↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current motion time series models struggle with limited large-scale datasets and poor generalizability across variations in device, location, and activity. Existing methods often train and test on the same dataset, limiting their applicability to real-world scenarios. This leads to a significant barrier in developing robust pre-trained models for human activity analysis.
UniMTS tackles these challenges head-on. It introduces a unified pre-training procedure using contrastive learning to align motion time series with text descriptions. This approach, combined with synthetic data generation and rotation-invariant augmentation, enables the model to learn the semantic meanings of motion data and generalize effectively. UniMTS achieves state-of-the-art results across 18 benchmark datasets, demonstrating exceptional zero-shot, few-shot, and full-shot performance.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces the first unified pre-training model for motion time series, addressing the critical challenge of limited large-scale datasets and improving generalizability across diverse settings. This opens new avenues for research in human activity analysis and related fields, potentially impacting applications like healthcare and AR/XR.
Visual Insights#

This figure illustrates the UniMTS pre-training framework. It shows how motion time series are generated from motion skeleton data using a physics engine, augmented with rotation invariance, and then aligned with text descriptions (augmented by a large language model) via contrastive learning. The framework aims to create a pre-trained model that generalizes across different device locations, orientations, and activities.

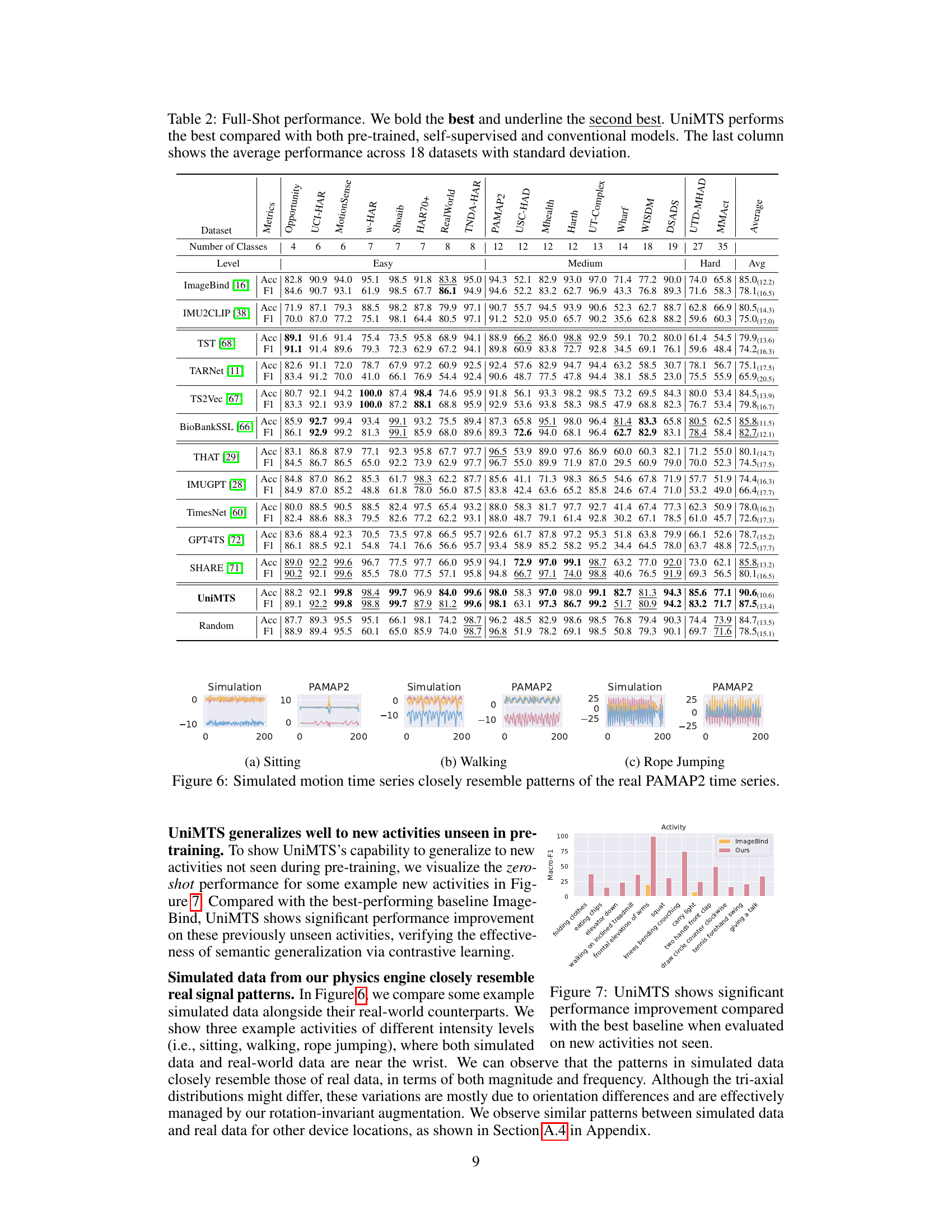
This table presents the zero-shot performance results of UniMTS and several baseline models across 18 motion time series classification benchmark datasets. The results are categorized by dataset and difficulty level (easy, medium, hard). For each dataset, accuracy (Acc), F1-score (F1), and top-2 retrieval performance (R@2) are reported. UniMTS consistently outperforms the baselines across all datasets and metrics, demonstrating its superior generalization capabilities.
In-depth insights#
Motion Data Synthesis#
Motion data synthesis is a crucial aspect of this research, addressing the scarcity of real-world, labeled motion capture data. The authors cleverly leverage existing motion skeleton datasets, employing a physics engine to simulate realistic motion time series from the skeletal joint positions and orientations. This approach is ingenious, mitigating the privacy and data acquisition challenges associated with large-scale motion capture. By generating data that realistically reflect accelerations and angular velocities, the approach makes it suitable for training deep learning models in various settings. The use of a physics engine also allows for data augmentation through rotation invariance, a key contribution towards generalization across various device orientations. This method addresses the challenge of real-world data variability in terms of mounting position and device type. The synthetic data, therefore, acts as a powerful tool to bridge the gap between available data and the needs of the pre-training phase, leading to improved model generalizability and robust performance on real-world benchmark datasets. A significant advantage is that this method scales to larger datasets, creating a foundation for more advanced motion analysis models in future.
Contrastive Pre-train#
A contrastive pre-training approach for motion time series focuses on learning robust and generalizable representations by aligning motion data with textual descriptions. This approach leverages the power of large language models (LLMs) to enrich the semantic understanding of motion patterns. The core idea is to learn a joint embedding space where similar motion patterns and their corresponding textual descriptions are close together, while dissimilar ones are far apart. This contrastive learning framework helps the model capture the underlying semantics of motion, enabling it to generalize better to unseen activities and variations in data collection settings such as device placement and orientation. The use of LLMs adds a layer of semantic richness that goes beyond simple label-based classification, improving generalization and robustness. By generating a unified representation space, contrastive pre-training tackles the challenges of limited, noisy and heterogeneous motion data often encountered in real-world applications. Synthetic data generation, combined with augmentation techniques, plays a crucial role in creating the large-scale training dataset needed to fully realize the potential of this method. Overall, this pre-training strategy enhances generalization capabilities and provides a significant step towards creating more robust and practical motion recognition models.
