↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Sim-to-real transfer in reinforcement learning is challenging due to the discrepancies between simulated and real-world environments. Existing methods, such as Domain Randomization, often suffer from reduced performance, high training costs, or require significant amounts of real-world data. This limits the applicability and scalability of simulated training for complex robot control tasks.
This paper introduces EASI (Evolutionary Adversarial Simulator Identification), a novel approach that tackles sim-to-real challenges by framing the problem as a search. EASI leverages a unique collaboration between Generative Adversarial Networks (GAN) and Evolutionary Strategies (ES) to identify physical parameter distributions that bridge the simulation-reality gap. The method is shown to be simple, low cost, and high fidelity, making it suitable for various tasks. Experimental results demonstrate EASI’s superior performance to existing methods, both in sim-to-sim and sim-to-real settings.
Key Takeaways#
Why does it matter?#
This paper is important because it presents EASI, a novel and efficient method for sim-to-real transfer in robotics. EASI addresses the limitations of existing methods by combining GAN and ES, requiring less real-world data and offering superior performance. This opens new avenues for researchers working on robotics and sim-to-real transfer problems, and the proposed method is relevant to the current focus on reducing data requirements and improving the robustness of simulated training.
Visual Insights#
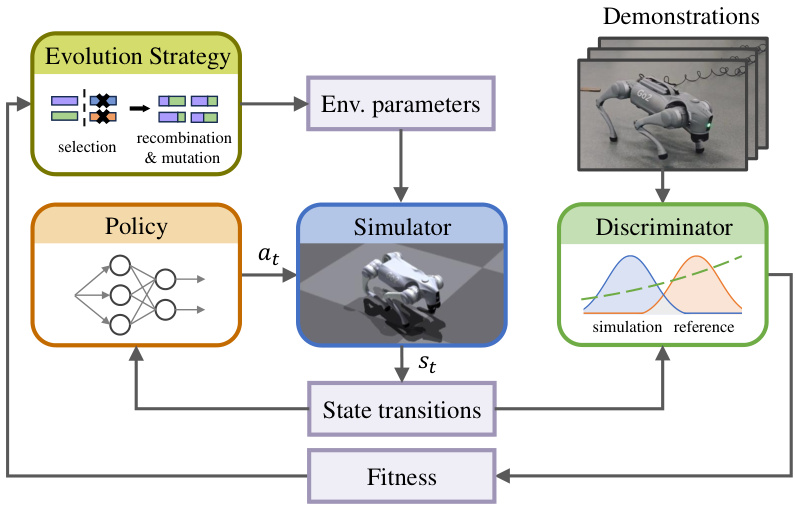
This figure shows a schematic overview of the Evolutionary Adversarial Simulator Identification (EASI) method. The figure depicts the interaction between four main components: the Evolutionary Strategy (ES), which evolves the simulator’s physical parameters; the policy (a neural network), which interacts with the simulator; the simulator itself, which generates state transitions; and a discriminator neural network, which aims to distinguish real-world state transitions from simulated ones. The discriminator’s output acts as the fitness function for the ES, guiding the parameter evolution to make the simulator’s state transitions more closely match those in the real world.

This table presents the performance of different sim-to-real transfer algorithms (UDR, FineTune, GARAT, and EASI) across four different target environments. Each target environment is created by manipulating a single parameter (Cartpole Cart DoF P, Ant Body Mass) at different levels (×0.25 or ×0.5). The results show that EASI consistently outperforms other methods in achieving higher rewards in these target environments, highlighting the effectiveness of EASI in adapting policies to the reality gap.
In-depth insights#
Sim-to-Real Gap#
The sim-to-real gap is a central challenge in reinforcement learning (RL) for robotics. It refers to the discrepancy between the simulated environment used for training RL agents and the real-world environment where they are deployed. Simulators, while offering cost-effective and safe training, inevitably fail to perfectly replicate the complexities of the real world. This mismatch stems from many factors, including imperfect modeling of physics, sensor noise, actuator dynamics, and unmodeled environmental disturbances. Bridging this gap is crucial for reliable real-world application of RL-trained robots. Approaches like domain randomization attempt to mitigate this gap by introducing variability into the simulator, but often at the cost of reduced performance and increased training time. More sophisticated methods focus on learning better models of the real world from limited real-world data, aiming to align the simulator to reality more closely, and thereby improving the transfer of learned policies. The sim-to-real gap highlights the limitations of relying solely on simulation for robot training and emphasizes the need for more robust and adaptable RL algorithms. Future research should focus on developing more efficient and effective methods for sim-to-real transfer, potentially leveraging techniques from system identification and robust control to further reduce the impact of the unavoidable discrepancies between simulation and the real world.
