↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world applications require selecting optimal subsets from large datasets. Existing neural network methods struggle with either fully capturing information from the larger dataset or managing complex interactions within the input data. They often fail to scale to large datasets exceeding available memory. This paper introduces the “Identity Property” which emphasizes that the model should know the original source of the information in the subset.
To address these challenges, the researchers propose HORSE, a hierarchical attention-based model that partitions the input into smaller, manageable chunks. These chunks are processed individually and aggregated to ensure consistency. Extensive experiments demonstrate that HORSE substantially outperforms state-of-the-art methods in large-scale settings, achieving performance improvements of up to 20%. HORSE enhances neural subset selection by effectively utilizing attention mechanisms and the Identity Property to capture complex interactions from large datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to neural subset selection that addresses the limitations of existing methods, particularly in handling large-scale datasets. The proposed HORSE model significantly improves performance while maintaining computational efficiency. This opens new avenues for research in areas such as anomaly detection and recommender systems where large datasets are commonly encountered. Its attention-based mechanism and theoretical grounding offer valuable insights for researchers working on improving the accuracy and scalability of neural set functions.
Visual Insights#

This figure compares three different neural network architectures for subset selection: EquiVSet, INSET, and HORSE. It illustrates how each model processes the input set (V) and the selected subset (S). EquiVSet and INSET use simple aggregation methods, while HORSE uses an attention mechanism to capture more complex interactions between the input set and the selected subset. HORSE also partitions the input set into smaller, manageable chunks before aggregation, improving scalability for large datasets.
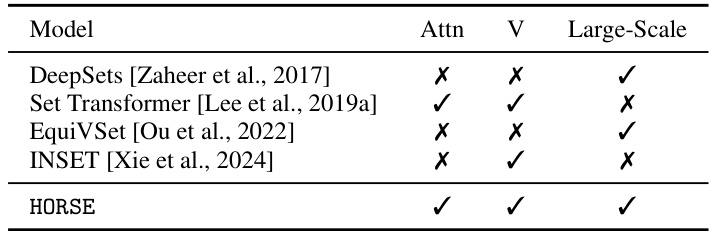
This table compares different methods for set encoding and subset selection. It shows whether each method uses an attention mechanism, explicitly uses information from the entire input set V, and is capable of handling large-scale datasets. The table highlights the differences in approach and capabilities of each method, making it easy to see the relative advantages of HORSE.
In-depth insights#
HORSE: Identity Property#
The concept of “HORSE: Identity Property” introduces a crucial constraint for neural subset selection models. It mandates that the model’s output must reliably reflect the originating superset (V) from which the selected subset (S) was derived. This is vital because it forces the model to learn not only the characteristics of the subset but also its relationship to the larger context. Failure to satisfy the Identity Property can lead to models that perform well on specific subsets but generalize poorly, making them unreliable. The Identity Property, therefore, acts as a regularizer, encouraging the model to learn more comprehensive and robust representations. HORSE’s architecture leverages attention mechanisms to achieve this, enabling the model to effectively capture the nuanced relationships between elements within subsets and across the entire superset. This is particularly important for large-scale applications where encoding the entire superset can be computationally expensive; by focusing on relevant aspects of the superset through attention, the Identity Property enhances both performance and scalability.
Attention-Based Encoding#
Attention-based encoding, in the context of neural subset selection, offers a powerful mechanism to effectively capture complex relationships within large-scale datasets. By leveraging attention mechanisms, the model dynamically weighs the importance of different elements in the input set, rather than relying on simple aggregation methods that may lose crucial information. This approach excels at handling high-cardinality sets, which often pose significant challenges for traditional set encoding techniques. The core strength lies in its ability to model complex interactions between elements, not just treating them as isolated entities. Attention weights are learned, allowing the model to adaptively focus on the most relevant subset of the features, improving both accuracy and efficiency. The hierarchical structure, further enhancing the effectiveness, enables processing of massive datasets by dividing the input into manageable chunks. Each subset then has its own attention mechanism, after which results are aggregated. This hierarchical strategy prevents the computational burden of processing the entirety of the dataset simultaneously. Finally, attention-based methods can be shown to satisfy the desirable ‘Identity Property’, enabling the model to explicitly retain information about the origin of the selected subset.