Generalization Metrics#
To evaluate the generalization capabilities of a model trained on motion time series data, a robust set of generalization metrics is crucial. These metrics should go beyond simple accuracy on a held-out test set, capturing the model’s performance under various conditions such as different device locations, mounting orientations, and activity types. Zero-shot performance, where the model encounters activities unseen during training, is a key indicator. Few-shot performance, using limited labeled data for new activities, assesses the model’s ability to learn and adapt rapidly. Analyzing these metrics across various datasets with diverse characteristics provides a comprehensive assessment of generalization. Furthermore, measuring the consistency of performance across these different conditions, rather than just the average performance, offers crucial insight into the robustness of the model. Finally, visualization techniques such as t-SNE plots, showing how the model clusters similar activities in the embedding space, can offer valuable qualitative insights complementing the quantitative metrics.
UniMTS Limitations#
UniMTS, while groundbreaking, presents limitations. Simulated data, though comprehensive, may not perfectly mirror real-world sensor noise and variability. This discrepancy could impact the model’s robustness in unforeseen situations. The reliance on LLM-augmented text descriptions introduces a dependence on the quality and biases inherent in those models, potentially affecting activity recognition accuracy. Further, the model’s generalization across different device locations is dependent on accurate joint mapping which may be inaccurate with varied mounting orientations or body types. Finally, limited dataset diversity in the pre-training phase, even though simulated, could constrain its ability to generalize to highly specialized or uncommon activities. Addressing these limitations, such as incorporating real-world data augmentation and exploring more robust methods for handling data noise and variations in sensor placement, would strengthen UniMTS’s capabilities and expand its applicability.
Future Work#
The authors thoughtfully outline several avenues for future research, highlighting the limitations of the current UniMTS model and suggesting concrete improvements. Improving the simulation of real-world data is a key focus, acknowledging that the current physics engine, while effective, produces approximations of real sensor data. The limitations of relying on existing motion datasets for pre-training are also noted. Expanding the dataset to include more diverse motion data obtained from various methods (e.g., video-based pose estimation) to enhance the generalizability and robustness of the model is proposed. Addressing the limitations of specific device placement, especially on the wrist versus the wrist joint, is a significant point of further exploration. In addition to extending the applications of UniMTS beyond activity classification, the researchers plan to explore adapting the model for tasks such as inertial navigation. Finally, optimizing the model’s efficiency for deployment on edge devices through techniques like quantization and pruning is a crucial consideration for practical applications.
More visual insights#
More on figures
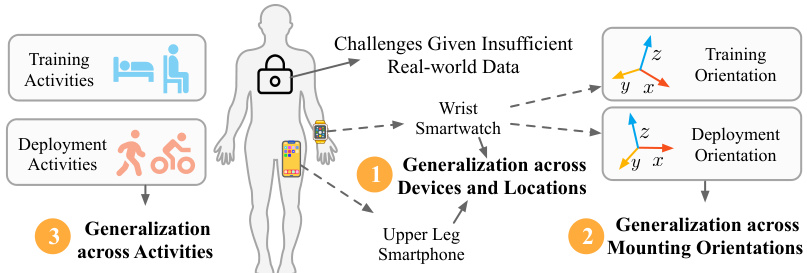
This figure illustrates the three main generalization challenges that the UniMTS model addresses. Existing methods often struggle to generalize across different device locations (e.g., a smartwatch on the wrist versus a smartphone on the thigh), device mounting orientations (e.g., a phone held vertically vs. horizontally), and different activity types (e.g., sitting versus running). The figure highlights these challenges visually, showing how the variation in device location, orientation, and activity during deployment differs from the training data, impeding generalization.

