↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current language models (LMs), despite impressive performance, don’t fully replicate human language processing. Previous studies have focused primarily on areas of shared functionality; however, this research highlights critical discrepancies, especially regarding aspects such as social/emotional intelligence and physical commonsense reasoning, which are crucial elements of human understanding. This gap reveals limitations in LMs’ ability to accurately reflect human cognitive processes and has significant implications for the broader field of AI and human-computer interaction.
To address these issues, this study uses a data-driven approach based on Magnetoencephalography (MEG) data from human participants reading and listening to narratives. The researchers then employ an LLM-based methodology to pinpoint specific areas where the LMs underperform compared to human brains. The study finds that fine-tuning the LM on social/emotional datasets and physical commonsense datasets significantly improves their prediction accuracy, aligning better with MEG brain response data. These findings underscore the importance of moving beyond solely focusing on similarities between LMs and human brains and delve deeper into the divergences to enhance the overall effectiveness and human-likeness of future AI systems.
Key Takeaways#
Why does it matter?#
This research is crucial because it reveals significant divergences between how language models and human brains process language, particularly concerning social-emotional intelligence and physical commonsense. This has implications for improving AI’s alignment with human cognition and developing more effective human-computer interactions. The findings also point towards promising new research avenues in fine-tuning language models to enhance their alignment with human brains.
Visual Insights#
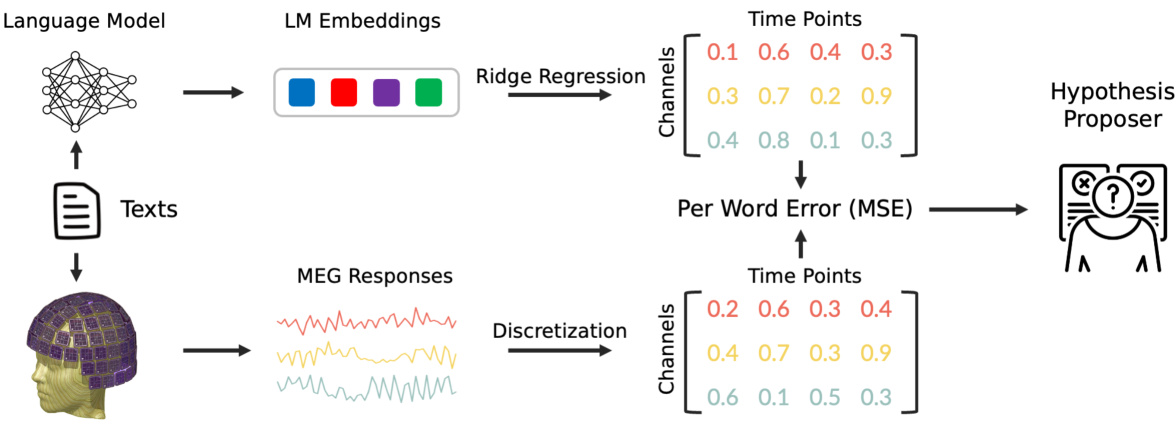
This figure illustrates the experimental workflow of the study. It begins with text input processed by a Language Model (LM) to generate word embeddings. These embeddings are then used in a ridge regression model to predict MEG (Magnetoencephalography) brain responses. The model’s accuracy is measured by calculating the Mean Squared Error (MSE) between predicted and actual MEG responses. High MSE indicates areas where the LM doesn’t accurately capture human brain activity. Finally, an LLM-based hypothesis proposer is used to explain these prediction errors in natural language.
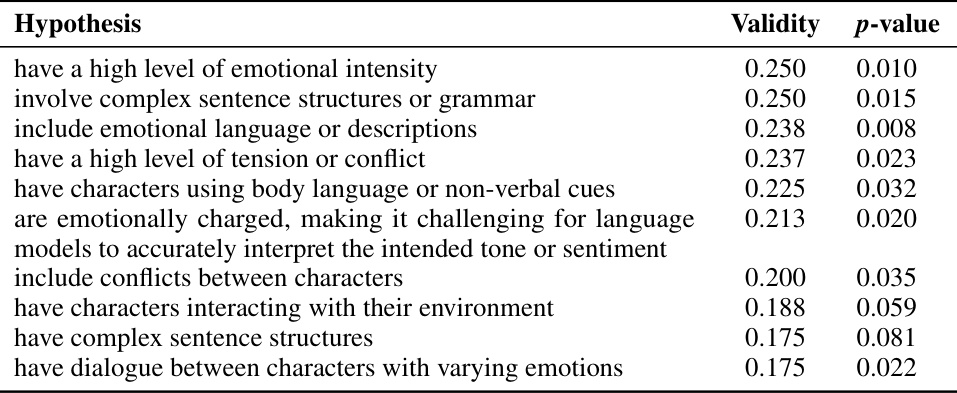
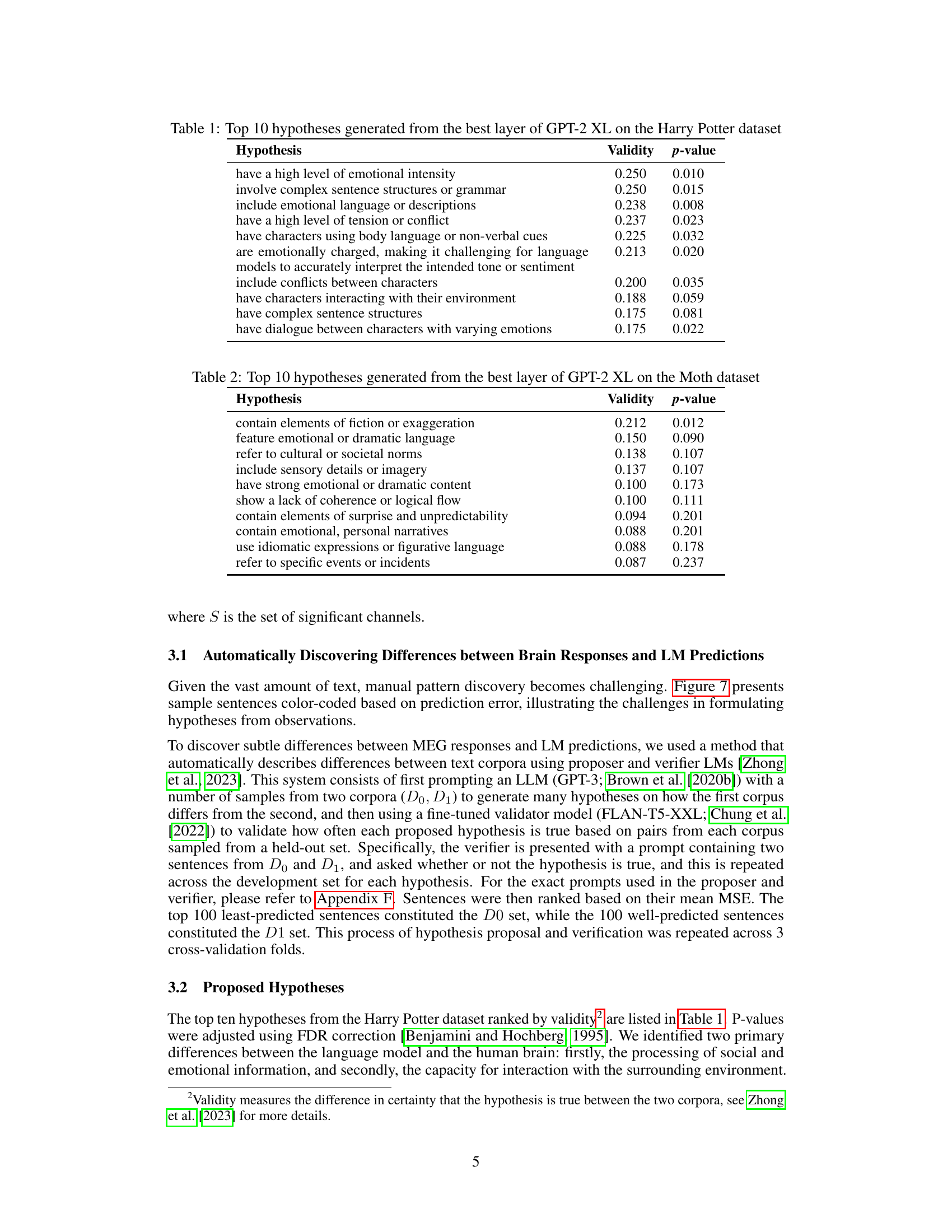
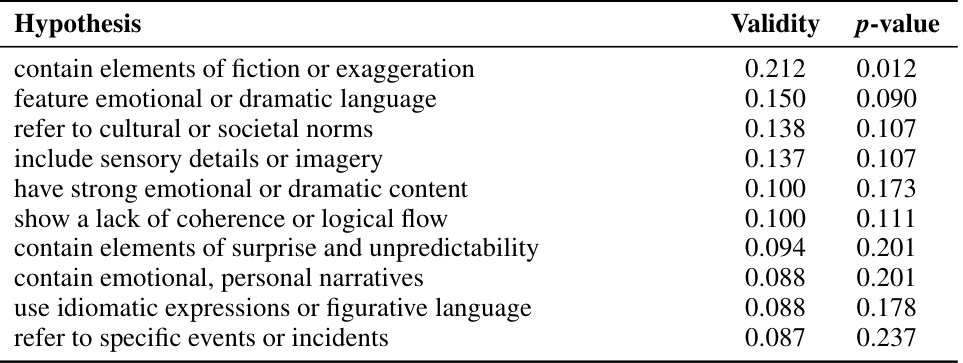
This table presents the top ten hypotheses generated by an LLM-based hypothesis proposer to explain the discrepancies between GPT-2 XL’s predictions and actual MEG responses for the Harry Potter dataset. The hypotheses are ranked by their validity (a measure of how well they distinguish between sentences where the model’s predictions were accurate and sentences where they were not), and a p-value indicating the statistical significance of the difference in validity. The hypotheses highlight aspects of language that the model struggles to capture, such as high levels of emotional intensity, complex sentence structures, and nuanced emotional language.
In-depth insights#
LM-Brain Divergence#
The concept of “LM-Brain Divergence” highlights the crucial discrepancies between how large language models (LLMs) and human brains process language. While LLMs demonstrate impressive linguistic capabilities, achieving near human-level performance on various tasks, their underlying mechanisms differ significantly from human cognitive processes. This divergence stems from several key factors: the sheer scale of data used to train LLMs versus the limited, experience-based learning in humans; the statistical regularities LLMs identify versus humans’ reliance on structured linguistic rules and real-world