EASI Framework#
The EASI framework, designed for sim-to-real transfer in robotics, cleverly combines evolutionary strategies (ES) and generative adversarial networks (GANs). ES acts as a generator, searching for optimal physical parameters in a simulator, aiming to bridge the reality gap between simulated and real-world environments. The GAN’s discriminator serves as the fitness function for ES, guiding the parameter search toward greater realism. This adversarial setup allows EASI to effectively learn the underlying dynamics of the real world from relatively little real-world data, making it a cost-effective solution. The framework’s simplicity and high fidelity stand as key advantages, enabling the creation of more realistic simulators with minimal real-world data. EASI’s success is demonstrated in both sim-to-sim and sim-to-real tasks, surpassing existing methods. While it offers a significant advance, further exploration is needed to address potential challenges such as limitations arising from noisy sensor data or the need for substantial computational resources. Despite these limitations, EASI presents a significant step toward making sim-to-real transfer more robust and reliable.
GAN-ES Synergy#
The proposed GAN-ES synergy leverages the strengths of both Generative Adversarial Networks (GANs) and Evolutionary Strategies (ES) to achieve a robust and efficient sim-to-real transfer. GANs excel at learning complex data distributions, allowing the discriminator to effectively distinguish between real-world and simulated data. ES, on the other hand, excels at optimization in high-dimensional spaces, making it ideal for searching the vast parameter space of the simulator. By combining these two techniques, the system can accurately identify and correct the discrepancies between the simulation and reality, leading to more effective policy transfer. This synergistic approach is particularly powerful as it addresses common issues found in traditional sim-to-real methods such as high computational costs, susceptibility to overfitting, and the dependence on high-quality labeled data. The result is a method that is more efficient, accurate and robust for closing the simulation-reality gap.
Sim-to-Real Tests#
In a research paper evaluating a sim-to-real transfer method, a section titled “Sim-to-Real Tests” would be crucial for demonstrating the practical effectiveness of the proposed approach. This section should present rigorous experimental results comparing the performance of policies trained in simulation and then transferred to a real-world environment against alternative methods. Key aspects to be included are the choice of real-world robotic platforms and tasks, details of the experimental setup including any necessary calibrations or modifications for the real-world scenario, and a detailed comparison of the performance metrics (e.g., success rate, speed, robustness) across different methods. A critical element would be a discussion of the challenges encountered during the sim-to-real transfer, such as discrepancies between the simulated and real-world dynamics, sensor noise, or environmental variations. The analysis should explain how the proposed method addresses these challenges and any limitations observed. Finally, the results should be presented with clear visualizations (e.g., graphs, tables) and statistical analysis to demonstrate the significance of any performance differences observed. Robustness is key—the analysis should explore how sensitive the results are to different hyperparameters and experimental conditions. The section’s overall goal would be to build confidence in the proposed method’s ability to effectively bridge the reality gap.
Future of EASI#
The future of EASI (Evolutionary Adversarial Simulator Identification) looks promising, given its demonstrated ability to bridge the reality gap in sim-to-real transfer. Further research could focus on enhancing its scalability and efficiency, particularly for high-dimensional control tasks and complex robots. Investigating alternative fitness functions beyond the GAN discriminator could potentially improve convergence speed and stability. Exploring different evolutionary strategies beyond ES might unlock superior performance or enable adaptation to specific problem structures. Integration with other sim-to-real techniques, such as domain randomization or data augmentation, holds the potential to create even more robust and reliable sim-to-real pipelines. Finally, a crucial area for future work involves extensive testing across diverse robotic platforms and real-world scenarios to thoroughly validate EASI’s generalizability and robustness. Addressing limitations related to the reliance on demonstration data and potential biases inherent in the training dataset are also essential for broader applicability.