Large-Scale Subset Selection#
Large-scale subset selection presents significant challenges in machine learning, demanding efficient algorithms to handle massive datasets. Existing methods often struggle with computational complexity and memory limitations when dealing with high-cardinality sets. The core problem revolves around finding optimal subsets that maximize a specific objective function, which is often computationally expensive to evaluate for all possible subsets. A key innovation is the development of hierarchical or partitioning strategies, breaking down the large-scale problem into smaller, manageable subproblems. This approach enhances efficiency by allowing parallel processing and reducing memory consumption. However, such methods need to carefully balance the trade-off between computational efficiency and the potential loss of information caused by partitioning. Another critical aspect is the design of neural network architectures capable of capturing complex interactions within and between subsets. Attention mechanisms and other advanced techniques are employed to overcome the limitations of traditional set encoding methods. Successfully addressing large-scale subset selection requires addressing computational scalability, memory efficiency, information preservation during partitioning, and the development of powerful neural network architectures tailored to set-valued functions.
Compound Selection#
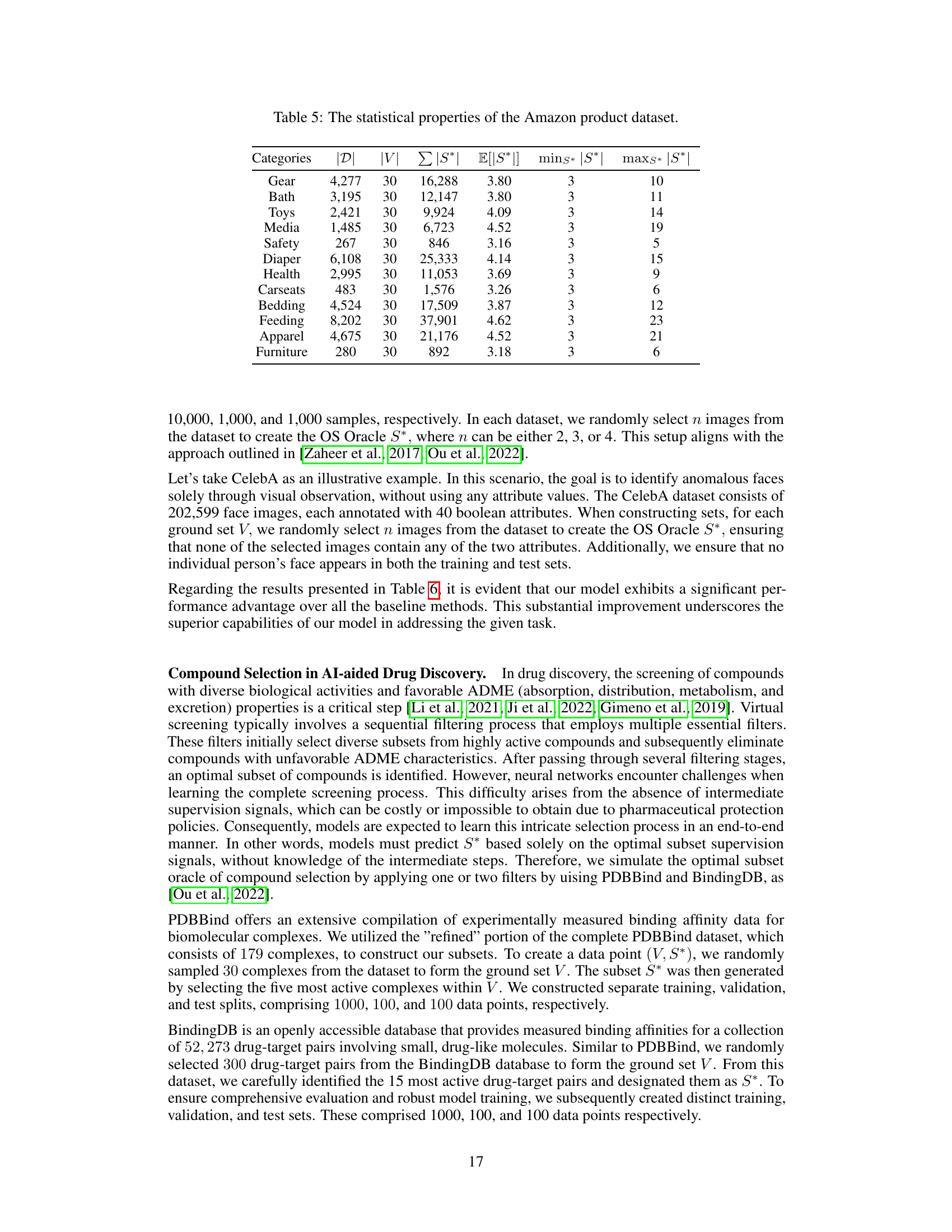
In the context of AI-aided drug discovery, compound selection is a critical step that involves identifying a subset of compounds with desirable biological activities and favorable ADME (absorption, distribution, metabolism, and excretion) properties from a vast chemical space. Traditional methods often employ sequential filtering, applying multiple criteria to progressively narrow the options. However, this