grounding; and finally, the passive nature of LLM training compared to humans’ active engagement in language use through social interaction and exploration. Understanding this divergence is critical for advancing AI, particularly in creating more human-like and robust language systems that incorporate nuanced aspects of social-emotional intelligence and physical commonsense, areas where current LLMs often fall short. Future research should focus on bridging this gap by incorporating richer, more multifaceted datasets into LLM training and by developing models that better reflect the dynamic, interactive nature of human language learning and processing.
MEG Prediction Model#
A MEG prediction model, in the context of language processing research, uses language model embeddings to predict human brain responses measured by magnetoencephalography (MEG). The core idea is leveraging the shared computational principles between language models and the human brain to predict neural activity. The model typically involves training a regression model (like ridge regression) on MEG data, using LM embeddings as predictors. The model’s performance is often evaluated using metrics like mean squared error (MSE), assessing how well the predicted MEG responses match the actual ones. A key aspect is identifying optimal layers within the language model to extract embeddings, as intermediate layers have shown superior performance. The spatiotemporal patterns of predictions offer crucial insights into the alignment between model predictions and brain activity, indicating whether the model is effectively capturing language processing dynamics in different brain regions and time windows. This model allows researchers to analyze which aspects of language processing are well-captured by the model and where divergences lie, potentially pointing to areas needing further investigation in language models.
Hypothesis Generation#
The process of hypothesis generation in this research is a critical element, bridging the gap between observed divergences in brain responses and language model predictions. Instead of manual hypothesis formulation, which would be impractical given the vast amount of data, the researchers employed a data-driven, automated approach. This involved using large language models (LLMs) as a “hypothesis proposer,” generating natural language hypotheses to explain the discrepancies. The key strength of this method is its scalability and objectivity, enabling the exploration of numerous subtle differences that manual analysis might miss. However, the reliance on LLMs introduces a potential source of bias; the hypotheses generated are inherently influenced by the LLM’s training data and underlying biases. Validation using human behavioral experiments is essential to mitigate this limitation and to confirm that the automatically generated hypotheses accurately reflect the observed divergences between human brains and language models.
Fine-tuning Effects#
Fine-tuning language models on specific datasets significantly improves their alignment with human brain responses. Targeted fine-tuning on social/emotional intelligence and physical commonsense datasets leads to more accurate predictions of MEG responses, particularly within specific temporal windows relevant to those cognitive processes. This suggests that the divergences between LMs and human brains are not simply due to a lack of computational power, but rather a deficiency in representing real-world knowledge. While the improved alignment is notable, it’s crucial to note the effect is not universal across all time windows or brain regions. The enhancements are more pronounced for words related to the fine-tuned domain, highlighting the importance of incorporating relevant knowledge during model training. This supports the hypothesis that the observed divergences between LMs and humans may be primarily due to insufficient representations of these knowledge domains.