More visual insights#
More on figures

This figure provides a schematic overview of the Evolutionary Adversarial Simulator Identification (EASI) method. It shows the main components of the system: an Evolutionary Strategy (ES) which acts as a generator of simulator parameters, a simulator, a discriminator neural network that distinguishes between real and simulated state transitions, and a feedback loop guided by the discriminator’s output. The ES evolves the simulator’s parameters based on the discriminator’s assessment of how well the simulated state transitions match the real-world transitions. The discriminator’s output acts as a fitness function, guiding the evolutionary process. The ultimate goal is to find a set of simulator parameters that produce state transitions highly similar to those observed in the real world.

This figure shows four different simulated robotic control tasks used in the paper’s experiments. From left to right, these are: a simple inverted pendulum on a cart (Cartpole), a quadrupedal robot (Go2), a simplified ant-like robot (Ant), and a ball balancing task on a three-legged platform (Ballbalance). These tasks represent different complexities and degrees of freedom, allowing for a thorough evaluation of the proposed sim-to-real transfer method.

This figure shows two real-world robotic tasks used to evaluate the EASI algorithm’s sim-to-real transfer capabilities. The left panel displays the Cartpole task, where the goal is to balance a pendulum on a cart by applying appropriate control actions. The right panel shows the Go2 task, which involves controlling a quadrupedal robot to maintain forward locomotion while adhering to a specified speed.
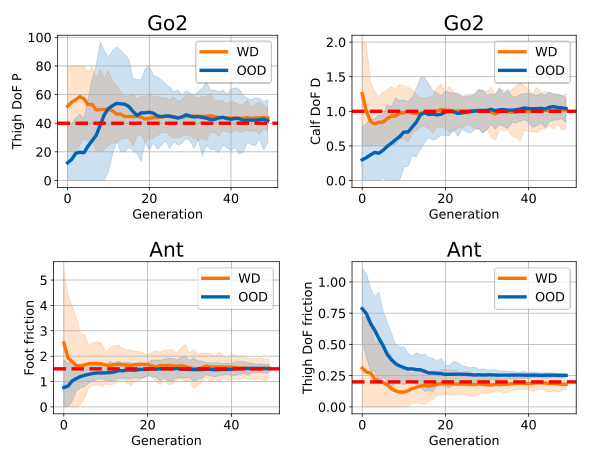