The figure illustrates the UniMTS pre-training framework. It shows how motion skeleton data is processed using a physics engine to generate motion time series, which are then augmented with rotation invariance. These time series are encoded using graph convolutional neural networks and aligned with text descriptions enriched by a large language model (LLM) through contrastive learning. The goal is to learn the semantic relationships between motion time series and their textual descriptions, enabling better generalization to unseen activities and contexts.
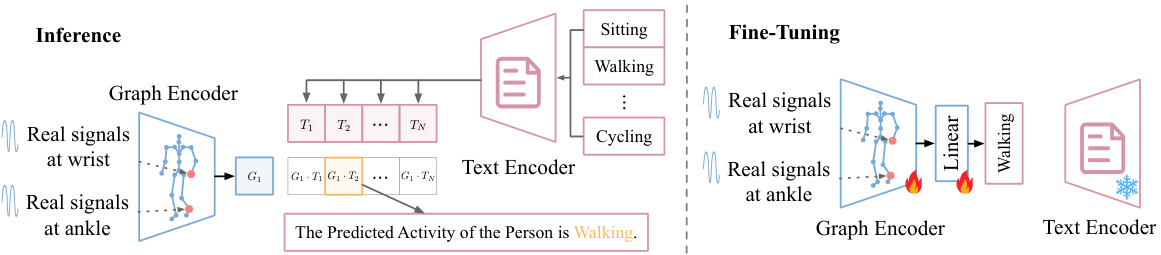
This figure illustrates the inference and fine-tuning phases of the UniMTS model. The left side shows the inference process: real-world motion time series data from various body locations are input into the graph encoder. The graph encoder generates an embedding that is compared against the text encoder’s embeddings for different activity labels. The activity with the highest similarity score is predicted. The right side shows the fine-tuning process: pre-trained model weights (graph encoder) are updated using real-world motion data to improve accuracy. The text encoder remains frozen during fine-tuning.

