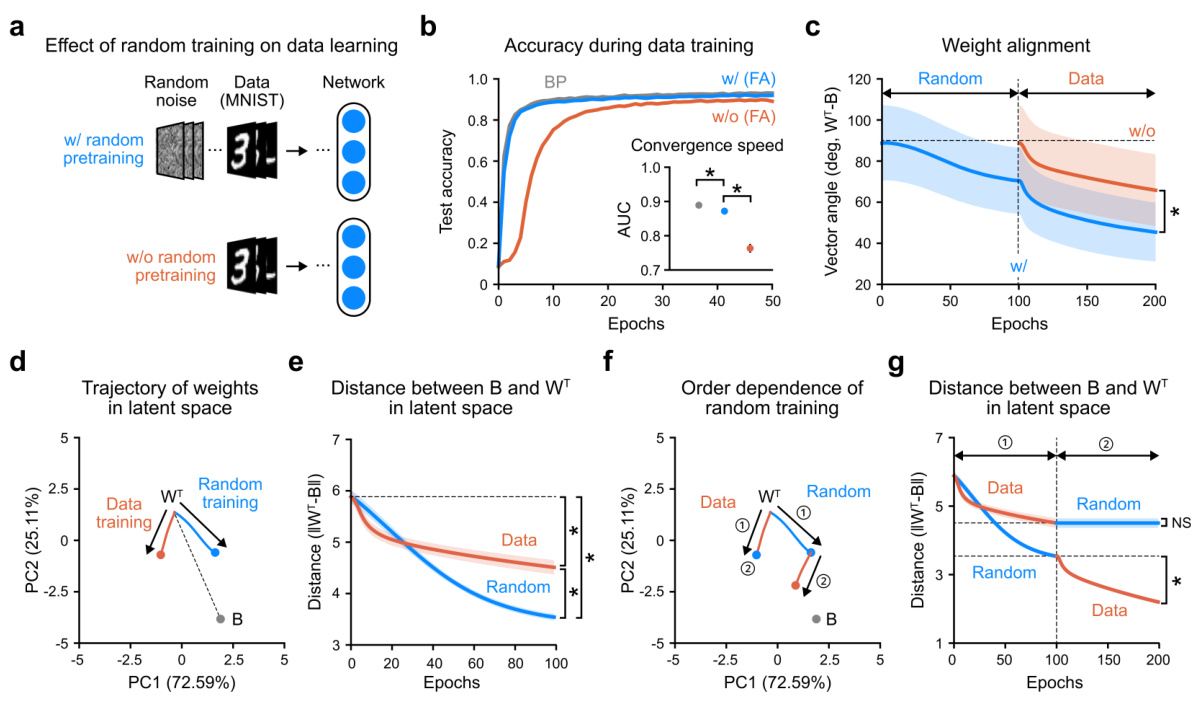
This figure demonstrates the effect of random noise pretraining on weight alignment to synaptic feedback. Panel (a) shows the difference between backpropagation and feedback alignment, highlighting the weight transport problem solved by feedback alignment. Panel (b) illustrates the biological plausibility of this mechanism. Panel (c) depicts the process of random noise pretraining. Panel (d) shows the cross-entropy loss during training. Panel (e) shows the alignment angle between forward weights and synaptic feedback. Panel (f) shows the effect of various input conditions on alignment.
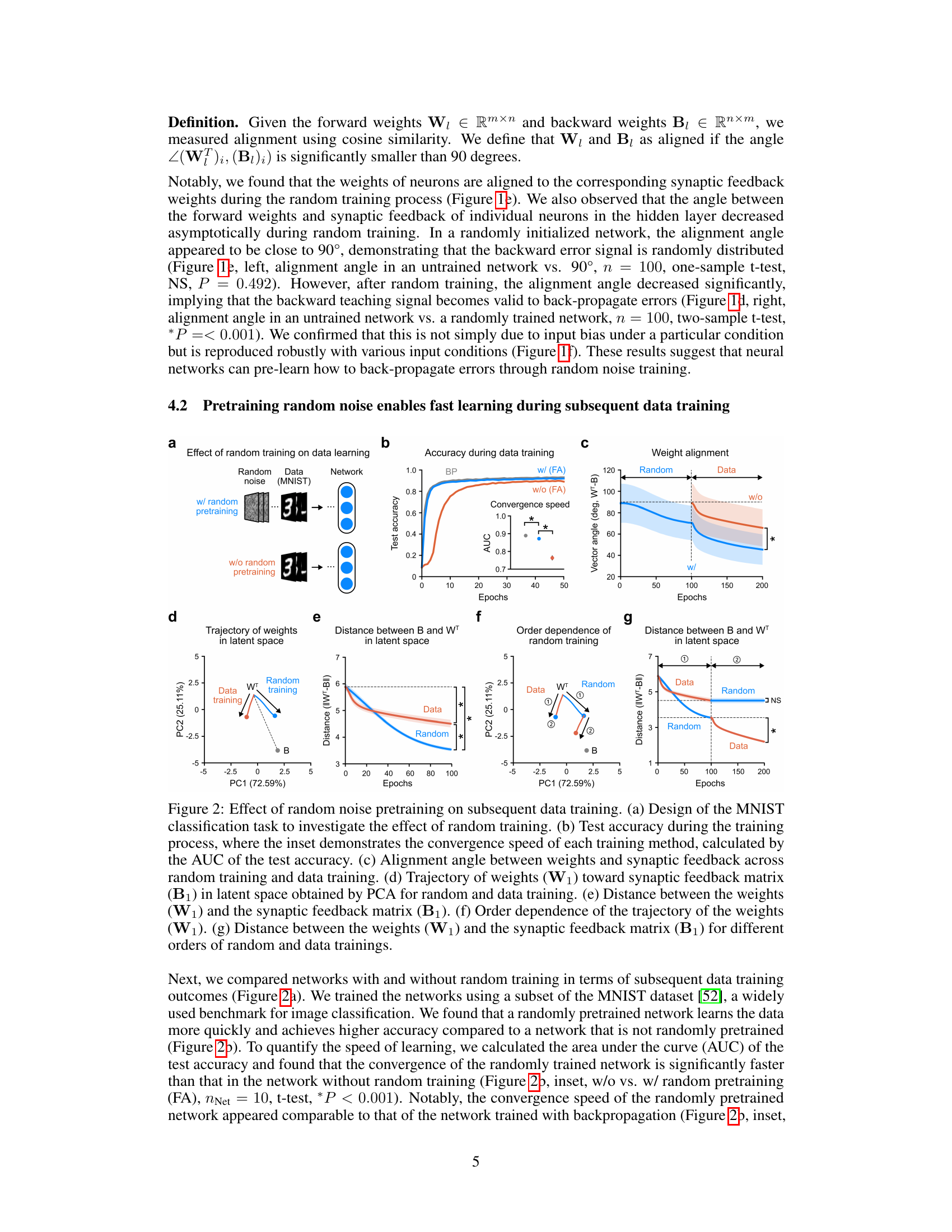
This figure shows the effects of random noise pretraining on a neural network’s subsequent learning with the MNIST dataset. It demonstrates faster convergence and higher test accuracy in the pretrained network compared to a network trained without pretraining. The figure uses various visualizations, including test accuracy curves, alignment angles between forward weights and synaptic feedback, and PCA-based trajectories of weight vectors in latent space, to illustrate the positive impact of the pretraining phase.