Future Research#
Future research directions stemming from this work could explore a wider range of linguistic tasks and modalities beyond narrative text, such as dialogues, poems, or code, to better understand the breadth of LM-brain alignment and divergence. Investigating other neuroimaging techniques such as EEG or fMRI, along with more sophisticated analysis methods, could provide a more nuanced picture of temporal and spatial brain activity patterns. Addressing the limitations of current LLM architectures by incorporating mechanisms for enhanced social/emotional understanding and commonsense reasoning is crucial. This might involve fine-tuning on more diverse and richer datasets, exploring new architectures, or integrating external knowledge sources. Finally, exploring the causal relationship between LLM improvements and brain alignment, through interventional studies, could offer valuable insights into the underlying computational mechanisms shared or not shared between artificial intelligence and human cognition.
More visual insights#
More on figures
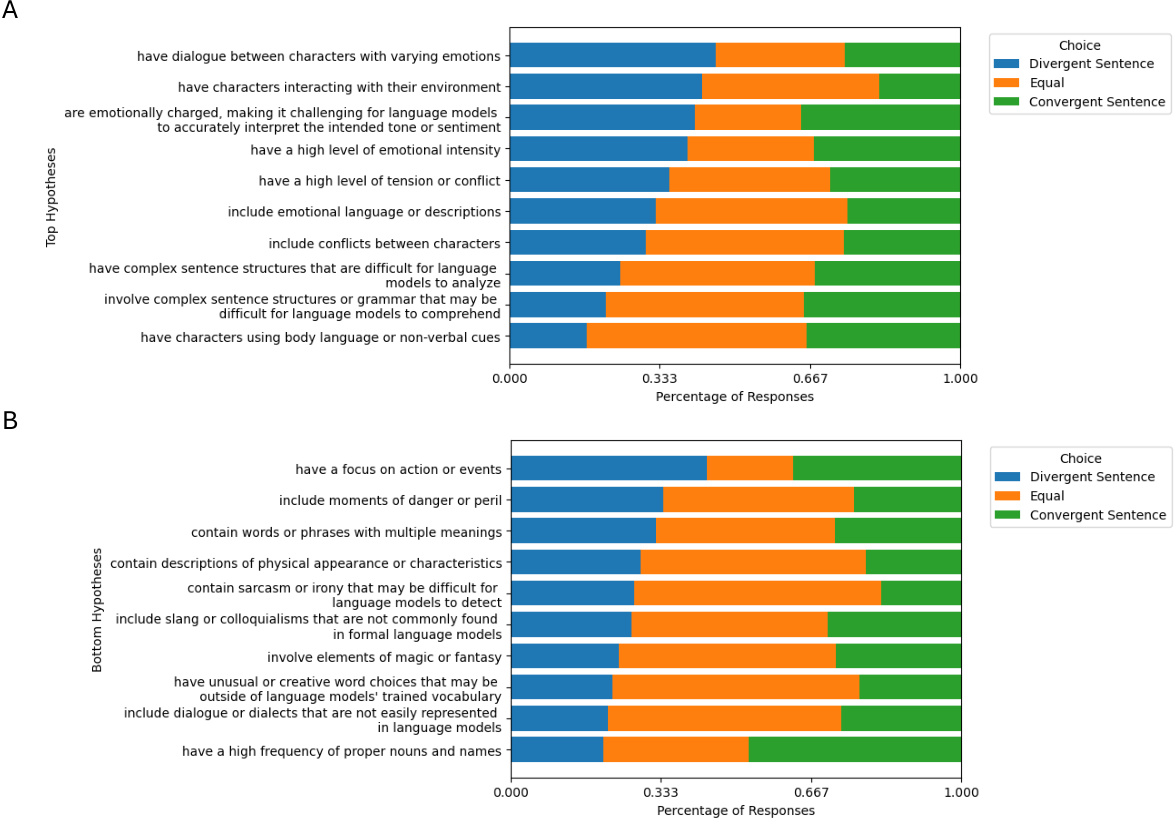
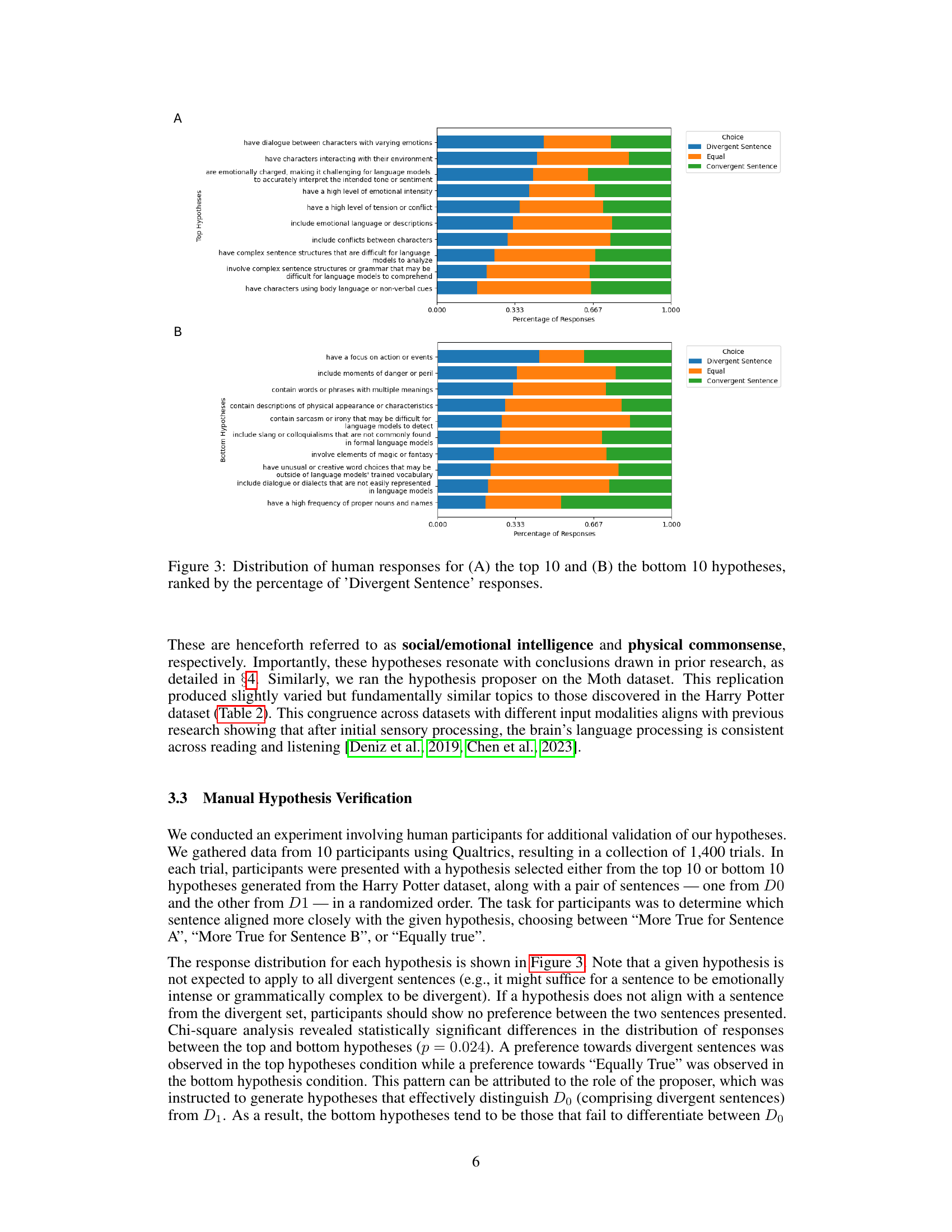