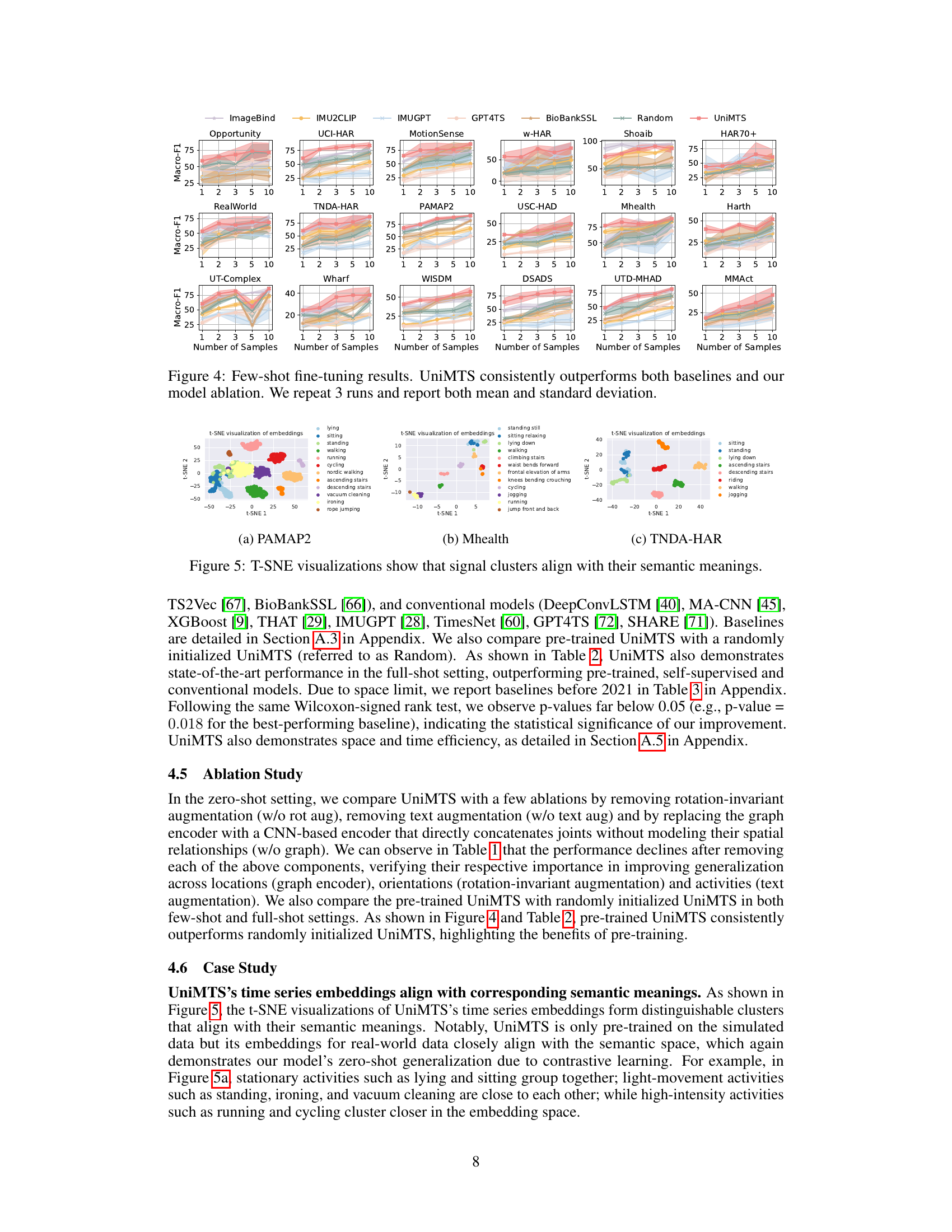
This figure shows the macro-F1 scores achieved by UniMTS and several baseline models (ImageBind, IMU2CLIP, IMUGPT, GPT4TS, BioBankSSL, Random) across 18 different datasets in a few-shot learning setting. Each dataset is represented by a separate subplot. The x-axis represents the number of samples used for training per class (1, 2, 3, 5, 10 samples). The y-axis shows the macro-F1 score. The shaded area around each line represents the standard deviation across three runs. UniMTS consistently outperforms all baselines across all datasets and training sample sizes, demonstrating the effectiveness of its unified pre-training approach.

This figure illustrates the inference and fine-tuning phases of the UniMTS model. The left side shows the inference process where real-world motion sensor data is mapped to the nearest joint in a skeleton graph. The model then computes similarity scores between the graph embedding (representing the motion data) and embeddings for various activity labels. The activity with the highest similarity score is predicted as the activity. The right side depicts the fine-tuning process, where the pre-trained text encoder is frozen, and only the graph encoder and a linear layer are trained further using real-world motion sensor data and corresponding activity labels to enhance performance.