This figure shows the parameter convergence process of EASI for the Go2 robot in a sim-to-sim setting. It displays the evolution of ten parameters over 40 generations, comparing two scenarios: WD (target parameters within the initial distribution) and OOD (target parameters outside the initial distribution). The plots illustrate how EASI efficiently adjusts parameter distributions to align the simulator with a target environment, regardless of whether the initial parameters are within or outside the target range. The dashed red line indicates the true value of the target parameter.
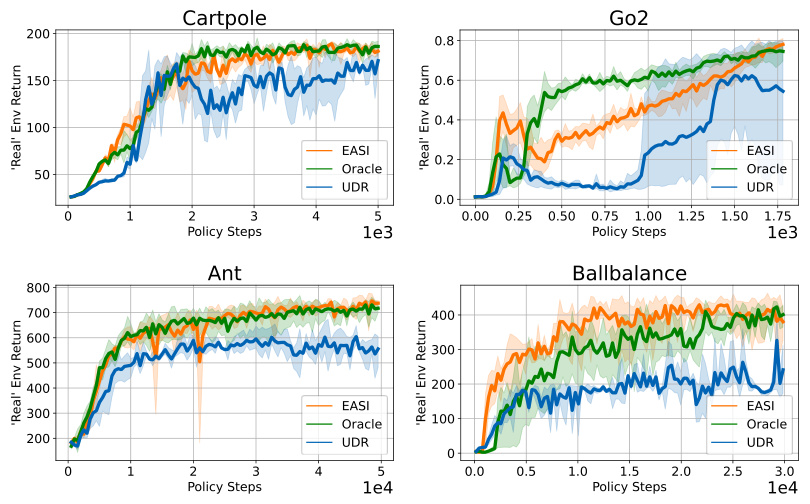
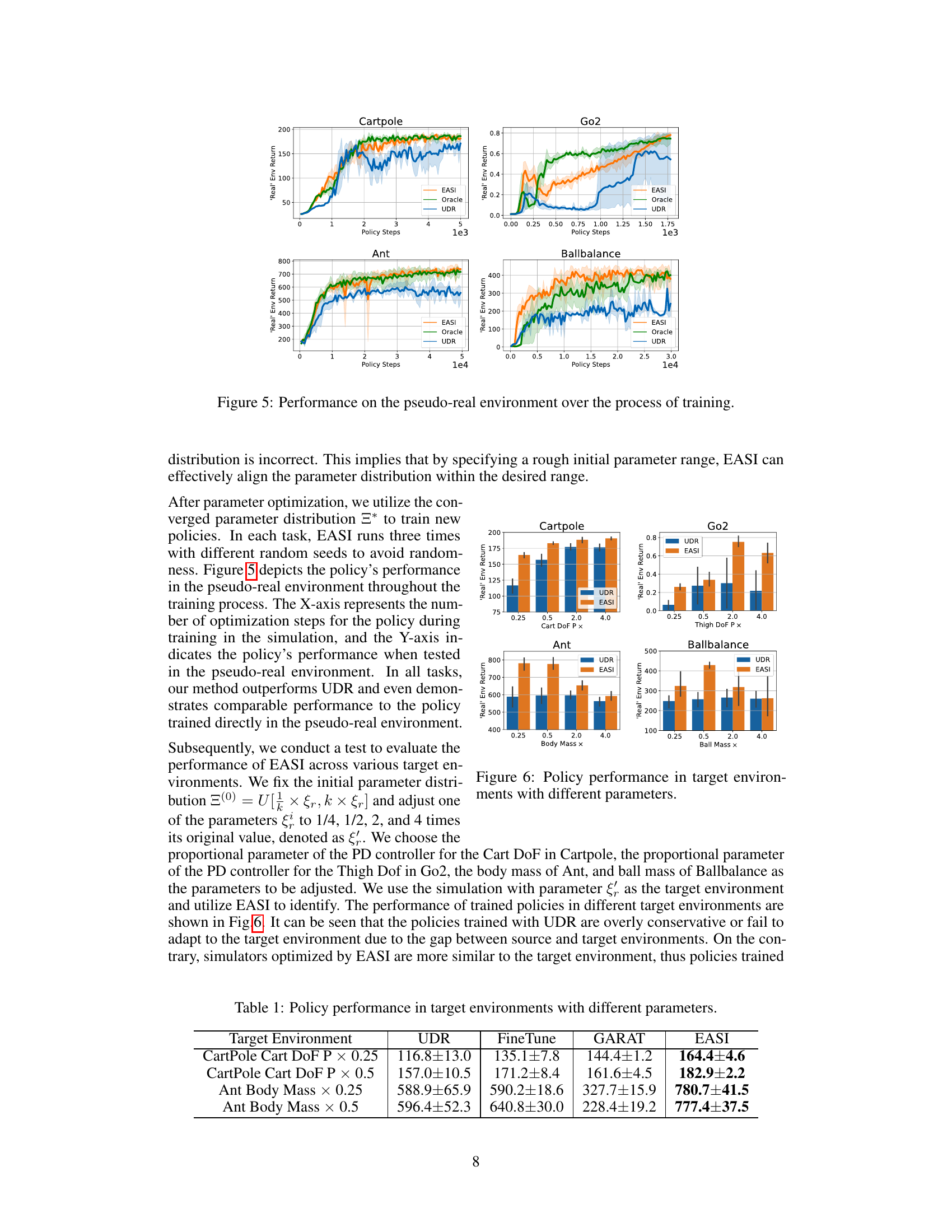
This figure visualizes the performance of policies trained using EASI, UDR (Uniform Domain Randomization), and an Oracle (ideal performance) in a pseudo-real environment. The x-axis represents the number of policy training steps, and the y-axis represents the return (cumulative reward) in the pseudo-real environment. The shaded area around each line represents the standard deviation across multiple runs. The figure demonstrates that EASI achieves performance comparable to the Oracle, significantly outperforming UDR in all four tested environments (Cartpole, Go2, Ant, and Ballbalance).

This figure visualizes the performance of policies trained using EASI and UDR in various target environments. Each bar represents the average return achieved by the policy in a specific target environment, with error bars indicating variability. The x-axis shows the scaling factor applied to specific parameters (Cart DoF P, Thigh DoF P, Body Mass, Ball Mass). The y-axis shows the average return (cumulative reward). The figure demonstrates that EASI-trained policies generally outperform UDR policies across all target environments and parameters, highlighting EASI’s ability to improve sim-to-real transfer by optimizing the simulator parameters.