This figure shows the results of a human validation experiment designed to verify the hypotheses generated by the LLM-based hypothesis proposer. The experiment presented participants with pairs of sentences and a hypothesis, asking them to choose which sentence better fit the hypothesis. The figure displays the distribution of responses (‘Divergent Sentence’, ‘Equal’, ‘Convergent Sentence’) for the top 10 and bottom 10 hypotheses, ranked by the percentage of participants who selected ‘Divergent Sentence’. This helps illustrate the difference in human judgement between the sentences the language model struggles to interpret vs. those it interprets well. Panel A shows the distribution for the top 10 hypotheses (those that best capture the difference between LM predictions and human brain responses), while Panel B shows the distribution for the bottom 10 hypotheses.
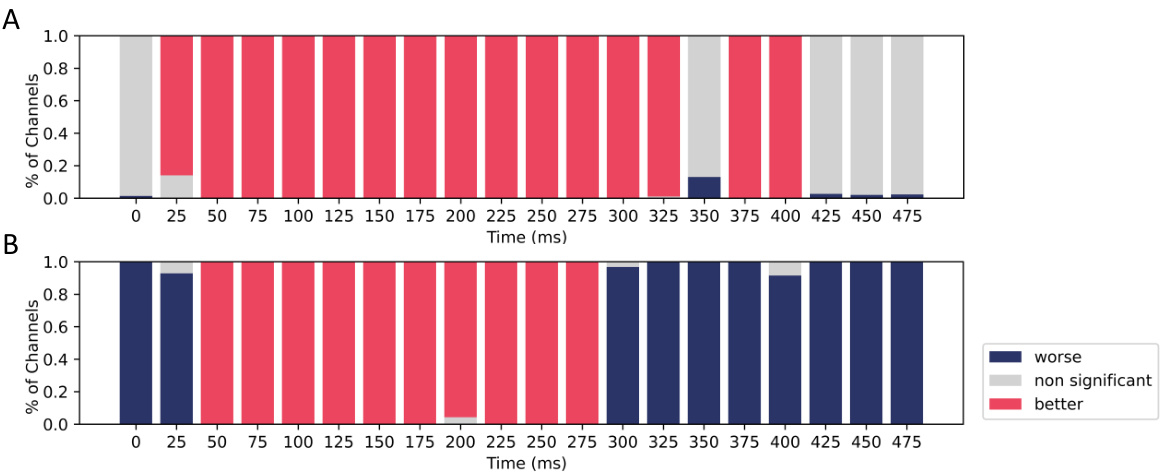
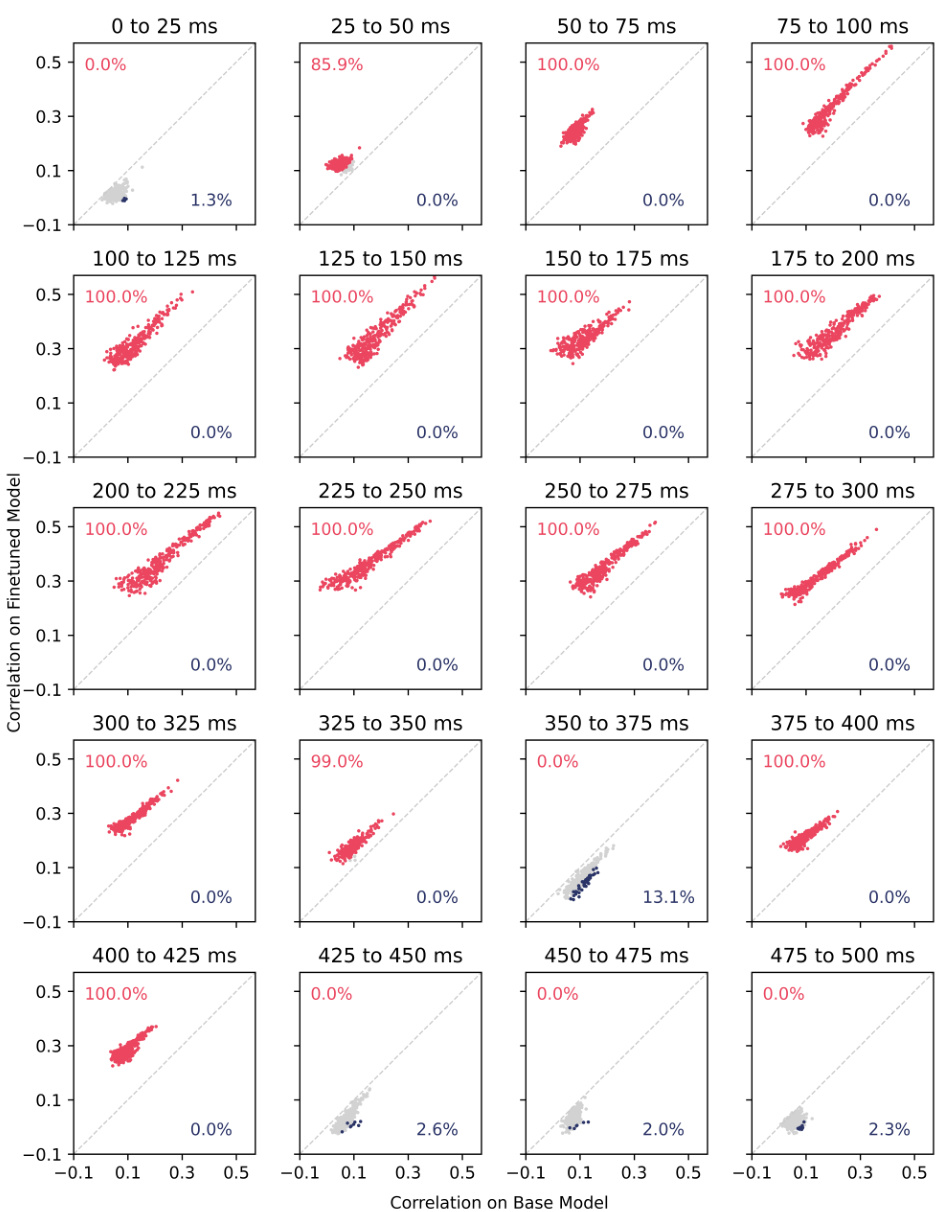
This figure compares the performance of the base language model with models fine-tuned on social and physical datasets. It shows the percentage of MEG channels where the fine-tuned models performed better, worse, or similarly to the base model across different time windows after word onset. The results indicate that fine-tuning improves performance during the typical language processing time period.