This figure compares simulated motion time series generated by the physics engine in UniMTS with real-world motion time series from the PAMAP2 dataset. Three different activities are shown: sitting, walking, and rope jumping. For each activity, the plot shows three axes of motion data (likely acceleration or angular velocity) for both the simulated and real data. The visual similarity between the simulated and real data suggests the effectiveness of the physics engine in generating realistic motion data for pre-training the UniMTS model.
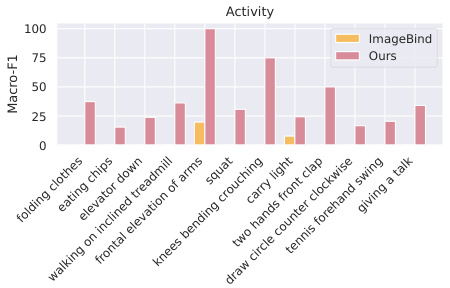
This figure shows the macro-F1 scores for several unseen activities for both UniMTS and the ImageBind baseline. UniMTS shows consistently higher performance, indicating its ability to generalize to new, previously unseen activities. The x-axis lists the activities, and the y-axis shows the macro-F1 score. The bars show a comparison between UniMTS and ImageBind for each activity.

This figure illustrates the UniMTS pre-training framework. It starts with motion skeleton data, which is fed into a physics engine to simulate realistic motion time series for each joint. Rotation-invariant augmentation is then applied to make the model robust to changes in device orientation. These augmented time series are input to a graph encoder (spatio-temporal graph convolutional neural network) to capture the relationships between joints. Simultaneously, text descriptions of the motion are augmented using a large language model (LLM). Finally, contrastive learning aligns the graph-encoded motion time series with the LLM-augmented text descriptions.

This figure compares simulated motion time series generated by the UniMTS model with real-world motion time series from the PAMAP2 dataset. Three activities are shown: sitting, walking, and rope jumping. For each activity, the plot shows the simulated and real data for three axes (x, y, z) of acceleration. The close similarity between the simulated and real data demonstrates the effectiveness of the physics engine used in UniMTS to generate realistic motion time series.
More on tables

This table presents the zero-shot performance results of UniMTS and several baselines across 18 benchmark datasets for motion time series classification. The results show accuracy, F1 score, and top-2 retrieval performance (R@2) for each dataset, categorized by difficulty level (Easy, Medium, Hard). UniMTS consistently outperforms the baselines, demonstrating its superior generalizability.
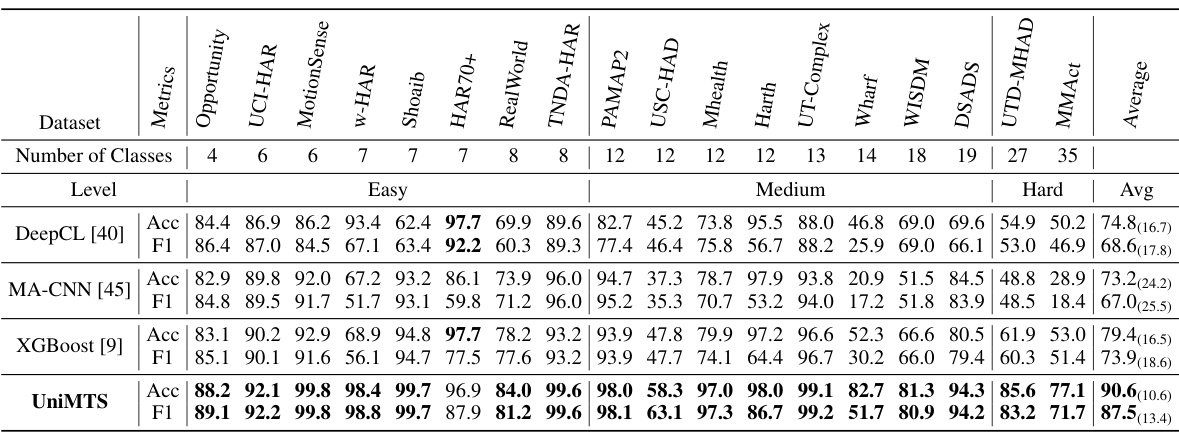
This table presents the results of a zero-shot learning experiment on 18 motion time series classification benchmark datasets. The model, UniMTS, is compared against several other methods (ImageBind, IMU2CLIP, IMUGPT, HARGPT, LLaVA). The table shows the accuracy, F1-score, and R@2 (top-2 retrieval) for each dataset and the average across all datasets. UniMTS significantly outperforms all other models in zero-shot classification.
Full paper#