process presents challenges for machine learning approaches due to the lack of intermediate supervision signals. The paper highlights the difficulty of directly learning the complete screening process using neural networks because the intermediate steps are generally unavailable, making it difficult to train effective models that accurately reflect the intricate decision-making involved. Therefore, the authors explore strategies for effective compound selection, particularly those that address this lack of intermediary feedback. The proposed approach likely utilizes a model architecture that integrates information from both the entire set of candidate compounds and the selected optimal subset (supervision). The model’s ability to capture complex interactions, handle large-scale input sets, and maintain permutation invariance is emphasized. The core focus is on modeling the relationships between the complete set and the selected subset, implicitly learning the function that assigns utility values to subsets.
Future Work: Scalability#
Regarding future work on scalability, the authors acknowledge that their current attention-based approach, while showing promise, may still face limitations when dealing with extremely large-scale datasets. A key area for improvement would be developing more efficient methods for handling the attention mechanism, perhaps by exploring techniques like sparse attention or hierarchical attention. Further research into the optimization of the partitioning strategy is needed. The current random partitioning may not always be optimal and could benefit from a more sophisticated approach that considers data characteristics or correlations. Exploring alternative architectures that move beyond the attention-based framework altogether, potentially leveraging graph neural networks or other set-encoding methods tailored for massive datasets, could also be a fruitful direction. Finally, thorough empirical evaluation on substantially larger datasets is crucial to validate the scalability and effectiveness of any proposed improvements.