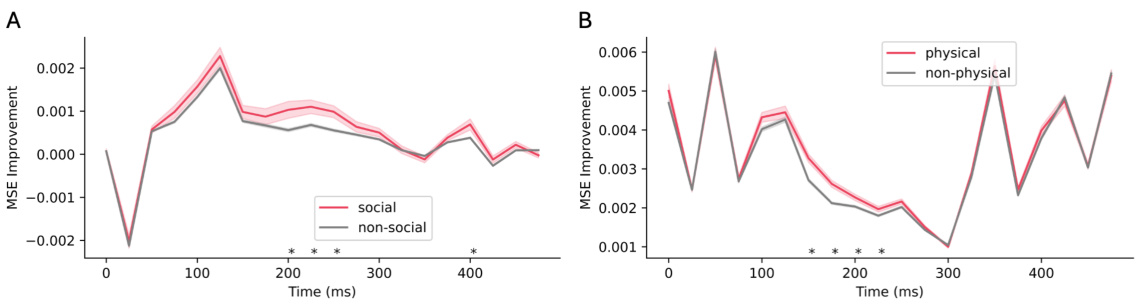
This figure displays a comparison of the Mean Squared Error (MSE) improvement between words categorized as ‘social’ or ‘physical’, and those outside these categories, after fine-tuning language models on datasets specific to each category. The x-axis represents time (in milliseconds) post-word onset, and the y-axis represents the difference in MSE between the fine-tuned model and the base model. Positive values indicate better performance of the fine-tuned model. Error bars are shown as shaded regions, and asterisks denote statistically significant differences between the two groups.
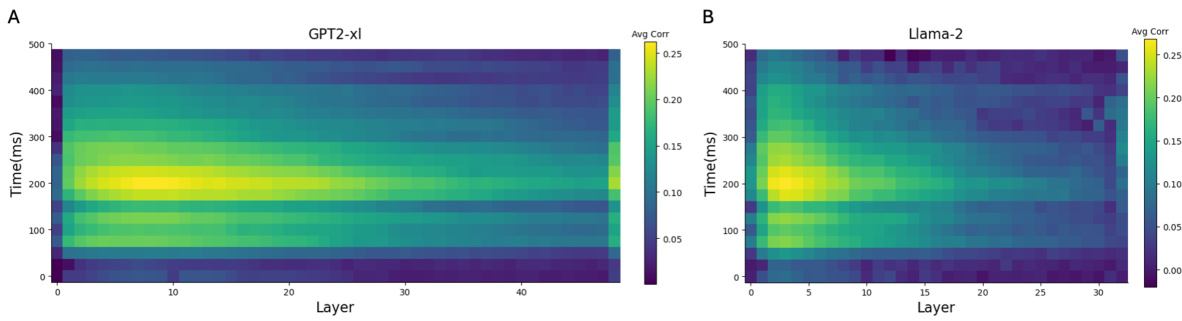
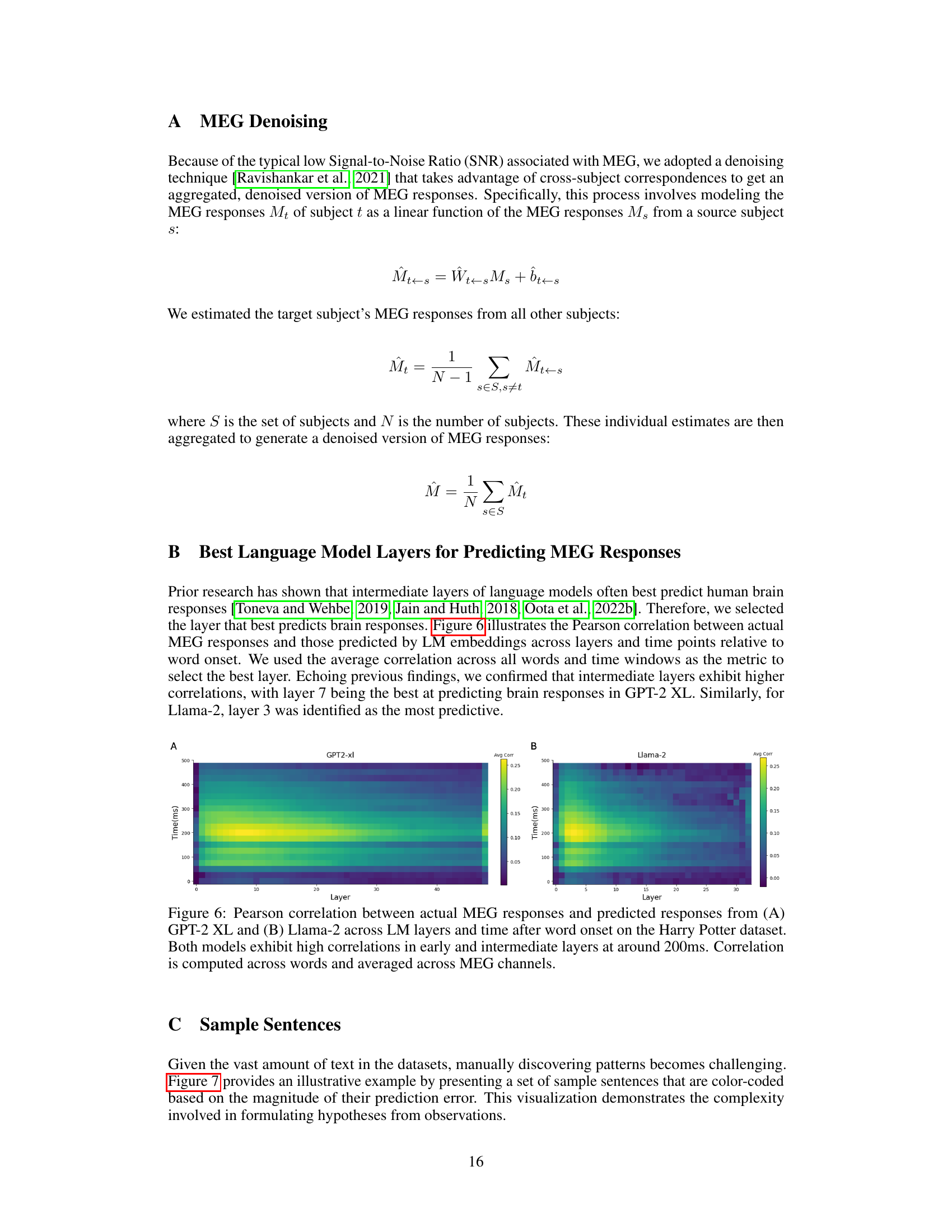
This figure displays the Pearson correlation between actual MEG responses and those predicted by GPT-2 XL and Llama-2 across different layers and time points relative to word onset in the Harry Potter dataset. High correlations are observed in the early and intermediate layers of both models at approximately 200ms post-word onset, suggesting a strong correspondence between the language models’ representations and human brain activity during language processing.