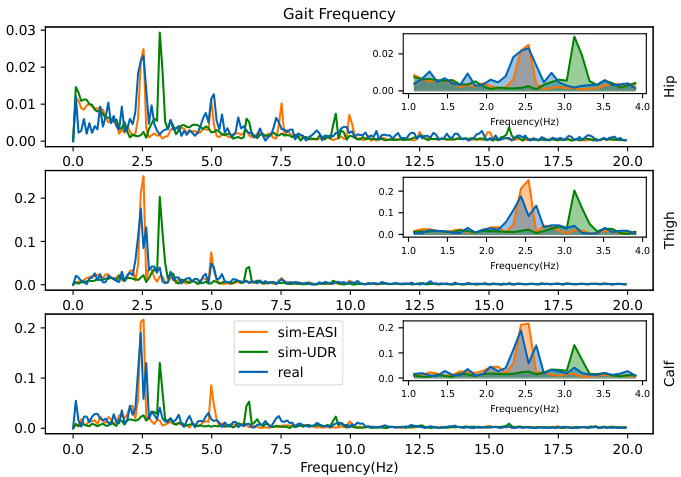
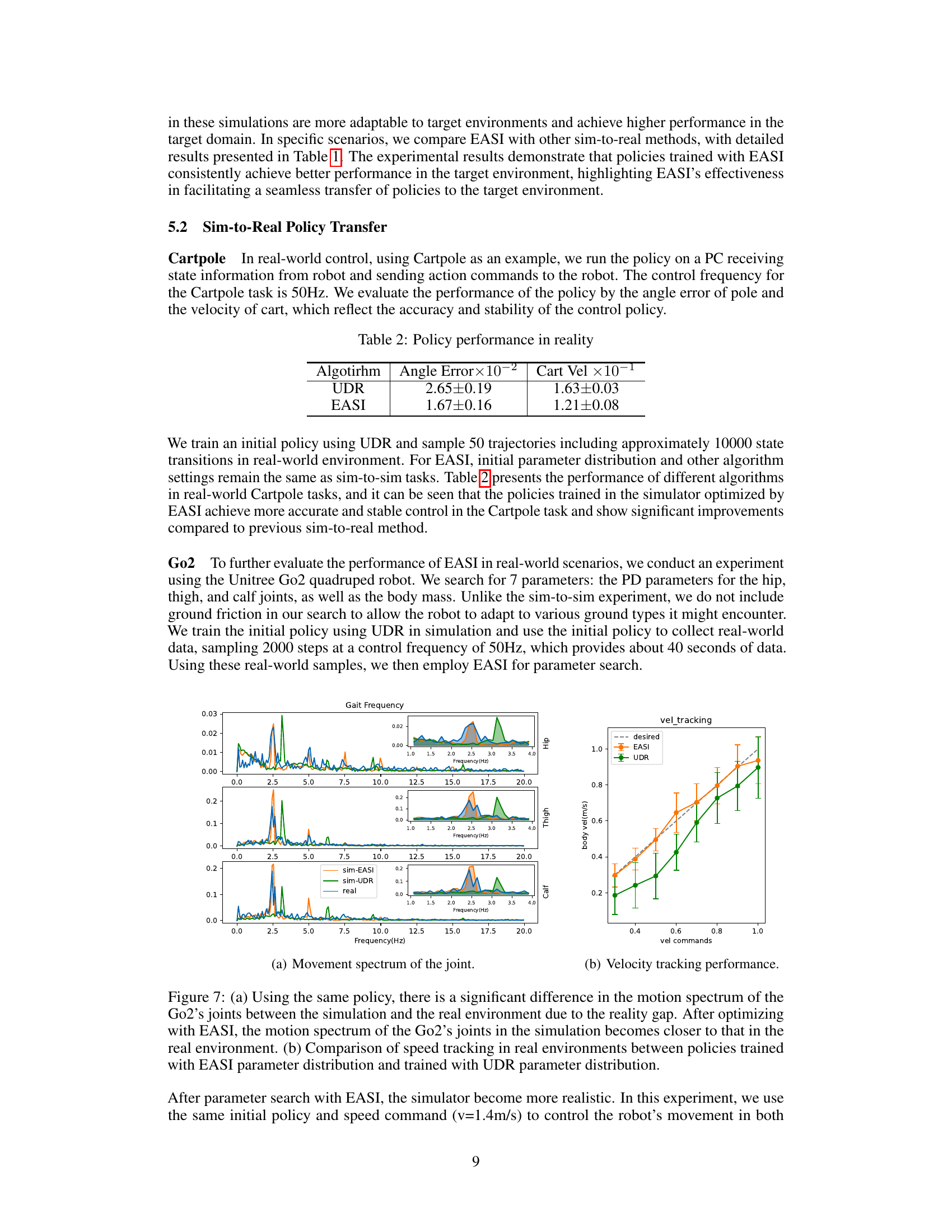
This figure compares the frequency spectrum of the Go2 robot’s joint movements and its speed tracking performance in simulation and reality. The left subplot (a) shows that before using EASI, there is a significant difference between the simulation and reality due to the reality gap. After applying EASI, the simulation’s frequency spectrum is much closer to the real-world data, indicating that EASI successfully reduces the reality gap. The right subplot (b) shows the speed tracking performance in the real world, demonstrating that the policy trained with EASI parameters outperforms the one trained with UDR parameters, achieving more accurate and stable control.