More visual insights#
More on figures

This figure shows the architecture of the HORSE model, highlighting its ability to maintain permutation invariance and satisfy the Identity Property. The left side illustrates how the model processes input sets, showing that regardless of the order of elements (permutation invariance), the model consistently generates the same output. The Identity Property is represented by the dashed lines showing the consistent output despite the model being fed both the selected subset and its origin set. The right side provides a legend explaining the symbols used in the diagram, clearly depicting the distinct stages of the model: the input sets, the attention mechanisms, and the final aggregation that ensures the desired properties are achieved.

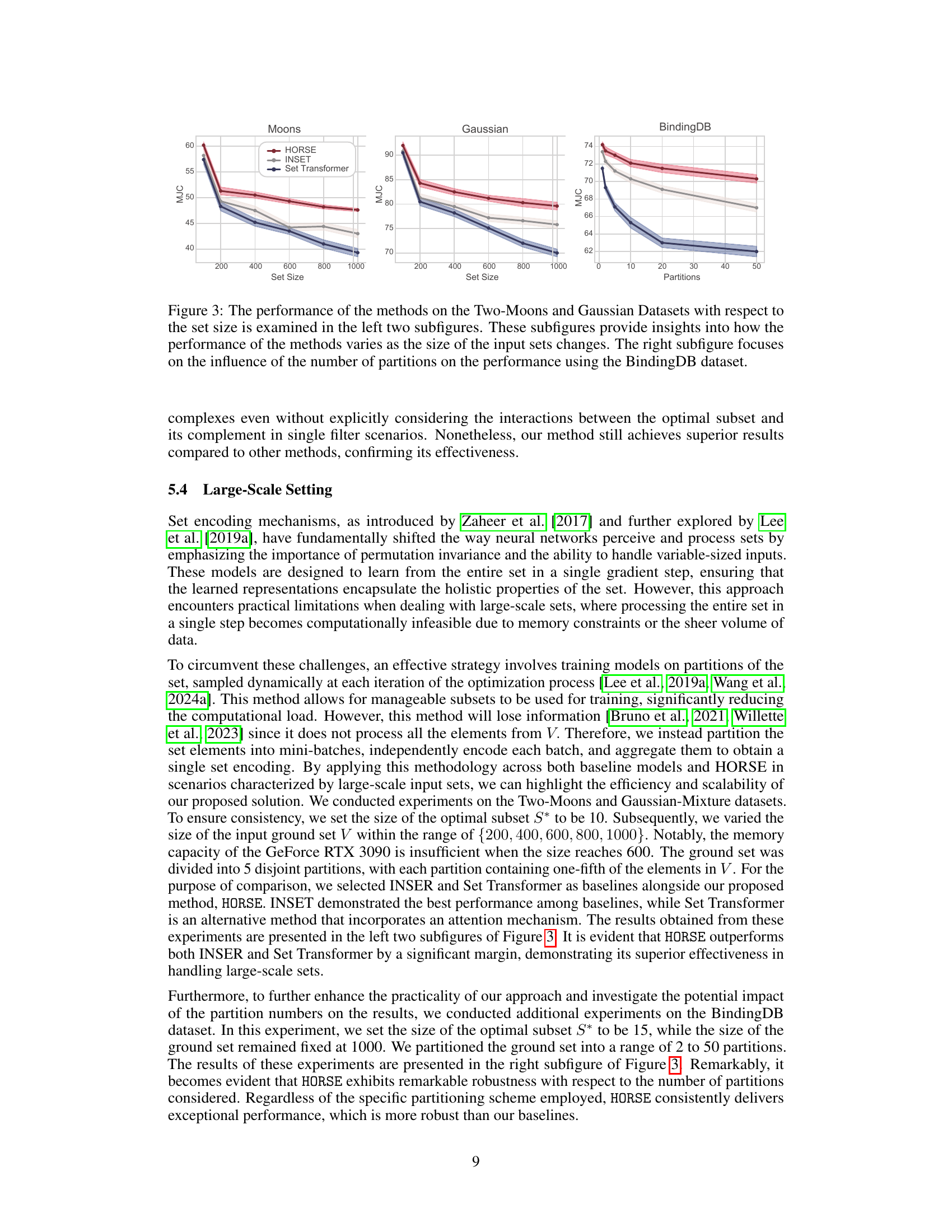
This figure compares three different methods (HORSE, INSET, and Set Transformer) on their ability to perform subset selection tasks on three different datasets. The left two graphs show how performance changes as the size of the dataset increases for two datasets (Two-Moons and Gaussian). The right graph examines how well the methods perform when the dataset is split into different numbers of partitions, which tests the scalability of the algorithms.
More on tables
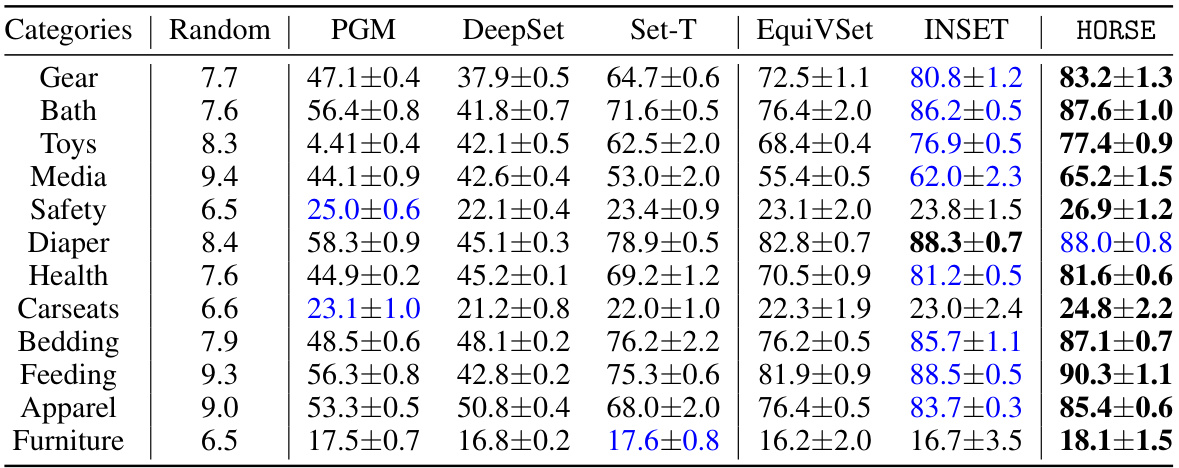
This table presents the performance of different models on a product recommendation task across 12 different product categories. The performance is measured using a metric (not specified in this excerpt). The best and second-best results for each category are highlighted. Set Transformer is abbreviated as ‘Set-T’ due to space constraints.