This figure shows sample sentences from the Harry Potter dataset color-coded according to their prediction error. The colors represent five 20-percentile ranges of words, from those with the highest prediction error (most divergent from human brain responses) to those with the lowest (least divergent). This illustrates the challenge in manually identifying patterns in large datasets of text.
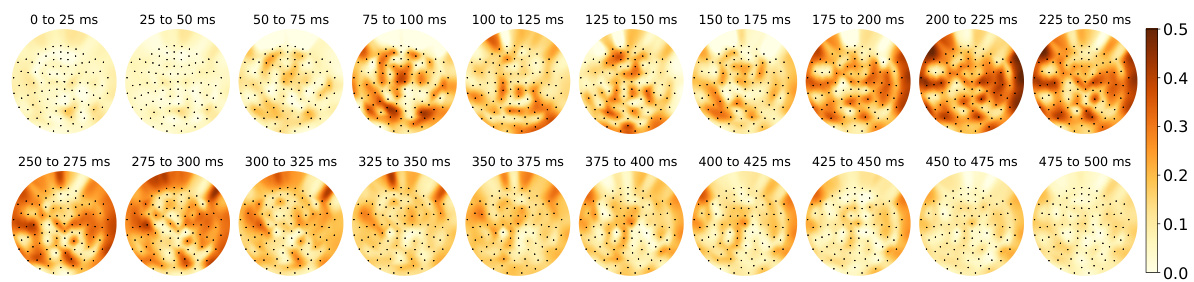
This figure shows the Pearson correlation between actual MEG responses and those predicted by the GPT-2 XL language model’s layer 7 embeddings for the Harry Potter dataset. The correlation is visualized across different time windows (0-500ms) post-word onset. The layout is a flattened representation of the MEG sensor array, where redder colors represent stronger correlations (more accurate predictions) between the model’s predictions and actual brain activity. The caption highlights that language regions show high correlation during typical language processing timeframes.
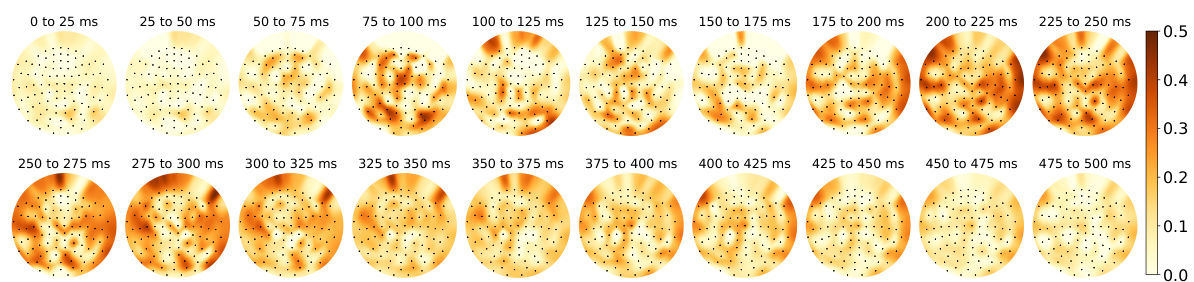
This figure displays the Pearson correlation between actual MEG responses and predicted responses generated using embeddings from layer 7 of the GPT-2 XL language model. The correlation is shown across various time windows (25ms intervals) after a word is presented. The visualization is a flattened representation of the MEG sensor array on the scalp, with color intensity representing the strength of the correlation. Higher intensity (deeper red) indicates better alignment between model predictions and actual brain responses. The caption notes that language regions show particularly good prediction accuracy within specific time windows.
This figure illustrates the experimental process used in the paper. It shows how language model embeddings are used to predict MEG (Magnetoencephalography) responses to words. The process starts with the language model receiving a word and its context to generate an embedding. This embedding then goes into a ridge regression model which predicts the MEG response to that word. The MSE is then calculated to measure the difference between the predicted and the actual MEG response. Finally, an LLM is used to generate hypothesis to explain the differences.