This figure demonstrates the effect of random noise pretraining on weight alignment to synaptic feedback. It shows the pathways of backpropagation and feedback alignment, a possible biological mechanism, and the random training process. The graphs illustrate the decrease in cross-entropy loss during random training and the increase in alignment angle between forward weights and synaptic feedback, demonstrating the effectiveness of the random noise pretraining in aligning the weights.

This figure demonstrates the robust generalization capabilities of the randomly pretrained networks on out-of-distribution tasks. Panel (a) shows the training setup using MNIST data and random noise pretraining. Panel (b) shows the testing results on transformed MNIST data (translated, scaled, and rotated), indicating superior performance for the randomly pretrained network. Finally, panel (c) displays testing results on the USPS dataset, further highlighting the generalization ability of the randomly pretrained network.

This figure demonstrates the task-agnostic fast learning capabilities of a randomly pretrained network. Panel (a) shows the meta-loss (a measure of adaptation difficulty) decreasing during random noise pretraining across three different tasks (MNIST, Fashion-MNIST, and Kuzushiji-MNIST). Panel (b) visualizes the trajectory of weights in a latent space during adaptation to these tasks, highlighting the more efficient adaptation of the pretrained network. Finally, panel (c) shows that the randomly pretrained network adapts to these tasks significantly faster than an untrained network.
Full paper#