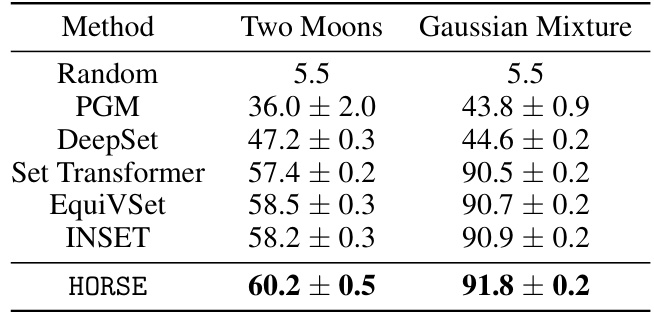
This table presents the performance of different methods (Random, PGM, DeepSet, Set Transformer, EquiVSet, INSET, and HORSE) on two synthetic datasets: Two-Moons and Gaussian Mixture. The Mean Jaccard Coefficient (MJC) is used as the evaluation metric, representing the similarity between the predicted and true subsets. Higher MJC values indicate better performance. The results show that HORSE achieves the highest MJC scores on both datasets, outperforming the other methods.
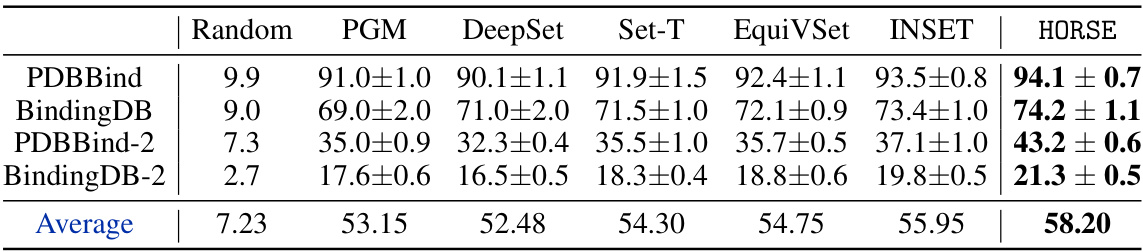
This table presents the results of compound selection tasks using various methods, including HORSE and several baselines. The best performing method for each dataset is shown in bold. The table shows that HORSE significantly outperforms the baselines in most of the tasks, demonstrating its effectiveness in handling large scale compound selection problems.

This table presents the performance of different models on a product recommendation task across 12 different product categories. The models’ performance is measured using a metric (not explicitly defined in the excerpt). The best and second-best results for each category are highlighted. Set Transformer is abbreviated as ‘Set-T’ due to space constraints.