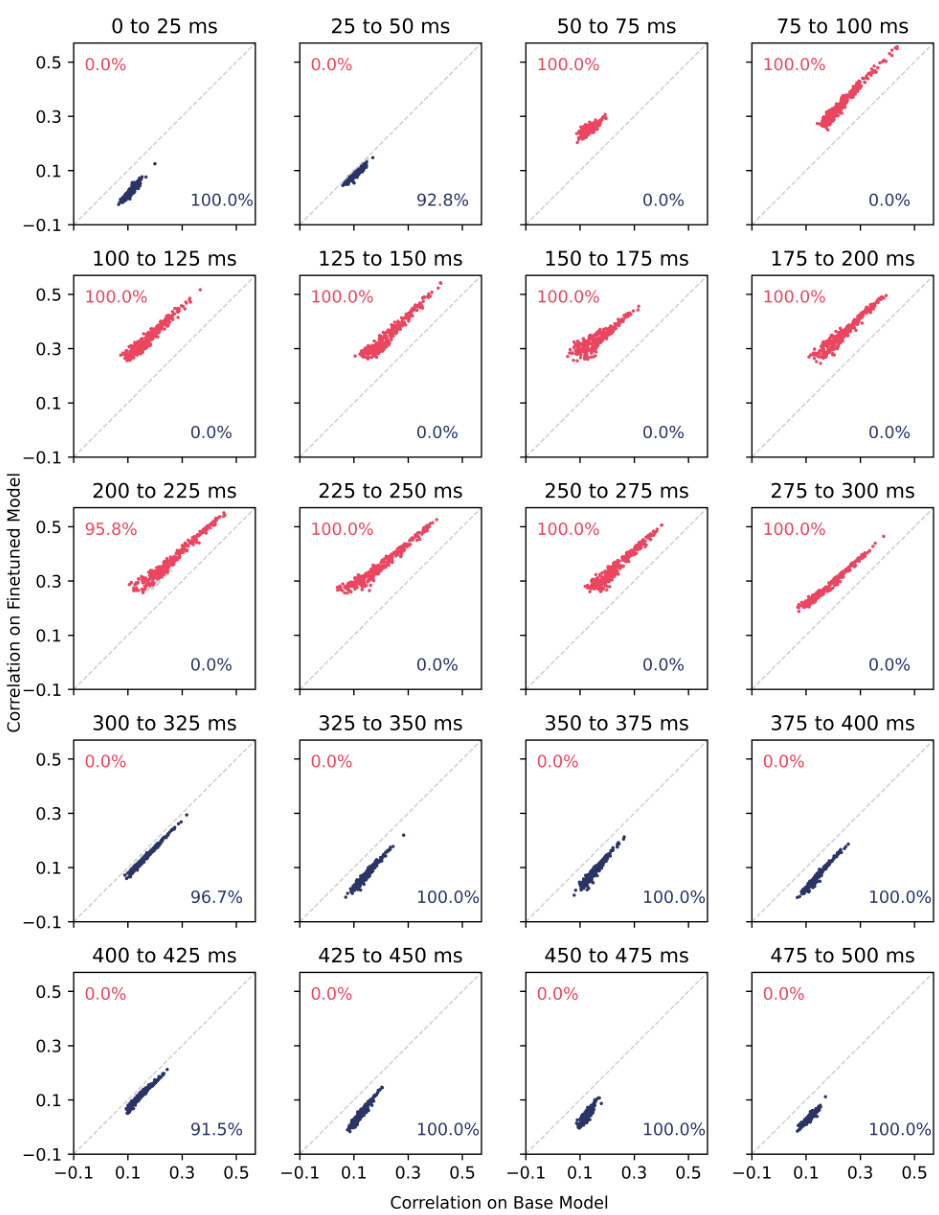
This figure compares the performance of the base language model and the models fine-tuned on social and physical datasets. The y-axis represents the percentage of MEG channels showing better, worse, or no significant difference in performance (measured by Pearson correlation) between the fine-tuned and base models. The x-axis shows time in milliseconds. The results show that the fine-tuned models outperform the base model, particularly during the language processing time windows.
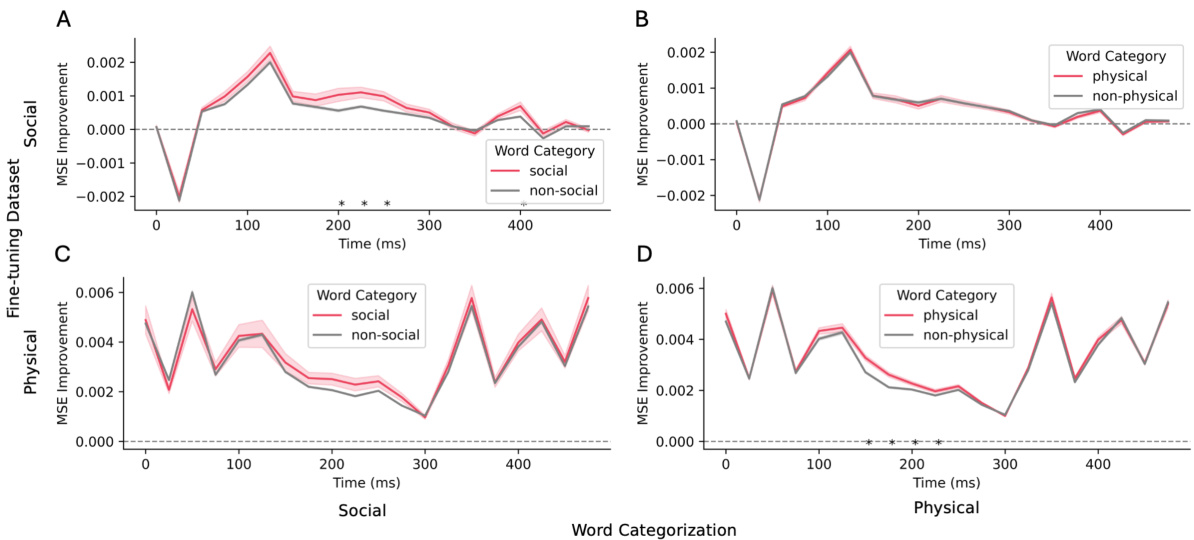
This figure compares the mean squared error (MSE) improvements for social and physical words versus non-social and non-physical words after fine-tuning language models on social and physical datasets. Lower MSE indicates better alignment between model predictions and actual MEG responses. The shaded areas represent standard error, and asterisks mark statistically significant differences (p<0.05 after FDR correction). The figure shows that fine-tuning improves alignment specifically for words in the target category (social/physical) across various time windows.
More on tables
This table presents the top 10 hypotheses generated by an LLM-based hypothesis proposer to explain the discrepancies between human brain responses and GPT-2 XL predictions for the Moth dataset. The hypotheses are ranked by their validity scores (a measure of how well they distinguish between sentences where the model’s predictions accurately reflect brain activity and sentences where they do not), and p-values are provided, indicating statistical significance after correcting for multiple comparisons. These hypotheses shed light on aspects of language processing which the model is not capturing well.