This figure compares the performance of policies trained using EASI and UDR in a real-world scenario. Subfigure (a) shows the frequency spectrums of joint movements in simulation (with EASI and UDR) and reality, demonstrating how EASI significantly reduces the difference between simulation and reality. Subfigure (b) shows the velocity tracking performance of both methods, indicating that EASI achieves better performance.
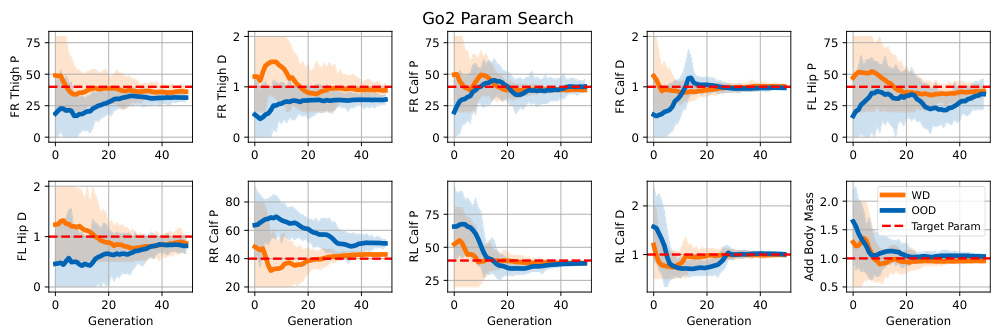
This figure visualizes the parameter search process of EASI in the Go2 environment. It presents ten out of 25 parameters being optimized, showing the convergence of parameters towards their target values. Two scenarios are compared: ‘WD’ (target parameter within the initial parameter distribution) and ‘OOD’ (target parameter outside the initial distribution). The plots illustrate how EASI adjusts parameter distributions across generations (x-axis), regardless of the initial distribution.
More on tables

This table presents the performance comparison of two algorithms, UDR and EASI, in terms of their ability to control a real-world Cartpole. The performance is measured by two metrics: angle error of the pole and velocity of the cart. Lower values indicate better performance. EASI demonstrates superior performance over UDR in both metrics, achieving significantly lower angle error and cart velocity.

This table presents the performance of the EASI algorithm in four different sim-to-sim tasks (Cartpole, Ant, Ballbalance, and Go2) with varying amounts of real-world data used for training. The results demonstrate EASI’s ability to effectively transfer policies from simulation to reality with a limited number of real-world data samples.

This table presents the results of a hyperparameter sensitivity analysis performed on the EASI algorithm. The analysis focuses on the ratio of μ (number of elite individuals selected) to λ (number of individuals in each generation) within the evolutionary strategy used in EASI. The table shows the impact of different μ/λ values on the parameter search error, a measure of how well EASI is able to find the desired simulator parameters. Lower parameter search error indicates better performance.

This table presents the performance of different sim-to-real transfer algorithms (UDR, Fine Tune, GARAT, and EASI) on four simulated robotic tasks (Cartpole, Go2, Ant, and Ballbalance) with modified physical parameters. Each row represents a task and a parameter variation (e.g., Cartpole Cart DoF P × 0.25 indicates the Cartpole task with the proportional parameter of the PD controller for the Cart DoF set to 0.25 times its original value). The numbers show the average return of the trained policy in each setting, demonstrating EASI’s robustness to parameter variations compared to other algorithms.
Full paper#