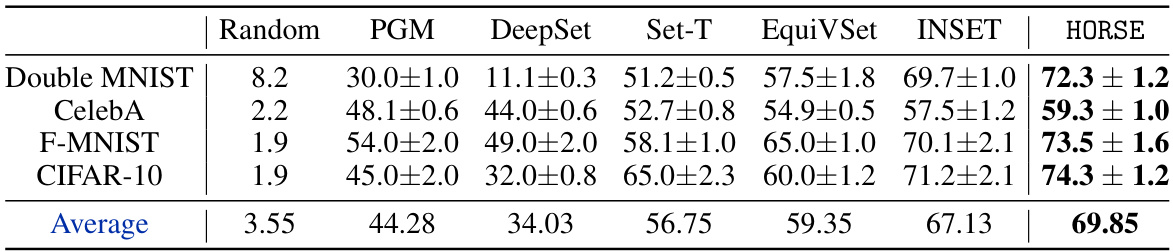
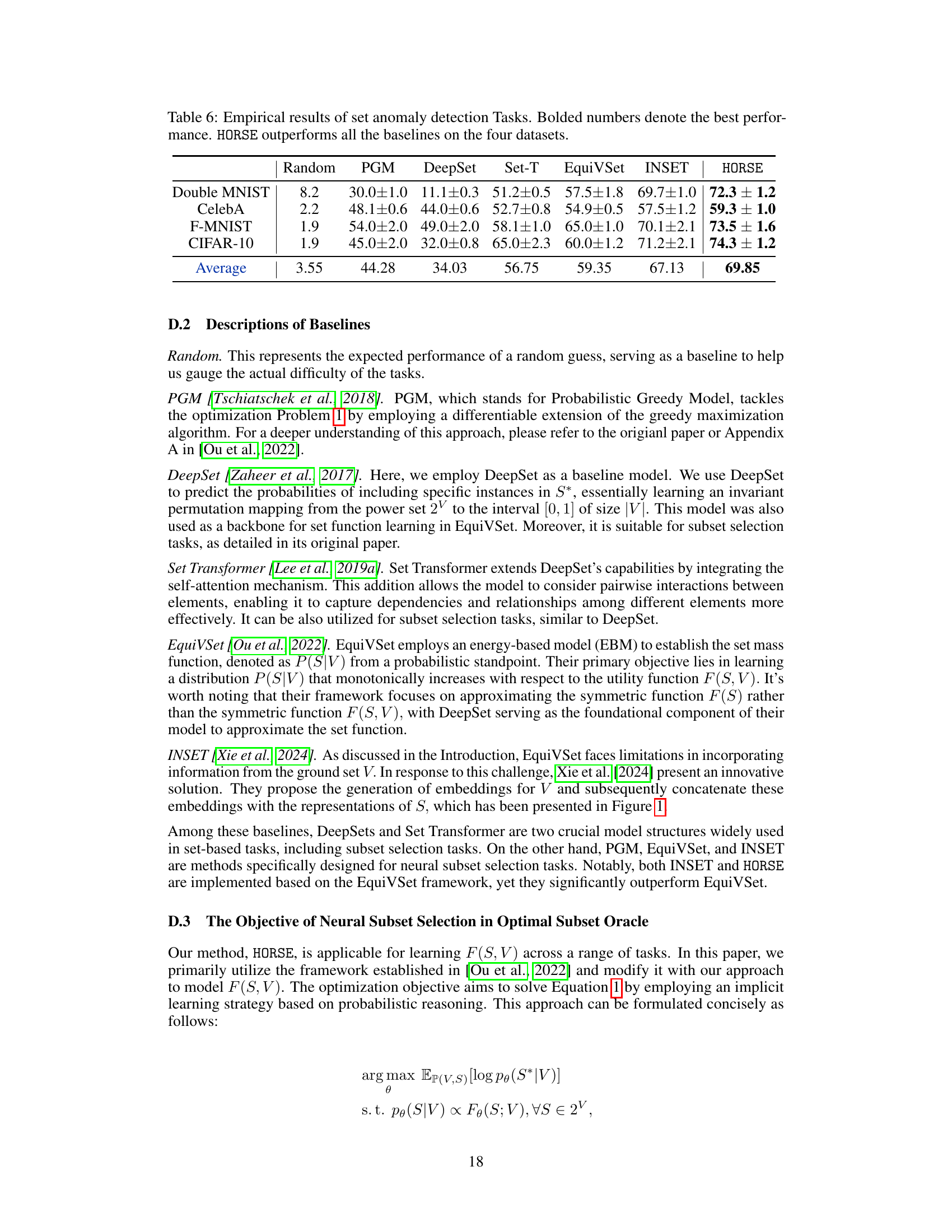
This table presents the performance of the proposed HORSE model and several baseline models on four set anomaly detection tasks (Double MNIST, CelebA, F-MNIST, and CIFAR-10). The performance metric used is not explicitly stated in the provided caption but can be inferred from the context of the paper. The results show that HORSE consistently outperforms the baselines across all four datasets, demonstrating its effectiveness in set anomaly detection tasks.

This table presents the results of an ablation study on the impact of the number of Monte Carlo samples (k) on the performance of the proposed HORSE model. It compares the performance of HORSE with different values of k (2, 4, 6, 8, 10) against the best-performing baseline models for the ‘Media’ and ‘Safety’ product categories in a product recommendation task. The table shows that increasing k generally improves performance, but the effect diminishes beyond a certain point.
Full paper#