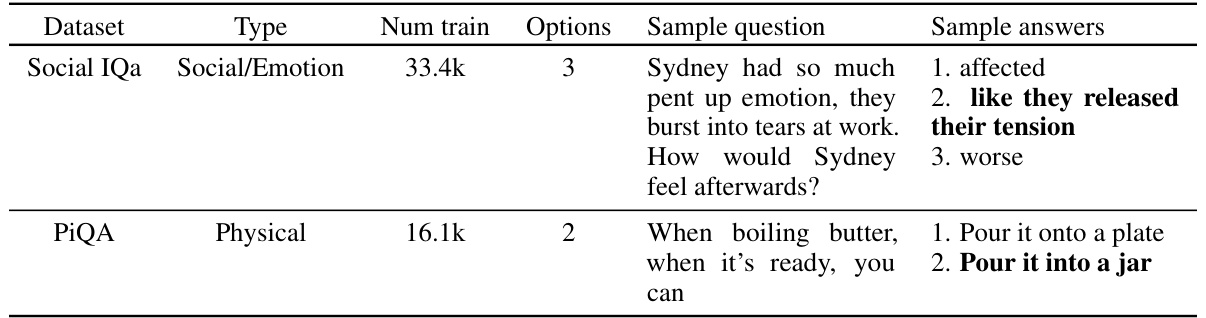
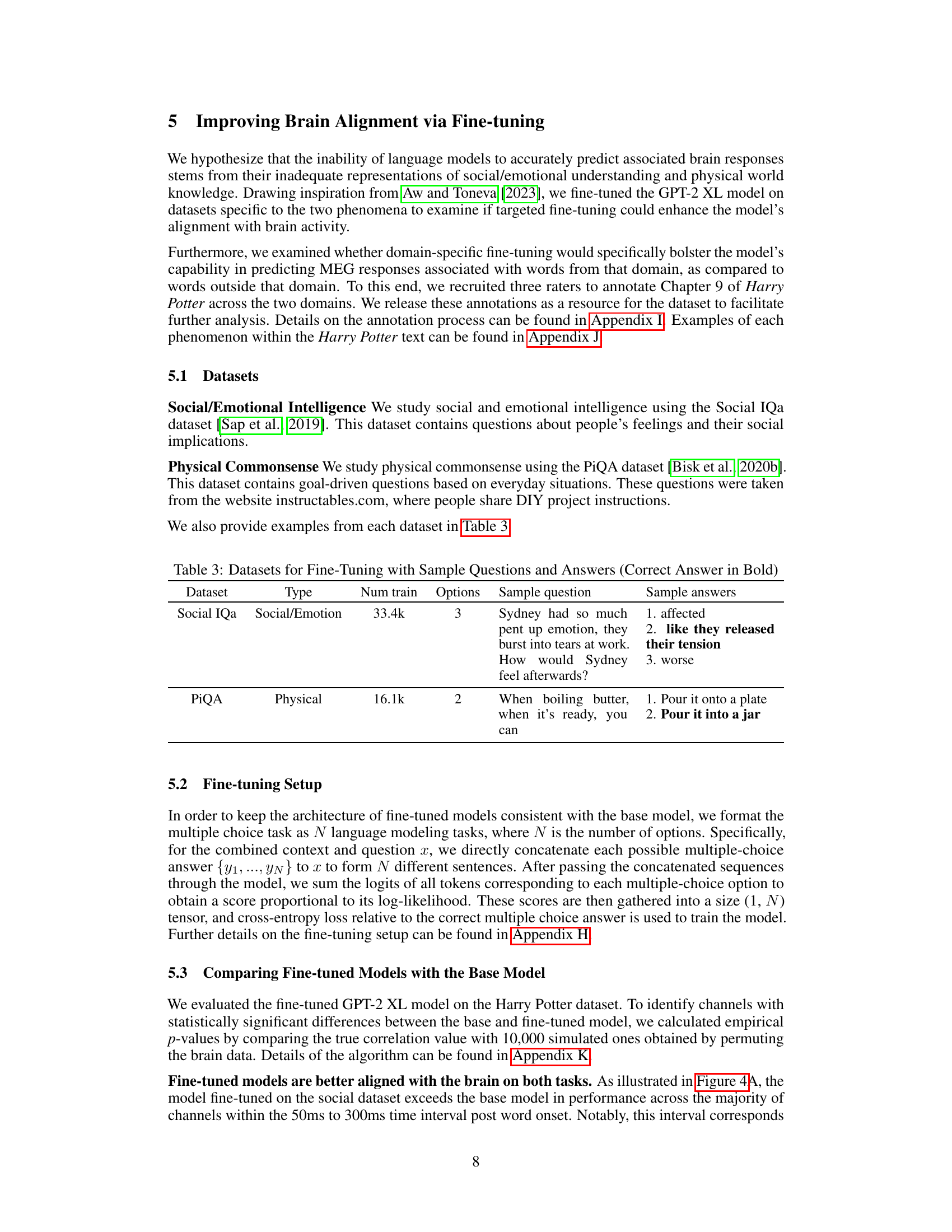
This table presents two datasets used for fine-tuning the language models: Social IQa (Social/Emotion) and PIQA (Physical). For each dataset, it lists the type, the number of training examples, the number of answer options per question, a sample question, and the corresponding sample answer choices. The correct answer is bolded for each example.

This table presents the top ten hypotheses generated by an LLM to explain divergences between human brain responses and GPT-2 XL model predictions on the Harry Potter dataset. The hypotheses are ranked by their validity (how well they distinguish between the sentences that the model predicted poorly versus well) and accompanied by their p-values. These hypotheses highlight aspects of language that are not well-captured by the model such as high levels of emotional intensity, complex sentence structures, emotional language, and characters interacting with their environment.

This table presents the top 10 hypotheses generated by an LLM to explain the discrepancies between human brain responses and the language model’s predictions for the Harry Potter dataset. The hypotheses focus on aspects related to physical actions, events, objects, and locations within the wizarding world, reflecting the strengths and limitations of the model in capturing different aspects of language understanding.
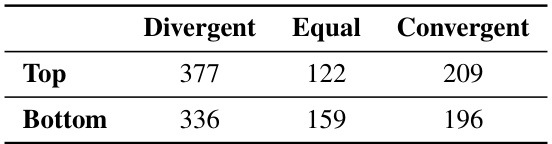
This table presents the results of a human evaluation experiment designed to validate the hypotheses generated by the LLM. Participants were given a hypothesis and two sentences, one from each of the sentence groups (divergent and convergent), and were asked to indicate which sentence best aligned with the hypothesis. The table shows the number of responses in each of three categories (Prefer Divergent, Equal, Prefer Convergent) for the top 10 and bottom 10 hypotheses.

This table presents the best epoch and accuracy achieved by fine-tuned language models on the Social IQa and PiQA datasets, compared against baseline (random) accuracy. It shows the performance of the models after fine-tuning on specific datasets for social/emotional intelligence and physical common sense.

This table presents the average loss and standard deviation across three cross-validation folds for different language models trained on the remaining chapters of Harry Potter. The models include a base model and models fine-tuned on either social or physical datasets. The loss values indicate the model’s performance on a language modeling task, with lower values reflecting better performance.
Full paper#